¿Qué es la seguridad de subprocesos?
Seguridad de subprocesos, la explicación en Wikipedia es:
La seguridad de subprocesos es un término en programación, lo que significa que cuando se llama a una función o biblioteca de funciones en un entorno concurrente , puede manejar correctamente las variables compartidas entre múltiples subprocesos , de modo que la función del programa se pueda completar correctamente.
Vamos a desmontar esta definición. Necesitamos resolver los siguientes puntos: 1. Concurrencia 2. Multihilo 3. Variables compartidas
simultaneidad
Cuando se trata de seguridad de subprocesos, una palabra que debe mencionarse es concurrencia.Si no hay concurrencia, entonces no hay problema de seguridad de subprocesos.
que es la concurrencia
Concurrente (Concurrent), en el sistema operativo, se refiere a varios programas en un período de tiempo entre que se inician y se ejecutan y se ejecutan, y todos estos programas se ejecutan en el mismo procesador.
Entonces, ¿cómo logra el sistema operativo esta concurrencia?
Ahora usamos el sistema operativo, ya sea Windows, Linux o MacOS, en realidad es un sistema operativo de tiempo compartido multiusuario y multitarea . Los usuarios que utilizan estos sistemas operativos pueden hacer varias cosas "simultáneamente".
Pero, de hecho, para una computadora con una sola CPU, la CPU solo puede hacer una cosa a la vez. Para que parezca "hacer varias cosas al mismo tiempo", el sistema operativo de tiempo compartido divide el tiempo de la CPU en intervalos de tiempo largos y cortos, es decir, "fracciones de tiempo". A través de la gestión del sistema operativo, este tiempo los cortes se dividen en turnos asignados a cada usuario.
Si un trabajo no ha completado toda la tarea antes de que finalice el intervalo de tiempo, el trabajo se suspenderá, se abandonará la CPU y esperará al siguiente ciclo antes de continuar. En este momento, la CPU se asigna a otro trabajo para usar.
Debido a la alta velocidad de procesamiento de la computadora, siempre que el intervalo de intervalo de tiempo se obtenga correctamente, habrá una "pausa" en medio de un trabajo de usuario desde el uso de un intervalo de tiempo asignado hasta la obtención del siguiente tiempo de CPU. slice, pero el usuario no lo notará, como si todo el sistema estuviera "monopolizado" por él.
Por lo tanto, en una computadora de una sola CPU, parece que "hacemos varias cosas al mismo tiempo", pero en realidad se hacen simultáneamente a través de la tecnología de división de tiempo de la CPU.
Cuando se trata de concurrencia, hay otra palabra que se confunde fácilmente con él, que es paralelismo.
La relación entre concurrencia y paralelismo
Paralelo (Parallel), cuando el sistema tiene más de una CPU, cuando una CPU ejecuta un proceso, otra CPU puede ejecutar otro proceso, y los dos procesos no aprovechan los recursos de la CPU y se pueden realizar al mismo tiempo. llamado Paralelo.
Joe Armstrong, el padre de Erlang, explicó la diferencia entre concurrencia y paralelismo con una imagen más vívida:
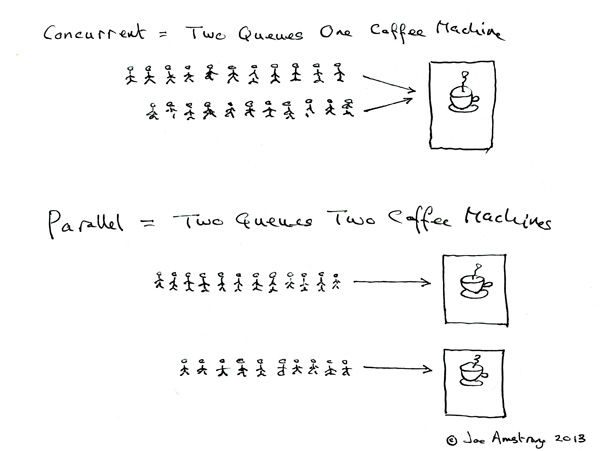
La concurrencia es cuando dos equipos usan una máquina de café alternativamente. Paralelo es cuando dos equipos utilizan dos máquinas de café al mismo tiempo.
Asignada al sistema informático, la máquina de café de la imagen de arriba es la CPU, y los dos equipos se refieren a los dos procesos.
subprocesos múltiples
proceso e hilo
Después de comprender la relación y la diferencia entre concurrencia y paralelismo, volvamos al sistema operativo multitarea de tiempo compartido presentado anteriormente para ver cómo la CPU programa los procesos.
Para que parezca que "hace varias cosas al mismo tiempo", el sistema operativo de tiempo compartido divide el tiempo de la CPU en "fracciones de tiempo" que son básicamente de la misma longitud y longitud. A través de la gestión del sistema operativo, estas se asignan a cada usuario a su vez, utilizados por cada tarea.
En un sistema multitarea, la CPU necesita manejar las operaciones de todos los programas, y cuando el usuario los cambia de un lado a otro, necesita registrar dónde se ejecutan estos programas. En el sistema operativo, cambiar la CPU a otro proceso requiere guardar el estado del proceso actual y restaurar el estado de otro proceso: la tarea que se está ejecutando actualmente se vuelve lista (o suspendida, eliminada) y otra tarea lista seleccionada se convierte en la Tarea actual. El cambio de contexto es un proceso que permite que la CPU registre y restaure el estado de varios programas en ejecución para que pueda completar la operación de cambio.
Durante el cambio de contexto, la CPU deja de procesar el programa que se está ejecutando actualmente y guarda la ubicación específica donde se está ejecutando el programa actual para que pueda continuar ejecutándose más tarde. Desde este punto de vista, el cambio de contexto es un poco como si leyéramos varios libros al mismo tiempo. Mientras cambiamos de libro, necesitamos recordar el número de página de cada libro que estamos leyendo actualmente. En el programa, la información del "número de página" durante el proceso de cambio de contexto se almacena en el bloque de control de proceso (PCB). PCB también se conoce como "marco de interruptor" (switchframe). La información del "número de página" siempre se guardará en la memoria de la CPU hasta que se vuelvan a utilizar.
Para el sistema operativo, una tarea es un proceso (Proceso). Por ejemplo, al abrir un navegador se inicia un proceso de navegador, al abrir un bloc de notas se inicia un proceso de bloc de notas y al abrir dos blocs de notas se inician dos blocs de notas. En este proceso, al abrir un Word se inicia un Proceso de la palabra.
Al cambiar entre múltiples procesos, se requiere un cambio de contexto. Pero el cambio de contexto seguramente consumirá algunos recursos. Entonces, la gente considera si es posible agregar algunas "subtareas" en un proceso, para reducir el costo del cambio de contexto. Por ejemplo, cuando usamos Word, puede realizar al mismo tiempo tipeo, revisión ortográfica, conteo de palabras, etc.. Estas subtareas comparten los mismos recursos de proceso, pero cambiar entre ellas no requiere cambiar de contexto.
Dentro de un proceso, si desea hacer varias cosas al mismo tiempo, debe ejecutar varias "subtareas" al mismo tiempo. Llamamos a estas "subtareas" en los subprocesos del proceso (Thread).
Con el tiempo, las personas han dividido aún más las responsabilidades entre procesos y subprocesos. El proceso se considera la unidad básica de asignación de recursos, el subproceso se considera la unidad básica de ejecución y los recursos se comparten entre varios subprocesos del mismo proceso.
Tome el lenguaje Java con el que estamos más familiarizados, los programas Java se ejecutan en la JVM y cada JVM es en realidad un proceso. Toda la asignación de recursos se basa en el proceso JVM. En este proceso de JVM, se pueden crear muchos subprocesos, los recursos de JVM se comparten entre varios subprocesos y se pueden ejecutar varios subprocesos al mismo tiempo.
variable compartida
La llamada variable compartida se refiere a una variable que puede ser operada por múltiples hilos.
Como mencionamos anteriormente, un proceso es la unidad básica de asignación de recursos y un subproceso es la unidad básica de ejecución. Por lo tanto, múltiples subprocesos pueden compartir parte de los datos en el proceso. En la JVM, las áreas del montón de Java y el área de métodos son áreas de datos compartidas por varios subprocesos. Es decir, múltiples subprocesos pueden operar los mismos datos almacenados en el montón o área de método. Entonces, en otras palabras, las variables almacenadas en el montón y el área de método son variables compartidas en Java.
Entonces, ¿qué variables en Java se almacenan en el montón, qué variables se almacenan en el área de método y qué variables se almacenan en la pila?
Variables de clase, variables miembro y variables locales
Hay tres tipos de variables en Java, a saber, variables de clase, variables miembro y variables locales. Se almacenan en el área de métodos, la memoria de pila y la memoria de pila de la JVM, respectivamente.
/**
* @author Hollis
*/
public class Variables {
/**
* 类变量
*/
private static int a;
/**
* 成员变量
*/
private int b;
/**
* 局部变量
* @param c
*/
public void test(int c){
int d;
}
}
Entre las tres variables definidas anteriormente, la variable a es una variable de clase, la variable b es una variable miembro y las variables c y d son variables locales.
Entonces, las variables a y b son variables compartidas y las variables c y d son variables no compartidas. Por lo tanto, si se encuentra con un escenario de subprocesos múltiples, debe considerar la seguridad de subprocesos para las operaciones de las variables a y b, pero no necesita considerar la seguridad de subprocesos para las operaciones de los subprocesos c y d.
resumen
Después de comprender algunos conocimientos básicos, regresemos y veamos la definición de seguridad de subprocesos:
La seguridad de subprocesos es un término en programación, lo que significa que cuando se llama a una función o biblioteca de funciones en un entorno concurrente , puede manejar correctamente las variables compartidas entre múltiples subprocesos , de modo que la función del programa se pueda completar correctamente.
Ahora sabemos qué es un entorno concurrente, qué son hilos múltiples y qué son variables compartidas. Entonces, siempre que prestemos atención al escribir código de subprocesos múltiples, podemos asegurarnos de que las funciones del programa se puedan ejecutar correctamente.
Luego viene el problema, la definición dice que la seguridad de subprocesos puede manejar correctamente las variables compartidas entre múltiples subprocesos, para que la función del programa se pueda completar correctamente .
¿Qué problemas existen en escenarios de subprocesos múltiples que pueden causar que las variables compartidas no se manejen correctamente? ¿Qué problemas existen en un escenario de subprocesos múltiples que evitarían que el programa se complete correctamente? ¿Cómo resolver estos problemas que afectan la "corrección" en escenarios de subprocesos múltiples? ¿Cuáles son los principios de realización de cada medio para resolver estos problemas?