1. Descripción
En esta serie de 4 partes, analizaremos la segmentación de imágenes desde cero utilizando técnicas de aprendizaje profundo en PyTorch. En este artículo, comenzaremos la serie con los conceptos e ideas básicos necesarios para la segmentación de imágenes.

Figura 1: Imágenes de mascotas y sus máscaras de segmentación (Fuente: Oxford-IIIT Pets Dataset )
La segmentación de imágenes es una técnica para aislar píxeles pertenecientes a objetos específicos en una imagen . El aislamiento de píxeles de objetos abre la puerta a aplicaciones interesantes. Por ejemplo, en la Figura 1, la imagen de la derecha es la máscara correspondiente a la imagen de la mascota donde los píxeles amarillos de la izquierda pertenecen a las mascotas. Una vez identificados los píxeles, podemos agrandar fácilmente la mascota o cambiar el fondo de la imagen. Esta tecnología se usa ampliamente en la función de filtro facial en varias aplicaciones de redes sociales.
Al final de esta serie de artículos, nuestro objetivo es guiar al lector a través de todos los pasos necesarios para construir un modelo de IA de visión y ejecutar experimentos con diferentes configuraciones usando PyTorch.
2. Esta serie de artículos
Esta serie está dirigida a lectores de todos los niveles de experiencia en aprendizaje profundo. Si desea aprender sobre el aprendizaje profundo y la IA visual en la práctica con una sólida experiencia teórica y práctica, ¡está en el lugar correcto! Esta será una serie de 4 partes con los siguientes artículos:
- Conceptos e Ideas (este artículo)
- modelos basados en CNN
- Convolución separable en profundidad
- Modelos basados en transformadores visuales
3. Introducción a la segmentación de imágenes
La segmentación de imágenes divide o segmenta una imagen en regiones correspondientes a objetos, fondo y límites. Véase la Figura 2, que muestra una escena urbana. Marca áreas correspondientes a automóviles, motocicletas, árboles, edificios, aceras y otros objetos interesantes con máscaras de diferentes colores. Estas regiones se identifican mediante técnicas de segmentación de imágenes.
Históricamente, hemos descompuesto las imágenes en regiones utilizando canalizaciones y herramientas de procesamiento de imágenes especializadas . Sin embargo, debido al sorprendente crecimiento de los datos visuales en las últimas dos décadas, el aprendizaje profundo se ha convertido en la solución preferida para las tareas de segmentación de imágenes. Reduce en gran medida la dependencia de los expertos para construir estrategias de segmentación de imágenes específicas del dominio, como se ha hecho en el pasado. Los profesionales del aprendizaje profundo pueden entrenar modelos de segmentación de imágenes si hay suficientes datos de entrenamiento disponibles para la tarea.

Figura 2: Escena de segmentación del conjunto de datos a2d2 (CC BY-ND 4.0)
3.1 ¿Cuáles son las aplicaciones de la segmentación de imágenes?
La segmentación de imágenes tiene aplicaciones en muchos campos, como la comunicación, la agricultura, el transporte, la salud, etc. Además, su aplicación crece con el crecimiento de los datos visuales. Aquí hay unos ejemplos:
- En los automóviles autónomos , los modelos de aprendizaje profundo procesan continuamente las transmisiones de video de las cámaras a bordo para segmentar la escena en objetos como automóviles, peatones y semáforos, lo cual es fundamental para que el automóvil funcione de manera segura.
- En imágenes médicas, la segmentación de imágenes ayuda a los médicos a identificar áreas en exploraciones médicas que corresponden a tumores, lesiones y otras anomalías.
- En las videollamadas de Zoom , se utiliza para proteger la privacidad personal reemplazando el fondo con una escena virtual.
- En agricultura , la información sobre malas hierbas y áreas de cultivo identificadas mediante la segmentación de imágenes se utiliza para mantener un rendimiento saludable de los cultivos .
Puede leer más detalles sobre la segmentación de imágenes en acción en esta página de v7labs .
3.2 ¿Cuáles son los diferentes tipos de tareas de segmentación de imágenes?
Hay muchos tipos diferentes de tareas de segmentación de imágenes, cada una con sus ventajas y desventajas. Los dos tipos más comunes de tareas de segmentación de imágenes son:
- Segmentación de clase o semántica: la segmentación de clase asigna a cada píxel de imagen una clase semántica, como fondo , carretera , automóvil o persona . Si hay 2 autos en la imagen, los píxeles correspondientes a los dos autos se etiquetarán como píxeles de autos. Se usa comúnmente en tareas como la conducción autónoma y la comprensión de la escena .
- Segmentación de objetos o instancias : la segmentación de objetos identifica objetos y asigna una máscara a cada objeto único en la imagen. Si hay 2 coches en la imagen, los píxeles correspondientes a cada coche se identificarán como pertenecientes a objetos separados. La segmentación de objetos se usa a menudo para rastrear objetos individuales, como un automóvil autónomo programado para seguir a un automóvil específico que se encuentra adelante.

Figura 3: Segmentación de objetos y clases (Fuente: MS Coco - Creative Commons Attribution License )
En esta serie, nos centraremos en la segmentación de clases.
3.3 Decisiones necesarias para implementar una segmentación eficiente de imágenes
El entrenamiento eficiente de modelos para velocidad y precisión requiere que se tomen muchas decisiones importantes durante el ciclo de vida de un proyecto. Esto incluye (pero no se limita a):
- Elección del marco de aprendizaje profundo
- Elija una buena arquitectura modelo
- Elija una función de pérdida eficaz para optimizar el aspecto que le interesa
- Evite el sobreajuste y el ajuste insuficiente
- Evaluar la precisión del modelo.
En el resto de este artículo, exploraremos cada uno de los aspectos anteriores con más profundidad y proporcionaremos enlaces a una serie de artículos que analizan cada tema con más detalle, que se pueden cubrir aquí.
4. PyTorch para una segmentación eficiente de imágenes
4.1 ¿Qué es PyTorch?
PyTorch es un marco de aprendizaje profundo de código abierto diseñado para ser flexible y modular para la investigación , con la estabilidad y el soporte necesarios para la implementación de producción. PyTorch proporciona un paquete de Python para funciones avanzadas como el cálculo de tensores (como NumPy), con una potente aceleración de GPU y TorchScript para facilitar la transición entre los modos entusiasta y gráfico. Con la última versión de PyTorch, el marco ofrece ejecución basada en gráficos, capacitación distribuida, implementación móvil y cuantificación. (Fuente: PyTorch en la página Meta AI )
PyTorch está escrito en Python y C++, lo que lo hace fácil de usar y aprender, así como eficiente de ejecutar. Es compatible con una amplia gama de plataformas de hardware, incluidas CPU, GPU y TPU (servidor y móvil).
4.2 ¿Por qué PyTorch es una buena opción para la segmentación de imágenes?
PyTorch es una opción popular para la investigación y el desarrollo de aprendizaje profundo porque proporciona un entorno flexible y potente para crear y entrenar redes neuronales. Es una excelente opción de marco para implementar la segmentación de imágenes basada en el aprendizaje profundo debido a las siguientes características:
- Flexibilidad : PyTorch es un marco flexible que le permite crear y entrenar redes neuronales de varias maneras. Puedes usar modelos pre-entrenados o crear los tuyos propios desde cero muy fácilmente
- Compatibilidad con backend : PyTorch admite múltiples backends, como hardware GPU/TPU
- Bibliotecas de dominio : PyTorch tiene un amplio conjunto de bibliotecas de dominio que facilitan el trabajo con datos verticales específicos. Por ejemplo, para la IA relacionada con la visión (imagen/video), PyTorch proporciona una biblioteca llamada Torchvision , que usaremos ampliamente en esta serie.
- Facilidad de uso y adopción por la comunidad : PyTorch es un marco fácil de usar, bien documentado y tiene una gran comunidad de usuarios y desarrolladores . Muchos investigadores usan PyTorch para sus experimentos, y los resultados de sus artículos publicados implementan el modelo en PyTorch de forma gratuita.
5. Selección de conjuntos de datos
Usaremos el conjunto de datos Oxford IIIT Pet (con licencia bajo CC BY-SA 4.0) para la segmentación de clases. Este conjunto de datos tiene 3680 imágenes en el conjunto de entrenamiento y cada imagen tiene un mapa de segmentación asociado. Un triplete es una de las 3 clases de píxeles:
- mascota
- fondo
- borde
Elegimos este conjunto de datos porque es lo suficientemente diverso como para proporcionarnos la importante tarea de segmentación de clases. Además, no es tan complicado que terminemos gastando nuestro tiempo lidiando con cosas como el desequilibrio de clases... y olvidándonos del principal problema que estamos tratando de entender y solucionar, a saber, la segmentación de clases.
Otros conjuntos de datos comúnmente utilizados para tareas de segmentación de imágenes incluyen:
6. Usa PyTorch para lograr una segmentación de imágenes eficiente
En esta serie, entrenaremos varios modelos para la segmentación de clases desde cero. Hay una serie de consideraciones a tener en cuenta al crear y entrenar un modelo desde cero. A continuación, cubriremos algunas de las decisiones clave que deberá tomar al hacerlo.
6.1 Elegir el modelo adecuado para su tarea
Hay muchos factores a considerar al elegir el modelo de aprendizaje profundo adecuado para la segmentación de imágenes. Algunos de los factores más importantes incluyen:
- Tipos de tareas de segmentación de imágenes : existen dos tipos principales de tareas de segmentación de imágenes: segmentación de clase (semántica) y segmentación de objeto (instancia). Dado que nos enfocamos en el problema de segmentación de clases más simple, consideraremos modelar el problema en consecuencia.
- Tamaño y complejidad del conjunto de datos : el tamaño y la complejidad del conjunto de datos afectan la complejidad de los modelos que necesitamos usar. Por ejemplo, si estamos tratando con imágenes con dimensiones espaciales pequeñas, podríamos usar un modelo más simple (o menos profundo) como una red totalmente convolucional (FCN). Si trabajamos con conjuntos de datos grandes y complejos, podemos usar modelos más complejos (o más profundos) como U-Net.
- Disponibilidad de modelos preentrenados: hay muchos modelos preentrenados disponibles para la segmentación de imágenes. Estos modelos se pueden usar como punto de partida para nuestros propios modelos, o se pueden usar directamente. Sin embargo, si usamos un modelo previamente entrenado, podemos estar limitados por las dimensiones espaciales de las imágenes de entrada al modelo. En esta serie, nos centraremos en cómo entrenar un modelo desde cero.
- Recursos informáticos disponibles : los modelos de aprendizaje profundo pueden ser costosos de entrenar. Si nuestros recursos informáticos son limitados, es posible que debamos elegir un modelo más simple o una arquitectura de modelo más eficiente.
En esta serie, utilizaremos el conjunto de datos Oxford IIIT Pet porque es lo suficientemente grande como para entrenar modelos de tamaño moderado y requiere el uso de una GPU. Le recomendamos enfáticamente que cree una cuenta en kaggle.com o use la GPU gratuita de Google Colab para ejecutar los cuadernos y el código a los que se hace referencia en esta serie.
6.2 Arquitectura modelo
Estas son algunas de las arquitecturas de modelos de aprendizaje profundo más populares para la segmentación de imágenes:
- U-Net: U-Net es una red neuronal convolucional comúnmente utilizada para tareas de segmentación de imágenes. Utiliza conexiones de salto, lo que ayuda a entrenar la red más rápido y mejora la precisión general. Si tiene que elegir, ¡U-Net siempre es una excelente opción predeterminada !
- FCN: La red totalmente convolucional ( FCN ) es una red totalmente convolucional, pero no es tan profunda como U-Net . La falta de profundidad se debe principalmente a la pérdida de precisión a mayores profundidades de red. Esto hace que el entrenamiento sea más rápido, pero puede que no sea tan preciso como U-Net.
- SegNet: SegNet es una arquitectura de modelo popular similar a U-Net, que usa menos memoria de activación que U-Net. Usaremos SegNet en esta serie.
- Visual Transformer (ViT): Visual Transformer ha ganado popularidad recientemente debido a su estructura simple y la aplicabilidad del mecanismo de atención al texto, la visión y otros dominios. Los transformadores de visión pueden ser más eficientes (en comparación con las CNN) en el entrenamiento y la inferencia, pero históricamente han requerido más datos para entrenar que las redes neuronales convolucionales. También usaremos ViT en esta serie.

Figura 4: Arquitectura del modelo UN et.
Estos son solo algunos de los muchos modelos de aprendizaje profundo disponibles para la segmentación de imágenes. El mejor modelo para una tarea en particular dependerá de los factores mencionados anteriormente, la tarea específica y sus propios experimentos.
6.3 Elegir la función de pérdida correcta
La elección de la función de pérdida para tareas de segmentación de imágenes es importante porque puede tener un impacto significativo en el rendimiento del modelo. Hay muchas funciones de pérdida diferentes disponibles, cada una con sus propias ventajas y desventajas. Las funciones de pérdida más utilizadas en la segmentación de imágenes son:
- Pérdida de entropía cruzada : la pérdida de entropía cruzada es una medida de la diferencia entre la distribución de probabilidad predicha y la distribución de probabilidad real
- Pérdida de IoU : la pérdida de IoU mide la cantidad de superposición entre la máscara predicha y la máscara real para cada clase. La pérdida de IoU penaliza los casos en los que sufriría la predicción o el recuerdo. El IoU definido no es diferenciable, por lo que debemos modificarlo ligeramente para usarlo como una función de pérdida.
- Pérdida de dados : La pérdida de dados también es una medida de la superposición entre la máscara predicha y la máscara de verdad del terreno.
- Pérdida de Tversky : la pérdida de Tversky se propone como una función de pérdida robusta que se puede utilizar para tratar con conjuntos de datos desequilibrados.
- Pérdida focalfocal tiene como objetivo centrarse en ejemplos difíciles de clasificar. Esto ayuda a mejorar el rendimiento del modelo en conjuntos de datos desafiantes.
La función de pérdida óptima para una tarea en particular dependerá de los requisitos específicos de la tarea. Por ejemplo, si la precisión es más importante, la pérdida de IoU o la pérdida de dados pueden ser mejores opciones. Si la tarea está desequilibrada, entonces la pérdida de Tversky o la pérdida focal pueden ser buenas opciones. Al entrenar un modelo, la función de pérdida específica utilizada puede afectar la tasa de convergencia del modelo.
La función de pérdida es un hiperparámetro del modelo, usar diferentes pérdidas basadas en los resultados que vemos nos permite reducir la pérdida más rápido y mejorar la precisión del modelo.
Predeterminado : en esta serie, utilizaremos la pérdida de entropía cruzada, ya que siempre es un buen valor predeterminado para elegir cuando se desconoce el resultado .
Puede utilizar los siguientes recursos para obtener más información sobre las funciones de pérdida.
- Funciones de pérdida de PyTorch: la guía definitiva
- Visión de Antorcha — Pérdida
- Medición de destellos
Veamos en detalle la pérdida de IoU que definimos a continuación, que es una alternativa sólida a la pérdida de entropía cruzada para tareas de segmentación.
6.4 Pérdida de IOU personalizado
IoU se define como intersección sobre unión. Para las tareas de segmentación de imágenes, podemos calcular esto calculando (para cada clase), la intersección de los píxeles en esa clase predicha por el modelo y la máscara de segmentación de la realidad del terreno.
Por ejemplo, si tenemos 2 clases:
- fondo
- gente
Luego, podemos determinar qué píxeles se clasifican como personas y compararlos con los píxeles reales de la persona y calcular el IoU para la clase de persona. Del mismo modo, podemos calcular el IoU de las clases de fondo.
Una vez que tengamos estas métricas de IoU específicas de clase, podemos optar por promediarlas sin ponderar o ponderarlas, y luego promediarlas nuevamente para tener en cuenta cualquier tipo de desequilibrio de clase que vimos en los ejemplos anteriores.
Las métricas de IoU definidas requieren que calculemos etiquetas duras para cada métrica. Esto requiere el uso de la función argmax(), que no es diferenciable, por lo que no podemos usar esta métrica como una función de pérdida. Por lo tanto, en lugar de usar etiquetas duras, aplicamos softmax() y usamos las probabilidades pronosticadas como etiquetas blandas para calcular la métrica de IoU. Esto produce una métrica diferenciable a partir de la cual podemos calcular la pérdida. Por lo tanto, a veces, cuando se usan en el contexto de las funciones de pérdida, las métricas de IoU también se denominan métricas de IoU blandas.
Si tenemos una métrica (M) entre 0,0 y 1,0, podemos calcular la pérdida (L) como:
L = 1 — METRO
Sin embargo, si su métrica tiene valores entre 0,0 y 1,0, aquí hay otro truco que puede usar para convertir la métrica en una pérdida. calcular:
L = -log (M)
Es decir, el logaritmo negativo del indicador calculado. Esta es una marcada desviación de la formulación anterior, que puede leer aquí y aquí . Básicamente, conduce a un mejor aprendizaje para su modelo.
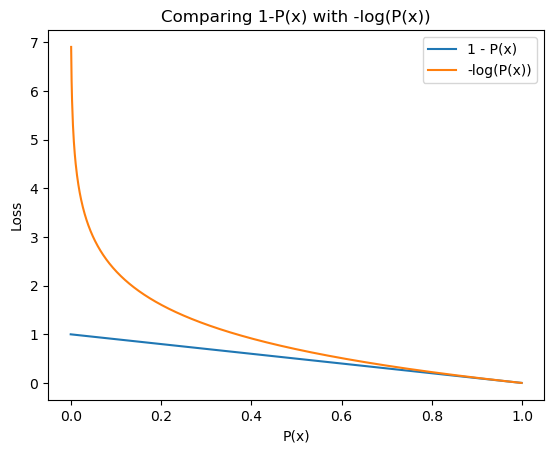
Figura 6: Comparación de la pérdida debida a 1-P(x) frente a -log(P(x)). Fuente: Autor.
Usar IoU como nuestra pérdida también acerca la función de pérdida a capturar lo que realmente nos importa. Existen ventajas y desventajas en el uso de una métrica de evaluación como función de pérdida. Si está interesado en explorar más esta área, puede comenzar con esta discusión sobre stackexchange .
6.5 Aumento de datos
Para entrenar un modelo de manera eficiente y efectiva para lograr una buena precisión, se debe prestar atención a la cantidad y el tipo de datos de entrenamiento utilizados para entrenar el modelo. Los datos de entrenamiento que elija usar afectarán significativamente la precisión de su modelo final, por lo que si hay algo que quiera aprender de esta serie de artículos, ¡debería ser esto!
Por lo general, dividiremos los datos en 3 partes aproximadamente en las proporciones que se mencionan a continuación.
- Formación (80%)
- Verificación (10%)
- Prueba (10%)
Entrenará el modelo en el conjunto de entrenamiento, evaluará la precisión en el conjunto de validación y repetirá el proceso hasta que esté satisfecho con las métricas informadas. Solo entonces evaluará el modelo en el conjunto de prueba y luego informará los números. Esto se hace para evitar que se introduzca cualquier tipo de sesgo en la arquitectura del modelo y los hiperparámetros utilizados durante el entrenamiento y la evaluación. En general, cuanto más ajuste la configuración según los resultados de sus datos de prueba, menos confiables serán sus resultados. Por lo tanto, debemos limitar nuestras decisiones a los resultados vistos en los conjuntos de datos de entrenamiento y validación.
En esta serie, no usaremos un conjunto de datos de prueba. En su lugar, usaremos el conjunto de datos de prueba como un conjunto de datos de validación y aplicaremos el aumento de datos al conjunto de datos de prueba para que siempre validemos el modelo con datos ligeramente diferentes . Esto evita que sobreajustemos nuestras decisiones en el conjunto de datos de validación. Es un poco como un truco, lo hacemos solo por expedientes y atajos. Para el desarrollo del modelo de producción, debe tratar de apegarse a la receta estándar anterior.
El conjunto de datos que usaremos en esta serie tiene 3680 imágenes en el conjunto de entrenamiento. Si bien esto puede parecer muchas imágenes, queremos asegurarnos de que nuestro modelo no se ajuste demasiado a estas imágenes, ya que entrenaremos el modelo en varias épocas.
En una sola época de entrenamiento, entrenamos el modelo en todo el conjunto de datos de entrenamiento y, por lo general, entrenamos modelos para 60 o más épocas en producción. En esta serie, solo entrenaremos el modelo durante 20 épocas para reducir el tiempo de iteración. Para evitar el sobreajuste , emplearemos una técnica llamada aumento de datos, que se utiliza para generar nuevos datos de entrada a partir de datos de entrada existentes . La idea básica detrás del aumento de datos de las entradas de imágenes es que si cambia la imagen ligeramente, se siente como una imagen nueva para el modelo, pero puede inferir que el resultado esperado es el mismo. Estos son algunos ejemplos del aumento de datos que aplicaremos en esta serie.
Si bien utilizaremos la biblioteca de Torchvision para aplicar el aumento de datos descrito anteriormente, lo alentamos a que evalúe la biblioteca de aumento de datos de Albumentations para tareas de visión. Ambas bibliotecas tienen un amplio conjunto de transformaciones disponibles para datos de imágenes. Personalmente seguimos usando Torch Vision simplemente porque lo empezamos nosotros. Las albumenaciones admiten primitivas de aumento de datos más ricas que pueden alterar simultáneamente la imagen de entrada, así como las anotaciones o máscaras de datos reales. Por ejemplo, si desea cambiar el tamaño o voltear una imagen, debe realizar los mismos cambios en la máscara de segmentación de la realidad del suelo. Las albumenaciones pueden hacer eso por usted desde el primer momento.
En términos generales, ambas bibliotecas admiten transformaciones que se aplican a las imágenes a nivel de píxel o que cambian las dimensiones del espacio de la imagen. La transformación a nivel de píxel se denomina transformación de color en Torchview, y la transformación espacial se denomina transformación geométrica en Torchview.
A continuación, veremos algunos ejemplos de transformaciones geométricas y a nivel de píxel aplicadas por las bibliotecas Torchvision y Albumentations.

Figura 7: Ejemplo de aumento de datos a nivel de píxel aplicado a una imagen mediante diafonía. Fuente: proteína

Figura 8: Ejemplo de aumento de datos aplicado a una imagen mediante transformadas de Torchvision. Fuente: Autor ( Cuaderno )

Figura 9: Ejemplo de transformación de nivel espacial aplicada mediante transformación de proteínas. Fuente: Autor ( Cuaderno )
6.6 Evaluación del rendimiento del modelo
Al evaluar el rendimiento de un modelo, debe comprender cómo se desempeña en las métricas que representan la calidad del rendimiento del modelo en datos reales. Por ejemplo, para una tarea de segmentación de imágenes, queremos saber con qué precisión el modelo puede predecir la clase correcta para un píxel. Por lo tanto, decimos que la precisión de píxel es la métrica de validación para este modelo.
Puede usar su métrica de evaluación como una función de pérdida (¡por qué no optimizar algo que realmente le importa!), excepto que eso no siempre es posible .
Además de la precisión , también realizaremos un seguimiento de la métrica de IoU (también conocida como índice Jaccard ) y la métrica de IoU personalizada que definimos anteriormente.
Para obtener más información sobre las diversas métricas de precisión disponibles para las tareas de segmentación de imágenes, consulte:
- Todas las métricas de segmentación — Kaggle
- Cómo evaluar modelos de segmentación de imágenes
- Evaluar modelos de segmentación de imágenes
6.7 Desventajas de usar la precisión de píxeles como métrica de rendimiento
Si bien la métrica de precisión puede ser una buena opción predeterminada para medir el rendimiento en las tareas de segmentación de imágenes, tiene sus propios inconvenientes que pueden ser importantes según su situación específica.
Por ejemplo, considere una tarea de segmentación de imágenes para identificar los ojos de las personas en una imagen y etiquetar esos píxeles en consecuencia. Por lo tanto, el modelo clasificará cada píxel como uno de los siguientes:
- fondo
- Ojo
Suponga que solo hay 1 persona en cada imagen y que el 98% de los píxeles no corresponden a ojos. En este caso, el modelo simplemente puede aprender a predecir cada píxel como un píxel de fondo y lograr una precisión de píxel del 98 % en la tarea de segmentación. ¡Guau!

Figura 10: Las máscaras de segmentación correspondientes para imágenes de rostros y sus ojos. Puede ver que el ojo es solo una parte muy pequeña de la imagen general. Fuente: Adaptado de Unsplash
En este caso, podría ser una mejor idea usar métricas de IoU o Dice, ya que IoU capturará cuánto fue correcta la predicción y no estará necesariamente sesgada por el área que ocupa cada clase en la imagen original. Incluso podría considerar usar IoU o el coeficiente de dados por clase como métrica. Esto captura mejor el rendimiento del modelo en la tarea en cuestión.
Cuando solo se considera la precisión de píxeles, la precisión y la recuperación del objeto para el que estamos calculando la máscara de segmentación (el ojo en el ejemplo anterior) puede capturar el detalle que estamos buscando.
Ahora que hemos cubierto la mayoría de los fundamentos teóricos de la segmentación de imágenes, tomemos un desvío y veamos las consideraciones relevantes para la inferencia y el despliegue de la segmentación de imágenes para las cargas de trabajo del mundo real.
6.8 Tamaño del modelo y latencia de inferencia
Por último, pero no menos importante, queremos asegurarnos de que nuestro modelo tenga una cantidad razonable de parámetros, pero no demasiados, ya que queremos un modelo pequeño y eficiente. Examinaremos este aspecto con más detalle en futuros artículos relacionados con la reducción del tamaño del modelo utilizando arquitecturas de modelos eficientes .
Lo que importa en términos de latencia de inferencia es la cantidad de operaciones matemáticas (sumas múltiples) que realiza nuestro modelo. Tanto el tamaño del modelo como las adiciones múltiples se pueden mostrar usando el paquete de información de la antorcha. Si bien la adición múltiple es un buen proxy para determinar la latencia del modelo, la latencia puede variar ampliamente entre los backends. La única forma real de determinar cómo se desempeñará un modelo en un backend o dispositivo específico es generar un perfil y compararlo en ese dispositivo específico con el conjunto de entradas que espera ver en un entorno de producción.
from torchinfo import summary
model = nn.Linear(1000, 500)
summary(
model,
input_size=(1, 1000),
col_names=["kernel_size", "output_size", "num_params", "mult_adds"],
col_width=15,
)producción:
====================================================================================================
Layer (type:depth-idx) Kernel Shape Output Shape Param # Mult-Adds
====================================================================================================
Linear -- [1, 500] 500,500 500,500
====================================================================================================
Total params: 500,500
Trainable params: 500,500
Non-trainable params: 0
Total mult-adds (M): 0.50
====================================================================================================
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 2.00
Estimated Total Size (MB): 2.01
====================================================================================================7. Revisión del artículo
Aquí hay un resumen rápido de lo que hemos discutido hasta ahora.
- La segmentación de imágenes es una técnica para dividir una imagen en segmentos (fuente: Wikipedia )
- Hay dos tipos principales de tareas de segmentación de imágenes: segmentación de clase (semántica) y segmentación de objeto (instancia). La segmentación de clases asigna cada píxel de una imagen a una clase semántica. La segmentación de objetos identifica cada objeto individual en una imagen y asigna una máscara a cada objeto único
- Usaremos PyTorch como marco de aprendizaje profundo y el conjunto de datos Oxford IIIT Pet en esta serie de segmentación eficiente de imágenes.
- Hay muchos factores a considerar al elegir el modelo de aprendizaje profundo adecuado para la segmentación de imágenes, incluidos (entre otros) el tipo de tarea de segmentación de imágenes, el tamaño y la complejidad del conjunto de datos, la disponibilidad de modelos previamente entrenados y los recursos informáticos disponibles. Algunas de las arquitecturas de modelos de aprendizaje profundo más populares para la segmentación de imágenes incluyen U-Net, FCN, SegNet y Vision Transformer (ViT).
- La elección de la función de pérdida para las tareas de segmentación de imágenes es importante porque puede tener un impacto significativo en el rendimiento del modelo y la eficiencia del entrenamiento. Para tareas de segmentación de imágenes podemos utilizar cross-entropy loss, IoU loss, dice loss o focal loss (entre otros)
- El aumento de datos es una técnica valiosa para prevenir el sobreajuste, así como para tratar con datos de entrenamiento insuficientes.
- Evaluar el rendimiento del modelo es importante para la tarea en cuestión y esta métrica debe elegirse con cuidado.
- El tamaño del modelo y la latencia de inferencia son métricas importantes a tener en cuenta al desarrollar un modelo, especialmente si tiene la intención de usarlo para aplicaciones en tiempo real, como la segmentación de rostros o la eliminación de ruido de fondo.
En la próxima publicación , veremos una red neuronal convolucional (CNN), creada desde cero con PyTorch, para realizar la segmentación de imágenes en el conjunto de datos Oxford IIIT Pet.