YOLOX se ha mejorado sobre la base de YOLOv3 y tiene un rendimiento comparable al de YOLOv5. Su estructura de modelo es la siguiente:
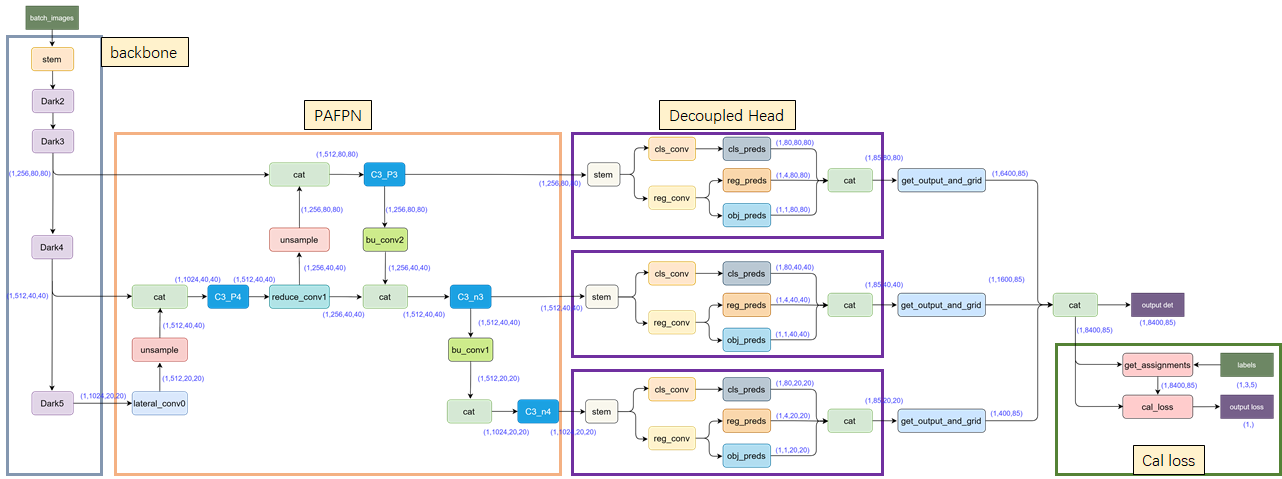
Dado que los blogueros solo quieren usar YOLOX para experimentos comparativos, no necesitan saber demasiado sobre la estructura del modelo.
Los blogueros anteriores han depurado YOLOv5, YOLOv7 y YOLOv8. En comparación, la configuración del entorno de YOLOX es similar, pero la configuración de sus parámetros está demasiado dispersa y es problemático cambiarla. Por ejemplo, los parámetros de época deben colocarse en yolox_base Archivo .py Para heredar en lugar de especificarlo directamente en train.py. Sin más preámbulos, comencemos el proceso de depuración.
Configuración del entorno
El proceso de depuración de YOLOX es básicamente similar al de YOLOv5, la diferencia es que se requiere un proceso de instalación.
es decir, ejecutar:
python setup.py develop
De lo contrario, le indicará que no se puede encontrar el archivo yolox al ejecutar

Después de una operación exitosa, los resultados son los siguientes: vale la pena señalar que es muy difícil para los bloggers tener éxito localmente, pero es muy fácil en el servidor.
Luego está el proceso de configuración del entorno conda, que es básicamente consistente con YOLOv5, y puede usar directamente la configuración del comando:
conda create -n yolox python=3.8
source activate yolox
pip install -r requirements.txt
Configuración del conjunto de datos
El conjunto de datos utilizado por YOLOX es COCO, pero la diferencia es que no se especifican parámetros en su entrenamiento y prueba, sino que se escribe directamente en el archivo de lectura del conjunto de datos, solo necesitamos modificar el directorio según sus requisitos, y el conjunto de datos Simplemente colóquelo en la carpeta conjuntos de datos / COCO. Por supuesto, también puede crear una conexión suave como un blogger:
ln -s /data/datasets/coco/ /home/ubuntu/outputs/yolox/YOLOX-main/datasets/COCO/
Pero este método sigue informando un error:
File "/home/ubuntu/outputs/yolox/YOLOX-main/yolox/data/datasets/datasets_wrapper.py", line 177, in __del__
if self.cache and self.cache_type == "ram":
AttributeError: 'COCODataset' object has no attribute 'cache'
No hay otra manera que copiar el conjunto de datos a este directorio.
Luego ejecuta el error:
assert img is not None, f"file named {
img_file} not found"
AssertionError: file named /home/ubuntu/outputs/yolox/YOLOX-main/datasets/COCO/val2017/000000567197.jpg not found
Después de mirar más de cerca, resulta que hay un problema con la estructura del directorio: no hay un directorio a nivel de imágenes, simplemente elimine este directorio. La estructura de directorio final es:

modelo de entrenamiento
<class 'torch.autograd.variable.Variable'>
RuntimeError: FIND was unable to find an engine to execute this computation
Esto se debe a que el blogger instaló torch 2.0 de forma predeterminada al instalar el entorno, lo que generó un error. Simplemente cambie la versión de la antorcha:
conda install pytorch==1.12.0 torchvision==0.13.0 torchaudio==0.12.0 cudatoolkit=11.6 -c pytorch -c conda-forge
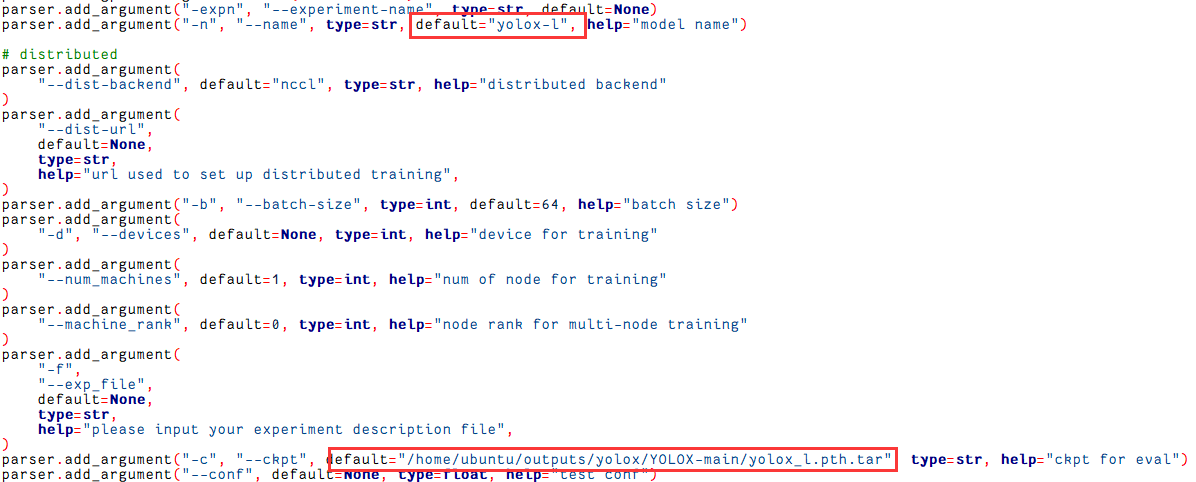
Luego necesitas modificar varios parámetros, el primero es especificar el nombre del modelo, el blogger usa yolox-l
parser.add_argument("-n", "--name", type=str, default="yolox-l", help="model name")
Luego configure el archivo de configuración de yolox-l, –f significa leer del archivo y luego modificar los parámetros en el archivo correspondiente:
parser.add_argument(
"-f",
"--exp_file",
default="/home/ubuntu/outputs/yolox/YOLOX-main/exps/default/yolox_l.py",
type=str,
help="plz input your experiment description file",
)
Modificación /home/ubuntu/outputs/yolox/YOLOX-main/exps/default/yolox_l.py, la configuración de num_class es incorrecta, el blogger está acostumbrado al modelo de clase DETR y con la clase en segundo plano, debería haber solo 3 clases.
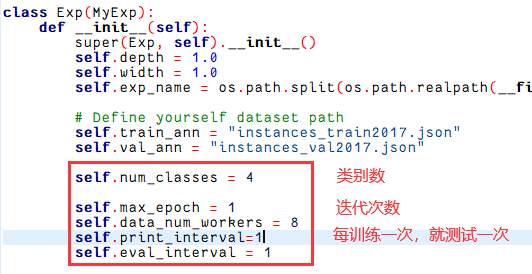
class Exp(MyExp):
def __init__(self):
super(Exp, self).__init__()
self.depth = 1.0
self.width = 1.0
self.exp_name = os.path.split(os.path.realpath(__file__))[1].split(".")[0]
# Define yourself dataset path
self.train_ann = "instances_train2017.json"
self.val_ann = "instances_val2017.json"
self.num_classes = 4
self.max_epoch = 1
self.data_num_workers = 8
self.print_interval=1
self.eval_interval = 1
Luego está el parámetro de tamaño de lote: la memoria de video ocupada por YOLOX aún es relativamente grande y el tamaño de lote se establece en 6.
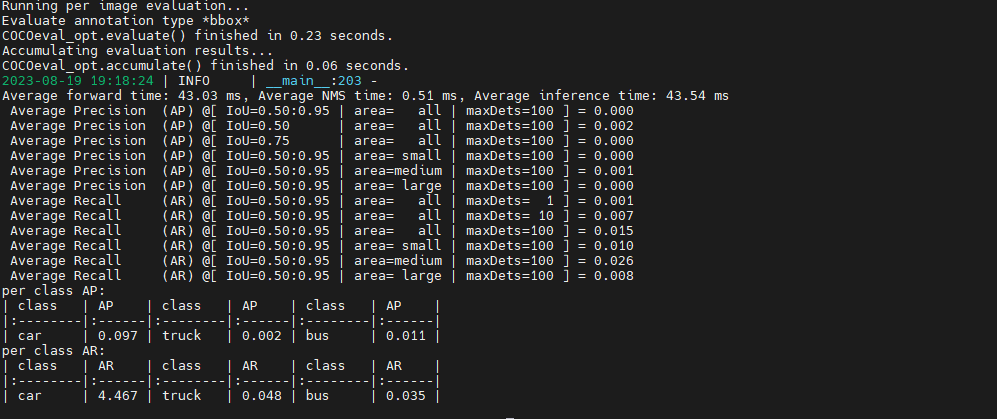
El tiempo de entrenamiento es bastante rápido, unos 45 minutos por época. El resultado del entrenamiento para 1 época, debido a que no se utiliza el modelo previamente entrenado, el valor es muy bajo. Otro problema es que la configuración de num_class es incorrecta. El blogger está acostumbrado al modelo de clase DETR y se agrega la clase de fondo. De hecho, solo debería haber 3 clases.
Ajuste fino del modelo previamente entrenado
Podemos usar el modelo entrenado por YOLOX-L como modelo de preentrenamiento y ajustarlo en el modelo para que pueda converger rápidamente. El num_class = 80 entrenado, podemos mantenerlo como está, es decir, num_class=3, y el modelo manejará automáticamente los problemas con categorías inconsistentes. Después de utilizar el modelo previamente entrenado, la velocidad de iteración se acelera significativamente y la precisión también mejora rápidamente.
parser.add_argument("-c", "--ckpt", default="/home/ubuntu/outputs/yolox/YOLOX-main/yolox_l.pth.tar", type=str, help="checkpoint file")
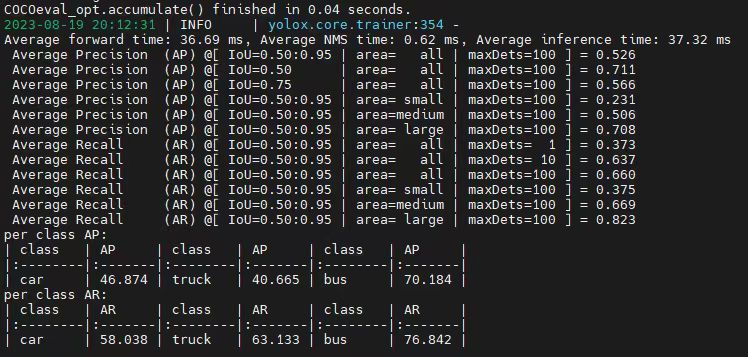
El resultado del entrenamiento para una época después del ajuste fino utilizando el modelo previamente entrenado.
modelo de evaluación
Complete la configuración de parámetros de eval.py:
python -m yolox.tools.eval -n yolox-s -c yolox_s.pth -b 64 -d 8 --conf 0.001 [--fp16] [--fuse]
Por supuesto, también puede utilizar parámetros, principalmente modificar estos dos parámetros.
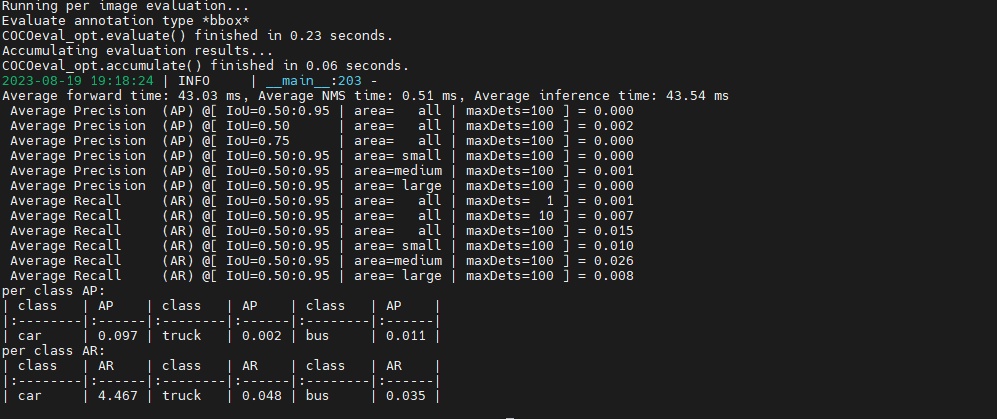
Luego ejecute python eval.pyel comando. Aquí se descubre que el uso del archivo de peso descargado informará un error, por lo que el blogger se entrenó durante 1 época y guardó el resultado del peso. No hay problema al usar esto y el archivo se guarda en YOLOX_outputs. Pero parece que se ha encontrado un problema, es decir, el valor es muy bajo.
razonamiento modelo
Primero descargamos el modelo que ha sido entrenado, el blogger aquí elige YOLOX-L, vale la pena señalar que descargar este archivo requiere pasar por encima de la pared. El archivo de peso descargado es un archivo tar, por lo que es necesario descomprimirlo:
tar -xvf yolox_l.pth.tar
Pero inesperadamente, se informó un error:
tar: esto no parece un archivo tar
tar: saltar al siguiente encabezado
tar: salir con estado de error debido a errores anteriores
Esta es una
solución de ERROR:
gzip -d xxxx.tar.gz (对于.tar.gz文件的处理方式)
tar -xf xxxx.tar (对于.tar文件处理方式)
Todavía no funciona, no hay manera, el blogger solo puede cambiar el nombre del sufijo a zip y luego usar descomprimir para descomprimir el archivo. Pero después de la descompresión, es una carpeta, que es diferente del archivo pth que el blogger vio antes. Efectivamente, se informa un error al ejecutar:
súper(). init (open(nombre, modo)) IsADirectoryError: [Errno 21] Es un
directorio: '/home/ubuntu/outputs/yolox/YOLOX-main/yolox_l.pth'
Resulta que no es necesario descomprimir el archivo de peso de YOLOX, se puede usar directamente, es decir, al especificar el archivo:
parser.add_argument("-c", "--ckpt", default="/home/ubuntu/outputs/yolox/YOLOX-main/yolox_l.pth.tar", type=str, help="ckpt for eval")
, especificando tamaño = 224, sus parámetros y cálculos se proporcionan en Demo.py,

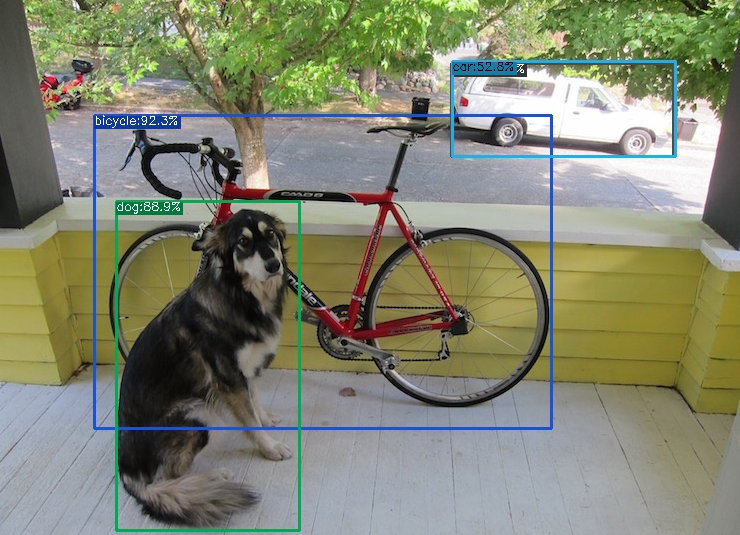
Los resultados del razonamiento son los siguientes: