escrito en frente
Con la unificación continua de la pila de tecnología interna de Didi, la integración continua de recursos de componentes técnicos relacionados en tiempo real y la precipitación continua de experiencia de desarrollo relacionada con datos en tiempo real en varias líneas de negocios, un conjunto de selección y gestión de tecnología óptima para el Se ha formado básicamente un plan de implementación específico para los diferentes escenarios comerciales de la compañía. Pero al mismo tiempo, también descubrimos que la mayoría de los estudiantes de desarrollo en tiempo real generalmente equiparan la construcción de datos en tiempo real con el desarrollo de datos flink en el proceso de construcción de datos en tiempo real y, a menudo, colocan otros componentes relacionados en el procesamiento de datos en tiempo real. proceso en el borde, que no se puede implementar de manera eficiente.Integre componentes de procesamiento de datos para cumplir con los requisitos en tiempo real de diferentes escenarios comerciales. Con este fin, a partir de las soluciones de desarrollo de datos en tiempo real típicas actuales en la empresa, clasificamos la selección de tecnologías de construcción de datos en tiempo real en diferentes escenarios para ayudar a todos a llevar a cabo mejor la construcción de datos en tiempo real y producir continuamente datos de alta calidad. datos de calidad y estables en tiempo real para el valor comercial.
Este artículo se divide en:
1. Principales escenarios comerciales de desarrollo de datos en tiempo real en la empresa
2. Soluciones comunes para el desarrollo de datos en tiempo real en la empresa
fuente de datos
canal de datos
centro de sincronización
plataforma de desarrollo en tiempo real
conjunto de datos
aplicación de datos en tiempo real
3. Selección de componentes de desarrollo de datos en tiempo real en escenarios específicos
Escenario de monitoreo de indicadores en tiempo real
Escenario de análisis de BI en tiempo real
Escenario de servicio en línea de datos en tiempo real
Sistema de características y etiquetas en tiempo real
4. Principios para el uso de los recursos de cada componente
5. Resumen y perspectiva
1. Principales escenarios comerciales de desarrollo de datos en tiempo real en la empresa
En la actualidad, los principales escenarios de uso de datos en tiempo real en diversas líneas de negocio de la empresa se dividen en cuatro partes:
Monitoreo de indicadores en tiempo real: por ejemplo, monitoreo de estabilidad de indicadores en el lado de producción e investigación, monitoreo de fluctuaciones anormales en indicadores en tiempo real en el lado comercial y monitoreo de salud comercial en el mercado operativo, etc. La característica principal de este tipo de escenario es que tiene altos requisitos de oportunidad de los datos y depende en gran medida de las series temporales, apoyándose principalmente en el eje temporal como medida de análisis, y la complejidad del análisis de datos es media.
Análisis de BI en tiempo real: principalmente para analistas de datos y estudiantes de operaciones para configurar Kanban en tiempo real o informes en tiempo real, incluido el tablero de operaciones de la empresa, Kanban central en tiempo real, pantallas grandes en tiempo real en la sala de exposiciones, etc. La característica principal de este tipo de escenario es que requiere una precisión de datos extremadamente alta, hay un cierto retraso en la puntualidad de los datos y necesita admitir capacidades de análisis de datos más complejas.
Servicio en línea de datos en tiempo real: proporciona principalmente indicadores en tiempo real en forma de interfaz API, y se utiliza principalmente para proporcionar datos en tiempo real para productos de datos. Este tipo de escenario tiene altos requisitos de puntualidad y precisión de los datos, complejidad de cálculo de índice promedio y requisitos muy altos para consultas de interfaz QPS. Al proporcionar datos en tiempo real, es necesario garantizar la alta disponibilidad de todo el servicio.
Funciones en tiempo real: se utilizan principalmente para actualizaciones de modelos de aprendizaje automático, predicciones de recomendación, estrategias de recomendación, sistemas de etiquetado, etc. Este tipo de escenario tiene requisitos generales para la puntualidad de los datos, la precisión y el QPS de consulta, pero su propia lógica de implementación tiene requisitos más altos para el uso de motores de computación en tiempo real, que requieren que los motores de computación en tiempo real tengan un sólido procesamiento de datos en tiempo real. Capacidades y capacidades de almacenamiento de estado fuerte. , Capacidades de acoplamiento de componentes externos más ricas.
2. Soluciones comunes para el desarrollo de datos en tiempo real en la empresa
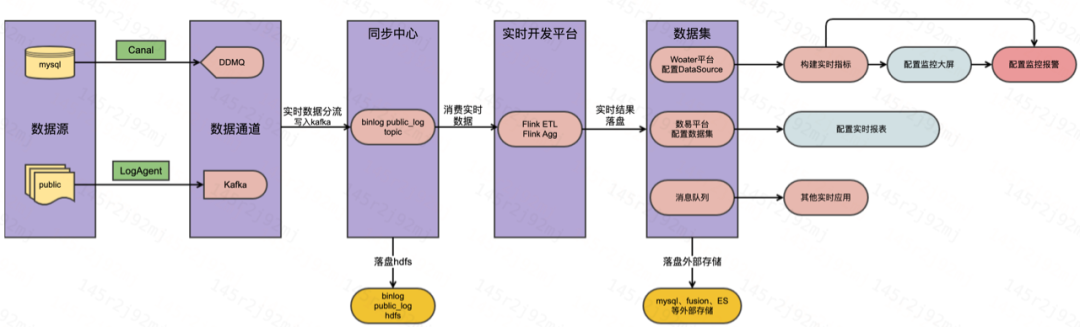
Los componentes generales del programa para el desarrollo de datos en tiempo real en la empresa incluyen principalmente seis partes: adquisición de datos en tiempo real, canal de datos, sincronización de datos, cálculo de datos en tiempo real, almacenamiento de conjuntos de datos en tiempo real y aplicación de datos en tiempo real. Actualmente, los componentes utilizados en estas seis partes son básicamente estables y se pueden utilizar de forma flexible en la plataforma correspondiente.
fuente de datos
En la actualidad, las principales fuentes de datos en tiempo real de la empresa son registros binlog generados por MySQL y registros puliclog generados en servidores empresariales. Los registros binlog de MySQL se completan a través de la herramienta de recopilación de código abierto de Ali, Canal. El principio de funcionamiento de Canal es disfrazarse de MySQL. esclavo y simular MySQL El protocolo de interacción del esclavo envía el protocolo de volcado al maestro MySQL, y el maestro MySQL recibe la solicitud de volcado enviada por Canal, y comienza a enviar el registro binario a Canal, y Canal analiza el registro binario y finalmente envía el resultado a DDMQ; el registro público es el registro comercial definido por la especificación de la empresa , al implementar LogAgent en el servidor comercial, el administrador de agentes procesará y generará la configuración de la colección. Después de que el agente acceda al administrador de agentes para extraer el configuración de la colección, la tarea de colección comenzará a ejecutarse y, finalmente, el registro se enviará a Kafka .
canal de datos
Los principales canales de mensajes de la empresa son DDMQ y Kafka. Todos los registros binlog provienen de DDMQ. DDMQ es un producto de código abierto de Didi a finales de 2018. Utiliza RocketMQ y Kafka como motor de almacenamiento de bajo nivel para mensajes. La característica principal es para admitir mensajes de retraso y transacciones. Al mismo tiempo, también admite funciones complejas de reenvío y filtrado de mensajes; el registro público utiliza principalmente Kafka como canal de mensajes, y el desarrollo del enlace intermedio de tareas en tiempo real también utiliza principalmente Kafka como el medio de almacenamiento Sus características principales son la alta escalabilidad y la perfección ecológica, y se desarrolla en cooperación con Flink La eficiencia es extremadamente alta, y la operación y el mantenimiento de los componentes es muy conveniente.
centro de sincronización
La función principal es separar los datos recopilados de la fuente en datos fuera de línea y en tiempo real de acuerdo con las necesidades comerciales. La función de sincronización de enlace de datos desarrollada sobre la base de DataX para los datos requeridos por la plataforma para escenarios fuera de línea completa la sincronización de datos de extremo a extremo y pone los resultados en hdfs. Para los datos requeridos en escenarios en tiempo real, use la tarea Dsink con un motor de computación en tiempo real incorporado para completar la configuración de recopilación de datos y enviar los resultados a la cola de mensajes de kafka.Al mismo tiempo, los datos se colocarán en hdfs para crear tablas de probabilidades incrementales o completas fuera de línea.
plataforma de desarrollo en tiempo real
En la actualidad, el desarrollo de tareas en tiempo real en la empresa se ha integrado completamente en la plataforma de desarrollo en tiempo real de Shumeng (plataforma de desarrollo de datos integral), que admite dos modos de flink jar y flink sql. la tarea jar en la tarea en tiempo real que se ejecuta en la plataforma En el desarrollo diario de tareas en tiempo real, se recomienda utilizar la sintaxis SQL de Flink 1.12 para completar el desarrollo de tareas en tiempo real.Por un lado, puede garantizar la consistencia de los indicadores y, por otro lado, puede también mejorar la mantenibilidad de las tareas en tiempo real. Durante el proceso de desarrollo de tareas, se recomienda a los usuarios introducir y utilizar la función de depuración local para evitar errores en el proceso de desarrollo de tareas en tiempo real tanto como sea posible y mejorar la tasa de éxito del lanzamiento de tareas en tiempo real. Por lo general, el trabajo principal que completamos en la plataforma de desarrollo en tiempo real es el cálculo de las operaciones ETL o los indicadores de resumen de luz , y luego escribimos los resultados del procesamiento en el receptor aguas abajo.
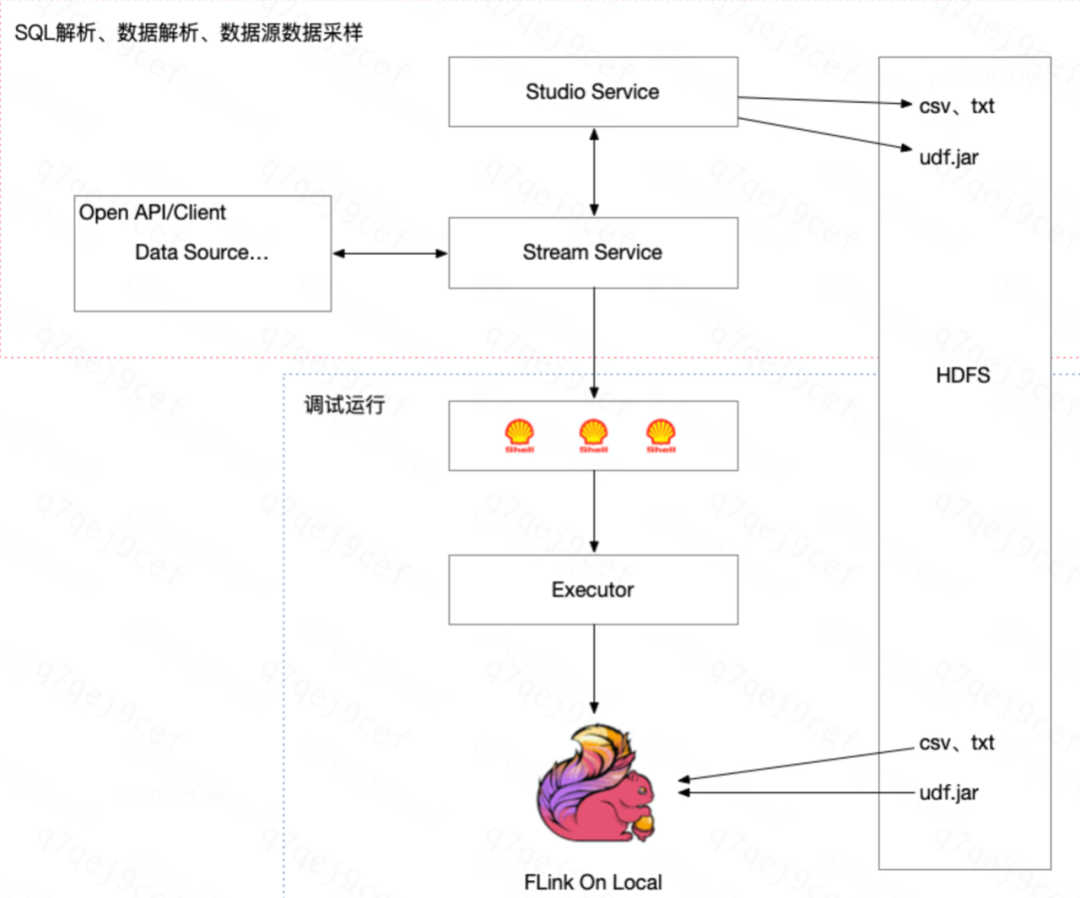
La imagen muestra el diagrama de flujo de la función de depuración local
conjunto de datos
Los sumideros aguas abajo de los resultados del cálculo generalmente incluyen Kakfa, druid, Clickhouse, MySQL, Hbase, ES, fusion, etc. Para los resultados intermedios de las tareas en tiempo real o los datos de la capa dwd de los almacenes de datos en tiempo real, los escribiremos en kafka; para los datos utilizados para el monitoreo de indicadores y las alarmas, los escribiremos en Druid y usaremos las características de base de datos de series de tiempo de druida para mejorar el rendimiento de monitoreo de indicadores en tiempo real; en el escenario de análisis bi comercial, los datos se pueden escribir en Clickhouse para configurar BI Kanban diversificado; los datos resultantes del cálculo del índice usando flink también se pueden escribir directamente en mysql , Hbase, ES o fusión La selección específica aquí se explicará en el siguiente capítulo escenarios comerciales específicos para instrucciones específicas. En la actualidad, todos los sumideros downstream se han integrado a la plataforma, para el caso de usar druid, generalmente es necesario configurar Datasource en Woater (plataforma de monitoreo de indicadores unificados), y para el caso de usar Clickhouse, generalmente es necesario configurar conjuntos de datos en Shuyi (plataforma de análisis de BI).

alarma de monitoreo

Análisis de BI en tiempo real
aplicación de datos en tiempo real
Para los datos de resultados en tiempo real, los métodos comúnmente utilizados incluyen la creación de indicadores en tiempo real en la plataforma Woater (plataforma de monitoreo de indicadores unificados) y la configuración de kanban en tiempo real o alarmas de monitoreo en tiempo real correspondientes para cumplir con el monitoreo de indicadores de resultados a nivel de minutos de negocios y análisis de curvas en tiempo real. También puede usar la tabla Shumengflow (Metatabla de Druid) o el conjunto de datos de ClickHouse en Shuyi ( plataforma de análisis de BI) para configurar informes en tiempo real para cumplir con los diferentes requisitos de análisis de BI en el lado comercial.
3. Selección de componentes de desarrollo de datos en tiempo real en escenarios específicos
El enlace anterior es el principal enlace de desarrollo del actual desarrollo de tareas en tiempo real.En el proceso de desarrollo en tiempo real, necesitamos analizar los problemas específicos en combinación con las necesidades específicas del negocio y las capacidades de cada plataforma, y elegir la opción de desarrollo más adecuada según los diferentes escenarios de negocio.
Escenario de monitoreo de indicadores en tiempo real
Características del escenario : dependencia obvia de la serie temporal, altos requisitos de puntualidad de los indicadores, precisión general de los indicadores, altos requisitos de QPS de consulta y altos requisitos de estabilidad de la salida de datos en tiempo real.
Enlace específico:

En este tipo de escenario, se recomienda configurar DataSource en Woater ( plataforma de monitoreo de indicadores unificados) y establecer las columnas de indicadores y columnas de dimensiones correspondientes en función de los requisitos de monitoreo. Para mejorar la eficiencia de las consultas, es necesario configurar la granularidad de agregación. la granularidad de agregación es de 30 segundos o 1 minuto Al mismo tiempo, para el cálculo de UV En el escenario de indicadores similares, es necesario establecer el campo de la columna del indicador correspondiente en el tipo hiperúnico para mejorar el rendimiento informático y mejorar la capacidad de Druid para consumir datos de temas configurando la partición de consumo de Druid. Generalmente se recomienda que la cantidad de particiones de temas sea un múltiplo par de la cantidad de particiones de Druid. Los indicadores en tiempo real configurados a través de DataSource se utilizan para configurar paneles de monitoreo en tiempo real y alarmas de monitoreo en tiempo real.
Reaseguramiento del enlace central: para escenarios de monitoreo central, para garantizar la estabilidad y la puntualidad del enlace en tiempo real, se requiere el desarrollo de doble enlace.

El enlace dual de procesamiento de datos en tiempo real comienza desde la fuente de datos original, incluida la tarea FLink activa-activa, el tema de resultado activo-activo y la tabla Druid activa-activa en tres partes. cambiando en el nivel de índice en tiempo real para lograr una consulta de índice estable, y también evitar falsos positivos en el monitoreo y alarmas posteriores.
Escenario de análisis de BI en tiempo real
Características del escenario : no depende completamente de la serie temporal, requiere una alta precisión de los indicadores en tiempo real, puede tolerar un cierto retraso de tiempo, tiene requisitos generales para la consulta de QPS y necesita admitir consultas de combinación de dimensión + índice flexibles.
Enlace específico:
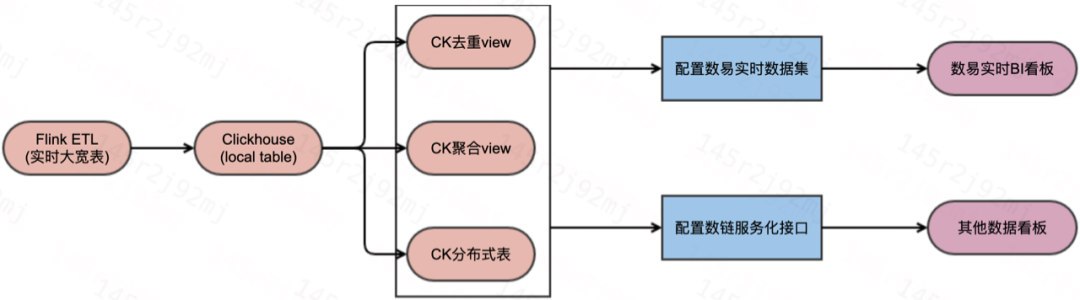
La solución principal para este tipo de escenario es aplanar la información de dimensión requerida tanto como sea posible en la tarea de flink y luego escribir los microlotes de datos en tiempo real aplanados en la tabla local de Clickhouse. Usamos la tabla local de ClickHouse como la tabla inferior y configuramos diferentes tablas de vista materializadas aguas abajo de acuerdo con las diversas necesidades comerciales. Para escenarios que requieren deduplicación en tiempo real basada en claves primarias, podemos usar el motor ReemplazoMergeTree de CK para implementar y luego usar real- tablas de vista materializadas deduplicadas en el tiempo como El conjunto de datos de Shuyi (plataforma de análisis de BI) o la interfaz de Shulian (plataforma de servicio de datos) consulte la tabla inferior para la configuración posterior de BI Kanban; para la escena Kanban de determinar dimensiones e indicadores, con el fin de mejorar el rendimiento de las consultas, también se puede basar en la tabla local de ClickHouse, use el motor AggregatingMergeTree para crear una tabla de vista agregada basada en los campos de dimensión requeridos por la empresa. De esta manera, puede satisfacer las necesidades de los datos descendentes fácilmente configurar el Kanban o proporcionar la interfaz de enlace de datos; el último es un escenario común que no requiere deduplicación y agregación previa en tiempo real, y puede escribir los datos de la pantalla grande de fink o los datos preliminares preagregados al CK En la tabla distribuida, configure directamente el conjunto de datos de Shuyi para permitir que los usuarios configuren los tableros de indicadores requeridos por el negocio.
Los principios fundamentales para la selección de tres tipos de tablas:
Para escenarios comerciales que requieren una precisión extremadamente alta de los indicadores comerciales y tienen claves primarias de deduplicación claras, se recomienda utilizar el gráfico de reducción de énfasis en tiempo real de CK.
Para escenarios donde la precisión de los indicadores comerciales es alta, hay dimensiones claras y definiciones de indicadores, y la lógica de consulta es compleja o el QPS de consulta es alto, se recomienda realizar operaciones de agregación previa y usar la tabla de vista de agregación de CK.
Para escenarios donde el volumen comercial no es grande y la lógica de los cambios comerciales es frecuente, se recomienda usar directamente la tabla común distribuida de CK para proporcionar una configuración kanban descendente en la etapa inicial para cumplir con los requisitos de iteración rápida y recuperación de datos del negocio.
Escenario de servicio en línea de datos en tiempo real
Características del escenario: altos requisitos para la precisión de los indicadores en tiempo real, altos requisitos para consultas QPS, requisitos generales para la puntualidad de los datos
Enlace específico:
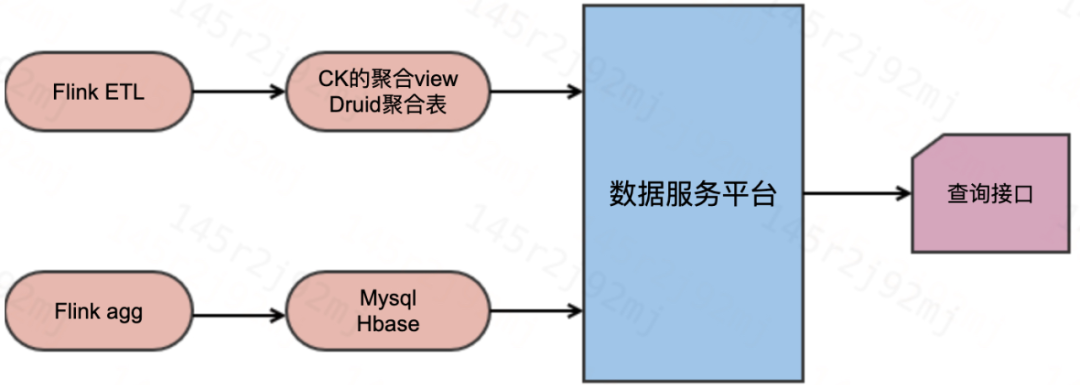
La característica principal de este tipo de escenario es que es necesario realizar varios preprocesamientos de los indicadores en tiempo real requeridos. Una forma es completar el cálculo de los indicadores en tiempo real requeridos en la tarea flink y escribir el resultado final. resultados a MySQL o Hbase en tiempo real El almacenamiento actualizado en tiempo real se utiliza para la encapsulación de interfaz por la plataforma de servicio de datos descendente. Este tipo de solución es adecuada para escenarios en los que la lógica empresarial cambia con poca frecuencia y es necesario proporcionar servicios de datos; otra forma es mover la lógica de agregación hacia abajo, y la tarea de flink es principalmente ampliar el contenido de datos y la agregación previa simple, y el trabajo de estadísticas del indicador principal se entrega a El motor OLAP descendente calcula, y la plataforma de servicio de datos proporciona un servicio de consulta de interfaz al encapsular el motor OLAP. La ventaja de esto es que la capacidad de agregación previa de OLAP también se puede usar para proporcionar servicios de indicadores en tiempo real eficientes cuando la lógica del indicador comercial cambia con frecuencia. La desventaja es que la presión de consulta en OLAP es relativamente alta y se necesitan más recursos. que se proporcionará para el consumo de OLAP para garantizar un alto QPS del servicio.
Sistema de características y etiquetado en tiempo real
Características del escenario: requisitos generales de precisión para indicadores en tiempo real, altos requisitos para consulta QPS y grandes cálculos de estado en tiempo real, y la necesidad de admitir la integración de indicadores en tiempo real y fuera de línea.
Enlace específico:
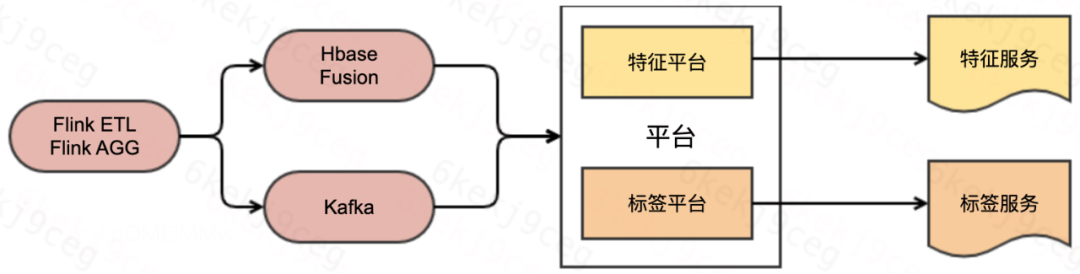
Dichos escenarios generalmente tienen columnas de indicadores y columnas de dimensiones claras, y una gran cantidad de funciones en tiempo real o etiquetas de indicadores deben conectarse a la plataforma. La primera solución es permitir que la plataforma consuma datos directamente a través del tema, y la plataforma proporciona servicios de características o etiquetas después del empaquetado. La segunda solución se basa en la poderosa capacidad de actualización de clave principal de Hbase y Fusion, las etiquetas en tiempo real y fuera de línea se vierten en él y luego se conectan a la plataforma para proporcionar servicios de características o servicios de etiquetas para el algoritmo posterior. estudiantes a utilizar.
4. Principios para el uso de los recursos de cada componente
El desarrollo de datos en tiempo real implica muchos componentes. Se recomienda seguir los principios básicos en el uso de cada componente para aprovechar al máximo los recursos y ahorrar una gran cantidad de costos innecesarios con la premisa de cumplir con el desarrollo de tareas en tiempo real.
Recopilación de datos : el principio de recopilación única, para el desarrollo de indicadores en tiempo real requeridos por el negocio, la fuente de datos ascendente debe reutilizarse tanto como sea posible para garantizar la unidad de las capas de ods en tiempo real y fuera de línea.
ddmq : una tarea de flink corresponde a un grupo de consumidores de ddmq, y se admiten varios temas para usar un grupo de consumidores. No se recomienda usar el mismo grupo de consumidores en diferentes tareas en tiempo real.
kafka : se recomienda que el flujo de tráfico de una sola partición no exceda los 3 MB/s. El tiempo de almacenamiento de Kafka para tareas importantes en tiempo real debe controlarse dentro de las 48-72 horas, y al menos 2 días de datos históricos pueden ser rastreado.
Flink : la concurrencia de origen de kafka y ddmq debe ser estrictamente coherente con la cantidad de particiones establecidas por kafka y ddmq, para que el rendimiento de consumo sea el mejor. El único recurso de TM de la tarea flink en la empresa es slot fijo = 2, taskmanagermemory = 4096, containers.vcores = 2. Se puede ajustar adecuadamente de acuerdo con diferentes escenarios comerciales. Para escenarios ETL puros, la cantidad de ranuras de TM individuales puede Las tareas con un gran uso de memoria pueden aumentar adecuadamente el valor de taskmanagermemory. En el proceso normal de desarrollo de tareas en tiempo real, se recomienda que la simultaneidad global de las tareas kafka sea coherente con la simultaneidad de origen. La simultaneidad global del consumo de ddmq debe determinarse de acuerdo con el flujo de ddmq. La simultaneidad global se establece en 3 para escenarios con tráfico en el rango de (1000±500), y para escenarios que exceden Además de esta conversión de relación, debe estimarse de acuerdo con el operador que consume el tiempo máximo en la lógica de cálculo comercial.
druida : al crear una tabla de druida, debe establecer la granularidad de agregación. La granularidad recomendada es de 30 s o 1 minuto. El período de almacenamiento de datos predeterminado es de 3 meses. La tabla de druida creada en un determinado escenario empresarial debe especificar los campos de dimensión e índice, y los campos de dimensión deben usarse tanto como sea posible. Tipo de cadena, Druid optimiza el mapa de bits y el índice invertido para el tipo de cadena; bajo la premisa de satisfacer las necesidades comerciales, el campo indicador usa el tipo estimado tanto como sea posible para mejorar el rendimiento del cálculo de indicadores en tiempo real.
Clickhouse : el intervalo predeterminado de las tareas de escritura en tiempo real de Flink no es inferior a 30 s, y el paralelismo de escritura debe controlarse dentro de los 10. El ciclo de almacenamiento de datos de la tabla CK debe controlarse en aproximadamente 1 mes. El tiempo debe ser utilizados como campos de partición, y otros tipos de campos no se pueden utilizar como particiones. Se recomienda usar el modo de conector nativo Flink2CK para escenarios de escritura de datos en tiempo real para mejorar la estabilidad de la escritura en tiempo real y reducir el consumo de CPU de CK; se recomienda controlar el rendimiento de escritura de Flink2CK dentro de 20M/s (solo concurrencia) para garantizar indirectamente la estabilidad del clúster CK.
5. Resumen y perspectiva
Este artículo resume principalmente las principales soluciones de desarrollo de tareas en tiempo real y las pilas de tecnología basadas en los escenarios comerciales específicos actuales de Didi, brindando a los usuarios una cierta base de entrada desde el desarrollo fuera de línea hasta el desarrollo de datos en tiempo real y, al mismo tiempo, brinda una mejor solución en tiempo real para estudiantes de productos y operaciones La popularidad del desarrollo de enlaces ha reducido el umbral de desarrollo para la construcción de datos en tiempo real hasta cierto punto. Después de eso, el monitoreo de indicadores en tiempo real, el análisis de BI en tiempo real, el servicio en línea de datos en tiempo real y las funciones en tiempo real de los cuatro escenarios comerciales típicos de Didi se utilizan para ilustrar las diferencias en la selección de componentes en tiempo real y el principios a seguir en cada escenario de negocio. Puede ayudar a los estudiantes de desarrollo empresarial a especificar un plan de desarrollo razonable en tiempo real de acuerdo con los requisitos de datos específicos e implementarlo rápidamente. Finalmente, este documento proporciona sugerencias de configuración para los componentes principales en el proceso de desarrollo de tareas en tiempo real para garantizar que el costo de desarrollo se reduzca tanto como sea posible bajo la premisa de completar el desarrollo de tareas en tiempo real del usuario y la eficiencia general de utilización de recursos. se mejora, reducción de costes y mejora de la eficiencia.