Preguntas de entrevistas para Hadoop
- ¿Cuéntanos sobre el proceso de carga y lectura de archivos en HDFS?
- ¿Qué debo hacer si uno de los bloques se daña repentinamente cuando HDFS está cargando archivos?
- ¿Cuál es la función de NameNode?
- 4. ¿Qué operaciones hará NameNode cuando se inicie?
- ¿HA similar a NameNode?
- ¿Proceso de envío de trabajos de Hadoop?
- ¿Cómo se fragmenta Hadoop?
- ¿Cómo reducir la cantidad de transferencia de datos desde el extremo de Hadoop Map al extremo de Reducir?
- Hadoop 的 Shuffle?
- ¿En qué escenarios se puede utilizar Combiner?
- ¿El papel de HMaster?
- ¿Cómo realizar el mecanismo de seguridad de hadoop?
- Para la implementación de la estrategia de programación de hadoop, ¿qué estrategia utiliza, por qué?
- ¿Cómo lidiar con la desviación de datos?
- Comentar sobre el principio de funcionamiento de hadoop?
- En resumen, ¿qué pasa con el modelo de programación de reducción de mapas de hadoop?
- ¿Cuál es el papel del TextInputFormat de hadoop y cómo personalizarlo?
- ¿Cuáles son los problemas comunes cuando se ejecuta el programa map-reduce?
- ¿Configuración de clúster de plataforma Hadoop y configuración de variables de entorno?
- ¿Ajuste del rendimiento de Hadoop?
- .Hadoop alta concurrencia?
- Archivos de configuración de Hadoop y construcción simple de clústeres de Hadoop
- Ajuste de parámetros de Hadoop
- Tiempo de inactividad de Hadoop
- Configuración de alta disponibilidad de Hadoop
- Configurar el clúster HDFS-HA
- Configurar la conmutación por error automática de HDFS-HA
- Configurar Yarn-HA

Preguntas de la entrevista de HBase
- ¿Cuáles son las características de HBase?
- ¿Cuál es la diferencia entre HBase y Hive?
- Principios de diseño de rowkey de HBase
- Las funciones y las diferencias de implementación de escanear y obtener en HBase
- Describa el uso de los métodos setCache y setBatch del objeto de escaneo en Hbase
- Usando start-hbase.sh como punto de partida, ¿cuál es el proceso de inicio de Hbase?
- Describa brevemente cuál es el propósito de compact en HBASE, cuándo se activa, en qué dos se dividen, cuáles son las diferencias y cuáles son los parámetros de configuración relevantes.
- ¿Cómo proporciona HBase una interfaz para el acceso front-end web?
- Cómo importar y exportar HBase
- ¿A qué debo prestar atención al compilar HBase?
chispa preguntas de la entrevista
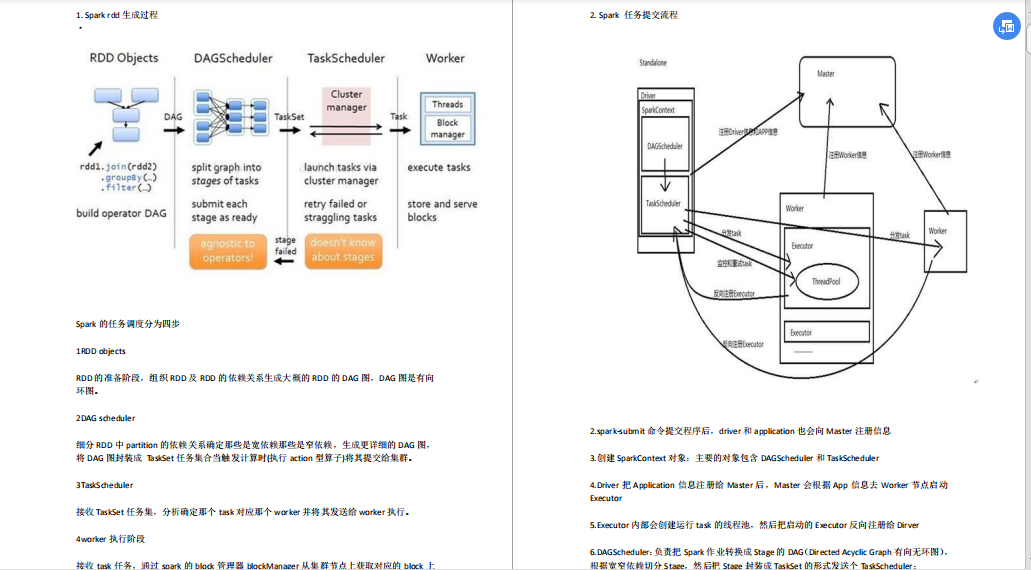
- ¿Principio y ajuste de Spark Shuffle?
- ¿Escenarios de uso de Hadoop y Spark?
- ¿Cómo garantiza Spark la rápida recuperación del tiempo de inactividad?
- ¿Cuáles son las similitudes y diferencias entre hadoop y spark?
- ¿El principio de persistencia RDD?
- ¿Mecanismo de punto de control?
- ¿Cuál es la diferencia entre el punto de control y el mecanismo de persistencia?
- ¿Cuál es la diferencia entre Spark Streaming y Storm?
- Mecanismo RDD?
- Spark Streaming y el principio de funcionamiento básico?
- DStream y el principio de funcionamiento básico?
- ¿Cuáles son los componentes de la chispa?
- ¿Mecanismo de funcionamiento de chispa?
- ¿Un proceso de trabajo de Spark?
- ¿Principio de programación de Spark Core?
- ¿Cómo funciona la chispa?
- ¿Qué son las optimizaciones de rendimiento de Spark?
- UpdateStateByKey detallado?
- ¿Amplia dependencia y estrecha dependencia?
- ¿Operación de conversión de estado en Spark Streaming?
- Spark marco informático de uso común?
- ¿Despertar la arquitectura general?
- ¿Cuáles son las características de Spark?
- ¿Pasos para construir un grupo de chispas?
- ¿Cuáles son los tres modos de envío de Spark?
- ¿Principio de la arquitectura del núcleo de Spark?
- ¿Arquitectura de clúster de hilos Spark?
- ¿Arquitectura de cliente de hilo Spark?
- Principio de inicialización de SparkContext
- ¿Análisis del principio del mecanismo de conmutación activo / en espera de Spark?
- ¿Cómo apoya Spark la recuperación de fallas?
- ¿Qué problemas resuelve Spark en Hadoop?
- ¿La generación y solución de tilt de datos?
- Spark logra alta disponibilidad: ¿Alta disponibilidad?
- En el trabajo de chispa real, ¿cómo determina cuántos recursos se necesitan en función de la cantidad de tareas?
- ¿Cómo resolver el problema de la fuga de memoria en Spark?

Preguntas de la entrevista de Zookeeper
- ¿Cuál es el marco de Zookeeper?
- ¿Cuáles son los escenarios de aplicación?
- ¿Qué protocolo se utiliza?
- Habla sobre el algoritmo de consenso distribuido Paxos
- Hablar sobre el algoritmo y el proceso de elección.
- ¿Qué tipo de nodos tiene Zookeeper?
- ¿Es permanente la notificación de monitoreo del reloj del cuidador al nodo?
- ¿Cuáles son los modos de implementación?
- ¿Cuáles son las funciones de la máquina en el clúster?
- El clúster requiere al menos algunas máquinas, ¿cuáles son las reglas del clúster?
- Si hay 3 máquinas en el clúster, ¿puede funcionar todavía un clúster? ¿Qué tal colgar dos?
- ¿El clúster admite máquinas sumadoras dinámicas?
- ¿Cuáles son los clientes java de zookeeper?
- ¿Qué es gordito y cómo se compara con el cuidador del zoológico?
- Di algunos comandos de uso común en zookeeper.


En respuesta a las preguntas anteriores, el editor ha clasificado las preguntas de la entrevista + los documentos de respuesta Además de este documento sobre el tema de la entrevista, hay algunos documentos prácticos específicos en el editor que se pueden proporcionar para que todos puedan aprender de forma gratuita.
Amigos que necesitan obtener documentos especiales para entrevistas y documentos reales: me gusta el artículo y síganme, agreguen asistente VX: mxx2020666, lo pueden obtener gratis