Tabla de contenido
1 ¿Qué es una base de datos vectorial?
2 Principio de funcionamiento de la base de datos vectorial
3 Algoritmo de recuperación de vectores
3.1 Métodos basados en árboles
3.2 Métodos basados en gráficos
3.3 Métodos basados en la cuantificación
3.5 Método basado en índice invertido
3.6 Tendencia de desarrollo de la recuperación de vectores
4 Principales bases de datos vectoriales de código abierto
5 IA y base de datos vectorial
1 ¿Qué es una base de datos vectorial?
La base de datos de vectores (Base de datos de vectores), también llamada base de datos de vectores, se utiliza principalmente para almacenar y procesar datos de vectores.
En matemáticas, un vector es una cantidad con magnitud y dirección, que se puede representar mediante un segmento de línea con una flecha. La flecha apunta a la dirección del vector, y la longitud del segmento de línea representa el tamaño del vector. La distancia o similitud entre dos vectores se puede obtener mediante la distancia de Hamming, la distancia euclidiana o la distancia del coseno.
Los datos no estructurados, como imágenes, textos, audio y video, pueden convertirse en datos vectoriales y almacenarse en una base de datos vectorial a través de alguna transformación o aprendizaje incorporado, para realizar la búsqueda y recuperación de similitudes de imágenes, texto, audio y video. Esto significa que puede utilizar una base de datos vectorial para encontrar los datos más similares o relacionados en función del significado semántico o contextual, en lugar de utilizar los métodos tradicionales de consulta de la base de datos en función de coincidencias exactas o criterios predefinidos.
La característica principal de la base de datos vectorial es el almacenamiento y la recuperación eficientes. El uso de tecnología de indexación y algoritmos de recuperación de vectores puede lograr una respuesta rápida en big data de alta dimensión. La base de datos vectorial también es un tipo de base de datos. Además de administrar datos vectoriales, también admite la administración de datos estructurados tradicionales. En el uso real, hay muchos escenarios en los que los campos vectoriales y los campos estructurados se filtran y recuperan al mismo tiempo, lo que también es un desafío para las bases de datos vectoriales.
2 Principio de funcionamiento de la base de datos vectorial
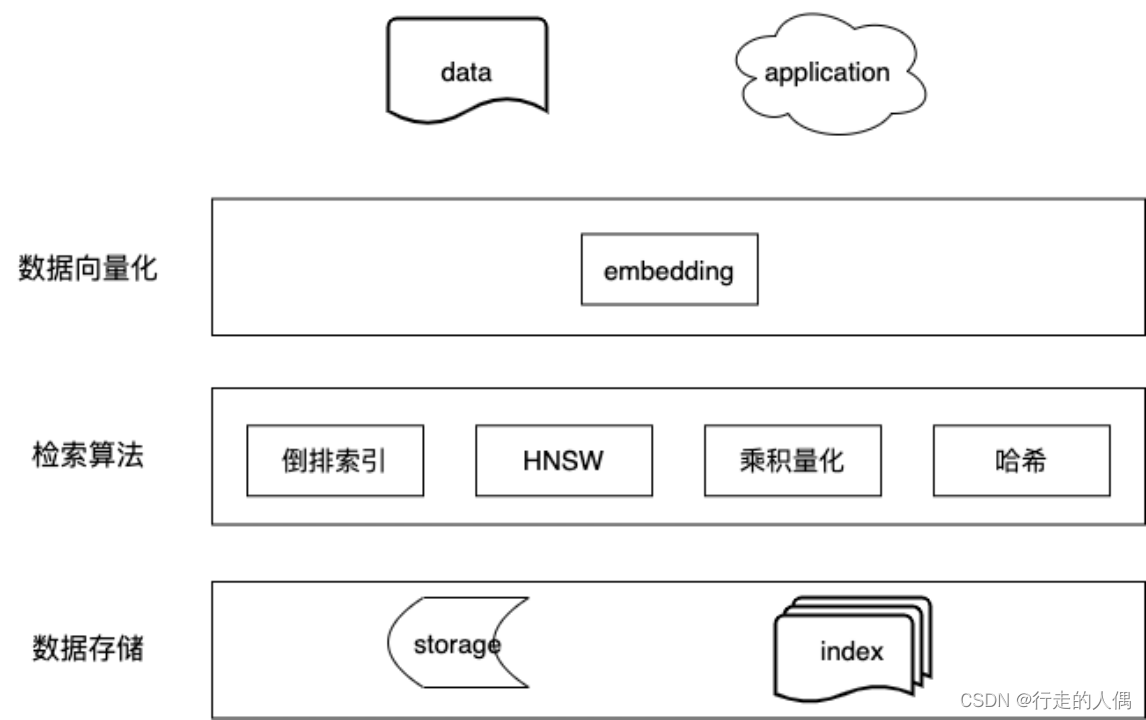
Estrictamente hablando, la vectorización de datos no pertenece a la base de datos de vectores, pero la vectorización de datos es una tarea muy importante y se incluye por el bien de la integridad del proceso. La diferencia con las bases de datos tradicionales se encuentra principalmente en los siguientes lugares: vectorización de datos, recuperación de vectores y cálculo de similitud.
2.1 Vectorización de datos
Los datos principales actuales incluyen imágenes, texto, audio y video.
Datos de imagen, que en realidad es una matriz bidimensional, y cada elemento de la matriz se compone de valores de tres canales R, G y B, por lo que se puede convertir directamente en datos vectoriales.
Se puede considerar que los datos de video agregan una dimensión de tiempo sobre la base de los datos de imagen, que se pueden considerar como una matriz tridimensional.
Hay muchos métodos para datos de texto y vectorización de datos de texto, incluidos métodos discretos y métodos continuos. Hay metodologías detalladas como referencia. Puede consultar el resumen de otros colegas del grupo: Principios básicos de representación del lenguaje (vectorización) en PNL y una revisión de la evolución histórica (https://blog.csdn.net/u010280923/article/details/130555437).
Los datos de audio, los datos de audio se pueden convertir primero en texto y procesar de acuerdo con el método de texto.
2.2 Cálculo de similitud
La distancia entre vectores se puede usar para medir la similitud entre dos vectores. Los métodos comunes incluyen la distancia del coseno, la distancia euclidiana y el producto interno del vector.
distancia del coseno La similitud se calcula calculando el coseno del ángulo entre dos vectores. Cuando el ángulo incluido es 0, la similitud es 1, cuando el ángulo incluido es 90 grados, la similitud es 0 y cuando el ángulo incluido es 180, la similitud es -1, por lo que el rango de valores de la similitud del coseno es [- 1,1].

Distancia euclidiana. El nombre completo de distancia euclidiana es distancia euclidiana , que mide la distancia entre dos puntos en el espacio, y los puntos en el espacio pueden considerarse como vectores a partir del origen.

Producto interior vectorial. También conocido como producto escalar, se refiere a una operación binaria que toma dos vectores sobre el número real R y devuelve un escalar de valor real. El producto escalar de dos vectores a = [a1, a2,…, an] y b = [b1, b2,…, bn] se define como: a b=a1b1+a2b2+…+anbn.
2.3 Recuperación de vectores
Ingrese un vector, encuentre los N vectores principales más similares al vector de entrada de la base de datos y regrese. En las aplicaciones prácticas, también es necesario guardar la relación de mapeo entre datos y vectores, es decir, devolver vectores topN y sus identificadores de datos, y obtener datos específicos de acuerdo con los identificadores de datos.
Si no utiliza ningún algoritmo para la indexación, debe recorrer todos los datos de la base de datos, calcular la similitud entre los datos de la consulta y los datos de la base de datos y, a continuación, devolver las entradas topN en orden inverso a la similitud. Este método generalmente se denomina recuperación de fuerza bruta, y la tasa de recuperación y la tasa de precisión son las más altas, pero lleva mucho tiempo recorrer y calcular la similitud en el caso de una gran cantidad de datos, y algunos algoritmos estratégicos son necesarios para optimización En términos de tasa de recuperación, compensación de memoria entre ocupación y tiempo de respuesta.
3 Algoritmo de recuperación de vectores
De hecho, la recuperación de vectores se puede ver como una búsqueda aproximada del vecino más cercano (búsqueda aproximada del vecino más cercano).A través del índice preconstruido, el espacio de búsqueda durante la consulta de datos se reduce tanto como sea posible y la velocidad de recuperación se acelera. En la actualidad, existen varios algoritmos de recuperación principales: método basado en árboles, método basado en gráficos, método basado en la cuantificación del producto, método basado en hash y método basado en índices invertidos.
3.1 Métodos basados en árboles
La idea principal del método basado en árboles es dividir los datos, similar al árbol de búsqueda binaria, lo que reduce el espacio de búsqueda y logra el propósito de una recuperación rápida. Pero este método no es adecuado para el espacio de alta dimensión. Los métodos basados en árboles incluyen principalmente KDTree (K-Dimensional Tree) y Annoy (Aproximate Nearest Neighbors Oh Yeah).
3.1.1 Árbol KDT
La construcción de KDTree también se basa en la idea de partición recursiva. Primero, se selecciona la dimensión con la varianza más grande, y la mediana de todos los datos en esta dimensión se usa como punto de segmentación para cortar el área superrectangular en dos subáreas, y las más pequeñas que la mediana se dividen a la izquierda. , la división más pequeña que la mediana es a la derecha, y los subárboles izquierdo y derecho se construyen recursivamente hasta que se dividen todos los datos.
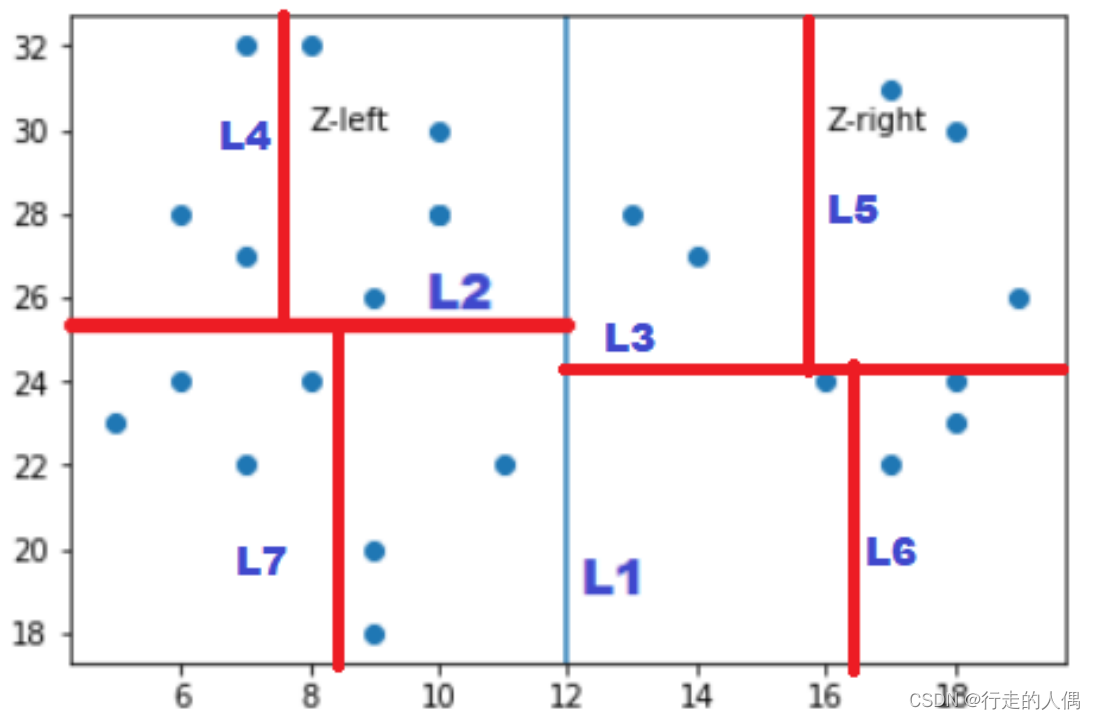
El siguiente es un ejemplo de un KDTree construido.
 Proceso de búsqueda basado en KDTree:
Proceso de búsqueda basado en KDTree:
1. Consulte los datos p, la dimensión de división d del nodo actual y juzgue el valor de las coordenadas de los datos p en la dimensión d y el tamaño del valor del nodo. Si es más grande, vaya al nodo secundario izquierdo y si es más pequeño, vaya al nodo secundario derecho;
2. Hasta que se atraviesa el nodo de hoja, se marca como visitado y la distancia al nodo de hoja se calcula como la distancia más corta;
3. Realice una operación de retroceso en el nodo hoja y calcule la distancia entre p y la rama no visitada en el nodo principal para cada retroceso.
a) Si la distancia entre el nodo de rama y p es mayor que la distancia más corta actual, continúe retrocediendo hasta el nodo raíz; b)
Si la distancia entre el nodo de rama y p es menor que la distancia más corta actual, use la distancia de rama y vaya al paso 1 y al paso 2 hasta el nodo Hoja, actualice la distancia más cercana entre la hoja y Q.
4. Devuelva los nodos topK en la subárea.
3.1.2 Molestar
Molesto usa un hiperplano para dividir el espacio. El hiperplano usa KMeans (k = 2) para encontrar dos centros de clúster. El plano normal de la línea central es el hiperplano dividido, e itera hasta que cada subespacio El número de datos está por debajo del umbral especificado. .


Para buscar cualquier punto en este espacio, se puede recorrer el árbol binario comenzando desde la raíz. Cada nodo intermedio (el cuadrado pequeño en el árbol de arriba) define un hiperplano, por lo que se puede juzgar de acuerdo con el hiperplano si el siguiente nodo secundario es el nodo secundario izquierdo o el nodo secundario derecho. La búsqueda de un punto se puede hacer en tiempo logarítmico, la altura del árbol.
3.2 Métodos basados en gráficos
El método basado en gráficos utiliza principalmente la estructura de datos del gráfico, utiliza la conectividad entre los nodos vecinos para construir una carretera y convierte el problema en un gráfico transversal, que puede reducir rápidamente el rango de búsqueda y acelerar la recuperación. Sin embargo, la estructura de datos del gráfico es relativamente compleja. Para lograr la máxima velocidad de recuperación, el gráfico completo generalmente se carga en la memoria, lo que resulta en un uso de memoria muy alto, pero la recuperación es rápida y la tasa de recuperación es alta. .
En la actualidad, el algoritmo de búsqueda de gráficos comúnmente utilizado es principalmente HNSW (Hierarchical Navigating Small World), y NSW (Navigating Small World) es su algoritmo previo, que también debe entenderse.
3.2.1 Nueva Gales del Sur
Sobre la base de una composición simple, NSW agrega las siguientes convenciones: todos los nodos deben tener nodos adyacentes; los nodos adyacentes deben tener conexiones; el número de amigos adyacentes se usa como un hiperparámetro, que especifica el usuario. Se utiliza principalmente para resolver algunas limitaciones del método de composición simple.
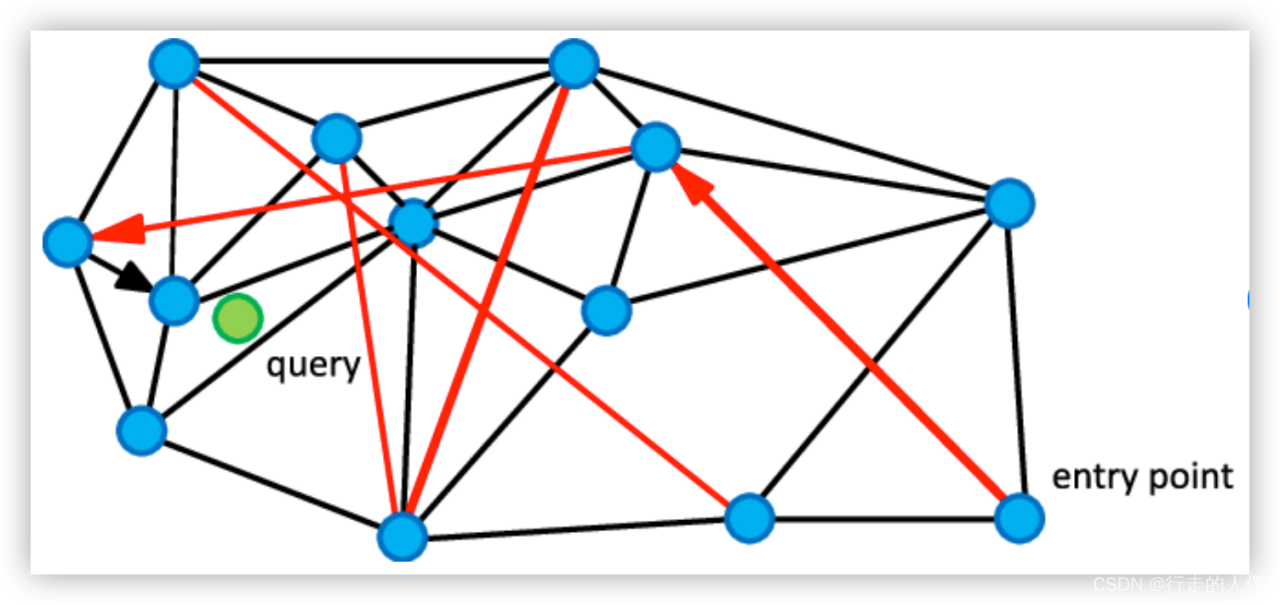
Proceso de composición de NSW:
Al insertar un nuevo nodo, primero busque los m nodos más cercanos al nuevo nodo y conecte el nuevo nodo con los m nodos.
Proceso de búsqueda de Nueva Gales del Sur:
Consulta los datos q, encuentra aleatoriamente un nodo de punto de entrada y sus nodos vecinos del gráfico, calcula la distancia entre el punto de entrada y el nodo vecino y p, si la distancia entre el vecino y p es menor que la distancia entre p y el punto de entrada, establezca el punto de distancia mínima hasta que Finalmente, se encuentra un punto, y la distancia entre todos sus vecinos y la consulta es mayor que este punto.
Como se muestra en la figura anterior, es necesario buscar el nodo más cercano a la consulta del nodo verde desde el gráfico vecino construido, comenzando desde los puntos de entrada seleccionados al azar, primero alcance rápidamente el nodo cercano a la consulta a través del enlace largo rojo, y luego pase el enlace corto negro para encontrar puntos satisfactorios.
NSW también es un cálculo aproximado y no se puede garantizar que sea el vecino real más cercano. El punto que se inserta antes tiene lados más redundantes, y es más probable que forme una carretera, y el punto que se inserta más tarde, menos probable es que tenga una carretera.
3.2.2 HNSW
HNSW es una solución mejorada basada en NSW. Utiliza principalmente la idea de omitir tablas y usa capas para implementar. Cada capa es un NSW, que también se puede llamar un método NSW en capas. Cuanto mayor sea el nivel, menor será el número de nodos, mayor será la distancia entre los nodos, menor será el número, más nodos, más conexiones y más cercana la distancia promedio.

Método de composición HNSW:
Los datos se insertan en la capa inferior, y luego se selecciona aleatoriamente un número de capa como el número de capa del nuevo nodo, y el nodo se agrega a cada capa desde la capa inferior a la vez, y los k nodos más cercanos se encuentran en cada uno. capa para establecer un borde con el nodo insertado.El algoritmo de búsqueda de la primera capa es el mismo que el de NSW.
Para cada nodo, hay un número máximo de aristas emax.Si el antiguo nodo excede emax después de establecer una nueva arista, se eliminará la arista con la mayor distancia.
Método de búsqueda HNSW:
A partir de la capa superior, cada capa encuentra el nodo vecino más cercano a través del algoritmo NSW, y el nodo de búsqueda inicial de la siguiente capa es el resultado de la búsqueda de la capa anterior.
3.3 Métodos basados en la cuantificación
El punto de partida del método de cuantificación es reducir la cantidad de cálculo. Los dos métodos anteriores reducen el espacio de búsqueda, pero la cantidad de cálculo individual sigue siendo muy grande. A través del método de cuantificación, se pierde cierta precisión, se reduce la cantidad de cálculo y se logra el propósito de acelerar la recuperación.
Los métodos de cuantificación incluyen principalmente SQ (ScalarQuantization) y PQ (Product Quantization).
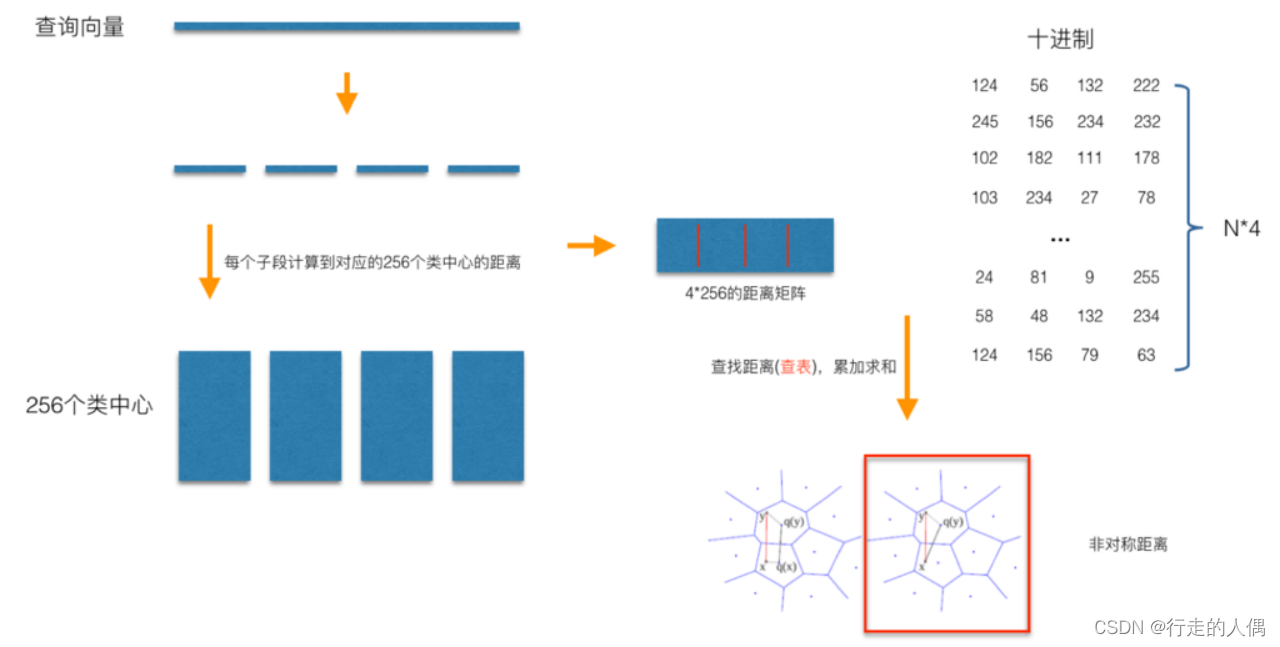
SQ es un número que cuantifica cada dimensión en un número específico de bits. Por ejemplo, cuantificar un int de 32 bits en un int de 8 bits reduce los costos de almacenamiento al perder una cierta cantidad de precisión. PQ divide todo el vector en M segmentos, y cada segmento se cuantifica en un número con un número específico de dígitos. Por ejemplo, la siguiente figura divide un vector de 128 dimensiones (32 bits por dimensión) en 4 segmentos, y cada segmento se cuantifica en un número de 8 bits. , es equivalente a que cada segmento contenga 256 centros de clúster, luego un vector de 128 dimensiones se puede representar mediante un vector de 4 dimensiones (8 bits por dimensión).
Aquí usamos PQ para ilustrar.
En el proceso de construcción del índice PQ, primero se segmenta y cuantifica cada vector y luego se agrupa cada segmento. Tomando una biblioteca de vectores de 128 dimensiones como ejemplo para ilustrar, primero divida el vector de 128 dimensiones en 4 segmentos, cada segmento tiene 32 dimensiones, y cada segmento se cuantifica en 8 bits mediante agrupamiento (256 centros de agrupamiento, 2 a la octava potencia ), es decir, un vector de 128 dimensiones se puede cuantificar en una representación de 4 dimensiones (8 bits por dimensión).
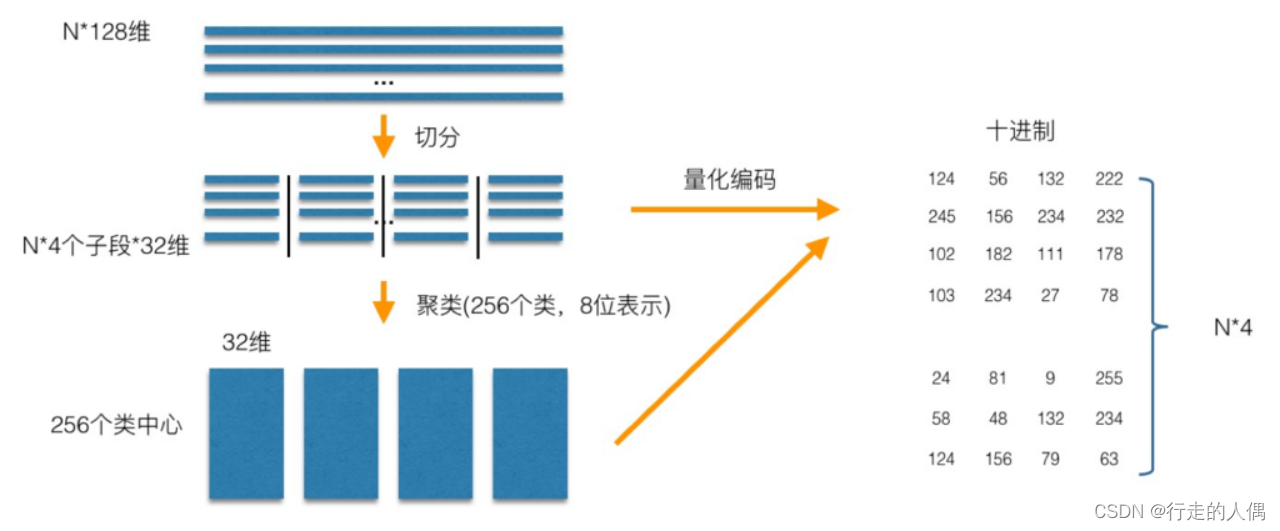 Al buscar, divida el vector de consulta de 128 dimensiones en 4 segmentos de vectores de 32 dimensiones de la misma manera, calcule la distancia entre cada vector de segmento y el centro del grupo del segmento actual para obtener una tabla de 4*256 y cuantifique la consulta. vector como [m1, m2, m3, m4], y luego consulte y calcule la distancia entre el vector de consulta y el vector en la biblioteca de la tabla previamente calculada d = d1 + d2 + d3 + d4, donde d1 es el primer sub -vector del vector de consulta y el centro del clúster cuyo ID es m1 Distancia, d2, d3, d4 son iguales.
Al buscar, divida el vector de consulta de 128 dimensiones en 4 segmentos de vectores de 32 dimensiones de la misma manera, calcule la distancia entre cada vector de segmento y el centro del grupo del segmento actual para obtener una tabla de 4*256 y cuantifique la consulta. vector como [m1, m2, m3, m4], y luego consulte y calcule la distancia entre el vector de consulta y el vector en la biblioteca de la tabla previamente calculada d = d1 + d2 + d3 + d4, donde d1 es el primer sub -vector del vector de consulta y el centro del clúster cuyo ID es m1 Distancia, d2, d3, d4 son iguales.
3.4 Métodos basados en hash
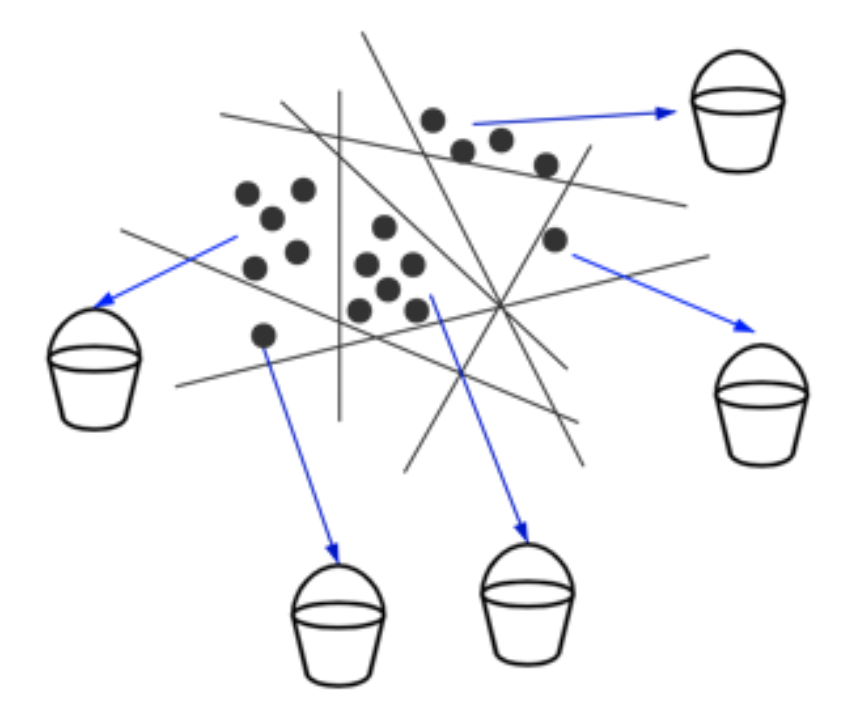
El método basado en hash utiliza principalmente las características de la función hash, y el valor hash de los datos con gran similitud también es similar. Las funciones hash pueden convertir datos de alta dimensión en datos de baja dimensión, lo que mejora en gran medida la eficiencia de la construcción. Pero la función hash también tiene otra limitación: los datos con valores hash similares no son necesariamente similares, lo que resulta en una baja tasa de recuperación de este método. El método basado en hash es principalmente LSH (Locality-Sensitive Hashing).
LSH es también un método basado en la división espacial, suponiendo que dos vectores son similares, sus valores hash también son similares. Use una función hash para mapear vectores similares en el mismo depósito. Al consultar, primero busque el depósito que sea más similar al vector de consulta y luego consulte y calcule el topk que sea más similar a los datos del depósito.
3.5 Método basado en índice invertido
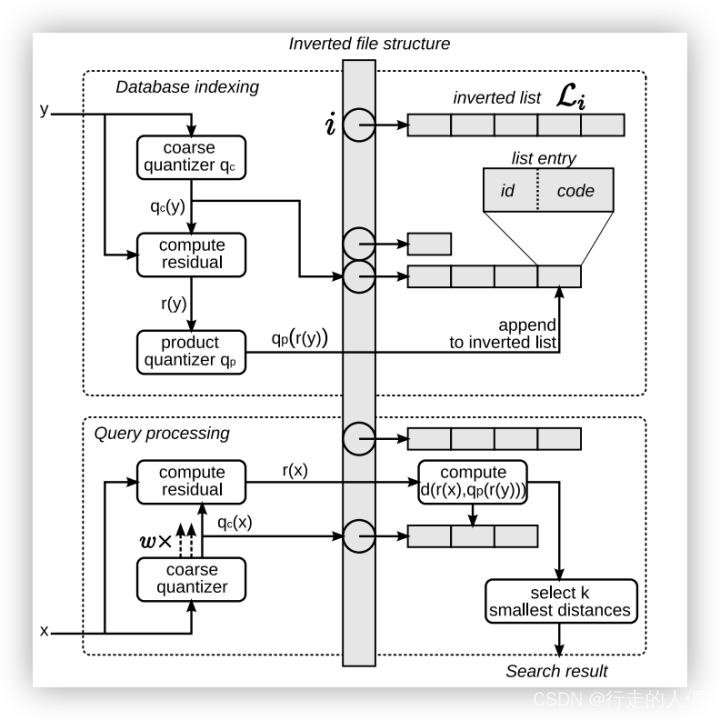
El índice invertido, también conocido comúnmente como índice invertido, archivo colocado o archivo invertido, es un método de indexación que se utiliza para almacenar la ubicación de almacenamiento de una palabra en un documento o un grupo de documentos en un mapa de búsqueda de texto completo. Es la estructura de datos más utilizada en los sistemas de recuperación de documentos. A través del índice invertido, puede obtener rápidamente una lista de documentos que contienen esta palabra según la palabra.
Para construir un índice invertido para un vector, aún es necesario usar el método de agrupación para dividir los datos en m subespacios a través de la agrupación y luego establecer un índice invertido para la relación de mapeo entre los datos y el centro de la agrupación. Al buscar, primero puede encontrar el centro del clúster más cercano al vector de consulta, luego encontrar todos los datos del subespacio contenidos en el centro del clúster desde el índice invertido y seleccionar los k datos más similares.
 3.6 Tendencia de desarrollo de la recuperación de vectores
3.6 Tendencia de desarrollo de la recuperación de vectores
En la actualidad, la arquitectura de la recuperación de vectores es más o menos la misma que la de la recuperación de datos tradicional. Cada algoritmo tiene sus propias ventajas y desventajas, y los escenarios de demanda actuales son cada vez más diversos. Respuesta/uso de memoria/alta tasa de recuperación, todos tienen ciertos requisitos, y un solo algoritmo no puede cumplirlos bien. Generalmente, una variedad de algoritmos se combinan y aplican para aprovechar al máximo sus respectivas ventajas y evitar debilidades. Por ejemplo, el índice invertido más la cuantificación del producto (IVFPQ), que puede tener en cuenta tanto la recuperación como la velocidad de consulta.
Por tratarse de datos vectoriales, sus operaciones matriciales también pueden ser aceleradas por GPU, cuando las condiciones del hardware son suficientes, GPU también es otra opción para acelerar consultas.
4 Principales bases de datos vectoriales de código abierto
4.1 Faiss
Faiss es una biblioteca de código abierto para la búsqueda eficiente de similitudes y la agrupación de vectores densos. Faiss está escrito en C++ con un contenedor Python/numpy completo. Algunos algoritmos de uso común tienen implementaciones de GPU.
Faiss proporciona una gran cantidad de algoritmos de indexación, puede crear diferentes tipos de índices y proporciona una función de cálculo de similitud de clics o distancia euclidiana.Algunos tipos de índices son líneas de base simples, como la búsqueda precisa. La mayoría de las estructuras de índice disponibles corresponden al tiempo de búsqueda, la calidad de la búsqueda, la memoria utilizada por vector de índice, el tiempo de entrenamiento, el tiempo de adición, los datos externos necesarios para el entrenamiento no supervisado, etc.
Utilizando el ejemplo, cree un índice.
import faiss # make faiss available
index = faiss.IndexFlatL2(d) # build the index
print(index.is_trained)
index.add(xb) # add vectors to the index
print(index.ntotal)Recuperar datos.
k = 4 # we want to see 4 nearest neighbors
D, I = index.search(xb[:5], k) # sanity checkprint(I)
print(D)
D, I = index.search(xq, k) # actual searchprint(I[:5])
# neighbors of the 5 first queriesprint(I[-5:])
# neighbors of the 5 last queries4.2 Búsqueda elástica
Elasticsearch , es un motor de búsqueda y análisis distribuido que admite varios tipos de datos. En la versión 7.3, Elasticsearch agregó soporte para indexar datos vectoriales y admitir consultas mixtas, pero la recuperación de vectores utiliza cálculos violentos, lo que resulta en una pérdida de alto rendimiento. Elasticsearch introdujo la búsqueda knn en la versión 8.0, que en realidad es un algoritmo de búsqueda de vecino más cercano aproximado. La similitud admite la distancia euclidiana, el producto escalar y la similitud del coseno. La capa inferior de la búsqueda knn en realidad usa HNSW. Sin embargo, este método no puede realizar una recuperación mixta.
PUT vector-index-test
{
"mappings": {
"properties": {
"my_vector": {
"type": "dense_vector",
"dims": 128,
"index": true,
"similarity": "dot_product"
}
}
}
}GET my-index-knn/_knn_search
{
"knn": {
"field": "title_vector",
"query_vector": [0.3, 0.1, 1.2, ...],
"k": 10,
"num_candidates": 20
},
"_source": ["name", "date"]
}4.3 Cometa
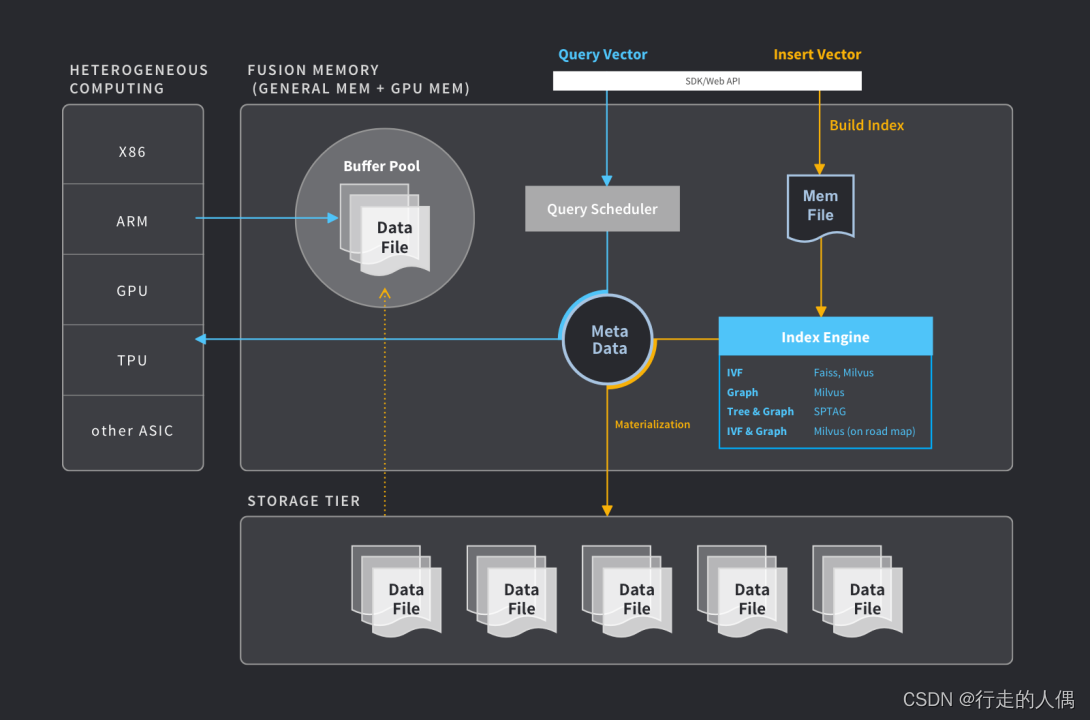
Milvus (https://github.com/milvus-io/milvus) es una base de datos de vectores distribuidos de código abierto, que tiene las características de alta disponibilidad, alto rendimiento y fácil expansión, y se utiliza para la recuperación en tiempo real de vectores masivos. datos.
Milvus se basa en bibliotecas de búsqueda de vectores como Faiss, Annoy y HNSW. El núcleo es resolver el problema de la recuperación de similitud de vectores densos. Basado en la biblioteca de recuperación de vectores, Milvus admite funciones como la partición de datos, la persistencia de datos, la ingesta de datos incrementales, la consulta híbrida escalar-vectorial, el viaje en el tiempo, etc., y optimiza en gran medida el rendimiento de la recuperación de vectores para cumplir con los requisitos de cualquier aplicación de escenario de recuperación de vectores. .
4.4 VectorPG
PGVector (https://github.com/pgvector/pgvector) es un complemento de vectores para la base de datos PG, que permite que la base de datos PG admita capacidades de recuperación de índices vectoriales. El algoritmo de indexación de pgvector utiliza el índice ivfflat basado en faiss, que proporciona una recuperación excelente.
# Enable the extension (do this once in each database where you want to use it)
CREATE EXTENSION vector;
# Create a vector column with 3 dimensions
CREATE TABLE items (id bigserial PRIMARY KEY, embedding vector(3));
# Insert vectors
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]');
# Get the nearest neighbors by L2 distance
SELECT * FROM items ORDER BY embedding <-> '[3,1,2]' LIMIT 5;
# Also supports inner product (<#>) and cosine distance (<=>)5 IA y base de datos vectorial
En los últimos años, la inteligencia artificial se ha desarrollado rápidamente, especialmente el desarrollo de grandes modelos de lenguaje ha llevado a la inteligencia artificial a un nuevo nivel. Aunque la representación semántica (incrustación) no es tan fácil de perder como los datos de imagen, el aprendizaje integral de grandes modelos de lenguaje, especialmente el aprendizaje de corpus de modelos múltiples, ha llevado la representación semántica un paso más cerca. Esta es otra oportunidad de desarrollo para las bases de datos vectoriales.
La recuperación basada en la semántica puede mejorar los motores de búsqueda tradicionales. En comparación con la recuperación basada en términos tradicionales, la recuperación semántica no solo puede recordar datos que contienen palabras clave, sino también datos que son sinónimos de oraciones de consulta. En la aplicación real, los resultados de las dos fuentes de recuperación se pueden ordenar y devolver.
También se puede utilizar para el almacenamiento en caché semántico. En la actualidad, la llamada de la API de diálogo del modelo a gran escala es más costosa desde el punto de vista computacional. De hecho, muchos problemas se repiten. Los resultados del diálogo del usuario se pueden almacenar en caché semánticamente, y no es necesario ingresarlos en el modelo para razonar cada vez. En algunos escenarios de una sola ronda, es relativamente útil.
Se espera que la brecha semántica pueda cerrarse por completo en un futuro próximo. En ese momento, todo podrá integrarse, todo el conocimiento se almacenará en la base de datos vectorial y llegará la verdadera inteligencia artificial.
6 Referencias
[1] ¿Qué es una base de datos vectorial?
[2] Base de datos de vectores | aprender
[3] Columna - Historia del desarrollo de bases de datos | Comunidad TiDB
[4] Hecho |
[5] Vecinos más cercanos y modelos vectoriales – parte 2 – algoritmos y estructuras de datos
[6] Encuentra el vecino más cercano usando KD Tree | kanoki
[7] Diez minutos para comenzar con la tecnología de recuperación de vectores-Conocimiento