Sugerencia: este artículo es una reproducción de Meteor 007. ¿Sabe qué hace que las listas enlazadas ordinarias alcancen la eficiencia de la búsqueda binaria?
Si hay alguna infracción, póngase en contacto para eliminar
Búsqueda binaria de lista doblemente enlazada
prefacio
如有侵权 请联系删除 Si hay alguna infracción, comuníquese para eliminarla. Si hay alguna infracción, comuníquese para eliminarla.
Declaración de derechos de autor: este artículo es un artículo original del blogger CSDN "Meteor 007", que sigue el acuerdo de derechos de autor CC 4.0 BY-SA. Para reimprimir, adjunte el enlace de la fuente original y esta declaración.
Enlace original: https://blog.csdn.net/qq_33220089/article/details/114641975
1. Arrays y listas enlazadas
1. matriz
En informática, una estructura de datos de matriz (inglés: estructura de datos de matriz), denominada matriz (inglés: Array), es una estructura de datos compuesta por una colección de elementos del mismo tipo y asigna una memoria continua para el almacenamiento. La dirección de almacenamiento correspondiente al elemento se puede calcular utilizando el índice del elemento.
Ventajas
a. El acceso aleatorio es más rápido (basado en el acceso de subíndices).
b. Simple de implementar y fácil de usar.
c, La dirección de la memoria es continua, lo que es muy compatible con la memoria caché de la CPU. Por ejemplo, el disruptor de colas de alto rendimiento también utiliza la continuidad de la memoria caché de la CPU + la dirección de la matriz para optimizar en gran medida el rendimiento.
Desventajas
a. La contigüidad de la memoria puede ser una ventaja o una desventaja.Si la memoria es escasa, la matriz se verá muy limitada.
b.Al insertar y borrar, provocará el movimiento de elementos (copia de datos), que es más lento.
C. El tamaño de la matriz es fijo, lo que limita en gran medida la cantidad de elementos y no es compatible con muchos datos dinámicos.
2. Lista enlazada
La lista enlazada (Linked list) es una estructura de datos básica común. Es una lista lineal, pero no almacena datos en un orden lineal, sino que almacena un puntero (Pointer) al siguiente nodo en cada nodo. Dado que no tiene que almacenarse en orden, la lista enlazada puede alcanzar la complejidad de O(1) al insertar, que es mucho más rápido que otra tabla de secuencia de lista lineal, pero se necesita O(n) para encontrar un nodo o acceder un tiempo de nodo numerado específico.
Ventajas
A. La estructura de lista enlazada puede hacer un uso completo del espacio de memoria de la computadora y realizar una administración de memoria dinámica flexible.
b. Eliminar inserción sin mover otros elementos.
C. No está limitado por el tamaño del elemento y se puede expandir a voluntad.
Desventaja
A. Se pierden las ventajas de la lectura aleatoria de matrices y, al mismo tiempo, la lista enlazada tiene una sobrecarga de espacio relativamente grande debido al aumento del campo de puntero del nodo.
b.La eficiencia del acceso aleatorio es menor que la de las matrices.
3. Análisis de la complejidad del tiempo
Comprender la complejidad del tiempo y la complejidad del espacio
Acceso aleatorio
a. Matriz: O(1)
b. La lista enlazada no admite
inserción aleatoria de acceso aleatorio, eliminar
a. Matriz: matriz ordenada -> O(n) necesita mantener el índice, matriz desordenada -> O(1)
B. Lista enlazada: O(1)
2. Mesa de salto
1. ¿Qué es una tabla de salto?
El concepto de lista enlazada se mencionó anteriormente. La complejidad del tiempo de consulta de la lista enlazada es: O(n). Incluso si se trata de una lista enlazada ordenada, tiene que recorrer y buscar desde el primer elemento de la lista enlazada. La complejidad temporal es alto Si dejas que vengas a optimizar, ¿tienes alguna solución? En este momento, aparece la tabla de saltos.
Jump list, nombre completo: jump list, en informática, jump list es una estructura de datos. Hace que la complejidad temporal media de las operaciones de búsqueda e inserción de una secuencia ordenada que contiene n elementos sea:logn
Para aquellos que han olvidado el registro, pueden leer esto para recordar [ ¿ Qué es el registro logarítmico? 】
Dibujemos una estructura de lista enlazada ordinaria:

esta es una estructura de lista enlazada simple ordinaria, si queremos encontrar el nodo 58, tenemos que consultar 1 -> 4 -> 7 -> 15 -> 20 -> 35 -> 50 -> 58, un total de 8 veces para encontrar los resultados que necesitamos, complejidad de tiempo: O(n), la eficiencia se puede imaginar, entonces intentemos optimizarla juntos.
La eficiencia de las consultas de Mysql se reducirá drásticamente cuando la cantidad de datos sea grande. ¿Cómo optimizan la eficiencia? Ese es el índice, aquí también podemos usar algo como un "índice" para optimizar esta lista ordinaria de enlaces simples.

Copiamos los nodos después de cada dos nodos en la lista enlazada original para hacer un índice para facilitar la búsqueda de datos
Todavía seguimos buscando el 58, solo necesitamos pasar por: 1 -> 7 -> 20 -> 50 -> 58, ¿lo has encontrado? Encontramos el nodo que buscamos después de solo buscar 5 veces. ¿Es eficiente? ¿Mejorado un poco?
Permítanme explicar esta imagen ahora. Ya que hemos establecido una capa de índice, al consultar, primero buscamos la primera capa de la capa de índice. Al buscar la capa de índice, encontramos que 50 y los nodos anteriores son todos menores que 58. Al atravesar a 50, su próximo nodo 66 es más grande que el nodo que se va a consultar, por lo que en este momento, se encontrará el nodo inferior en el nodo 50 (el nodo de la lista enlazada original es el puntero de 50), y luego atravesará hacia abajo uno encontrará 58.
La adición de "índice" solo guarda tres consultas y la optimización no es obvia. ¿Es necesaria esta optimización? Hemos establecido una capa de "índice" aquí, ¿cuántas capas más de "índice" debemos construir? ¿Cómo será?
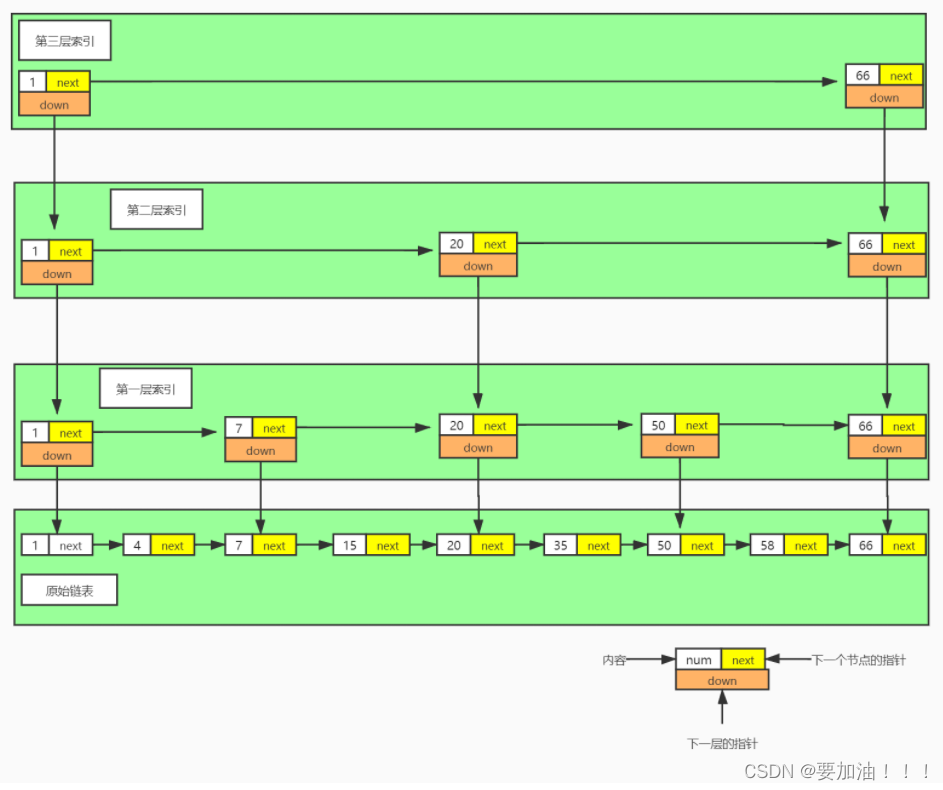
En este momento, descubrimos que solo se necesitan 4 veces para encontrar el nodo 58 que necesitamos encontrar. 4 veces es la mitad de rápido que 8 veces. No tengo demasiados datos aquí. Cuando hay suficientes datos, el efecto será más evidente.
Llamamos a esta estructura de datos compuesta de índices capa por capa: 跳表ahora creo que debería tener una comprensión más profunda de lo que es una tabla de salto, y
es posible que tenga otra pregunta en este momento. Para construir la capa de índice, definitivamente consumiremos mucho espacio. Esta es una forma de intercambiar espacio por tiempo , pero cuando la cantidad de datos es grande, ¿habrá espacio suficiente?
Analicemos ahora la complejidad de tiempo/espacio de las tablas de salto.
2. Omitir análisis de tablas
Suponiendo que el número de nodos en la lista enlazada original es: n, sabemos que extraemos un nodo cada dos nodos como un nodo en la capa de índice, entonces el número de nodos en la primera capa de índice debería ser el nodo de la lista enlazada original 1/2 del número, es decir, n/2, el número de nodos en el índice de segundo nivel es 1/2 del número de nodos en el índice de primer nivel, que es 1/4 del número de nodos en la lista enlazada original, es decir, n/4, el número de nodos en el índice de la tercera capa es 1/2 del número de nodos en el índice de la segunda capa, 4/1 del número de nodos en el índice de la primera capa, y 1/8 del número de nodos en la lista enlazada original, y así sucesivamente, el número de nodos indexados en la capa k es 1/2 del índice en la capa k-1, luego el número de nodos indexados en la capa k :


¿Por qué falta la base 2 en los logaritmos? De hecho, en el análisis de la complejidad del tiempo, el análisis es solo una tendencia, no un valor fijo. El nivel de número relativo, el número base puede ignorarse. La introducción relacionada específica no se presentará aquí. Si está interesado, puede Baidu, y no es complicado Lo que tenemos que averiguar ahora es ¿cuánto es esta x?
En el diagrama de estructura de la tabla de salto dibujado arriba, extraemos un nodo de índice cada dos nodos, por lo que cuando necesitamos consultar un determinado nodo en la tabla de salto, debemos atravesar de arriba a abajo en la capa de índice, cada capa no excederá 3 como máximo, ¿por qué 3 en lugar de 4, 5, 6? Dibujemos un diagrama simple para ilustrar.
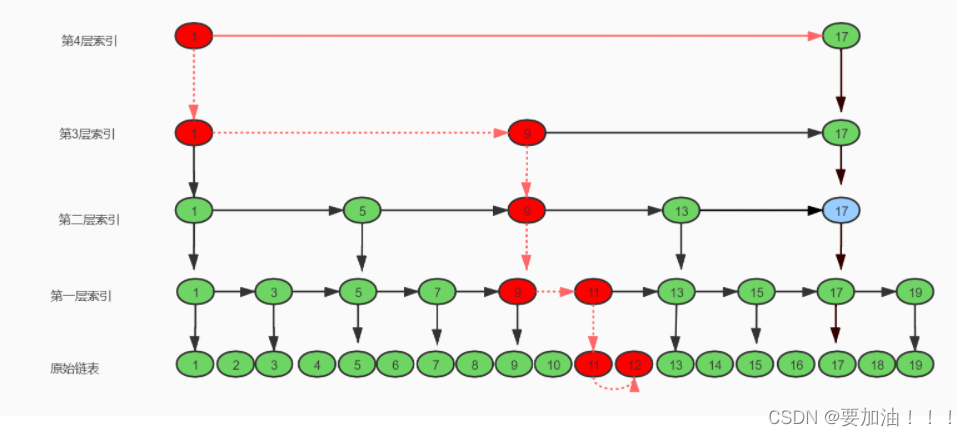
Necesitamos encontrar el nodo 12. Cuando llegamos al nodo 9, encontramos que 12 > 9 && 12 > 11. En este momento, juzgará el siguiente nodo 11 de 9, y 11 < 12 && 12<13, entonces baja un índice de nivel, alcanza el índice de la primera capa, y solo hay tres nodos entre 9 y 13, incluso si desciende a la lista enlazada original, solo hay tres nodos como máximo antes de los dos nodos de rango, por lo que cada capa necesita ser atravesado El número máximo de nodos se obtiene de esta manera, porque x es una constante 3, que se puede omitir directamente, por lo que la complejidad de tiempo final de la tabla de salto es:log(n)
3. La tabla de saltos ocupa memoria
Aunque la eficiencia de la consulta se ha mejorado mucho, también hay un problema muy importante, es decir, la tabla de salto ocupará espacio de memoria adicional, porque requiere muchas capas de índices, por lo que no vale la pena recomendar esta estructura de datos. Ahora que redis está oficialmente en uso, ¿a qué le tienes miedo?
Analicemos nuevamente la complejidad espacial de la tabla de salto para ver si consume mucha memoria.
Suponiendo que la longitud de la lista enlazada original es n, entonces la longitud del índice de la primera capa es n/2, la longitud del índice de la segunda capa es: n/4, la longitud del índice de la tercera capa: n/8, y la longitud del índice de la última capa (capa más alta): 2, es obvio que se trata de una secuencia geométrica :

el tamaño total ocupado por la capa de índice es: n - 2, más la lista enlazada original n = 2n -2, por lo que la complejidad espacial de la lista de omisión es: , la O(n)constante se puede omitir, que es que cada dos La complejidad espacial de extraer un nodo índice de un nodo, ¿cuántos nodos más para extraer un nodo índice? Por ejemplo, se extrae uno cada 3 y uno cada 5. El método de cálculo es el mismo que el anterior y la complejidad del espacio resultante también es: , O(n)pero el espacio se reduce mucho.
Ahora que hemos terminado la consulta, ¿qué pasa con los efectos de inserción y eliminación de la tabla de salto? ¿También funcionará bien? Echemos un vistazo juntos.
Dado que nuestra lista enlazada está ordenada, tenemos que encontrar la posición de inserción primero al insertar. La complejidad del tiempo de consulta de la tabla de salto es, después de O(logn)encontrar la posición que se insertará es la operación de inserción, la complejidad del tiempo de inserción de la lista enlazada única es O(1), no lo probaré aquí, por lo que todo el proceso de inserción es igual a encontrar la posición de inserción + insertar = O(logn).
De hecho, la complejidad de tiempo de la operación de eliminación también es O (logn), ¿por qué?
De hecho, es lo mismo que insertar, pero habrá una operación adicional para encontrar el nodo predecesor, porque la eliminación hará que cambien los punteros de los nodos anterior y posterior.Este último nodo existe en el nodo actualmente eliminado, pero el el nodo predecesor anterior no lo hace. La consulta también es O(logn), así que elimine O(logn)+O(logn), por lo que la complejidad temporal de la eliminación es finalmente: O(logn), pero hay una cosa a tener en cuenta sobre la eliminación , si el nodo a eliminar también existe en la capa de índice, entonces los nodos de la capa de índice deben eliminarse al mismo tiempo , y el problema de los nodos predecesores se puede resolver utilizando una lista doblemente enlazada
4. Actualización del índice
La consulta, la eliminación y la adición de tablas de salto son excelentes en términos de rendimiento, ¿puede seguir siendo tan excelente? Dado que la tabla de salto también se usa para almacenar datos, definitivamente estará acompañada de frecuentes adiciones y eliminaciones. Suponiendo que se inserten más datos entre los nodos de índice en un cierto intervalo adyacente, dará lugar a una distribución desigual de los datos. De manera uniforme, el tiempo de consulta la eficiencia en un determinado intervalo se reduce y, en el peor de los casos, puede degenerar en una lista de un solo enlace. Todos los datos están en este intervalo, por lo que actualizamos y mantenemos la capa de índice en tiempo real cuando se insertan datos para garantizar el salto. La estructura de datos de la tabla no se degenerará en exceso, entonces, ¿cómo mantenemos los cambios en la capa de índice?
De hecho, no es difícil. La tabla de saltos utiliza una función aleatoria para mantener el equilibrio de los datos, es decir, para mantener los datos relativamente uniformes. Cuando agregamos datos a la tabla de saltos, la función aleatoria genera un número aleatorio. Función. Este número aleatorio es el índice. El número de capas, y luego agregue los nodos que se agregarán a los nodos de la capa de índice en esta capa, asumiendo que los datos que necesitamos insertar son 7, y el número aleatorio generado por el aleatorio función es: 2, entonces la inserción será de la siguiente manera como se muestra en la figura:
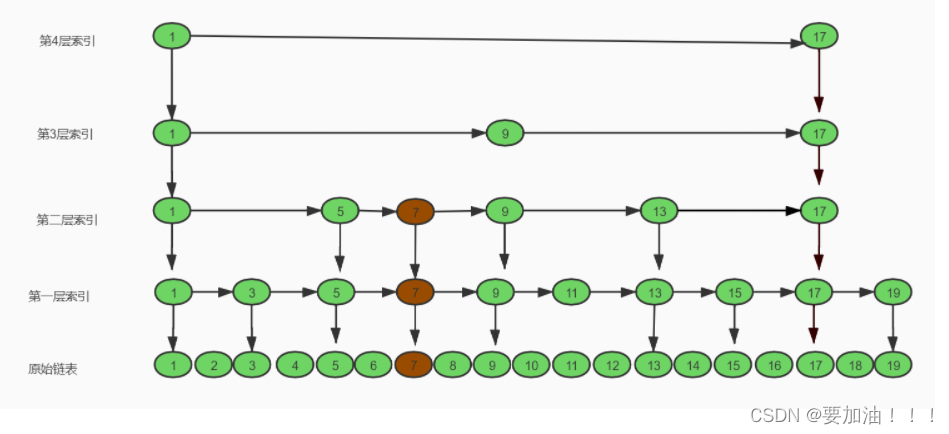
Aquí, los requisitos para la función aleatoria son muy altos. Puede garantizar el equilibrio de la tabla de salto y no degradará el rendimiento de la tabla de salto. Esto es lo mismo que el árbol rojo-negro para zurdos/diestros. .
Resumir
1. ¿Qué es una tabla de salto?
Saltar lista, hasta el final: Jump list En informática, una jump list es una estructura de datos. Hace que la complejidad temporal media de las operaciones de búsqueda e inserción de una secuencia ordenada que contiene n elementos sea:logn
2. Complejidad de tiempo/espacio de la lista de salto
Complejidad temporal: lO(logn)l, complejidad espacial: lO(n)l, la complejidad espacial disminuirá con el aumento de la distancia del intervalo de índice, pero la tendencia de la complejidad espacial sigue siendo lO(n)l, porque la información almacenada en la capa de índice es relativa a la lista enlazada original. Será mucho menos, por lo que incluso la complejidad espacial de O(n) es aceptable.
3. Aplicación de la tabla de salto
- Una colección ordenada para redis.
- El motor de almacenamiento de clave/valor de código abierto de Google.
- Estructura de almacenamiento interno HBase MemStore.
4. Actualización dinámica de la lista de salto
Dado que la tabla de omisión se compone de índices de múltiples capas, al insertar con frecuencia, causará demasiados datos antes de los nodos de índice adyacentes en un extremo. En el peor de los casos, todos los datos se concentrarán en un segmento determinado. Entre índices adyacentes nodos, esto hará que la lista de saltos degenere en una lista enlazada ordinaria, y la complejidad del tiempo también degenerará a O(n), por lo que en este momento, es necesario actualizar dinámicamente los nodos de índice en la lista de saltos. a través de la implementación de funciones aleatorias.
5. ¿Por qué Redis usa la lista de saltos para implementar la recopilación ordenada?
- Jump list es una estructura de datos compuesta por lista enlazada + índice multinivel. A través de la idea de diseño de intercambiar espacio por tiempo, se realiza la "búsqueda binaria" basada en lista enlazada. La complejidad temporal de buscar, eliminar e insertar es O (inicio de sesión).
- En comparación con el árbol B, el árbol rojo-negro, el árbol AVL, etc., la implementación de la tabla de salto es mucho más simple. El mantenimiento del equilibrio de este tipo de árboles es bastante problemático, mientras que la actualización del índice dinámico de la tabla de salto es relativamente mucho más simple. .
- La búsqueda de intervalos de la tabla de saltos es mejor que la del árbol rojo-negro.
Si hay alguna infracción, comuníquese para eliminar
la declaración de derechos de autor: este artículo es un artículo original del blogger de CSDN "Meteor 007", siguiendo el acuerdo de derechos de autor CC 4.0 BY-SA, adjunte el enlace de la fuente original y esta declaración para su reimpresión.
Enlace original: https://blog.csdn.net/qq_33220089/article/details/114641975