Autor de este artículo: Byte, científico jefe de Guanyuan Data. Liderar la aplicación de múltiples proyectos de IA en las 500 empresas más importantes del mundo y ganar el campeonato Hackathon en la dirección de la venta minorista inteligente en muchas ocasiones. Trabajó una vez en MicroStrategy y Alibaba Cloud, y tiene más de diez años de experiencia en la industria.
En el artículo anterior, presentamos la composición y construcción de la plataforma de aprendizaje automático nativa de la nube [1]. En las aplicaciones empresariales reales, la plataforma de aprendizaje automático depende en gran medida de la plataforma de datos subyacente de la empresa. Aunque el aumento de la IA ha sido ola tras ola en los últimos dos años, depende mucho de la infraestructura de la plataforma de datos para implementar bien la aplicación del algoritmo. También se puede ver en algunos informes de análisis [2] de a16z que las empresas de plataformas de datos han atraído mucha atención del mercado y del capital, y conceptos como la pila de datos moderna [3] han surgido a medida que los tiempos lo requieren . En este artículo, hablemos de lo que es la llamada plataforma de datos nativos en la nube.
1. Historial de desarrollo
La primera plataforma de datos provino de la tecnología de bases de datos relacionales (RDBMS). Desde el principio, comenzó con el sistema OLTP que registraba datos de operaciones comerciales y desarrolló gradualmente los requisitos relacionados para el análisis de datos de las condiciones comerciales y la toma de decisiones posteriores, que es el llamado sistema OLAP., que contiene muchas teorías clásicas y métodos técnicos.
En la década de 1980, existía un método de diseño para establecer un sistema de almacenamiento de datos (Data Warehouse) para las necesidades de análisis de datos, que se convirtió en la primera generación de sistema de "plataforma de datos". En 1992, el famoso "padre del almacén de datos" Bill Inmon publicó el libro "Construyendo el almacén de datos", que formó un conjunto de metodologías centralizadas y de arriba hacia abajo para construir almacenes de datos a nivel empresarial. Otro magnate, Ralph Kimball, publicó el libro "The Datawarehouse Toolkit" en 1996 y propuso la idea de construir un almacén de datos de nivel empresarial basado en el concepto de Data Mart de abajo hacia arriba. En la década de 1990, los libros de estos dos maestros casi se convirtieron en las obras autorizadas de lectura obligada para los profesionales, y el concepto de almacenes de datos de nivel empresarial se hizo popular gradualmente y fue ampliamente adoptado e implementado por las principales empresas junto con las aplicaciones de análisis de BI. En ese momento, todos los principales sistemas de software procedían de importantes software comerciales de código cerrado, como IBM DB2, SQL Server, Teradata, Oracle, etc.
A principios del siglo XXI, comenzó a surgir el concepto de Internet, y en términos de procesamiento y análisis de datos, también surgió el desafío de "big data" como los tiempos lo requieren. La tecnología de almacenamiento de datos tradicional ha sido difícil de hacer frente a los datos masivos en la era de Internet, las estructuras de datos que cambian rápidamente y varios requisitos de almacenamiento y procesamiento de datos semiestructurados y no estructurados. A partir de los tres artículos clásicos (MapReduce, GFS, BigTable) publicados por Google, ha surgido una pila de tecnología de sistema de datos distribuidos diferente de la tecnología de base de datos relacional tradicional. Posteriormente, esta tendencia fue impulsada por el ecosistema de código abierto de Hadoop, que ha tenido un profundo impacto en la industria durante más de diez años. Recuerdo haber asistido a varias conferencias técnicas en ese momento, y todos hablaban sobre tecnologías y conceptos como "lago de datos", NoSQL, SQL en Hadoop, etc. La mayoría de las plataformas de datos adoptadas por las empresas de Internet se basaban en el ecosistema de código abierto de Hadoop ( HDFS, Hilo, HBase, Colmena, etc.). También han aparecido en el mercado los famosos Hadoop Troika, Cloudera, Hortonworks y MapR.
Con el surgimiento de la ola de computación en la nube liderada por AWS, todos son cada vez más conscientes de varios problemas en la arquitectura del sistema Hadoop, incluido el almacenamiento y el enlace de recursos informáticos, la dificultad y el costo de operación y mantenimiento son muy altos, y no pueden soportar la transmisión de datos. procesamiento, consultas interactivas, etc. Un cambio muy grande en la era nativa de la nube es que todos tienden a reducir el costo de propiedad y operación y mantenimiento de varios sistemas, y los proveedores de la nube brindan servicios profesionales. Otra gran tendencia es la búsqueda de capacidades de "elasticidad" extremas. Por ejemplo, algunos almacenes de datos en la nube pueden incluso cobrar por la cantidad de cómputo consumida por una sola consulta. Estos requisitos son relativamente difíciles de cumplir en el ecosistema de Hadoop, por lo que el concepto de una nueva generación de plataformas de datos nativas de la nube ha surgido gradualmente, que también es el tema principal de este artículo.
2. Arquitectura de la plataforma de datos
2.1 Arquitectura clásica de almacén de datos
Desde una perspectiva tradicional, una plataforma de datos es aproximadamente igual a una plataforma de almacenamiento de datos. Por lo tanto, solo se necesitan herramientas ETL para cargar datos de varias fuentes de datos en el almacén de datos y luego usar SQL para realizar varios procesos, conversiones y crear un sistema de almacén de datos jerárquico, y luego proporcionar servicios externos a través de la interfaz SQL:
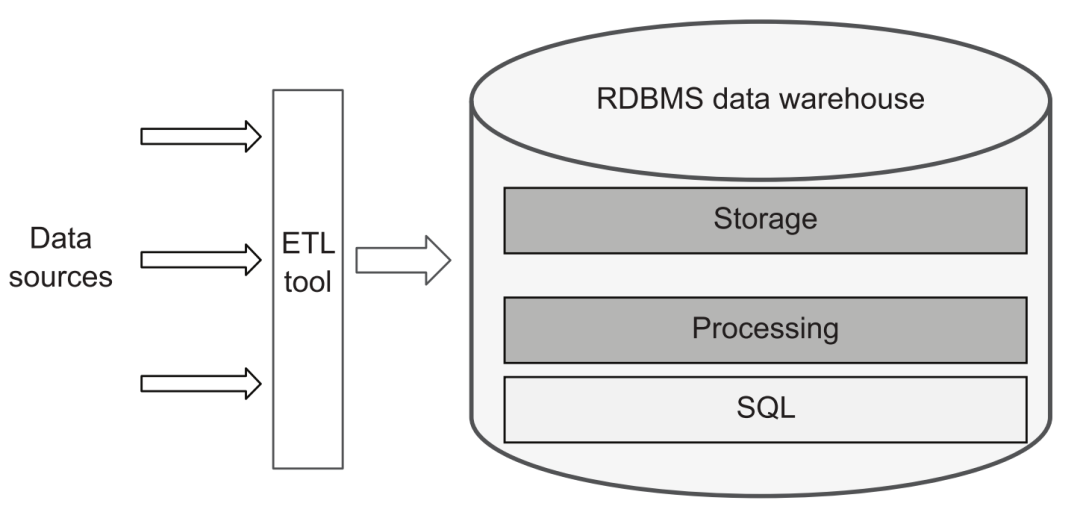
plataforma de datos tradicional
2.2 Arquitectura del lago de datos
Sin embargo, con el desarrollo de los negocios, todos gradualmente tienen más requisitos para las capacidades de la plataforma de datos, incluidos algunos de los clásicos cuatro V:
-
Variedad, la diversidad de datos. Por ejemplo, es necesario almacenar y procesar varios datos Json, Avro y ProtoBuf semiestructurados, o texto, imágenes, audio y video no estructurados. El procesamiento de estos contenidos es a menudo difícil de manejar para SQL. Además, los requisitos se han vuelto más diversos. Además del análisis de BI, los requisitos de modelado y análisis de IA, y el consumo de resultados de análisis por parte de los sistemas comerciales se han vuelto cada vez más comunes.
-
Volumen, la magnitud de los datos. Con la transformación de los negocios en línea y la digitalización, el pensamiento basado en datos es cada vez más popular, y la cantidad de datos que las empresas modernas necesitan almacenar y procesar también es cada vez mayor. Aunque el software de almacenamiento de datos comercial tradicional puede admitir la expansión horizontal, su arquitectura a menudo está vinculada con el almacenamiento y la informática, lo que genera una gran sobrecarga. Este es también un punto de diferencia muy significativo en las plataformas de datos modernas.
-
Velocidad, la velocidad de cambio de datos. En algunos escenarios de aplicación de datos, la necesidad de una toma de decisiones automatizada en tiempo real ha comenzado a surgir gradualmente. Por ejemplo, después de que un usuario navega por algunos productos, el sistema puede obtener nuevos datos de comportamiento y actualizar el contenido recomendado por el usuario en tiempo real; o tomar una decisión automática de revisión de control de riesgos basada en el comportamiento del usuario en los últimos minutos, etc. En este caso, la operación tradicional de almacenamiento de datos T+1 obviamente no puede satisfacer la demanda.
Impulsada por estos requisitos, la arquitectura de la plataforma de datos ha evolucionado hacia una estructura más compleja, y también se han comenzado a introducir muchos componentes de sistemas de big data conocidos, como Hadoop y Spark. Entre ellos, la conocida Arquitectura Lambda propuesta por el autor de Storm, Nathan Marz:
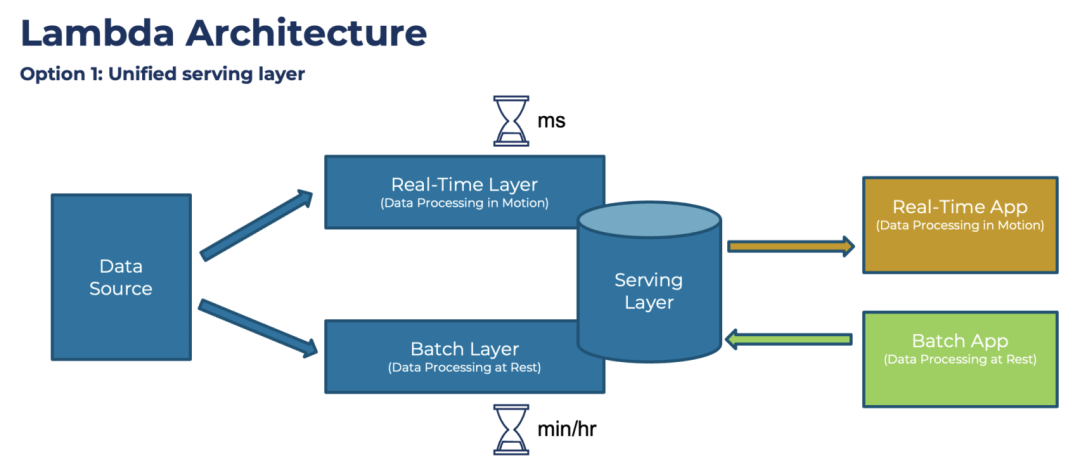
arquitectura lambda
El diseño de esta arquitectura ha sido objeto de mucha experiencia, resumen y deliberación. El núcleo es el procesamiento por lotes (Batch Layer) de la cantidad total de datos todos los días. En comparación con la conversión de datos tradicional basada en SQL, puede admitir tipos de datos más ricos. y métodos de procesamiento Al mismo tiempo, con la ayuda de la arquitectura Hadoop, también puede admitir una mayor cantidad de datos. Al mismo tiempo, para admitir los requisitos de "tiempo real”, se agrega una capa de procesamiento de transmisión (capa en tiempo real). Finalmente, cuando se consumen los datos, los dos datos se pueden combinar (capa de servicio) para formar el resultado final. Sin embargo, esta arquitectura también ha sido criticada, especialmente por la necesidad de mantener dos conjuntos de marcos informáticos, procesamiento por lotes y en tiempo real, y de implementar dos veces la misma lógica de procesamiento, lo que es insuficiente en términos de complejidad arquitectónica y costos de desarrollo y mantenimiento. Más tarde, Jay Kreps, el autor de Kafka, propuso la arquitectura Kappa, que quería unificar el procesamiento por lotes y el procesamiento en tiempo real, lo que significaba "integración flujo-lote".
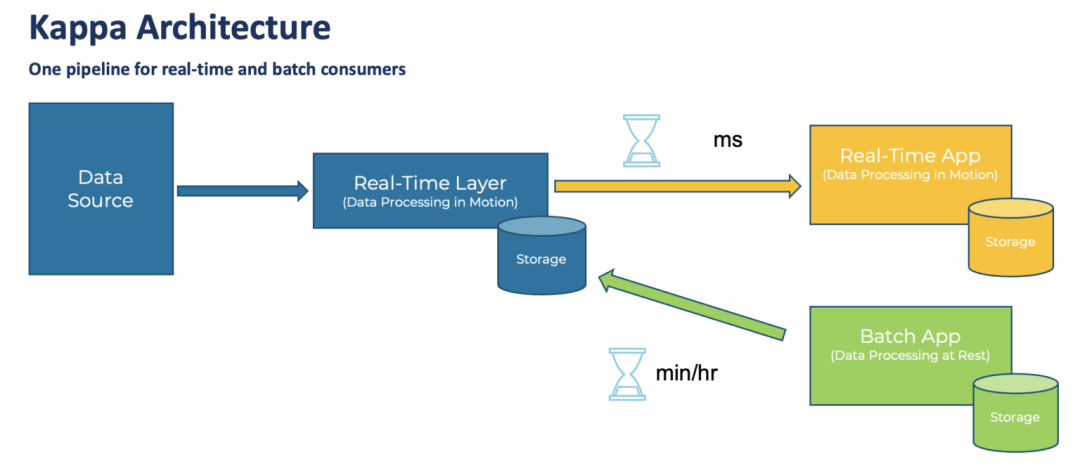
Arquitectura Kappa
Pero personalmente siento que la arquitectura Kappa es demasiado idealista Incluso para 2022, la transmisión de datos está lejos de convertirse en la corriente principal de la industria. La duplicación de datos del flujo de mensajes, la secuencia de mensajes, el soporte para cálculos complejos (como la unión en tiempo real), el soporte para varios sistemas de datos de origen, la gestión del esquema de datos, el control de costos del almacenamiento de datos, etc. aún no han alcanzado un nivel muy estable. nivel Estado útil y eficiente. Por lo tanto, no es realista dejar que los datos de una empresa se ejecuten completamente sobre la base de un sistema de transmisión de datos. Por lo tanto, la arquitectura principal de la plataforma de datos en esta etapa en realidad combina el sistema de procesamiento por lotes con el sistema de procesamiento en tiempo real en función de los requisitos comerciales y la madurez de todo el sistema de proceso.
2.3 Arquitectura nativa de la nube
Para los requisitos de combinación de varios componentes, con el advenimiento de la era nativa de la nube, han surgido cada vez más productos de datos SaaS que son más fáciles de "ensamblar y usar". En comparación con la complejidad de implementar y mantener los clústeres de Hadoop y Kafka en el pasado, la nueva generación de productos nativos de la nube generalmente puede usar directamente los servicios de alojamiento, pagar sobre la marcha y usarlos listos para usar, lo cual es muy amigable para los no usuarios. -Compañías de Internet. Por lo tanto, las arquitecturas de plataformas de datos comunes han comenzado a desarrollarse en la dirección de introducir varios componentes de productos y han surgido muchas ideas nuevas e interesantes:
-
A nivel de procesamiento de datos, se utilizan diferentes motores de cómputo para realizar tareas de procesamiento por lotes o procesamiento de flujo, pero para la interfaz de usuario se espera que sea lo más consistente posible, por lo que existe la llamada "integración flujo-lote".
-
En términos de almacenamiento y servicios de datos, el "lago de datos" y el "almacén de datos" solían estar en disputa, pero después de varios años de desarrollo, descubrieron que no podían reemplazarse por completo. Por lo tanto, el campo del lago de datos ha agregado mucho soporte para funciones como SQL, Schema y administración de datos, y se ha convertido en una nueva especie de lago. Y los almacenes de datos también se están volviendo nativos de la nube, y muchos almacenes de datos en la nube también admiten el uso de sus motores informáticos para calcular y procesar archivos directamente en el lago de datos. La "integración de Hucang" también se ha convertido en un término popular.
-
Además, existen requisitos para funciones de consulta por lotes y de un solo punto en la tienda de funciones, "HSAP" nacido de la combinación de requisitos de aplicaciones de consumo de datos y análisis en tiempo real, y así sucesivamente.
La descripción general de la arquitectura de datos unificada proporcionada por la conocida institución de inversión a16z es muy representativa:
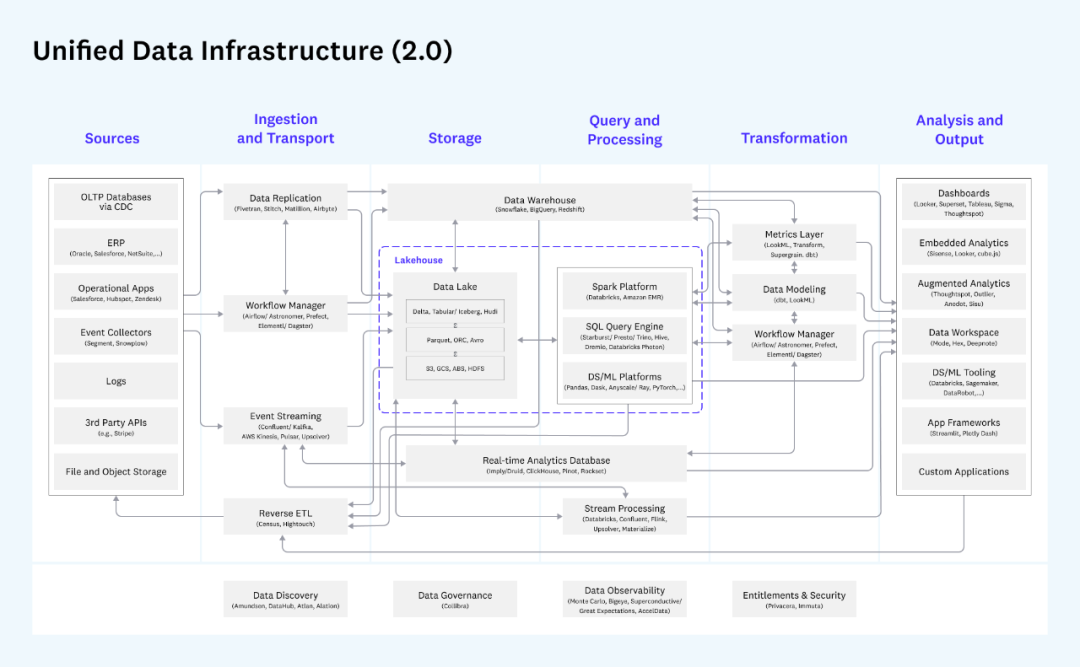
arquitectura de datos unificados de a16z
Esta imagen es muy detallada. Divide todo el proceso de transferencia de datos en fuentes de datos (generalmente no incluidas en la plataforma de datos), adquisición y transmisión de datos, almacenamiento, procesamiento de consultas, conversión de datos y salida de análisis. Cada bloque Cada módulo y los productos relacionados son marcado en detalle. Por lo general, las empresas seleccionarán algunos de los componentes para su implementación de acuerdo con sus necesidades.Por ejemplo, si no hay demanda de transmisión de datos, entonces no se necesita la siguiente parte del acceso y procesamiento de datos de transmisión. A diferencia de la arquitectura Lambda, para el mismo escenario comercial, generalmente no es necesario dejar que el mismo dato pase por el enlace de procesamiento en tiempo real y el enlace de procesamiento por lotes dos veces en T+1, pero elija el adecuado. puede ser utilizado para el procesamiento posterior.
Sin embargo, el diagrama de arquitectura mencionado anteriormente es demasiado complicado porque tiene en cuenta las necesidades de diferentes empresas en diferentes escenarios y en diferentes etapas. Personalmente, prefiero una descripción general de la arquitectura relativamente simplificada proporcionada por el autor en el libro "Diseño de datos en la nube". Plataforma":
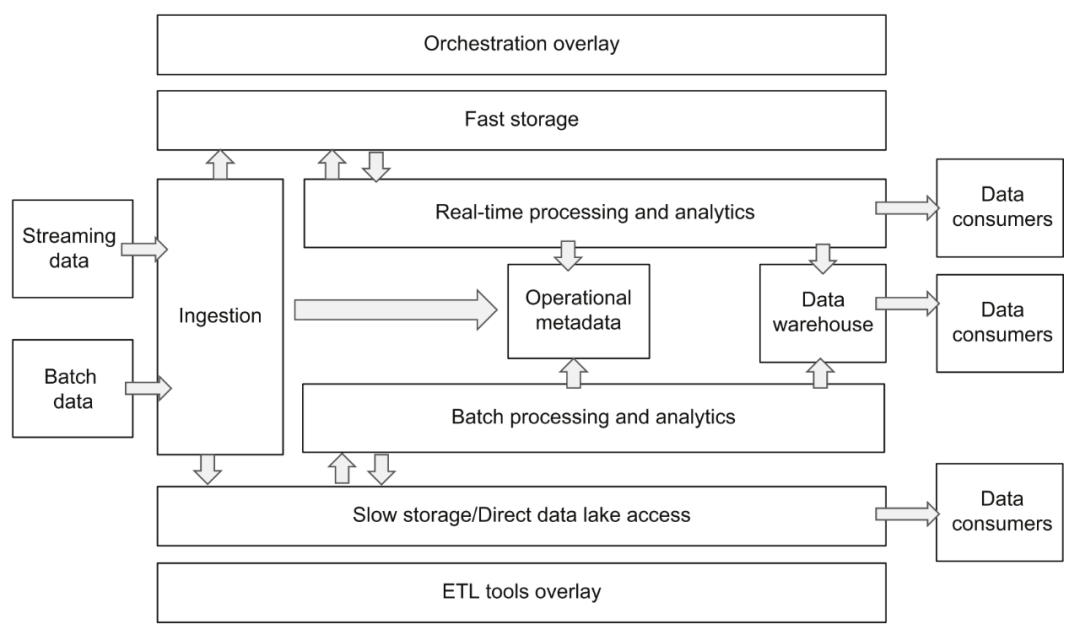
Arquitectura de plataforma de datos en la nube
El núcleo de esta arquitectura es básicamente el mismo que el de la arquitectura de referencia proporcionada por a16z, pero el diseño dividido de cada capa es más claro, lo que nos ayuda a comprender y planificar toda la plataforma de datos. Si las responsabilidades y las interfaces entre cada capa pueden definirse claramente, será muy beneficioso para la estandarización del flujo de datos y el reemplazo y actualización flexibles de la implementación de componentes. Más adelante, ampliaremos y describiremos los diversos componentes de la plataforma de datos en la nube en función de estos dos diagramas.
En términos generales, la tendencia de evolución de la arquitectura de la plataforma de datos en los últimos años tiene principalmente dos aspectos. Uno es satisfacer las diversas necesidades comerciales. Los componentes generales del sistema de la plataforma son cada vez más, lo que se encuentra en una etapa altamente diferenciada. El usuario permanece transparente, la segunda es que la selección de componentes tiende a elegir productos de varios proveedores de nube pública o proveedores de plataformas SaaS de datos. En el caso de una arquitectura compleja, el costo de mantenimiento no aumenta demasiado, pero las responsabilidades entre los componentes son claras. (acoplamiento flexible) y la estandarización de la interfaz siguen siendo un desafío.
3. Adquisición de datos
En términos de adquisición de datos, la plataforma debe ser capaz de admitir datos por lotes y acceso a datos de transmisión.
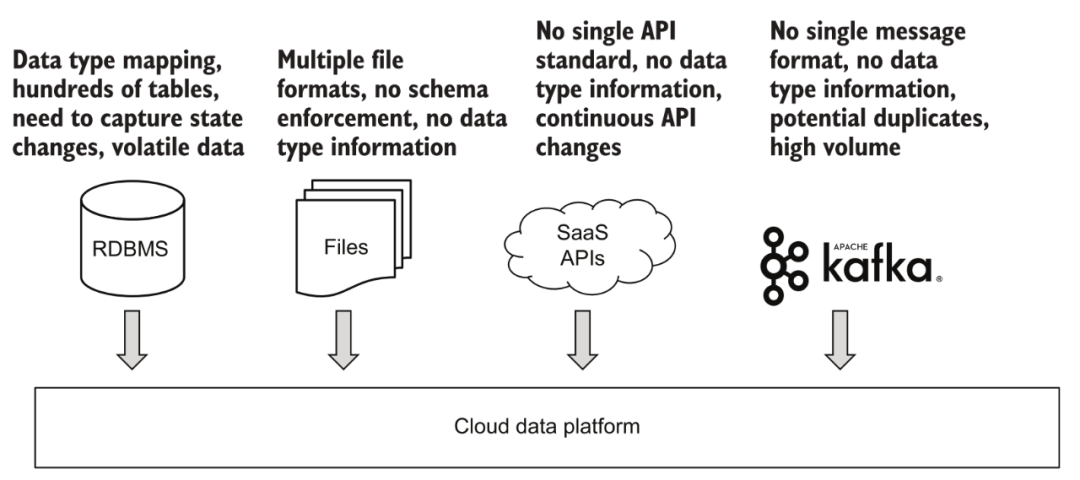
Acceso a varios datos
3.1 Adquisición por lotes
Para datos por lotes, como varios archivos cargados, ftp u otras fuentes de datos de API de terceros que no pueden admitir el consumo en tiempo real. De hecho, las diversas fuentes de datos actualmente conectadas por la mayoría de las empresas y la estructura básica de datos dentro de la empresa son básicamente en forma de procesamiento por lotes. La gran mayoría de las plataformas soportan bastante bien esta área. Un enfoque típico consiste en desencadenar tareas a intervalos regulares, obtener contenido de datos actualizado de forma incremental o completa de fuentes de datos a través de componentes y almacenarlos en la plataforma de datos. Si la configuración del activador de esta tarea se establece con más frecuencia, también podemos obtener un contenido de datos actualizado "casi en tiempo real" a través del procesamiento por lotes para su posterior análisis y uso.
3.2 Adquisición de transmisión
La transmisión de datos es una tendencia muy popular en los últimos años, pero tiene relativamente pocas aplicaciones fuera de las empresas de Internet. La comprensión de todos del "tiempo real" también es diferente. Por ejemplo, para escenarios de análisis, generalmente se reconoce que la actualización de datos de T+1 (el día siguiente ve la situación hasta el día anterior) pertenece al procesamiento por lotes, siempre que haya múltiples actualizaciones de datos en un día, pertenece a los Análisis "en tiempo real". Este tipo de demanda se puede realizar completamente a través de la actualización de lotes pequeños mencionada anteriormente. Para algunos escenarios de toma de decisiones automática, como los sistemas de recomendación y el control de riesgos de transacciones, incluso si se logran actualizaciones de "lotes pequeños" al minuto, la puntualidad no cumple con los requisitos y se debe conectar un sistema de transmisión de datos.
Un escenario más interesante es conectarse a los datos de la base de datos del sistema empresarial ascendente. Si se utiliza el acceso por lotes, el enfoque general es consultar regularmente las tablas de datos relacionadas a través de una marca de tiempo de actualización y luego guardar los datos incrementales en la plataforma de datos. Este método parece no ser un problema, pero de hecho, si la entrada de datos original se ha cambiado varias veces durante la ventana de tiempo de actualización, por ejemplo, el usuario primero abrió la membresía dentro de los 5 minutos y luego la canceló, a través de una consulta por lotes. puede ser posible Después de las dos consultas, el usuario está en el estado de no miembro, y la información de cambio de estado intermedio se pierde. Es por eso que cada vez más escenarios ahora usan la tecnología CDC para capturar cambios en tiempo real en los datos comerciales y conectarse a la plataforma de datos a través de la transmisión de datos para evitar cualquier pérdida de información.
La ruta de construcción sugerida para este bloque es construir primero una capacidad estable de acceso a datos por lotes, luego obtener datos de transmisión y, finalmente, considerar el procesamiento y análisis de datos de transmisión (introduciendo Flink y similares) en función de las necesidades reales.
3.3 Demanda y Productos
Para los componentes de adquisición de datos, se deben cumplir los siguientes requisitos:
-
La arquitectura del complemento admite el acceso a datos desde múltiples fuentes de datos, como diferentes bases de datos, archivos, API, fuentes de datos de transmisión, etc., y admite configuraciones personalizadas flexibles.
-
La operatividad, porque necesita lidiar con varios sistemas de terceros, el registro de información diversa y la conveniencia de solucionar problemas cuando ocurren errores son muy importantes.
-
Rendimiento y estabilidad, para hacer frente a la gran cantidad de datos y el funcionamiento estable de importantes procesos de análisis y toma de decisiones, se requiere una garantía de calidad de plataforma de nivel empresarial.
También hay muchos productos que se pueden considerar para la adquisición de datos:
-
Servicios relacionados de las tres nubes principales, como AWS Glue, Google Cloud Data Fusion, Azure Data Factory para procesamiento por lotes, AWS Kinesis, Google Cloud Pub/Sub, Azure Event Hubs para transmisión de datos, etc.
-
Servicios SaaS de terceros, como Fivetran, Stitch, Matillion, Airbyte, etc. mencionados por a16z.
-
Frameworks de código abierto como Apache NiFi, Kafka, Pulsar, Debezium (herramienta CDC), etc.
-
Basado en el servicio Serverless, la función de adquisición de datos se desarrolla por sí misma.
Tenga en cuenta que cuando se trata de servicios en la nube, servicios SaaS de terceros, código abierto o selección de herramientas de desarrollo propio, puede consultar la siguiente figura para la evaluación de compensación. Cuanto más se acerque a los productos del extremo derecho, como los proveedores de la nube, se requiere menos inversión en operación, mantenimiento y desarrollo, pero la capacidad de control y la portabilidad son relativamente débiles (a menos que sean compatibles con la API estándar del marco de código abierto); más a la izquierda es lo contrario, el uso de productos de código abierto tiene una personalización muy flexible (pero se debe prestar atención al control de la modificación mágica de las sucursales privadas) y flexibilidad de implementación, pero el costo de I + D y operación y mantenimiento será mucho más alto.
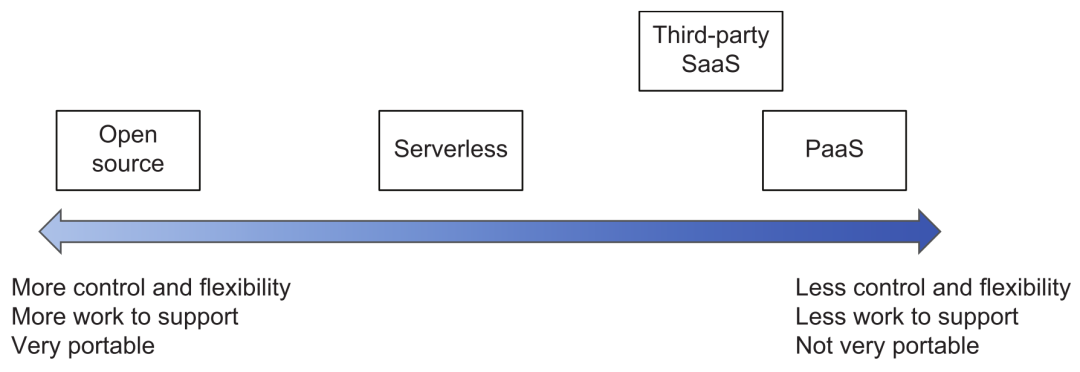
Compensaciones de selección de productos
4. Almacenamiento de datos
Después de la adquisición de datos, los datos deben guardarse en el almacenamiento de la plataforma. En el diagrama de arquitectura de la plataforma de datos anterior, vemos que el autor divide el almacenamiento en dos partes: rápido y lento:
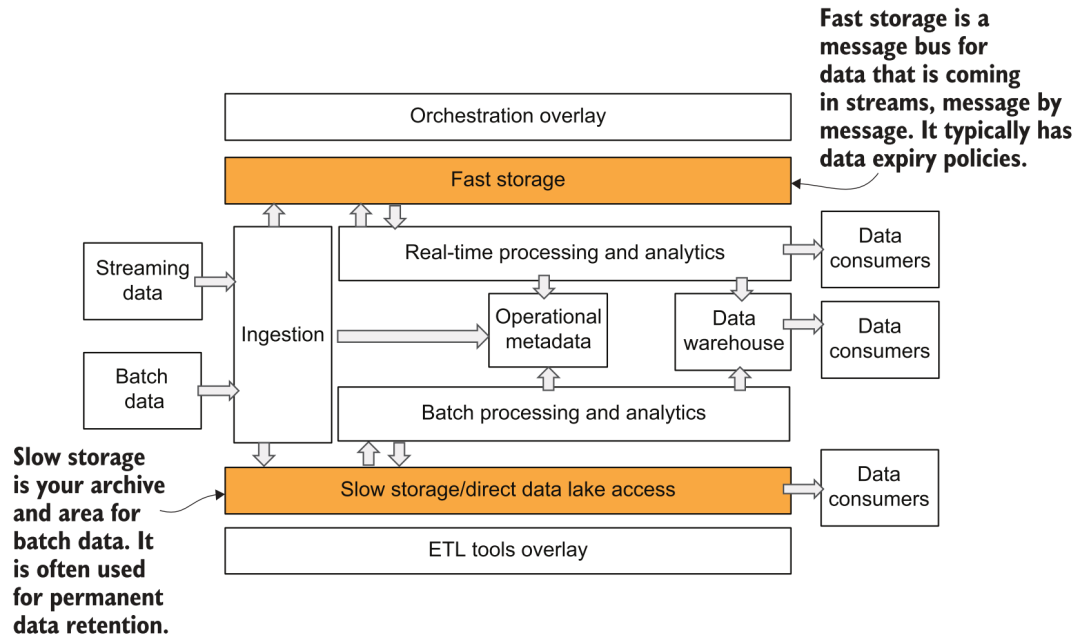
Almacenamiento rápido y lento
4.1 Almacenamiento lento
Este almacenamiento lento es relativamente fácil de entender. En la era de los almacenes de datos, es la parte de almacenamiento del sistema de almacén. En la era de los grandes datos, es el llamado lago de datos. Los sistemas de archivos distribuidos como HDFS eran más popular antes, y ahora se utilizan cada vez más el almacenamiento y el cálculo.Desarrollándose en la dirección de la separación, los métodos de almacenamiento principales básicamente eligen varios objetos de almacenamiento, como S3, GCS, ABS, etc. La forma de almacenamiento del lago de datos es relativamente gratuita y, a menudo, es difícil garantizar la calidad de los datos y la gestión y el control empresarial. Por lo tanto, en los últimos dos años, Databricks ha propuesto el concepto de lago, en el que se almacenan los metadatos y el almacenamiento correspondientes. construido sobre el almacenamiento de objetos subyacente. El protocolo de almacenamiento puede admitir la gestión de esquemas, la versión de datos, el soporte de transacciones y otras características, que también hemos presentado en el artículo Sistema de lago de datos en la plataforma de algoritmos [4].
4.2 Almacenamiento rápido
Este almacenamiento rápido puede ser más fácil de malinterpretar. En el diagrama de la arquitectura Lambda y la arquitectura a16z, el almacenamiento rápido generalmente se refiere a un sistema de almacenamiento que brinda servicios de análisis en tiempo real y consultas ad hoc para los consumidores de datos. Por ejemplo, podemos usar algunas bases de datos analíticas con un alto rendimiento en tiempo real (Presto, ClickHouse), o para servicios de almacenamiento específicos como sistema KV, RDBMS, etc. En la imagen proporcionada por el autor, el almacenamiento rápido en realidad representa un significado más simple, que es el almacenamiento integrado del sistema de transmisión de datos, como Kafka y la parte del sistema Pulsar que almacena mensajes de eventos. ¿Se siente como volver a la antigua forma de vincular la informática y el almacenamiento? Así que ahora tanto Kafka como Pulsar han comenzado a admitir el almacenamiento en niveles [5], lo que mejora la escalabilidad general y reduce los costos.
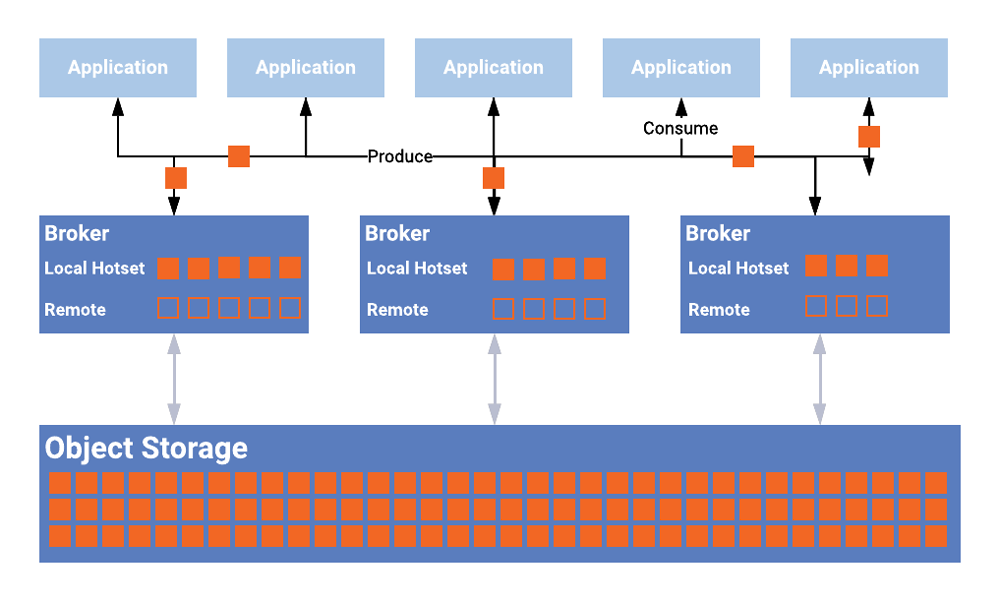
Almacenamiento en niveles
4.3 Proceso de acceso a datos
Los datos ingresados desde la capa de acceso a datos generalmente se almacenan directamente en el almacenamiento lento en forma de datos sin procesar y luego se convierten en la forma que debe usarse más adelante a través de otro procesamiento y programación, como la tabla en la casa del lago o el almacén de datos que proporciona servicios externos intermedios. Una vez que los datos de transmisión ingresan al almacenamiento rápido, el componente de análisis y procesamiento en tiempo real adquirirá y consumirá los datos y, finalmente, activará la actualización de datos descendentes. Al mismo tiempo, la transmisión de datos generalmente guarda una copia de los datos originales para ralentizar el almacenamiento sincrónicamente a través de un flujo de procesamiento en tiempo real, de modo que las operaciones de procesamiento flexibles posteriores se puedan realizar para otros requisitos de uso. Los mensajes en el almacenamiento rápido que viene con el sistema en tiempo real generalmente solo se conservan durante un período de tiempo para evitar altos costos de almacenamiento. Aquí se puede ver que el almacenamiento lento básicamente necesita almacenar la cantidad total de datos, y su sobrecarga será muy alta, razón por la cual la corriente principal generalmente elige sistemas de almacenamiento de objetos baratos y fáciles de expandir.
4.4 Demanda y Productos
Para los componentes de almacenamiento, algunos requisitos de características importantes incluyen:
-
Alta confiabilidad, la pérdida de datos es definitivamente la más inaceptable. Generalmente, solo C en CAP es una característica que no se puede comprometer.
-
La escalabilidad requiere la capacidad de expandir y contraer fácilmente el espacio de almacenamiento.
-
Para el rendimiento, el almacenamiento lento debe tener un rendimiento relativamente bueno para respaldar la adquisición simultánea de grandes cantidades de datos por parte de los consumidores. Y el almacenamiento rápido debe tener una muy buena velocidad de respuesta de lectura y escritura para pequeños volúmenes de datos.
En términos de productos de almacenamiento, los servicios de los proveedores de la nube deberían ser la opción principal.Después de todo, es demasiado complicado construir y mantener clústeres de almacenamiento por sí mismo. También hay algunos proyectos de código abierto basados en el almacenamiento de objetos de estos proveedores de la nube que han agregado algunas funciones adicionales (como compatibilidad con POSIX) y optimización, como lakeFS [6], JuiceFS [7] y SeaseedFS [8], etc. (los dos últimos son proyectos chinos).
5. Tratamiento de datos
El procesamiento de datos es más complejo en toda la plataforma, y también es una parte donde varios géneros compiten ferozmente. El enfoque más típico es utilizar dos conjuntos de motores informáticos para admitir el procesamiento por lotes y el procesamiento de flujo, respectivamente, lo que es consistente con la parte de adquisición de datos. La ventaja de esto es que se puede seleccionar la tecnología más adecuada para el escenario comercial y se pueden utilizar mejor las fortalezas del propio marco. La mayoría de las empresas se basan principalmente en requisitos de procesamiento por lotes, por lo que no es necesario introducir un motor de procesamiento continuo al principio.
5.1 Procesamiento por lotes
El marco más popular para el procesamiento por lotes es Apache Spark. Como un proyecto de código abierto anticuado, la comunidad está activa, la etapa de desarrollo es relativamente madura y las funciones son muy completas y poderosas. Además del procesamiento de datos estructurado típico, también puede admitir datos no estructurados, datos gráficos, etc. Si se basa en datos estructurados, entonces el antiguo Hive y los recién llegados, como Presto y Dremio, también son muy buenas opciones para los motores informáticos SQL. Al realizar el procesamiento por lotes de datos masivos, también intervienen muchos métodos de optimización, como la selección de varios métodos de combinación, el ajuste del paralelismo de tareas y el procesamiento de datos sesgados, etc., que no se detallarán aquí.
5.2 Procesamiento de flujo
En términos de procesamiento de transmisión, el más escuchado en China debe ser Apache Flink. Además, al igual que Spark Streaming, Kafka Streams también proporciona capacidades de procesamiento de flujo correspondientes. Para algunas lógicas de cálculo complejas, el umbral de desarrollo para la computación de flujos sigue siendo bastante alto y muchos requisitos se pueden cumplir sin cálculos complejos en el procesamiento de flujos. Por ejemplo, podemos simplemente procesar los datos y escribirlos en bases de datos analíticas en tiempo real, como ClickHouse, Pinot, Rockset o sistemas como ElasticSearch, almacenamiento KV y base de datos en memoria, que también pueden proporcionar una gran part of streaming computing Se cumplen los requisitos y presentaremos los ejemplos correspondientes más adelante. El procesamiento de secuencias, al igual que el procesamiento por lotes, requiere varias optimizaciones de rendimiento y escalabilidad, como la especificación de la lógica de partición, la resolución de sesgos de datos y el ajuste de puntos de control.
5.3 Integración por lotes de flujo
En los últimos años, el concepto de integración de transmisión por lotes se ha vuelto popular, especialmente en la comunidad de Flink, que cree que el procesamiento por lotes es solo una forma especial de procesamiento de transmisión, que se puede completar utilizando un marco unificado. Esto es casi lo mismo que la arquitectura Kappa mencionada anteriormente. Por supuesto, también hay intentos de unificación a nivel de software, como Apache Beam, que puede usar el mismo DSL para el desarrollo y luego cambiar a Spark o Flink para el procesamiento por lotes y el procesamiento de flujo cuando se ejecuta la ejecución subyacente.
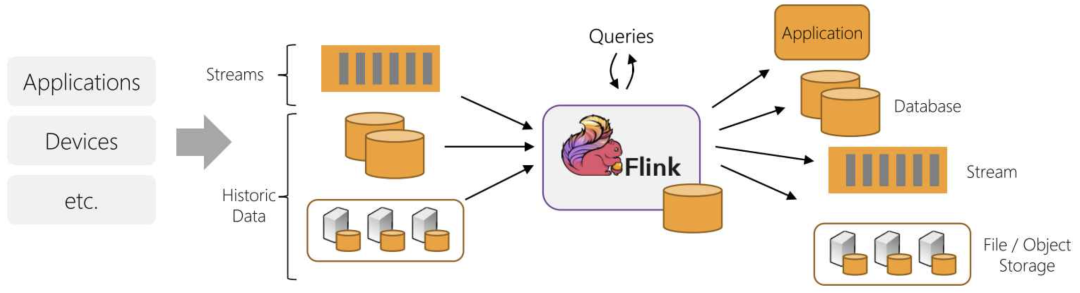
Integración por lotes y streaming de Flink
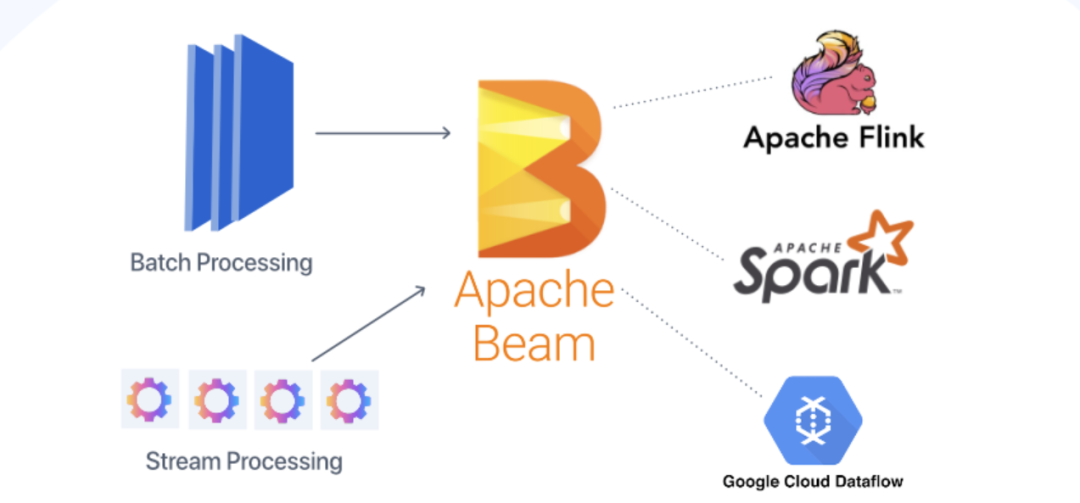
Integración por lotes y streaming de Beam
5.4 Demanda y Productos
Para los componentes de procesamiento de datos, los requisitos que deben cumplirse son:
-
La capacidad de expansión horizontal de la informática puede utilizar múltiples nodos para calcular grandes cantidades de datos.
-
Estabilidad y disponibilidad, capacidades de conmutación por error/recuperación de múltiples nodos.
-
Compatibilidad flexible y abierta con API/SDK/DSL, como SQL o varios lenguajes de programación principales para desarrollar la lógica de procesamiento.
Productos de procesamiento por lotes Además de los diversos marcos de código abierto mencionados anteriormente, los proveedores de la nube también brindan varios servicios administrados, incluidos los conocidos AWS EMR, Google Dataproc o Cloud Dataflow (basado en Beam), Azure Databricks, etc.
Los productos de procesamiento de transmisiones incluyen AWS Kinesis Data Analytics, Google Cloud Dataflow y Azure Stream Analytics proporcionados por proveedores de la nube. Además, hay algunos proveedores de SaaS conocidos, incluida la empresa "oficial" de Kafka, Confluent [9], Upsolver [10], Materialise [11], etc.
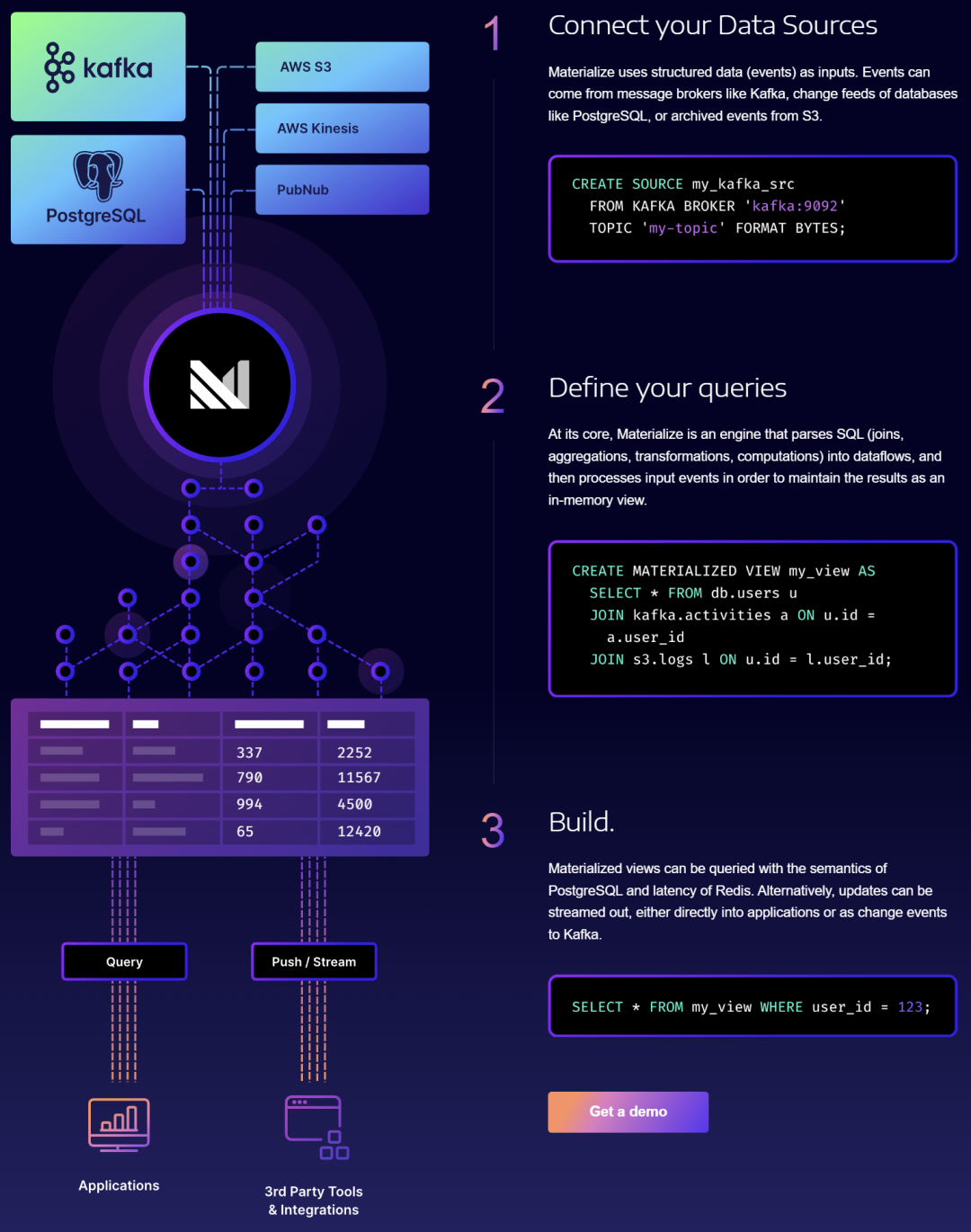
Empresa de procesamiento de datos de transmisión Materialise
6. Metadatos
Después de años de aplicación industrial y pulido de productos, el RDBMS tradicional está relativamente completo en términos de metadatos. Sin embargo, debido a que la plataforma de datos en la nube aún no se ha popularizado, a menudo se pasa por alto fácilmente en el proceso de construcción interno de cada empresa. Esta parte de la capacidad es en realidad una parte crucial de un producto maduro de nivel empresarial.
6.1 Metadatos de la plataforma
Durante el funcionamiento de la plataforma, se generará diversa información, como varias fuentes de datos configuradas, ejecución de adquisición de datos, ejecución de procesamiento de datos, esquema, información estadística, relación sanguínea de conjuntos de datos, uso de recursos del sistema, diversa información de registro y más. A través de esta información, podemos monitorear y alertar varias tareas de la plataforma, y cuando ocurren problemas, también podemos solucionarlos y tratarlos convenientemente al ver esta información, en lugar de iniciar sesión en la consola de administración de cada módulo para verificar uno por uno.
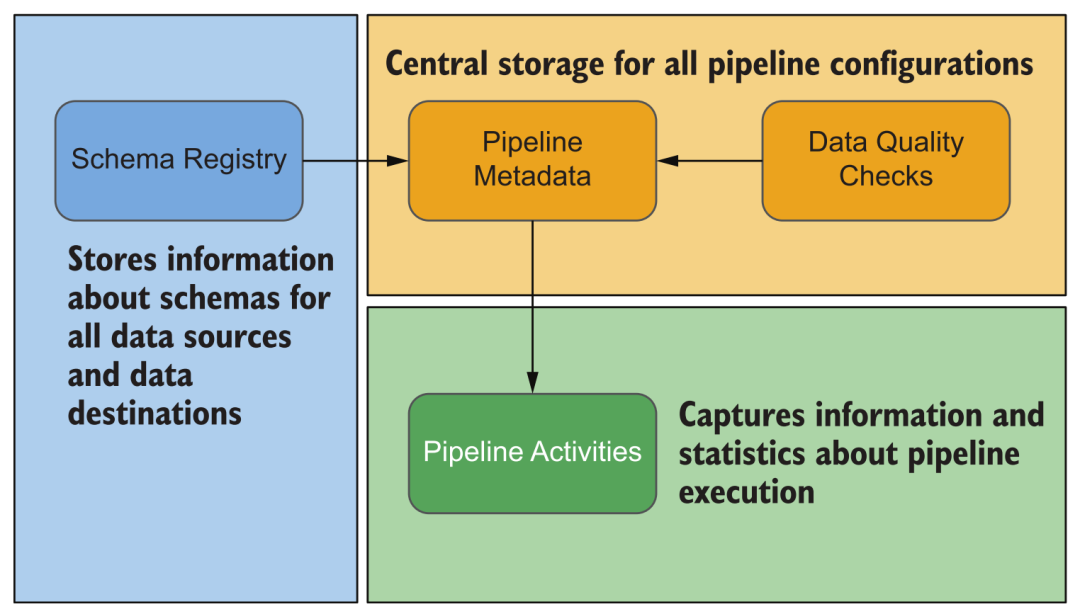
Tipo de metadatos de la plataforma
El esquema es un gran tema. En comparación con el sistema de almacenamiento de datos basado en tecnología de base de datos relacional, la plataforma de datos en la nube tiene ciertas ventajas en el manejo flexible de cambios en el esquema del conjunto de datos. Cuando la mayoría de los almacenes de datos en la nube se ocupan de los cambios de esquema, sus servicios se verán afectados en cierta medida (por ejemplo, se requieren bloqueos de tablas). Y muchos lagos pueden admitir mejor la evolución del esquema, como la opción mergeSchema en Delta. Por supuesto, esta función no es omnipotente En toda la plataforma de datos, implica el procesamiento y la transformación de varios datos, la interacción de varios enlaces, sistemas posteriores como almacenes de datos, análisis en tiempo real de escritura de bases de datos y consumo de otros El esquema debe estar estrictamente documentado y gestionado.
Registro de esquemas en metadatos
Otra categoría de metadatos muy importante es la calidad de los datos. Con el avance de la digitalización empresarial, cada vez hay más fuentes de datos involucradas, y varios procesamientos y transformaciones de datos internos se vuelven cada vez más complejos, y varias decisiones empresariales dependen cada vez más del contenido de los datos y los resultados del análisis correspondiente. todavía puede garantizar la calidad de los "productos de datos" y la eficiencia general de la operación iterativa y el mantenimiento durante todo el proceso de creciente complejidad se ha convertido en un tema muy crítico. Tales demandas han promovido el surgimiento del llamado movimiento DataOps, aprovechando la experiencia de cómo mantener el desarrollo empresarial, la entrega, la operación y el mantenimiento de software complejo en DevOps, y aplicándolo al campo de los productos de datos.
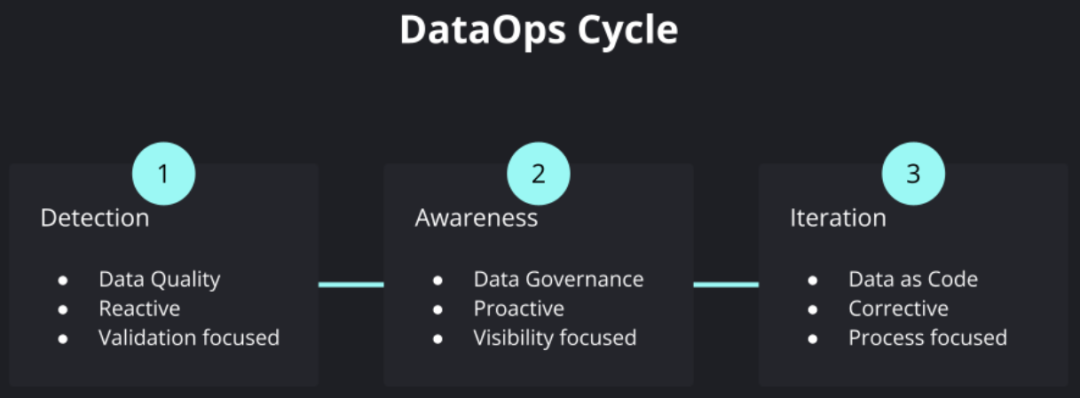
Ciclo de operaciones de datos
Una parte muy importante de esto es el monitoreo y las pruebas continuas de la inspección de la calidad de los datos, que se aplica al flujo de datos CI/CD, así como al control de datos, descubrimiento de datos y otros enlaces. Esto también ha dado lugar a una nueva clase de productos llamada "Observabilidad de datos", que expresa muy vívidamente el objetivo de conocer el estado general de salud de los datos en la plataforma de datos.
6.2 Metadatos comerciales
Además de los metadatos a nivel técnico, también existen requisitos relacionados con la gestión y el uso de metadatos en las empresas. Por ejemplo, cuando hay más conjuntos de datos en la plataforma, la gestión y la búsqueda serán más complicadas, y la estructura básica de carpetas puede no satisfacer las necesidades. Por lo tanto, necesitamos admitir funciones como la descripción, el etiquetado y la búsqueda de conjuntos de datos. para ayudar a los usuarios comerciales a encontrarlos más rápidamente Información de datos comerciales adecuada. Los productos llamados Data Discovery y Data Catalog generalmente están diseñados para satisfacer tales necesidades.
Además, dependiendo del negocio de la empresa, también es necesario seguir los requisitos de cumplimiento de datos correspondientes, como la protección de la privacidad de la información personal, el apoyo a varios derechos y libertades de datos de los usuarios, etc. Las capacidades en esta área también requieren gestión de metadatos dedicada y soporte de gobierno de datos. Las empresas típicas son Collibra, etc.
6.3 Demanda y Productos
Para los componentes de metadatos, los requisitos convencionales aún deben garantizar una alta disponibilidad y escalabilidad.Cuando la escala de la plataforma es grande, la escala de los metadatos también será muy considerable. Otra cosa importante es la flexibilidad y la escalabilidad, como admitir contenido de metadatos definidos por el usuario y proporcionar servicios externos a través de API abiertas. En módulos como el procesamiento de datos, la orquestación y ejecución de procesos y el posterior consumo de datos, es necesario tratar todo tipo de metadatos, por lo que un servicio de metadatos bien diseñado ha llamado cada vez más la atención.
Este campo es relativamente nuevo y es posible que los productos proporcionados por los proveedores de la nube no satisfagan todas las necesidades, como AWS Glue Data Catalog, Google Data Catalog y Azure Data Catalog.
También hay algunos proveedores de código abierto que brindan servicios relacionados, y hay relativamente pocos metadatos de plataforma, el más representativo es Márquez [12]. En el nivel de metadatos comerciales o más completo, están Apache Atlas [13], Amundsen [14], DataHub [15], Atlan [16], Alation [17], etc.
Introducción a la función Atlan
Para la observación de datos, también hay muchas herramientas y productos de código abierto con los que estamos familiarizados, como Deequ basado en Spark de código abierto de AWS [ 18], "Pengci" Dickens' Great Expectations [19], Monte Carlo [20], BigEye [21] espera.
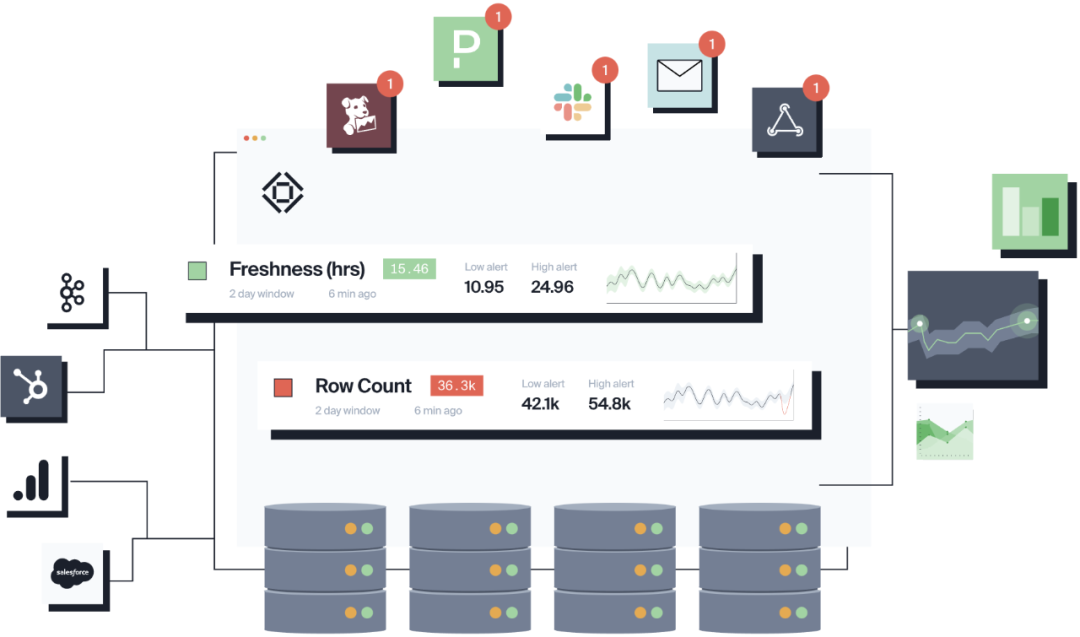
ojo grande
7. Consumo de datos
En comparación con la era del almacén de datos, los servicios externos proporcionados por la plataforma de datos también son mucho más ricos. Además de las aplicaciones típicas de análisis de datos, también han comenzado a surgir aplicaciones de consumo de datos de transmisión, ciencia de datos y aprendizaje automático. Con el fin de satisfacer diferentes necesidades, la plataforma de datos en la nube puede introducir o conectar varios sistemas de datos especiales bajo la idea de diseño de acoplamiento flexible y componentes, y expandir de manera flexible sus capacidades de servicio.
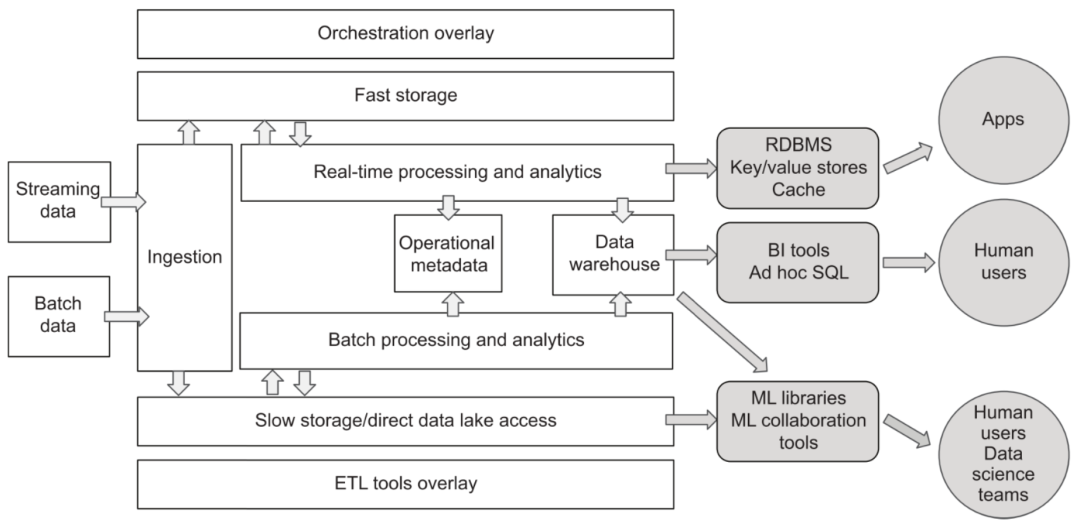
Diversas necesidades de consumo de datos.
7.1 Consulta de análisis
Para los requisitos de análisis de datos de BI, la mayoría de las aplicaciones utilizan SQL para consultar y obtener datos. Debido al aumento de las necesidades de análisis de datos de autoservicio, la flexibilidad de las consultas, la puntualidad de las interacciones (que generalmente requieren respuestas de subsegundo a segundo nivel) y los crecientes requisitos para procesar grandes cantidades de datos, consultas tradicionales de Hive, Spark Debido al problema del tiempo de respuesta, muchas veces es incapaz de atender la demanda. En este contexto, hay muchas soluciones correspondientes:
-
Almacenes de datos en la nube, como BigQuery, Redshift, Azure Synapse de los tres proveedores principales o Snowflake de un tercero. En el caso de los requisitos de procesamiento de datos estructurados, incluso es posible utilizar directamente estos sistemas como núcleo para reemplazar los almacenes de datos tradicionales para construir la plataforma de datos completa.
-
Lakehouse, como el motor informático comercial Photon de Spark, o tecnologías como Presto y Dremio, realizan un procesamiento de consultas eficiente basado en formatos abiertos (Delta, Hudi, Iceberg) en algunos lagos de datos.
-
Bases de datos de análisis en tiempo real de código abierto, como ClickHouse mencionado anteriormente, y varios proyectos emergentes como Apache Doris [22], Databend [23], etc.
7.2 Ciencia de datos
En el campo de la ciencia de datos y el aprendizaje automático, la ecología más importante se construye en base a Python. Su modo de operación típico obtendrá directamente una gran cantidad de datos de la capa de almacenamiento de datos a través de cuadernos, scripts de Python, etc. para un procesamiento y uso unificados. El entrenamiento posterior del modelo, etc., rara vez necesita ejecutar consultas complejas a través de SQL. En este caso, si puede acceder directamente a los archivos originales en almacenamiento lento, entonces el costo general es, naturalmente, el más bajo. Por supuesto, también hay desventajas al hacerlo, como que el control de datos, los permisos, etc. serán difíciles de garantizar.
Además, si considera todo el proceso de desarrollo, implementación y monitoreo del aprendizaje automático, se presentará otro gran conjunto de requisitos relacionados con MLOps.Entre ellos, los requisitos para los datos involucran el almacén de características y la diferencia entre lote y modos de solicitud de características en tiempo real. , que también corresponde a los requisitos de adquisición por lotes y consulta de un solo punto en la plataforma de datos que discutimos, y si los componentes de implementación se pueden reutilizar se puede considerar durante la construcción.
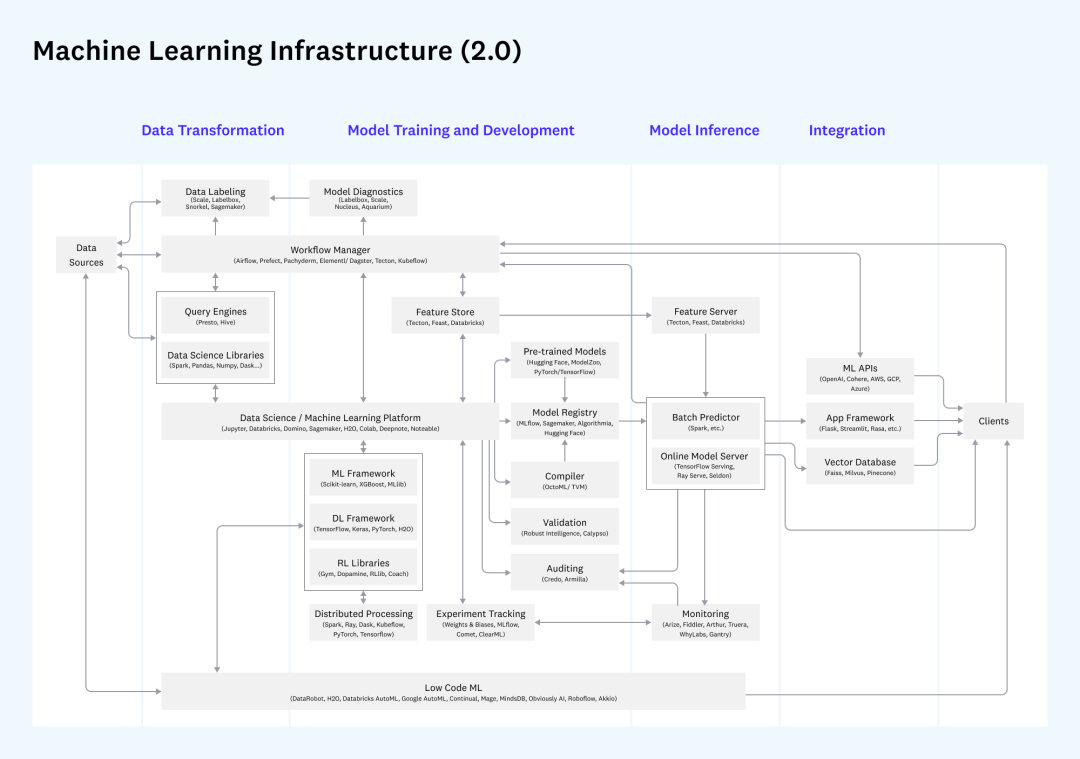
Infraestructura relacionada con el aprendizaje automático
Para discusiones relacionadas con MLOps, también puede consultar mi introducción anterior a MLOps [24].
7.3 Consumo en tiempo real
Finalmente, para los resultados del procesamiento y análisis de flujos, también habrá aplicaciones correspondientes para el consumo en tiempo real. Puede proporcionar servicios externos mediante inserción de resultados en tiempo real, escritura en una base de datos relacional, almacenamiento KV, sistema de caché (como Redis) y sistema de búsqueda (como ElasticSearch). Muchos sistemas de procesamiento de flujo, como Flink, también admiten consultas en tiempo real, y se pueden desarrollar API específicas para proporcionar resultados de datos directamente desde el sistema de flujo.
7.4 Permisos y Seguridad
En las aplicaciones de nivel empresarial, el control de los permisos de los usuarios, la auditoría y el monitoreo de varios registros de operaciones, incluida la desensibilización de datos, el cifrado, etc., son muy importantes. Además del soporte de la plataforma en sí, también podemos considerar el uso de varios servicios en la nube relacionados, como Azure Active Directory, servicios de autenticación de identidad como Auth0
7.5 Productos de la capa de servicio
Además del almacén de datos en la nube mencionado anteriormente, Lakehouse y la base de datos de análisis en tiempo real, también hay productos como Metric Store, que se basan en varias fuentes de datos y brindan servicios unificados al mundo exterior. Como LookML [26], Transform [27], Metlo [28], etc.
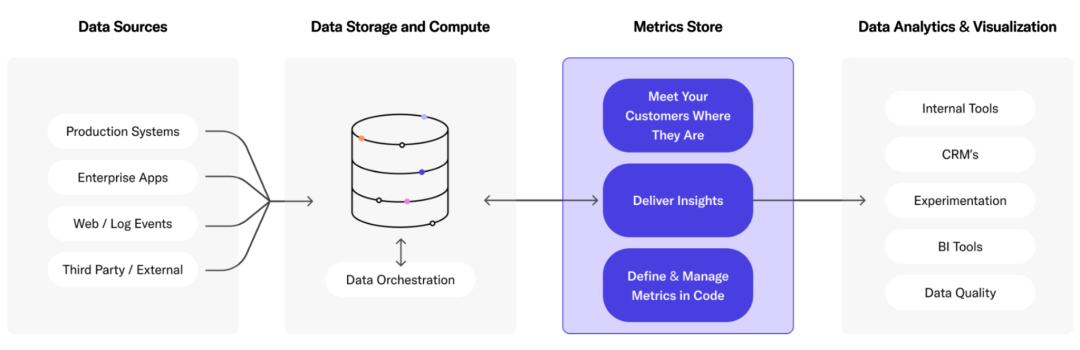
Tienda métrica
8 Orquestación de procesos y ETL
8.1 Orquestación de procesos
En la arquitectura de almacenamiento de datos tradicional, las herramientas de orquestación también son una parte extremadamente importante. En la plataforma de datos en la nube, la programación de la ejecución de los procesos de canalización relacionados será más complicada. Por ejemplo, necesitamos desencadenar el proceso de adquisición de datos a través del tiempo o la API, y luego desencadenar y programar varias tareas en cascada. Cuando hay un problema o una falla en la ejecución de la tarea, puede volver a intentarlo y recuperarse automáticamente, o pedirle al usuario que intervenga.
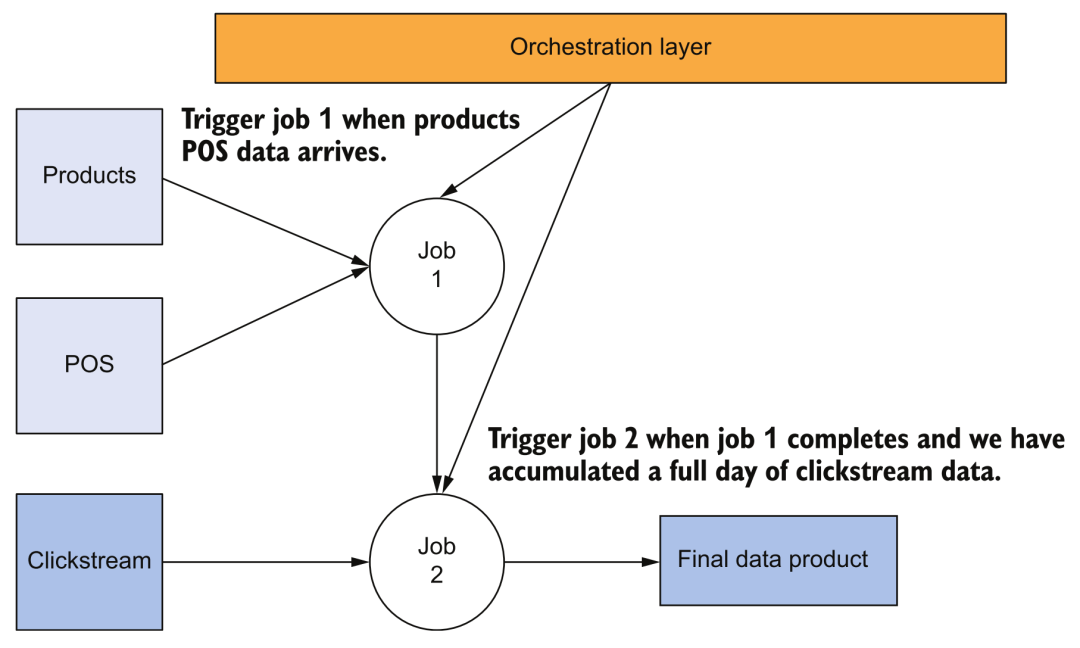
diagrama de flujo
Por ejemplo, la figura anterior muestra la dependencia de tareas más simple. La activación de la tarea 2 depende de la finalización exitosa de la tarea por lotes de la tarea 1. En este momento, necesitamos herramientas de orquestación para respaldar este tipo de trabajo.
8.2 ETL
Las tareas específicas realizadas en el proceso de orquestación son generalmente varias operaciones de acceso y conversión de datos, que es lo que comúnmente llamamos ETL. Además de desarrollar la lógica de negocios a través de SQL o SDK de motores informáticos (como PySpark), también hay muchos productos en el mercado que admiten el desarrollo sin código o con poco código, lo que reduce en gran medida el umbral para los usuarios. Por ejemplo, nuestro Guanyuan SmartETL es un buen producto en este sentido y ha sido amado por muchos empleados de negocios.
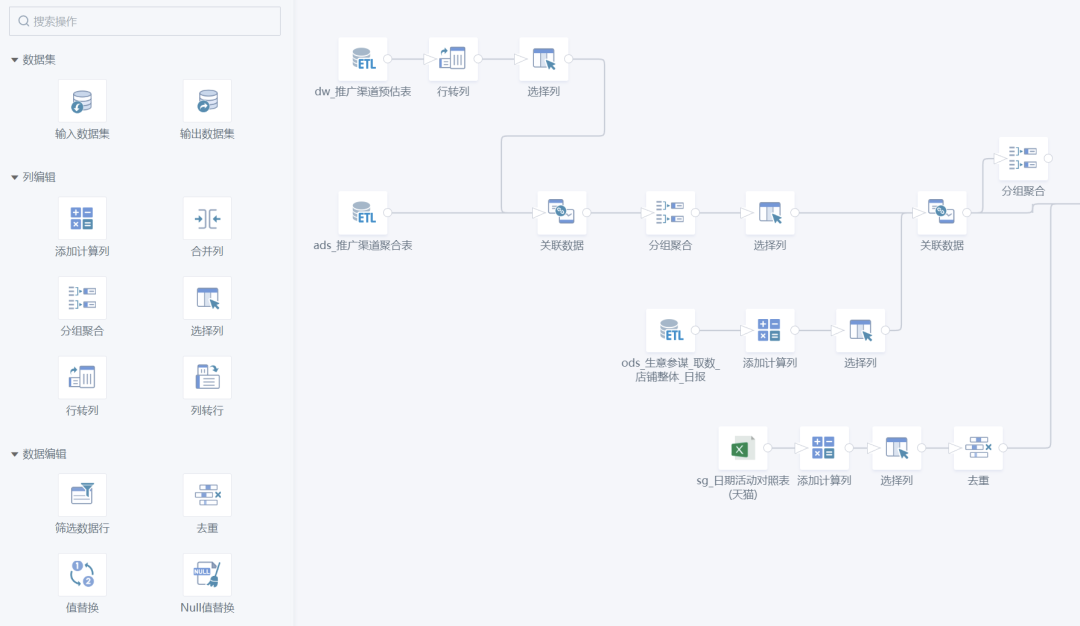
Guanyuan SmartETL
8.3 Demanda y Productos
Para las herramientas relacionadas con la orquestación de procesos, los principales requisitos del sistema son:
-
Escalabilidad, programación de soporte y monitoreo de tuberías masivas.
-
La estabilidad debe garantizar la estabilidad y la alta disponibilidad. Una vez que la capacidad de orquestación de procesos se paraliza, significa que las capacidades centrales de procesamiento de datos de toda la plataforma se han detenido.
-
Observable, operable y mantenible, el estado de ejecución de varias tareas, registros, sobrecarga de recursos del sistema, etc. debe registrarse y verse fácilmente, conveniente para la operación y el mantenimiento y la resolución de problemas.
-
La apertura facilita el desarrollo de varias lógicas de procesamiento personalizadas en la herramienta para ejecutar diferentes tipos de tareas.
-
Compatibilidad con DataOps, incluso si se proporciona un desarrollo de arrastrar y soltar sin código, la capa inferior aún debería poder satisfacer las necesidades de DataOps, como la gestión de versiones de la lógica de canalización, las pruebas y la liberación (CI/CD) y admitir llamadas API para realizar la automatización del proceso, etc.
Se puede notar que, de hecho, muchas herramientas de adquisición y procesamiento de datos también tienen algunas capacidades de orquestación o ETL. Los productos de los proveedores de la nube son básicamente herramientas de adquisición de datos, incluidos AWS Glue, Google Cloud Composer (versión alojada de Airflow), Google Cloud Data Fusion y Azure Data Factory.
En términos de herramientas de código abierto, entre las herramientas de orquestación, Airflow debería ser la más famosa. Con la gran demanda de orquestación de flujos de trabajo en el campo del aprendizaje automático, han surgido muchas estrellas en ascenso, como Dagster, Prefect, Flyte, Cadence, Argo (oleoducto KubeFlow) espere. Además, la popularidad de DolphinScheduler [29] es bastante buena. No hay muchas herramientas de código abierto para ETL, y talend no es completamente de código abierto, las más famosas son Apache NiFi [30] y OpenRefine [31], dos proyectos de código abierto con una larga historia.
Los proveedores de SaaS pueden referirse a proveedores de adquisición de datos, como Airbyte, Fivetran, Stitch, Rivery, etc. Muchos proyectos de código abierto de herramientas de orquestación mencionados anteriormente también tienen empresas comerciales correspondientes que brindan servicios de alojamiento. También tengo que mencionar el muy popular dbt [32], una herramienta de conversión de datos utilizada por casi todas las empresas. Ha tomado prestadas muchas de las mejores prácticas en el campo de la ingeniería de software. Se puede decir que satisface las necesidades de DataOps. A muy buen producto para apoyar.
9. Mejores prácticas
9.1 Capas de datos
Cuando creamos un sistema de almacenamiento de datos empresarial, generalmente seguimos algunas de las mejores prácticas clásicas. Por ejemplo, con respecto al modelo de tabla de datos, existen métodos de diseño como el esquema en estrella y el modelo de copo de nieve; desde la perspectiva del proceso de transferencia de datos, existen métodos muy clásicos. almacenes de datos Modo jerárquico:
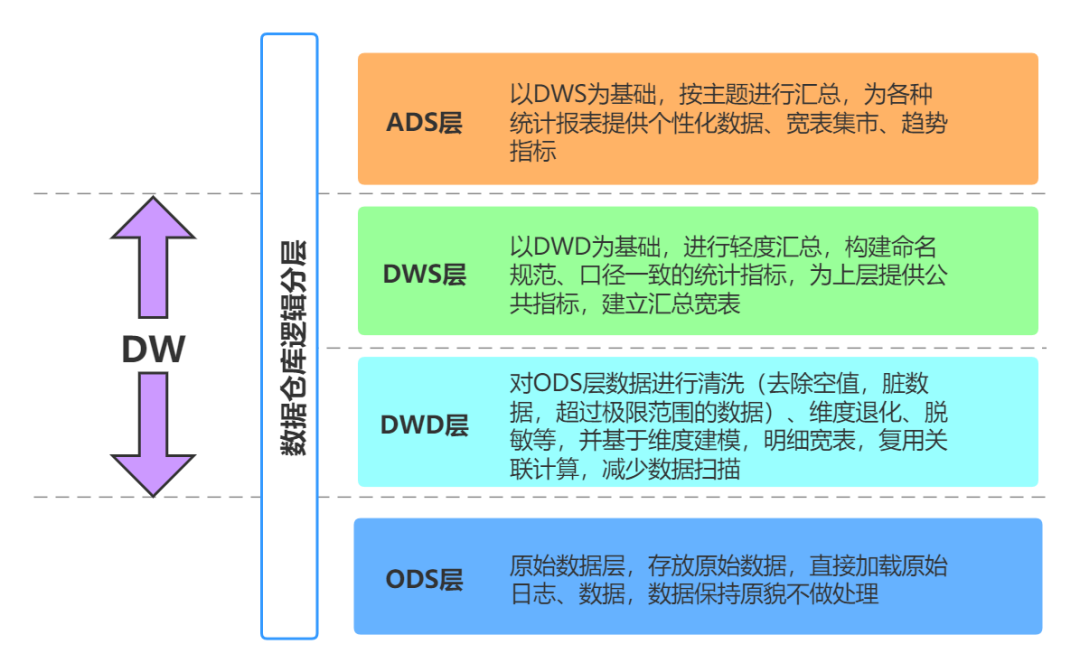
Jerarquía del almacén de datos
En la plataforma de datos en la nube, también podemos aprender de esta idea. Por ejemplo, el flujo de datos en la casa del lago diseñada por Databricks es muy similar a la capa de almacenamiento de datos anterior:
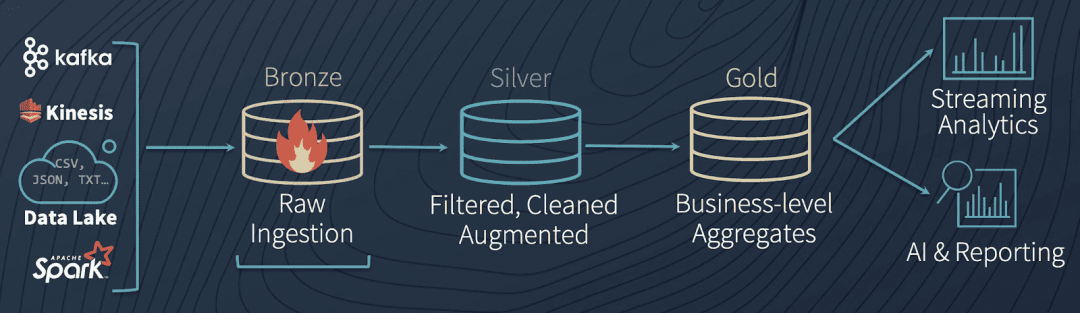
Arquitectura de datos Lakehouse
Los pasos específicos del proceso son los siguientes:
-
En general, al ingresar a la plataforma de datos en la nube a través de la adquisición de datos, el estado de los datos originales (que pueden estar en el formato original o en formato Avro) se mantendrá tanto como sea posible y se almacenará en el área de aterrizaje (bronce). Tenga en cuenta que en la arquitectura general, solo las herramientas de la capa de adquisición de datos pueden escribir en esta área.
-
Luego, los datos originales se someterán a algunos controles de calidad generales, desduplicación, limpieza y conversión, y entrarán en el área de ensayo (plata). A partir de aquí, se recomienda utilizar un formato de almacenaje columnar similar al parquet.
-
Al mismo tiempo, los datos originales se copiarán en el área de archivo y luego se utilizarán para el reprocesamiento, la depuración de procesos o la prueba de nuevas canalizaciones.
-
La herramienta de la capa de procesamiento de datos leerá los datos del área de preparación, realizará varios procesos de lógica comercial, agregación, etc. y finalmente formará datos de producción (dorados) y proporcionará servicios de datos.
-
Los datos en el área de preparación también se pueden dejar sin procesar, pasar al área de producción y finalmente fluir hacia el almacén de datos.Esta parte es equivalente a los datos sin procesar, que pueden ayudar a los consumidores de datos a comparar y localizar problemas relacionados en algunos casos.
-
Diferentes lógicas de procesamiento de datos formarán "productos de datos" para diferentes temas comerciales y escenarios de aplicaciones, brindarán servicios de consumo por lotes (especialmente escenarios de algoritmos) en el área de producción o cargarán almacenes de datos para brindar servicios de consulta SQL.
-
Durante el proceso de transferencia entre la preparación y la producción, si la capa de procesamiento de datos encuentra algún error, puede guardar los datos en el área fallida y, una vez resuelta la solución de problemas, colocar los datos nuevamente en el área de aterrizaje para desencadenar todo el proceso nuevamente.
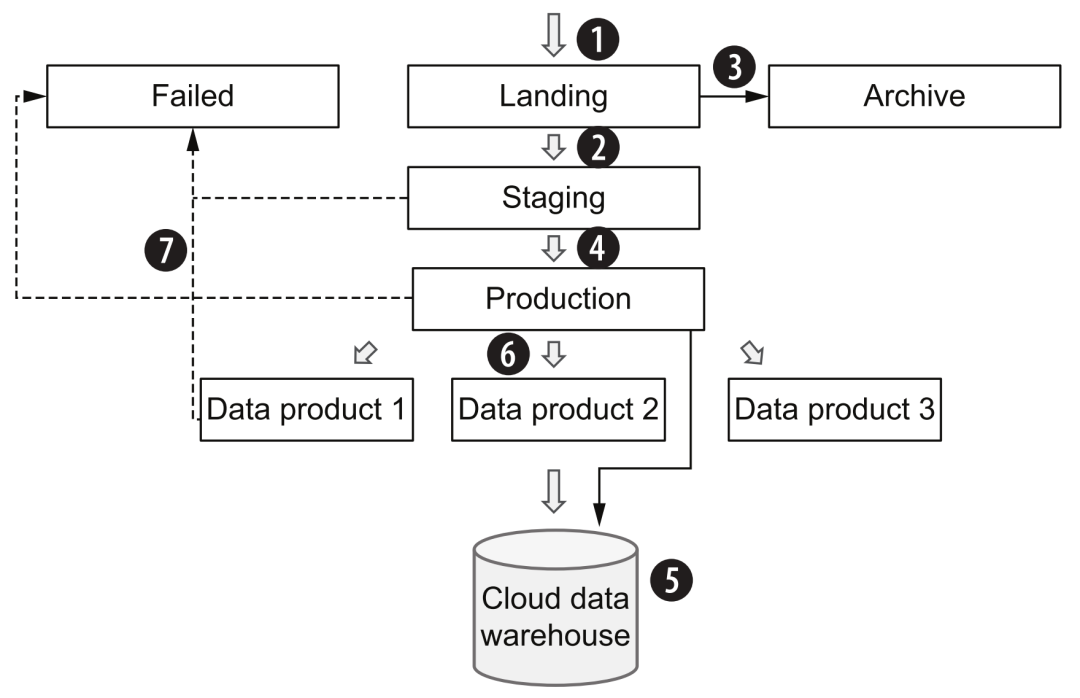
Mejores prácticas de procesamiento de datos
Estas áreas se pueden dividir por conceptos típicos de almacenamiento de objetos, como "depósito" o "carpeta". También se puede determinar el control de acceso de cada área a diferentes módulos de capa según diferentes patrones de lectura y escritura, así como el diseño de almacenamiento en frío y caliente para ahorrar costos. Además, el flujo de procesamiento de la transmisión de datos también puede aprender de una lógica similar, pero habrá más desafíos en la deduplicación de datos, la inspección de calidad, la mejora de datos y la gestión de esquemas.
9.2 Distinguir entre la adquisición de transmisión y los requisitos de análisis de transmisión
A menudo escuchamos que los clientes de análisis de BI tienen la demanda de "análisis de datos en tiempo real". Sin embargo, después de un análisis cuidadoso, los usuarios no miran el tablero de análisis de BI todo el tiempo para hacer un "análisis en tiempo real" En términos generales, hay un cierto intervalo de tiempo para abrir el tablero. Solo debemos asegurarnos de que los datos que los clientes ven cada vez que abren el panel de análisis estén actualizados, por lo que se puede usar la siguiente arquitectura para cumplir con los requisitos:
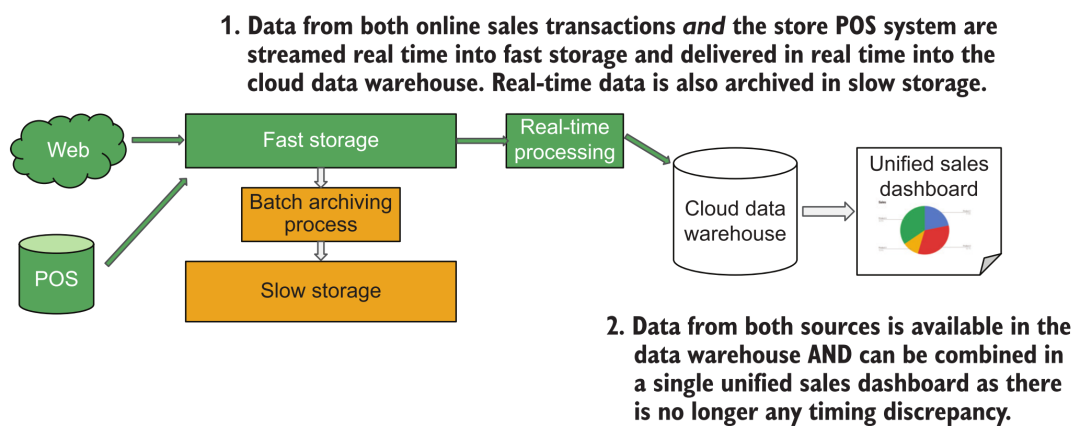
Arquitectura de adquisición de datos de transmisión
Aquí solo necesitamos escribir los datos del pedido en el almacén de datos en la nube en tiempo real a través del sistema de adquisición de datos de transmisión. Cuando el usuario abre el informe de vez en cuando, active la consulta SQL del almacén de datos para mostrar los últimos resultados.
Pero considere otro escenario: en cierto juego, queremos mostrar datos de acción en tiempo real de los usuarios, como información estadística, como los puntos de experiencia ganados desde el lanzamiento. En este momento, puede que no sea apropiado si todavía usamos la arquitectura de "adquisición de transmisión" mencionada anteriormente. Porque en este momento, cada jugador realmente está mirando sus estadísticas en "tiempo real", por lo que se debe lograr el soporte de consultas de alta frecuencia y gran concurrencia. El tiempo de respuesta y las capacidades de servicio simultáneo de los almacenes de datos en la nube generales son difíciles de cumplir, y este es el requisito real para el "análisis en tiempo real". Necesitamos realizar operaciones de análisis estadístico de transmisión después de transmitir nuevos datos de los usuarios y almacenar los resultados en algunos sistemas de base de datos/caché que puedan admitir consultas de alta simultaneidad y baja latencia para satisfacer las necesidades de consumo de datos de los reproductores en línea masivos.
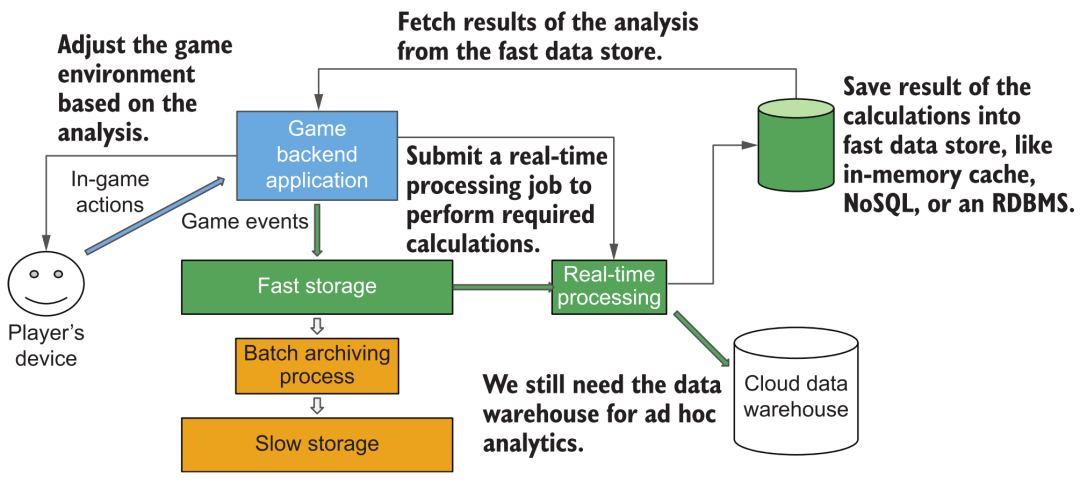
Arquitectura de análisis de datos de transmisión
9.3 Control del gasto en computación en la nube
En la era nativa de la nube, las barreras de entrada para que usemos varios componentes son mucho más bajas. La escalabilidad elástica lista para usar y la ausencia de O&M han brindado mucha comodidad a los desarrolladores y están cambiando silenciosamente nuestra pensamiento. En la era de los sistemas autoconstruidos, tenemos una comprensión más refinada y una optimización profunda de la sobrecarga de recursos de cada componente y la tasa de utilización de todo el clúster. Pero ahora la compensación de varios diseños de sistemas ha pasado de la asignación de grupos de recursos limitados a la compensación entre costo y rendimiento, lo que ha reducido la conciencia de la optimización de costos de recursos para cada componente. Incluir a los propios proveedores de la nube a veces "malos" intencionalmente o no. Recientemente, hay un artículo The Non-Expert Tax [33] dedicado a discutir la economía del escalado automático de los proveedores de la nube.
Por lo tanto, como desarrollador de una plataforma de datos en la nube, aún es necesario tener una comprensión profunda de varios componentes de computación en la nube, principios de arquitectura de productos, modelos de carga y practicar los métodos de optimización y monitoreo de recursos correspondientes. Los ejemplos típicos incluyen el control de sobrecarga de la red (reducción de la transmisión entre nubes), el diseño de almacenamiento en caliente y en frío, la partición de datos y otros métodos de optimización para mejorar la eficiencia de procesamiento y computación de datos, etc.
9.4 Evite el acoplamiento apretado
Como se puede ver en el diagrama de arquitectura compleja anterior, una plataforma de datos en la nube generalmente consta de una gran cantidad de componentes, y toda la ecología tecnológica cambia cada día que pasa. Generalmente, para este tipo de sistema complejo, adoptaremos un método de construcción paso a paso. Durante el proceso, continuaremos aumentando, reemplazando o eliminando algunos productos componentes. Por lo tanto, debemos aprender del principio de acoplamiento débil en ingeniería de software para evitar que un producto/interfaz específico tenga dependencias estrechas. Aunque a veces el acceso directo al almacenamiento subyacente parece reducir los pasos intermedios y ser más eficiente, también nos hará encontrar muchos problemas cuando queramos expandirnos y cambiar más adelante. Idealmente, deberíamos aclarar los límites y las interfaces entre los componentes tanto como sea posible y encapsular diferentes productos para proporcionar interfaces relativamente estándar para la interacción y los servicios.
10. Construcción de plataforma de datos
10.1 Valor comercial
Finalmente, vale la pena mencionar que la construcción de una plataforma compleja de datos en la nube no puede promoverse únicamente desde una perspectiva técnica. Todo el proyecto debe iniciarse y planificarse a partir de objetivos empresariales (comerciales). Los valores típicos de una plataforma de datos incluyen:
-
Reduzca los gastos, mejore la eficiencia de las operaciones comerciales, ahorre inversiones en activos y varios costos de operación y mantenimiento.
-
Código abierto, soporte de optimización de marketing, optimización de la experiencia del cliente y otros escenarios, y promueve el crecimiento de los ingresos de la empresa.
-
Innovación, a través de excelentes capacidades de productos, para respaldar el análisis de datos de autoservicio y la toma de decisiones del negocio, para explorar rápidamente nuevos puntos de crecimiento.
-
Cumplimiento, a través de la construcción de una plataforma unificada para cumplir con diversas regulaciones, políticas y necesidades regulatorias de datos.
Debemos aclarar las demandas comerciales de la empresa y diseñar estrategias y planes de datos para la construcción de plataformas de datos de manera específica. Para conocer cómo las estrategias técnicas sirven a los objetivos comerciales, también puede consultar este artículo The Road to Senior Engineers: Technical Strategy [34], que no se elaborará aquí.
10.2 Ruta de construcción
Como se puede ver en el diagrama de arquitectura anterior, la composición de toda la plataforma es bastante complicada y, por lo general, lleva varios años construirla y mejorarla gradualmente. Esto es consistente con la evolución en línea, digital e inteligente de la propia empresa, en lugar de ignorar el statu quo de los datos empresariales y desarrollar e implementar plataformas de transmisión de datos, plataformas de aprendizaje automático y otras tecnologías aparentemente modernas.
En los primeros días de su establecimiento, Guanyuan pensó profundamente y propuso una metodología de ruta de implementación 5A para el análisis de datos y la toma de decisiones inteligente en las empresas [35], incluido el análisis de autoservicio, basado en escenas, automatización y mejora, y finalmente se dio cuenta automatización de la toma de decisiones paso a paso. En correspondencia con la construcción de la plataforma de datos, también puede consultar marcos de políticas similares, por ejemplo:
-
La agilidad se puede lograr mediante la construcción del sistema básico de almacenamiento de datos y la aplicación de productos de análisis de BI de autoservicio para lograr el objetivo de "ver datos".
-
Basado en escenarios, a través de la capa métrica y el mercado de aplicaciones en productos de BI, forman las mejores prácticas de varios escenarios comerciales, para que más usuarios puedan saber "cómo mirar los datos".
-
La automatización requiere que la plataforma tenga ciertas capacidades de orquestación, conecte varios resultados de análisis con sistemas comerciales, envíe resultados automáticamente (ETL inverso), alerta temprana de datos, etc., para lograr el efecto de "datos que persiguen a las personas".
-
La mejora, sobre la base del análisis, la adición adicional de capacidades de pronóstico y modelado de IA requiere que la plataforma admita el procesamiento y el consumo de datos algorítmicos (como datos no estructurados, cuadernos) para lograr una "visión del futuro".
-
Movilidad, al final esperamos ir más allá sobre la base de la previsión, pasando de la IA analítica a la IA de acción, lo que requiere que la plataforma brinde capacidades de servicio externo más completas (API, datos en tiempo real, Prueba AB, etc.), combinado con algunas herramientas de código bajo Se espera que la creación de aplicaciones comerciales basadas en datos logre una "toma de decisiones automática".
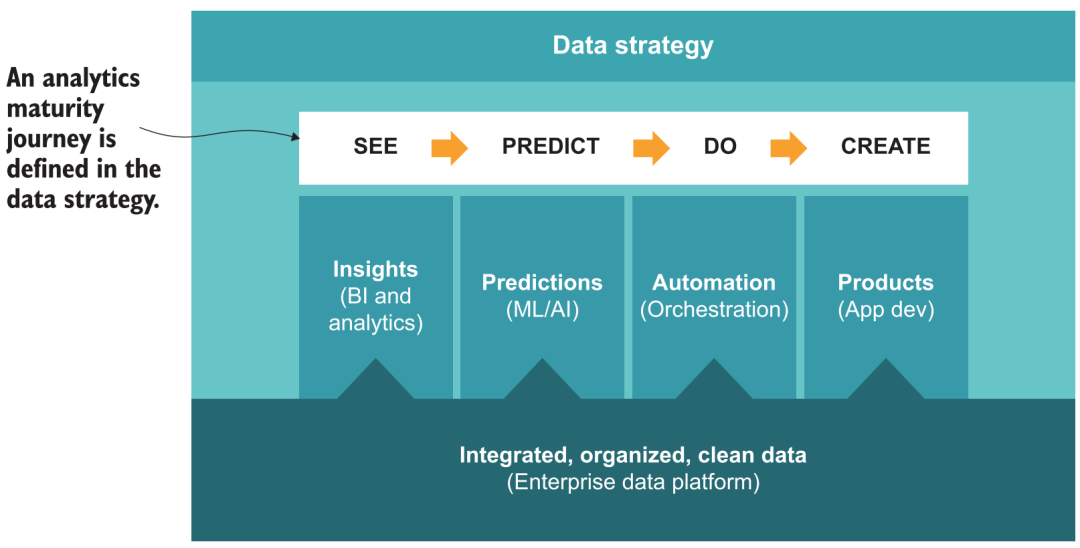
Viaje de madurez de análisis de datos
10.3 Promoción de usuarios
Además de la metodología de evolución a nivel de arquitectura técnica, también es un tema importante cómo dar a conocer y promover la plataforma a nivel empresarial. Hay demasiados proyectos de plataformas de datos que carecen de una comunicación y comprensión empresarial profundas. En ausencia de un consenso entre ambas partes, se promueven proyectos complejos y el período de construcción es extremadamente largo, lo que finalmente conduce a la falla a mitad de camino. Deberíamos reflejar rápidamente el valor de la plataforma a través de algunos proyectos pequeños, mejorar el consenso entre las dos partes, ganar la confianza de los usuarios y promoverla gradualmente a más departamentos organizacionales; después de obtener más aplicaciones, también impulsará la escena y enriquecerá la demanda, que a su vez también aumentará Puede orientar y promover la construcción y desarrollo de la propia plataforma, y entrar en un círculo virtuoso. Esta es también la ruta y el método de "hacer uso comercial" que estamos explorando y practicando constantemente.
Al final, pusimos un pequeño anuncio. Nosotros en Guanyuan Data tenemos una gran experiencia en el nivel de tecnología de productos mencionado anteriormente, servicios empresariales y promoción comercial. A través de las líneas de productos Universe, Galaxy y Atlas, puede admitir plataformas de datos empresariales en diversas etapas de madurez del análisis de datos, análisis de BI + IA y necesidades de toma de decisiones. Para algunos clientes líderes en la industria, nuestros productos también han alcanzado con éxito el hito de más de 20,000 analistas activos y usuarios de toma de decisiones de datos.Es concebible que una empresa de este tipo pueda incorporar las enormes ventajas de la eficiencia y la calidad de la toma de decisiones en el feroz competencia en el mercado. Los amigos interesados son bienvenidos a discutir e intercambiar juntos, y buscar oportunidades de cooperación y co-construcción :)
Referencias
[1] Composición y construcción de una plataforma de aprendizaje automático nativa en la nube: https://zhuanlan.zhihu.com/p/383528646
[2] Algunos informes de análisis de a16z: https://future.com/data50/
[3] pila de datos moderna: https://www.moderndatastack.xyz/
[4] Sistema de lago de datos en plataforma de algoritmo: https://zhuanlan.zhihu.com/p/400012723
[5] almacenamiento en niveles: https://www.confluent.io/blog/infinite-kafka-storage-in-confluent-platform/
[6] lagoFS: https://github.com/treeverse/lakeFS
[7] JuiceFS: https://github.com/juicedata/juicefs
[8] SeaseedFS: https://github.com/chrislusf/seaweedfs
[9] Confluente: https://www.confluent.io/
[10] Upsolver: https://www.upsolver.com/
[11] Materializar: https://materialize.com/
[12] Márquez: https://github.com/MarquezProject/marquez
[13] Atlas de Apache: https://atlas.apache.org/
[14] Amundsen: https://www.amundsen.io/
[15] Centro de datos: https://datahubproject.io/
[16] Atlán: https://atlan.com/
[17] Alación: https://www.alation.com/
[18] Deequ: https://github.com/awslabs/deequ
[19] Grandes expectativas: https://github.com/great-expectations/great_expectations
[20] Montecarlo: https://www.montecarlodata.com/
[21] BigEye: https://www.bigeye.com/
[22] Apache Doris: https://doris.apache.org/
[23] Bend de datos: https://databend.rs/
[24] Introducción a MLOps: https://zhuanlan.zhihu.com/p/357897337
[25] Autenticación0: https://auth0.com/
[26] LookML: https://www.looker.com/platform/data-modeling/
[27] Transformar: https://transform.co/
[28] Metlo: https://blog.metlo.com/
[29] Programador de delfines: https://github.com/apache/dolphinscheduler
[30] Apache NiFi: https://github.com/apache/nifi
[31] OpenRefine: https://github.com/OpenRefine/OpenRefine
[32] base de datos: https://www.getdbt.com/
[33] El Impuesto de No Expertos: https://dl.acm.org/doi/10.1145/3530050.3532925
[34] El camino hacia la ingeniería sénior: estrategia técnica: https://zhuanlan.zhihu.com/p/498475916
[35] Metodología de ruta de aterrizaje 5A: https://zhuanlan.zhihu.com/p/43515719