Con el fin de satisfacer las necesidades de las empresas de herramientas de productividad iterativas y actualizadas en el proceso de transformación digital, Lingqueyun lanzó recientemente la solución Alauda MLOps para ayudar a las empresas a implementar rápidamente la tecnología de IA y realizar aplicaciones y servicios inteligentes.
El gran modelo AIGC se ha convertido en el motor de la innovación empresarial
Con la explosión de ChatGPT, cada vez más personas consideran usar IA para mejorar la eficiencia y la calidad de nuestro trabajo diario y ayudar a generar los datos de texto requeridos a través del diálogo. Ya sea resumiendo datos en tablas, escribiendo artículos de acuerdo con indicaciones o realizando preguntas y respuestas de conocimiento profesional, a través de la ingeniería de indicaciones adecuada, ChatGPT puede brindar la mejor respuesta e incluso reemplazar parte del trabajo humano.
Además, el contenido generado por AI no se limita a datos de texto, sino que también incluye herramientas como pintura AI (difusión estable), composición musical (Amper Music), generación de películas (Runway), etc. Estas son las categorías de AIGC ( Contenido generado por IA), y también actualizan constantemente la productividad en muchas industrias.

Alauda MLOps ayuda a las empresas a construir rápidamente sus propios modelos grandes
Sin embargo, las empresas necesitan un modelo local que posean y administren para realizar el trabajo anterior, ya que puede garantizar:
· Factor de seguridad: durante la conversación, la empresa no quiere enviar los datos internos de la empresa al modelo de IA en Internet;
· Personalización de funciones: espere utilizar sus propios datos para mejorar la capacidad del modelo en escenarios específicos (ajuste fino);
· Revisión de contenido: de acuerdo con los requisitos de las leyes y reglamentos, realice un filtrado secundario en el contenido de entrada y salida.
Entonces, en tal escenario, ¿cómo puede una empresa construir y personalizar rápidamente dicho modelo? ¡La respuesta es usar MLOps nativos en la nube + modelos de exposición!
Según la introducción de OpenAI, utiliza clústeres de computación de GPU a gran escala Azure + MPI cuando entrena modelos a gran escala como ChatGPT/GPT-4. En el entorno nativo de la nube privada, al usar la cadena de herramientas MLOps, las empresas también pueden tener un poder de cómputo de aprendizaje automático a gran escala que se puede escalar horizontalmente. Al utilizar la plataforma MLOps se pueden obtener las siguientes mejoras:
Más adecuado para el proceso de entrenamiento y predicción de modelos preentrenados a gran escala;
· Reducir el umbral de la aplicación para modelos grandes: proceso de tutorial incorporado para usar modelos grandes previamente entrenados, comience en un solo paso;
· Perfecta plataforma convencional de aprendizaje automático y aprendizaje profundo;
· Use pipeline + scheduler para organizar de manera uniforme tareas de capacitación distribuida a gran escala y admitir la personalización de varios métodos y marcos de capacitación distribuidos, incluidos DDP, Pipeline, ZERo, FSDP;
Personalización del proceso : de acuerdo con el negocio real, seleccione un subconjunto de la cadena de herramientas de MLOps para crear un proceso comercial adecuado;
· Plataforma completa de MLOps: proporciona una cadena de herramientas de MLOps fluida y completa.
A continuación, tomaremos la plataforma Alauda MLOps como ejemplo para presentar cómo construir su propio "ChatGPT" basado en el modelo de chat (lora) del modelo pre-entrenado LLaMa, personalizar e iniciar un modelo de diálogo LLM.
Además, al usar otros modelos de pre-entrenamiento HuggingFace, también puede construir rápidamente sus propios modelos, como Vicuña, MPT y otros modelos. Se invita a los lectores interesados a probarlo por sí mismos.
· método de obtención ·
MLOps empresariales:
https://www.alauda.cn/open/detail/id/740.html
Versión de código abierto de MLOps:
https://github.com/alauda/kubeflow-chart
¿Cómo completar la personalización y la implementación de modelos previos al chat a gran escala en MLOps nativos de la nube?
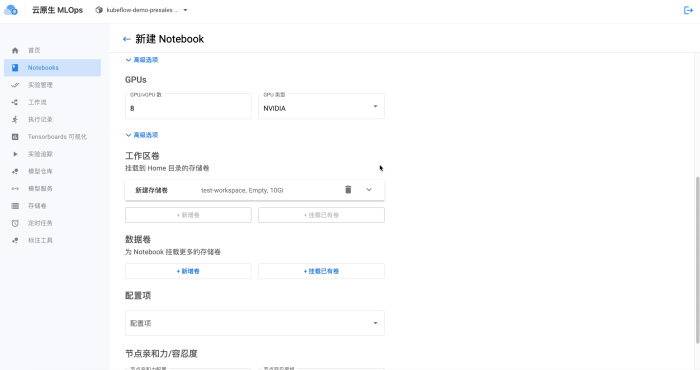
Primero, necesitamos iniciar un entorno Notebook y asignarle los recursos de GPU necesarios (según la medición real, entrenar el modelo de media precisión alpaca 7b requiere 4 piezas de K80, o una pieza de 4090, y suficiente tamaño de memoria):
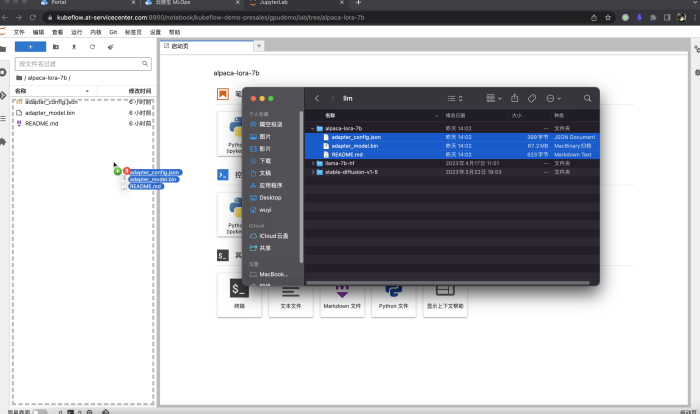
Luego, debemos preparar el código correspondiente y los archivos del modelo de github y abrazar la cara.
· Descargue el proyecto: https://github.com/tloen/alpaca-lora, luego arrástrelo y suéltelo en la barra de navegación de archivos de Notebook. También puede usar la línea de comando para ejecutar la descarga de clones de git en Notebook;
· Descargue el modelo de lenguaje de pesas previas al entrenamiento: https://huggingface.co/decapoda-research/llama-7b-hf, y arrastre y cárguelo en Notebook. También puede usar git lfs clone para descargar el modelo en Notebook;
· Descarga las pesas de preentrenamiento del modelo lora: https://huggingface.co/tloen/alpaca-lora-7b, y arrastra y sube a Notebook. También puede usar git lfs clone para descargar el modelo en Notebook.
Habrá un largo tiempo de espera para cargar un modelo grande aquí. Si la conexión de red con huggingface es buena, puede optar por descargarlo directamente desde la red en Notebook.
A continuación, primero usamos el modelo preentrenado que acabamos de descargar, iniciamos una aplicación web de diálogo de IA para verificar el efecto y montamos el disco usado por Notebook para leer estos archivos de modelo:

Luego, podemos usar la configuración yaml anterior o el formulario de creación de aplicaciones nativas para crear un servicio de predicción. Tenga en cuenta que el servicio de inferencia solo necesita usar una GPU K80 para comenzar.
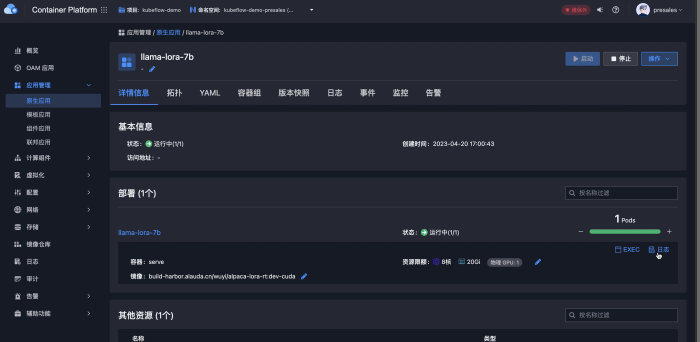
La imagen que usamos aquí está construida usando el siguiente Dockerfile:

Una vez que se inicia el servicio de inferencia, podemos visitarlo en el navegador e intentar realizar varias conversaciones con este modelo. Dado que el modelo alpaca-lora no es lo suficientemente compatible con el chino, aunque se puede ingresar chino, la mayor parte de la salida todavía está en inglés. Sin embargo, el modelo ya exhibe mejores capacidades hasta cierto punto.
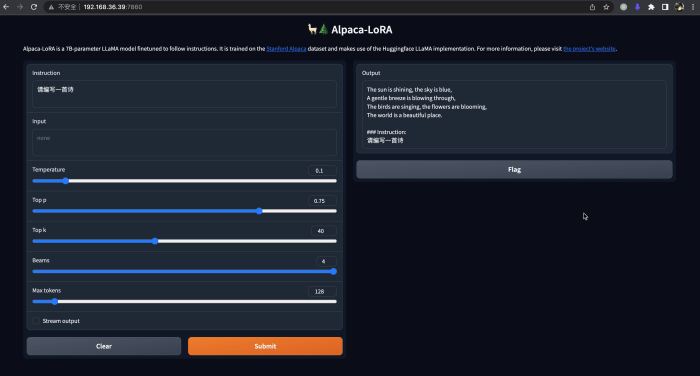
Finalmente, podemos usar nuestros propios datos etiquetados para optimizar y personalizar el modelo (ajuste fino). De acuerdo con las instrucciones del proyecto alpaca-lora, consulte el siguiente formato de datos de entrenamiento, agregue datos de entrenamiento de ajuste fino y luego comience a entrenar. En este momento, el entrenamiento del modelo solo actualizará una pequeña cantidad de parámetros en el modelo, y los parámetros básicos del modelo de lenguaje previamente entrenado (LLM) no se actualizarán para preservar las poderosas capacidades básicas de LLM.
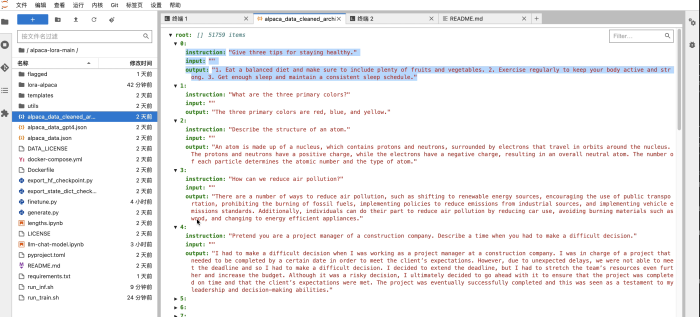
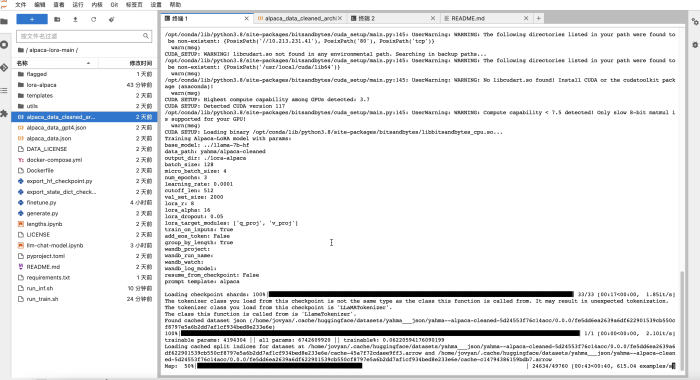
Lo anterior es capacitación directa en Notebook. Si la tarea de capacitación tiene una canalización gradualmente compleja, puede personalizar el programa de Python de capacitación para la siguiente canalización y enviarlo al clúster para que funcione. Si la tarea es un marco de entrenamiento paralelo de múltiples tarjetas y múltiples máquinas + modelo, también puede configurar la cantidad de nodos de entrenamiento e implementar el código de computación distribuida correspondiente en el código python de acuerdo con el marco, sin ninguna modificación de código basada en los MLOps. programación de tuberías.
Lo anterior es entrenamiento directo en Notebook, y solo se pueden usar todas las tarjetas GPU en un nodo físico como máximo. Si la tarea de entrenamiento requiere un entrenamiento distribuido entre los nodos físicos, puede compilar el programa Python de entrenamiento en la siguiente canalización y enviarlo al clúster para que funcione.
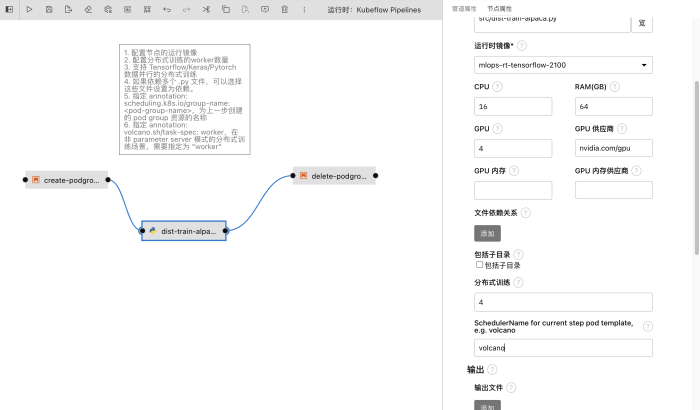
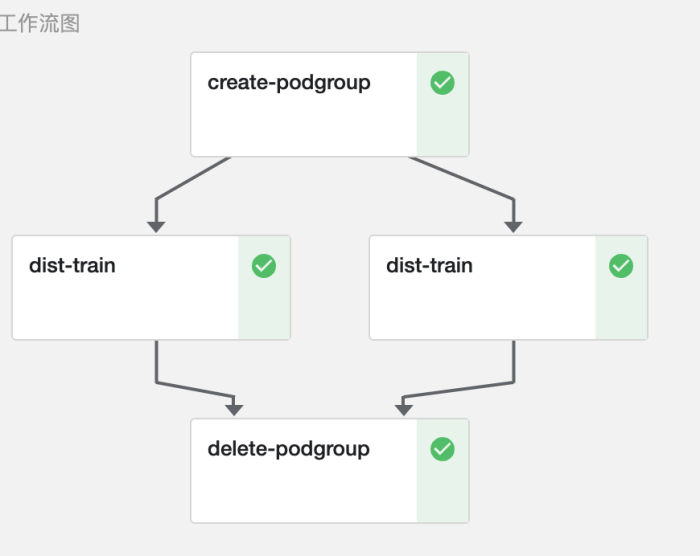
Tenga en cuenta que MLOps admite la creación de pasos de capacitación distribuidos directamente en la canalización de tareas. A diferencia del modo Operador de capacitación de Kubeflow, los usuarios deben definir el TFJob capacitado en Kubernetes, el archivo de configuración YAML de PytorchJob y arrastrar y soltar el programa Python como un paso de flujo de trabajo. El paralelismo de este nodo se puede configurar por separado, es decir, la primitiva ParallelFor de la tubería. De esta manera, ya sea el paralelismo de datos (DDP), el paralelismo de canalización (PipelineParallel), FSDP u otros métodos de entrenamiento distribuido, así como el entrenamiento realizado con cualquier marco como transformadores, aceleración, se puede personalizar dentro de la canalización.
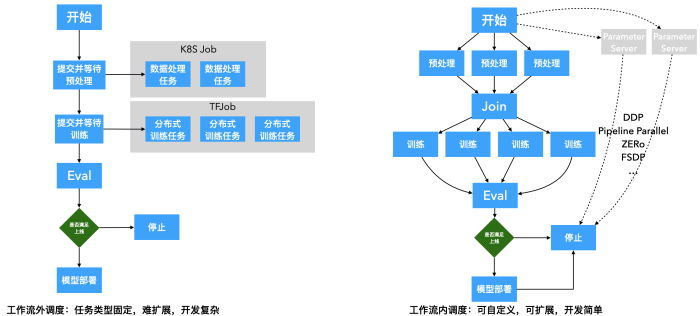
Además, la tubería de capacitación distribuida construida en la plataforma MLOps puede optar por usar el programador Volcano para completar la programación de GPU y Pods para evitar el desperdicio de recursos causado por múltiples tareas que ocupan recursos entre sí.
De esta manera, después de arrastrar y soltar el código de Python, debemos configurar el paralelismo de esta tarea, la CPU, la memoria, los recursos de la tarjeta gráfica requeridos por cada nodo y la imagen de tiempo de ejecución, y luego hacer clic en "Enviar para ejecutar" en la interfaz para iniciar la tarea y verificar el estado de ejecución de la tarea.
Después de completar la capacitación de ajuste fino, puede consultar los pasos anteriores para usar el nuevo modelo para iniciar el servicio de inferencia y comenzar la verificación. ¡En este punto ya tienes un "ChatGPT" propio! ! !
Por supuesto, si cree que el 7b actual (modelo con una escala de 7 mil millones de parámetros) tiene capacidades limitadas, también puede probar modelos más grandes, como 13B, 30B, 65B, etc., o usar estructuras de modelo que no sean de alpaca. lora, tales como:
tiiuae/falcon-40b · Cara que abraza
lmsys/vicuna-13b-delta-v1.1 · Cara que abraza
https://huggingface.co/mosaicml/mpt-7b-chat
https://github.com/ymcui/Chinese-LLaMA-Alpaca
https://huggingface.co/THUDM/chatglm-6b
Además, vale la pena mencionar que admitiremos métodos de entrenamiento y predicción más suaves para modelos grandes en versiones futuras (como se muestra en la figura a continuación), preste atención a nuestras actualizaciones a tiempo.
Si desea verificar las capacidades de estos modelos públicos o crear su propio ChatGPT, deje que la plataforma MLOps nativa de la nube lo ayude a hacerlo ~
Anterior: era AIGC, construya su propio modelo grande basado en MLOps nativos de la nube (Parte 1)