Entrenamiento paralelo de datos distribuidos basado en Pytorch
Introducción: uso de DistributedDataParallel en PyTorch para el entrenamiento de modelos distribuidos de múltiples GPU
motivación
La forma más fácil de acelerar el entrenamiento de redes neuronales es usar GPU, que proporcionan una mayor velocidad que las CPU en tipos de cálculos comunes en redes neuronales (multiplicación y suma de matrices). A medida que los modelos o conjuntos de datos crecen, una GPU puede volverse insuficiente rápidamente. Por ejemplo, los modelos de lenguajes grandes como BERT y GPT-2 se entrenan en cientos de GPU. Para realizar un entrenamiento multi-GPU, debemos tener una forma de dividir el modelo y los datos entre las diferentes GPU y coordinar el entrenamiento .
¿Por qué distribuir datos en paralelo?
Mucha gente prefiere implementar sus propios modelos de aprendizaje profundo en Pytorch porque tiene el mejor equilibrio entre el control y la facilidad de uso del marco de la red neuronal. Pytorch tiene dos formas de dividir modelos y datos en varias GPU : nn.DataParallely nn.DistributedDataParallel.
nn.DataParallel es más fácil de usar (simplemente ajuste el modelo y ejecute el script de entrenamiento). Sin embargo, dado que utiliza un proceso para calcular los pesos de los modelos y luego los distribuye a cada GPU en cada lote, la red se convierte rápidamente en un cuello de botella y la utilización de GPU suele ser baja . Además, nn.DataParallel requiere que todas las GPU estén en el mismo nodo y no se puede usar con Apex para entrenamiento de precisión mixta .
Por lo tanto, las principales diferencias entre nn.DataParallely nn.DistributedDataParallelse pueden resumir de la siguiente manera:
1. DistributedDataParallel admite el paralelismo de modelos, mientras que DataParallel no, lo que significa que si el modelo es demasiado grande y la memoria de una sola tarjeta es insuficiente, solo se puede usar el primero. 2.
DataParallel es un multiproceso de un solo proceso, solo se usa para situaciones de una sola máquina, mientras que DistributedDataParallel es multiproceso, adecuado para situaciones de una sola máquina y varias máquinas, y realmente realiza entrenamiento
distribuido ; DistributedDataParallel es más eficiente, porque cada proceso es un intérprete de Python independiente, evitando el problema de GIL, y el costo de comunicación es bajo, su velocidad de entrenamiento es más rápida, básicamente se ha abandonado DataParallel 4. Se debe explicar que cada proceso en DistributedDataParallel tiene
un optimizador independiente, que realiza su propio proceso de actualización, pero el gradiente pasa Pasado a cada proceso, el contenido es el mismo para todas las ejecuciones.
Insuficiencia de la información disponible
En general, la documentación de Pytorch es completa y clara, sin embargo, al tratar de descubrir cómo usarla DistributedDataParallel, se descubre que todos los ejemplos y tutoriales son una combinación de funciones irrelevantes inaccesibles, incompletas o sobrecargadas.
Pytorch proporciona un tutorial sobre capacitación distribuida con AWS que hace un buen trabajo al mostrar cómo configurarlo en el lado de AWS. Sin embargo, el resto es un poco complicado, porque por alguna razón dedica mucho tiempo a mostrar cómo calcular las métricas y luego vuelve a mostrar cómo envolver el modelo e iniciar el proceso. Tampoco describe nn.DistributedDataParallello que hace, lo que hace que los bloques de código relacionados sean difíciles de seguir.
Los tutoriales sobre cómo escribir aplicaciones distribuidas con Pytorch son mucho más detallados de lo necesario para un primer paso, y son inaccesibles para alguien sin experiencia en el multiprocesamiento de Python. Pasa mucho tiempo duplicando nn.DistributedDataParallella funcionalidad en él. Sin embargo, no brinda una descripción general de alto nivel de lo que hace, ni brinda información sobre cómo usarlo ( https://pytorch.org/tutorials/intermediate/ddp_tutorial.html )
También hay un tutorial de Pytorch sobre cómo comenzar con el paralelismo de datos distribuidos . Este muestra cómo hacer alguna configuración, pero no explica el propósito de la configuración, y luego muestra un código para dividir el modelo entre GPU y hacer un paso de optimización . Desafortunadamente, estoy bastante seguro de que el código escrito no se ejecutará (los nombres de las funciones no coinciden) y no le dice cómo ejecutar el código. Al igual que los tutoriales anteriores, no brinda una descripción general de alto nivel de cómo funciona el entrenamiento distribuido.
Lo más parecido que proporciona Pytorch al ejemplo de MWE es el ejemplo de formación de Imagenet. Desafortunadamente, este ejemplo también demuestra casi todas las demás características de Pytorch, por lo que es difícil averiguar qué es relevante para el entrenamiento distribuido de múltiples GPU.
ApexProporciona su propia versión del ejemplo Pytorch Imagenet. Su versión de nn.DistributedDataParallel es un reemplazo de Pytorch que solo es útil después de aprender a usar Pytork.
Este tutorial hace un buen trabajo al describir lo que sucede debajo del capó y en qué se nn.DataParalleldiferencia de Sin embargo, no tiene nn.DataParallelejemplos de código sobre cómo usarlo.
Describir
Este tutorial está realmente dirigido a aquellos que ya están familiarizados con el entrenamiento de modelos de redes neuronales en Pytorch . Comience por esbozar la idea general. Luego, se muestra un ejemplo de trabajo mínimo de entrenamiento con MNIST en GPU. Modifiqué este ejemplo para entrenar en varias GPU, posiblemente en varios nodos, y explicar los cambios línea por línea. Es importante destacar que también explica cómo ejecutar el código. Como beneficio adicional, también demuestra cómo realizar Apexun entrenamiento distribuido simple de precisión mixta con .
diagrama general del marco
El uso DistributedDataParallelde multiprocesamiento replica el modelo en múltiples GPU , cada una controlada por un solo proceso. (Un proceso es una instancia de python que se ejecuta en una computadora; al tener múltiples procesos ejecutándose en paralelo, podemos aprovechar los procesadores que tienen múltiples núcleos de CPU. Si lo desea, puede hacer que cada proceso controle múltiples GPU, pero eso obviamente es menos eficiente que Tener una GPU por proceso es más lento. También es posible tener varios procesos de trabajo que obtengan datos para cada GPU, pero esto se omitirá por simplicidad.) Las GPU pueden estar todas en el mismo nodo o distribuidas en varios nodos. (Un nodo es una "computadora", incluidas todas sus CPU y GPU. Si usa AWS, un nodo es una instancia EC2). Cada proceso realiza la misma tarea y cada proceso se comunica con todos los demás procesos . Solo se pasan gradientes entre procesos/GPU para que la comunicación de la red no se convierta en un cuello de botella.
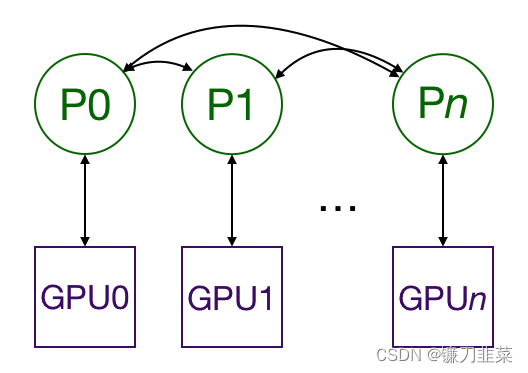
Durante el entrenamiento, cada proceso carga sus propios mini lotes desde el disco y los pasa a la GPU. Cada GPU tiene su propio paso hacia adelante y luego los gradientes se reducen entre las GPU. El gradiente de cada capa no depende de la capa anterior, por lo que el gradiente de reducción total se calcula simultáneamente con el paso hacia atrás para aliviar aún más el cuello de botella de la red. Al final del proceso inverso, cada nodo tiene un gradiente promedio, lo que garantiza que los pesos del modelo permanezcan sincronizados .
Todos estos requieren múltiples procesos (posiblemente en múltiples nodos) para sincronizarse y comunicarse . Pytorch distributed.init_process_grouplogra esto a través de sus funciones. Esta función necesita saber dónde encontrar el proceso 0 para que todos los procesos puedan sincronizarse y el número total esperado de procesos . Cada proceso individual también necesita saber el número total de procesos y su rango en el proceso y qué GPU se utiliza. world sizeEs muy común referirse al número total de procesos . Finalmente, cada proceso necesita saber qué parte de los datos procesar para que los lotes no se superpongan. Pytorch proporciona nn.utils.data.DistributedSamplerpara lograr esto, que consiste en dividir los datos de cada proceso para garantizar que los datos de entrenamiento no se superpongan.
Para un mecanismo interno más detallado de DDP, consulte la documentación oficial: DATOS DISTRIBUIDOS EN PARALELO
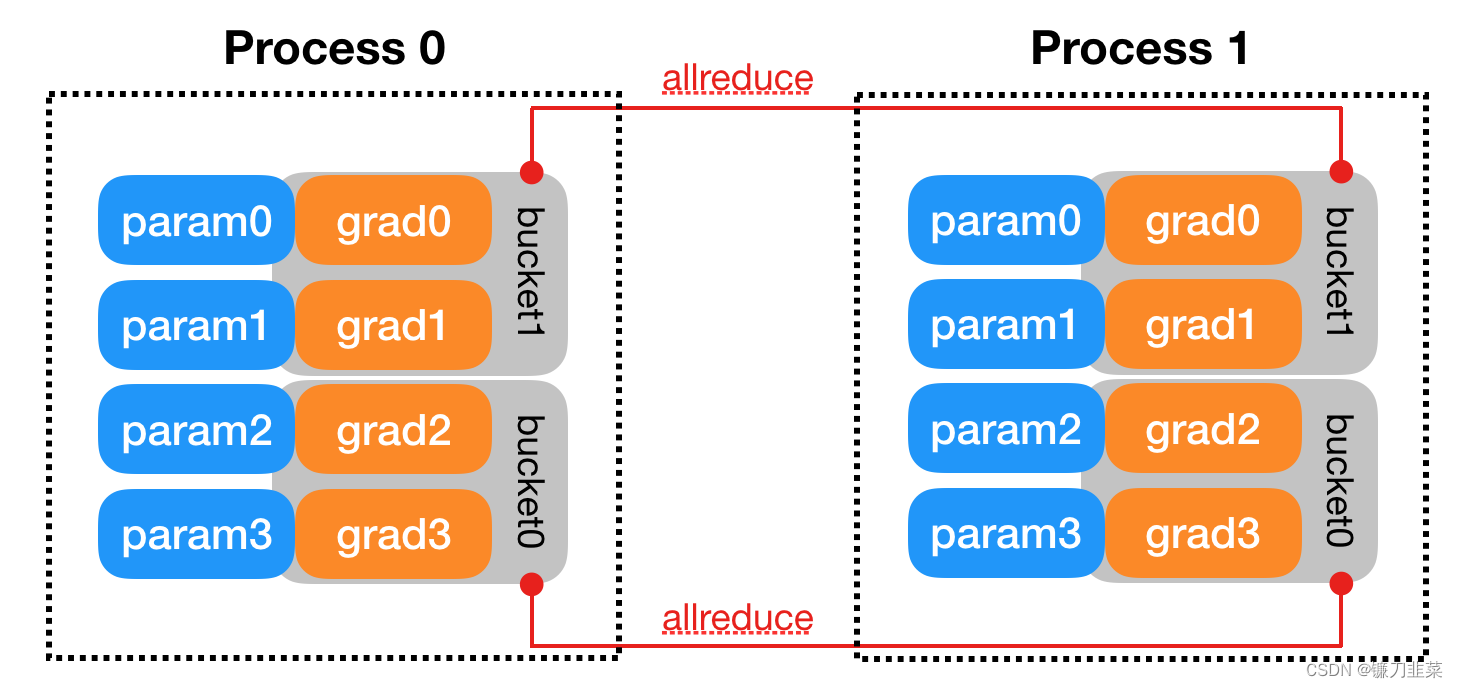
Ejemplo de demostración mínimo con explicación
Para demostrar cómo se puede hacer esto, crearemos un ejemplo que se entrena en MNIST, luego lo modificaremos para que se ejecute en múltiples GPU en múltiples nodos y, finalmente, también permitirá el entrenamiento de precisión mixta.
sin multiprocesamiento
Primero, importa las dependencias requeridas:
import os
import argparse
import torch
import torch.nn as nn
import torch.distributed as dist
import torch.multiprocessing as mp
import torchvision
import torchvision.transforms as transforms
from datetime import datetime
from apex.parallel import DistributedDataParallel as DDP
from apex import amp
Definimos un modelo convolucional muy simple para predecir MNIST.
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc = nn.Linear(7 * 7 * 32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
El siguiente es el proceso de formación:
def train(gpu, args):
torch.manual_seed(0)
model = ConvNet()
torch.cuda.set_device(gpu)
model.cuda(gpu)
# model = nn.DataParallel(model, device_ids=device_ids)
# model = model.cuda(device=gpu)
batch_size = 100
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
# Data loading code
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(),
download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True,
num_workers=0, pin_memory=True)
start = datetime.now()
total_step = len(train_loader)
for epoch in range(args.epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
labels = labels.cuda(non_blocking=True)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0 and gpu == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch + 1, args.epochs, i + 1, total_step,
loss.item()))
if gpu == 0:
print("Training complete in: " + str(datetime.now() - start))
La función main() tomará algunos parámetros y ejecutará la función de entrenamiento.
def main():
parser = argparse.ArgumentParser()
parser.add_argument("-n", "--nodes", default=1, type=int, metavar='N')
parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node')
parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes')
parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run')
args = parser.parse_args()
train(0, args)
Finalmente, asegúrese de llamar a la función main().
if __name__ == '__main__':
main()
Puede ejecutar este código abriendo una terminal y escribiendo python src/mnist.py-n 1-g 1-nr 0, y se entrenará en una sola GPU en un solo nodo.
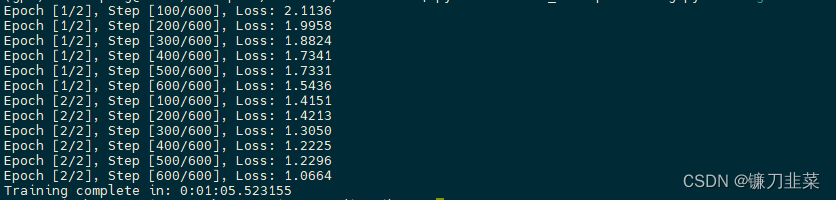
Habilitar multiprocesamiento
Para hacer esto con multiprocesamiento, necesitamos un script para iniciar un proceso para cada GPU . Cada proceso necesita saber qué GPU usar y su rango entre todos los procesos en ejecución . El script debe ejecutarse en cada nodo.
Eche un vistazo a los cambios en cada función. El nuevo código ha sido aislado para facilitar su búsqueda:
def main():
parser = argparse.ArgumentParser()
parser.add_argument("-n", "--nodes", default=1, type=int, metavar='N')
parser.add_argument('-g', '--gpus', default=1, type=int, help='number of gpus per node')
parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes')
parser.add_argument('--epochs', default=2, type=int, metavar='N', help='number of total epochs to run')
args = parser.parse_args()
#########################################################
args.world_size = args.gpus * args.nodes
os.environ['MASTER_ADDR'] = '172.20.109.105'
os.environ['MASTER_PORT'] = '8888'
mp.spawn(train, nprocs=args.gpus, args=(args,))
#########################################################
# train(0, args)
en:
args.nodesrepresenta el número total de nodos,args.gpusIndica el número total de GPU por nodo (el número de GPU por nodo es el mismo)args.nrIndica el número de serie del nodo actual entre todos los nodos.
De acuerdo con la cantidad total de nodos y la cantidad de GPU por nodo, se puede calcular world_size, es decir, la cantidad total de procesos a ejecutar.Todos los procesos necesitan saber la dirección IP y el puerto del proceso 0, para que todos los procesos se puede sincronizar al principio.Generalmente al proceso 0 se le llama El proceso maestro , por ejemplo, imprimiremos información o guardaremos el modelo en el proceso 0.
PyTorch permite mp.spawniniciar todos los procesos del nodo en un nodo , cada proceso se ejecuta train(i, args), donde i es de 0 a args.gpus-1. Recuerde ejecutar la función main() en cada nodo para que haya un total de args.nodes*args.gpus=args.world_sizeprocesos.
Nuevamente, queremos modificar la función de entrenamiento:
def train(gpu, args):
############################################################
rank = args.nr * args.gpus + gpu
dist.init_process_group(backend='nccl', init_method='env://', world_size=args.world_size, rank=rank)
############################################################
torch.manual_seed(0)
model = ConvNet()
torch.cuda.set_device(gpu)
model.cuda(gpu)
batch_size = 100
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
############################################################
# Wrap the model
model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
############################################################
# Data loading code
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(),
download=True)
############################################################
train_sampler = torch.utils.data.distributed.DistributedSampler(dataset=train_dataset, num_replicas=args.world_size,
rank=rank)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=False,
num_workers=0, pin_memory=True, sampler=train_sampler)
############################################################
start = datetime.now()
total_step = len(train_loader)
for epoch in range(args.epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
labels = labels.cuda(non_blocking=True)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0 and gpu == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch + 1, args.epochs, i + 1, total_step,
loss.item()))
if gpu == 0:
print("Training complete in: " + str(datetime.now() - start))
Aquí, primero calcule el número de programa actual: rank = args.nr * args.gpus + gpuy luego dist.init_process_groupinicialice el entorno distribuido, donde
backendEl parámetro especifica el backend de comunicación , incluidosmpi,gloo,nccly se selecciona aquíncclEs el marco de comunicación oficial de varias tarjetas proporcionado por Nvidia, que es relativamente eficiente.mpiTambién es un protocolo de comunicación común para la informática de alto rendimiento, pero debe instalar el marco de implementación de MPI usted mismo, por ejemploOpenMPI.glooTiene un backend de comunicación incorporado, pero no es lo suficientemente eficiente.init_methodSe refiere a cómo inicializar para completar la sincronización del proceso al principio. Lo que establecemos aquí se refiereenv://al método de inicialización de la variable de entorno. Se deben configurar cuatro parámetros en la variable de entorno:MASTER_PORT,MASTER_ADDR,WORLD_SIZE,RANK, ya hemos configurado los dos primeros parámetros, Estos dos últimos parámetros también se pueden configurar a través de los parámetros de neutralizacióndist.init_process_groupde funciones . Otros métodos de inicialización incluyen el sistema de archivos compartidos y TCP Por ejemplo, si se usa TCP como método de inicialización , se debe proporcionar la dirección IP y el puerto del maestro. Tenga en cuenta que esta llamada está bloqueando y debe esperar a que todos los procesos se sincronicen, y fallará si falla algún proceso.world_sizerankinit_method='tcp://10.1.1.20:23456'- Para el lado del modelo, solo necesita
DistributedDataParallelenvolver el modelo original, copiar el modelo a la GPU para procesarlo y admitirá las operaciones de All-Reduce de gradiente en segundo plano. - Para el lado de los datos, utilícelo
nn.utils.data.DistributedSamplerpara dividir datos para cada proceso, solo necesitadataloaderusarlo ensampler, vale la pena señalar que debe llamarse al comienzo de cada época en el proceso del ciclo de capacitacióntrain_sampler.set_epoch(epoch)(principalmente para asegurar la división de cada época son diferentes) otros códigos de entrenamiento permanecen sin cambios.
Finalmente, se puede ejecutar el código, por ejemplo, si tenemos 4 nodos y cada nodo tiene 8 tarjetas gráficas, entonces necesitamos ejecutarlas en los terminales de los 4 nodos:
python src/mnist-distributed.py -n 4 -g 8 -nr i
Por ejemplo, ejecute en el nodo 0:
python src/mnist-distributed.py -n 4 -g 8 -nr 0
args.gpusEn otras palabras, ejecutar este script en cada nodo le indica que inicie procesos que estén sincronizados entre sí antes de que comience el entrenamiento .
Cabe señalar que lo que es efectivo en este momento batch_sizees que batch_size_per_gpu * world_sizepara modelos con BN, también se puede usar BN síncrona para obtener mejores resultados:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
Lo anterior describe el proceso de entrenamiento distribuido, que también es aplicable al proceso de evaluación o prueba , por ejemplo, dividimos los datos en diferentes procesos para la predicción, lo que puede acelerar el proceso de predicción. El código de implementación es exactamente el mismo que el del proceso anterior, pero si queremos calcular un determinado indicador, debemos realizar All-Reduce a partir de los resultados estadísticos de cada proceso , ya que cada proceso solo calcula una parte del contenido de los datos. Por ejemplo, si queremos calcular la precisión de la clasificación, podemos contar el número total de datos y el número de conteos de clasificación correctos de cada proceso, y luego agregarlos.
Una cosa a mencionar aquí es que al inicializar un entorno distribuido, dist.init_process_groupen realidad se establece un grupo de procesos distribuidos predeterminado (grupo de procesos distribuidos) Este grupo también inicializará el torch.distributedpaquete Pytorch. De esta forma, la API que podemos usar directamente torch.distributedpuede realizar operaciones básicas distribuidas, la siguiente es la implementación específica:
# define tensor on GPU, count and total is the result at each GPU
t = torch.tensor([count, total], dtype=torch.float64, device='cuda')
dist.barrier() # synchronizes all processes
dist.all_reduce(t, op=torch.distributed.ReduceOp.SUM,) # Reduces the tensor data across all machines in such a way that all get the final result.
t = t.tolist()
all_count = int(t[0])
all_total = int(t[1])
acc = all_count / all_total
Método de inicio de entrenamiento distribuido
En el proceso anterior, el torch.multiprocessingpaquete PyTorch ( Paquete de multiprocesamiento - torch.multiprocessing ) se usa para iniciar el entrenamiento distribuido. Actualmente, el ejemplo de entrenamiento oficial de ImageNet se usa de esta manera, y la biblioteca detectron2 también se inicia de esta manera: https:/ / github.com/facebookresearch/detectron2/blob/main/detectron2/engine/launch.py.
Si usa torch.multiprocessing.spawnel inicio, debe prestar atención a que el entrenamiento de entrada functiondebe estar en fn(i,*args)este formato, donde el primer parámetro i se refiere al número de proceso del nodo actual, este parámetro en realidad sirve como el local_rankllamado local_rankproceso de entrenamiento en el nodo actual Serial número, el rango mencionado anteriormente es en realidad el número de programa global. Este parámetro es muy importante, porque el dispositivo dispositivo utilizado por cada proceso debe configurarse de acuerdo con este parámetro. En general, se considera directamente como el número de GPU utilizado y la configuración es como local_ranksigue:
torch.cuda.set_device(args.local_rank) # before your code runs
# set DDP
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)
# 或者
with torch.cuda.device(args.local_rank):
# your code to run
Además de adoptar mp.spawn, también se puede utilizar torch.distributed.launchpara iniciar el programa ( paquete de comunicación distribuida - torch.distributed ), que es una forma más común de iniciar. Por ejemplo, para el entrenamiento de varias tarjetas en una sola máquina, el método de inicio es el siguiente:
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS_YOU_HAVE
YOUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3 and all other arguments of your training script)
Entre ellos NUM_GPUS_YOU_HAVEestá la cantidad total de GPU, YOUR_TRAINING_SCRIPT.pypero el script de entrenamiento, que es básicamente el mismo que el anterior, pero la diferencia es torch.distributed.launchque algunas variables de entorno ( ) se establecerán automáticamente al iniciar, https://github.com/pytorch/pytorch/blob/master/torch/distributed/run.py#L211por ejemplo, lo que necesitamos RANKy WORLD_SIZEse puede obtener. directamente de las variables de entorno:
rank = int(os.environ["RANK"])
world_size = int(os.environ['WORLD_SIZE'])
Hay local_rankdos formas de obtener:
1) Una es agregar un parámetro de línea de comando al script de entrenamiento, que se asignará automáticamente cuando se inicie el programa :
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int)
args = parser.parse_args()
local_rank = args.local_rank
2) Otra forma es torch.distributed.launchcomenzar con plus --use_env=True.En este caso, LOCAL_RANKesta variable de entorno se establecerá y se puede obtener de la variable de entorno local_rank:
"""
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS_YOU_HAVE --use_env=True
YOUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3 and all other arguments of your training script)
"""
import os
local_rank = int(os.environ["LOCAL_RANK"])
Para el entrenamiento de varias máquinas y varias tarjetas , como dos nodos, el comando de inicio es el siguiente:
# Node 1: (IP: 192.168.1.1, and has a free port: 1234)
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS_YOU_HAVE --nnodes=2 --node_rank=0 --master_addr="192.168.1.1"
--master_port=1234 YOUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3 and all other arguments of your training script)
# Node 2
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS_YOU_HAVE --nnodes=2 --node_rank=1 --master_addr="192.168.1.1"
--master_port=1234 YOUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3 and all other arguments of your training script)
aquí
--nnodesIndica el número de nodos entrantes--node_rankIndica el número del nodo entranteworld_size=nnodes*nproc_per_node。
Sin embargo, la última versión de PyTorch ha lanzado torchrun en su lugar torch.distributed.launch. torchrunEl uso de y torch.distributed.launches básicamente el mismo, pero el comando se abandona --use_envy se local_rankestablece directamente en la variable de entorno. La última versión torchvisionusa torchrunel método de inicio, consulte vision/references/classification en main · pytorch/vision para obtener más detalles .
Entrenamiento mixto de precisión (usando ápice)
Instalar Apex :
git clone https://github.com/NVIDIA/apex
cd apex
# if pip >= 23.1 (ref: https://pip.pypa.io/en/stable/news/#v23-1) which supports multiple `--config-settings` with the same key...
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./
# otherwise
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --global-option="--cpp_ext" --global-option="--cuda_ext" ./
Documentación oficial de Apex: Apex (una extensión de PyTorch)
El entrenamiento de precisión mixta (una combinación de entrenamiento de punto flotante (FP32) y semiprecisión (FP16)) nos permite usar tamaños de lote más grandes y aprovechar NVIDIA Tensor Cores para un cálculo más rápido. Las instancias p3 de AWS utilizan GPU NVIDIA Tesla V100 con núcleos Tensor. Es muy sencillo utilizar el ápice de NVIDIA para entrenamientos de precisión mixtos, solo es necesario modificar parte del código:
def train(gpu, args):
############################################################
rank = args.nr * args.gpus + gpu
dist.init_process_group(backend='nccl', init_method='env://', world_size=args.world_size, rank=rank)
############################################################
torch.manual_seed(0)
model = ConvNet()
torch.cuda.set_device(gpu)
model.cuda(gpu)
batch_size = 100
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
############################################################
# Wrap the model
model, optimizer = amp.initialize(model, optimizer, opt_level='O2')
model = DDP(model)
############################################################
# Data loading code
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(),
download=True)
############################################################
# train_sampler = torch.utils.data.distributed.DistributedSampler(dataset=train_dataset, num_replicas=args.world_size,
# rank=rank)
# train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=False,
# num_workers=0, pin_memory=True, sampler=train_sampler)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True,
num_workers=0, pin_memory=True)
############################################################
start = datetime.now()
total_step = len(train_loader)
for epoch in range(args.epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
labels = labels.cuda(non_blocking=True)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
############################################################
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
############################################################
optimizer.step()
if (i + 1) % 100 == 0 and gpu == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch + 1, args.epochs, i + 1, total_step,
loss.item()))
if gpu == 0:
print("Training complete in: " + str(datetime.now() - start))
En realidad hay dos cambios:
- El primero es usar
amp.initializepara empaquetarmodelyoptimizeradmitir el entrenamiento de precisión mixta, queopt_levelse refiere al nivel de optimización.Si es O0 (usar todos los flotantes) o O3 (usar la mitad de precisión en todo), no es una precisión mixta real, pero puede se puede utilizar para determinar el efecto del modelo y La línea de base de la velocidad, y O1 y O2 son dos configuraciones de precisión mixta. Puede elegir una para el entrenamiento de precisión mixta. Los detalles se pueden encontrar en la documentación de Apex . - Otro punto es que antes de actualizar los parámetros según el gradiente, el gradiente debe escalarse a través de amp.scale_loss para evitar el subdesbordamiento del gradiente. Además, puede reemplazar nn.DistributedDataParallel con apex.parallel.DistributedDataParallel.
Sí, el primer carácter en todos estos códigos es una "O" mayúscula y el segundo carácter es un número. Sí, si sustituye cero, obtiene un mensaje de error desconcertante.
apex.parallel.distributedDataParallelSí nn.distributedDataParallearun reemplazo. Ya no es necesario especificar la GPU, ya que Apex solo permite una GPU por proceso. También asume que se llama al script antes de mover el modelo a la GPU torch.cuda.set_device(local_rank).
El entrenamiento de precisión mixta requiere escalar la pérdida para evitar el subdesbordamiento del gradiente. Apex hará esto automáticamente.
Este script funciona de la misma manera que el script de entrenamiento distribuido.
python without_multiprocessing.py -n 1 -g 4 -nr 0
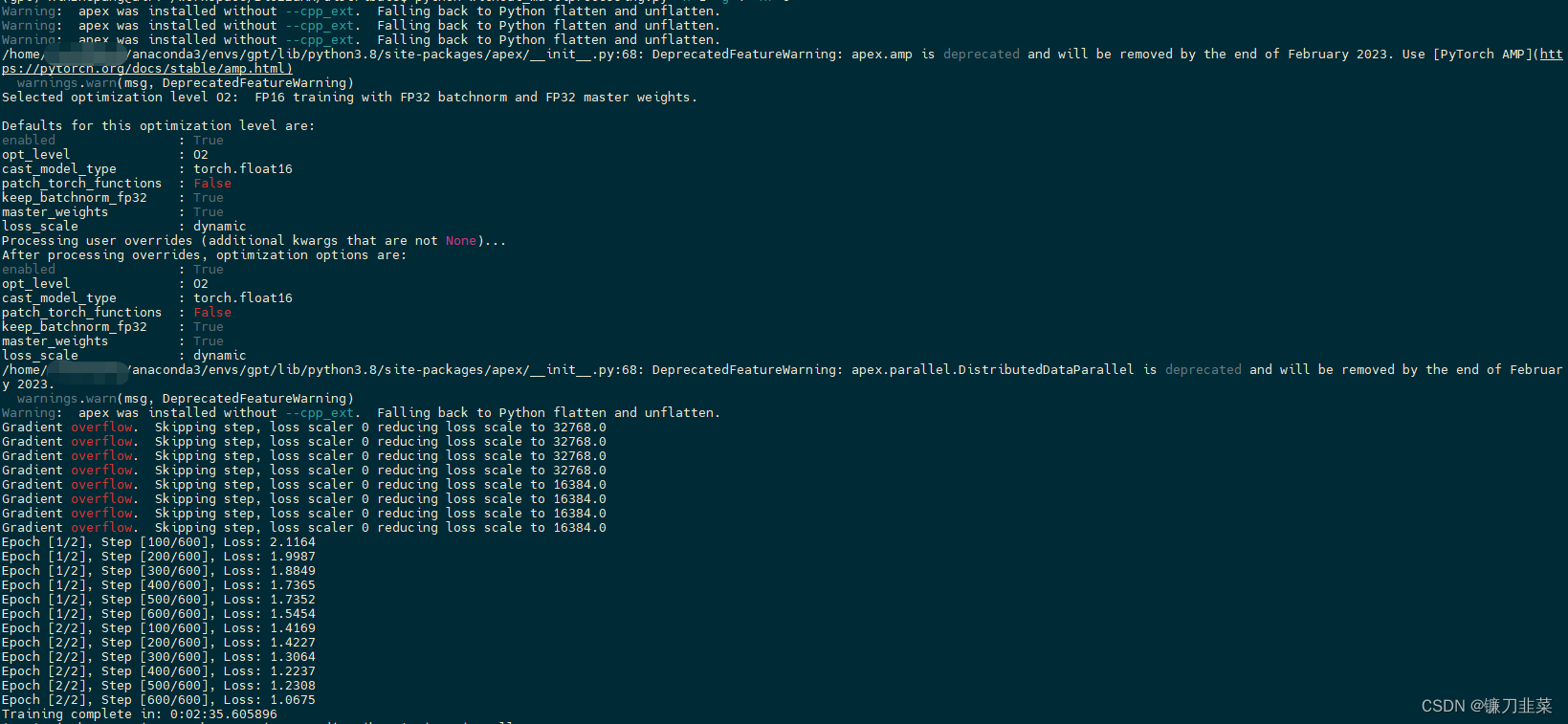
Además, la nueva versión de PyTorch tiene un entrenamiento de precisión mixto incorporado, consulte PAQUETE AUTOMÁTICO DE PRECISIÓN MIXTA - TORCH.AMP Agregue la descripción del enlace para obtener más detalles . Además, la implementación distribuida oficial de PyTorch está relativamente completa ahora, y su rendimiento y efecto son buenos. Una solución alternativa es admitir horovodno solo PyTorch sino también los marcos TensorFlow y MXNet. Es relativamente fácil de implementar y la velocidad también es buena.