Tabla de contenido
Trabajo de implementación del modelo
- El modelo entrenado realiza inferencias sobre plataformas de software y hardware específicas.
- Código de inferencia optimizado y acelerado para hardware
Plataforma de equipos de entrenamiento:
CPU, GPU, DSP
El significado de la existencia de ONNX
La relación correspondiente entre el modelo y el hardware resulta de la complejidad de adaptación mxn, lo que conduce a problemas como desarrollo complejo y baja eficiencia.
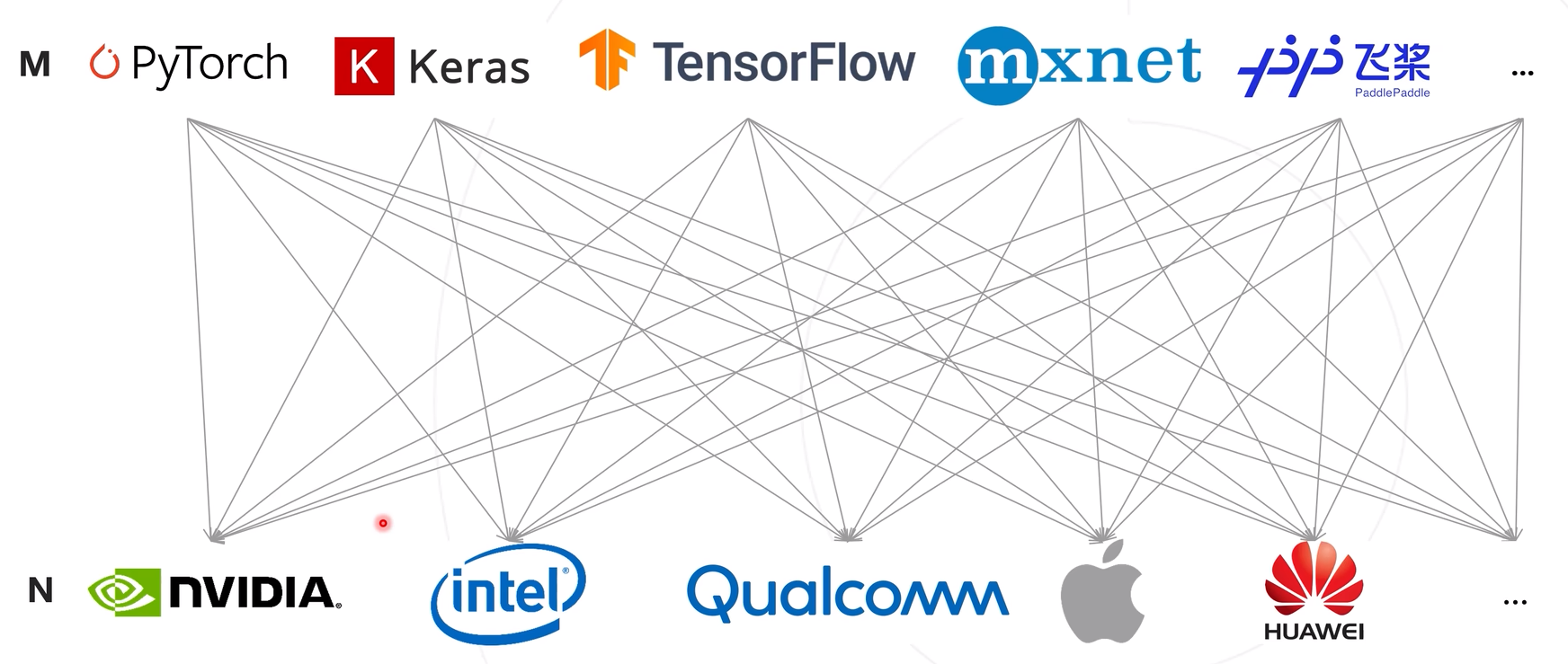
Utilice una estructura de expresión del modelo para unificar la estructura de salida del marco de capacitación y transformar la complejidad de la implementación del modelo de mxn a m+n.
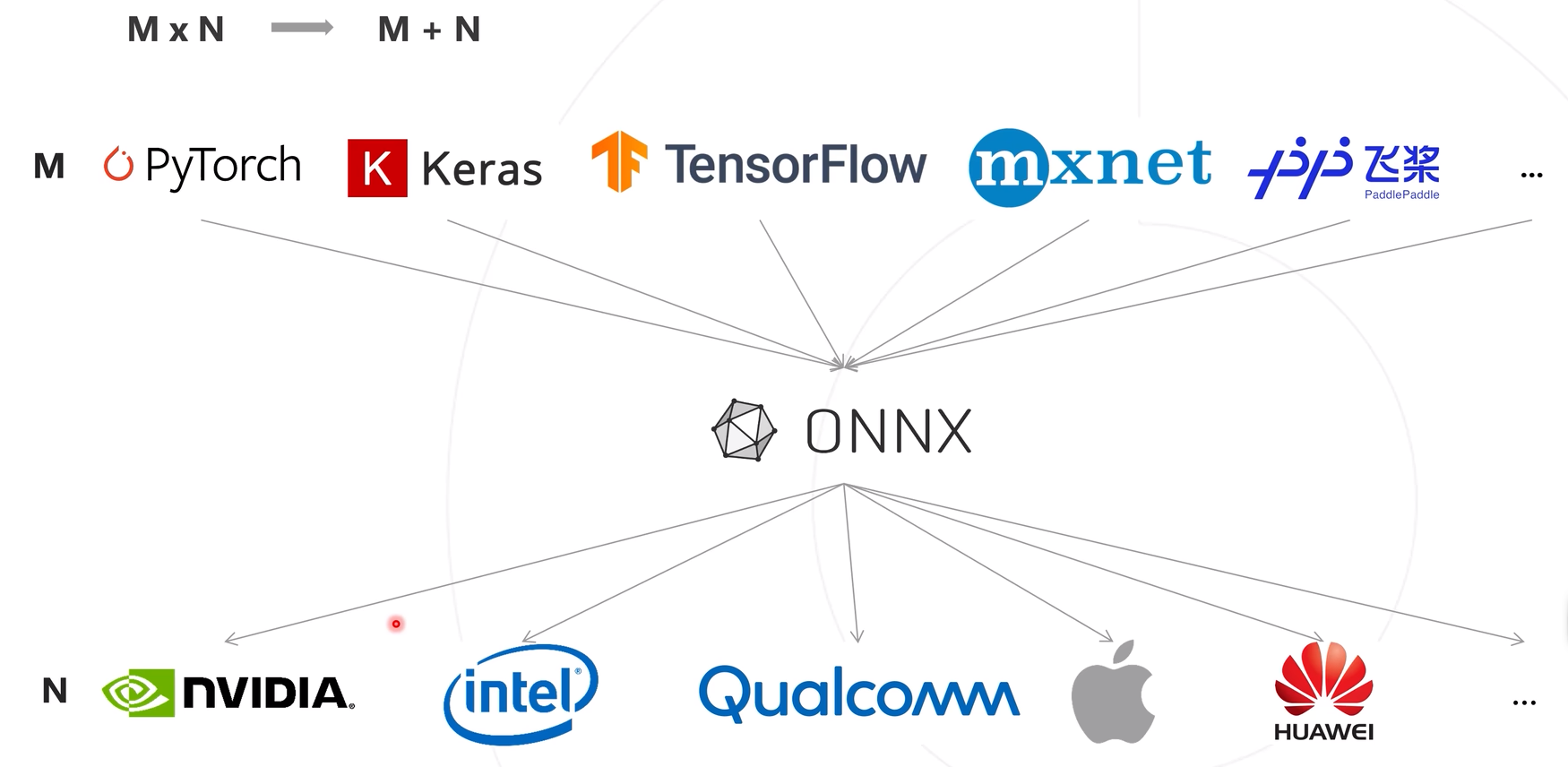
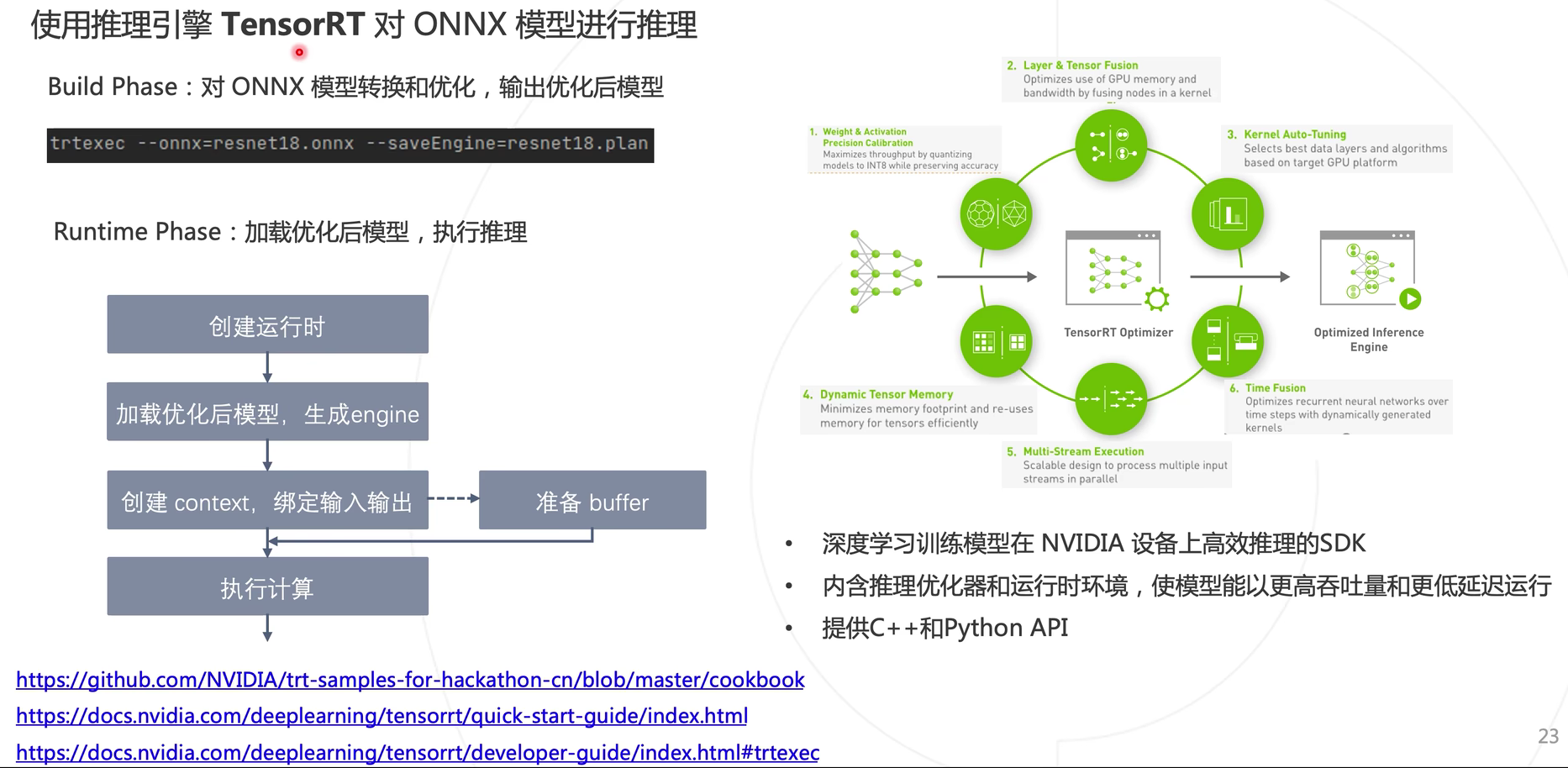
La transformación ONNX es un formato de modelo, que es texto, no un programa, y no se puede ejecutar directamente en el dispositivo. Por lo tanto, se requiere una pila de software para cargar el modelo ONNX y permitir una inferencia eficiente en los dispositivos de hardware. Esta pila de software se refiere al marco de inferencia del modelo. Los marcos de inferencia se clasifican en marcos de inferencia de uso general y de desarrollo propio por parte de los proveedores de hardware. La capa inferior del marco de razonamiento de desarrollo propio está bien optimizada y la eficiencia de cálculo del razonamiento es alta, no es universal y no se puede aplicar a otros chips. El marco de razonamiento general es versátil y se puede aplicar a diferentes plataformas de software y hardware, lo que reduce la dificultad del desarrollo y mejora la eficiencia del desarrollo. Los usuarios no necesitan prestar atención al marco subyacente y solo necesitan completar las interfaces correspondientes.
 El proceso de inferencia general: primero use el marco del modelo para entrenar el modelo, luego conviértalo a la estructura del modelo ONNX y luego use el marco de inferencia para ejecutar eficientemente el modelo ONNX en la plataforma de software y hardware.
El proceso de inferencia general: primero use el marco del modelo para entrenar el modelo, luego conviértalo a la estructura del modelo ONNX y luego use el marco de inferencia para ejecutar eficientemente el modelo ONNX en la plataforma de software y hardware.

ONNX (Intercambio de redes neuronales abiertas)
Un formato de archivo abierto diseñado para el aprendizaje automático y utilizado para almacenar modelos entrenados. Diferentes marcos de formación pueden almacenar modelos en el mismo formato e interactuar entre sí. Está copatrocinado por empresas como Microsoft, Amazon, Facebook e IBM.

Ejemplo de ONNX
Utilice torch.onnx.exportla exportación del modelo onnx.
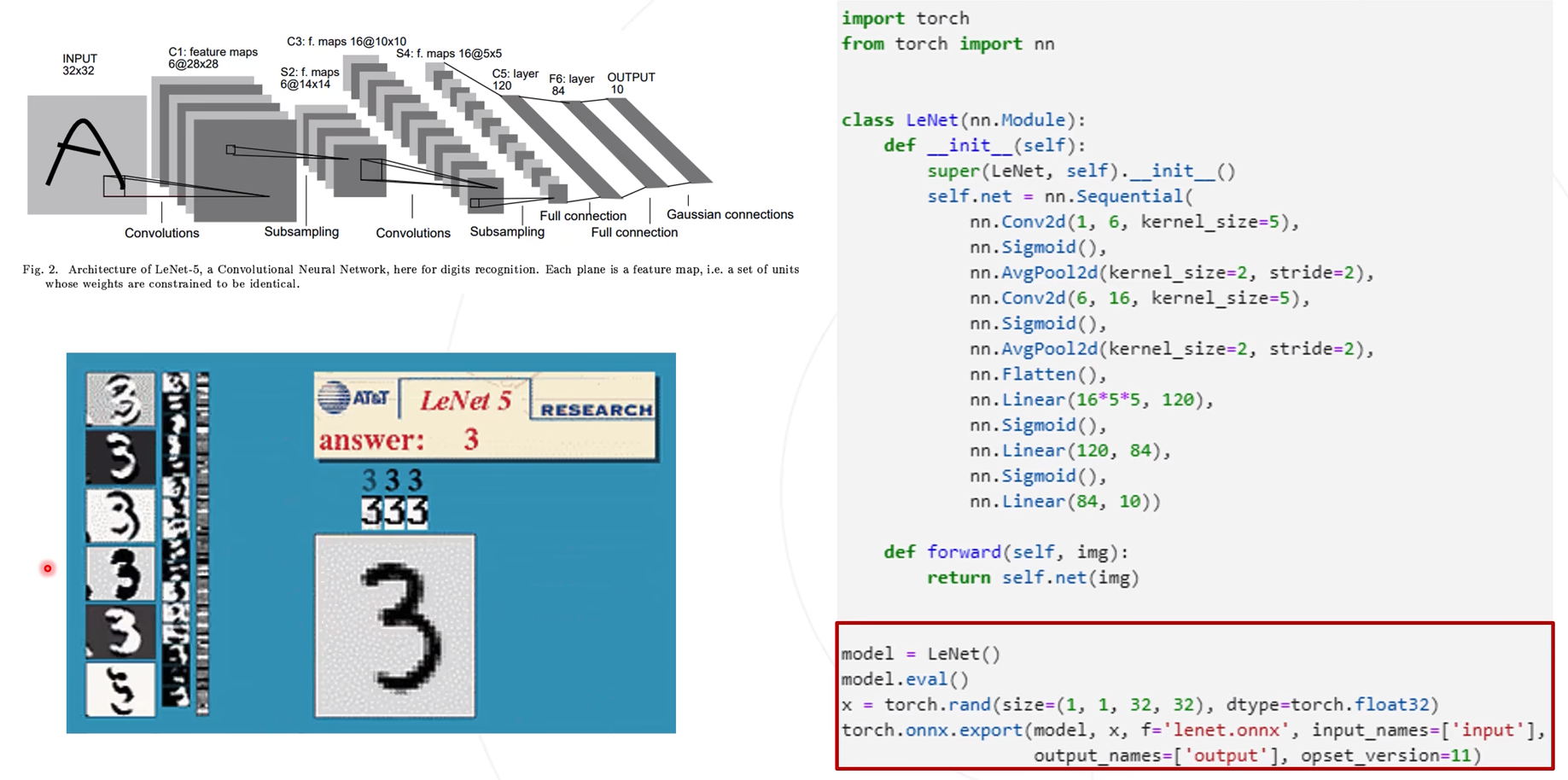
Después de exportar el modelo onnx, ingrese netron.app para visualizar la estructura del modelo.


Explicación del parámetro de exportación del modelo ONNX de ResNet

Ejemplo de inferencia de modelo
Utilice el ejemplo en mmdeploy para aplicar ONNX Runtime para la inferencia del modelo.
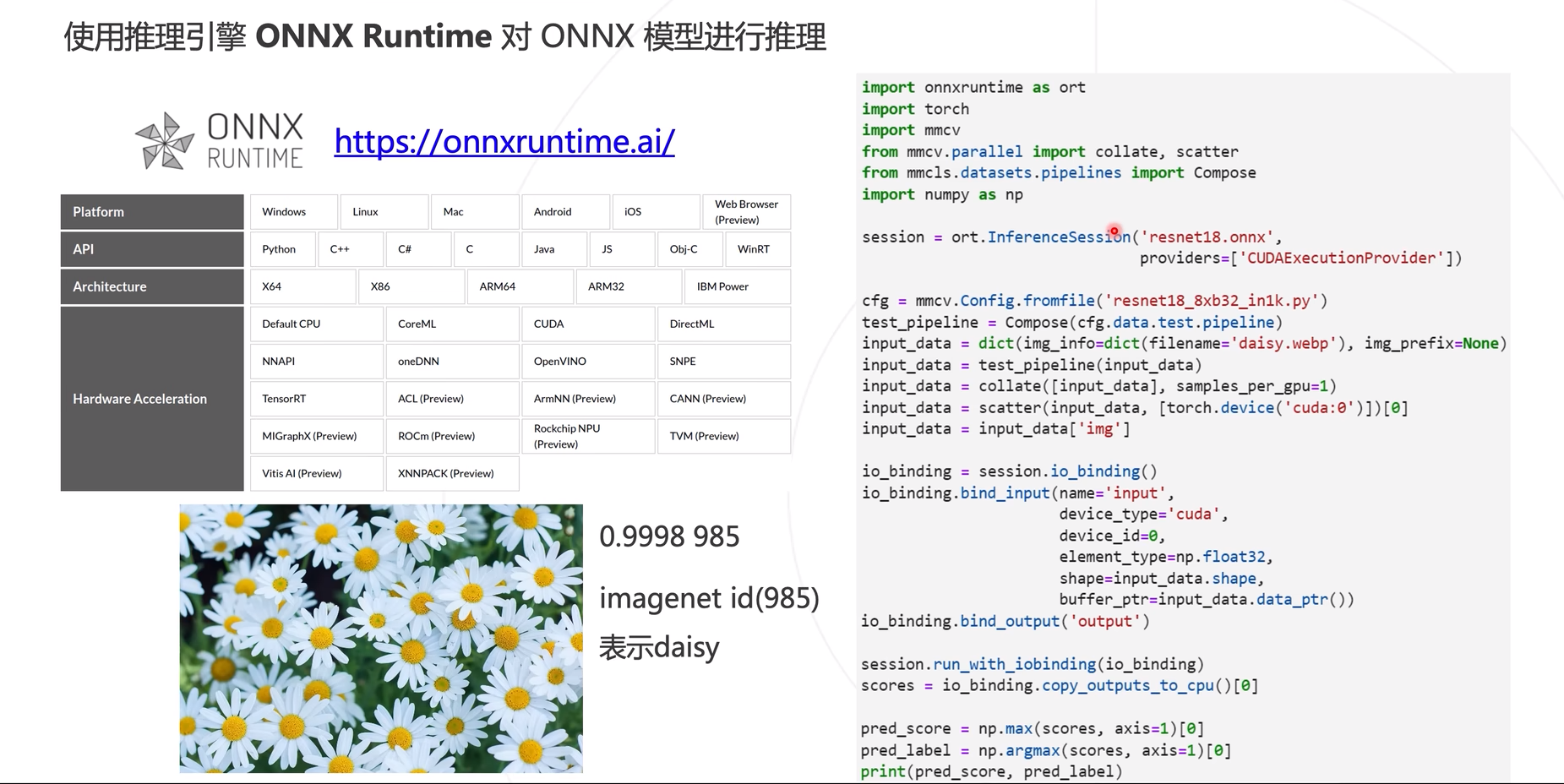
Utilice TensorRT para inferir el modelo ONNX.
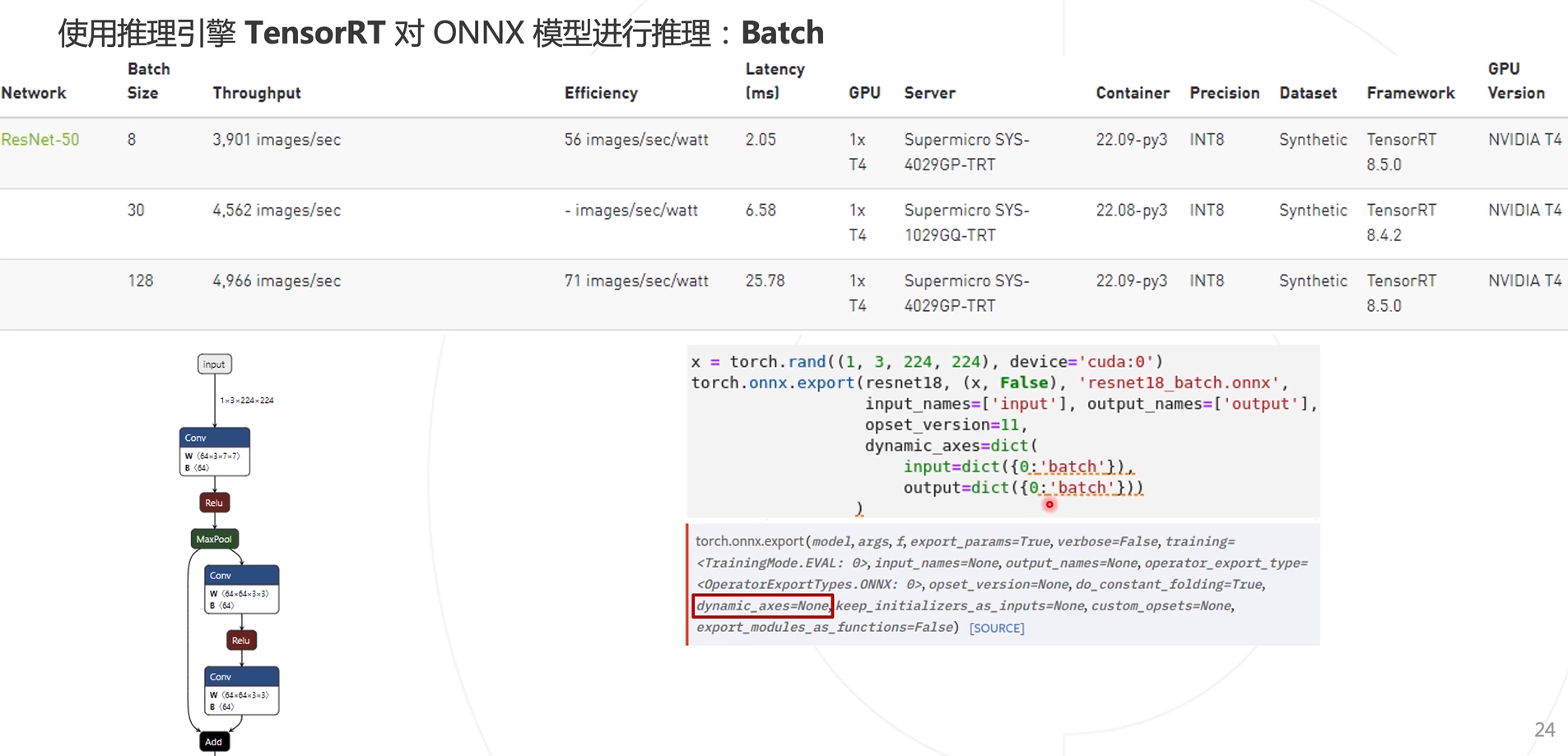
Ajuste de lotes
Al generar ONNX arriba, (1, X, X, esto se puede lograr con el parámetro Dynamic_axes.
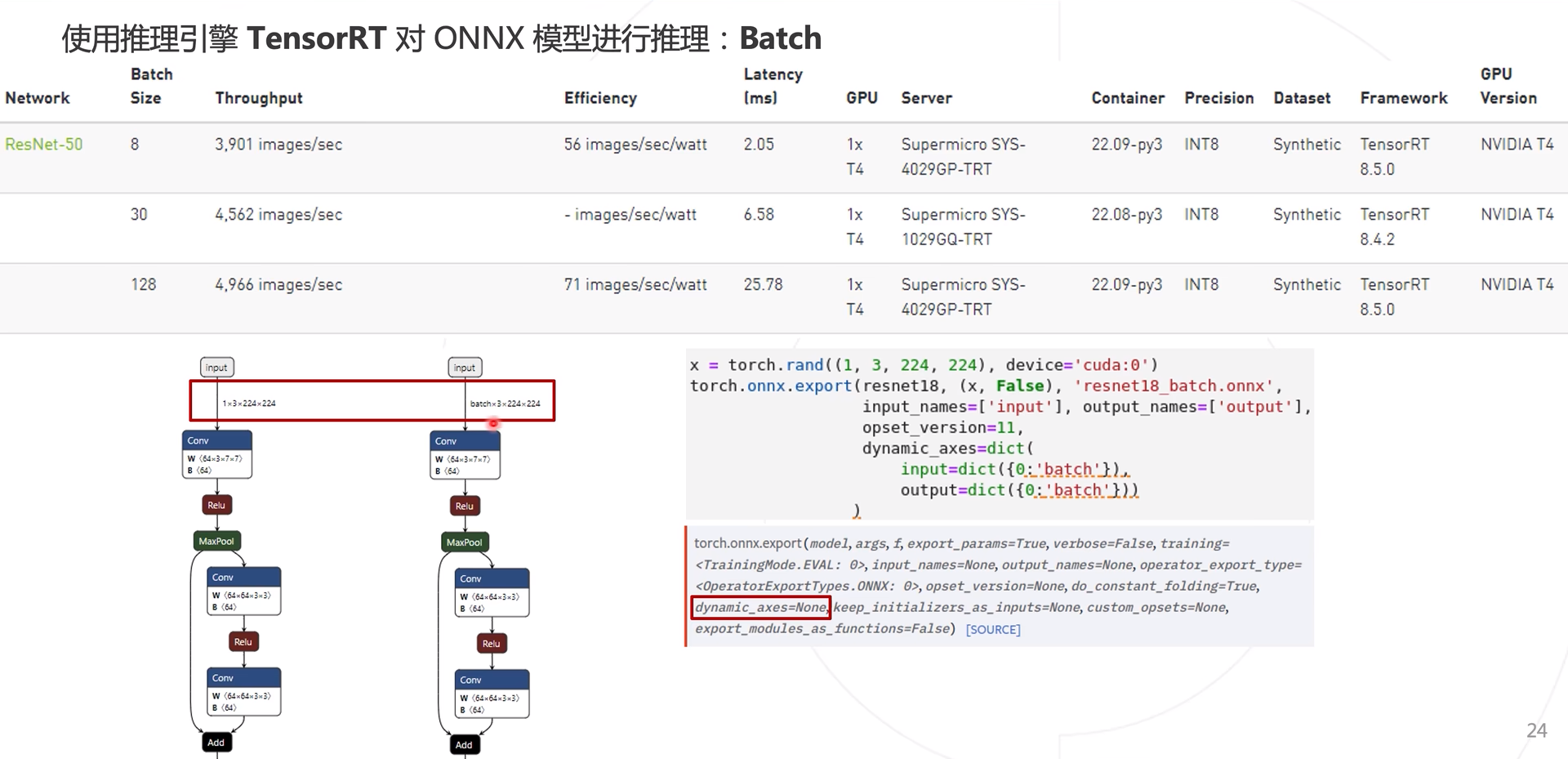
Modificar en la conversión de formato de datos del modelo TensorRT, la configuración de los parámetros minShapes y maxShapes

Cuantificar
Además de utilizar Batch para aumentar la velocidad de inferencia del modelo, también puede utilizar la cuantificación para la aceleración. En términos generales, el uso float16no afectará el cambio de precisión del modelo, mientras que int8la precisión del modelo se reducirá ligeramente después de usar el formato de almacenamiento.
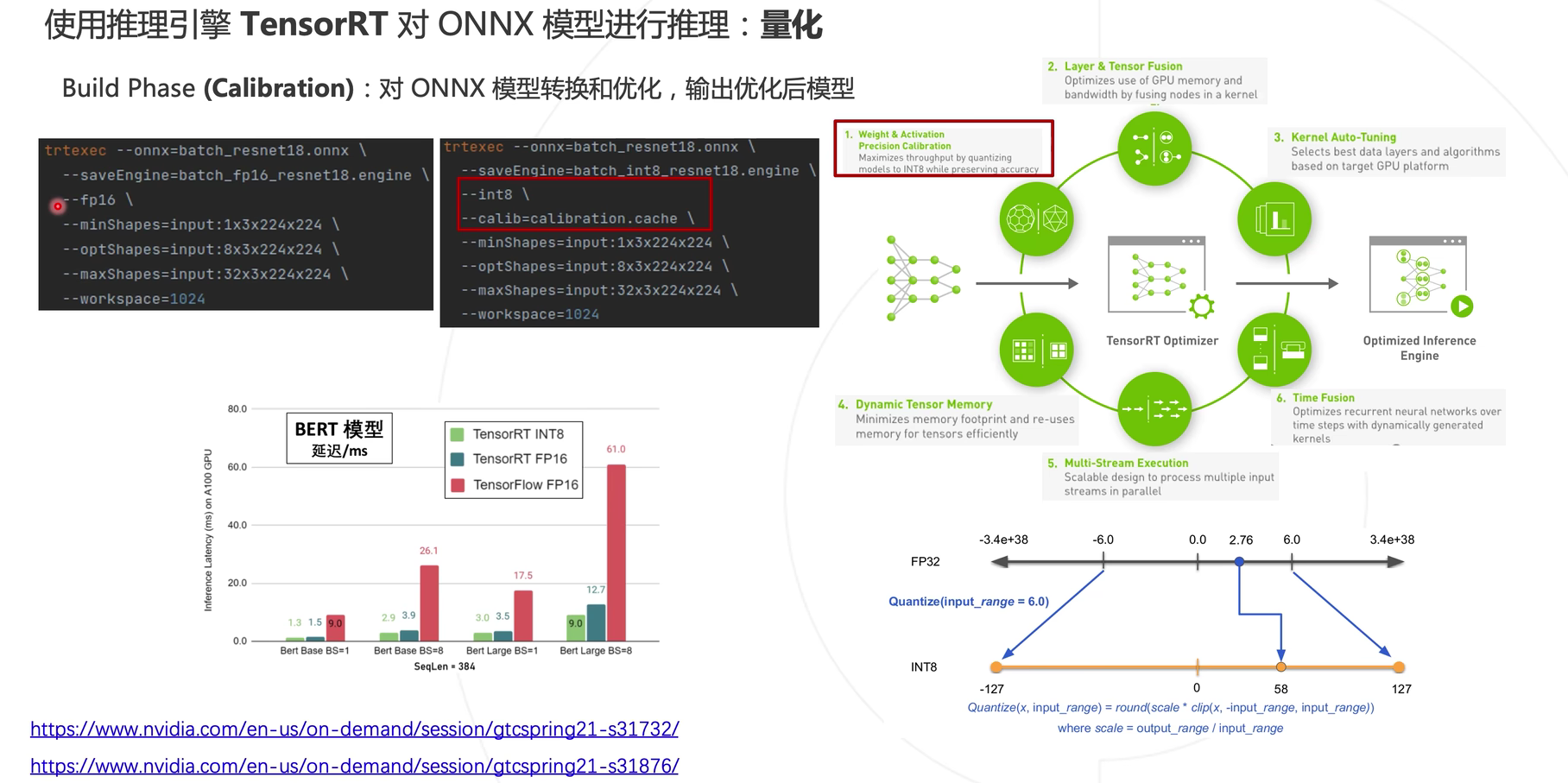
Método cuantitativo
- Cuantización post-entrenamiento: Cuantización post-entrenamiento (PTQ)
- Cuantización durante el entrenamiento: entrenamiento consciente de la cuantificación (QAT)
Si está utilizando QAT, la conversión de precisión del modelo se implementó durante el proceso de capacitación del modelo y puede usar la conversión de estructura de datos onnx. Si está utilizando PTQ, debe realizar la conversión de precisión en la plataforma informática correspondiente.
Cuantización simétrica: Tomando el intervalo de simetría numérica del modelo y correspondiente a INT8 (-127, 127), se puede obtener un coeficiente de cuantificación (entendido simplemente como un coeficiente proporcional, 127/6), correspondiendo así el valor en FP32 a INT8.
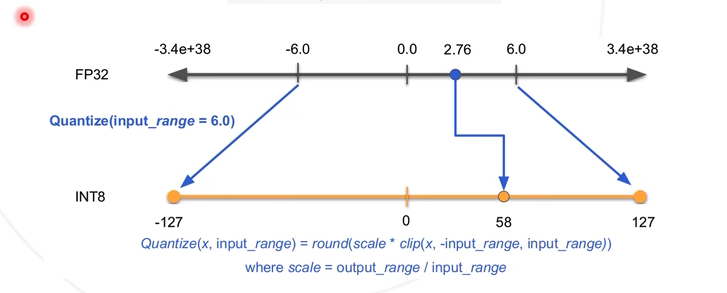
En TensorRT se llamacalibration
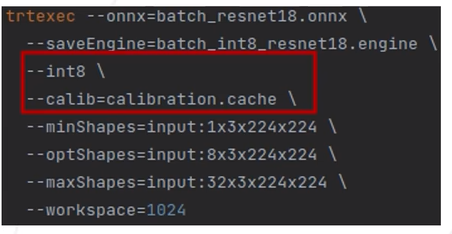
problema comun
