Un algoritmo de aprendizaje automático es un modelo generado a partir de datos, es decir, un algoritmo para el aprendizaje (en lo sucesivo, también denominado algoritmo). Aportamos experiencia al algoritmo, y este puede generar modelos basados en datos empíricos. Ante una nueva situación, el modelo nos proporcionará resultados de juicio (predicción). Por ejemplo, juzgamos a un niño como un buen candidato para un atleta basándonos en "alta, piernas largas y peso ligero". Cuantifica estos datos y dáselo a la computadora, y generará un modelo en base a ello.Al enfrentarse a una nueva situación (juzgar si otro niño puede convertirse en atleta), el modelo emitirá un juicio correspondiente.
características de los datos
Por ejemplo, para probar un grupo de niños, primero se deben obtener los datos básicos de este grupo de niños. Este conjunto de datos incluye datos como la altura, la longitud de las piernas y el peso Estos elementos que reflejan el rendimiento o la naturaleza de un objeto (o un evento) en un aspecto determinado se denominan atributos o características . El valor específico, como "188 cm" que refleja la altura, es el valor de la característica o el valor del atributo . La recopilación de este conjunto de datos "(altura=188 cm, longitud de la pierna=56 cm, peso=46 kg), ..., (altura=189 cm, longitud de la pierna=55 cm, peso=48 kg)" se denomina un conjunto de datos , donde los datos de cada niño se denominan muestra.
El proceso de aprender un modelo a partir de datos se llama aprendizaje o entrenamiento. Los datos utilizados en el proceso de entrenamiento se denominan datos de entrenamiento, cada muestra que contiene se denomina muestra de entrenamiento y el conjunto de muestras de entrenamiento se denomina conjunto de entrenamiento.
Por supuesto, si desea obtener un modelo, además de tener datos, también necesita adjuntar las etiquetas correspondientes a las muestras. Por ejemplo, "(((alto, de piernas largas, liviano), buen tipo)"). Las "buenas semillas" aquí son las etiquetas, y generalmente nos referimos a las muestras con etiquetas como "ejemplos".
Después de aprender el modelo, para probar el efecto del modelo, debe probarse, y las muestras probadas se denominan muestras de prueba. Al ingresar una muestra de prueba, no se proporciona la etiqueta de la muestra de prueba (categoría objetivo), pero el modelo determina la etiqueta de la muestra (a qué categoría pertenece). Comparando la diferencia entre la etiqueta predicha de la muestra de prueba y la etiqueta de la muestra real, se puede calcular la precisión del modelo.
La mayoría de los algoritmos de aprendizaje automático se derivan de la práctica diaria. El algoritmo del vecino más cercano K es uno de los algoritmos de aprendizaje automático más simples, que se usa principalmente para dividir objetos en clases conocidas y se usa ampliamente en la vida. Por ejemplo, si el entrenador quiere seleccionar un grupo de corredores de fondo, ¿cómo debe seleccionarlo? Es posible que esté utilizando el algoritmo K-vecino más cercano y seleccionará candidatos que sean altos, de piernas largas, livianos, con una circunferencia de rodilla y tobillo pequeña, tendones de Aquiles obvios y arcos
grandes. Sentirá que esos niños tienen el potencial de los atletas, o que las características de estos niños son muy parecidas a las de los atletas.
La idea básica del algoritmo del vecino más cercano K
La esencia del algoritmo del vecino más cercano K es asignar el objeto especificado de acuerdo con el conocido特征值分类 . Por ejemplo, al ver a un padre y un hijo, en circunstancias normales, al juzgar sus edades, uno puede decir inmediatamente cuál es el padre y cuál es el hijo. Esto es a través del atributo de edad 特征值来划分.
El ejemplo anterior es la clasificación más simple basada en una sola dimensión de característica. En escenarios reales, la situación puede ser más complicada, con múltiples dimensiones de característica. Por ejemplo, para clasificar un video deportivo, determine si el video es un juego de tenis de mesa o de fútbol.
Para determinar la clasificación, es necesario definir las características. Aquí se definen dos características, una es la acción de "agitar" del atleta y la otra es la acción de "patear" del atleta. Por supuesto, no podemos clasificar un video como un "juego de ping pong" solo por ver la acción de "saludar", porque sabemos que algunos jugadores de fútbol están acostumbrados a saludar para comunicarse con sus compañeros en el campo deportivo. Del mismo modo, no podemos clasificar un video como un "partido de fútbol" solo por ver una "patada", ya que algunos jugadores de tenis de mesa usan "patadas" para expresar sus emociones.
Contamos la cantidad de acciones de "saludar" y "patear" en el video dentro de un cierto período de tiempo y encontramos las siguientes reglas:
- En el video de un partido de tenis de mesa, hay muchas más "olas" que "patadas".
- Los videos de los partidos de fútbol muestran muchas más "patadas" que "olas".
De acuerdo al análisis de un grupo de videos se obtienen los datos que se muestran en la Tabla 20-1.
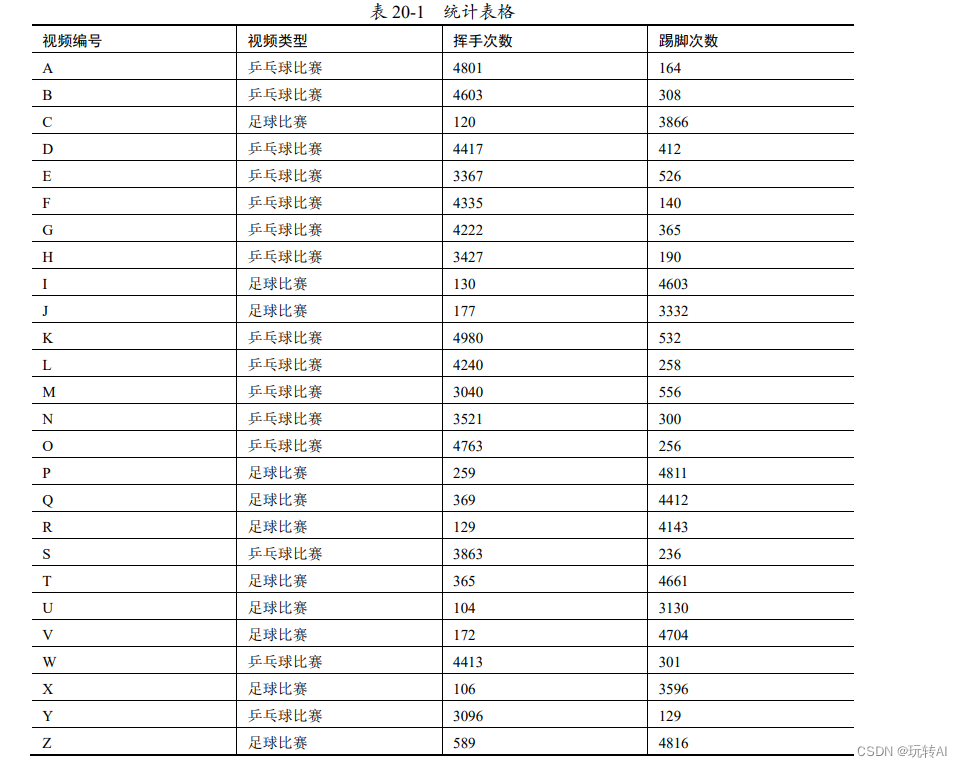
Para facilitar la observación, los datos anteriores se dibujan como un diagrama de dispersión, como se muestra en la figura 20-1.
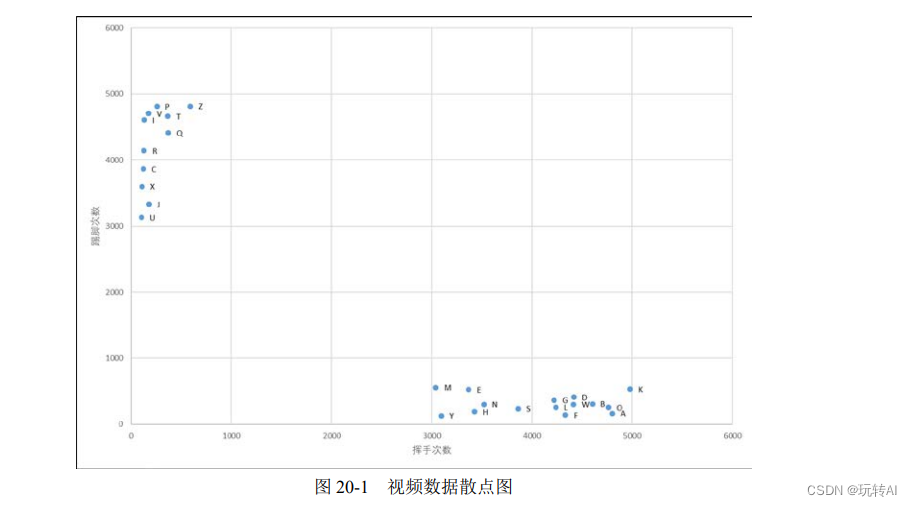
Como se puede ver en la Figura 20-1, los puntos de datos exhiben características de agrupamiento:
- Los puntos de datos en el video del juego de tenis de mesa se recopilan en el área donde las coordenadas del eje x son [3000, 5000] y las coordenadas del eje y son [1,500].
- Los puntos de datos en el video del partido de fútbol están agrupados en el área donde las coordenadas del eje y son [3000, 5000] y las coordenadas del eje x son [1,500].
En este momento, hay una prueba de video y las estadísticas muestran que hay 2000 acciones de "saludar" y 100 acciones de "patear". Si su ubicación está marcada en la Figura 20-1, se puede encontrar que el vecino más cercano a la ubicación de la prueba de video es un video de un juego de tenis de mesa, por lo que se puede juzgar que el video es un video de un juego de tenis de mesa.
El ejemplo anterior es un ejemplo extremo, en blanco y negro, pero los datos de clasificación reales a menudo tienen muchos parámetros y no es tan fácil de juzgar. Por lo tanto, para mejorar la confiabilidad del algoritmo, se seleccionarán
k puntos vecinos durante la implementación, y a qué clase pertenece más entre estos k puntos, y luego se divide el punto actual a identificar en qué clase. Por conveniencia de juicio,
el valor de k suele ser un número impar, que es la misma razón por la cual los miembros de la junta generalmente se organizan como un número impar para obtener un resultado de votación claro.
Por ejemplo, se sabe que un conocido artista gemelo A y B se parece mucho. Si desea juzgar si la persona en una imagen T es el artista A o el artista B, los pasos específicos para implementarlo utilizando el K-más cercano algoritmo vecino son los siguientes:
(1) Recoge 100 fotos del artista A y del artista B cada uno.
(2) Determina varias características importantes para identificar a las personas y usa estas características para etiquetar las fotos de los artistas A y B.
Por ejemplo, según ciertas 4 características, cada foto se puede expresar como [156, 34, 890, 457] (es decir, un punto de muestra). De acuerdo con el método anterior,
se obtienen un conjunto de datos FA de 100 fotos del artista A y un conjunto de datos FB de 100 fotos del artista B. En este momento, los elementos en los conjuntos de datos FA y FB
tienen la forma de los valores propios mencionados anteriormente, y cada conjunto tiene 100 de tales valores propios. En resumen, utiliza valores numéricos para representar fotos y obtiene
el conjunto de características numéricas (conjunto de datos) FA del artista A y el conjunto de características numéricas FB del artista B.
(3) Calcule la característica de la imagen T a reconocer y use el valor de la característica para representar la imagen T. Por ejemplo, el valor de característica TF de la imagen T puede
ser [257, 896, 236, 639].
(4) Calcular la distancia entre el valor propio TF de la imagen T y cada valor propio en FA y FB.
(5) Encuentre los puntos de muestra que producen las k distancias más cortas (encuentre los k vecinos más cercanos a T), cuente el número de puntos de muestra que pertenecen a FA y FB entre los k puntos de muestra, y qué conjunto de datos tiene más puntos de muestra, determine qué artista es la imagen T.
Por ejemplo, encuentre 11 puntos más cercanos, entre estos 11 puntos, hay 7 puntos de muestra que pertenecen a FA y 4 puntos de muestra que pertenecen a FB, entonces se determina que el artista en esta imagen T es A; de lo contrario, si Entre estos 11 puntos, 6 puntos de muestra pertenecen a FB y 5 puntos de muestra pertenecen a FA, entonces se determina que el artista en esta imagen T es B.
Lo anterior es la idea básica del algoritmo del vecino más cercano K.
pensamiento computacional
La "sensación" de una computadora se logra a través de cálculos lógicos y cálculos numéricos. Por lo tanto, en la mayoría de los casos, necesitamos procesar numéricamente los objetos a procesar por la computadora y cuantificarlos en valores específicos para su procesamiento posterior.
Después de obtener los valores propios de cada muestra, el algoritmo K-vecino más cercano calcula la distancia entre los valores propios de las muestras a identificar y los valores propios de cada muestra de clasificación conocida, y luego encuentra las k muestras vecinas más cercanas, según las k muestras vecinas más próximas La clasificación de la muestra con mayor proporción pertenece a determinar la clasificación de la muestra a identificar.
01. Normalización
Para casos simples, es suficiente calcular directamente la distancia (brecha) del valor propio.
Por ejemplo, en cierto drama de cine y televisión, se ha sabido por medios técnicos que la altura del sospechoso es de 186 cm y la altura de la víctima es de 172 cm. Ante la policía, tanto A como B afirmaron ser víctimas.
En este punto, podemos determinar quién es la verdadera víctima midiendo la altura de los dos:
- La altura de A es 185 cm, la distancia desde la altura del sospechoso = 186-185 = 1 cm, y la distancia desde la altura de la víctima = 185-172 = 7 cm. La altura de A está más cerca de la del sospechoso, por lo que se confirma que A es el sospechoso.
- La altura de B es 173 cm, la distancia desde la altura del sospechoso = 186-173 = 13 cm y la distancia desde la altura de la víctima = 173-172 = 1 cm. La altura de B es más cercana a la de la víctima, por lo que B se identifica como la víctima.
El ejemplo anterior es un caso especial muy simple. En escenarios reales, se pueden requerir más parámetros para el juicio.
Por ejemplo, en un drama de cine y televisión extranjero, la policía supo por medios técnicos que el sospechoso medía 180 cm y le faltaba un dedo; la víctima medía 173 cm y tenía los diez dedos intactos. En ese momento, A y B, que acudieron a rendirse, afirmaron ser víctimas.
Cuando hay múltiples parámetros, estos parámetros generalmente se forman en una lista (matriz) para un juicio integral. En este ejemplo, (altura, número de dedos) se utiliza como característica.
Por lo tanto, el sospechoso tiene valores propios de (180, 9) y la víctima tiene valores propios de (173, 10).
En este punto, se pueden hacer los siguientes juicios para los dos:
- A mide 175 cm de altura y no tiene un dedo.El valor propio de A es (175, 9).
- La distancia entre A y el valor característico del sospechoso = (180-175) + (9-9) = 5
- La distancia entre A y el valor característico de la víctima = (175-173) + (10-9) = 3
En este momento, el valor propio de A está más cerca de la víctima y se determina que A es la víctima.
- La altura de B es 178 cm y sus diez dedos están sanos. El valor propio de B es (178, 10).
- La distancia entre B y el valor característico del sospechoso = (180-178) + (10-9) = 3
- La distancia entre B y el valor característico de la víctima = (178-173) + (10-10) = 5
En este momento, los valores propios de B y el sospechoso están más cerca, y se concluye que B es el sospechoso.
Por supuesto, sabemos que los resultados anteriores son incorrectos . Debido a que la altura y el número de dedos tienen diferentes dimensiones (pesos), los pesos entre los diferentes parámetros deben tenerse en cuenta al calcular la distancia desde el valor de la característica. Por lo general, debido a razones como las dimensiones inconsistentes de cada parámetro , es necesario procesar los parámetros para que todos los parámetros tengan el mismo peso.
En general, es suficiente para normalizar los parámetros. Al normalizar, el valor propio generalmente se divide por el valor máximo (o la diferencia entre el valor máximo y el valor mínimo) de todos los valores propios .
Por ejemplo, en el ejemplo anterior, la altura se divide por la altura máxima de 180 (cm), y el número de dedos de cada persona se divide por el número máximo de dedos 10 (10 dedos) para obtener un nuevo valor de característica. El método de cálculo es:
Rasgos normalizados = (altura de cada persona/altura máxima 180, número de dedos/índice largo de la mano 10)
Por lo tanto, después de la normalización:
- El valor de característica del sospechoso es (180/180, 9/10) = (1, 0,9)
- El valor característico de la víctima es (173/180, 10/10) = (0,96, 1)
En este punto, los dos pueden juzgarse en función de los valores propios normalizados:
- El valor característico de A es (175/180, 9/10)=(0.97, 0.9)
- La distancia entre A y el valor característico del sospechoso = (1-0.97) + (0.9-0.9) = 0.03
- La distancia entre A y el valor característico de la víctima = (0.97-0.96) + (1-0.9) = 0.11
En este momento, los valores propios de A y el sospechoso están más cerca, y se concluye que A es el sospechoso.
-
El valor característico de B es (178/180, 10/10)=(0.99, 1)
-
La distancia de valor propio entre B y el sospechoso = (1-0.99) + (1-0.9) = 0.11
-
Distancia de valores propios entre B y la víctima = (0.99-0.96) + (1-1) = 0.03
En este momento, los valores propios de B y la víctima están más cerca, y se concluye que B es la víctima.
02. Cálculo de distancia
En la discusión anterior, calculamos la distancia varias veces. El método utilizado es primero restar los elementos correspondientes en los valores propios y luego sumarlos.
Por ejemplo, hay valores propios A(185, 75) y B(175, 86) en forma de (altura, peso), y la distancia entre C(170, 80) y el valor propio A y el valor propio B se juzga a continuación :
- Distancia entre C y A = (185-170) + (75-80) = 15+(-5) =10
- Distancia de C a B = (175-170) + (86-80) = 5+6 = 11
Mediante el cálculo, la distancia entre C y A es más cercana, por lo que C se clasifica como la categoría a la que pertenece A.
Por supuesto, sabemos que el juicio anterior es incorrecto , porque hay un número negativo al calcular la distancia entre C y A, que compensa una parte del número positivo. Entonces, para evitar este tipo de compensación positiva y negativa, generalmente calculamos la suma de valores absolutos :
- La distancia entre C y A = |185-170|+|75-80| = 15+5 = 20
- Distancia entre C y B = |175-170|+|86-80| = 5+6 = 11
Después de tomar el valor absoluto y luego sumar, se calcula que la distancia entre C y B es más cercana, y C se clasifica como la categoría a la que pertenece B. Esta distancia expresada por la suma de valores absolutos se llama
曼哈顿距离.
Calcular la distancia de esta manera es básicamente suficiente, pero hay mejores formas. Por ejemplo, se puede introducir una forma de calcular sumas de cuadrados. El método de cálculo en este momento es:

La forma más general es calcular la raíz cuadrada de la suma de cuadrados. Esta distancia es la distancia euclidiana ampliamente utilizada. Su método de cálculo es:
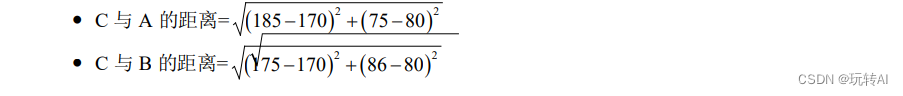
Después de leerlo, intente usar su propia comprensión del algoritmo vernáculo K-vecindario, ¡nos vemos en el área de comentarios! ! !