Hay mucha investigación sobre métodos de impulso y se han propuesto muchos algoritmos. El más representativo es el algoritmo AdaBoost (algoritmo AdaBoost).
El método de mejora es comenzar con el algoritmo de aprendizaje débil y aprender repetidamente para obtener una serie de clasificadores débiles (también llamados clasificadores básicos), y luego combinar estos clasificadores débiles para formar un clasificador fuerte.
Para el método de impulso, hay dos preguntas que responder: una es cómo cambiar el peso o la distribución de probabilidad de los datos de entrenamiento en cada ronda; la otra es cómo combinar clasificadores débiles en un clasificador fuerte. Con respecto a la primera pregunta, el enfoque de AdaBoost es aumentar los pesos de aquellas muestras que fueron clasificadas incorrectamente por la ronda anterior de clasificadores débiles y reducir los pesos de aquellas muestras que fueron clasificadas correctamente. De esta forma, aquellos datos que no hayan sido clasificados correctamente recibirán más atención por parte del clasificador débil en la siguiente ronda debido al aumento de su peso. Así, el problema de clasificación es "divide y vencerás" por una serie de clasificadores débiles. En cuanto a la segunda cuestión, es decir, la combinación de clasificadores débiles, AdaBoost adopta el método de votación por mayoría ponderada. Específicamente, aumente el peso de un clasificador débil con una tasa de error de clasificación pequeña para que desempeñe un papel más importante en la votación, y reduzca el peso de un clasificador débil con una tasa de error de clasificación grande para que desempeñe un papel más pequeño en la votación. .

Explicación del algoritmo:
Hay N datos de entrada, y cada dato corresponde a un parámetro de peso wi, luego hay N datos de entrenamiento y N parámetros de peso i∈1-n. El conjunto se denota como D. m se refiere a la iteración de la m-ésima ronda, m ∈ 1-M. G significa clasificador.
En (1), primero configure todos los parámetros de valor w para que sean iguales. El valor es 1/N. El conjunto es D1.
AdaBoost aprende repetidamente el clasificador básico y realiza los siguientes 2-4 pasos secuencialmente en cada ronda de m=1,2,...,M.
En el paso (2), aprenda con el conjunto de datos de entrenamiento de la distribución de peso Dm de cada ronda para obtener el clasificador básico, y el clasificador Gm(Xi) clasifica los datos de entrenamiento Xi.
Según el resultado G(xi) = {+1, -1} y el resultado real yi clasificado por el clasificador de la m-ésima ronda Gm.
Generalmente, la función de pérdida que solemos obtener es,  pero aquí debido a que se pondera cada Xi, el error real debe registrarse como
pero aquí debido a que se pondera cada Xi, el error real debe registrarse como
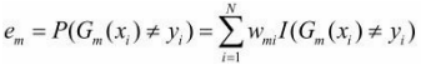
En el paso (3), con el error, podemos calcular qué peso le debe dar el clasificador actual.
Calcular su coeficiente como:

El logaritmo aquí es el logaritmo natural.
Esto da como resultado un modelo de la rueda,

Paso (4), con el coeficiente am del modelo, podemos recorrer y calcular el coeficiente de peso W(m+1,i) de cada dato de entrada Xi en la siguiente ronda m+1.


Obtenga el conjunto de ponderaciones de datos para la siguiente ronda:
![]()
De esta forma, puede saltar al paso (2) para el próximo ciclo hasta que M se redondee.
Paso (5):
Finalmente, cada clasificador débil obtenido en estas M rondas se multiplica por el peso am y se combina linealmente para obtener el modelo clasificador integrado final:
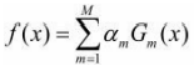
Entonces el clasificador final es:

caso:
Ejemplo 8.1 Dados los datos de entrenamiento que se muestran en la Tabla 8.1. Suponiendo que el clasificador débil es generado por x<v o x>v, su umbral v hace que el clasificador tenga la tasa de error de clasificación más baja en el conjunto de datos de entrenamiento. Use el algoritmo AdaBoost para aprender un clasificador fuerte.

desatar:
(1) Inicializar distribución de peso
W1 = 1/10 = 0,1

(2) En la primera vuelta, para m=1
1. En los datos de entrenamiento cuya distribución de peso es D1, la tasa de error de clasificación es la más baja cuando el umbral v es 2.5, por lo que el clasificador básico es:
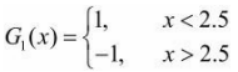
La tasa de error de G1(x) en el conjunto de datos de entrenamiento
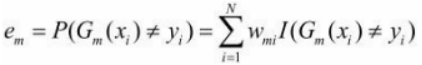
![]()
2. Calcular el coeficiente de G1(x):

3. Actualiza la distribución del peso de los datos de entrenamiento Xi:

El signo clasificador [f 1(x)] tiene 3 puntos mal clasificados en el conjunto de datos de entrenamiento.
(3) Para la segunda vuelta m=2:
1. En los datos de entrenamiento con una distribución de peso de D2, la tasa de error de clasificación es la más baja cuando el umbral v es 8.5, y el clasificador básico es

2. La tasa de error e2 de G2(x) en el conjunto de datos de entrenamiento es 0,2143.
3. Calcular a2=0,6496.
4. Actualice la distribución del peso de los datos de entrenamiento:

El signo clasificador [f 2(x)] tiene 3 puntos mal clasificados en el conjunto de datos de entrenamiento.
(4) Para la tercera vuelta m=3:
1. En los datos de entrenamiento con una distribución de peso de D3, la tasa de error de clasificación es la más baja cuando el umbral v es 5.5, y el clasificador básico es

2. La tasa de error e3 de G3(x) en el conjunto de muestra de entrenamiento es 0.1820.
3. Calcular a3=0.7514.
4. Actualiza la distribución del peso de los datos de entrenamiento:
![]()
A fin de obtener:
![]()
El número de puntos mal clasificados del signo clasificador [f 3(x)] en el conjunto de datos de entrenamiento es 0.
(5) Entonces el clasificador final es:
![]()