Escribí un blog sobre la tabla de secuencias hace algún tiempo, http://t.csdn.cn/0gCRp
Las tablas de secuencias a veces tienen algunas desventajas inevitables:
pregunta:1. Inserción y eliminación en el medio / cabeza, la complejidad del tiempo es O(N)2. Para aumentar la capacidad, debe solicitar un nuevo espacio, copiar datos y liberar espacio antiguo. Habrá mucho consumo.3. El aumento de la capacidad es generalmente un aumento de 2 veces, y es probable que se desperdicie una cierta cantidad de espacio. Por ejemplo, la capacidad actual es 100 , y cuando esté llena, se incrementará a 200. Seguimos insertando 5 datos y no se insertarán datos más tarde, por lo que se desperdiciarán 95 espacios de datos.
1. El concepto, la estructura y las ventajas y desventajas de la lista enlazada simple
1.1 Concepto
1.2 Estructura de una lista enlazada simple
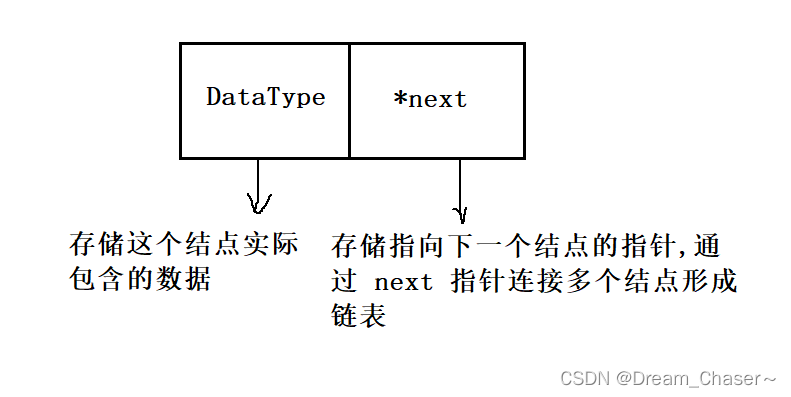
La lista de enlaces simples es una estructura lineal compuesta por una serie de nodos, cada nodo contiene dos campos: campo de datos y campo de puntero .
El campo de datos se usa para almacenar datos y el campo de puntero se usa para almacenar el puntero del siguiente nodo. El nodo principal de la lista enlazada individualmente apunta al primer nodo y el campo de puntero del último nodo está vacío.
La estructura de un nodo:
Estructura física: En la memoria real, la apariencia real.
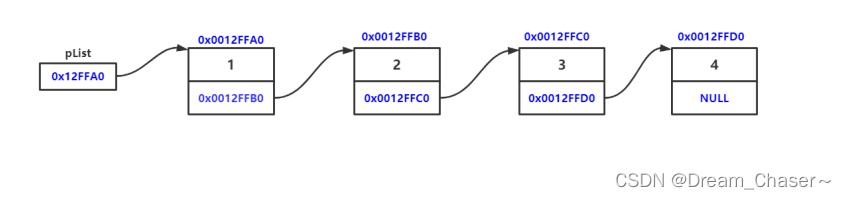
1.3 Ventajas y desventajas de la lista enlazada única
La lista de enlaces simples es una estructura de datos común, tiene las siguientes ventajas y desventajas:
ventaja:
- Alta eficiencia de las operaciones de inserción y eliminación: dado que los nodos de la lista enlazada individualmente contienen punteros al siguiente nodo, al insertar y eliminar nodos, solo se debe modificar el puntero del puntero y no hay necesidad de mover un gran número de elementos de datos, por lo que la eficiencia es alta.
- Alta utilización del espacio: los nodos de la lista enlazada individualmente solo contienen dos partes, datos y punteros, y no es necesario preasignar espacio de memoria, por lo que la utilización del espacio es relativamente alta.
- Longitud variable: la longitud de la lista enlazada individualmente se puede aumentar o reducir dinámicamente según las necesidades, y no es necesario predefinir el tamaño de la matriz, que tiene una mayor flexibilidad.
defecto:
- Baja eficiencia de acceso aleatorio: dado que los nodos de la lista enlazada individualmente solo contienen punteros al siguiente nodo, es imposible acceder directamente al nodo antes de un determinado nodo. Debe atravesar del nodo principal al nodo, por lo que el acceso aleatorio la eficiencia es baja.
- Desperdicio de espacio de almacenamiento: dado que cada nodo de la lista de enlaces únicos necesita almacenar el puntero del siguiente nodo, en el caso de almacenar la misma cantidad de datos, la lista de enlaces únicos requiere más espacio de almacenamiento.
- Pérdida de información de enlace: Solo hay un puntero al siguiente nodo en la lista enlazada individualmente, y el nodo anterior no se puede acceder directamente, por lo tanto, cuando es necesario recorrer la lista enlazada en sentido inverso o eliminar un nodo, es necesario para guardar el puntero del nodo anterior, de lo contrario la operación no se completará.
2. Implementación de lista única enlazada
Cada función de interfaz de una sola lista enlazada
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int SLTDataType;//这样做的目的是为了增加代码的可读性和可维护性,以及提高代码的可移植性,
//因为如果将来需要更改 SLTDataType 的类型,只需要在 typedef 语句中修改一处即可,
// 如果我们在程序的其他地方需要修改 SLTDataType 的类型,
//只需在 typedef 语句中修改 int 为其他类型即可,不需要修改其他代码。
//typedef int SLTADataType;
typedef struct SListNode //--single Linked List
{
SLTDataType data;//成员变量
struct SListNode* next;
}SLTNode;
void SLTPrint(SLTNode* phead);
//void SLPushFront(SLTNode* pphead,SLTDataType x);
void SLPushFront(SLTNode** pphead, SLTDataType x);//头部插入
//void SLPushBack(SLTNode* phead, SLTDataType x);
void SLPushBack(SLTNode** pphead, SLTDataType x);//尾部插入
void SLPopFront(SLTNode** pphead);//头部删除
void SLPopBack(SLTNode** pphead);//尾部删除
//单链表查找
SLTNode* STFind(SLTNode* phead, SLTDataType x);
//单链表pos之前插入
void SLInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
//单链表pos之后插入
void SLInsertAfter(SLTNode* pos, SLTDataType x);
//单链表pos位置删除
void SLErase(SLTNode** pphead, SLTNode* pos);
//单链表pos之后删除
void SLEraseAfter(SLTNode* phead);2.1 Definición de nodos
Abreviatura en inglés:
El inglés de la lista enlazada individual es: Lista enlazada única -- abreviada como SL
El inglés de la tabla de secuencias es: Tabla de secuencias -- abreviada como Seq
El ingles del nodo es: nodo
Las principales funciones de typedef son: se utiliza principalmente para mejorar la legibilidad y la mantenibilidad del código, de modo que la legibilidad del código sea mejor, porque el nombre SLTDataType explica el significado del tipo de la variable x, y de forma más concisa, alias más claros, que hacen que el código sea más legible y mantenible.
typedef int SLTDataType;
typedef struct SListNode //--single Linked List
{
SLTDataType data;//成员变量
struct SListNode* next;
}SLTNode;Define una estructura de nodos de lista vinculados individualmente SLTNode, que contiene dos variables miembro: una data variable int denominada y un puntero al siguiente nodo denominado. SLTDataTypenext
2.2 Impresión de lista enlazada
"La esencia de la asignación de punteros es copiar la dirección de una variable de puntero a otra variable de puntero"
int *p1, *p2;
p1 = (int*)malloc(sizeof(int)); // 为p1分配内存
*p1 = 10; // 设置p1指向的内存的值为10
p2 = p1; // 将p1的地址赋值给p2En el código anterior, tanto p1 como p2 son variables de puntero. p1 se asigna a la memoria y apunta a esa memoria. La línea de código p2 = p1 copia la dirección de p1 a p2, de modo que p2 también apunta a la memoria a la que apunta p1.
Por lo tanto, después de la asignación del puntero, las dos variables de puntero apuntan al mismo bloque de memoria, y el valor de acceder a la memoria a través de cualquier variable de puntero será el mismo.
La asignación de puntero no copia el contenido de la memoria al que apunta el puntero , sino que sólo copia el valor de la dirección en la variable del puntero .
dibujo:
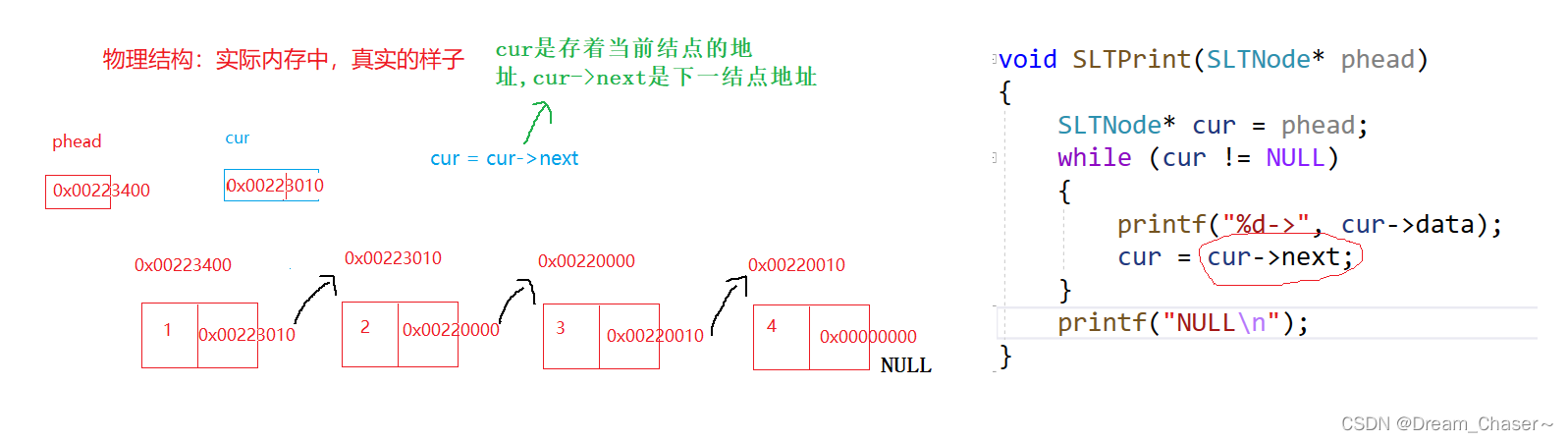 Código:
Código:
//函数的作用是遍历单链表,并将每个节点的数据元素打印到屏幕上。
void SLTPrint(SLTNode* phead)//参数是一个指向 SLTNode 类型的指针 phead,表示单链表的头节点。
{
SLTNode* cur = phead;//头结点存储的地址给cur指针。
while (cur != NULL)//使用一个while循环对单链表进行遍历,循环条件为 cur 不为 NULL。
{ //cur 可以表示当前正在处理的节点的地址,
//通过访问 cur->data 和 cur->next 成员变量,可以获取当前节点的数据元素和下一个节点的地址
printf("%d->", cur->data);
cur = cur->next;//cur是存着当前结点的地址,cur->next是下一结点地址
}
printf("NULL\n");
}
2.3 Crear un nuevo nodo
SLTNode* BuyLTNode(SLTDataType x)//表示要创建的节点的数据元素。
//函数的作用是创建一个新的单链表节点,并将其初始化为包含数据元素 x 的节点。
{
//SLTNode node;//这样是不行,处于不同的空间,出了作用域是会销毁的。
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));//使用malloc函数动态分配了一个大小为SLTNode的内存块,
//并将其强制转换为 SLTNode 指针类型,即创建了一个新的节点。
if (newnode == NULL)
{
perror("malloc fail");
return NULL;
}
//需要注意的是,在使用 malloc 函数动态分配内存时,需要手动释放内存,否则会导致内存泄漏
//因此,在创建单链表节点后,我们应该在适当的时候使用 free 函数释放节点所占用的内存
newnode->data = x;
newnode->next = NULL;
return newnode;//返回的是一个结点的地址
}Lo que hace esta función es crear un nuevo nodo de lista vinculado individualmente e inicializarlo para que contenga el elemento de datos x. El proceso de implementación específico consiste en asignar dinámicamente un bloque de memoria mediante la función malloc y luego convertirlo en el tipo de puntero SLTNode, es decir, se crea un nuevo nodo. Luego establezca el miembro de datos del nodo en x, el siguiente miembro en NULL y finalmente devuelva la dirección del puntero del nuevo nodo.
Cabe señalar que cuando se usa la función malloc para asignar memoria dinámicamente, la memoria debe liberarse manualmente, de lo contrario, se producirán fugas de memoria. Por lo tanto, después de crear un nodo de lista enlazada individualmente, deberíamos usar la función libre para liberar la memoria ocupada por el nodo en el momento apropiado.
2.4 Enchufe de cola de lista enlazada única
Código de error 1:
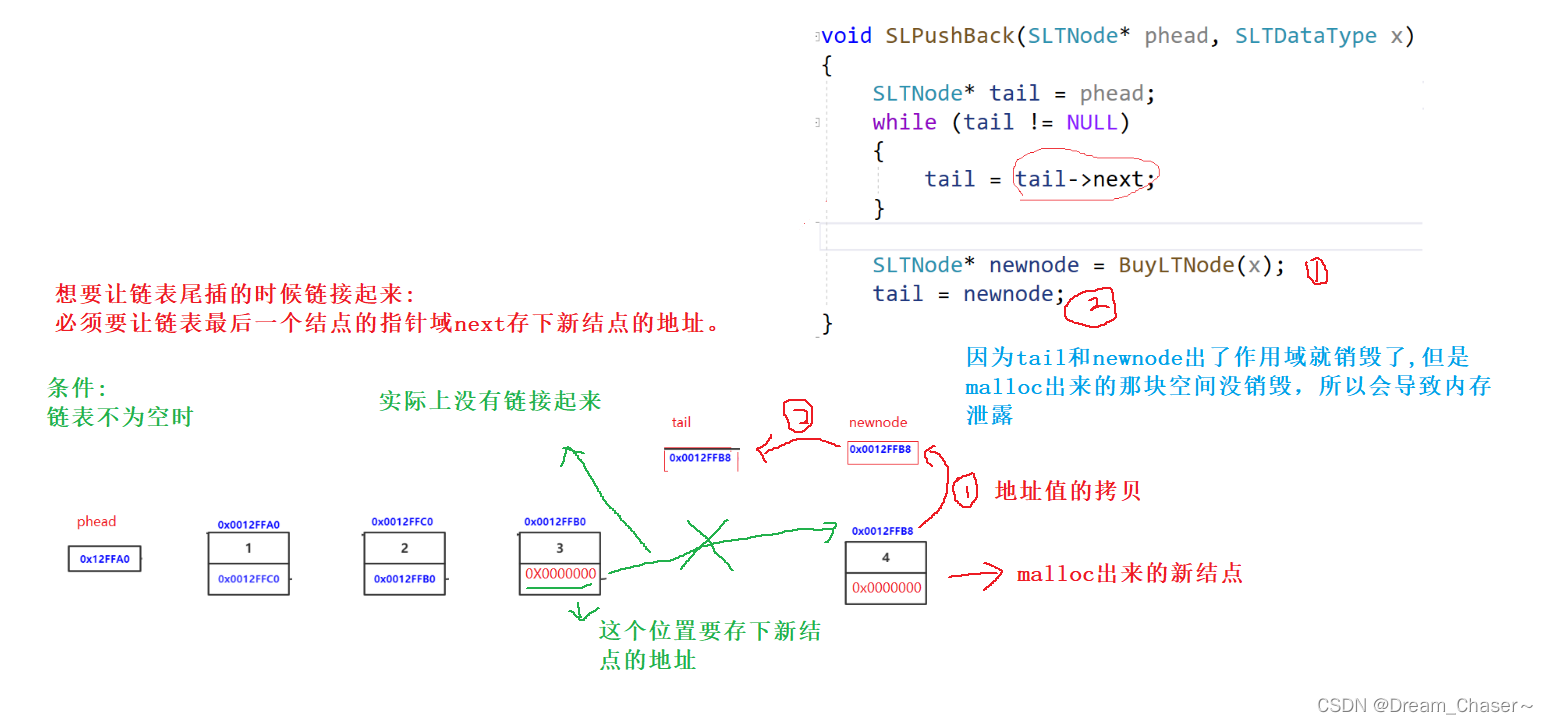
void SLPushBack(SLTNode* phead, SLTDataType x)
{ SLTNode* tail = phead; while (cola != NULL) { cola = cola->siguiente; }
SLTNode* newnode = BuyLTNode(x);
tail = newnode;//Este lugar no está vinculado
}
1. La lista vinculada no está vinculada
2. La variable de puntero se destruye fuera del alcance y la memoria se pierde
Agregue el conocimiento de las fugas de memoria:
Si no se utiliza la función free para liberar el espacio de memoria asignado por la función malloc, estos espacios de memoria siempre ocuparán recursos del sistema hasta el final del programa o el reinicio del sistema operativo.
Cuando finalice el programa, el sistema operativo recuperará todo el espacio de memoria utilizado por el programa, incluido el espacio no liberado por la función libre . Sin embargo, durante la ejecución del programa , estos espacios de memoria no liberados siempre ocuparán recursos del sistema , lo que puede provocar el agotamiento de los recursos de memoria del sistema , afectando así la estabilidad y el rendimiento del sistema.
Por lo tanto, para evitar fugas de memoria, los desarrolladores deben usar explícitamente la función gratuita en el programa para liberar el espacio de memoria que ya no se usa, a fin de garantizar el uso efectivo de los recursos del sistema.
Código de error 2:
void SLPushFront(SLTNode** pphead, SLTDataType x);
void SLPushBack(SLTNode* phead, SLTDataType x);
void TestSList1()
{ SLTNode* plist = NULL; SLPushFront(&plist,1); SLPushFront(&plist,2); SLPushFront(&plist,3); SLPushFront(&plist,4);SLTPrint(plist);
SLPushBack(plist, 5);//Aquí hay un puntero de primer nivel
SLTPrint(plist);}
void SLPushBack(SLTNode* phead, SLTDataType x)
{ SLTNode* tail = phead; while (cola->siguiente!= NULL) { cola = cola->siguiente; }
SLTNode* newnode = BuyLTNode(x);
cola->siguiente = nuevonodo;
}
En este caso, la cabeza se conecta primero y luego la cola. El puntero de nivel se puede pasar más tarde, pero los parámetros son uniformes y no se pueden escribir.Para dos funciones idénticas, el puntero de primer nivel se pasa y el puntero de segundo nivel se pasa más tarde.
Así que pase el puntero secundario constantemente.
El requisito previo para esta situación es que la lista enlazada no esté vacía y que la siguiente estructura se pueda modificar directamente para guardar la dirección del nuevo nodo.
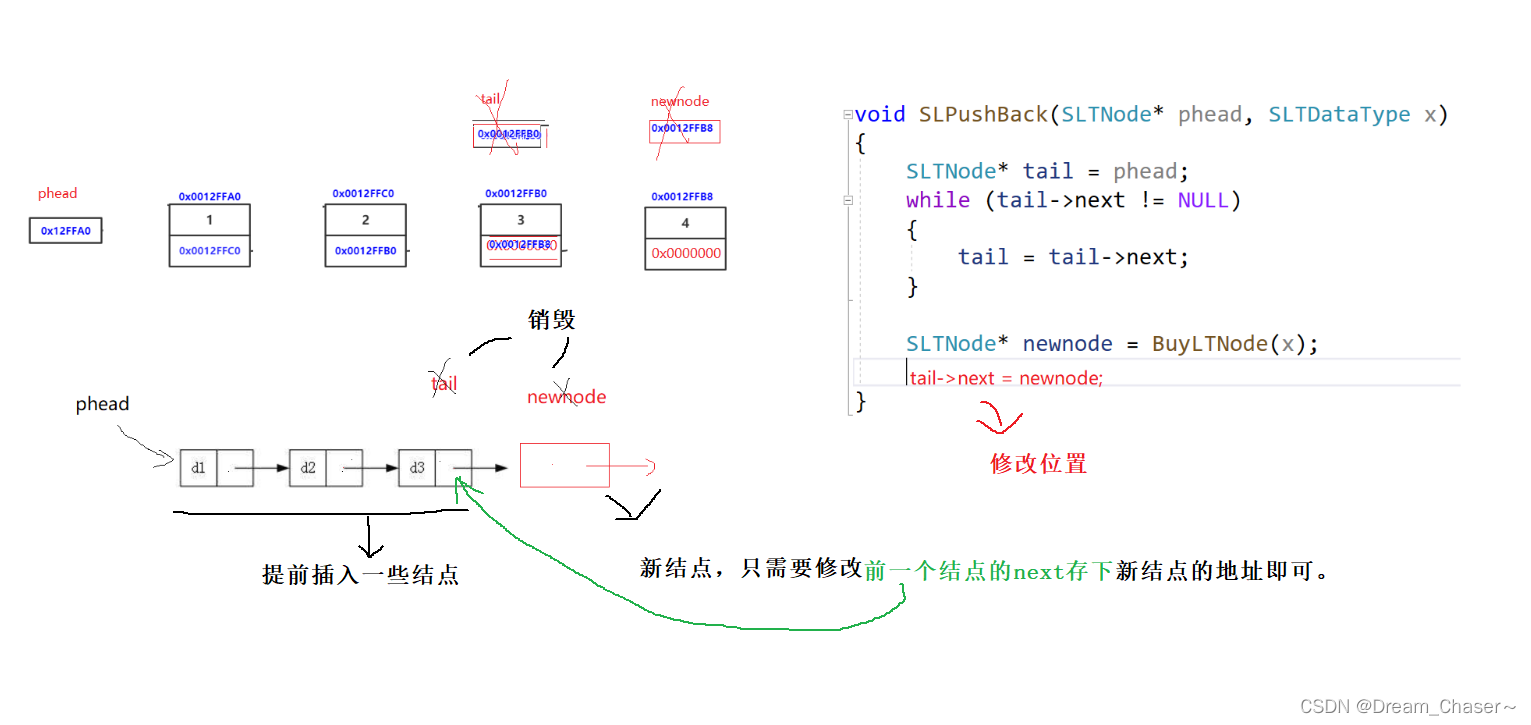
implementar:
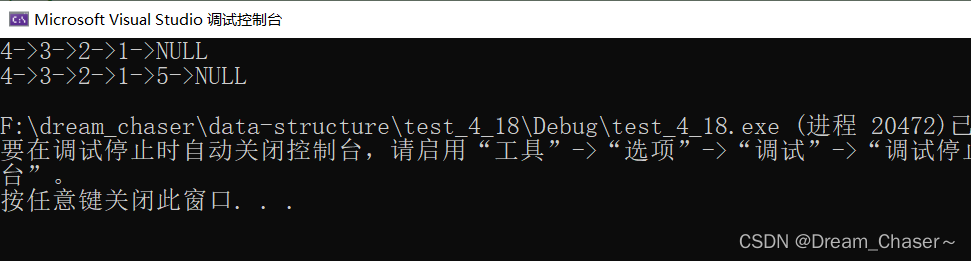
Código de error 3:
dibujo:
void SLPushFront(SLTNode** pphead, SLTDataType x);
void SLPushBack(SLTNode* phead, SLTDataType x);void TestSList2()
{ SLTNode* plist = NULL; SLPushBack(plista, 1); SLPushBack(plista, 2); SLTImprimir(plista); }void SLPushBack(SLTNode* phead, SLTDataType x)
{ SLTNode* newnode = BuyLTNode(x);
if (phead == NULL)
{ phead = newnode; } else { SLTNode* tail = phead; while (cola->siguiente!= NULL) { cola = cola->siguiente; }
cola->siguiente = nuevonodo;
}
}
producción:
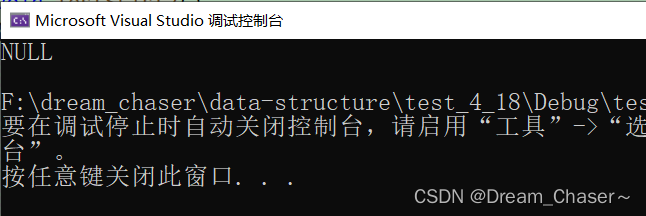
Enumerar tantos casos incorrectos y luego ir al caso correcto:
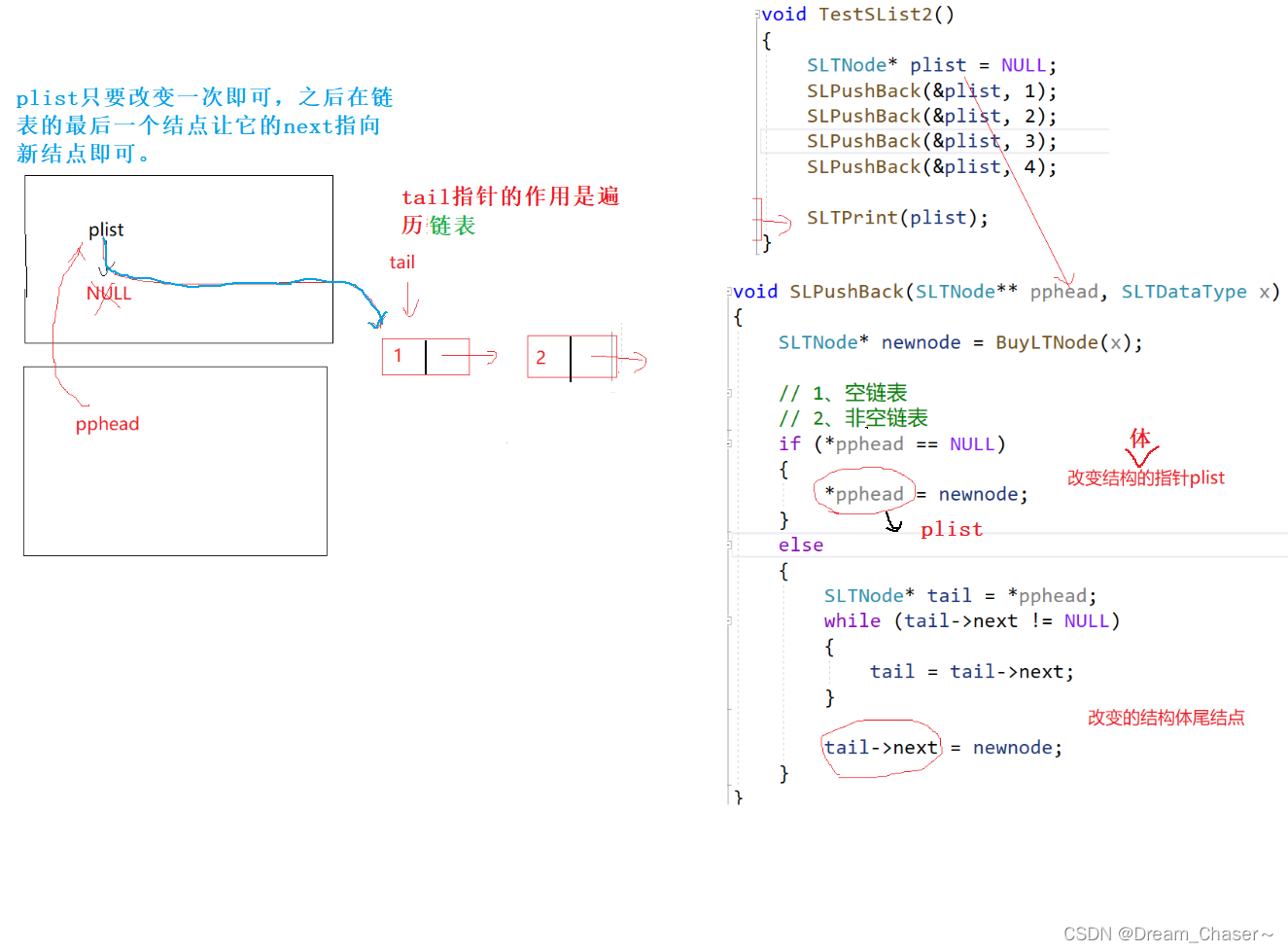
void SLPushBack(SLTNode** pphead, SLTDataType x)
void TestSList2()
{
SLTNode* plist = NULL;
SLPushBack(&plist, 1);
SLPushBack(&plist, 2);
SLPushBack(&plist, 3);
SLPushBack(&plist, 4);
SLTPrint(plist);
}
//要让新节点和tail链接起来,一定要去改tail的next
void SLPushBack(SLTNode** pphead, SLTDataType x)//尾插的本质是让上一个结点链接下一个结点
{
SLTNode* newnode = BuyLTNode(x);
// 1、空链表
// 2、非空链表
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}Ejecución de código:

2.5 enchufe de mesa de un solo enlace
Ideas de tapones para la cabeza:

La idea de insertar el segundo nodo:
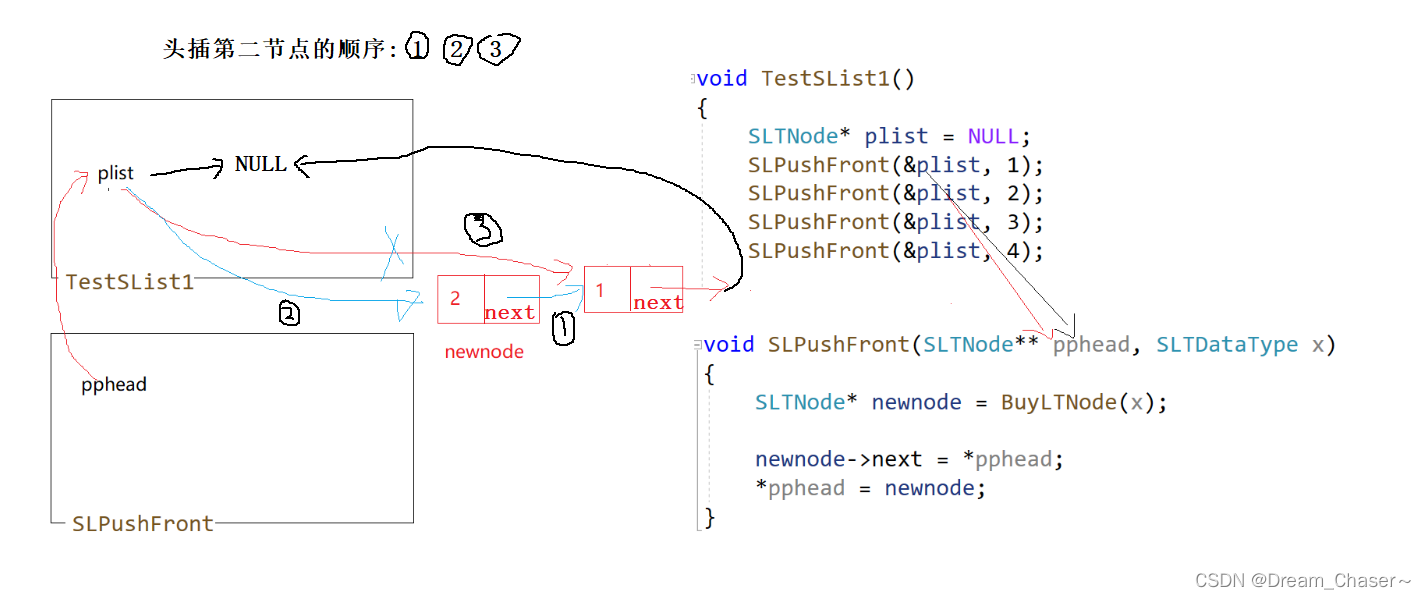
El código para conectar el encabezado se puede escribir así
void SLPushFront(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));//使用malloc函数动态分配了一个大小为SLTNode的内存块,
//并将其强制转换为 SLTNode 指针类型,即创建了一个新的节点。
if (newnode == NULL)
{
perror("malloc fail");
return NULL;
}
//需要注意的是,在使用 malloc 函数动态分配内存时,需要手动释放内存,否则会导致内存泄漏
//因此,在创建单链表节点后,我们应该在适当的时候使用 free 函数释放节点所占用的内存
newnode->data = x;
newnode->next = NULL;
//return newnode;//返回的是一个结点的地址
newnode->next = *pphead;
*pphead = newnode;//将头节点*pphead 更新为新节点的地址,以使新节点成为新的头节点。
}Sin embargo, para evitar la escritura repetida de programas para crear nuevos nodos, puede usar la función BuyLTNode(x) anterior para definir nuevos nodos para lograr el propósito de la abreviatura, o la función que se puede conectar también se puede escribir así :
void SLPushFront(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuyLTNode(x);
newnode->next = *pphead;
*pphead = newnode;
}En
SLPushFrontla función, primero llamamosBuyLTNode(x)a la función para crear un nuevo nodo, luego apuntamosnextel puntero del nuevo nodo al nodo principal de la lista vinculada actual y luego apuntamos el puntero del encabezado de la lista vinculada al nuevo nodo, completando así la operación de insertar un nuevo nodo a la cabeza de la lista enlazada.
Ejecución de código:
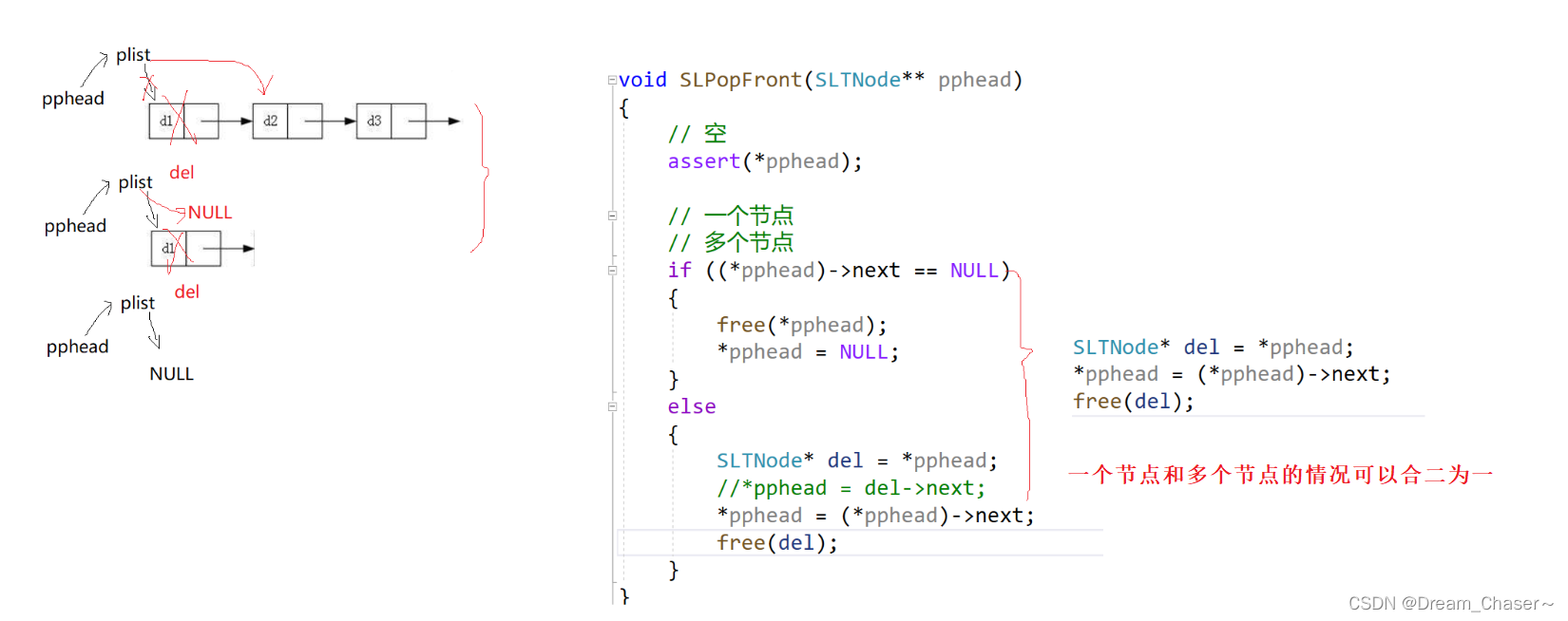
2.6 Eliminación de la cola de la lista enlazada individualmente
Caso de error:

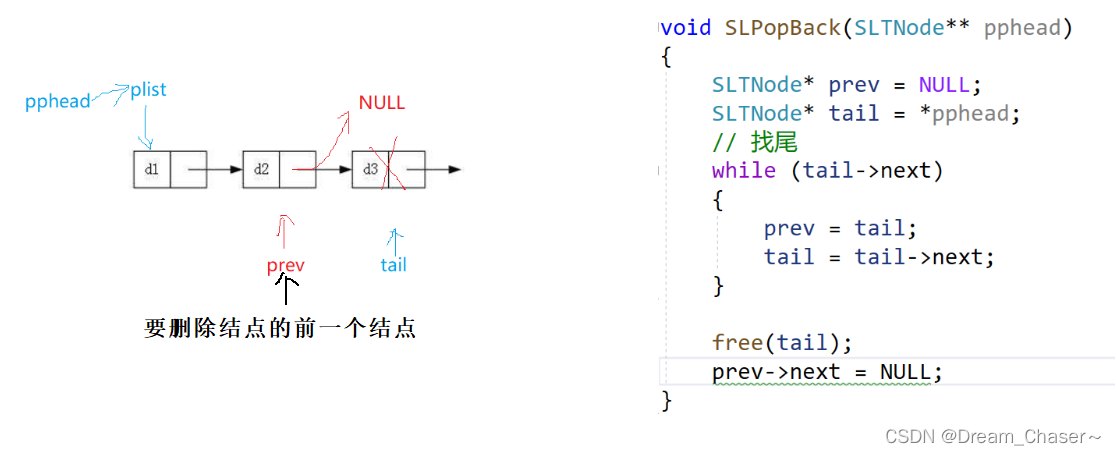
Método 1:
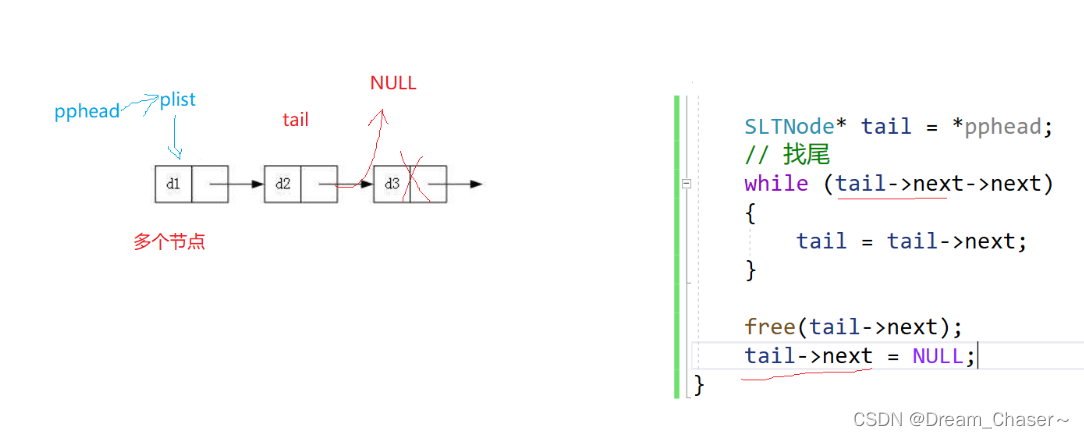
Método 2:
Ejemplo de código:
void SLPopBack(SLTNode** pphead)
{
//没有节点(空链表)
//暴力检查
assert(*pphead);
//温柔检查
if (*pphead == NULL)
{
return;
}
//一个节点
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}//多个节点
else
{
SLTNode* prev = NULL;
SLTNode* tail = *pphead;
//找尾
//方法一
/*while (tail->next)
{
prev = tail;
tail = tail->next;
}
free(tail);
prev->next = NULL;*/
//方法二
SLTNode* tail = *pphead;
while (tail->next->next)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}implementar:
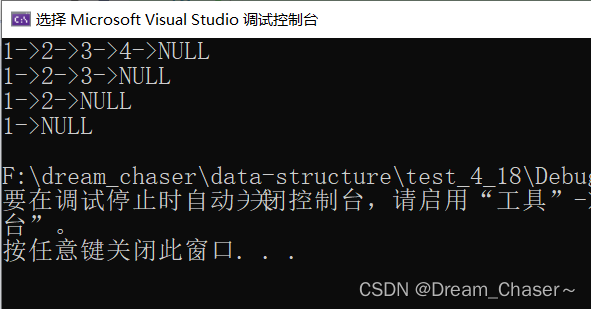
2.7 Eliminación de encabezado de enlace simple
Ideas:
void SPopFront(SLTNode** pphead)
{
//没有节点
//暴力检查
assert(*pphead);
//温柔检查
if (*pphead == NULL)
return;// 一个节点
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
//多个节点
else
{
SLTNode* del = *pphead;//相当于一个标记,删掉的标记
//写法一
//*pphead = del->next;
//写法二
*pphead = (*pphead)->next;
free(del);
}
}implementar:

2.8 Lista enlazada individualmente para encontrar/modificar un valor
Use la inserción de cola para insertar 1, 2, 3 y 4 en la lista vinculada en orden, luego busque el elemento con un valor de 3 en la lista vinculada y cámbielo a 30 (puede acceder al nodo cuyos datos son 3 por definiendo el puntero del punto de tipo de estructura, y modificar directamente a través de pos->next=30)
Nota: Puede definir directamente una función de prueba en la función principal para modificar el valor, y no es necesario definir una nueva función.
SLTNode* STFind(SLTNode* phead, SLTDataType x)
{
//assert(phead);
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}implementar:

2.9 La lista enlazada individualmente se inserta antes de pos
Ideas:

void SLInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pphead);//&plist
assert(pos);
//assert(*pphead);
//一个节点
if (*pphead == NULL)
{
SLPushFront(pphead, x);
}
else//多个节点
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
SLTNode* newnode = BuyLTNode(x);
prev->next = newnode;
newnode->next = pos;
}
}implementar:

2.10 La lista enlazada individualmente se inserta después de pos
Ideas:
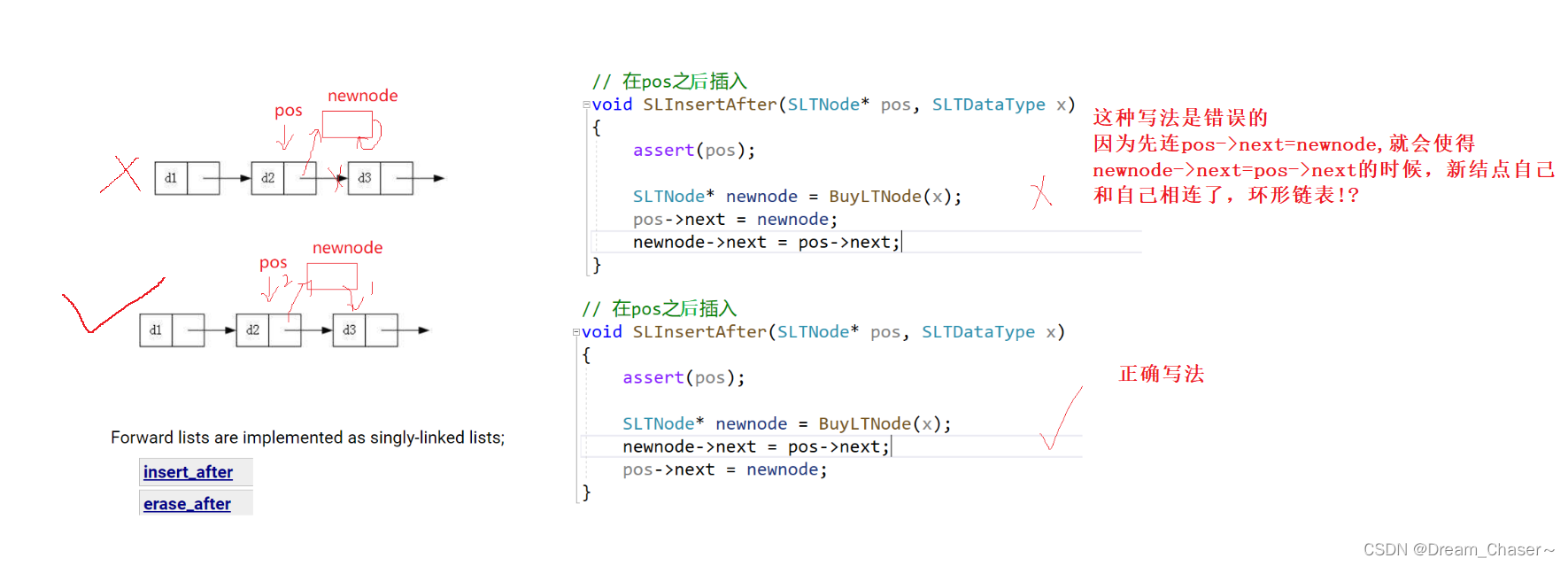
void SLInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = BuyLTNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
2.11 La lista enlazada individualmente elimina el valor de pos
Ideas:
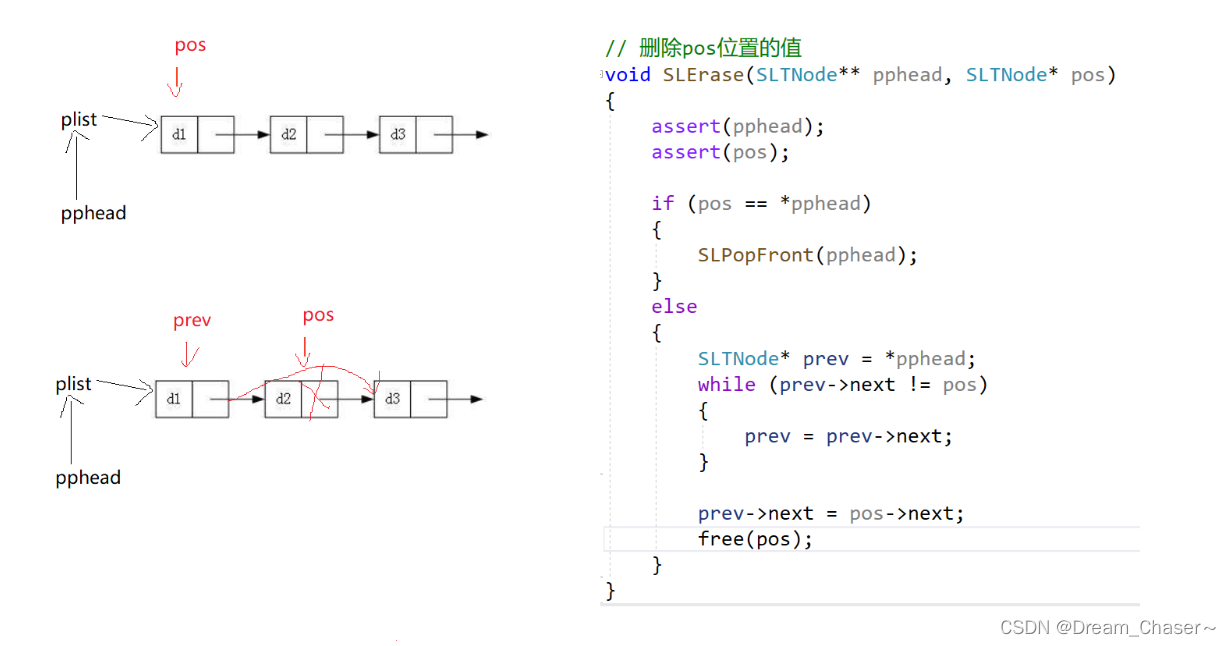
void SLErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead);
assert(pos);
if (pos == *pphead)
{
SLPopFront(pphead);
}
else
{
SLTNode* prev = *pphead;
while (prev->next!=pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
}
}
2.12 La lista enlazada individualmente elimina el valor después de pos
Ideas:
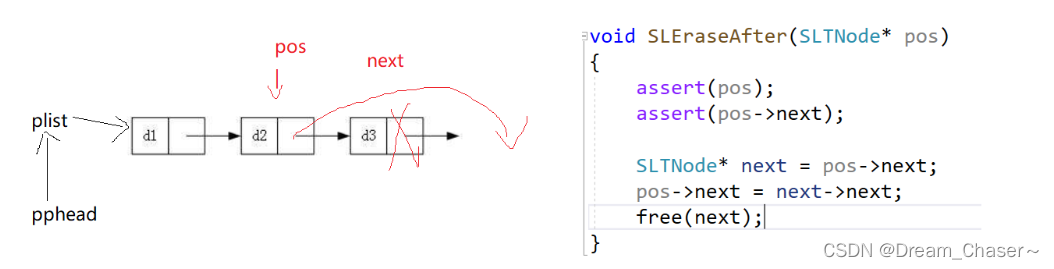
void SLEraseAfter(SLTNode* pos)
{
assert(pos);
SLTNode* next= pos->next;
pos->next = next->next;
free(next);
} 
3. Realización de la función del caso
3.1 Prueba
void TestSList1()
{
SLTNode* plist = NULL;
SLPushFront(&plist,1);
SLPushFront(&plist,2);
SLPushFront(&plist,3);
SLPushFront(&plist,4);
SLTPrint(plist);
SLPushBack(plist, 5);
SLTPrint(plist);
}enchufe de cabeza 3.2
void TestSList2()
{
SLTNode* plist = NULL;
SLPushFront(&plist, 1);
SLPushFront(&plist, 2);
SLPushFront(&plist, 3);
SLPushFront(&plist, 4);
SLTPrint(plist);
SLPushBack(&plist, 5);
SLTPrint(plist);
}3.3 enchufe trasero
void TestSList3()
{
SLTNode* plist = NULL;
SLPushBack(&plist, 1);
SLTPrint(plist);
SLPushBack(&plist, 2);
SLTPrint(plist);
SLPushBack(&plist, 3);
SLTPrint(plist);
SLPushBack(&plist, 4);
SLTPrint(plist);
}3.4 eliminación de encabezado
void TestSList4()
{
SLTNode* plist = NULL;
SLPushBack(&plist, 1);
SLPushBack(&plist, 2);
SLPushBack(&plist, 3);
SLPushBack(&plist, 4);
SLTPrint(plist);
//头删
SLPopFront(&plist);
SLTPrint(plist);
SLPopFront(&plist);
SLTPrint(plist);
SLPopFront(&plist);
SLTPrint(plist);
SLPopFront(&plist);
SLTPrint(plist);
}3.5 eliminación de cola
void TestSList5()
{
SLTNode* plist = NULL;
SLPushBack(&plist, 1);
SLPushBack(&plist, 2);
SLPushBack(&plist, 3);
SLPushBack(&plist, 4);
SLTPrint(plist);
SLPopBack(&plist);
SLTPrint(plist);
SLPopBack(&plist);
SLTPrint(plist);
SLPopBack(&plist);
SLTPrint(plist);
}3.6 Buscar/modificar un valor
void TestSList6()
{
SLTNode* plist = NULL;
SLPushBack(&plist, 1);
SLPushBack(&plist, 2);
SLPushBack(&plist, 3);
SLPushBack(&plist, 4);
SLTPrint(plist);
SLTNode* pos = STFind(plist,3);
if (pos)
pos->data = 30;
SLTPrint(plist);
}3.7 insertar antes de pos
void TestSList7()//pos之前插入
{
SLTNode* plist = NULL;
SLPushBack(&plist, 1);
SLPushBack(&plist, 2);
SLPushBack(&plist, 3);
SLPushBack(&plist, 4);
SLTPrint(plist);
SLTNode* pos = STFind(plist,3);
if (pos)
{
SLInsert(&plist, pos, 30);
}
SLTPrint(plist);
}3.8 insertar después de pos
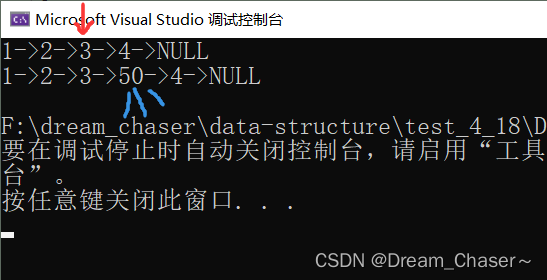
void TestSList8()//pos之后插入
{
SLTNode* plist = NULL;
SLPushBack(&plist, 1);
SLPushBack(&plist, 2);
SLPushBack(&plist, 3);
SLPushBack(&plist, 4);
SLTPrint(plist);
SLTNode* pos = STFind(plist, 3);
if (pos)
{
SLInsertAfter(pos, 50);
}
SLTPrint(plist);
}3.9 Eliminar el valor de la posición pos
void TestSList9() {
SLTNode* plist = NULL;
SLPushBack(&plist, 1);
SLPushBack(&plist, 2);
SLPushBack(&plist, 3);
SLPushBack(&plist, 4);
SLTPrint(plist);
SLTNode* pos = STFind(plist, 3);
if (pos)
{
SLErase(&plist,pos);
}
SLTPrint(plist);
}3.10 Eliminar el valor después de pos
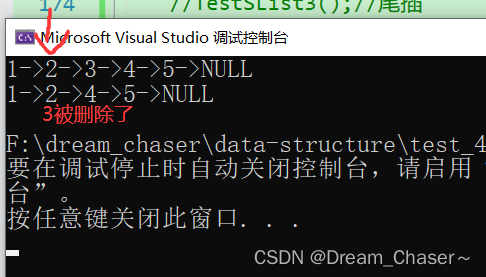
void TestSList10() {
SLTNode* plist = NULL;
SLPushBack(&plist, 1);
SLPushBack(&plist, 2);
SLPushBack(&plist, 3);
SLPushBack(&plist, 4);
SLPushBack(&plist, 5);
SLTPrint(plist);
SLTNode* pos = STFind(plist, 2);
if (pos)
{
SLEraseAfter(pos);
}
SLTPrint(plist);
}Al final de este capítulo, si hay algún error, puede señalarlo, gracias por su visita.