Python scikit-learn ライブラリでの 10 個のクラスタリング アルゴリズムの適用
クラスタリングに関する記事、10 のクラスタリングの概要、および Python コードを共有します。
この記事では、scikit-learn 機械学習ライブラリの 10 個のクラスタリング アルゴリズムを Python で実装して使用する方法について説明します。
- アフィニティの伝播 (AP クラスタリング)
- 集約クラスタリング
- シラカバ
- DBSCAN
- K 平均法
- ミニバッチ K 平均法
- 平均シフト
- 光学
- スペクトルクラスタリング
- 混合ガウスモデル
1. データ生成
make_classification() 関数を使用して、テスト バイナリ分類データセットを作成します。データセットには、クラスごとに 2 つの入力フィーチャと 1 つのクラスターを含む 1000 の例が含まれます。これらのクラスターは 2 次元で表示されるため、データを散布図にプロットし、指定したクラスターごとにプロット内の点をカラー プロットすることができます。
少なくともテスト問題に関して、クラスターがどの程度適切に識別されているかを確認すると役立ちます。このテスト問題のクラスターは多変量ガウス分布に基づいており、すべてのクラスタリング アルゴリズムがこれらのタイプのクラスターの識別に効果的であるわけではありません。したがって、このチュートリアルの結果は、一般的な方法を比較するための基礎として使用しないでください。合成クラスタリング データセットの作成と要約の例を以下に示します。
# 综合分类数据集
from numpy import where
from sklearn.datasets import make_classification
from matplotlib import pyplot
# 定义数据集
X, y = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 为每个类的样本创建散点图
for class_value in range(2):
# 获取此类的示例的行索引
row_ix = where(y == class_value)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
この例を実行すると、合成クラスター化データセットが作成され、次に入力データの散布図が作成されます。ここで、点はクラス ラベル (理想化されたクラスター) によって色付けされます。二次元では 2 つの異なるデータ グループがはっきりと確認でき、自動クラスタリング アルゴリズムがこれらのグループを検出できることが期待されます。

次に、このデータセットに適用されるクラスタリング アルゴリズムの例を見ていきます。各メソッドをデータセットに合わせて調整するために、最小限の試みをいくつか行いました。
2. 10のクラスタリングアルゴリズム
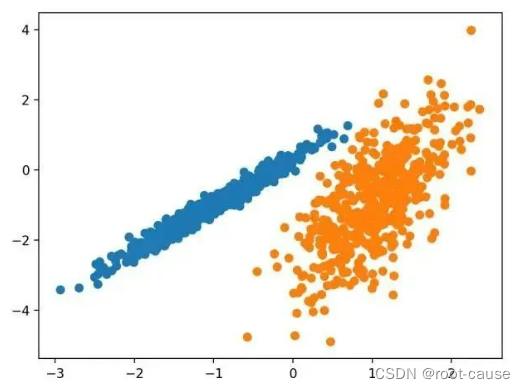
1. 親和性の伝播
親和性の伝播には、データを最もよく要約するサンプルのセットを見つけることが含まれます。
2 つのデータ点ペア間の類似性の入力尺度として、「類似性伝播」と呼ばれる方法を設計します。高品質のサンプルと対応するクラスターのセットが出現するまで、データ ポイント間で実数値のメッセージを交換します。
出典: By Passing Messages Between Data Points 2007。
これは AffinityPropagation クラスを通じて実装されており、調整する主な設定は、Damping を 0.5 から 1 に設定することであり、場合によっては Preferences も設定します。
完全な例を以下に示します。
# 亲和力传播聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import AffinityPropagation
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = AffinityPropagation(damping=0.9)
# 匹配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
サンプルを実行すると、トレーニング データセットにモデルが適合し、データセット内の各サンプルのクラスターが予測されます。次に、割り当てられたクラスターごとに色付けされた散布図が作成されます。
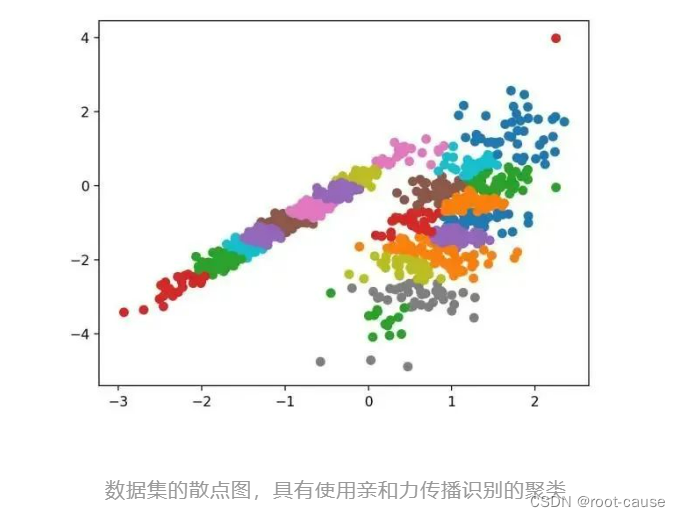
2. 集合クラスタリング
集約クラスタリングでは、必要なクラスター数に達するまでサンプルをマージします。これは、AgglomerationClustering クラスを通じて実装される、より広範な階層クラスタリング メソッドの一部であり、主な構成は、データ内のクラスター数の推定値 (たとえば 2) である「n_clusters」セットです。完全な例を以下に示します。
# 聚合聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import AgglomerativeClustering
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = AgglomerativeClustering(n_clusters=2)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
サンプルを実行すると、トレーニング データセットにモデルが適合し、データセット内の各サンプルのクラスターが予測されます。次に、割り当てられたクラスターごとに色付けされた散布図が作成されます。この場合、合理的なグループ化が見つかります。
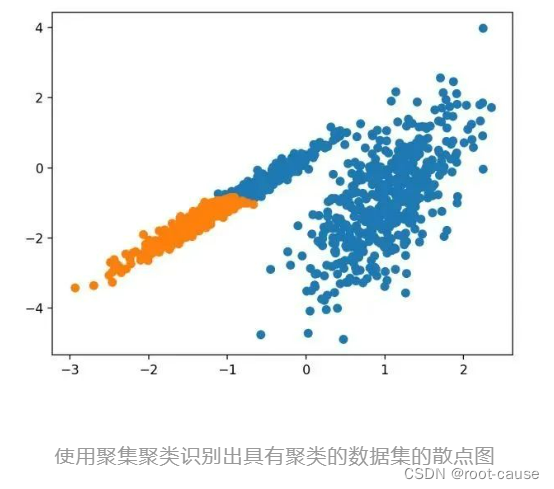
3.樺
BIRCH クラスタリング (BIRCH は、Balanced Iterative Reduction、階層を使用したクラスタリングの頭字語です) には、クラスターの重心が抽出されるツリー状の構造の構築が含まれます。
BIRCH は、利用可能なリソース (つまり、利用可能なメモリと時間の制約) で最高品質のクラスターを生成するために、受信した多次元メトリック データ ポイントを増分的かつ動的にクラスター化します。
これは Birch クラスを通じて実装され、主な設定は「threshold」と「n_clusters」ハイパーパラメータで、後者はクラスタ数の推定値を提供します。完全な例を以下に示します。
# birch聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import Birch
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = Birch(threshold=0.01, n_clusters=2)
# 适配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
サンプルを実行すると、トレーニング データセットにモデルが適合し、データセット内の各サンプルのクラスターが予測されます。次に、割り当てられたクラスターごとに色付けされた散布図が作成されます。この場合、適切なグループ化が見つかります。
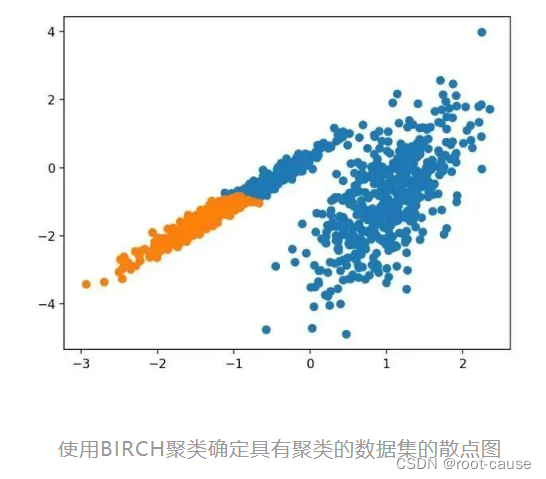
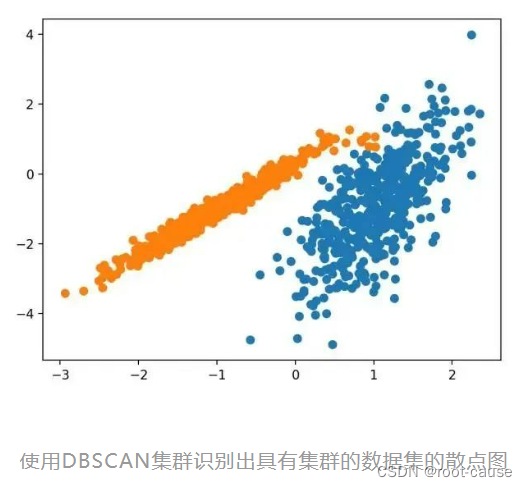
4. DBSスキャン
DBSCAN クラスタリング (DBSCAN は密度ベースの空間クラスタリングのノイズ アプリケーションです) には、ドメイン内の高密度領域を見つけて、その周囲の特徴空間領域をクラスタに拡張することが含まれます。
...私たちは、密度ベースのクラスター設計の概念に依存して、任意の形状のクラスターを発見する新しいクラスター化アルゴリズム DBSCAN を提案します。DBSCAN に必要な入力パラメータは 1 つだけであり、ユーザーはその適切な値を決定できます。
- 出典: 「ノイズの多い大規模空間データベース用の密度ベースのクラスタリング検出アルゴリズム」、1996 年
これは DBSCAN クラスを通じて実装され、主な設定は「eps」と「min_samples」ハイパーパラメータです。
完全な例を以下に示します。
# dbscan 聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import DBSCAN
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = DBSCAN(eps=0.30, min_samples=9)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
サンプルを実行すると、トレーニング データセットにモデルが適合し、データセット内の各サンプルのクラスターが予測されます。次に、割り当てられたクラスターごとに色付けされた散布図が作成されます。この場合、合理的なグループ化が見つかりましたが、さらに調整が必要でした。
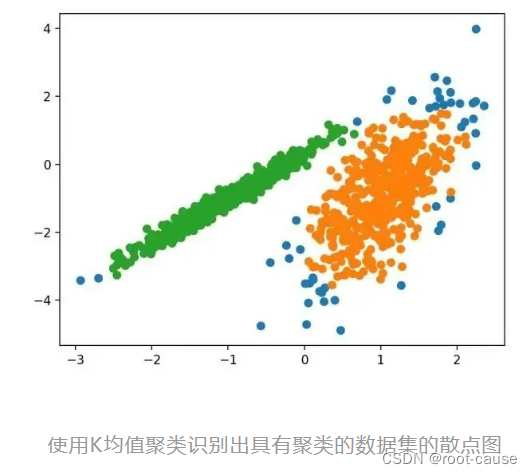
5. K 平均法
K 平均法クラスタリングはおそらく最も一般的なクラスタリング アルゴリズムであり、サンプルをクラスタに割り当てて各クラスタ内の分散を最小限に抑えます。
この論文の主な目的は、N 次元の母集団を k 個のセットに分割するためのサンプルベースの手順を説明することです。「K-means」と呼ばれるこのプロセスは、クラス内分散の意味でかなり効率的な分割を与えるようです。
これは K-means クラスで実装されており、最適化する主な構成は、データ内の推定クラスター数に設定された「n_clusters」ハイパーパラメーターです。完全な例を以下に示します。
# k-means 聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import KMeans
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = KMeans(n_clusters=2)
# 模型拟合
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
サンプルを実行すると、トレーニング データセットにモデルが適合し、データセット内の各サンプルのクラスターが予測されます。次に、割り当てられたクラスターごとに色付けされた散布図が作成されます。この場合、合理的なグループ化が見つかりますが、各次元の分散が等しくないため、この方法はこのデータセットにはあまり適していません。
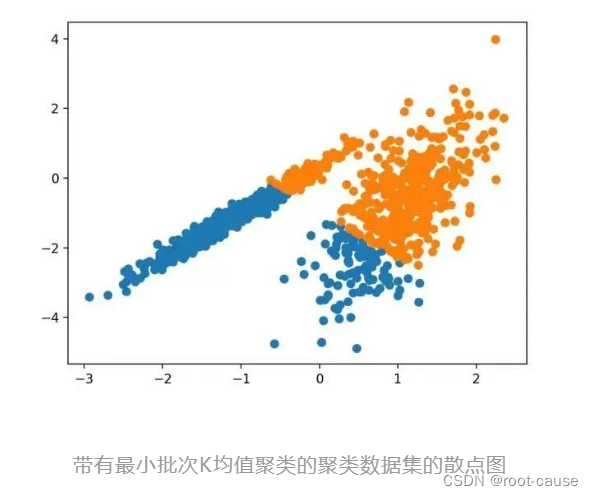
6. ミニバッチ K 平均法
ミニバッチ K 平均法は、データセット全体ではなくサンプルの小さなバッチを使用してクラスター重心を更新する K 平均法の修正バージョンです。これにより、大規模なデータセットの更新が高速になり、統計ノイズに対してより堅牢になる可能性があります。
...K 平均法クラスタリングを使用したミニバッチ最適化を提案します。これにより、従来のバッチ アルゴリズムと比較して計算コストが桁違いに削減され、同時にオンライン確率的勾配降下法よりも優れたソリューションが提供されます。
これは MiniBatchKMeans クラスを介して実装され、最適化する主な構成は、データ内の推定クラスター数に設定される「n_clusters」ハイパーパラメーターです。完全な例を以下に示します。
# mini-batch k均值聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import MiniBatchKMeans
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = MiniBatchKMeans(n_clusters=2)
# 模型拟合
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
サンプルを実行すると、トレーニング データセットにモデルが適合し、データセット内の各サンプルのクラスターが予測されます。次に、割り当てられたクラスターごとに色付けされた散布図が作成されます。この場合、標準の K 平均法アルゴリズムと同等の結果が得られます。
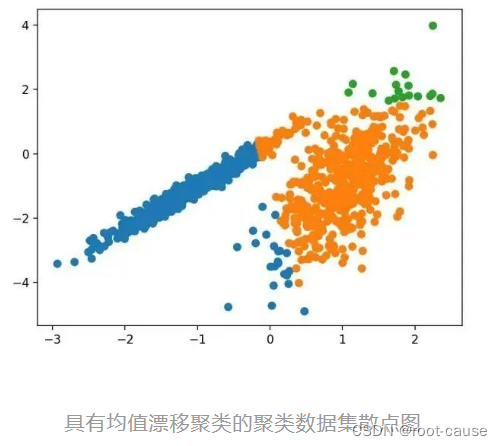
7. 平均シフトクラスタリング
平均シフト クラスタリングには、特徴空間内のインスタンス密度に従って重心を見つけて調整することが含まれます。
離散データについては、再帰的平均シフト手順がよどみ点に最も近い基礎となる密度関数に収束することが実証され、密度パターンの検出におけるその使用が実証されています。
これは MeanShift クラスを通じて実装され、主な構成は「帯域幅」ハイパーパラメータです。完全な例を以下に示します。
# 均值漂移聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import MeanShift
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = MeanShift()
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
サンプルを実行すると、トレーニング データセットにモデルが適合し、データセット内の各サンプルのクラスターが予測されます。次に、割り当てられたクラスターごとに色付けされた散布図が作成されます。この場合、適切なクラスターのセットがデータ内で見つかります。
8. 光学系
OPTICS クラスタリング (OPTICS は、クラスター構造を識別するための順序付けポイントよりも短い) は、上記の DBSCAN の修正バージョンです。
データセットのクラスターを明示的に生成するのではなく、密度に基づいたクラスター構造を表すデータベースの拡張順序付けが作成されるクラスター分析用の新しいアルゴリズムを導入します。このクラスターのランキングには、広範囲のパラメーター設定に対する密度クラスター化と同等の情報が含まれています。
これは OPTICS クラスを通じて実装され、主な設定は「eps」と「min_samples」ハイパーパラメータです。完全な例を以下に示します。
# optics聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import OPTICS
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = OPTICS(eps=0.8, min_samples=10)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
サンプルを実行すると、トレーニング データセットにモデルが適合し、データセット内の各サンプルのクラスターが予測されます。次に、割り当てられたクラスターごとに色付けされた散布図が作成されます。この場合、このデータセットでは妥当な結果を得ることができません。

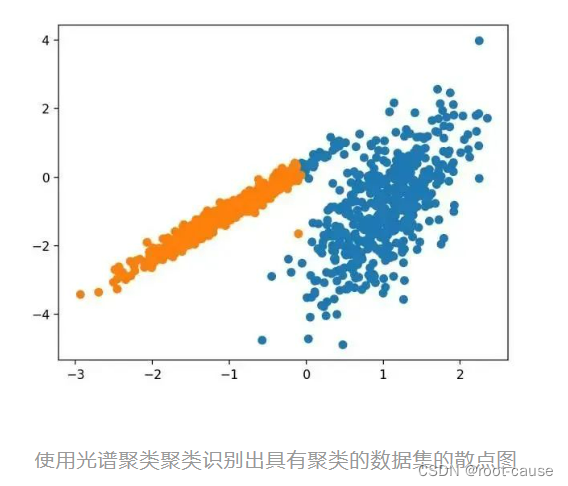
9. スペクトルクラスタリング
スペクトル クラスタリングは、線形線形代数から取られたクラスタリング手法の一般的なクラスです。
最近多くの分野で登場した有望な代替手段は、クラスタリングを使用したスペクトル アプローチです。ここでは、点間の距離から導出された行列の上部固有ベクトルが使用されます。
これはスペクトル クラスタリング クラスを通じて実装されますが、メインのスペクトル クラスタリングは線形線形代数から取得したクラスタリング手法で構成される汎用クラスです。調整するのは「n_clusters」ハイパーパラメーターで、データ内のクラスターの推定数を指定します。完全な例を以下に示します。
# spectral clustering
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import SpectralClustering
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = SpectralClustering(n_clusters=2)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
サンプルを実行すると、トレーニング データセットにモデルが適合し、データセット内の各サンプルのクラスターが予測されます。次に、割り当てられたクラスターごとに色付けされた散布図が作成されます。
10. 混合ガウスモデル
混合ガウス モデルは、名前が示すように、ガウス確率分布の混合である多変量確率密度関数を要約します。これは Gaussian Mixture クラスを通じて実装され、調整する主な構成は、データ内の推定クラスター数を指定する「n_clusters」ハイパーパラメーターです。完全な例を以下に示します。
# 高斯混合模型
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.mixture import GaussianMixture
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = GaussianMixture(n_components=2)
# 模型拟合
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:
# 获取此群集的示例的行索引
row_ix = where(yhat == cluster)
# 创建这些样本的散布
pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
サンプルを実行すると、トレーニング データセットにモデルが適合し、データセット内の各サンプルのクラスターが予測されます。次に、割り当てられたクラスターごとに色付けされた散布図が作成されます。この場合、クラスターが完全に識別されていることがわかります。データセットはガウス分布の混合として生成されたため、これは驚くべきことではありません。

3. まとめ
この記事では、Python でクラスタリング アルゴリズムをインストールして使用する方法、および scikit-learn 機械学習ライブラリの Python でクラスタリング アルゴリズムを実装して使用する方法について説明します。具体的には、クラスタリングは、特徴空間内の入力データ内の自然グループを発見する教師なし問題です。
テスト結果: さまざまなクラスタリング アルゴリズムがあり、すべてのデータセットに最適な単一の方法はありません。