こんにちは、Wei Xue AI です。今日は、K 平均法アルゴリズムに基づく機械学習の実践 11 テキスト クラスタリング分析を紹介し、テキスト クラスタリング ファイルを生成します。テキスト クラスタリング分析は NLP の分野の中核的なタスクであり、類似したテキスト サンプルをグループ化することで、テキスト データに隠されたパターンや構造を発見するのに役立ちます。
このプロジェクトでは、K 平均法アルゴリズムを使用してテキスト クラスタリング分析を実装します。K 平均法アルゴリズムは、一般的に使用されるクラスタリング アルゴリズムであり、サンプルを K クラスターに繰り返し割り当て、各クラスター内のサンプルの二乗誤差の合計を最小化することで最適なクラスター分割を決定します。テキスト データをベクトル表現に変換し、K 平均法アルゴリズムを使用してベクトルをクラスタリングすることにより、テキストの自動分類とグループ化を実現できます。
目次
1. はじめに
2. テキストクラスタリング分析の基礎知識
3. テキストクラスタリング分析プロジェクトの設計と実装
4. テキストクラスタリング分析実装コードケース
5. テキストクラスタリング分析のメリット、デメリット、課題
6. テキストクラスタリング分析
7.
I.はじめに
テキストクラスタリング分析とは、テキストデータを分類・整理する手法で、テキスト間の類似点や関連性を発見し、類似したテキストを1つのカテゴリに分類します。テキスト クラスタリングは実際の応用において非常に重要であり、大規模なテキスト データの構造と内容を理解し、そこに隠された情報とパターンを発見するのに役立ちます。
2. テキストクラスタリング分析の基礎知識
テキスト クラスタリングとは、テキスト データセットを複数の互いに素なカテゴリに分割し、同じカテゴリ内のテキストの類似性が高く、異なるカテゴリ間の類似性が低くなるようにすることを指します。一般的に使用されるテキスト クラスタリング アルゴリズムには、K 平均法アルゴリズムと階層クラスタリング アルゴリズムが含まれます。K 平均法アルゴリズムは、反復最適化を通じてテキスト データを K クラスターに分割し、各クラスターには類似性があります。階層的クラスタリング アルゴリズムは、異なるテキスト間の類似性を計算し、完全なクラスターが形成されるまで最も類似したテキストを徐々にマージします。クラスター ツリー。
テキスト クラスタリングでは、テキスト表現が重要な問題になります。一般的に使用されるテキスト表現方法には、ワードバッグ モデルや TF-IDF などがあります。ワード バッグ モデルはテキストをベクトルとして表し、各次元はテキスト内の特定の単語の出現数を表します。TF-IDF は、テキスト セット全体における単語の頻度とその重要性を考慮します。
K 平均法アルゴリズムの数学的原理は、次の式で表すことができます。
n 個のサンプルX=\{x_1, x_2, ..., x_n\} を含むデータセット X = { x 1 , x 2 , . . , xn } があるとします。バツ={ ×1、バツ2、。。。、バツんここで、各サンプルxi x_iバツ私はは d 次元ベクトル(xi 1 , xi 2 , ..., xid ) (x_{i1}, x_{i2}, ..., x_{id}) です。( ×私1、バツ私2、。。。、バツ私は)。K 平均法アルゴリズムは、これらのサンプルを K 個のクラスターに分割し、各サンプルが 1 つのクラスターにのみ属することを目的としています。
まず、K個の初期クラスター中心 μ = { μ 1 , μ 2 , . . . , μ K } \mu=\{\mu_1, \mu_2, ..., \mu_K\} を選択する必要があります。メートル={ メートル1、メートル2、。。。、メートルKここで、各クラスターの中心は d 次元ベクトルです。
次に、アルゴリズムの反復プロセスは次のようになります。
- 各サンプルxi x_iについてバツ私は、各クラスター中心からの距離を計算し (通常はユークリッド距離またはその他の距離測定方法を使用)、最も近いクラスター中心に対応するクラスターに分類します。
- 各クラスターについて、そのすべてのサンプルの平均を新しいクラスターの中心として計算します。
- 停止条件が満たされるまで手順 1 と 2 を繰り返します (たとえば、最大反復回数に達するか、クラスターの中心が大幅に変化しなくなる)。
K 平均法アルゴリズムの最適化の目標は、すべてのサンプルとそのクラスター中心の間の距離の合計を最小化すること、つまり、次の目的関数を最小化することです。 J = ∑ i = 1 n ∑ j = 1 K rij ∣
∣ xi − μ j ∣ ∣ 2 J = \sum_{i=1}^{n} \sum_{j=1}^{K} r_{ij} ||x_i - \mu_j||^2J=i = 1∑んj = 1∑Kr私は∣ ∣ ×私は−メートルj∣ ∣2
ここで、rij r_{ij}r私はサンプルxi x_iを示しますバツ私はクラスタjjに所属jの標識変数 ( xi x_iの場合)バツ私はクラスタjjに所属j则rij = 1 r_{ij}=1r私は=1、それ以外の場合はrij = 0 r_{ij}=0r私は=0。
反復最適化プロセスを通じて、K 平均法アルゴリズムは目的関数JJのセットが見つかるまでクラスター中心を継続的に更新します。J-最小化の最終的なクラスタリング結果。
K-means アルゴリズムは、異なる初期クラスター中心選択に対して異なる局所最適解に収束する可能性があることに注意してください。これを克服するには、複数の実行または他のヒューリスティックを使用して、クラスタリングの結果を改善できます。
3. テキストクラスタリング分析プロジェクトの設計と実施
テキスト クラスタリング分析プロジェクトを実行する場合、まずデータの収集と前処理が必要です。データはニュースレポートやソーシャルメディアなどのさまざまなソースから取得できますが、クリーンアップしてノイズを除去する必要があります。次のステップは、テキストの特徴の抽出と表現です。ワード バッグ モデルまたは TF-IDF メソッドを使用して、テキストをベクトル表現に変換できます。次に、適切なクラスタリング アルゴリズムを選択し、パラメーターの調整を実行する必要があります。最後に、クラスタリング結果をよりよく理解して説明するために、クラスタリング結果が評価および視覚化されます。
4. テキストクラスタリング分析実装コードケース
ここでは、Python 言語と scikit-learn ライブラリを使用して K-means クラスタリング アルゴリズムを実装し、ニュース テキスト データ セットをクラスタリングするなど、特定のテキスト クラスタリング分析の実装コード ケースを示します。
#coding utf-8
import csv
import jieba
from sklearn.cluster import KMeans
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
import os
import re
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# 对中文文本进行分词
def tokenize_text(text):
return " ".join(jieba.cut(text))
# 去除标点符号
def remove_punctuation(text):
punctuation = '!"#,。、$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
text = re.sub(r'[{}]+'.format(punctuation), '', text)
return text
# 将分词后的文本转化为tf-idf矩阵
def text_to_tfidf_matrix(texts):
tokenized_texts = [tokenize_text(remove_punctuation(text)) for text in texts]
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(tokenized_texts)
return tfidf_matrix
# 聚类函数
def cluster_texts(tfidf_matrix, n_clusters):
kmeans = KMeans(n_clusters=n_clusters)
kmeans.fit(tfidf_matrix)
return kmeans.labels_
# 保存聚类结果到新的CSV文件
def save_clusters_to_csv(filename, texts, labels):
base_filename, ext = os.path.splitext(filename)
output_filename = f"{base_filename}_clusters{ext}"
with open(output_filename, "w", encoding="utf-8", newline="") as csvfile:
csvwriter = csv.writer(csvfile)
for text, label in zip(texts, labels):
csvwriter.writerow([text, label])
return output_filename
# 输出聚类结果
def print_cluster_result(texts, labels):
clusters = {
}
for i, label in enumerate(labels):
if label not in clusters:
clusters[label] = []
clusters[label].append(texts[i])
for label, text_list in clusters.items():
print(f"Cluster {label}:")
for text in text_list:
print(f" {text}")
def text_KMeans(filename,n_clusters):
df = pd.read_csv(filename, encoding='utf-8') # 读取csv文件
texts = df['text'].tolist() # 提取文本数据为列表格
print(df.iloc[:, [0, -1]])
# 将文本转化为tf-idf矩阵
tfidf_matrix = text_to_tfidf_matrix(texts)
# 进行聚类
labels = cluster_texts(tfidf_matrix, n_clusters)
clusters = []
for i, label in enumerate(labels):
clusters.append(label)
df['cluster'] = clusters
output = 'data_clustered.csv'
df.to_csv('data_clustered.csv', index=False, encoding='utf-8')
return output,labels,tfidf_matrix
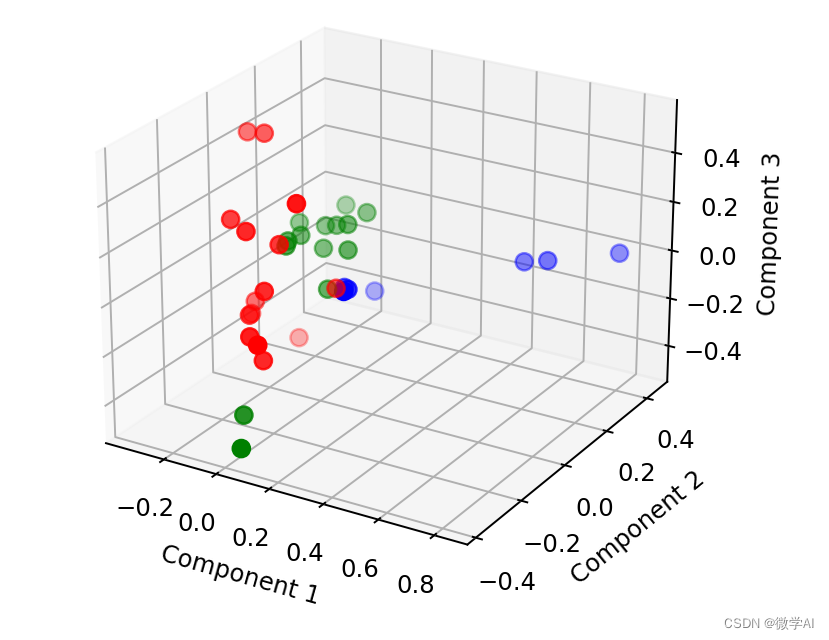
def pca_picture(labels,tfidf_matrix):
# 进行降维操作并将结果保存到DataFrame中
pca = PCA(n_components=3)
result = pca.fit_transform(tfidf_matrix.toarray())
result_df = pd.DataFrame(result, columns=['Component1', 'Component2', 'Component3'])
# 将聚类结果添加到DataFrame中
result_df['cluster'] = labels
# 绘制聚类图形
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
colors = ['red', 'blue', 'green']
for i in range(3):
subset = result_df[result_df['cluster'] == i]
ax.scatter(subset['Component1'], subset['Component2'], subset['Component3'], color=colors[i], s=50)
ax.set_xlabel("Component 1")
ax.set_ylabel("Component 2")
ax.set_zlabel("Component 3")
plt.show()
if __name__ == "__main__":
# 加载中文文本
filename = "data.csv"
n_clusters =3
output,labels,tfidf_matrix = text_KMeans(filename, n_clusters)
pca_picture(labels, tfidf_matrix)
PCA アルゴリズムを実行して 3D 画像を生成します。
5. テキストクラスタリング分析の長所、短所、課題
テキスト クラスタリング分析には、テキスト データの構造と内容を理解するのに役立つ洞察が得られる、自動クラスタリングを実現して手動介入を削減できる、大規模なデータを効率的に処理して分析を高速化できる、という利点があります。
ただし、テキスト クラスタリングにはいくつかの欠点もあります。クラスタリングは類似性に基づいているため、非常に主観的なテキスト データに対して不正確な分類が発生する可能性があります。クラスタリング アルゴリズムでは通常、トレーニングと調整のためにラベル付きデータが必要ですが、シナリオによっては取得が困難な場合があります。ノイズへの対処冗長な情報も課題です。
さらに、テキスト クラスタリングはいくつかの課題にも直面しています: 高次元の問題、つまりテキストの特徴の次元が高い場合、クラスタリングの結果が不正確になるか解釈が困難になる可能性があります; 自然言語の複雑さによる意味の類似性の問題、テキスト間の意味上の違い 類似性を捉えるのは困難ですが、カテゴリの不均衡の問題、つまり、異なるカテゴリのテキスト サンプル数の大きな違いが、クラスタリングの効果に影響を与える可能性があります。
6. テキストクラスタリング解析の今後の発展動向
将来的に、テキスト クラスタリング分析は次の方向に発展する可能性があります: (深層学習手法を組み合わせることによるテキストの特徴表現の改善、応用分野の拡大など、いくつかのアイデアが提案される可能性があります)
7. 結論
テキスト クラスタリング分析は、大規模なテキスト データを理解して整理するのに役立つ重要な手法です。適切なアルゴリズムと特徴表現方法を選択し、関連する課題を克服することで、正確で解釈可能なクラスタリング結果を得ることができます。テクノロジーの継続的な進歩により、テキスト クラスタリング分析はさまざまな分野で幅広い応用の可能性を秘めています。