Directorio de artículos
0 tutoriales preliminares
1 ¿Qué es la implementación de modelos?
En el tutorial anterior, presentó la construcción del entorno yolov5 y cómo usar yolov5 para el entrenamiento y prueba de modelos.Aunque puede realizar el reconocimiento objetivo de imágenes o videos, todo se basa en el marco de aprendizaje profundo de pytorch. Solo para usar el modelo entrenado, debe adjuntar un marco enorme, por lo que el programa aparecerá inflado y no elegante. Por lo tanto, es muy necesario deshacerse de la dependencia del marco de aprendizaje profundo. Este es el despliegue del modelo de aprendizaje profundo.
2 Cómo implementar
Aquí se usa el módulo dnn de opencv, que puede leer y usar el modelo de aprendizaje profundo. Sin embargo, este módulo no es compatible con el modelo pytorch, es decir, el archivo de formato pt entrenado. Por lo tanto, al usar este modelo, debe convertir el archivo pt a un formato de modelo que pueda leer opencv, es decir, onnx.
La conversión del formato del modelo utiliza el archivo export.py que viene con yolov5, que proporciona una variedad de formatos de archivo correspondientes a marcos comunes de aprendizaje profundo. Como regla antigua, lea los comentarios al principio del archivo antes de usarlo:
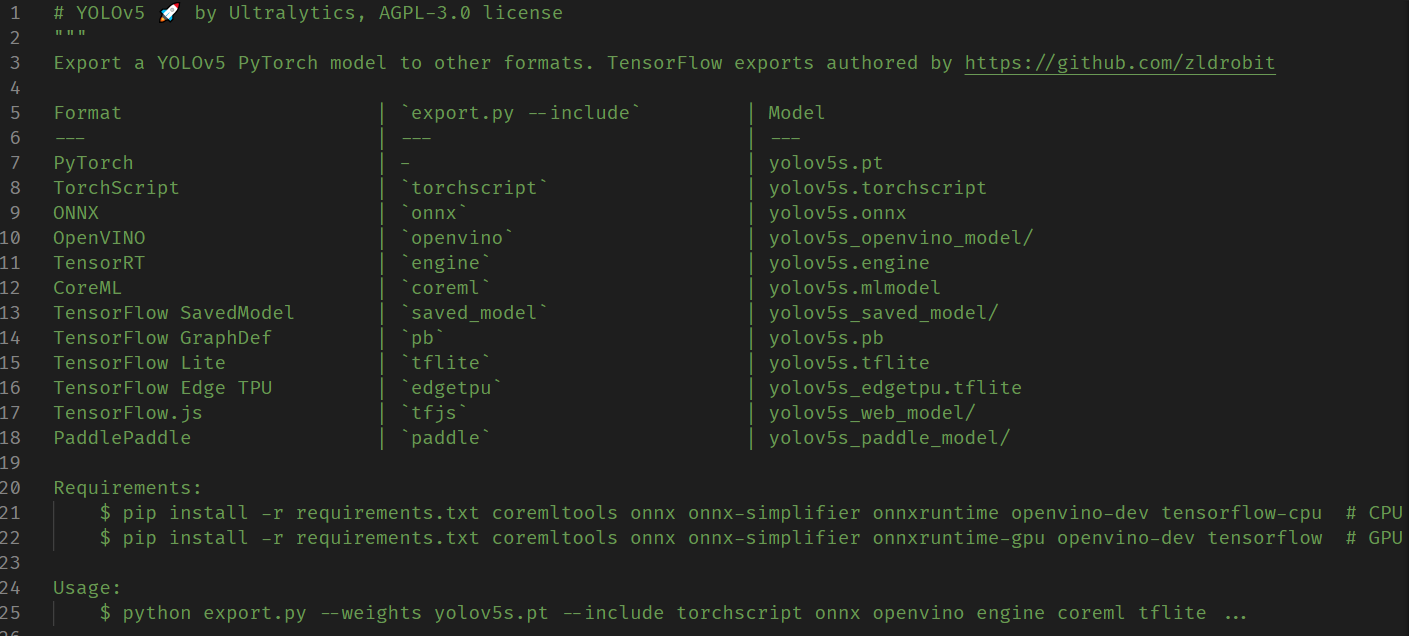
Lo que necesitamos es el formato onnx, así que instale onnx antes de ejecutar:
pip install onnx
Luego ejecute el archivo export.py:
python export.py --weights 'C:\Users\Zeoy\Desktop\Code\Python\yolov5-master\runs\train\exp19\weights\best.pt' --include onnx
El archivo onnx generado también se encuentra en la carpeta donde se encuentra el best.pt original.
Una vez completada la conversión, el siguiente paso es usar y ejecutar el código que se muestra a continuación:
import cv2
import numpy as np
class Onnx_clf:
def __init__(self, onnx:str='Material/best.onnx', img_size=640, classlist:list=['bottle']) -> None:
''' @func: 读取onnx模型,并进行目标识别
@para onnx:模型路径
img_size:输出图片大小,和模型直接相关
classlist:类别列表
@return: None
'''
self.net = cv2.dnn.readNet(onnx) # 读取模型
self.img_size = img_size # 输出图片尺寸大小
self.classlist = classlist # 读取类别列表
def img_identify(self, img, ifshow=True) -> np.ndarray:
''' @func: 图片识别
@para img: 图片路径或者图片数组
ifshow: 是否显示图片
@return: 图片数组
'''
if type(img) == str: src = cv2.imread(img)
else: src = img
height, width, _ = src.shape #注意输出的尺寸是先高后宽
_max = max(width, height)
resized = np.zeros((_max, _max, 3), np.uint8)
resized[0:height, 0:width] = src # 将图片转换成正方形,防止后续图片预处理(缩放)失真
# 图像预处理函数,缩放裁剪,交换通道 img scale out_size swapRB
blob = cv2.dnn.blobFromImage(resized, 1/255.0, (self.img_size, self.img_size), swapRB=True)
prop = _max / self.img_size # 计算缩放比例
dst = cv2.resize(src, (round(width/prop), round(height/prop)))
# print(prop) # 注意,这里不能取整,而是需要取小数,否则后面绘制框的时候会出现偏差
self.net.setInput(blob) # 将图片输入到模型
out = self.net.forward() # 模型输出
# print(out.shape)
out = np.array(out[0])
out = out[out[:, 4] >= 0.5] # 利用numpy的花式索引,速度更快, 过滤置信度低的目标
boxes = out[:, :4]
confidences = out[:, 4]
class_ids = np.argmax(out[:, 5:], axis=1)
class_scores = np.max(out[:, 5:], axis=1)
# out2 = out[0][out[0][:][4] > 0.5]
# for i in out[0]: # 遍历每一个框
# class_max_score = max(i[5:])
# if i[4] < 0.5 or class_max_score < 0.25: # 过滤置信度低的目标
# continue
# boxes.append(i[:4]) # 获取目标框: x,y,w,h (x,y为中心点坐标)
# confidences.append(i[4]) # 获取置信度
# class_ids.append(np.argmax(i[5:])) # 获取类别id
# class_scores.append(class_max_score) # 获取类别置信度
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.25, 0.45) # 非极大值抑制, 获取的是索引
# print(indexes)
iffall = True if len(indexes)!=0 else False
# print(iffall)
for i in indexes: # 遍历每一个目标, 绘制目标框
box = boxes[i]
class_id = class_ids[i]
score = round(class_scores[i], 2)
x1 = round((box[0] - 0.5*box[2])*prop)
y1 = round((box[1] - 0.5*box[3])*prop)
x2 = round((box[0] + 0.5*box[2])*prop)
y2 = round((box[1] + 0.5*box[3])*prop)
# print(x1, y1, x2, y2)
self.drawtext(src,(x1, y1), (x2, y2), self.classlist[class_id]+' '+str(score))
dst = cv2.resize(src, (round(width/prop), round(height/prop)))
if ifshow:
cv2.imshow('result', dst)
cv2.waitKey(0)
return dst, iffall
def video_identify(self, video_path:str) -> None:
''' @func: 视频识别
@para video_path: 视频路径
@return: None
'''
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
# print(fps)
while cap.isOpened():
ret, frame = cap.read()
#键盘输入空格暂停,输入q退出
key = cv2.waitKey(1) & 0xff
if key == ord(" "): cv2.waitKey(0)
if key == ord("q"): break
if not ret: break
img, res = self.img_identify(frame, False)
cv2.imshow('result', img)
print(res)
if cv2.waitKey(int(1000/fps)) == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
@staticmethod
def drawtext(image, pt1, pt2, text):
''' @func: 根据给出的坐标和文本,在图片上进行绘制
@para image: 图片数组; pt1: 左上角坐标; pt2: 右下角坐标; text: 矩形框上显示的文本,即类别信息
@return: None
'''
fontFace = cv2.FONT_HERSHEY_COMPLEX_SMALL # 字体
# fontFace = cv2.FONT_HERSHEY_COMPLEX # 字体
fontScale = 1.5 # 字体大小
line_thickness = 3 # 线条粗细
font_thickness = 2 # 文字笔画粗细
line_back_color = (0, 0, 255) # 线条和文字背景颜色:红色
font_color = (255, 255, 255) # 文字颜色:白色
# 绘制矩形框
cv2.rectangle(image, pt1, pt2, color=line_back_color, thickness=line_thickness)
# 计算文本的宽高: retval:文本的宽高; baseLine:基线与最低点之间的距离(本例未使用)
retval, baseLine = cv2.getTextSize(text,fontFace=fontFace,fontScale=fontScale, thickness=font_thickness)
# 计算覆盖文本的矩形框坐标
topleft = (pt1[0], pt1[1] - retval[1]) # 基线与目标框上边缘重合(不考虑基线以下的部分)
bottomright = (topleft[0] + retval[0], topleft[1] + retval[1])
cv2.rectangle(image, topleft, bottomright, thickness=-1, color=line_back_color) # 绘制矩形框(填充)
# 绘制文本
cv2.putText(image, text, pt1, fontScale=fontScale,fontFace=fontFace, color=font_color, thickness=font_thickness)
if __name__ == '__main__':
clf = Onnx_clf()
import tkinter as tk
from tkinter.filedialog import askopenfilename
tk.Tk().withdraw() # 隐藏主窗口, 必须要用,否则会有一个小窗口
source = askopenfilename(title="打开保存的图片或视频")
# source = r'C:\Users\Zeoy\Desktop\YOLOData\data\IMG_568.jpg'
if source.endswith('.jpg') or source.endswith('.png') or source.endswith('.bmp'):
res, out = clf.img_identify(source, False)
print(out)
cv2.imshow('result', res)
cv2.waitKey(0)
elif source.endswith('.mp4') or source.endswith('.avi'):
print('视频识别中...按q退出')
clf.video_identify(source)
else:
print('不支持的文件格式')
Algunas explicaciones sobre este flujo de código:
-
El primero es llamar
readNeta la función para leer el archivo del modelo onnx. -
Luego preprocesar la imagen de entrada. Específicamente, incluye: primero, debe usar numpy para convertir la imagen en un cuadrado (porque el modelo está entrenado con una imagen cuadrada), en lugar de estirarlo directamente, llena los píxeles con un valor de 0 en el lado corto y luego llama a la función para obtener el
blobFromImagecuadrado. La imagen se procesa previamente, incluida la normalización del valor de píxel, la configuración del tamaño de la imagen de salida, la conversión del espacio de color a RGB, etc. Para conocer los parámetros específicos, consulte este blog . Tenga en cuenta que el tamaño de la imagen de salida aquí debe ser coherente con los parámetros seleccionados durante el entrenamientoimg-size. El valor predeterminado es 640. Al mismo tiempo, es necesario registrar la relación de escala de la imagen cuadrada en relación con el tamaño de la imagen de salida, es decir ,正方形边长 / 640es un número de punto flotante. -
El siguiente paso es la entrada y salida de la imagen.
setInputLa función ingresa el bloque de imagen preprocesado y luego llamaforwarda la función para obtener la salida del modelo. Estas salidas del modelo son los cuadros correspondientes a los objetivos marcados con un círculo. -
El número de casillas obtenidas arriba es más de 2w, pero no todas son objetivos, y deben seleccionarse de acuerdo con el nivel de confianza. Aquí, se usa el índice elegante de numpy, que es mucho más rápido que la operación de bucle. Luego llame
NMSBoxesa la supresión de valor no máximo para obtener el objetivo determinado y luego haga un bucle para generar el marco de la imagen. -
El contenido específico es leer el código y los comentarios para entender.