Perfil de la empresa: Mango TV, como plataforma de video por Internet bajo Hunan Radio and Television, bajo la guía estratégica de "una nube, múltiples pantallas, integración múltiple", cultiva la competitividad central a través de contenido propio, desde la transmisión exclusiva y la singularidad hasta la originalidad. y a través de una operación orientada al mercado Completó la ronda A y la ronda B de financiamiento, y realizó con éxito la reestructuración de activos en junio de 2018, convirtiéndose en la primera plataforma de video estatal de acciones A nacionales.
Sugerencias: haga clic en "Leer el texto original" para recibir 5000CU* horas de recursos de la nube Flink de forma gratuita
01
Historial de construcción del almacén de datos en tiempo real de Mango TV
La construcción del almacén de datos en tiempo real de Mango TV se divide en tres fases, la primera fase es de 2014 a 2019. La selección de tecnología adopta Storm/Flink Java+Spark SQL. La primera mitad de 20-22 es la segunda etapa, y la selección de tecnología adopta Flink SQL+Spark SQL. La segunda mitad de 22 ahora es la tercera etapa, y la selección de tecnología adopta Flink SQL+StarRocks. Cada actualización se itera sobre la base original, para tener funciones más completas, mayor velocidad y satisfacer mejor las necesidades del lado comercial. A continuación, los presentaremos uno por uno.
La primera generación se basa en Storm/Flink Java+Spark SQL
El procesamiento de datos en tiempo real de Mango TV comenzó muy temprano. Al principio se utilizó Storm. En 2018, nació Flink. Las ventajas del procesamiento de flujo y estado de Flink son impresionantes, y la popularidad de la comunidad de código abierto y el éxito de los principales fabricantes han hecho que sea imposible rechazarlo, por lo que se utilizó Flink para construir un almacén de datos en tiempo real, pero en ese momento era fue principalmente para satisfacer las necesidades del negocio.El desarrollo de estilo chimenea se llevará a cabo en función de las necesidades de las partes. El proceso básico es conectar los datos ascendentes de Kafka, usar Flink Java para procesar la lógica comercial relevante y luego enviar los datos al almacenamiento de objetos. Luego use Spark SQL para realizar un procesamiento secundario, como estadísticas sobre los datos, y luego entréguelos a los clientes. La ventaja de esta etapa es que aprovecha las fortalezas de Flink para hacer que los datos estén más en tiempo real desde la fuente hasta la terminal, lo que satisface las necesidades comerciales y de puntualidad del lado comercial de los datos. La desventaja es que se realiza una función cuando es necesario, y no hay construcción ni precipitación de un almacén de datos en tiempo real.
La segunda generación se basa en Flink SQL+Spark SQL
Con base en la acumulación técnica y los problemas descubiertos en la etapa anterior, se propone un nuevo plan para construir un almacén de datos en tiempo real. En este momento, la función Flink SQL se ha perfeccionado preliminarmente, lo que puede satisfacer las necesidades de todos los aspectos de la construcción de un almacén de datos.En comparación con Flink Java, SQL también puede reducir los costos de desarrollo, mantenimiento y otros aspectos. Por lo tanto, se eligió Flink SQL para construir un almacén de datos en tiempo real. En esta etapa se lleva a cabo el diseño de la arquitectura en capas del almacén de datos en tiempo real, que se explicará en detalle más adelante. El proceso básico es conectar los datos de Kafka aguas arriba para formatearlos y enviarlos a Kafka, la capa inferior recibe los datos de Kafka para el procesamiento de campos, el filtrado de datos basura y otras operaciones y luego los envía a Kafka, y la última capa recibe los datos de Kafka para la expansión de dimensiones, y luego escribe los datos en el objeto almacenado. Después de que Spark SQL lea los datos en el almacenamiento de objetos para estadísticas y otros procesamientos, se entrega a los clientes para su uso. La ventaja de esta etapa es que se realiza el diseño de arquitectura en capas del almacén de datos, se estandariza la definición de datos de cada capa, se realiza el desacoplamiento de datos de cada capa, se evita el desarrollo estilo chimenea y los problemas de desarrollo repetido se resuelven y el almacén de datos en tiempo real se está moviendo gradualmente hacia la madurez. La desventaja es que no es lo suficientemente flexible como para usar Spark SQL para estadísticas y resúmenes posteriores. Es necesario diseñar indicadores con anticipación, y ante las necesidades cambiantes de los clientes, muchas veces es imposible responder en tiempo y forma.
La tercera generación se basa en Flink SQL+StarRocks
Con la profundización gradual de la construcción de almacenes de datos en tiempo real, Spark SQL no es lo suficientemente flexible y las desventajas de una velocidad de procesamiento insuficiente son cada vez más prominentes. En este momento, StarRocks ha entrado en nuestra mira, su arquitectura MPP, motor de vectorización, combinación de múltiples tablas y otras características muestran ventajas en rendimiento y facilidad de uso, todo lo cual compensa las deficiencias de Spark SQL en esta área. Entonces, después de la investigación, se decidió reemplazar Spark SQL con StarRocks en el almacén de datos en tiempo real. En esta etapa, la estructura jerárquica del almacén de datos en tiempo real creado con Flink SQL no ha cambiado y las funciones posteriores relacionadas con el análisis estadístico con Spark SQL se han reemplazado gradualmente con StarRocks. Con base en las ventajas de StarRocks y los puntos débiles encontrados en la construcción de un almacén de datos en tiempo real, no copiamos el modelo anterior de Spark SQL, sino que elegimos un nuevo modelo. Las consultas ad hoc se implementan mediante StarRocks. Anteriormente, Spark SQL se usaba para recopilar estadísticas y resumir los datos, y luego escribir los datos del resultado final en el almacenamiento de objetos. Pero ahora StarRocks se usa directamente para resumir los datos detallados y mostrarlos en la página principal. La ventaja de hacer esto es que puede satisfacer las necesidades del lado comercial de manera más rápida y flexible, reducir la carga de trabajo de desarrollo y reducir el tiempo de prueba y puesta en línea. El excelente rendimiento de StarRocks evita que se ralentice la velocidad de las consultas ad hoc, y las funciones son más potentes, más flexibles y la velocidad de entrega es más rápida.
02
Introducción a la plataforma de programación de computación en tiempo real Flink de desarrollo propio
puntos de dolor existentes
Los comandos de tareas nativos son complejos, la depuración es problemática y los costos de desarrollo son relativamente altos.
Los conectores, las UDF, los paquetes de tareas Jar, etc. no se pueden administrar, la depuración es complicada y, a menudo, se encuentran conflictos de dependencia.
Es imposible lograr un monitoreo y una gestión de alarmas y autoridades unificados sobre los recursos.
El desarrollo de tareas SQL es complicado y no existe un editor fácil de usar y una plataforma de gestión y almacenamiento de código.
Las tablas básicas, las tablas de dimensiones y el Catálogo no tienen plataforma de registro y visualización.
Las tareas de múltiples versiones y entre nubes no se pueden administrar bien.
Sin un buen mecanismo de gestión de registros, es imposible localizar rápidamente los problemas en el entorno de producción.
Diseño de la arquitectura de la plataforma
Diagrama de la arquitectura de la plataforma de programación de Flink en tiempo real:
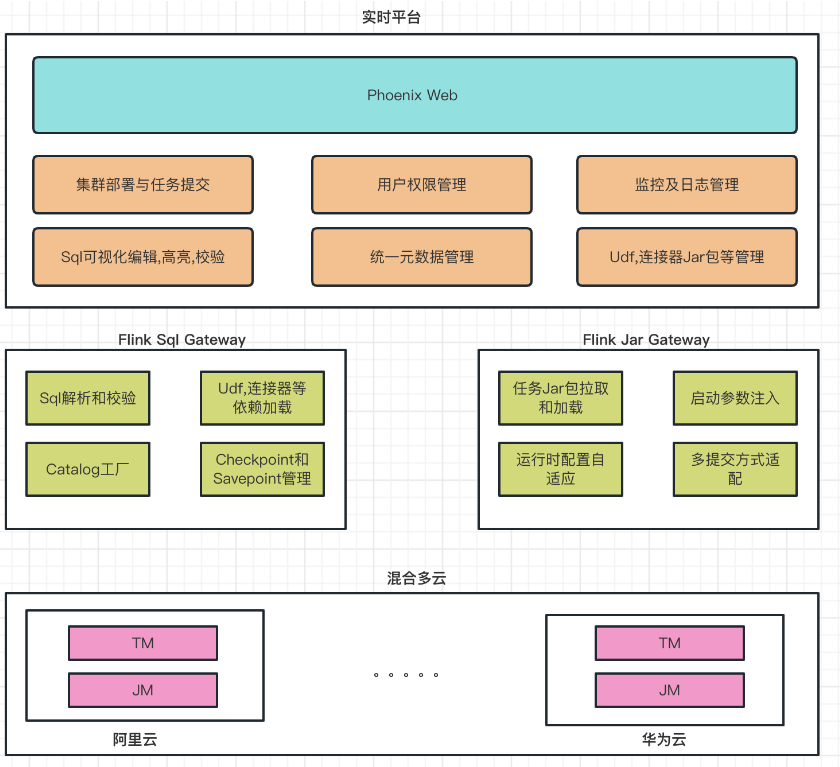
La plataforma se divide principalmente en tres partes:
1. El módulo web de Phoenix es el principal responsable de enfrentar a los usuarios.
Implementación de clústeres y envío de tareas.
Gestión de la autoridad comercial interna de la empresa.
Catálogo de soporte y gestión de información multifuente.
Tres partes, como UDF y el conector, dependen de la administración de paquetes Jar.
Gestión de registros y alarmas de monitoreo de múltiples tipos.
Edición y validación visual de SQL y almacenamiento de múltiples versiones.
2. Tanto Flink SQL Gateway como Flink Jar Gateway son servicios modificados y personalizados basados en la versión de código abierto. Admiten el análisis y la verificación de SQL en línea con los escenarios comerciales y el envío de tareas Jar. Admiten el modo local, Yarn-per-job modo y Modo de aplicación También se admite el punto de guardado automático.
Realice el análisis y la verificación de SQL.
Se requieren dependencias de tres partes para cargar tareas de SQL y Jar.
La tarea SQL se conecta al almacén de catálogo para la asociación y el mapeo.
Gestión y recuperación automática de Checkpoint y Savepoint.
Inyección de parámetros de inicio de tareas tipo Jar.
Configuración de tiempo de ejecución adaptable.
Se adaptan múltiples tipos de métodos de presentación.
3. El módulo multinube híbrido es el principal responsable de la distribución de las tareas de inicio y la gestión de la información entre las nubes.
03
Práctica de capas de almacén de datos en tiempo real de Flink SQL
Al usar Flink SQL para construir un almacén de datos en tiempo real, el primer problema es cómo resolver la arquitectura en capas del almacén de datos. Hay muchas experiencias excelentes en la industria como referencia. Al mismo tiempo, según nuestra situación, finalmente adoptó la siguiente arquitectura de almacenamiento de datos:
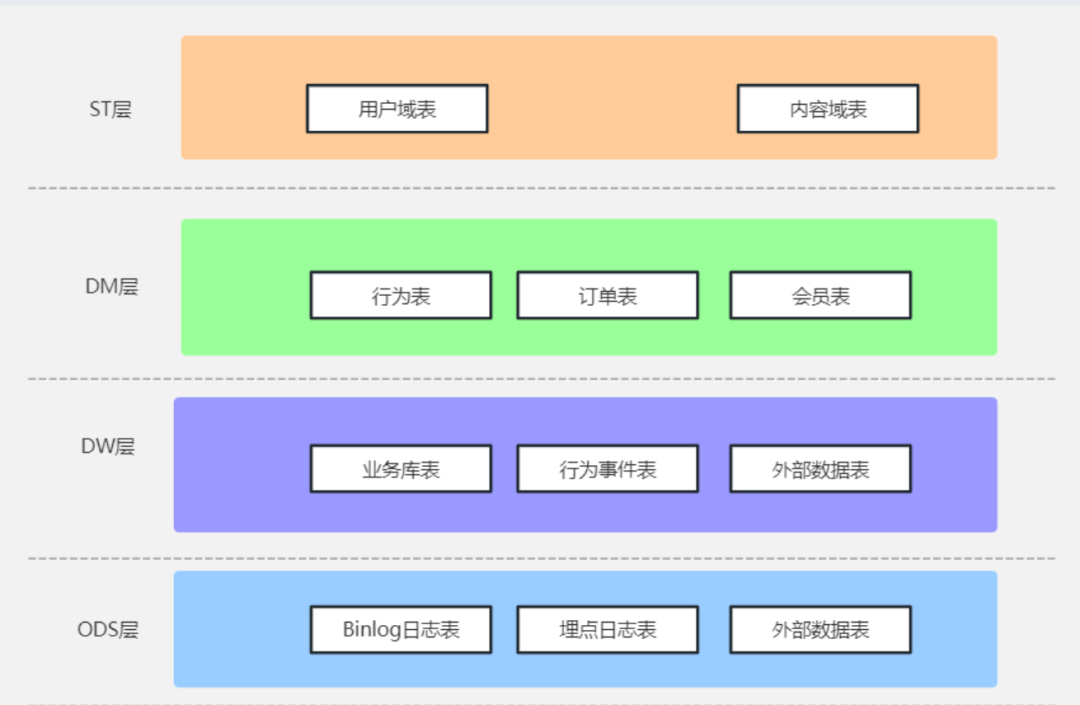
Capa ODS: la capa de registro original. En esta capa, las fuentes de datos, como los registros Binlog ascendentes, los registros de comportamiento del usuario y los datos externos, se sincronizan con el almacén de datos. Los datos de varias fuentes de datos y formatos se analizan y formatean a través de una función UDF unificada. y finalmente salida de datos JSON con formato.
Capa DW: capa de detalles de datos, donde se procesan principalmente el filtrado de datos de error, el escape de campos, los nombres de campos unificados, etc., y los datos de salida pueden cumplir con el uso del análisis básico diario.
Capa DM: la capa del modelo de datos, donde se realiza la expansión de la dimensión para complementar la información pública relevante. Luego se divide en dominios según el negocio y los datos de salida tienen dimensiones más ricas, que pueden cumplir con los requisitos de uso de datos del análisis avanzado.
Capa ST: capa de aplicación de datos, que se resume de acuerdo con el negocio, la función y otras dimensiones, y se entrega a la página de inicio para su visualización. Los datos de salida se pueden entregar a la Web, la aplicación, el subprograma y otras funciones.
04
Problemas encontrados en el proceso de producción del almacén de datos en tiempo real de Flink SQL
Al crear un almacén de datos en tiempo real, me encontré con muchos problemas. Aquí hay algunos problemas típicos para explicar las ideas de solución:
1. Asociación de tablas múltiples, esta es una función muy importante y de uso común cuando se crea un almacén de datos. En la etapa inicial de la construcción de un almacén de datos en tiempo real usando Flink SQL, estábamos realmente confundidos por la deslumbrante variedad de tipos de unión de Flink, especialmente cuando se trata de asociación de tablas múltiples, algunos datos de tablas de dimensiones están en Hive, algunos datos de tablas de dimensiones están en MySQL y algunos datos de tablas de dimensiones están incluso en otro OLAP. Qué tipo de método de asociación elegir fue un gran problema en ese momento tiempo Después de muchos intentos, bajo el equilibrio de rendimiento, funcionalidad y otros aspectos, se resumen las siguientes reglas:
La tabla de flujo se asocia con la tabla de dimensiones (pequeño volumen de datos), utilizando Lookup Join. Cuando el volumen de datos de la tabla de dimensiones es inferior a 100 000, la tabla de Hive se puede usar como tabla de dimensiones, porque la mayoría de los datos de la tabla de dimensiones en el El almacén de datos fuera de línea está en Hive. Se puede reutilizar directamente, ahorrando el trabajo adicional de importación y exportación de datos, y no hay cuellos de botella en el rendimiento. Después de que la tabla de dimensiones se actualiza cada hora, Flink SQL también puede leer los datos más recientes.
La tabla de flujo está asociada con tablas de dimensiones (gran volumen de datos). Se utiliza Lookup Join. Cuando el volumen de datos de la tabla de dimensiones está por debajo de 100.000-10 millones, las tablas de MySQL se pueden usar como tablas de dimensiones. En este momento, las tablas de dimensiones de Hive no pueden cumplir requisitos de desempeño. Los datos se pueden exportar a MySQL y el mecanismo de caché también se puede usar para cumplir con los requisitos.
La tabla de flujo se asocia con la tabla de flujo, usando Interval Join, y el campo de tiempo de las dos tablas de flujo se usa para controlar el rango de asociación.Este método de asociación se usa actualmente con más frecuencia. La forma de uso también está más cerca de estar fuera de línea.
2. Procesamiento de tablas complejas. En algunos escenarios complejos de limpieza de datos, al asociar tablas de dimensiones, los datos de las tablas de dimensiones deben someterse a una o incluso varias capas de procesamiento antes de que puedan utilizarse. En tales escenarios, los almacenes de datos fuera de línea pueden ser directamente Escriba subconsultas de varios niveles durante Join para completarlas en un solo paso. Sin embargo, no se admite en Flink SQL y se rechaza en el mecanismo subyacente. Después de muchos intentos y dificultades, la solución final es preprocesar los datos de la tabla de dimensiones en Hive, y el almacén de datos en tiempo real usa los datos de la tabla de dimensiones preprocesados. Sin embargo, esta es solo una solución transitoria. En la actualidad, hemos aprendido de la comunidad que habrá un nuevo mecanismo en el futuro para realizar la asociación de tablas de dimensiones después de realizar cálculos complejos arbitrarios en las tablas de dimensiones. Debo decir que la actualización de la comunidad Flink sigue siendo muy rápida.
3. El estado es demasiado grande Cuando se asocian dos tablas de flujo o se realizan estadísticas de resumen, el mecanismo de Flink es almacenar en caché los datos en el estado. Esto hace que el estado sea demasiado grande, lo que genera fallas frecuentes en la tarea y el GC. Ante esta situación, tras estudiar el mecanismo de memoria de Flink, la solución es la siguiente:
Acorte el intervalo de tiempo y reduzca adecuadamente el intervalo de tiempo de los dos flujos durante la asociación según las necesidades comerciales.
Ajuste el tamaño de la memoria administrada, puede ajustar la proporción de la memoria administrada y reducir adecuadamente el uso de otra memoria.
Configure el TTL del estado para evitar almacenar en caché demasiados datos.
4. El punto de control caducó antes de completarse, con frecuencia aparecen excepciones en las tareas. En el entorno de producción real, se encuentra que algunas tareas informan con frecuencia de este error. Este error significa que el punto de control no se puede completar con éxito, porque el punto de control de Flink tiene un mecanismo de barrera para garantizar que los datos son exactos ExactlyOnce. Consistencia, si un lote de datos no se puede procesar, Checkpoint no se puede completar. Los interesados pueden ir a averiguar. Hay muchas razones para este error, y diferentes problemas tienen diferentes respuestas.A continuación, los escenarios y soluciones se enumeran a continuación:
El período de tiempo de espera del punto de control es demasiado corto. Esta es una situación relativamente común y fácil de resolver. La razón es que el período de tiempo de espera de Checkpoint es demasiado corto, lo que hace que se informe antes de que se complete el Checkpoint. La solución es configurarlo más. Generalmente lo configuramos entre 6 segundos y 2 minutos según el tipo de tarea.
Las tareas tienen contrapresión, que también es muy común. Hay múltiples operaciones en una tarea, y una de las operaciones tarda mucho tiempo en afectar la ejecución de toda la tarea. También afectará a la finalización de Checkpoint, lo que implica que, si te interesa, puedes consultarlo. La solución es encontrar la tarea de ejecución lenta de WebUi, analizar el problema específico en detalle y resolverlo.
Memoria insuficiente, permítanme hablar sobre el fondo primero, generalmente usamos rocksdb statebackend en el entorno de producción, y el punto de control completo se reservará de manera predeterminada. En este caso, cuando se encuentren tareas que utilicen el statebackend del montón, como las estadísticas de asociación y grupo, los resultados intermedios del cálculo se almacenarán en caché en State, y la memoria de State será por defecto el 40 % de la memoria total. No será suficiente, lo que conduce a GC frecuentes y también afecta la ejecución de Checkpoint. La solución es la siguiente:
Aumente la memoria de TaskManager.Después de aumentar la memoria de TaskManager, otras áreas de memoria aumentarán en consecuencia.
Para aumentar la proporción de memoria de la memoria administrada, se debe establecer el parámetro taskmanager.memory.managed.fraction, que se puede ajustar hasta un 90 % en la producción real de acuerdo con la situación real. Este método solo aumenta ManagedMemory una pieza, si los recursos de memoria no son muy abundantes, puede usar este método.
Utilice el punto de control incremental en su lugar, ajuste el tiempo TTL del estado de acuerdo con la situación real y habilite el punto de control incremental. Incluso sin ajustar el tamaño de la memoria, el problema se puede resolver.
5. Al usar la función if en Flink SQL, un descubrimiento accidental, al devolver String, devolverá de acuerdo con la longitud máxima. ¿Qué significa? Por ejemplo, si (condición, cadenaA, cadenaB), la longitud de cadenaA es 10 y la longitud de cadenaB es 2. Si condición = falso, cuando se devuelve cadenaB, la longitud de cadenaB se completará a 10, y se darán espacios si no es suficiente. Esto es algo a tener en cuenta. Pero luego supe que este fenómeno se solucionó en la versión 1.16.3, y estamos usando 1.15, por lo que si lo encuentra, puede reemplazarlo con CaseWhen o actualizar la versión de Flink a 1.16.3 y superior para resolverlo.
05
Antecedentes y problemas de selección de StarRocks
En el marco anterior, usamos el motor de procesamiento de flujo Flink para completar la limpieza del registro original, la ampliación de datos y la agregación ligera, y luego aterrizamos en el sistema de archivos distribuido o el almacenamiento de objetos, y programamos lotes en el nivel de cinco minutos hasta fuera de línea. Spark SQL.Después del procesamiento, los resultados serán consultados a través de motores como Presto.Este tipo de arquitectura revela gradualmente muchos problemas en el entorno de producción.
Por ejemplo:
Hay un problema de cálculos repetidos. Los datos originales se limpiarán repetidamente en diferentes tareas, y algunas asociaciones que requieren múltiples datos originales también se limpiarán repetidamente. Esto desperdicia muchos recursos informáticos y la reutilización del código y el flujo de datos es pobre.
Para satisfacer el valor acumulado histórico del procesamiento por lotes fuera de línea y el índice de cálculo de la ventana actual de 5 minutos, es muy probable que el cálculo del índice no se pueda completar dentro de los 5 minutos durante el período de tráfico pico y cuando el índice de el día se acumula hasta la noche.Existe un gran riesgo de tiempo de espera, y la empresa retroalimentará la latencia para las métricas en tiempo real.
Debido al hecho de que el procesamiento por lotes de Spark fuera de línea es un poco débil en el caso del análisis combinado multidimensional y se requiere rendimiento en tiempo real. El negocio en línea ha generado muchos escenarios en tiempo real. Por otro lado, el refinamiento de las operaciones y la civilización del análisis también han generado requisitos de análisis multidimensional. Estos escenarios requieren datos subyacentes extremadamente detallados y ricos en dimensiones. Estos dos partes La superposición de estos resultados dio origen a una escena de análisis multidimensional en tiempo real. En este momento, necesitamos aumentar continuamente las combinaciones de dimensiones, aumentar los campos de resultados y aumentar los recursos informáticos para cumplir con los escenarios anteriores, pero aún es un poco débil.
Hoy en día, la puntualidad de los datos aumenta día a día. En muchos escenarios, la puntualidad de los datos requiere segundos y milisegundos. El método anterior de 5 minutos no puede satisfacer las necesidades comerciales.
En las tareas en tiempo real anteriores, a menudo es necesario unir flujos y flujos en la memoria de Flink. Todo esto debe hacerse en la memoria de tareas de Flink. Debido a que el tiempo de llegada de datos de múltiples flujos de datos ascendentes es inconsistente, es difícil para diseñar una ventana adecuada para la computación Datos amplios en el motor, cuando se usa Flink Interval Join, el intervalo de tiempo entre múltiples flujos es demasiado largo, los datos de estado serán muy grandes y el cálculo de estado como mapState está habilitado, que es demasiado personalizado.
Para la limpieza de Flink o los resultados de cálculo, es posible que se requieran varios medios de almacenamiento. Para obtener datos detallados, podemos almacenarlos en un sistema de archivos distribuido o en un almacenamiento de objetos. En este momento, es Flink+HDFS. Para los datos de flujo de actualización comercial, puede ser Flink CDC+hbase (cassandra u otras bases de datos de valores clave), Flink+MySQL(redis) se puede usar para generar datos de flujo de retroceso para Flink, Flink+elasticsearch se puede usar para datos de control de riesgos o visualización de versiones detalladas tradicionales, y indicadores de datos de registro a gran escala El análisis puede ser Flink+clickhouse, que es difícil de unificar, se consumen muchos recursos y los costos de mantenimiento también son altos.
Cuando hay actividades a gran escala o programas a gran escala en línea, la cantidad de datos en tiempo real aumenta drásticamente. En el caso de la escritura masiva en tiempo real, el retraso de escritura es grande, la eficiencia de escritura no es alta y los datos atrasos
Análisis general, la arquitectura temprana tiene algunos problemas.
Las fuentes de datos son diversas y el costo de mantenimiento es relativamente alto.
Rendimiento insuficiente, gran retraso de escritura, acumulación de datos en escenarios de grandes promociones y mala experiencia de consulta interactiva.
Cada fuente de datos está fragmentada y no se puede correlacionar ni consultar, lo que forma muchas islas de datos. Luego, desde la perspectiva del desarrollo, cada motor debe invertir en los costos correspondientes de aprendizaje y desarrollo, y la complejidad del programa es relativamente alta.
Altos requisitos en tiempo real, rápida eficiencia de desarrollo y fuerte reutilización de código o datos.
El desarrollo de tareas en tiempo real no tiene el mismo conjunto de estándares y cada uno funciona de forma independiente.
Para ello, realizamos una sencilla comparación de rendimiento en el entorno de prueba, los detalles son los siguientes:
Entorno de comparación StarRocks: 4 *16C*128G Presto: 22*32C*256G (no exclusivo)
Volumen de datos: tabla de eventos (10 mil millones de datos en total, 10 millones de reutilizaciones por día)
caso de prueba |
pronto |
Rocas estelares |
Prueba de agregación de tabla única |
13.1 |
5 |
prueba de asociación |
19 |
8 |
retener |
24 |
15 |
función de ventana |
dieciséis |
8 |
embudo |
3.5 |
3.2 |
Asociación de varias tablas |
36 |
19 |
Esta prueba utiliza 4 servidores BE con memoria 16C128G, y la conclusión de la prueba básicamente puede cumplir con los requisitos de consulta de decenas de miles de millones de datos. Los resultados de las pruebas muestran que el rendimiento de StarRocks es significativamente mejor que el de Presto en el caso de una gran diferencia en los recursos, y la eficiencia promedio aumenta de 2 a 3 veces.
06
Análisis en tiempo real del almacén de datos basado en Flink SQL+StarRocks
Basado en el sistema de capas de almacenamiento de datos Flink SQL que se ha creado, se ha actualizado de la versión StarRocks2.5X a la versión de separación de almacenamiento e informática StarRocks3.0X y se ha puesto en un entorno de producción a gran escala.
El diagrama de arquitectura de la integración de almacenes de lagos en tiempo real y fuera de línea:
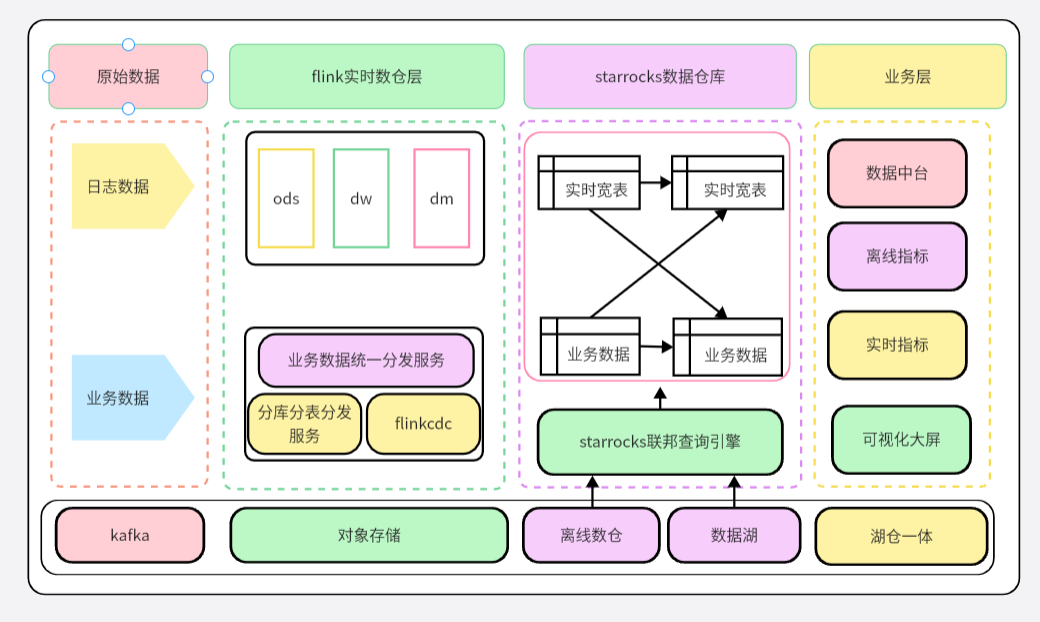
modelo detallado
Los datos de registro más comunes en el entorno de producción de big data se caracterizan por una gran cantidad de datos, cálculos complejos y flexibles multidimensionales, muchos indicadores de cálculo, rendimiento sólido en tiempo real, consulta de alto rendimiento en el segundo nivel, simple y estable escritura de secuencias en tiempo real y combinación de tablas grandes, deduplicación de alta cardinalidad.
Estos elementos se pueden satisfacer para Flink SQL+StarRocks. Primero, use Flink SQL en la plataforma en tiempo real para limpiar y ampliar rápidamente los datos de registro de transmisión en tiempo real. Al mismo tiempo, StarRocks proporciona el conector de salida Flink-Connector-StarRocks. de la caja, y admite ExactlyOnce y soporte de transacciones, baja latencia e importación rápida a través de Stream Load.
Por ejemplo:
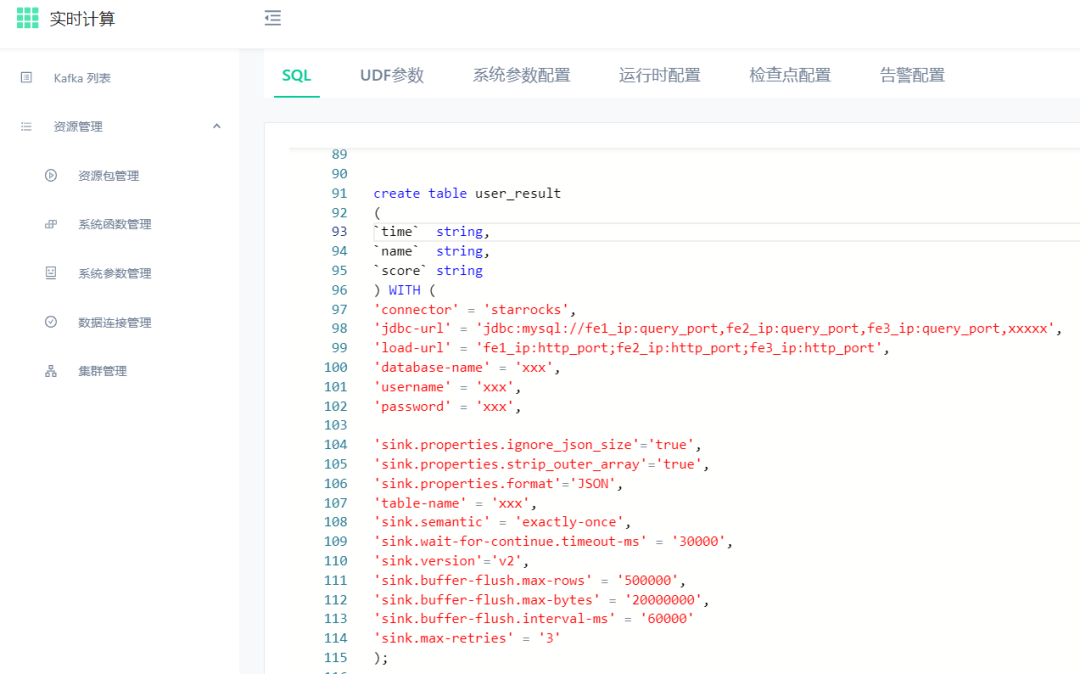
A través del eficiente y simple modo de creación de tablas Flink SQL, se escriben lotes de millones de datos y la velocidad es rápida. Al mismo tiempo, la cantidad de accesos de usuarios multidimensionales para una sola tabla en el entorno de producción con más de una mil millones de datos, y los datos de deduplicación del usuario pueden alcanzar el segundo nivel.
modelo de clave primaria
En los almacenes de datos OLAP, los datos variables generalmente están mal vistos.
Para el método de cambio de datos en el almacén de datos:
Método 1: algunos almacenes de datos OLAP proporcionan la función de actualización del modelo Merge on Read para completar los cambios de datos, como (clickhouse).
Método 2: en pocas palabras, es crear una nueva tabla de particiones, eliminar los datos en la tabla de particiones anterior y luego actualizarla en lotes.
Inserte los datos modificados en la nueva partición y complete el cambio de datos a través del intercambio de partición.
Al actualizar por lotes, la tabla se reconstruirá, los datos de partición se eliminarán y el proceso de actualización de datos es complicado y puede provocar errores.
El modo Merge on Read es simple y eficiente cuando se escribe, pero consume muchos recursos para la fusión de versiones cuando se lee Al mismo tiempo, debido a la existencia del operador merge, el predicado no se puede empujar hacia abajo y el índice no se puede utilizado, lo que afecta seriamente el rendimiento de la consulta. StarRocks proporciona un modelo de clave principal basado en el modo Eliminar e Insertar, lo que evita el problema de que los operadores no se pueden empujar hacia abajo debido a la fusión de versiones. El modelo de clave principal es adecuado para escenarios en los que es necesario actualizar los datos en tiempo real. Puede resolver mejor las operaciones de actualización de nivel de fila y admitir TPS de un millón de niveles. Es especialmente adecuado para escenarios en los que MySQL u otras bibliotecas comerciales están sincronizadas con StarRocks. .
Además, la combinación perfecta de Flink CDC y StarRocks puede realizar una sincronización en tiempo real completa e incremental de extremo a extremo desde la base de datos empresarial hasta el almacén de datos OLAP. Una tarea puede resolver todos los problemas por lotes y en tiempo real con alta eficiencia y estabilidad. . Al mismo tiempo, el modelo de clave principal también puede resolver el problema de la salida del flujo de retroceso en Flink, admite la actualización por condición y admite la actualización por columna.Estas son muchas ventajas que las bases de datos OLAP tradicionales no tienen al mismo tiempo.
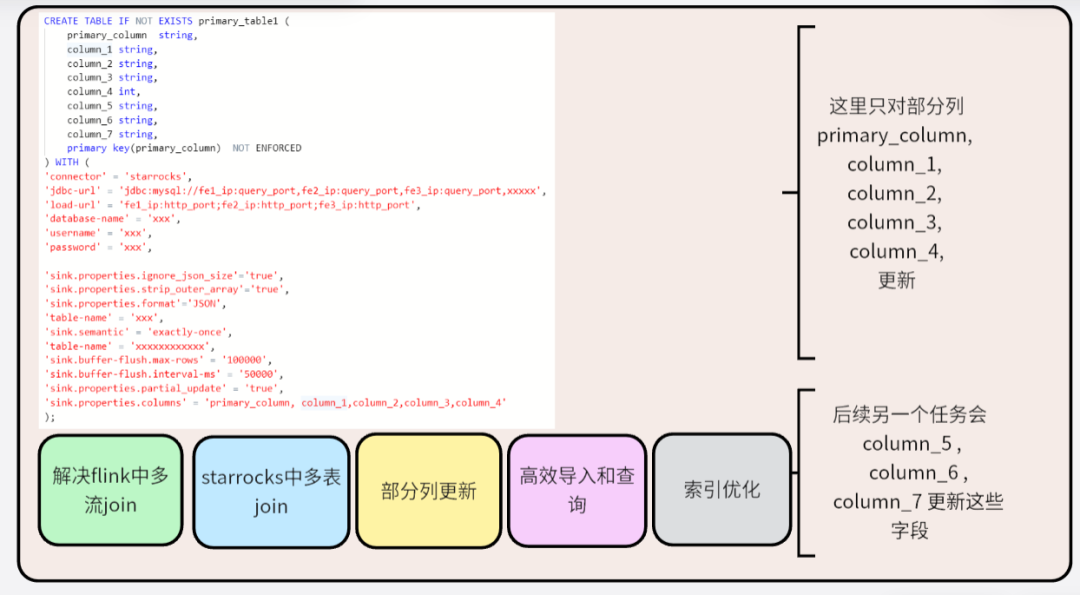
El modelo Flink CDC+StarRocks puede resolver muchos problemas en el entorno de producción. La solución conjunta de StarRocks y Flink para construir un sistema de análisis de datos en tiempo real subvertirá algunas restricciones existentes hasta cierto punto, formando un nuevo paradigma de datos en tiempo real. análisis y acelerar la integración Los datos de registro en tiempo real y los datos comerciales también pueden resolver el problema de la extracción por lotes de datos tradicionales fuera de línea, realizar la unificación de datos fuera de línea y en tiempo real, y acelerar el proceso de integración de flujo por lotes.
modelo de agregación
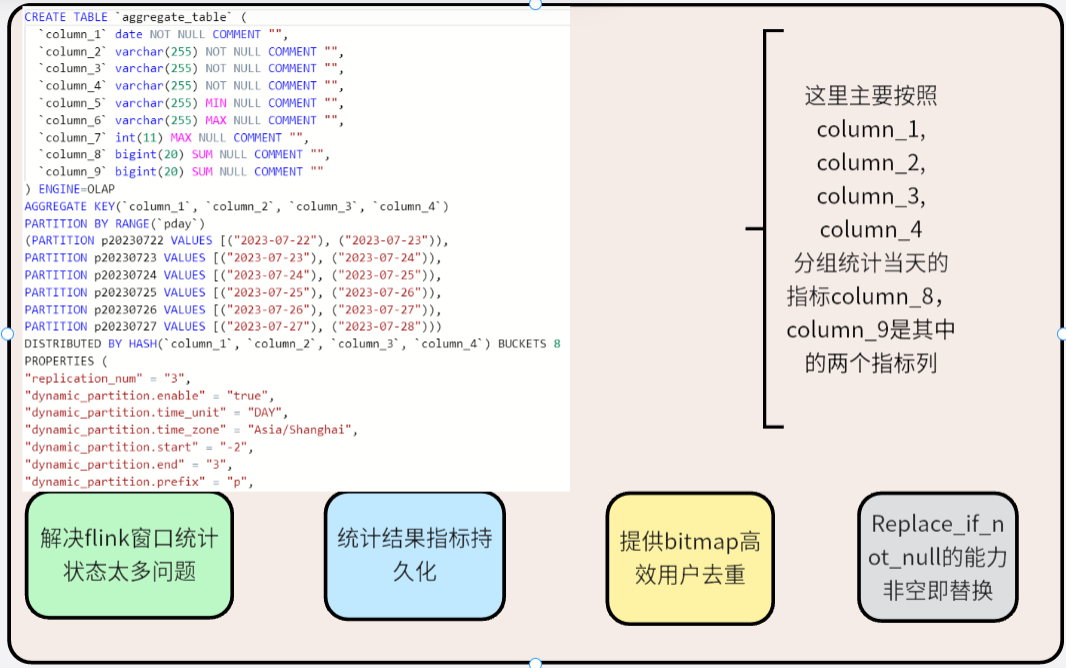
Hay otro escenario en el almacén de datos en tiempo real. No nos importan mucho los datos detallados originales. La mayoría de ellos son consultas resumidas, como SUM, MAX, MIN y otros tipos de consultas. Los datos antiguos no se actualizan. con frecuencia, y solo se agregarán datos nuevos. Cuando puede considerar usar el modelo de agregación. Al crear una tabla, admite la definición de claves de ordenación y columnas de índice, y la especificación de funciones de agregación para columnas de índice. Cuando varios datos tienen la misma clave de ordenación, la columna de índice se agregará. Al analizar estadísticas y resumir datos, el modelo de agregación puede reducir los datos que deben procesarse durante la consulta y mejorar la eficiencia de la consulta.
En el pasado, es posible que coloquemos estas operaciones en Flink para las estadísticas. Los datos de estado existirán en la memoria, lo que hará que los datos de estado sigan creciendo y consumiendo muchos recursos. Cambie las estadísticas simples de Flink al modelo de agregación Flink SQL+StarRocks. , Flink Aquí solo necesita limpiar los datos detallados e importarlos a StarRocks, que es muy eficiente y estable.
En la producción real, lo usamos principalmente para contar el tiempo de visualización del usuario, los clics, las estadísticas de pedidos, etc.
vista materializada
Las aplicaciones en un entorno de almacenamiento de datos a menudo realizan consultas complejas en muchas tablas grandes, lo que a menudo implica la asociación y agregación de miles de millones de filas de datos en varias tablas. Para realizar este método de asociación de tablas múltiples en tiempo real y resultados de consultas, podemos colocar este contenido en el almacén de datos en tiempo real de Flink para procesamiento, procesamiento en capas de asociación, fusión, estadísticas y otras tareas, y finalmente generar la capa de resultados. datos, el procesamiento de tales consultas generalmente consume una gran cantidad de recursos y tiempo del sistema, lo que resulta en costos de consulta extremadamente altos.
Ahora puede considerar usar la nueva idea de Flink SQL+StarRocks para lidiar con este problema informático jerárquico a gran escala, de modo que Flink SQL solo necesita manejar algunas tareas de limpieza simples aquí y empujar hacia abajo una gran cantidad de lógica de cálculo repetida a StarRocks para su ejecución. La transmisión en tiempo real aterriza en tiempo real, y el método de modelado de la vista materializada de varios niveles se puede establecer en StarRocks. La vista materializada de StarRocks no solo admite la asociación entre tablas internas y tablas internas, sino también admite la asociación entre tablas internas y tablas externas. Por ejemplo, sus datos están en MySQL, Hudi, Hive, etc. se pueden acelerar a través de la vista materializada de StarRocks y establecer reglas de actualización periódicas para evitar la programación manual de tareas relacionadas. Una de las características más importantes es la vista materializada que hemos establecido. Cuando hay una nueva consulta para consultar la tabla base que ha creado la vista materializada, el sistema juzga automáticamente si los resultados precalculados en la vista materializada se pueden reutilizar para procesar la consulta. Si se puede reutilizar, el sistema leerá directamente los resultados precalculados de las vistas materializadas relevantes para evitar cálculos repetidos que consumen tiempo y recursos del sistema. Cuanto mayor sea la frecuencia de consulta o más compleja sea la declaración de consulta, más evidente será la mejora del rendimiento.
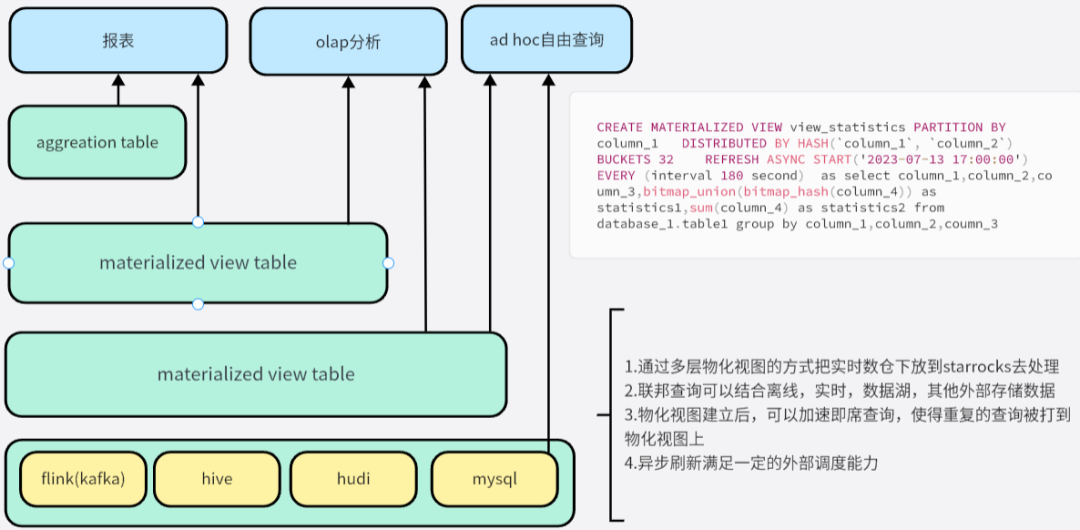
El tiempo real es el futuro, y StarRocks se está dando cuenta gradualmente de esta capacidad. La solución conjunta de StarRocks y Flink para construir un sistema de análisis de datos en tiempo real subvertirá algunas restricciones existentes hasta cierto punto y formará un nuevo paradigma de datos en tiempo real. análisis.
07
perspectiva del futuro
Lago y almacén integrados
En la actualidad, Mango TV ha realizado la construcción de un almacén de datos que integra flujos y lotes, y el enfoque futuro estará en la construcción de un almacén de lago integrado.
Un lago de datos se caracteriza por la capacidad de almacenar datos sin procesar de varios tipos y formatos, incluidos datos estructurados, datos semiestructurados y datos no estructurados. Un almacén de datos se trata de estructurar y organizar datos para satisfacer necesidades comerciales específicas.
La integración de lago y almacén integra las características del almacén de datos y el lago de datos para crear un centro de datos unificado y realizar una gestión centralizada de datos. La arquitectura integrada de lago y almacén puede proporcionar una mejor seguridad, rentabilidad y apertura. No solo puede almacenar y administrar una gran cantidad de datos sin procesar, sino también organizar los datos en una forma estructurada para facilitar el análisis y la consulta.
A través de la integración del lago y el almacén, Mango TV puede proporcionar servicios de datos más completos a la empresa, respaldar la toma de decisiones comerciales y la innovación, y realizar un control y una gestión integrales de los datos, incluida la recopilación, el almacenamiento, el procesamiento y el análisis de datos. Al mismo tiempo, la integración de Lake y Warehouse también puede admitir el uso de múltiples motores y herramientas informáticas, como Flink, Spark, Hive, etc., lo que hace que el procesamiento y el análisis de datos sean más flexibles y eficientes.
código bajo
El método de desarrollo actual es escribir tareas de envío de SQL en la plataforma de desarrollo propio. Cuando se enfrenta a algunos escenarios de limpieza, la mayor parte de este método es un trabajo repetitivo y hay mucho margen de mejora. El código bajo es un concepto popular hoy en día y tiene grandes ventajas en la reducción de costos y el aumento de la eficiencia. Nuestro próximo plan es realizar gradualmente código bajo. La primera etapa es conectar la plataforma en tiempo real con la plataforma de informes de datos. Al leer los metadatos relevantes en la plataforma de informes, podemos generar automáticamente las tareas de limpieza de datos correspondientes, liberar productividad, y mejorar el trabajo Eficiencia y rapidez en la entrega.
La ventaja del código bajo es que puede automatizar y simplificar el trabajo repetitivo en el proceso de desarrollo, reduciendo la carga de trabajo de codificación de los desarrolladores. Visualmente, los desarrolladores pueden arrastrar y configurar para completar tareas sin escribir mucho código. Esto no solo mejora la eficiencia del desarrollo, sino que también reduce el riesgo de errores.
Al implementar un enfoque de desarrollo de código bajo, Mango TV podrá acelerar el procesamiento y análisis de datos y mejorar la eficiencia general del equipo. Además, el código bajo también puede reducir los requisitos técnicos para los desarrolladores, lo que permite que más personas participen en el procesamiento y análisis de datos.
En resumen, con base en las características de la tecnología Flink, Mango TV se enfocará en realizar la arquitectura integrada del lago y el almacén en la futura construcción del almacén de datos, para lograr la gestión y utilización integral de los datos. Al mismo tiempo, Mango TV planea implementar gradualmente métodos de desarrollo de código bajo para mejorar la eficiencia del desarrollo y la velocidad de entrega. Estas iniciativas promoverán aún más el desarrollo de Mango TV en el campo del análisis de datos de video largo y brindarán un mayor apoyo para la toma de decisiones comerciales y la innovación.
▼ " Envío de cuenta pública de Apache Flink ", invitamos a todos a participar en el largo plazo ▼

Destacados anteriores





▼ " Revisión del evento " Escanee la imagen a continuación para ver la repetición de la transmisión en vivo ▼

▼ Siga " Apache Flink " para obtener productos secos más técnicos ▼

 Haga clic en " Leer el texto original " para recibir 5000CU* horas de recursos en la nube de Flink de forma gratuita
Haga clic en " Leer el texto original " para recibir 5000CU* horas de recursos en la nube de Flink de forma gratuita