Directorio de artículos
abstracto
- Actualmente hay dos cambios importantes en el campo de la generación de imágenes, y hay dos tendencias: una es el transformador autorregresivo y la otra es DDPM.
- Este artículo intenta combinar las ventajas de estos dos métodos, introducir la experiencia en el campo de los modelos de lenguaje pre-entrenados a gran escala en la síntesis y lograr una síntesis de voz multitímbrica de alta expresividad, y llama a este trabajo TorToiSe. Este artículo utiliza UnivNet como codificador de voz para la reconstrucción de formas de onda.
- Este documento adopta: (1) el uso de una estructura de transformador general; (2) el uso de un conjunto de datos grande y de alta calidad; (3) el entrenamiento con un tamaño de lote muy grande. Síntesis de voz SOTA implementada. Es muy importante ceñirse a estos tres puntos, y cualquier modalidad digital puede entrenar un modelo general utilizando este marco.
introducción
generación de imágenes
- Método basado en DALL-E: en realidad es el decodificador del modelo NLP, que realiza la autoatención en función de la entrada, por lo que la cantidad de cálculo es O ( N 2 ) O (N ^ 2)O ( norte2 ), N es la longitud de la secuencia. Si la secuencia es demasiado larga, la complejidad computacional estalla. Además, el método autorregresivo tradicional se basa en tokens de imagen discretos, que se reconstruyen en píxeles de imagen.DALL-E 1 utiliza VQVAE para la cuantificación, que puede reconstruir imágenes borrosas.
- Enfoques basados en DDPM:
- Hay dos tipos de problemas en el modelo generativo: (1) comportamiento de búsqueda del medio, que da como resultado imágenes borrosas; (2) colapso de modo, que da como resultado una mala generalización.
- Los DDPM son relativamente baratos para evitar las dos deficiencias anteriores y pueden generar imágenes de alta resolución utilizando señales de guía de baja calidad.
- Problemas con los DDPM: (1) Los DDPM deben guiar la señal y la alineación de salida, pero el texto y el audio en sí no tienen una relación de alineación de secuencia. (2) Para generar imágenes de alta calidad, los DDPM necesitan múltiples rondas de reenvío, lo que consume una gran cantidad de cómputo.
- Reclasificación: DALL-E utiliza la estrategia de "reclasificación" en el proceso de autorregresión y selecciona la mejor de k salidas para su uso posterior. Esto requiere un buen discriminador que pueda distinguir qué es un buen par texto-imagen. Por ejemplo, DALL-E usa CLIP.
resumen
- Los modelos autorregresivos son más largos que las transiciones entre diferentes modalidades, y los DDPM sufren problemas de alineación
- Los DDPM generan modos altamente expresivos en dominios continuos y los modelos autorregresivos usan¿Características discretas? por qué。
- Ambos métodos pueden mejorar el efecto de salida aumentando la cantidad de cálculo
método
- Este documento combina autorregresivos y DDPM para generar características discretas de texto a audio a través de autorregresivos y luego generar voz de alta calidad a través de DDPM.
Aplicación de autorregresión+DDPM a TTS
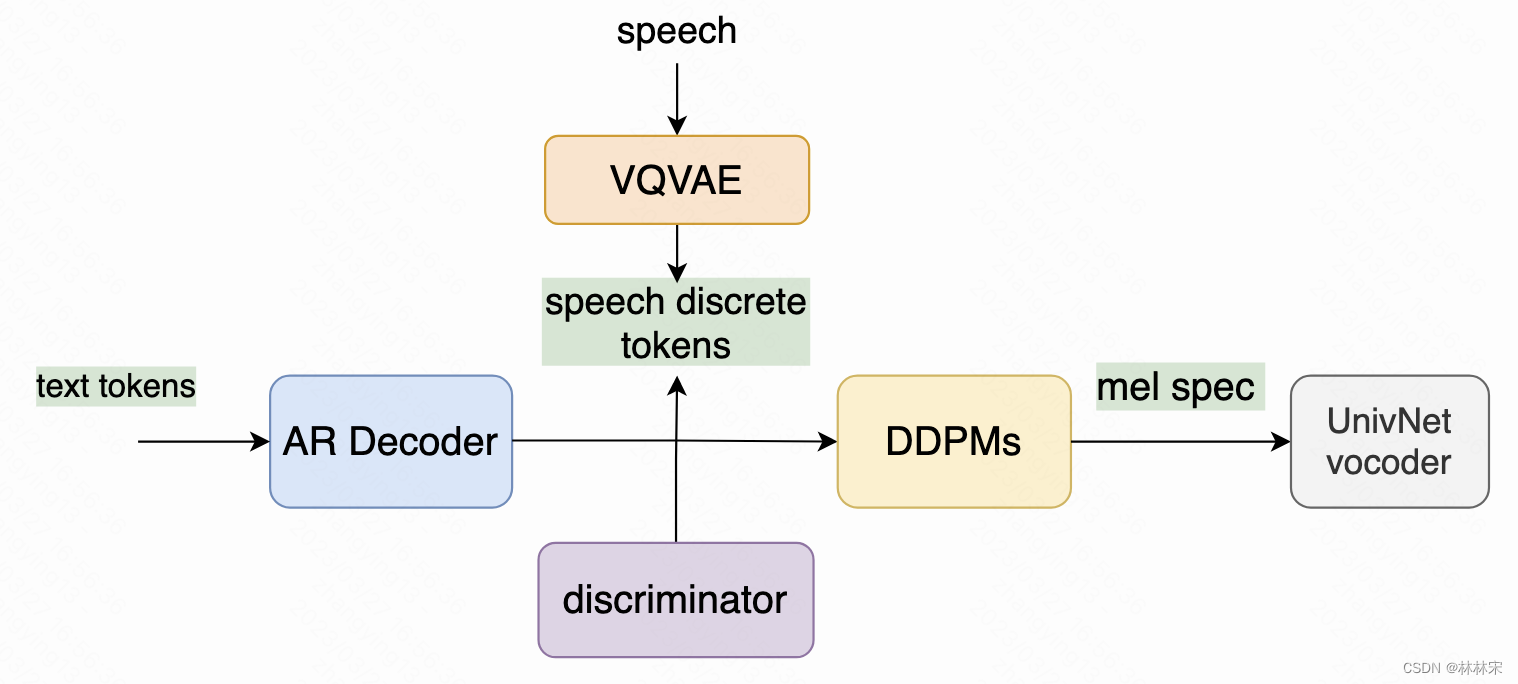
- entrada de condición: corte una sección del audio del mismo hablante como una entrada condicional para controlar el tono/prosodia del discurso sintetizado. Se ingresa un codificador de condición separado a AR Decoder y DDPM.
- Fintune DDPM: Primero, complete el entrenamiento desde tokens discretos de voz hasta mel-spec. Después de que el modelo converja, use el resultado de salida del modelo GPT para ajustar DDPM.Este paso es el que más contribuye a la mejora de los resultados generados
CLVP: Transformador preentrenado de voz y lenguaje contrastivo
- Al igual que DALL-E con CLIP, entrene un discriminador de aprendizaje contrastivo para volver a clasificar.
- Debido a que los datos TTS son un par de texto y voz, el CLVP capacitado puede desempeñarse muy bien en la tarea discriminatoria definida en este documento y juzgar si el token de voz y el token de texto coinciden.
entrenamiento e inferencia
- 8*NIVIDIA 3090, alrededor de 1 año
- La salida de AR Decoder es el método de muestreo del núcleo
- Configuración DDPM utilizada (no la última moda)

- conjunto de datos:
- tren: conjuntos de datos LibriTTS y HiFiTTS (890h) + 49000h datos rastreados en línea
- prueba: prueba LibriTTS
evaluación
- tts-scores : Aprende del método de distancia de inicio de Frechet en la imagen para evaluar la calidad de la generación, en lugar de la puntuación MOS, mejora la eficiencia y puede usarse en la fase de entrenamiento.
Apéndice I: Recopilación ampliada de conjuntos de datos
- Limpie los datos de 9.8wh rastreados desde Internet, elimine el ruido de fondo obvio, varias personas hablando al mismo tiempo y datos de baja calidad.
- Use el modelo wav2vec-large y use LibriTTS y HiFiTTS para ajustar el modelo, porque, por ejemplo, la puntuación no es importante en las tareas de ASR, pero sí lo es en las tareas de TTS.
Apéndice II - Detalles de la arquitectura y la formación
VQ-VAE
Refiriéndose al diseño del aprendizaje de representación discreta neuronal , ingrese mel-spec para predecir tokens de voz discretos. Después de 10k pasos, la pérdida de log mse converge.

Decodificador AR

-
Usando la estructura de GPT2, la diferencia con DALL-E es que solo se usa la estructura de autoatención
-
La estructura del mensaje:

-
entrada de condición: ingrese un mel-spec con un máximo de 6 s, otra pieza de audio del mismo altavoz y obtenga una incrustación de vector después de pasar por el codificador. Para una muestra de entrenamiento, obtenga dos codificaciones, promedie y colóquelas al principio < SC >.
-
Inserte la descripción de la imagen aquí
Use la incrustación posicional aprendida: texto/mel cada uno tiene información de posición, la longitud máxima es de 403 tokens de texto + 604 tokens de mel. El audio de 6 s se usa al comienzo del entrenamiento y el audio de ~ 27 s se agrega más tarde. Después de que AR-Decoder converja, use el ajuste fino de datos limpios de LibriTTS y HIFITTS.
CLVP
Codificador doble, codificación de texto y mel. Los tokens de entrada pierden aleatoriamente un 15%, el texto más grande es de aproximadamente 350, el mel más largo es de 293, aproximadamente 13 segundos
difusión
- 3 entradas de condición: señal de paso de tiempo (proporción de norma de red); condición de voz; entrada de decodificador AR.
trabajo futuro
- La restricción de la atenuación del código VQVAE se puede mejorar en gran medida;
- El código de posición relativa reemplaza al código de posición absoluta, que puede estar exento de la limitación de la longitud de entrada;
- Cuanto mayor sea el tamaño del lote de aprendizaje comparativo, mejor será el efecto;
- Mayor longitud de audio: campo perceptivo de CLVP 13s, más inútil;
- Desajuste de front-end y back-end: modelo acústico 22k, vocoder 24k