1 Instalación y despliegue de canales
1.1 Dirección de instalación del canal
(1) Dirección del sitio web oficial de Flume http://flume.apache.org/
(2) Dirección de visualización de documentos http://flume.apache.org/FlumeUserGuide.html
(3) Dirección de descarga http://archive.apache.org / dist/canal/
1.2 Instalación y despliegue
(1) Cargue apache-flume-1.9.0-bin.tar.gz en el directorio /opt/software de linux.
(2) Descomprima apache-flume-1.9.0-bin.tar.gz en el directorio /opt/module/.
tar -zxf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/module/
(3) Modificar el nombre de apache-flume-1.9.0-bin a flume-1.9.0
mv /opt/module/apache-flume-1.9.0-bin /opt/module/flume-1.9.0
(4) Cambie el archivo flume-env.sh.template bajo flume-1.9.0/conf a flume-env.sh, y configure el archivo flume-env.sh:
mv flume-env.sh.template flume-env.sh
vim flume-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_271
2 Primeros pasos con Flume
2.1 Caso oficial de monitoreo de datos portuarios
(1) Requisitos: use Flume para monitorear un puerto, recopilar datos del puerto e imprimir en la consola.
(2) Análisis:
envíe datos al puerto 44444 de la máquina a través de la herramienta netcat -> Flume monitorea el puerto 44444 de la máquina, lee datos a través del extremo fuente de Flume -> escribe los datos adquiridos en la consola a través del extremo SInk de Flume .
Pasos:
(1) Instalar usando netcat:
//下载netcat
sudo yum install -y nc
//开启服务端端口
nc -lk 9999
//开启服务端进行通信
nc localhost 9999
(2) Determinar si el puerto 44444 está ocupado
sudo netstat -nlp | grep 44444
(3) Cree una carpeta de trabajo en flume-1.9.0, cree un archivo de configuración de Flume Agent netcat-flume-logger.conf debajo del trabajo (que representa la fuente de datos, a través de flume, hasta el receptor), agregue el siguiente contenido
# Name the components on this agent
#组件声明
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port =44444
# Describe the sink a1.sinks.k1.type = logger
# Use a channel whichbuffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1

(4) Abra el puerto de escucha del canal
//方式一
bin/flume-ng agent --conf conf/ --name a1 --conf-file job/netcat-flume-logger.conf -Dflume.root.logger=INFO,console
//方式二
bin/flume-ng agent -c conf/ -n a1 -f job/netcat-flume-logger.conf -Dflume.root.logger=INFO,console
Descripción del parámetro:
(i) –conf/-c: El archivo de configuración está en el directorio conf/.
(ii) –nombre/-n: Indica que el agente se llama a1.
(iii) –conf-file/-f: El archivo de configuración leído por flume esta vez es el archivo netcat-flume-logger.conf en el directorio de trabajo.
(iv) -Dflume.root.logger-INFO,console: -D indica que el valor del atributo del parámetro flume.root.logger se modifica dinámicamente cuando se ejecuta flume, y el nivel de impresión del registro de la consola se establece en el nivel INFO. Los niveles de registro incluyen: registro, información, advertencia, error.
(5) Use netcat para enviar contenido al puerto 44444 de esta máquina
nc localhost 44444
hello
(6) Observe los datos recibidos en la página de monitoreo Flume
2.2 Monitoreo en tiempo real de un solo archivo adicional
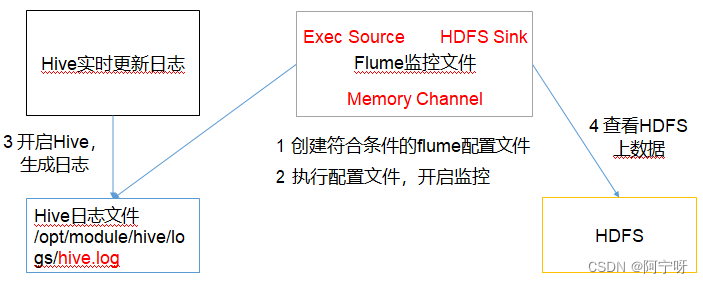
(1) Requisitos: Supervise los registros de Hive en tiempo real y cárguelos en HDFS.
(2) Análisis:
Pasos:
(1) Cree un archivo en el directorio del trabajo: file-flume-hdfs.conf
Si desea leer archivos en el sistema Linux, debe ejecutar el comando de acuerdo con las reglas del comando Linux. Dado que el registro de Hive está en el sistema Linux, se selecciona el tipo de archivo a leer: exec significa ejecutar. Indica la ejecución de un comando de Linux para leer un archivo.
Añadir:
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
#定义source类型为exec可执行命令的
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /opt/module/hive/logs/hive.log
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop102/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round= true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event 才 flush 到 HDFS 一次
a2.sinks.k2.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件(单位s)
a2.sinks.k2.hdfs.rollInterval = 60
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event 数量无关
a2.sinks.k2.hdfs.rollCount = 0
# Use a channelwhich buffers eventsin memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
(2) canal de circulación
bin/flume-ng agent --conf conf/ --name a2 --conf-file job/file-flume-hdfs.conf
//或用
bin/flume-ng agent -n a2 -c conf/ -f job/file-flume-hdfs.conf
(3) Inicie Hadoop y Hive y opere Hive para generar registros.
La fuente Exec es adecuada para monitorear un archivo adjunto en tiempo real .
Desventajas: la cola solo puede transmitir los últimos 10 datos y no admite la reanudación de la transmisión desde los puntos de interrupción.
2.3 Monitoreo en tiempo real de múltiples archivos nuevos en el directorio
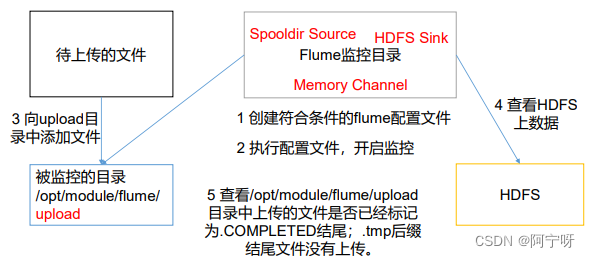
(1) Requisitos: use Flume para monitorear archivos en todo el directorio y cárguelos en HDFS
(2) Análisis:
Pasos:
(1) Cree un archivo de configuración dir-flume-hdfs.conf en el directorio de trabajo y agregue el siguiente contenido
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
#定义source类型为目录
a3.sources.r3.type = spooldir
#监控目录
a3.sources.r3.spoolDir = /opt/module/flume-1.9.0/upload
#定义文件上传完的后缀
a3.sources.r3.fileSuffix = .COMPLETED
#是否有文件头
a3.sources.r3.fileHeader = true
#忽略所有以.tmp结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
# Describe the sink
a3.sinks.k3.type= hdfs
a3.sinks.k3.hdfs.path =hdfs://hadoop102/flume/upload/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round= true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a3.sinks.k3.hdfs.batchSize= 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是 128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event 数量无关
a3.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
(2) Inicie el comando del archivo de monitoreo
bin/flume-ng agent --conf conf/ --name a3 --conf-file job/dir-flume-hdfs.conf
Al usar Spooling Directory Source, no cree ni modifique continuamente archivos en el directorio de monitoreo, los archivos cargados terminarán con .COMPLETED, la carpeta monitoreada busca cambios en los archivos cada 500 milisegundos.
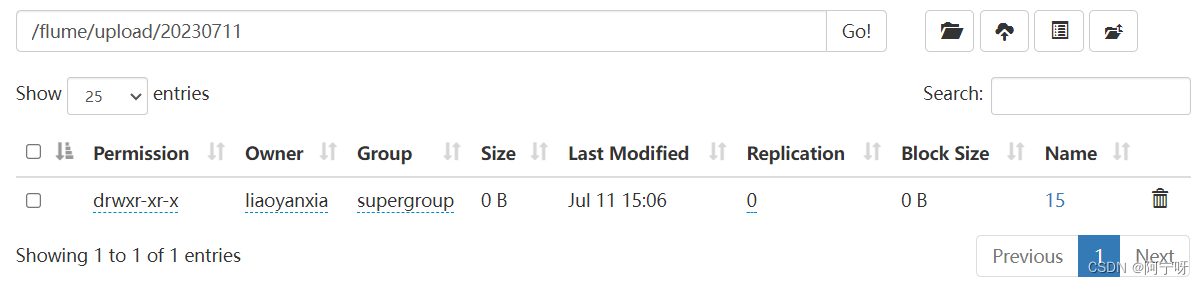
(3) Agregue archivos a la carpeta de carga, cree una carpeta de carga en el directorio /opt/module/flume y agregue los siguientes archivos
touch test.txt
touch text.tmp
touch test.log
Spooldir Source es adecuado para sincronizar archivos nuevos.
Desventajas: no es adecuado para monitorear y sincronizar archivos con registros adjuntos en tiempo real
2.4 Monitoreo en tiempo real de múltiples archivos adicionales en el directorio
Taildir Source es adecuado para monitorear múltiples archivos adjuntos en tiempo real y puede realizar la reanudación del punto de interrupción.
Taildir Descripción:
Taildir Source mantiene un archivo de posición en formato json, que actualizará regularmente la última posición leída por cada archivo en el archivo de posición, para que pueda realizar una carga continua desde los puntos de interrupción.
El formato del archivo de posición es el siguiente:
{
"inode":2496272,"pos":12,"file":"/opt/module/flume-1.9.0/files/file1.txt"}
{
"inode":2496275,"pos":12,"file":"/opt/module/flume-1.9.0/files/file2.txt"}
Nota: El área donde se almacenan los metadatos de archivos en Linux se llama inodo. Cada inodo tiene un número. El sistema operativo usa números de inodo para identificar diferentes archivos. Los sistemas Unix/Linux no usan nombres de archivo internamente, pero usan números de inodo para identificar archivos. .
(1) Requisitos: use Flume para monitorear los archivos adjuntos en tiempo real de todo el directorio y cárguelos en HDFS.
(2) Análisis:
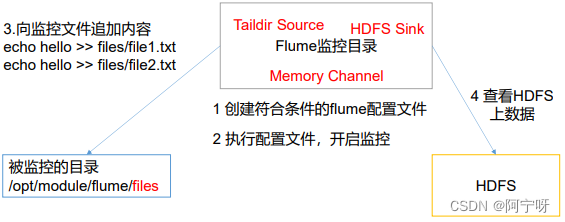
Pasos:
(1) Cree el archivo de configuración taildir-flume-hdfs.conf en el directorio del trabajo y agregue el siguiente contenido:
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
#定义source类型
a3.sources.r3.type = TAILDIR
#指定position——file的位置
a3.sources.r3.positionFile = /opt/module/flume-1.9.0/tail_dir.json
a3.sources.r3.filegroups = f1 f2
#定义监控目录文件
a3.sources.r3.filegroups.f1 = /opt/module/flume/files/.*file.*
a3.sources.r3.filegroups.f2 = /opt/module/flume/files2/.*log.*
# Describe the sink
a3.sinks.k3.type= hdfs
a3.sinks.k3.hdfs.path =hdfs://hadoop102/flume/upload2/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个 Event才 flush 到 HDFS 一次
a3.sinks.k3.hdfs.batchSize= 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval= 60
#设置每个文件的滚动大小大概是 128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event 数量无关
a3.sinks.k3.hdfs.rollCount = 0
# Use a channelwhich buffers eventsin memory
a3.channels.c3.type= memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the sourceand sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
(2) Inicie el comando de carpeta de monitoreo
bin/flume-ng agent --conf conf/ --name a3 --conf-file job/taildir-flume-hdfs.conf
(3) Agregue contenido adicional al archivo de archivos, cree archivos y carpetas de archivos2 en el directorio /opt/module/flume-1.9.0 y agregue archivos a esta carpeta:
#files文件夹下
touch file1.txt
touch file2.txt
echo hello >> file1.txt
echo lyx >> file2.txt
#files2文件夹下
touch file3.log
echo hi >> file3.log
(4) Verifique los datos en HDFS.
Hay un problema con lo anterior:
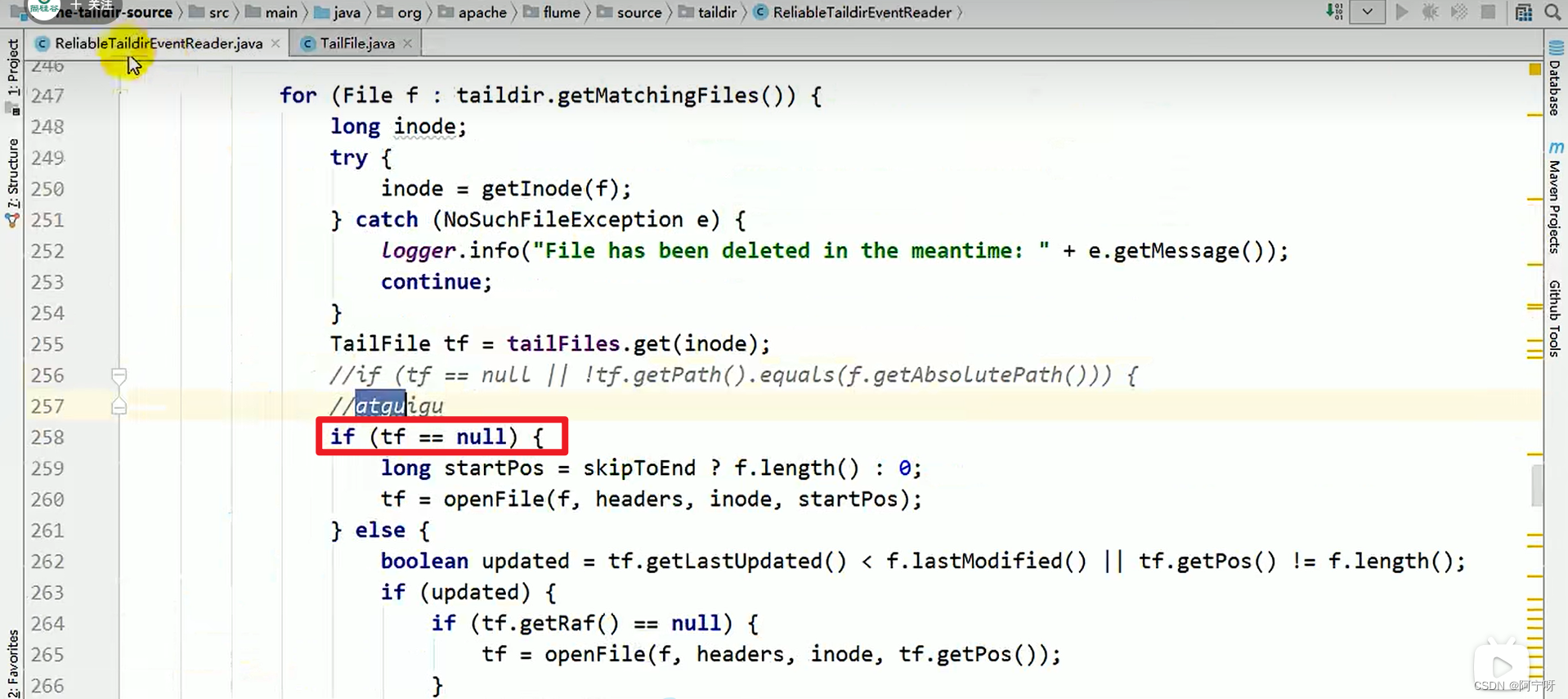
si el nombre del archivo se cambia regularmente y se recrea un archivo con un nuevo nombre de archivo original, los datos monitoreados y cargados serán el contenido del archivo acumulado, no los datos del contenido actualizado, lo que resultará en la duplicación de datos. .
Solución:
modifique las operaciones de actualización y lectura en el código fuente, luego empaquete y descargue el archivo modificado en el local, cárguelo en el directorio lib para reemplazar el código fuente y reinicie el comando de la carpeta de monitoreo.
(1) Operación de actualización: solo mire el valor del inodo.
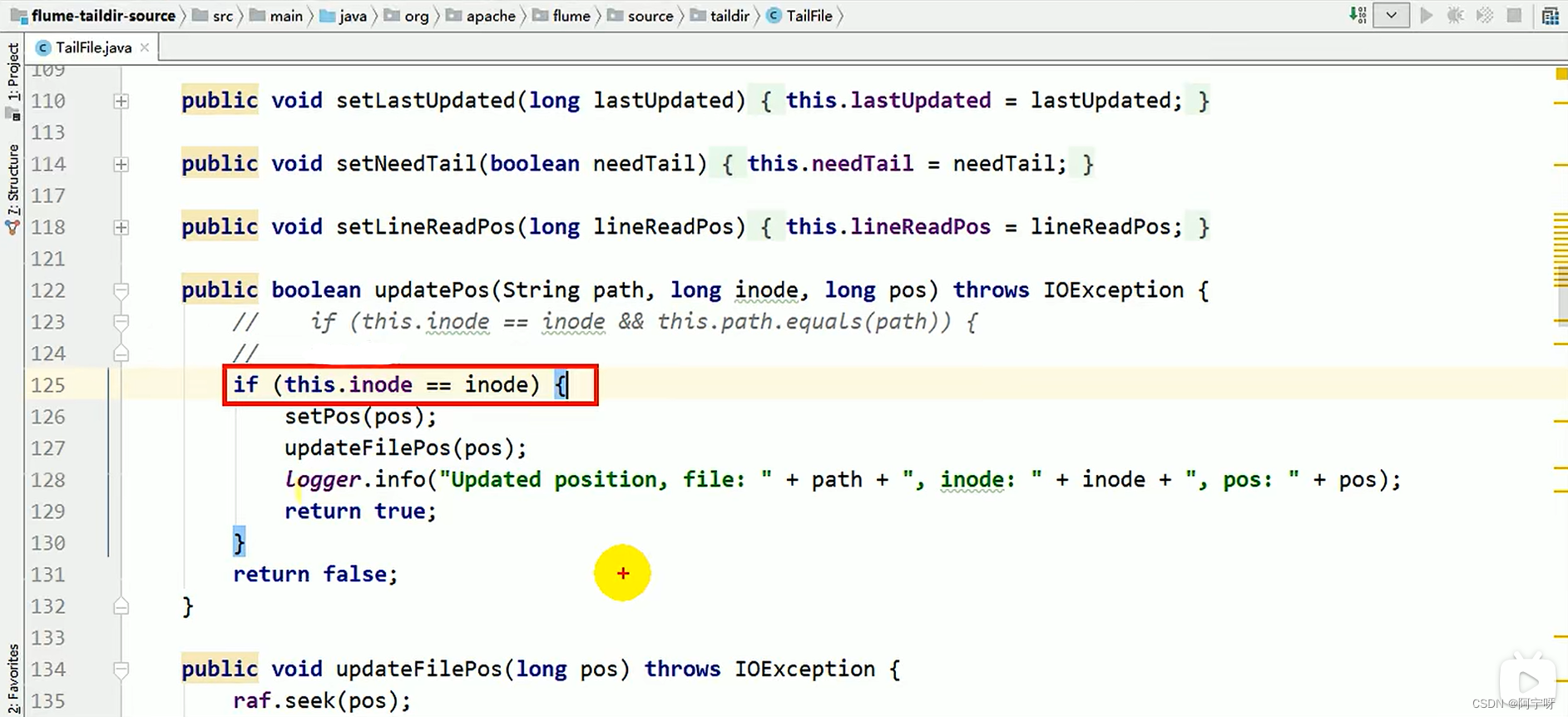
(2) Operación de lectura: siempre que el archivo sea un archivo nuevo, solo se mira el valor del inodo, no la ruta absoluta.