Tabla de contenido
Estructura de canal
Proceso de ejecución de Flume: Fuentes —— Procesador de canales —— Interceptores —— Selector de canales —— Canales —— Procesador de sumideros —— Sumideros
Entre ellos, hay transacciones (put y take) de Soucrce a Channel y de Channel a Sink
Serie avro

Para que los datos fluyan entre varios agentes o saltos, el receptor del agente anterior y la fuente del agente actual deben ser de tipo avro , y el receptor apunta al nombre de host (o dirección IP) y al puerto de la fuente. Esta es la base de otras estructuras complejas, pero no se recomienda conectar demasiados canales, porque demasiados canales no solo afectarán la velocidad de transmisión, sino que una vez que un canal de nodo se desconecte durante el proceso de transmisión, afectará a todo el sistema de transmisión.
Copiar y multiplexar

Flume admite la multiplexación de flujos de eventos a uno o más destinos. Esto se logra mediante la definición de un multiplexor de flujo que puede replicar o enrutar selectivamente eventos a uno o más canales.
En el ejemplo anterior, puede ver que la fuente del Agente llamado foo puede dividir el flujo de datos en tres canales diferentes. Al seleccionar un canal ( selector de canales ), puede ser replicación (replicación) o multiplexación (multiplexación).
Para la replicación, cada evento se envía a todos los canales. Para la multiplexación, cuando el atributo del evento coincide con el valor preconfigurado, el evento se entrega al canal disponible correspondiente. Por ejemplo, en el siguiente ejemplo oficial, si el atributo del evento se establece en CZ, se selecciona el canal c1; si el atributo del evento se establece en US, se seleccionan los canales c2 y c3; de lo contrario, se selecciona el canal c4;
a1.sources = r1
a1.channels = c1 c2 c3 c4
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = state
a1.sources.r1.selector.mapping.CZ = c1
a1. sources.r1.selector.mapping.US = c2 c3
a1.sources.r1.selector.default = c4
El selector de canales selecciona la estrategia de replicación de forma predeterminada (replicando)
Equilibrio de carga y conmutación por error

Hay tres tipos de procesador fregadero, a saber DefaultSinkProcessor , LoadBalancingSinkProcessor y FailoverSinkProcessor .
DefaultSinkProcessor corresponde a un solo Sink, LoadBalancingSinkProcessor y FailoverSinkProcessor corresponden al Sink Group, LoadBalancingSinkProcessor puede realizar la función de equilibrio de carga y FailoverSinkProcessor puede realizar la función de failover.
polimerización

Este modo es muy común y muy práctico. Las aplicaciones web diarias generalmente se distribuyen en miles de servidores, que generan muchos registros y son muy difíciles de procesar. El uso del canal puede resolver bien este problema.Cada servidor despliega un canal para recopilar registros y los transmite a un canal que recopila registros y luego carga el canal a hdfs, hive, hbase, etc. para el análisis de registros.
Mecanismo de transacción
Mecanismo de transacción de Flume (similar al mecanismo de transacción de la base de datos): Flume utiliza dos transacciones independientes para ser responsable de la entrega de eventos de Soucrce a Channel y de Channel a Sink . Por ejemplo, la fuente del directorio de spool crea un evento para cada línea del archivo. Una vez que todos los eventos de la transacción se envían al canal y el envío es exitoso, Soucrce marcará el archivo como completo. De la misma manera, la transacción maneja el proceso de transferencia de Canal a Sumidero de manera similar, si el evento no puede ser registrado por alguna razón, la transacción será revertida. Y todos los eventos permanecerán en el Canal, esperando ser entregados nuevamente.
Según los principios arquitectónicos de Flume, es imposible que Flume pierda datos. Tiene un mecanismo de transacción interno completo. Source to Channel son transaccionales y Channel to Sink es transaccional, por lo que no habrá pérdida de datos en estos dos enlaces. La única situación posible de pérdida de datos es que el canal usa memoryChannel y el agente está inactivo y los datos se pierden, o los datos de almacenamiento del canal están llenos, lo que hace que la fuente ya no escriba y se pierdan los datos no escritos.
Flume no perderá datos, pero puede causar su duplicación. Por ejemplo, si Sink envió los datos correctamente pero no se recibe respuesta, Sink enviará los datos nuevamente, lo que puede causar la duplicación de datos.
Caso 1: fuente de datos única y múltiples exportaciones
analisis de CASO
Use Flume1 para monitorear los cambios de archivos, Flume1 pasa los cambios a Flume2 y Flume2 es responsable de almacenarlos en HDFS . Al mismo tiempo, Flume1 transfiere el contenido modificado a Flume3 y Flume3 es responsable de enviarlo al sistema de archivos local .
Pasos del caso
-
Cree un archivo vacío: toque date.txt
-
Inicie HDFS y Yarn: start-dfs.sh , start-yarn.sh
-
Cree tres archivos de configuración, flume1.conf , flume2.conf , flume3.conf :
el nombre del primer agente es flume1 , una fuente es r1 , dos canales son c1 y c2 y dos sumideros son k1 y k2. . El tipo de fuente es taildir , que supervisa el archivo local date.txt . El tipo de sumidero es avro y los puertos de los dos sumideros son diferentes y están conectados a los otros dos agentes. El tipo de canal es memoria. Hay tres tipos de
procesador fregadero , a saber DefaultSinkProcessor , LoadBalancingSinkProcessor y FailoverSinkProcessor . Para enviar datos desde una fuente de datos a diferentes lugares, un sumidero está vinculado a un canal y se requieren múltiples canales y sumideros.# Name the components on this agent a1.sources = r1 a1.channels = c1 c2 a1.sinks = k1 k2 将数据复制给所有channel# 将数据复制给所有channel(默认,可不写) a1.sources.r1.selector.type = replicating # Describe/configure the source a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1 = /opt/flume-1.9.0/date.txt a1.sources.r1.positionFile = /opt/flume-1.9.0/file/position.json # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = master a1.sinks.k1.port = 44444 a1.sinks.k2.type = avro a1.sinks.k2.hostname = master a1.sinks.k2.port = 55555 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2El tipo de fuente del segundo agente es avro , que está conectado al primer agente. El tipo de fregadero es HDFS .
# Name the components on this agent a2.sources = r1 a2.channels = c1 a2.sinks = k1 # Describe/configure the source a2.sources.r1.type = avro a2.sources.r1.bind = master a2.sources.r1.port = 44444 # Describe the sink a2.sinks.k1.type = hdfs a2.sinks.k1.hdfs.path = hdfs://master:9000/a/%Y%m%d/%H a2.sinks.k1.hdfs.filePrefix = logs a2.sinks.k1.hdfs.round = true a2.sinks.k1.hdfs.roundValue = 1 a2.sinks.k1.hdfs.roundUnit = hour a2.sinks.k1.hdfs.useLocalTimeStamp = true a2.sinks.k1.hdfs.batchSize = 100 a2.sinks.k1.hdfs.fileType = DataStream a2.sinks.k1.hdfs.rollInterval = 30 a2.sinks.k1.hdfs.rollSize = 134217700 a2.sinks.k1.hdfs.rollCount = 0 # Use a channel which buffers events in memory a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1El tipo de fuente del tercer agente también es avro , que está conectado al primer agente. El tipo de fregadero es file_roll .
# Name the components on this agent a3.sources = r1 a3.channels = c1 a3.sinks = k1 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = master a3.sources.r1.port = 55555 # Describe the sink a3.sinks.k1.type = file_roll a3.sinks.k1.sink.directory = /opt/flume-1.9.0/file # Use a channel which buffers events in memory a3.channels.c1.type = memory a3.channels.c1.capacity = 1000 a3.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1 -
Inicie canal2, canal3, canal1 respectivamente. Nota 1 al final, porque la fuente avro debe ser el servidor.
bin/flume-ng agent -c conf -f flume2.conf -n a2 -Dflume.root.logger=INFO,console bin/flume-ng agent -c conf -f flume3.conf -n a3 -Dflume.root.logger=INFO,console bin/flume-ng agent -c conf -f flume1.conf -n a1 -Dflume.root.logger=INFO,console -
Ingrese fecha> fecha.txt para modificar el archivo
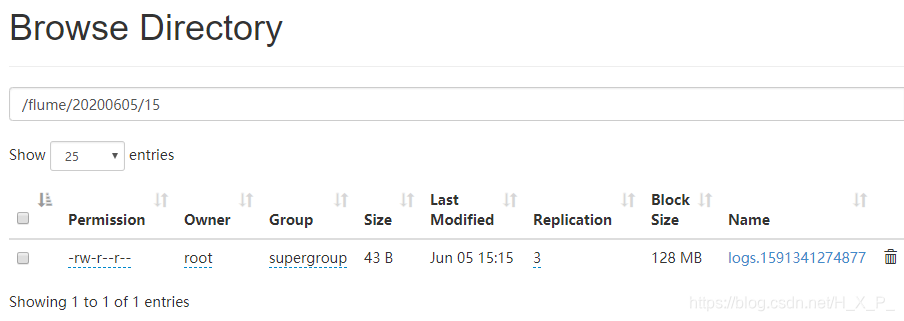
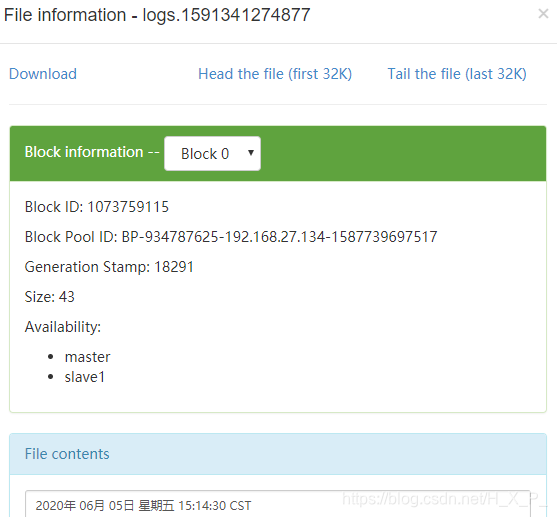
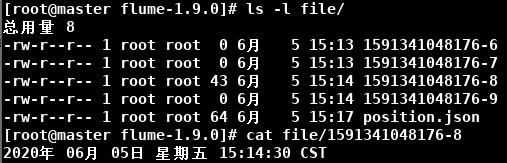
Caso 2: Conmutación por error
analisis de CASO
Utilice el monitor Flume1 de un puerto cuyo receptor de grupo de sumideros colinda respectivamente con Flume2 y Flume3 , utilizando FailoverSinkProcessor , implemente la funcionalidad de conmutación por error .
Pasos del caso
-
Cree tres archivos de configuración, flume1.conf , flume2.conf , flume3.conf : el
primer agente agrega una configuración para los grupos de receptores , utilizando la estrategia de conmutación por error . Tenga en cuenta que, la prioridad k2 es mayor que k1 , por lo que k2 canal correspondiente está activado y k1 correspondiente al canal está en espera# Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinks = k1 k2 a1.sinkgroups = g1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = master a1.sources.r1.bind = 33333 # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = master a1.sinks.k1.port = 44444 a1.sinks.k2.type = avro a1.sinks.k2.hostname = master a1.sinks.k2.port = 55555 # Sink groups a1.sinkgroups.g1.sinks = k1 k2 a1.sinkgroups.g1.processor.type = failover a1.sinkgroups.g1.processor.priority.k1 = 50 a1.sinkgroups.g1.processor.priority.k2 = 100 a1.sinkgroups.g1.processor.maxpenalty = 10000 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c1El tipo de sumidero del segundo agente es logger
# Name the components on this agent a2.sources = r1 a2.channels = c1 a2.sinks = k1 # Describe/configure the source a2.sources.r1.type = avro a2.sources.r1.bind = master a2.sources.r1.port = 44444 # Describe the sink a2.sinks.k1.type = logger # Use a channel which buffers events in memory a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1La configuración del segundo y tercer agente es similar, pero el número de puerto es diferente
# Name the components on this agent a3.sources = r1 a3.channels = c1 a3.sinks = k1 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = master a3.sources.r1.port = 55555 # Describe the sink a3.sinks.k1.type = logger # Use a channel which buffers events in memory a3.channels.c1.type = memory a3.channels.c1.capacity = 1000 a3.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1 -
Inicie canal2, canal3, canal1 respectivamente.
bin/flume-ng agent -c conf -f flume2.conf -n a2 -Dflume.root.logger=INFO,console bin/flume-ng agent -c conf -f flume3.conf -n a3 -Dflume.root.logger=INFO,console bin/flume-ng agent -c conf -f flume1.conf -n a1 -Dflume.root.logger=INFO,console -
Inicie una nueva terminal, escriba nc master 33333 y luego escriba algo.
La esquina superior izquierda es flume1 , la esquina superior derecha es flume2 , la esquina inferior izquierda es flume3 y la esquina inferior derecha es el cliente . Dado que la prioridad de flume3 es más alta que la de flume2 , entonces flume3 está activado , flume3 puede recibir la información.
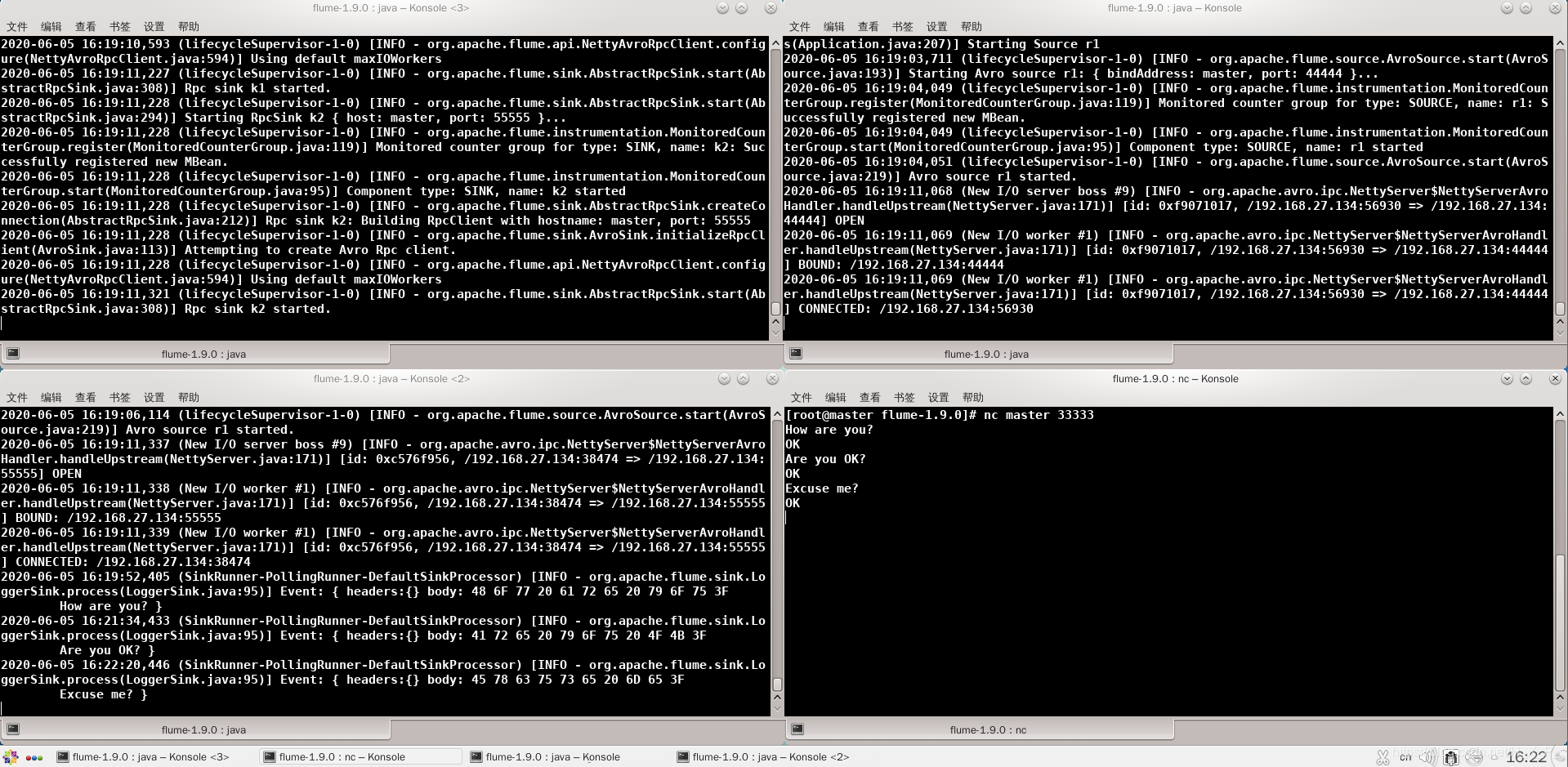
En este momento, flume3 cuelga, luego flume2 pasa a positivo, de espera a activado , y puede recibir mensajes.
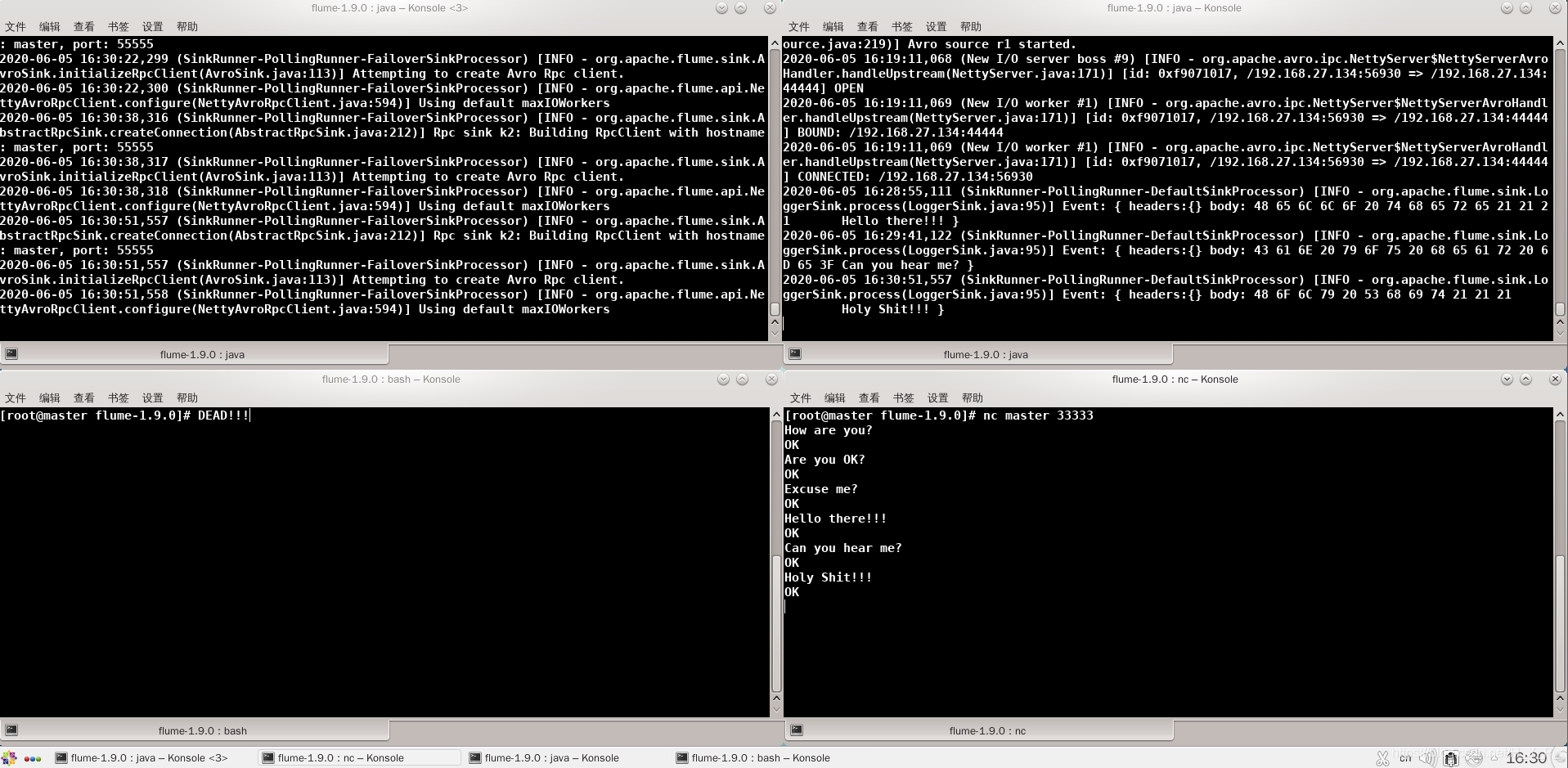
En este momento, flume3 se resucita. Debido a que la prioridad de flume3 es mayor que flume2 , flume3 puede recibir mensajes nuevamente.
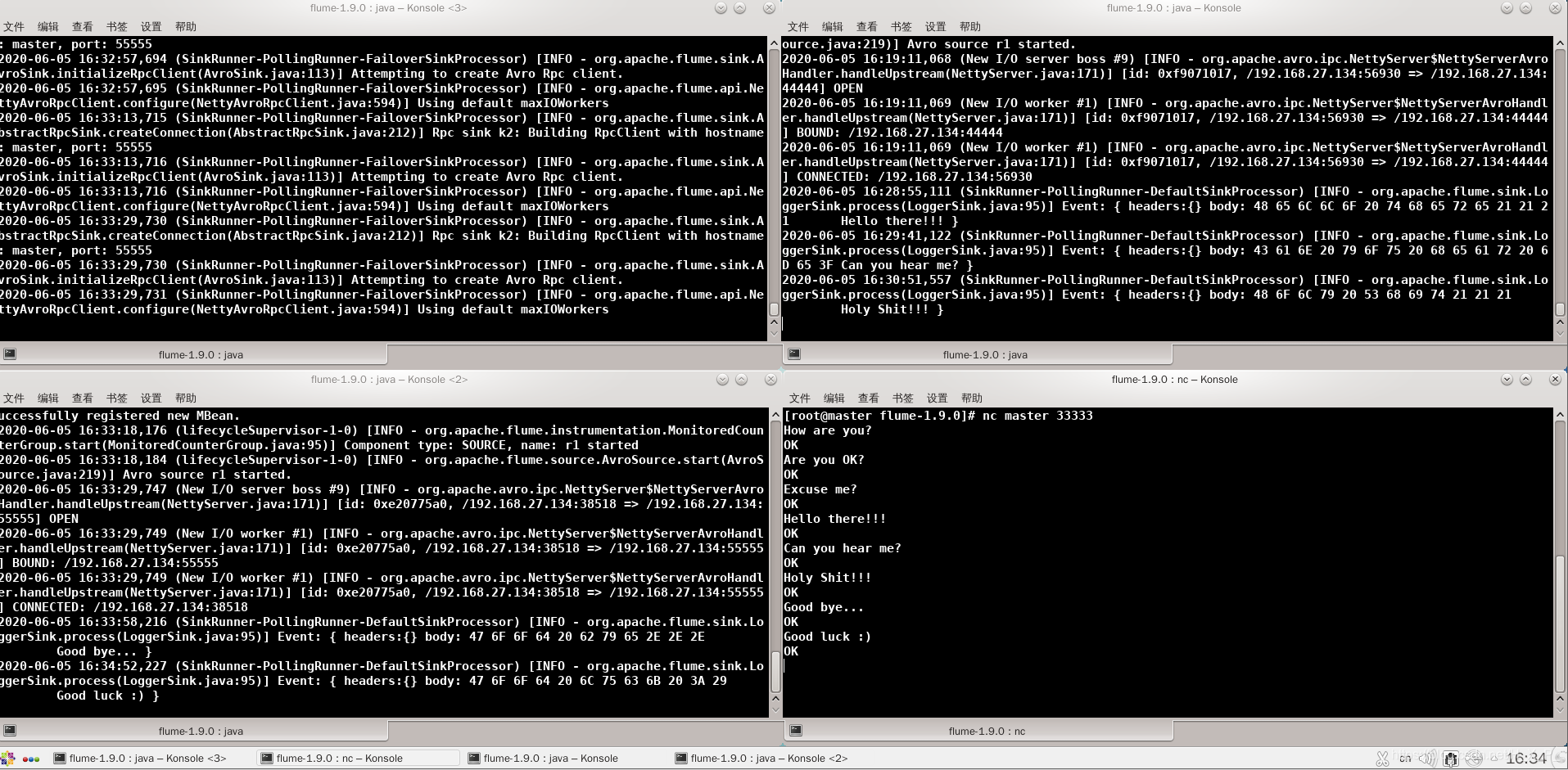
Caso 3: equilibrio de carga
Pasos del caso
-
Cree tres archivos de configuración, flume1.conf , flume2.conf , flume3.conf . Entre ellos, flume2.conf y flume3.conf son los mismos que flume2 y flume3 en el caso dos. flume1 es solo la estrategia de Sink Groups cambiada. La siguiente es la configuración de flume1:
# Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinks = k1 k2 a1.sinkgroups = g1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = master a1.sources.r1.port = 33333 # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = master a1.sinks.k1.port = 44444 a1.sinks.k2.type = avro a1.sinks.k2.hostname = master a1.sinks.k2.port = 55555 # Sink groups a1.sinkgroups.g1.sinks = k1 k2 a1.sinkgroups.g1.processor.type = load_balance a1.sinkgroups.g1.processor.backoff = true a1.sinkgroups.g1.processor.selector = random # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c1 -
Inicie canal2, canal3, canal1 respectivamente. Inicie una nueva terminal, escriba nc master 33333 y luego escriba algo.
La esquina superior izquierda es flume1 , la esquina superior derecha es flume2 , la esquina inferior izquierda es flume3 y la esquina inferior derecha es el cliente .
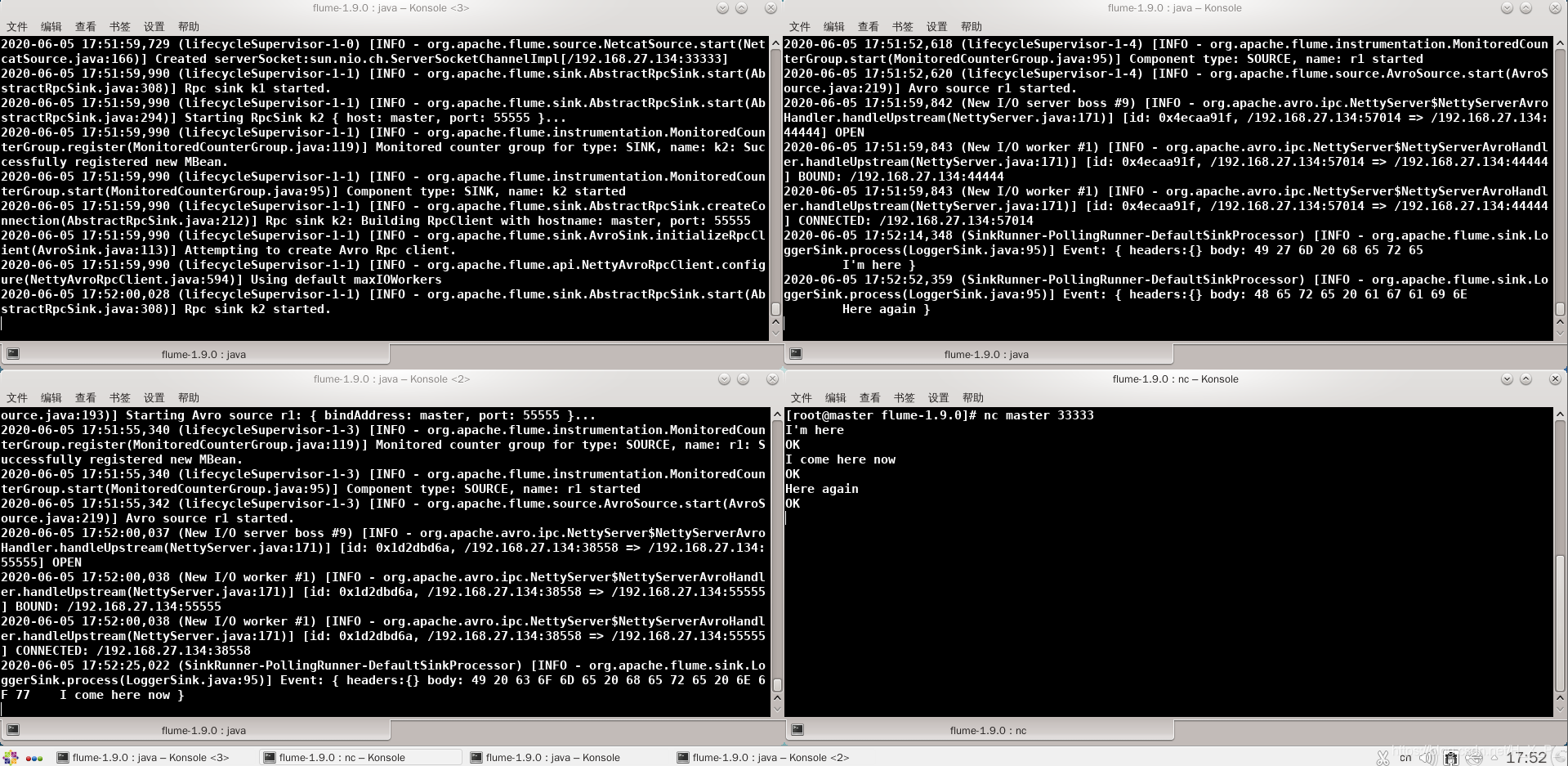
Caso 4: Agregación
analisis de CASO
esclavo1 en Flume1 monitoreando un puerto de datos, esclavo2 en Flume2 monitorean el archivo local date.txt , Flume1 y Flume2 envían datos al maestro en Flume3 , Flume3 los datos de impresión a la consola.
Pasos del caso
-
Cree el archivo de configuración flume1.conf en slave1. El tipo de fuente es netcat , puerto de escucha. : El tipo de fregadero es Avro , con acoplamiento flume3.
# Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinks = k1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 33333 # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = master a1.sinks.k1.port = 44444 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1Cree el archivo de configuración flume2.conf en slave2. El tipo de fuente es exec , que monitorea archivos. : El tipo de fregadero es Avro , con acoplamiento flume3.
# Name the components on this agent a2.sources = r1 a2.channels = c1 a2.sinks = k1 # Describe/configure the source a2.sources.r1.type = exec a2.sources.r1.command = tail -F /opt/flume-1.9.0/date.txt # Describe the sink a2.sinks.k1.type = avro a2.sinks.k1.hostname = master a2.sinks.k1.port = 44444 # Use a channel which buffers events in memory a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1Cree un archivo de configuración flume3.conf en el maestro. fuente de tipo Avro , y flume2 flume1 recibiendo datos enviados. : El tipo de receptor es logger , que escribe los datos recibidos en la consola.
# Name the components on this agent a3.sources = r1 a3.channels = c1 a3.sinks = k1 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = master a3.sources.r1.port = 44444 # Describe the sink a3.sinks.k1.type = logger # Use a channel which buffers events in memory a3.channels.c1.type = memory a3.channels.c1.capacity = 1000 a3.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1 -
Inicie canal2, canal3, canal1 respectivamente.
-
Ingrese nc localhost 33333 en slave1 , y luego envíe datos
-
Ingrese fecha> fecha.txt en esclavo2
-
Los datos recibidos se pueden ver en el maestro