Recientemente, estoy estudiando el entrenamiento distribuido y el almacenamiento de modelos grandes. Mi propia base relacionada con la distribución es relativamente débil. Todas las arquitecturas basadas en el aprendizaje profundo provienen de la tradición. Resumí la solución distribuida anterior para big data, es decir, Hadoop:
¿Por qué Hadoop?
La función de Hadoop es muy simple: crear un entorno informático y de almacenamiento unificado y estable en un entorno de clúster de múltiples computadoras y proporcionar soporte de plataforma para otros servicios de aplicaciones distribuidas.
Hasta cierto punto, Hadoop organiza varias computadoras en una sola (haciendo lo mismo), luego HDFS es equivalente al disco duro de esta computadora y MapReduce es el controlador de CPU de esta computadora .
Problema
Dado que Hadoop es un software diseñado para clústeres, al aprender a usarlo , inevitablemente nos encontraremos con la situación de configurar Hadoop en varias computadoras , lo que creará muchos obstáculos para los estudiantes, principalmente dos:
- Grupos de ordenadores caros. Un entorno de clúster compuesto por varias computadoras requiere hardware costoso.
- Difícil de implementar y mantener. Implementar el mismo entorno de software en muchas computadoras requiere mucho trabajo y es muy inflexible y difícil de volver a implementar después de que cambia el entorno.
Para resolver estos problemas, tenemos un método Docker muy maduro .
Docker es un sistema de administración de contenedores que puede ejecutar múltiples "máquinas virtuales" (contenedores) como máquinas virtuales y formar un clúster. Debido a que la máquina virtual virtualiza completamente una computadora, consume muchos recursos de hardware y es ineficiente. Docker solo proporciona un entorno operativo independiente y reproducible. De hecho, todos los procesos en el contenedor aún se ejecutan en el kernel del .host
Diseño general de Hadoop
El marco Hadoop es un marco para el procesamiento de big data de grupos de computadoras, por lo que debe ser un software que se pueda implementar en varias computadoras. Los hosts en los que se implementa el software Hadoop se comunican a través de sockets (red).
Hadoop incluye principalmente dos componentes: HDFS y MapReduce: HDFS es responsable de distribuir y almacenar datos, y MapReduce es responsable de mapear y procesar datos, y resumir los resultados del procesamiento.
El principio más fundamental del marco Hadoop es utilizar una gran cantidad de computadoras para operar simultáneamente para acelerar el procesamiento de grandes cantidades de datos . Por ejemplo, si una empresa de motores de búsqueda quiere filtrar y resumir palabras candentes de billones de datos que no han sido estandarizados, necesita organizar una gran cantidad de computadoras para formar un grupo para procesar la información. Si se utiliza una base de datos tradicional para procesar esta información, se necesitará mucho tiempo y un gran espacio de procesamiento para procesar los datos. Esta magnitud se vuelve difícil para cualquier computadora. La principal dificultad radica en organizar una gran cantidad de hardware y alta Acelerar la integración en una computadora, incluso si se implementa con éxito, se producirán costosos costos de mantenimiento.
Hadoop puede ejecutarse en unos pocos miles de computadoras económicas producidas en masa y organizadas como un grupo de computadoras.
Un clúster de Hadoop puede almacenar datos de manera eficiente y distribuir tareas de procesamiento, lo que tendrá muchos beneficios. En primer lugar, puede reducir el costo de construcción y mantenimiento de la computadora y, en segundo lugar, una vez que cualquier computadora tiene una falla de hardware, no tendrá un impacto fatal en todo el sistema informático, porque el marco del clúster para el desarrollo de la capa de aplicación debe asumir que la computadora fallar .
HDFS
Sistema de archivos distribuido Hadoop, sistema de archivos distribuido Hadoop, HDFS para abreviar.
HDFS se utiliza para almacenar archivos en el clúster y la idea central que utiliza es la idea GFS de Google, que puede almacenar archivos grandes.
En los clústeres de servidores, a menudo se requiere que el almacenamiento de archivos sea eficiente y estable, y HDFS logra estas dos ventajas al mismo tiempo.
El almacenamiento eficiente de HDFS se logra mediante grupos de computadoras que procesan solicitudes de forma independiente. Debido a que el usuario (la mitad del cual es el programa back-end) envía una solicitud de almacenamiento de datos, a menudo responde que el servidor está procesando otras solicitudes, lo cual es la razón principal de la lenta eficiencia del servicio. Pero si el servidor de respuesta asigna directamente un servidor de datos al usuario y luego el usuario interactúa directamente con el servidor de datos, la eficiencia será mucho más rápida.
La estabilidad del almacenamiento de datos a menudo se logra mediante "varias copias más", que también utiliza HDFS. La unidad de almacenamiento de HDFS es el bloque (Bloque), y un archivo puede dividirse en varios bloques y almacenarse en la memoria física. Por lo tanto, HDFS a menudo copia n copias de bloques de datos de acuerdo con los requisitos del configurador y los almacena en diferentes nodos de datos (servidores que almacenan datos). Si un nodo de datos falla, los datos no se perderán.
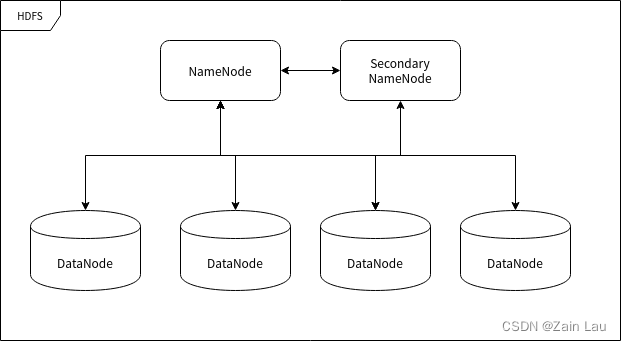
Nodos HDFS
HDFS se ejecuta en muchas computadoras diferentes, algunas dedicadas a almacenar datos y otras dedicadas a dirigir a otras computadoras para que almacenen datos. La "computadora" mencionada aquí puede denominarse nodo en el clúster.
Nodo de nombres (NameNode)
NameNode (NameNode) es un nodo que se utiliza para dirigir el almacenamiento de otros nodos. Cualquier "sistema de archivos" (sistema de archivos, FS) debe tener la función de mapear archivos de acuerdo con la ruta del archivo. El nodo nombrado es una computadora que se utiliza para almacenar esta información de mapeo y proporcionar servicios de mapeo, actuando como un "administrador" en toda la función del sistema HDFS, por lo que solo hay un nodo con nombre en un clúster HDFS.
Nodo de datos (Nodo de datos)
DataNode Un nodo utilizado para almacenar bloques de datos . Cuando el nodo nombrado reconoce un archivo y lo divide en bloques, se almacenará en el nodo de datos asignado. Los nodos de datos tienen la función de almacenar datos y leer y escribir datos. Los bloques de datos almacenados son similares al concepto de "sector" en el disco duro, que es la unidad básica de almacenamiento HDFS .
Nodo de nombre secundario
El NameNode secundario (NameNode secundario), alias "NameNode secundario", es el " secretario " del NameNode. Esta descripción es muy apropiada porque no reemplaza el trabajo del nodo nombrado, independientemente de la capacidad del nodo nombrado para continuar trabajando. Es el principal responsable de descargar el namenode, hacer una copia de seguridad del estado del namenode y realizar algún trabajo administrativo si el namenode así lo solicita. También puede proporcionar datos de respaldo para restaurar el NameNode si el NameNode deja de funcionar. Puede haber varios nodos con subnombres.
Mapa reducido
El significado de MapReduce es tan obvio como su nombre: Map and Reduce (mapeo y reducción).
procesamiento de grandes datos
El procesamiento de grandes cantidades de datos es un asunto típico "simple en su razonamiento, complejo en su implementación". El motivo de la "implementación complicada" es principalmente que los recursos de hardware (principalmente memoria) serán insuficientes cuando se procese una gran cantidad de datos mediante métodos tradicionales.
Ahora que hay un fragmento de texto (esta cadena puede tener hasta 1 PB o más en un entorno real), realizamos una estadística simple de "caracteres numéricos", es decir, contamos el número de todos los caracteres que han aparecido en este texto. :
AABABCCABCDABCDE
El resultado después de las estadísticas debería ser:
A 5
B 4
C 3
D 2
E 1
El proceso de las estadísticas es realmente muy simple, es decir, cada vez que se lee un carácter, es necesario verificar si el mismo carácter ya existe en la tabla. De lo contrario, agregue un registro y establezca el valor del registro en 1, y aumente directamente el valor del registro en 1 si lo hay.
Pero si cambiamos el objeto estadístico aquí de "caracteres" a "palabras", entonces el tamaño de la muestra se volverá muy grande en un instante, por lo que puede resultar difícil para una computadora contar las "palabras" utilizadas por miles de millones de usuarios en un año.
En este caso, todavía tenemos una manera de completar este trabajo: primero dividimos la muestra en secciones que pueden ser procesadas por una sola computadora, y luego realizamos estadísticas sección por sección, y establecemos los resultados estadísticos del mapeo cada vez que se realizan las estadísticas . El procesamiento consiste en combinar resultados estadísticos en un resultado de datos más grande y, finalmente, completar la reducción de datos a gran escala.
En el caso anterior, la primera etapa para finalizar el trabajo es "mapear", clasificar y ordenar los datos; hasta ahora, podemos obtener un resultado que es mucho más pequeño que los datos de origen. La segunda etapa del trabajo generalmente la realiza el clúster. Después de ordenar los datos, debemos resumirlos en su conjunto. Después de todo, puede haber clasificaciones superpuestas de los resultados del mapeo de múltiples nodos. Los resultados del mapeo en este proceso se reducirán aún más a resultados estadísticos obtenibles.
Conceptos de MapReduce
Ejemplo:
Supongamos que hay 5 archivos, cada uno con dos columnas que registran el nombre de una ciudad y la temperatura correspondiente registrada en esa ciudad en diferentes fechas de medición. El nombre de la ciudad es la clave (Key) y la temperatura es el valor (Value). Por ejemplo: (Xiamén, 20). Ahora queremos encontrar la temperatura máxima para cada ciudad en todos los datos (tenga en cuenta que puede aparecer la misma ciudad en cada archivo).
Usando el marco MapReduce, podemos dividir esto en 5 tareas de mapa, donde cada tarea es responsable de procesar uno de los cinco archivos. Cada tarea de mapa examina cada dato del archivo y devuelve la temperatura máxima para cada ciudad del archivo.
Por ejemplo, para los siguientes datos:
| Ciudad | temperatura |
|---|---|
| Xiamén | 12 |
| Llevar a la fuerza | 34 |
| Xiamén | 20 |
| Llevar a la fuerza | 15 |
| Beijing | 14 |
| Beijing | dieciséis |
| Xiamén | 24 |
Por ejemplo, puede considerar MapReduce como un censo , y la Oficina del Censo enviará varios investigadores a cada ciudad. Cada censista de cada ciudad contará una parte de la población de esa ciudad y los resultados se agregarán a la capital. En la capital, las estadísticas de cada ciudad se reducirán a un solo recuento (la población de cada ciudad), y luego se podrá determinar la población total del país. Este mapeo de persona a ciudad se paraleliza y los resultados se combinan (Reducir). Esto es mucho más eficiente que enviar a una persona a contar a todos los habitantes del país de forma continua.
Tres modos de Hadoop: modo independiente, modo pseudo-clúster y modo clúster
- Modo independiente: Hadoop solo existe como una biblioteca, que puede ejecutar tareas de MapReduce en una sola computadora y solo se utiliza para que los desarrolladores creen un entorno de aprendizaje y experimentación.
- Modo pseudo-clúster: en este modo, Hadoop se ejecutará en una sola máquina en forma de proceso demonio, que generalmente se utiliza para que los desarrolladores creen un entorno de aprendizaje y experimentación.
- Modo de clúster: este modo es el modo de entorno de producción de Hadoop, es decir, este es el modo que Hadoop realmente utiliza para proporcionar servicios a nivel de producción.
Configuración e inicio de HDFS
HDFS es similar a una base de datos y se inicia como un proceso demonio . Para utilizar HDFS, debe utilizar el cliente HDFS para conectarse al servidor HDFS a través de la red (socket) para realizar el uso del sistema de archivos.
Configure el entorno básico de Hadoop, el nombre del contenedor es hadoop_single , inicie e ingrese al contenedor.
Una vez dentro del contenedor, verifique que Hadoop exista:
hadoop version
Hadoop existe si el resultado muestra el número de versión de Hadoop.
A continuación pasaremos a los pasos formales.
Crear un nuevo usuario de hadoop
Cree un nuevo usuario llamado hadoop:
adduser hadoop
Instale una pequeña herramienta para modificar contraseñas de usuarios y gestión de derechos:
yum install -y passwd sudo
Establecer contraseña de usuario de hadoop:
passwd hadoop
Ingrese la contraseña las próximas dos veces, ¡asegúrese de recordarla!
Modifique el propietario del directorio de instalación de hadoop para que sea el usuario de hadoop:
chown -R hadoop /usr/local/hadoop
Luego modifique el archivo /etc/sudoers con un editor de texto, en
root ALL=(ALL) ALL
añadir una línea después
hadoop ALL=(ALL) ALL
Luego salga del contenedor.
Cierre y envíe el contenedor hadoop_single para reflejar hadoop_proto:
docker stop hadoop_single
docker commit hadoop_single hadoop_proto
Cree un nuevo contenedor hdfs_single:
docker run -d --name=hdfs_single --privileged hadoop_proto /usr/sbin/init
De esta manera se crea el nuevo usuario.
Iniciar HDFS
Ahora ingrese al contenedor recién creado:
docker exec -it hdfs_single su hadoop
Ahora debería ser el usuario de hadoop:
whoami
Debería mostrar "hadoop"
Generar claves SSH:
ssh-keygen -t rsa
Aquí puedes seguir presionando Enter hasta que finalice la generación.
Luego agregue la clave generada a la lista de confianza:
ssh-copy-id hadoop@172.17.0.2
Ver la dirección IP del contenedor:
ip addr | grep 172
Entonces sabes que la dirección IP del contenedor es 172.17.0.2, tu IP puede ser diferente a esta.
Antes de iniciar HDFS, realizamos algunas configuraciones simples: todos los archivos de configuración de Hadoop se almacenan en el subdirectorio etc/hadoop en el directorio de instalación, por lo que podemos ingresar a este directorio:
cd $HADOOP_HOME/etc/hadoop
Aquí modificamos dos archivos: core-site.xml y hdfs-site.xml
En core-site.xml, agregamos el atributo debajo de la etiqueta:
<property>
<name>fs.defaultFS</name>
<value>hdfs://<你的IP>:9000</value>
</property>
Agregue la propiedad debajo de la etiqueta en hdfs-site.xml:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
Formatear la estructura del archivo:
hdfs namenode -format
Luego inicie HDFS:
start-dfs.sh
El inicio se divide en tres pasos, iniciando NameNode, DataNode y Secondary NameNode respectivamente.
Ejecute jps para ver el proceso de Java
Hasta ahora, se ha establecido el proceso del demonio HDFS. Dado que HDFS tiene un panel HTTP, podemos visitar http://su contenedor IP:9870/ a través de un navegador para ver el panel HDFS e información detallada.
Usos de HDFS
Carcasa HDFS
Volviendo al contenedor hdfs_single, se utilizarán los siguientes comandos para operar HDFS:
# 显示根目录 / 下的文件和子目录,绝对路径
hadoop fs -ls /
# 新建文件夹,绝对路径
hadoop fs -mkdir /hello
# 上传文件
hadoop fs -put hello.txt /hello/
# 下载文件
hadoop fs -get /hello/hello.txt
# 输出文件内容
hadoop fs -cat /hello/hello.txt
Los comandos más básicos de HDFS se describen arriba y hay muchas otras operaciones admitidas por los sistemas de archivos tradicionales.
API HDFS
HDFS ha sido compatible con muchas plataformas back-end y actualmente la distribución oficial incluye interfaces de programación C/C++ y Java. Además, los administradores de paquetes de los lenguajes Node.js y Python también admiten la importación de clientes HDFS.
Aquí hay una lista de dependencias para el administrador de paquetes:
Experto:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
Gradle:
providedCompile group: 'org.apache.hadoop', name: 'hadoop-hdfs-client', version: '3.1.4'
MNP:
npm i webhdfs
pepita:
pip install hdfs
Ejemplo de conexión de Java a HDFS (modificar dirección IP):
实例
package com.zain;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
public class Application {
public static void main(String[] args) {
try {
// 配置连接地址
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://172.17.0.2:9000");
FileSystem fs = FileSystem.get(conf);
// 打开文件并读取输出
Path hello = new Path("/hello/hello.txt");
FSDataInputStream ins = fs.open(hello);
int ch = ins.read();
while (ch != -1) {
System.out.print((char)ch);
ch = ins.read();
}
System.out.println();
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
}