prefacio
Java es más fácil de aprender que otros lenguajes de programación, y gran parte de esto se debe al mecanismo de gestión de memoria automática de la JVM.
Para los desarrolladores comprometidos con el lenguaje C, tienen la "propiedad" de cada objeto, y un mayor poder también significa más responsabilidades. Los desarrolladores de C deben mantener el proceso de cada objeto "desde el nacimiento hasta la muerte". Cuando se descarta un objeto, su memoria debe liberarse manualmente, de lo contrario se producirá una fuga de memoria. Para los desarrolladores de Java, el mecanismo de administración de memoria automática de JVM resuelve este problema de dolor de cabeza, y los problemas de fugas de memoria y desbordamiento de memoria no son fáciles de ocurrir.GC permite a los desarrolladores concentrarse más en el programa en sí en lugar de preocuparse por la memoria. asignar, cuándo desasignar y cómo desasignar.
1. Área de datos de tiempo de ejecución de JVM
Antes de hablar de GC, es necesario comprender el modelo de memoria de la JVM, cómo la JVM planifica la memoria y las áreas principales de GC.
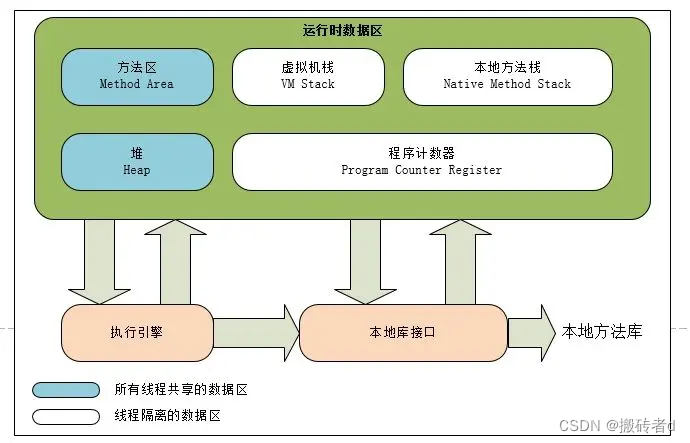
Como se muestra en la figura, cuando se ejecuta la JVM, la memoria se dividirá en cinco grandes áreas, entre las cuales el "área de método" y el "montón" se crean con el inicio de la JVM, y son áreas de memoria compartidas por todos los subprocesos. . La pila de la máquina virtual, la pila de métodos locales y el contador del programa se crean junto con la creación del subproceso y se destruyen después de que se ejecuta el subproceso.
1.1 Contador de programa
El contador de programa (Program Counter Register) es un espacio de memoria muy pequeño, casi insignificante.
Puede considerarse como el indexador de número de línea del código de bytes ejecutado por el subproceso, que apunta a la siguiente instrucción que debe ejecutar el subproceso actual. Para: Las funciones básicas como bifurcaciones condicionales, bucles, saltos y excepciones dependen del contador del programa.
Para un núcleo de CPU, solo se puede ejecutar un subproceso en cualquier momento. Si se agota el intervalo de tiempo de la CPU del subproceso, se suspenderá y esperará a que el sistema operativo reasigne el intervalo de tiempo antes de continuar con la ejecución. ¿Cómo sabe el subproceso dónde se ejecutó por última vez? Se implementa a través del contador de programa y cada subproceso necesita mantener un contador de programa privado.
Si el subproceso está ejecutando un método Java, el contador registra la dirección de la instrucción de código de bytes JVM. Si se ejecuta el método Nativo, el valor del contador es Indefinido.
El contador del programa es la única área de memoria que no especifica ninguna condición OutOfMemoryError, lo que significa que las excepciones OOM no pueden ocurrir en esta área, ¡y el GC no reciclará esta área!
1.2 Pila de máquinas virtuales
La pila de máquinas virtuales (Java Virtual Machine Stacks) también es privada para subprocesos y tiene el mismo ciclo de vida que el subproceso.
La pila de la máquina virtual describe el modelo de memoria de la ejecución del método Java. Cuando la JVM quiere ejecutar un método, primero creará un marco de pila (Stack Frame) para almacenar: tabla de variables locales, pila de operandos, enlace dinámico, salida de método y otros información. Una vez que se crea el marco de la pila, se insertará en la pila para su ejecución y se sacará de la pila una vez que finalice la ejecución del método.
El proceso de ejecución del método es el proceso de cada marco de pila desde que se presiona hasta que se abre.
La tabla de variables locales se usa principalmente para almacenar varios tipos de datos básicos, referencias a objetos y tipos de dirección de retorno conocidos por el compilador. El espacio de memoria requerido por la tabla de variables locales se ha confirmado en tiempo de compilación y el tamaño de la tabla de variables locales no se modificará durante la operación.
En la especificación JVM, la pila de máquinas virtuales especifica dos excepciones:
- La profundidad de pila solicitada por el subproceso StackOverflowError
es mayor que la profundidad de pila permitida por JVM.
La capacidad de la pila es limitada.Si el marco de la pila empujado por el subproceso supera el límite, se lanzará una excepción StackOverflowError, por ejemplo: recursividad del método. - La pila de máquinas virtuales OutOfMemoryError
se puede expandir dinámicamente. Si no se puede obtener suficiente memoria durante la expansión, se lanzará una excepción OOM.
1.3 Pila de métodos nativos
La pila de métodos nativos (Native Method Stack) también es privada para subprocesos, lo que es muy similar a la pila de máquinas virtuales.
La diferencia es que la pila de la máquina virtual sirve para ejecutar métodos Java, mientras que la pila de métodos locales sirve para ejecutar métodos nativos.
Al igual que la pila de máquinas virtuales, la especificación de JVM también especifica dos excepciones, StackOverflowError y OutOfMemoryError, para la pila de métodos locales.
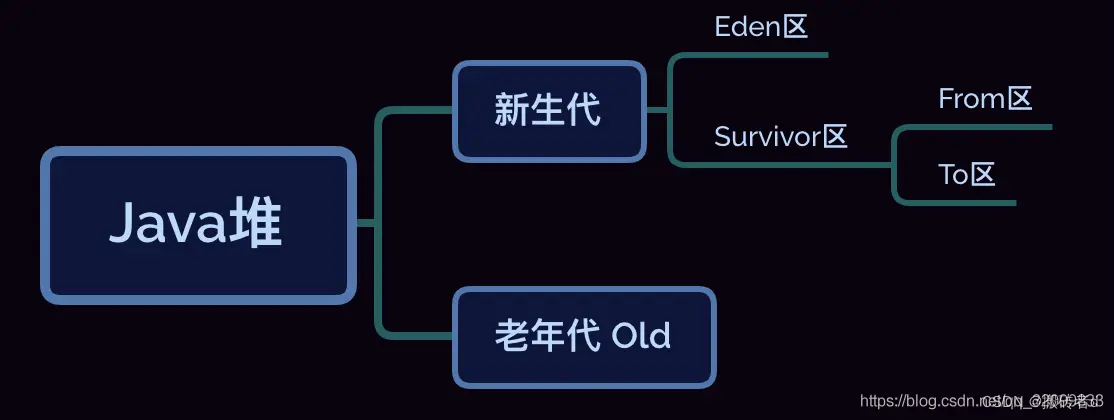
1.4 montón
El montón de Java (Java Heap) es compartido por subprocesos. En términos generales, también es el área de memoria más grande administrada por la JVM, y también es el área de administración principal del recolector de basura GC.
El montón de Java se crea cuando se inicia la JVM y su función es almacenar instancias de objetos.
Casi todos los objetos se crean en el montón, pero con el desarrollo de compiladores JIT y la madurez de las técnicas de análisis de escape, la asignación en la pila y las técnicas de optimización de reemplazo escalar hacen que "todos los objetos se asignen en el montón" menos absoluto.
Debido a que es el área administrada principalmente por GC, también se denomina: Montón de GC.
Para el reciclaje eficiente de GC, el montón de Java se divide de la siguiente manera:
1.5 Área de método
El área de métodos (Method Area), como el montón de Java, también es un área de memoria compartida por subprocesos.
Se utiliza principalmente para almacenar: información de clase cargada por la JVM, constantes, variables estáticas, código generado por el compilador justo a tiempo y otros datos.
También conocido como: Non-Heap (Non-Heap), el propósito es distinguirlo del montón de Java.
La especificación JVM tiene restricciones relativamente flexibles en el área de métodos, y es posible que JVM ni siquiera realice la recolección de elementos no utilizados en el área de métodos. Esto lleva al hecho de que en la versión anterior de JDK, el área de métodos también se llama: PermGen (PermGen).
No es una buena idea usar la generación permanente para implementar el área de método, y es fácil causar un desbordamiento de memoria. Por lo tanto, desde JDK7, ha habido una acción de "eliminar la generación permanente", y el conjunto de constantes de cadenas se colocó originalmente en la generación permanente serán removidos. En JDK8, la generación permanente se elimina oficialmente y se introduce el metaespacio.
2. Descripción general del GC
Garbage Collection (Recolección de basura) se abrevia como "GC". Su historia es mucho más larga que el propio lenguaje Java. Lisp, que nació en el Instituto Tecnológico de Massachusetts en 1960, fue el primer lenguaje en comenzar a utilizar la asignación dinámica de memoria y la basura. tecnología de recolección.
Para realizar la recolección automática de elementos no utilizados, primero debe pensar en tres cosas: las
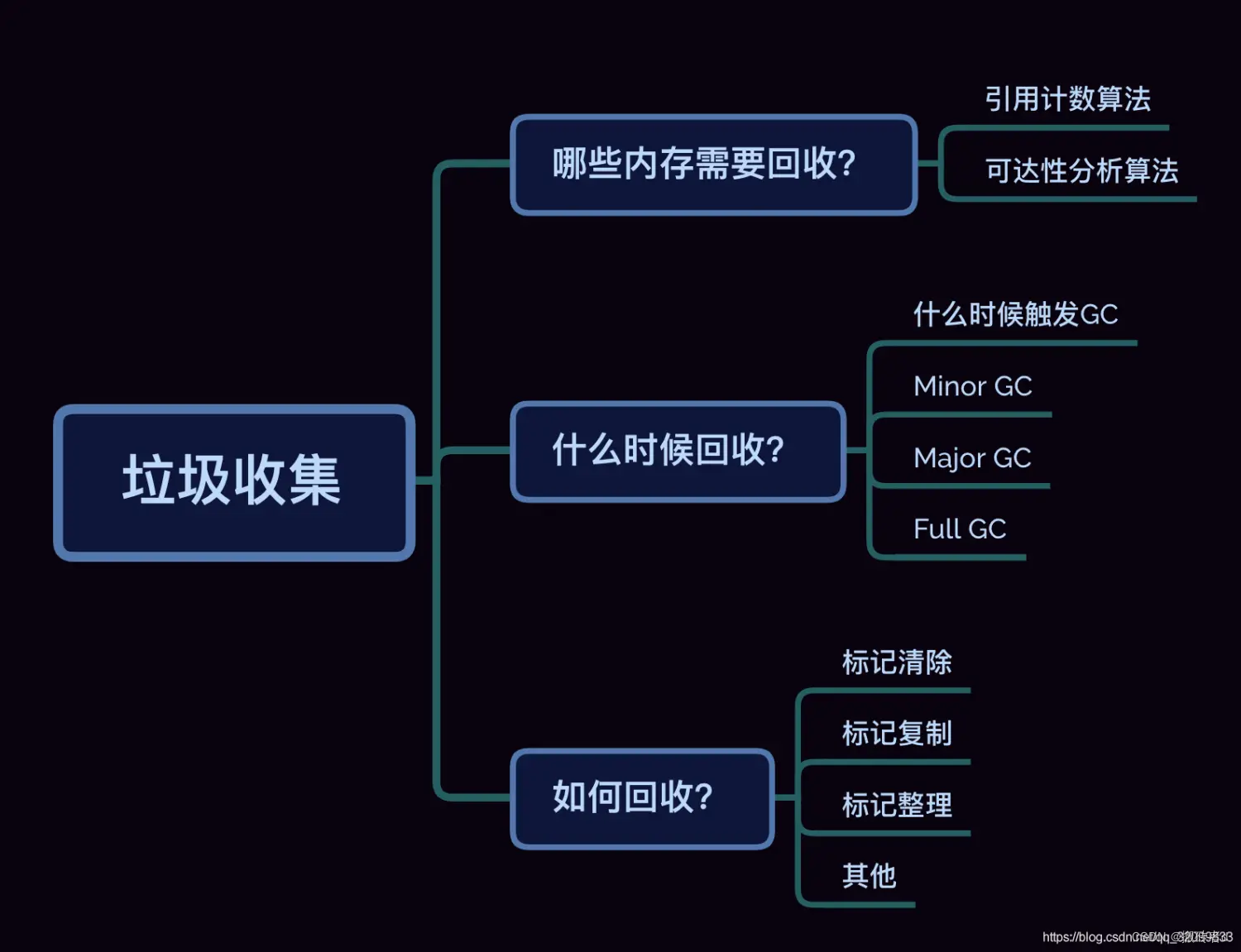
cinco áreas de memoria principales de la JVM se introdujeron anteriormente. El contador del programa ocupa muy poca memoria, que es casi insignificante, y nunca se desbordará de la memoria, y el GC no necesita reciclarlo. La pila de la máquina virtual y la pila del método local "viven y mueren juntas” con el subproceso. Los marcos de la pila en la pila se insertan y extraen de la pila de manera ordenada con la operación del método. La cantidad de memoria asignada a cada marco de pila se ha determinado básicamente durante el período de compilación. Por lo tanto, la asignación y recuperación de memoria en estas dos áreas son deterministas y no hay necesidad de considerar cómo recuperar.
El área de métodos es diferente ¿Cuántas clases de implementación tiene una interfaz? ¿Cuánta memoria ocupa cada clase? Incluso puede crear clases dinámicamente en tiempo de ejecución, por lo que el GC necesita reciclar el área del método.
Lo mismo es cierto para el montón de Java. Casi todas las instancias de objetos de Java se almacenan en el montón. Cuántas instancias de objetos creará una clase solo se puede saber cuando el programa se está ejecutando. La asignación y recuperación de esta parte de la memoria es dinámica, y GC necesita enfocarse en eso.
2.1 Qué objetos necesitan ser reciclados
El primer paso para realizar la recolección automática de basura es determinar qué objetos se pueden reciclar. En términos generales, hay dos formas: el algoritmo de recuento de referencias y el algoritmo de análisis de accesibilidad, y casi todas las JVM comerciales utilizan este último.
2.1.1 Algoritmo de conteo de referencia
Agregue un contador de referencia al objeto, agregue 1 cada vez que se haga referencia al contador y disminuya 1 cada vez que se cancele el contador de referencia. Cuando el contador es 0, significa que ya no se hace referencia al objeto y se puede reciclar. en este momento.
Aunque el algoritmo de conteo de referencias (Reference Counting) ocupa algo de espacio de memoria extra, su principio es simple y eficiente, es una buena implementación en la mayoría de los casos, pero tiene un serio inconveniente: no puede resolver referencias circulares.
Por ejemplo, una lista enlazada se debe reciclar siempre que no haya ninguna referencia a la lista enlazada, pero lamentablemente, dado que los contadores de referencia de todos los elementos de la lista enlazada no son 0, no se puede reciclar, lo que provoca pérdidas de memoria.
2.1.2 Algoritmo de análisis de accesibilidad
En la actualidad, las JVM comerciales convencionales utilizan el análisis de accesibilidad para determinar si los objetos se pueden reciclar.
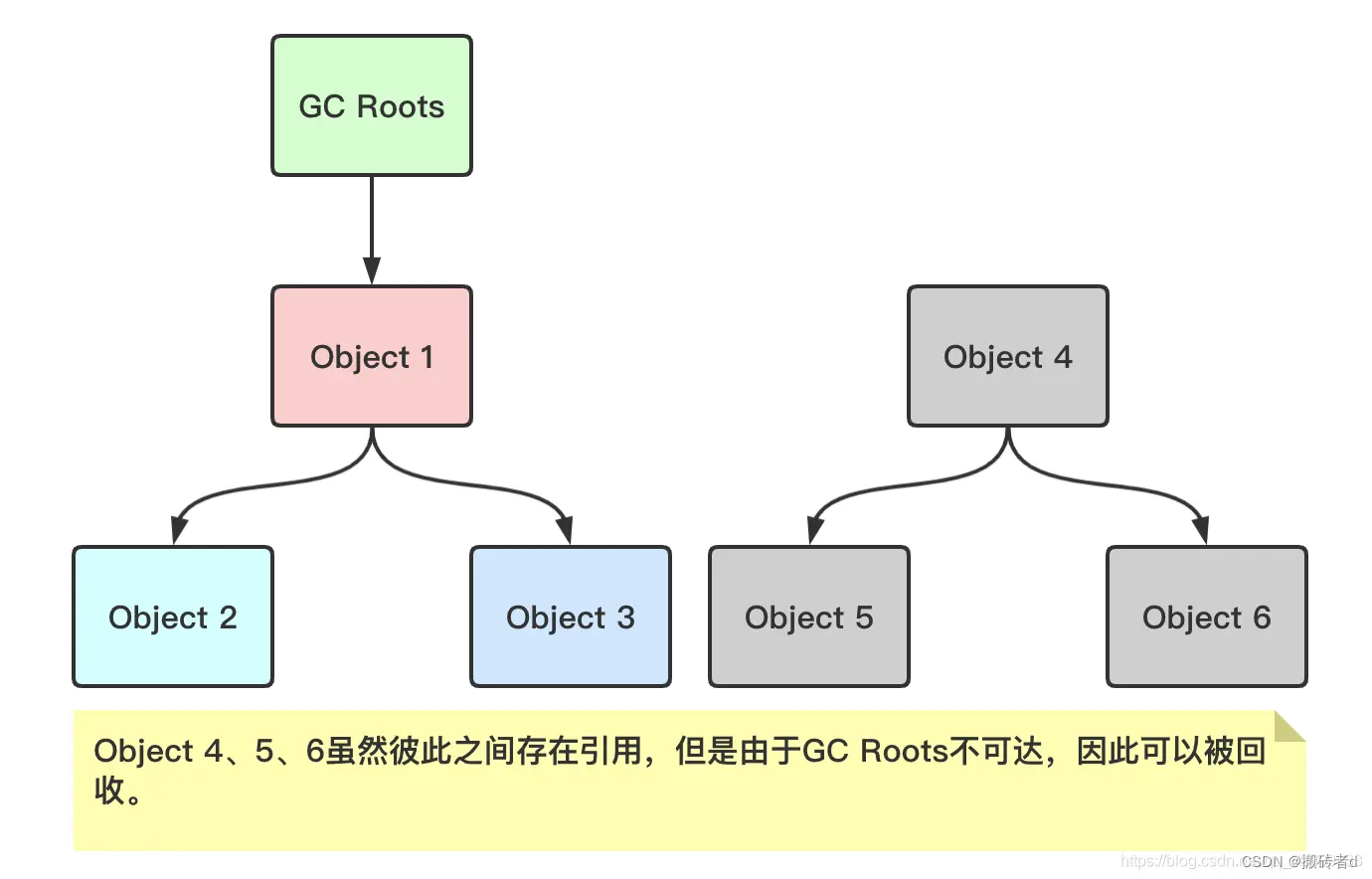
La idea básica de este algoritmo es:
Utilice una serie de objetos raíz llamados "Raíces de GC" como el conjunto de nodos de inicio. A partir de estos nodos, busque hacia abajo a través de la relación de referencia. La ruta de búsqueda se denomina "cadena de referencia". Si un objeto llega a Raíces de GC Si no hay una cadena de referencia conectado, significa que el objeto es inalcanzable y puede ser reciclado.
Alcanzabilidad del objeto significa que existe una relación de referencia directa o indirecta entre las dos partes.
La accesibilidad de la raíz o la accesibilidad de las raíces del GC significa que existe una relación de referencia directa o indirecta entre los objetos y las raíces del GC.
Los objetos que se pueden usar como raíces de GC son los siguientes:
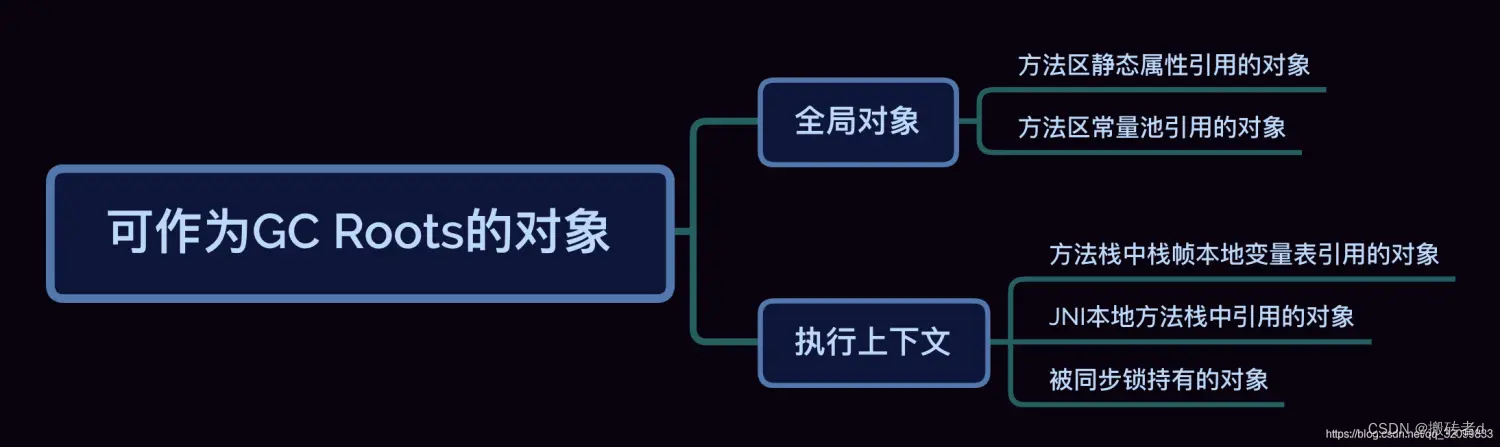
El análisis de accesibilidad significa que la JVM primero enumera los nodos raíz, encuentra algunos objetos que deben sobrevivir para garantizar el funcionamiento normal del programa y luego usa estos objetos como raíces para comenzar. Después de la búsqueda, los objetos con cadenas de referencia directa o indirecta sobrevivirán y los objetos sin cadenas de referencia se reciclarán.
2.2 Cuándo reciclar
La JVM divide la memoria en cinco áreas, y diferentes GC realizarán la recolección de basura para diferentes áreas.Los tipos de GC generalmente se dividen en las siguientes categorías:
- Minor GC
también se conoce como "Young GC" y "Light GC", que es solo para la recolección de basura de la nueva generación. - Major GC
, también conocido como "Old GC", es solo para la recolección de basura en la vejez. - El GC mixto
es un GC mixto, que realiza la recolección de elementos no utilizados para la nueva generación y algunas generaciones anteriores, y solo algunos recolectores de elementos no utilizados lo admiten. - GC completo
GC de montón completo, GC pesado, recolección de elementos no utilizados para todo el área de método y montón de Java, el GC más largo.
¿Cuándo se activa el GC y qué tipo de GC se activa? Los diferentes recolectores de basura se implementan de manera diferente, y también puede influir en la toma de decisiones de la JVM mediante el establecimiento de parámetros.
En términos generales, la nueva generación activará GC después de que se agote el área Eden, pero el área antigua no puede hacer esto, porque algunos recopiladores simultáneos pueden continuar ejecutándose durante el proceso de limpieza, lo que significa que el programa aún está creando objetos, asignando memoria, que requiere que la generación anterior lleve a cabo la "garantía de asignación de espacio". Los objetos que no pueden caber en la nueva generación se colocarán en la generación anterior. Si la velocidad de recuperación de la generación anterior es más lenta que la velocidad de creación de objetos, dará lugar a "fallo de garantía de asignación". , en este momento, la JVM debe activar Full GC para obtener más memoria disponible.
2.3 Cómo reciclar
Después de localizar el objeto que necesita ser reciclado, es hora de comenzar a reciclar. Cómo reciclar objetos ha vuelto a ser un problema.
¿Qué tipo de método de reciclaje será más eficiente? ¿Es necesario comprimir y organizar la memoria después del reciclaje para evitar la fragmentación? En respuesta a estos problemas, los algoritmos de reciclaje de GC se dividen aproximadamente en las siguientes tres categorías:
- algoritmo de barrido de marcas
- algoritmo de marca-copia
- Algoritmo de clasificación de marcas
Los detalles del algoritmo de recuperación se presentarán a continuación.
3. Algoritmo de recuperación de GC
La JVM divide el montón en diferentes generaciones. Los objetos almacenados en diferentes generaciones tienen diferentes características. El uso de diferentes algoritmos de recuperación de GC para diferentes generaciones puede mejorar la eficiencia de GC.
3.1 Teoría de la colección generacional
En la actualidad, la mayoría de los recolectores de basura JVM siguen la teoría de la "recolección generacional", que se basa en tres hipótesis.
3.1.1 La hipótesis de la generación débil
La gran mayoría de los objetos son la vida y la muerte.
Piensa si los programas que escribimos son así. La mayoría de las veces, creamos un objeto solo para realizar algunos cálculos comerciales. Una vez que se obtienen los resultados del cálculo, el objeto es inútil y se puede reciclar.
Otro ejemplo: el cliente solicita devolver una lista de datos. Después de que el servidor consulta la base de datos y la convierte en una respuesta JSON para el front-end, los datos de esta lista se pueden reciclar.
Cosas como esta pueden llamarse objetos de "vivir y morir".
3.1.2 Hipótesis generacional fuerte
Cuantos más objetos sobrevivan a la GC, más difícil será reciclarlos.
Esta hipótesis se basa completamente en estadísticas de probabilidad. Se puede suponer que los objetos que no se pueden reciclar después de muchos GC no se reciclarán en el próximo GC, por lo que no hay necesidad de reciclarlos con frecuencia y moverlos. En la vejez, reduzca la frecuencia de reciclaje y dejar que el GC recicle la nueva generación con mayores beneficios.
3.1.3 Hipótesis de citas intergeneracionales
Las citas intergeneracionales son raras en comparación con las citas de la misma generación.
Esta es una inferencia implícita basada en el razonamiento lógico de las dos primeras hipótesis: dos objetos que tienen una relación de referencia mutua deberían tender a vivir o morir al mismo tiempo.
Por ejemplo, si un objeto de nueva generación tiene una referencia intergeneracional, dado que el objeto de la generación anterior es difícil de perecer, la referencia hará que el objeto de la nueva generación sobreviva cuando se recopile, y luego se promoverá a la generación anterior después envejece También se eliminaron las referencias posteriores.
3.2 Resolviendo las referencias intergeneracionales
Las referencias intergeneracionales son raras, pero posibles. Si escanea toda la generación anterior en busca de muy pocas referencias intergeneracionales, la sobrecarga de cada GC será demasiado grande y el tiempo de pausa del GC será inaceptable. Si se ignoran las referencias intergeneracionales, los objetos de la nueva generación se reciclarán incorrectamente, lo que provocará errores en el programa.
3.2.1 Conjunto recordado
La JVM resuelve este problema a través del conjunto recordado. Al establecer la estructura de datos del conjunto recordado en la nueva generación, se evita agregar toda la generación anterior al rango de escaneo de GC Roots al reciclar la nueva generación, lo que reduce la sobrecarga de GC.
El conjunto de memoria es una estructura de datos abstractos de punteros desde el "área de no colección" al "área de colección". Para decirlo sin rodeos, es para marcar "los objetos a los que hace referencia la generación anterior en la generación joven". Los conjuntos de memoria pueden tener las siguientes tres precisiones de registro:
- Precisión de longitud de palabra: el registro tiene una precisión de longitud de palabra de máquina, es decir, el número de bits direccionables del procesador.
- Precisión del objeto: precisa para el objeto, ya sea que haya un puntero de referencia de generación cruzada en el campo del objeto.
- Precisión de la tarjeta: precisa para un área de memoria, ya sea que haya referencias intergeneracionales a objetos en esta área.
La precisión de longitud de palabra y la precisión de objeto son demasiado refinadas, y se necesita mucha memoria para mantener el conjunto de memoria, por lo que muchas JVM usan "precisión de tarjeta", también conocida como: "tabla de tarjeta". La tabla de tarjetas es una implementación del conjunto de memoria, y también es la forma más utilizada en la actualidad. Define la precisión de registro del conjunto de memoria, la relación de mapeo con la memoria, etc.
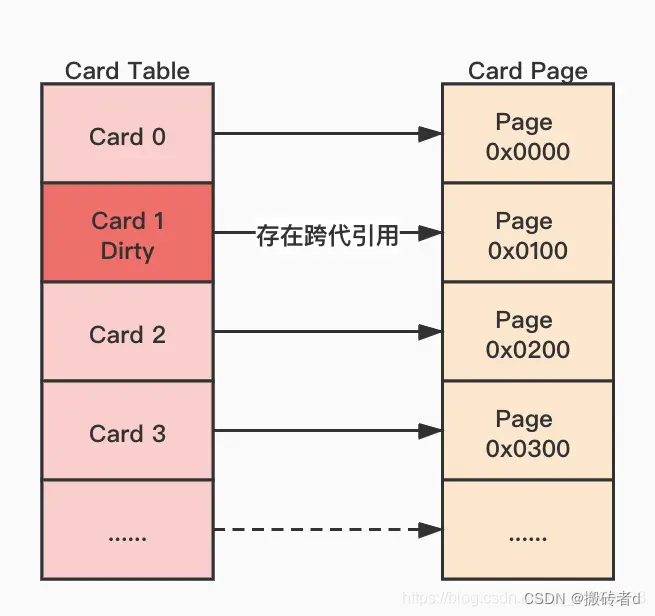
HotSpot utiliza una matriz de bytes para implementar la tabla de tarjetas. Divide el espacio de almacenamiento dinámico en una serie de áreas de memoria potencia de dos. Esta área de memoria se denomina "página de tarjeta". El tamaño de una página de tarjeta es generalmente 2. Potencia de , HotSpot utiliza 2 elevado a la novena potencia, es decir, 512 bytes. Cada elemento de la matriz de bytes corresponde a una página de tarjeta. Si hay una referencia intergeneracional a un objeto en una página de tarjeta, la JVM marcará la página de tarjeta como "sucia". El GC solo necesita escanear la página sucia correspondiente El área de memoria se puede utilizar para evitar escanear todo el montón.
La estructura de la mesa de cartas se muestra en la siguiente figura:
3.2.2 Barrera de escritura
La tabla de tarjetas es solo una estructura de datos utilizada para marcar qué área de memoria tiene referencias intergeneracionales ¿Cómo mantiene la JVM la tabla de tarjetas? ¿Cuándo se ensucian las páginas de una tarjeta?
HotSpot mantiene la tabla de tarjetas a través de la "barrera de escritura". La JVM intercepta la acción de "asignación de propiedad de objeto". Similar a la programación de aspectos de AOP, la JVM puede intervenir antes y después de la asignación de propiedad de objeto. Se denomina "barrera antes de escribir". ", y el procesamiento posterior a la asignación se denomina "barrera posterior a la escritura". El pseudocódigo es el siguiente:
void setField(Object o){
before();//写前屏障
this.field = o;
after();//写后屏障
}
Después de habilitar la barrera de escritura, la JVM generará las instrucciones correspondientes para todas las operaciones de asignación. Una vez que una referencia a un objeto en la generación anterior apunte a un objeto en la generación joven, HotSpot configurará el elemento de la tabla de tarjetas correspondiente como sucio.
Distinga la "barrera de escritura" aquí de la "barrera de escritura" de reordenar las instrucciones de memoria en la programación concurrente para evitar confusiones.
Además de la sobrecarga de la barrera de escritura en sí misma, la tabla de tarjetas también enfrenta el problema de "uso compartido falso" en escenarios de alta concurrencia. El sistema de caché de las CPU modernas se almacena en unidades de "líneas de caché". El tamaño es generalmente de 64 bytes. Cuando varios subprocesos modifican variables independientes, si estas variables están en la misma línea de caché, las líneas de caché de cada uno dejarán de ser válidas sin ningún motivo. Los subprocesos tienen que iniciar con frecuencia instrucciones de carga para recargar datos, lo que resulta en Reducción actuación.
Una línea de caché tiene 64 bytes, cada página de tarjeta tiene 512 bytes, 64✖️512 bytes tiene 32 KB, si los objetos actualizados por diferentes subprocesos están dentro de estos 32 KB, hará que la tabla de tarjetas se actualice al mismo tiempo. Una línea de caché afecta actuación. Para evitar este problema, HotSpot admite configurar el elemento como sucio solo cuando no está marcado. Esto agregará un juicio, pero puede evitar el problema del intercambio falso.
-XX:+UsarCondCardMark
para abrir este juicio.
3.3 Eliminación de marcas
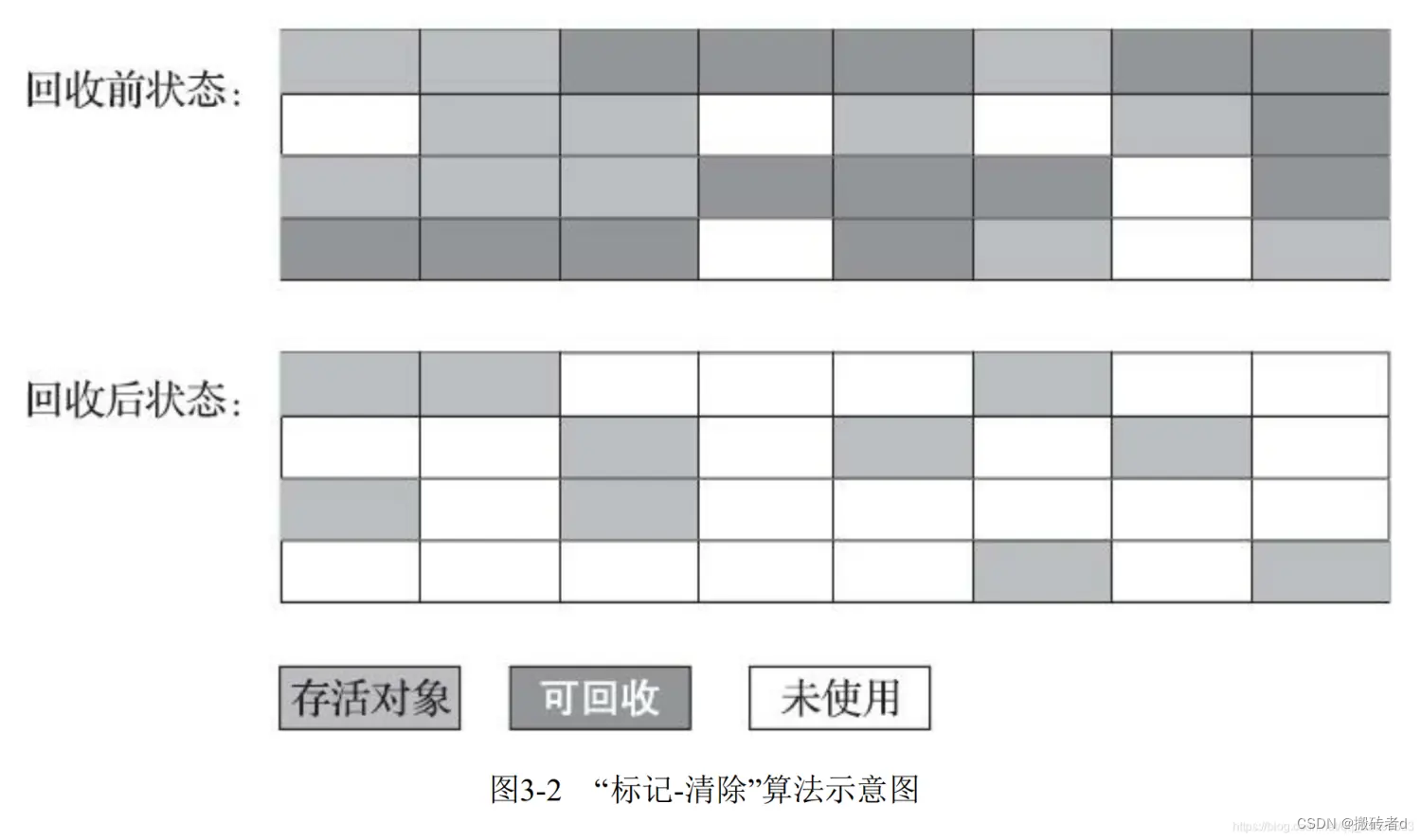
El algoritmo de marcar y barrer se divide en dos procesos: marcar y borrar.
El recolector primero marca los objetos que necesitan ser reciclados y los limpia uniformemente después de completar el marcado. También es posible marcar los objetos sobrevivientes y luego borrar todos los objetos no marcados, según la proporción de objetos sobrevivientes y objetos muertos en la memoria.
defecto:
Eficiencia de ejecución inestable
El consumo de tiempo de marcar y borrar aumenta con el aumento del número de objetos en el montón de Java.
Fragmentación de la memoria
Después de borrar la marca, la memoria generará una gran cantidad de fragmentos de espacio discontinuos, lo que no es propicio para la subsiguiente asignación de memoria para nuevos objetos.
3.4 Marcar copia
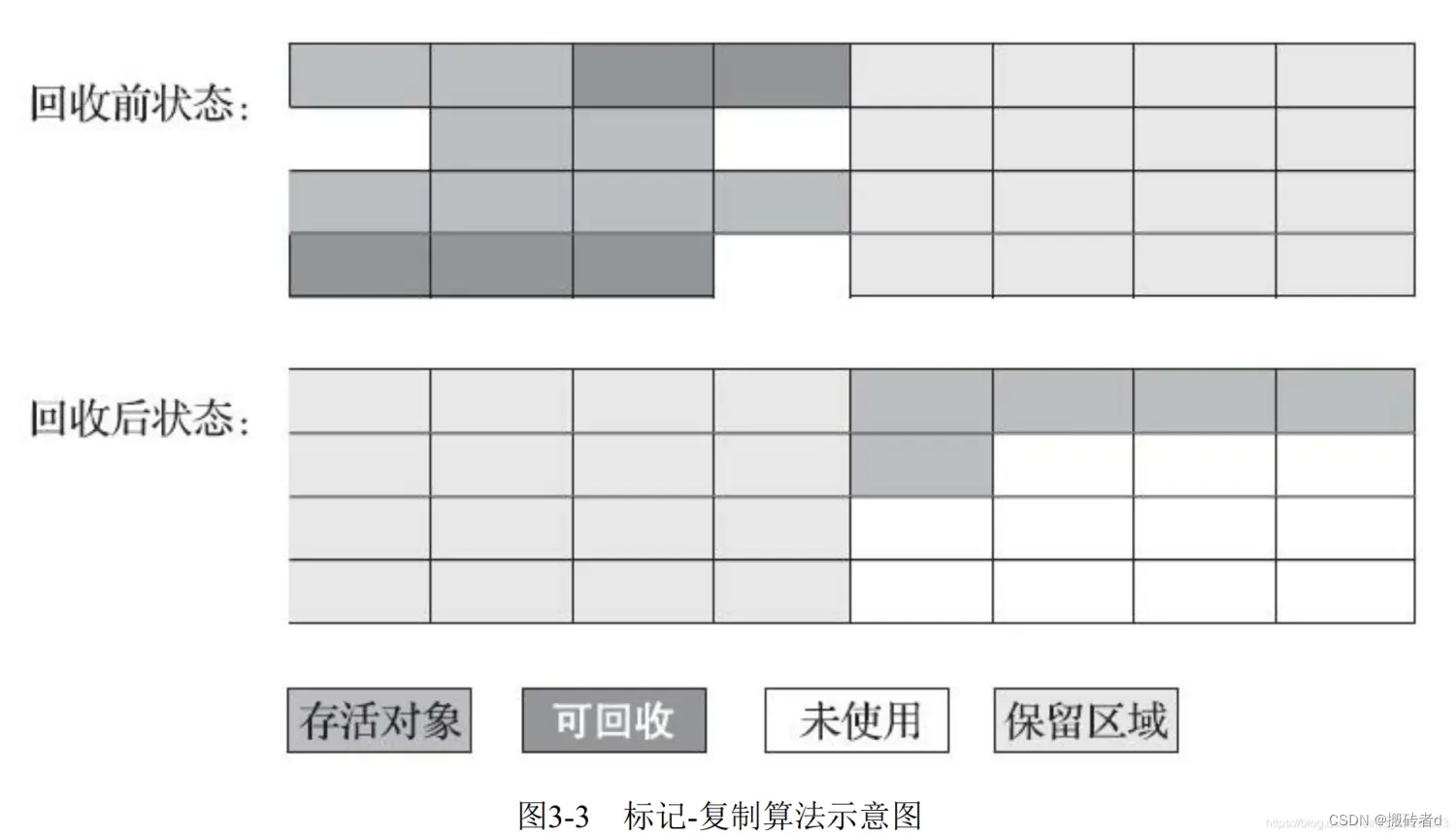
Para resolver el problema de la fragmentación de la memoria causada por el algoritmo de barrido de marcas, se ha mejorado el algoritmo de copia de marcas.
El algoritmo de copia de marcas divide la memoria en dos áreas, y solo una de ellas se usa a la vez. Durante la recolección de basura, primero se marca. Una vez que se completa la marca, los objetos supervivientes se copian en otra área y luego todos los se limpian las áreas actuales.
La desventaja es que si no se puede reciclar una gran cantidad de objetos, se generará una gran cantidad de sobrecarga de copia de memoria. La memoria disponible se reduce a la mitad y el desperdicio de memoria es relativamente grande.
Dado que la gran mayoría de los objetos se reciclarán en el primer GC, es necesario copiar muy pocos objetos, por lo que no es necesario dividir el espacio de acuerdo con 1:1.
La proporción predeterminada del área Eden al área Survivor de la máquina virtual HotSpot es 8:1, es decir, el área Eden es 80 %, el área From Survivor es 10 % y el área To Survivor es 10 %. La memoria disponible de toda la nueva generación es el área Eden + un área Survivor, que es el 90%, otro 10% del área Survivor se usa para la replicación de particiones.
Si aún sobrevive una gran cantidad de objetos después de la GC menor, más allá del alcance de un área de supervivientes, se realizará la garantía de asignación (promoción de manejo) para asignar directamente los objetos a la generación anterior.
3.5 Marcado y acabado
Además de más operaciones de copia cuando sobrevive una gran cantidad de objetos, el algoritmo de copia de marca también requiere espacio de memoria adicional en la generación anterior para garantizar la asignación, por lo que este algoritmo de reciclaje generalmente no se usa en la generación anterior.
Los objetos que pueden sobrevivir en la generación anterior generalmente son objetos que no se pueden reciclar después de múltiples GC. Según la "hipótesis generacional fuerte", los objetos de la generación anterior generalmente son difíciles de reciclar. De acuerdo con las características de supervivencia de los objetos en la vejez, se introduce un algoritmo de clasificación de marcas.
El proceso de marcado del algoritmo de limpieza de marcas es consistente con el algoritmo de limpieza de marcas, pero el algoritmo de limpieza de marcas no limpia directamente los objetos marcados como el algoritmo de limpieza de marcas, sino que mueve todos los objetos supervivientes a un extremo del área de memoria, y luego limpia directamente los objetos fuera del límite.espacio de memoria.
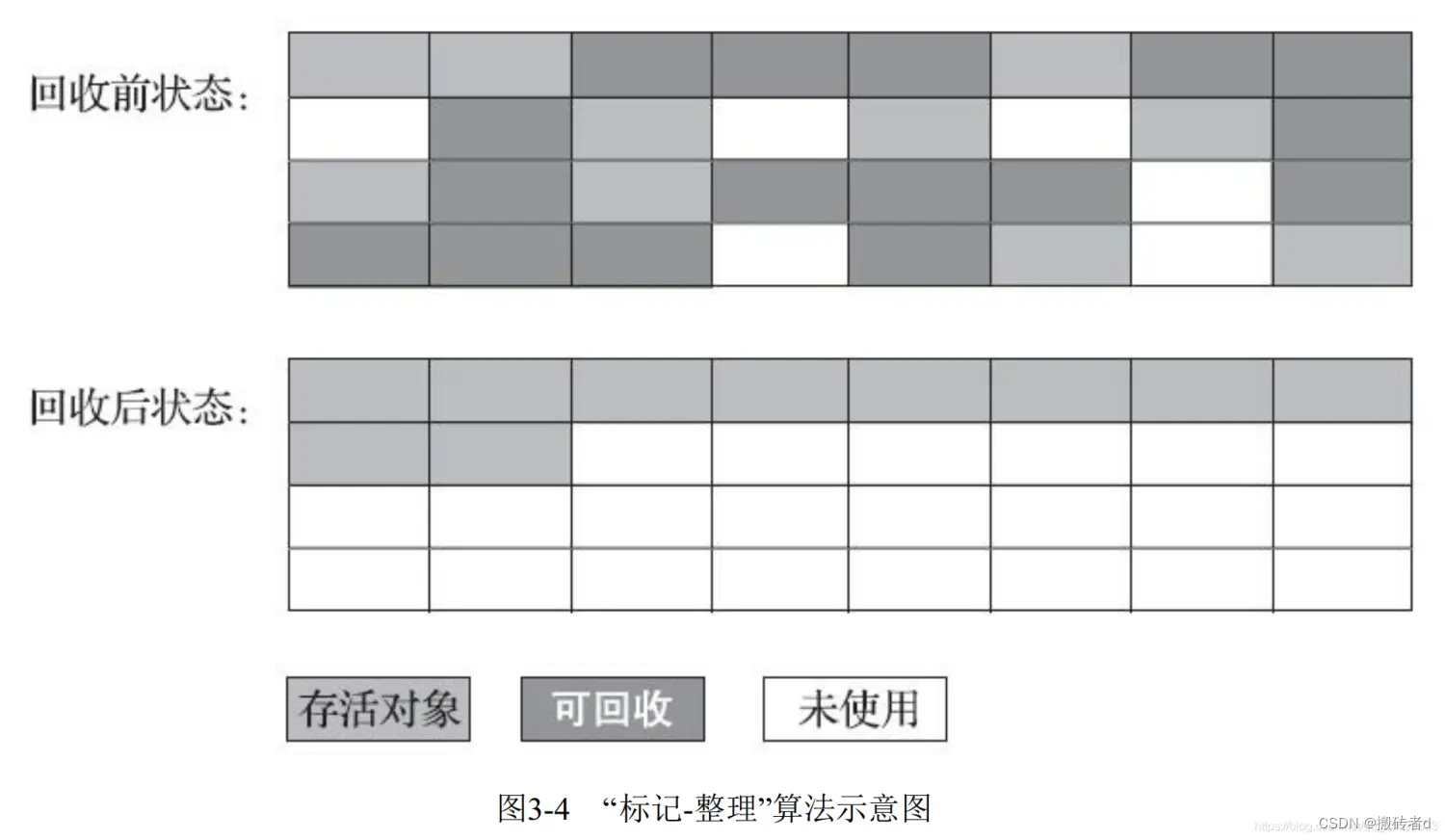
En comparación con el algoritmo de limpieza de marcas, la mayor diferencia entre el algoritmo de limpieza de marcas es que los objetos supervivientes deben moverse.
Mover objetos vivos durante la GC tiene ventajas y desventajas.
La desventaja
se basa en la "hipótesis generacional fuerte". En la mayoría de los casos, una gran cantidad de objetos sobrevivirán después del GC de la generación anterior. Para mover estos objetos, todas las direcciones de referencia deben actualizarse. Esta es una operación costosa y esto La operación necesita suspender todos los subprocesos del usuario, es decir, el programa bloqueará la pausa en este momento, y la JVM llama a esta pausa: Stop The World (STW).
Ventajas
Después de mover el objeto para organizar el espacio de memoria, no se generará una gran cantidad de fragmentos de memoria discontinuos, lo que es beneficioso para la subsiguiente asignación de memoria para el objeto.
Se puede ver que hay ventajas y desventajas si el objeto se mueve o no. Si se muda, es responsable de la recuperación de memoria y de la asignación de memoria simple. Si no se mueve, es fácil recuperar memoria y complicar la asignación de memoria. Teniendo en cuenta el rendimiento de todo el programa, mover objetos obviamente es más rentable, porque la frecuencia de asignación de memoria es mucho mayor que la frecuencia de recuperación de memoria.
Hay otra solución: no mueva el objeto en momentos normales, use el algoritmo de borrado de marcas y solo habilite el algoritmo de borrado de marcas cuando la fragmentación de la memoria afecte la asignación de objetos grandes.
4. Recolector de basura
Hay demasiadas JVM implementadas de acuerdo con la "Especificación de máquina virtual Java", y cada plataforma JVM tiene N recolectores de basura para que los usuarios elijan. Esto no está claro en un artículo. Por supuesto, los desarrolladores no necesitan entender todos los recolectores de basura.Tomando Hotspot JVM como ejemplo, los recolectores de basura principales se clasifican principalmente en las siguientes categorías:
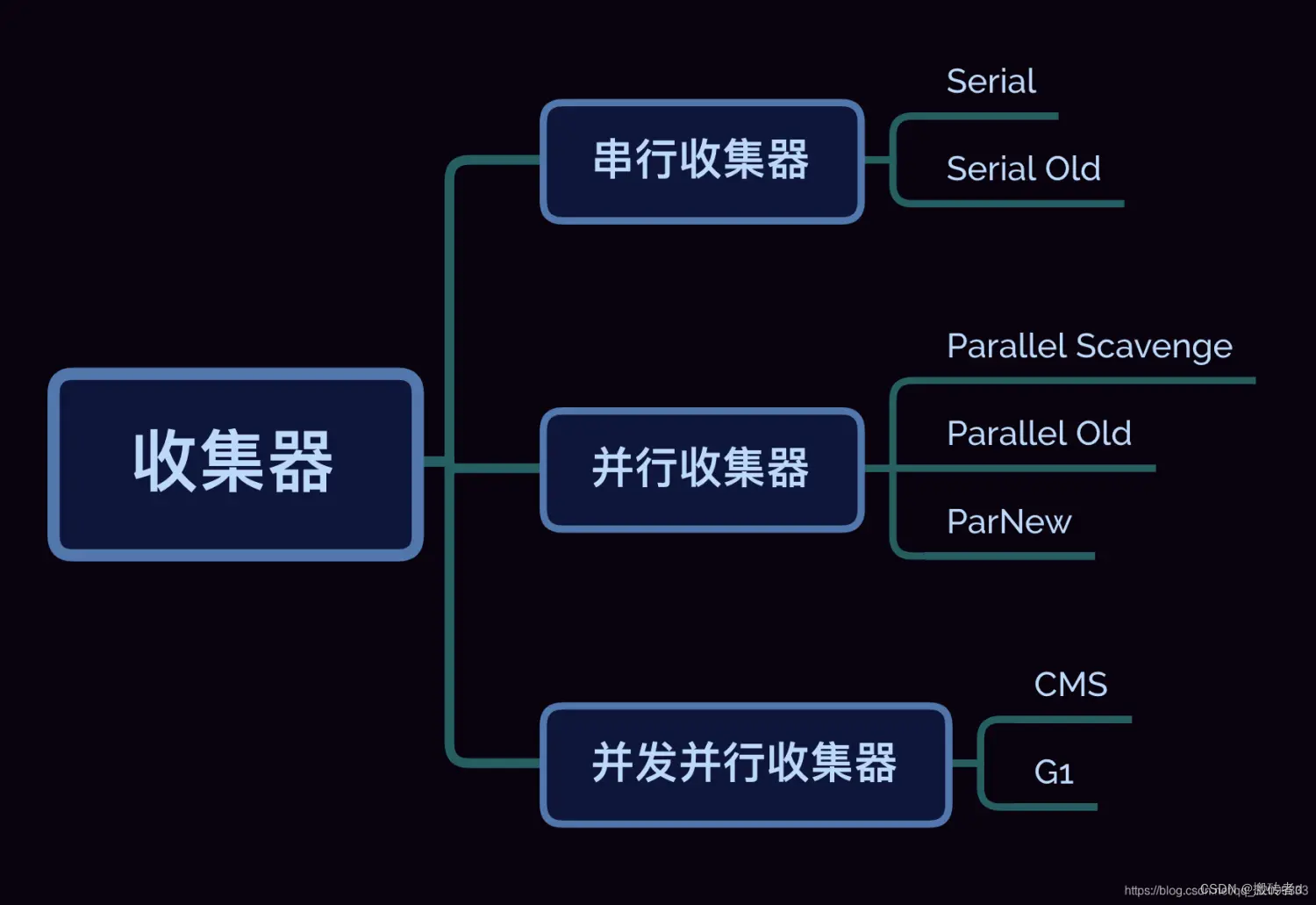
Serie : colección de subproceso único, subprocesos de usuario en pausa.
Paralelo : colección de subprocesos múltiples, subprocesos de usuario en pausa.
Simultaneidad : los subprocesos de usuario y los subprocesos de GC se ejecutan simultáneamente.
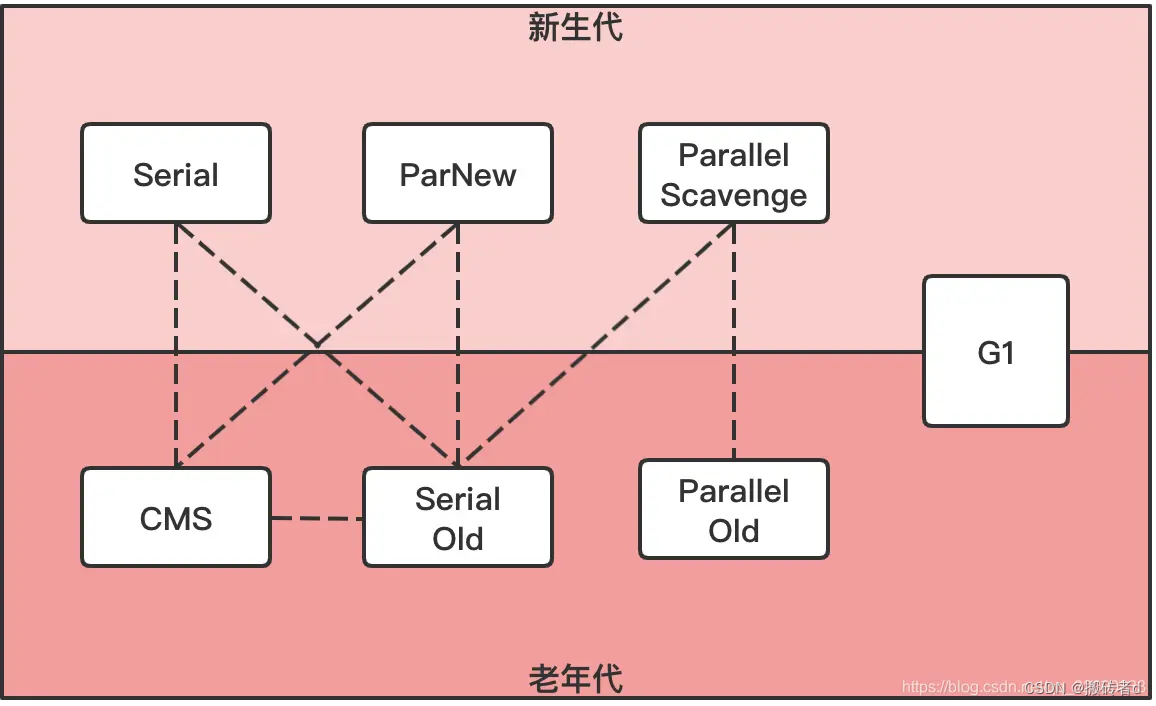
Como se mencionó anteriormente, la mayoría de los recolectores de elementos no utilizados de JVM siguen la teoría de la "recolección generacional”. Distintos recolectores de elementos no utilizados reclaman diferentes áreas de memoria. En la mayoría de los casos, JVM requiere dos recolectores de elementos no utilizados para trabajar juntos. Las líneas punteadas en la siguiente figura representan que los dos recolectores pueden usarse juntos.
4.1 Colector de nueva generación
4.1.1 Serie
El recolector de elementos no utilizados más básico y más antiguo, que utiliza el algoritmo de copia de marca, solo inicia un subproceso para completar la recolección de elementos no utilizados y todos los subprocesos de usuario (STW) se suspenderán durante el reciclaje.
Use -XX:+UseSerialGCparámetros para habilitar el recopilador Serial. Dado que es una colección de un solo subproceso, el rango de aplicación de Serial es muy limitado:
- La aplicación es muy liviana y el espacio de almacenamiento dinámico es inferior a 100 MB.
- Los recursos de la CPU del servidor son escasos.
4.1.2 Barrido paralelo
Un colector de generación joven de subprocesos múltiples que utiliza el algoritmo de marca-copia.
Habilitado por parámetros -XX:+UseParallelGC, ParallelGC se caracteriza por estar muy preocupado por el rendimiento del sistema.Proporciona dos parámetros para permitir que el usuario controle el rendimiento del sistema:
- -XX:MaxGCPauseMillis: establezca el tiempo máximo de pausa para la recolección de elementos no utilizados. Debe ser un número entero mayor que 0. ParallelGC trabajará para lograr este objetivo. Si este valor es demasiado pequeño, es posible que ParallelGC no pueda garantizarlo. Si el usuario desea que el tiempo de pausa del GC sea muy corto, ParallelGC intentará reducir el espacio del almacenamiento dinámico, ya que lleva menos tiempo recuperar un almacenamiento dinámico más pequeño que recuperar un almacenamiento dinámico más grande, pero esto activará el GC con más frecuencia, lo que reducirá el tiempo del sistema. rendimiento
- -XX:GCTimeRatio: establece el tamaño del rendimiento, su valor es un número entero de 0 a 100. Suponiendo que GCTimeRatio sea n, entonces ParallelGC no dedicará más del 100 %
1/(1+n)del tiempo a la recolección de elementos no utilizados. El valor predeterminado es 19, lo que significa que ParallelGC no dedicará más del 5 % del tiempo a la recopilación de elementos no utilizados.
ParallelGC es el recolector de elementos no utilizados predeterminado de JDK8. Es un recolector de elementos no utilizados que prioriza el rendimiento. Los usuarios pueden establecer el tiempo máximo de pausa y el rendimiento de GC mediante -XX:MaxGCPauseMillisy . -XX:GCTimeRatioPero estos dos parámetros son contradictorios: un tiempo de pausa menor significa que el GC necesita reciclar con más frecuencia, lo que aumenta el tiempo total de reciclaje del GC y conduce a una disminución en el rendimiento.
4.1.3 ParNuevo
ParNew también es un recolector de basura de nueva generación con subprocesos múltiples que utiliza el algoritmo de marca-copia. Su estrategia de reciclaje, algoritmo y parámetros son los mismos que Serial, pero simplemente cambia de hilo único a hilo múltiple. Nació solo para cooperar con el colector CMS. CMS es un colector de la generación anterior, pero Parallel Scavengeno puede funcionar con CMS. Serial se recicla en serie y la eficiencia es demasiado baja, por lo que nació ParNew.
Use parámetros -XX:+UseParNewGCpara habilitar, pero este parámetro se eliminó en versiones posteriores a JDK9, porque JDK9 tiene como valor predeterminado el recopilador G1, CMS se reemplazó y ParNew nació para cooperar con CMS, CMS se abandonó y ParNew no tiene valor. .
4.2 Colector de vieja generación
4.2.1 Serie antigua
Usando el algoritmo de marcado, como Serial, un recolector de basura exclusivo de un solo hilo para la vejez. El espacio de la generación anterior suele ser más grande que el de la nueva generación, y el algoritmo de clasificación de marcas necesita mover objetos durante el proceso de reciclaje para evitar la fragmentación de la memoria, por lo que la recopilación de la generación anterior requiere más tiempo que la nueva. generación.
Como el recolector de elementos no utilizados más antiguo, Serial Old tiene otra ventaja, es decir, se puede usar junto con la mayoría de los recolectores de elementos no utilizados de nueva generación, y también se puede usar como un recolector de respaldo para fallas concurrentes de CMS.
Use el parámetro -XX:+UseSerialGCpara habilitar, la nueva generación y la generación anterior usarán el colector en serie. Al igual que Serial, a menos que su aplicación sea muy liviana o los recursos de la CPU sean muy limitados, no se recomienda usar este recopilador.
4.2.2 Paralelo Antiguo
ParallelOldGC es un recolector de basura exclusivo paralelo de subprocesos múltiples para la vejez. Al igual que Parallel Scavenge, es un recolector de rendimiento primero. Parallel Old nació para cooperar con Parallel Scavenge.
ParallelOldGC utiliza el algoritmo de marcado, que está habilitado por parámetros -XX:+UseParallelOldGC. Los parámetros -XX:ParallelGCThreads=npueden establecer la cantidad de subprocesos que se habilitarán durante la recolección de elementos no utilizados. También es el recolector de generación anterior predeterminado de JDK8.
4.2.3 CMS
CMS (Barrido de marcas concurrente) es un hito en el recolector de basura, ¿por qué dices eso? Porque antes, los subprocesos de GC y los subprocesos de usuario no podían funcionar al mismo tiempo, incluso Parallel Scavenge, son solo varios subprocesos para reciclar en paralelo durante GC, todo el proceso de GC aún tiene que suspender los subprocesos de usuario, es decir, detener el Mundo. La consecuencia de esto es que el programa Java se congelará por un tiempo después de ejecutarse por un período de tiempo, reduciendo la velocidad de respuesta de la aplicación, lo cual es inaceptable para los programas que se ejecutan en el servidor.
¿Por qué se deben suspender los subprocesos de los usuarios durante la GC?
En primer lugar, si el subproceso del usuario no se suspende, significa que se seguirá generando basura durante el período y nunca se limpiará.
En segundo lugar, la ejecución de subprocesos de usuario conducirá inevitablemente a cambios en la relación de referencia de los objetos, lo que conducirá a dos situaciones: etiqueta faltante y etiqueta incorrecta.
1. Falta la etiqueta: originalmente no era basura, pero durante el proceso de GC, el subproceso del usuario modificó su relación de referencia, lo que hizo que GC Roots fuera inalcanzable y se convirtiera en basura. Esta situación es mejor, no se genera más que basura flotante y el GC la limpiará la próxima vez.
2. Etiquetado incorrecto: originalmente era basura, pero durante el proceso de GC, el subproceso del usuario redirigió la referencia a él. En este momento, si el GC lo recicla, causará un error de programa.
Para lograr la recolección concurrente, la implementación de CMS es mucho más complicada que los varios recolectores de basura presentados anteriormente.Todo el proceso de GC se puede dividir aproximadamente en las siguientes cuatro etapas:
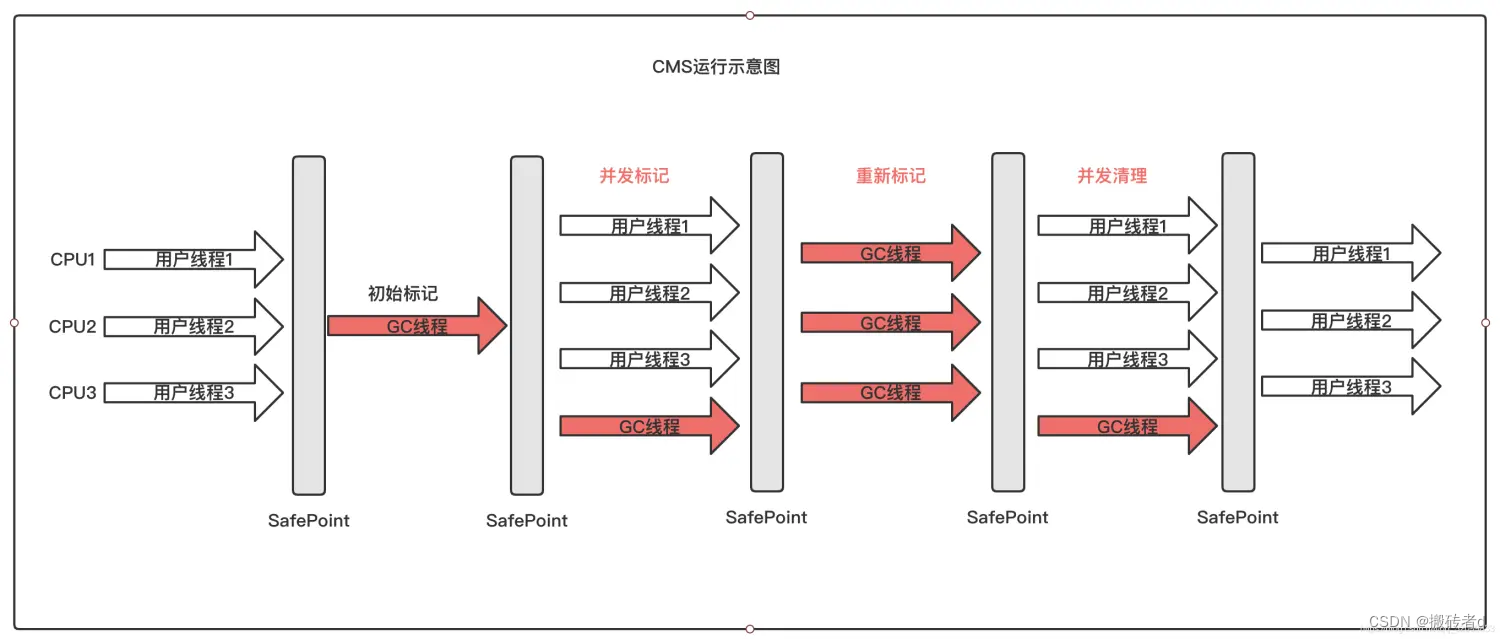
1. Marca inicial
La marca inicial es solo para marcar los objetos con los que GC Roots puede relacionarse directamente, lo cual es muy rápido. El proceso de marcado inicial necesita activar STW, pero este proceso es muy rápido y el consumo de tiempo del marcado inicial no disminuirá debido al aumento del espacio de almacenamiento dinámico, es controlable, por lo que la breve pausa causada por este proceso puede ser ignorado
2. Marcaje concurrente
El marcado simultáneo consiste en atravesar profundamente los objetos marcados inicialmente y utilizar estos objetos como raíces para recorrer todo el gráfico de objetos. Este proceso lleva mucho tiempo y el tiempo de marcado será más largo a medida que aumente el espacio de almacenamiento dinámico. Afortunadamente, este proceso no activará STW, los subprocesos de usuario aún pueden funcionar y el programa aún puede responder, pero el rendimiento del programa se verá un poco afectado. Debido a que el subproceso GC ocupará una cierta cantidad de CPU y recursos del sistema, es más sensible al procesador. La cantidad de subprocesos de GC habilitados por CMS de manera predeterminada es: (cantidad de núcleos de CPU + 3) / 4. Cuando la cantidad de núcleos de CPU supera los 4, los subprocesos de GC ocuparán menos del 25 % de los recursos de CPU. menos de 4, los subprocesos de GC no El impacto del programa será muy grande, lo que resultará en una disminución significativa en el rendimiento del programa.
3. Reetiquetar
Dado que el subproceso del usuario todavía se está ejecutando durante el marcado simultáneo, significa que durante el marcado simultáneo, el subproceso del usuario puede cambiar la relación de referencia entre los objetos y pueden ocurrir dos situaciones: una es que el objeto que no se pudo reciclar ahora se puede reciclar , el otro es un objeto que podría haber sido reciclado, pero no se puede reciclar ahora. Para estos dos casos, CMS necesita suspender el hilo del usuario y realizar un comentario.
4. Limpieza simultánea
Una vez completada la observación, se puede limpiar al mismo tiempo. Este proceso también lleva mucho tiempo y los gastos generales de limpieza aumentarán a medida que aumente el espacio de almacenamiento dinámico. Afortunadamente, este proceso no requiere STW. Los subprocesos de usuario aún pueden ejecutarse normalmente y el programa no se congelará. Sin embargo, al igual que el marcado simultáneo, el subproceso GC aún ocupa una cierta cantidad de recursos de la CPU y del sistema durante la limpieza, lo que reducirá el rendimiento. del programa. .
CMS fue pionero en la recopilación concurrente, lo que hace posible que los subprocesos de usuario y los subprocesos de GC funcionen simultáneamente, pero las desventajas también son obvias:
1. Sensible al procesador
En la fase simultánea de marcado y limpieza, aunque CMS no activará STW, el marcado y la limpieza requieren la intervención de subprocesos de GC.Los subprocesos de GC ocuparán una cierta cantidad de recursos de CPU, lo que provocará una disminución en el rendimiento del programa y una respuesta más lenta del programa. Es mejor si hay más núcleos de CPU.Cuando los recursos de la CPU son escasos, los subprocesos de GC tienen un gran impacto en el rendimiento del programa.
2. Basura flotante
En la fase de limpieza concurrente, dado que el subproceso del usuario aún se está ejecutando, la basura creada por el subproceso del usuario durante este período se denomina "basura flotante". El GC no puede limpiar la basura flotante esta vez, y solo puede limpiarla en la próxima GC.
3. Fallo de concurrencia
Debido a la existencia de basura flotante, el CMS debe reservar algo de espacio para cargar esta basura recién generada. CMS no puede esperar hasta que el área antigua esté llena para limpiarla como el recopilador Serial Old. En JDK5, CMS se activará cuando se utilice el 68 % del espacio en la generación anterior y el 32 % del espacio se reserve para cargar basura flotante. Esta es una configuración relativamente conservadora. Si la generación anterior no crece demasiado rápido en la referencia real, puede -XX:CMSInitiatingOccupancyFractionaumentar este valor adecuadamente a través de parámetros. En JDK6, el umbral de activación se eleva al 92%, dejando solo el 8% del espacio reservado para la basura flotante.
Si la memoria reservada por CMS no puede acomodar la basura flotante, dará lugar a una "falla de concurrencia". En este momento, la JVM debe activar el plan de preparación y permitir que el recopilador Serial Old recupere el área Old, y el tiempo de pausa se alarga. .
4. Fragmentación de la memoria
Dado que CMS usa el algoritmo "marcar borrado", significa que se generará una gran cantidad de fragmentos de memoria en el montón después de que se complete la limpieza. La fragmentación excesiva de la memoria puede causar muchos problemas, uno de los cuales es que es difícil asignar memoria para objetos grandes. La consecuencia es que todavía hay mucho espacio de almacenamiento dinámico, pero no se puede encontrar un área de memoria continua para asignar memoria para objetos grandes, y se debe activar un GC completo, por lo que el tiempo de pausa del GC será más largo.
En respuesta a esta situación, CMS ofrece una solución alternativa. A través de -XX:CMSFullGCsBeforeCompactionla configuración de parámetros, cuando CMS activa N veces Full GC debido a la fragmentación de la memoria, la fragmentación de la memoria se resolverá antes de ingresar Full GC la próxima vez. Sin embargo, este parámetro se abandona en JDK9 utilizado.
4.2.3.1 Algoritmo de marcado de tres colores
Después de presentar el recolector de elementos no utilizados de CMS, debemos comprender por qué los subprocesos de GC de CMS pueden funcionar con subprocesos de usuario.
La JVM juzga si un objeto se puede reciclar, y la mayoría de ellos utilizan el algoritmo de "análisis de accesibilidad".
Comience a atravesar desde GC Roots, los alcanzables sobreviven y los inalcanzables se reciclan.
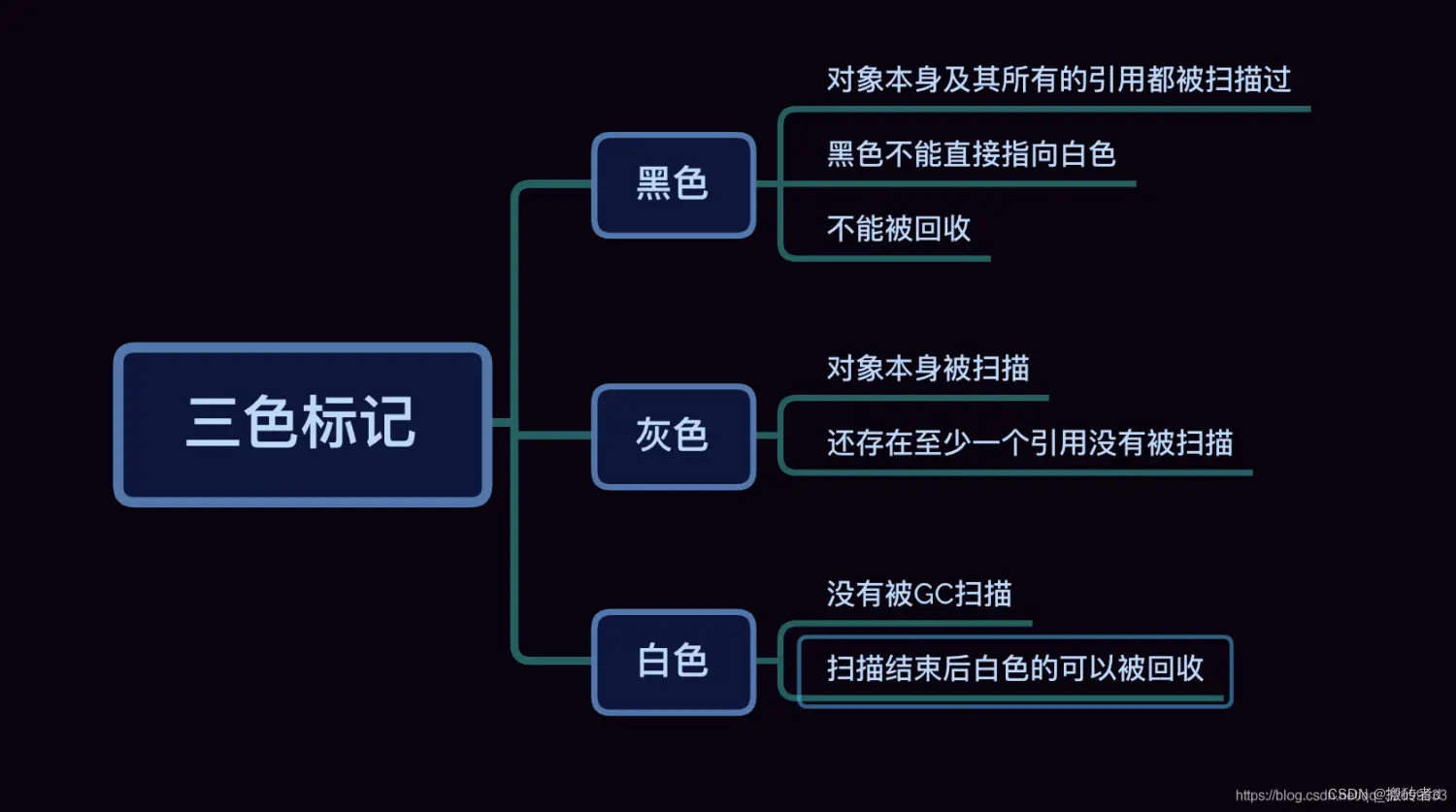
CMS marca objetos en tres colores:
el proceso de marcado es más o menos el siguiente:
- Al principio, todos los objetos son blancos y no se accede a ellos.
- Ponga en gris los objetos directamente asociados con GC Roots.
- Al atravesar todas las referencias del objeto gris, el propio objeto gris se establece en negro y la referencia se establece en gris.
- Repita el paso 3 hasta que no haya más objetos grises.
- Al final, los objetos negros sobreviven y los objetos blancos se reciclan.
La premisa de la correcta ejecución de este proceso es que ningún otro hilo cambie la relación de referencia entre los objetos, sin embargo, durante el proceso de marcaje concurrente, los hilos de usuario siguen ejecutándose, por lo que habrá casos de faltantes y marcados erróneos.
Marca de fuga
Supongamos que el GC ya está atravesando el objeto B, y en este momento el subproceso del usuario ejecuta la operación AB=null, cortando la referencia de A a B.
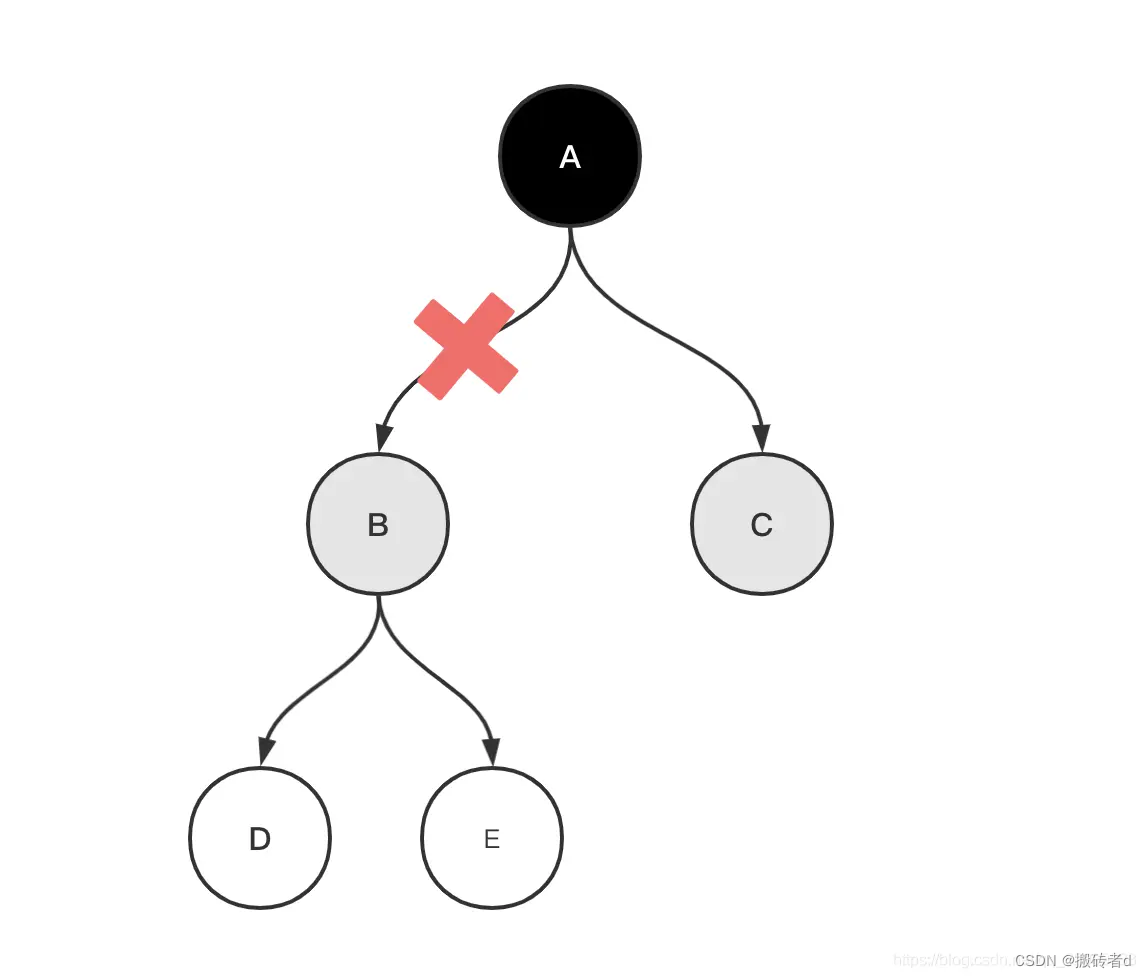
Originalmente, después de la ejecución A.B=null, B, D y E se pueden reciclar, pero debido a que B se ha vuelto gris, aún se considerará como un objeto sobreviviente y continuará atravesando.
El resultado final es que esta ronda de GC no reciclará B, D y E, y se recogerán en el siguiente GC, que también forma parte de la basura flotante.
De hecho, este problema aún se puede resolver con una "barrera de escritura". Simplemente agregue una barrera de escritura cuando A escribe B, registre los registros que B está cortado y márquelos en blanco cuando vuelva a marcar.
Etiquetado incorrecto
Suponiendo que el subproceso de GC ha atravesado a B, el subproceso de usuario realiza las siguientes operaciones:
B.D=null;//B到D的引用被切断
A.xx=D;//A到D的引用被建立
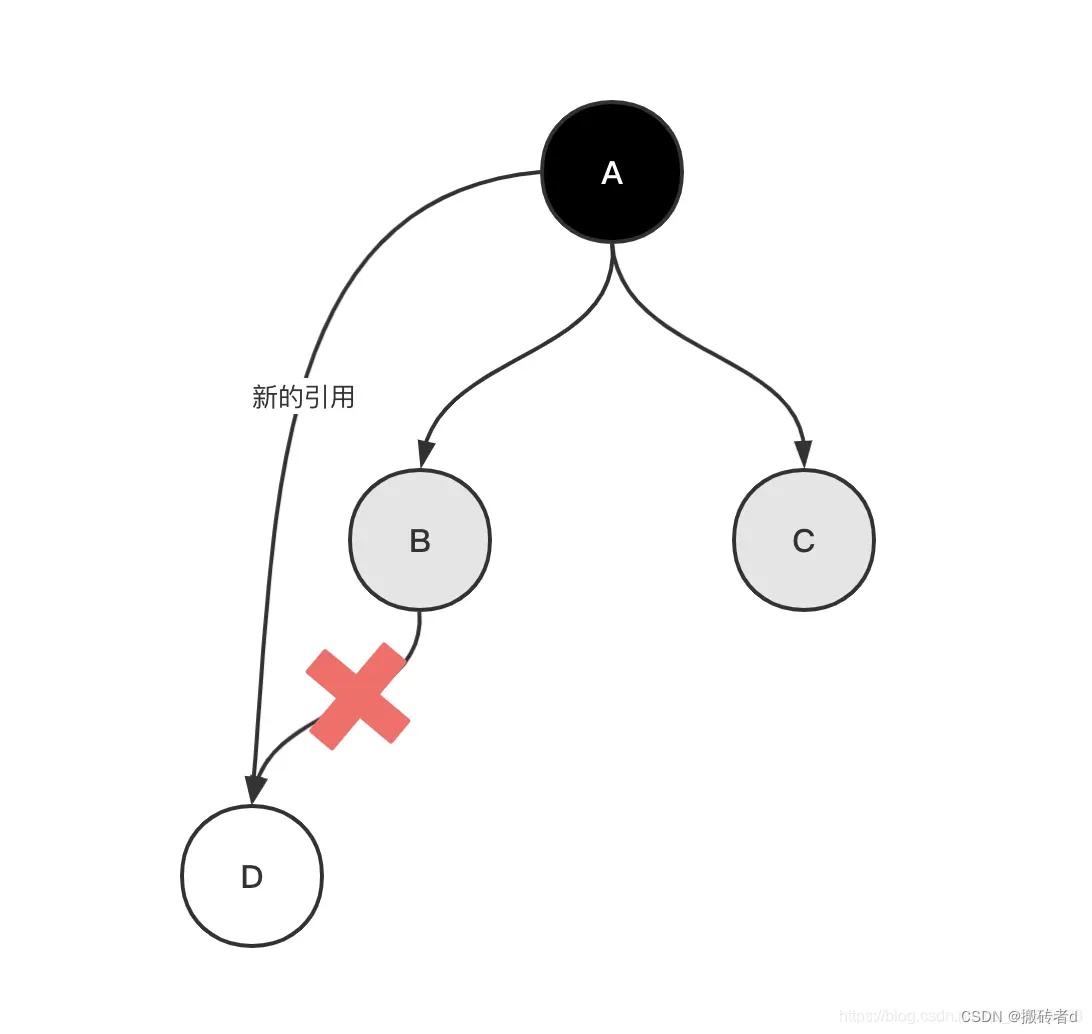
Se corta la referencia de B a D y se establece la referencia de A a D.
En este momento, el hilo GC sigue funcionando, porque B ya no hace referencia a D, aunque A vuelve a hacer referencia a D, pero debido a que A se ha marcado como negro, GC no volverá a atravesar A, por lo que D se marcará como blanco, y finalmente tratado como basura Reciclar.
Se puede ver que el resultado de un etiquetado incorrecto es mucho más grave que la fuga de tablas. La basura flotante puede ser limpiada por GC la próxima vez, y el reciclaje de objetos que no deberían reciclarse provocará errores en el funcionamiento del programa.
El etiquetado incorrecto solo ocurrirá si se cumplen las dos condiciones siguientes:
- Las referencias de gris a blanco están rotas.
- Se establece una referencia de negro a blanco.
Siempre que se rompa alguna condición, se puede resolver el problema del etiquetado incorrecto.
Instantánea original y actualización incremental
Lo que rompe la instantánea original es la primera condición: cuando se rompe la referencia del objeto gris que apunta al objeto blanco, se registra esta relación de referencia. Cuando finalice el escaneo, tome estos objetos grises como la raíz y vuelva a escanear. Es equivalente a escanear de acuerdo con la instantánea del gráfico del objeto en el momento en que se inicia el escaneo sin importar si la relación de referencia se elimina o no.
Lo que rompe la actualización incremental es la segunda condición: cuando se establece una referencia de negro a blanco, se registra la nueva relación de referencia y, una vez que se completa el escaneo, el objeto negro en estos registros se usa como la raíz para volver a escanear. Es equivalente a que una vez que un objeto negro establece una referencia a un objeto blanco, se convertirá en un objeto gris.
La solución adoptada por CMS es: barrera de escritura + actualización incremental para lograr, rompiendo la segunda condición.
Cuando se establece una referencia de blanco a negro, la relación de referencia se registra a través de una barrera de escritura y, una vez que se completa el escaneo, el objeto negro en la relación de referencia se usa como raíz para volver a escanear.
El pseudocódigo es más o menos el siguiente:
class A{
private D d;
public void setD(D d) {
writeBarrier(d);// 插入一条写屏障
this.d = d;
}
private void writeBarrier(D d){
// 将A -> D的引用关系记录下来,后续重新扫描
}
}
4.3 Colector Híbrido
4.3.1 G1
El nombre completo de G1 es "Garbage First" recolector de basura primero. JDK7 se usa oficialmente y JDK9 se usa de forma predeterminada. Parece que reemplaza al recolector de CMS.
Dado que va a reemplazar a CMS, no hay duda de que G1 también es un recolector de basura concurrente y paralelo. Los subprocesos de usuario y los subprocesos de GC pueden funcionar al mismo tiempo, y el enfoque también está en el tiempo de respuesta de la aplicación.
Uno de los mayores cambios en G1 es que es solo una generación lógica, y la estructura física ya no es generacional. Divide todo el montón de Java en varias regiones de diferentes tamaños. Cada región puede jugar en el área Eden, el área Survivor o el espacio de la generación anterior según sea necesario. G1 puede usar diferentes estrategias para tratar con regiones que juegan diferentes roles.
Para todos los recolectores de elementos no utilizados anteriores a G1, el ámbito de recuperación es la nueva generación completa (GC menor), la generación anterior completa (GC principal) o todo el almacenamiento dinámico de Java (GC completo). Pero G1 saltó fuera de esta jaula. Puede formar un Conjunto de Recolección (CSet para abreviar) para que cualquier parte del montón se recicle. El estándar de medición ya no es a qué generación pertenece, sino qué Región tiene la mayor cantidad de basura y elige el valor de reciclaje Se recupera la región más alta, que también es el origen del nombre "Garbage First".
Aunque G1 aún conserva el concepto de generación, la nueva generación y la vieja generación ya no son dos áreas de memoria continuas y fijas, sino que están compuestas por una serie de Regiones, y cada GC, la nueva generación y la vieja generación El tamaño del espacio de la vieja generación se ajustará dinámicamente. La razón por la que G1 puede controlar el tiempo de pausa de GC y establecer un modelo de tiempo de pausa predecible es que considera a la Región como la unidad más pequeña de una única recuperación, y el espacio de memoria recuperado cada vez es un múltiplo entero del tamaño de la Región. , para que pueda evitarse.La recolección de elementos no utilizados se realiza en todo el montón de Java.
G1 rastreará la cantidad de basura en cada región, calculará el valor de reciclaje de cada región, mantendrá una lista de prioridades en segundo plano y luego dará prioridad al reciclaje de la región "más basura" de acuerdo con el tiempo de pausa de GC establecido por el usuario , para garantizar que G1 pueda reclamar tanta memoria como esté disponible en un período de tiempo limitado.
El ciclo completo de reciclaje de G1 se puede dividir aproximadamente en las siguientes etapas:
-
La memoria en el área Eden está agotada, lo que hace que el GC de nueva generación comience a reciclar el área Eden y el área Survivor. Después del GC de nueva generación, el área Eden se borrará, al menos un objeto se mantendrá en el área Survivor y los objetos restantes se limpiarán o ascenderán a la generación anterior. Durante este proceso, se puede ajustar el tamaño de la generación joven.
-
Ciclo de marcado concurrente
2.1 Marcado inicial : solo los objetos de marcado directamente relacionados con GC Roots estarán acompañados por un GC de nueva generación y causarán STW.
2.2 Escaneo del área raíz : el GC de nueva generación activado durante el marcado inicial limpiará el área Eden y los objetos sobrevivientes se moverán al área Survivor. En este momento, es necesario escanear el área antigua directamente accesible desde el área Survivor. y marcar estos objetos Este proceso se puede ejecutar simultáneamente.
2.3 Marcado simultáneo : similar a CMS, escaneará y encontrará objetos sobrevivientes en todo el montón y los marcará, sin activar STW.
2.4 Remarcado: active STW y corrija las referencias entre objetos debido a la ejecución continua de subprocesos de usuario durante el marcado simultáneo.
2.5 Limpieza exclusiva: active STW, calcule el valor de recuperación de cada Región, ordene las Regiones e identifique las áreas que se pueden mezclar y reciclar.
2.6 Limpieza simultánea: identifique y limpie regiones completamente inactivas sin causar pausas. -
Reciclado mixto: En la fase de limpieza concurrente del ciclo de marcaje concurrente, aunque G1 también recupera algo de espacio, la proporción sigue siendo bastante baja. Pero después de eso, G1 ha sabido claramente el valor de recuperación de cada Región. En la fase de recogida mixta, G1 dará prioridad al reciclaje de la Región con más basura, estas Regiones incluyen tanto la nueva generación como la antigua, por lo que se denominan “recogida mixta”. Los objetos supervivientes en la Región limpiada se moverán a otras Regiones, lo que también evita la fragmentación de la memoria.
Al igual que CMS, debido a que los subprocesos de usuario aún se ejecutan durante el reciclaje simultáneo, es decir, se asigna memoria, por lo que si la velocidad de recuperación no puede mantenerse al día con la velocidad de asignación de memoria, G1 también activará un GC completo cuando sea necesario para obtener más memoria disponible.
Use los parámetros -XX:+UseG1GCpara abrir el colector G1 -XX:MaxGCPauseMillispara establecer el tiempo de pausa máximo objetivo, y G1 trabajará para lograr este objetivo. Si el tiempo de pausa del GC excede el tiempo objetivo, G1 intentará ajustar la proporción de la nueva generación a la generación anterior, el tamaño del montón y promoción Una serie de parámetros como la edad en un intento de lograr objetivos preestablecidos.
-XX:ParallelGCThreadsSe usa para establecer el número de subprocesos de GC durante la recopilación paralela
-XX:InitiatingHeapOccupancyPercenty se usa para especificar cuánto el uso de todo el montón de Java activará la ejecución del ciclo de marcado simultáneo. El valor predeterminado es 45.
4.3.2 ZGC orientado al futuro
ZGC es un recolector de elementos no utilizados de baja latencia que se agregó en JDK 11. Su objetivo es controlar el tiempo de pausa de GC en cualquier tamaño de memoria de almacenamiento dinámico con la premisa de que tiene el menor impacto posible en el rendimiento en diez milisegundos.
ZGC está orientado a montones supergrandes y admite un espacio de montón máximo de 4 TB. Al igual que G1, también adopta el formato de diseño de memoria regional.
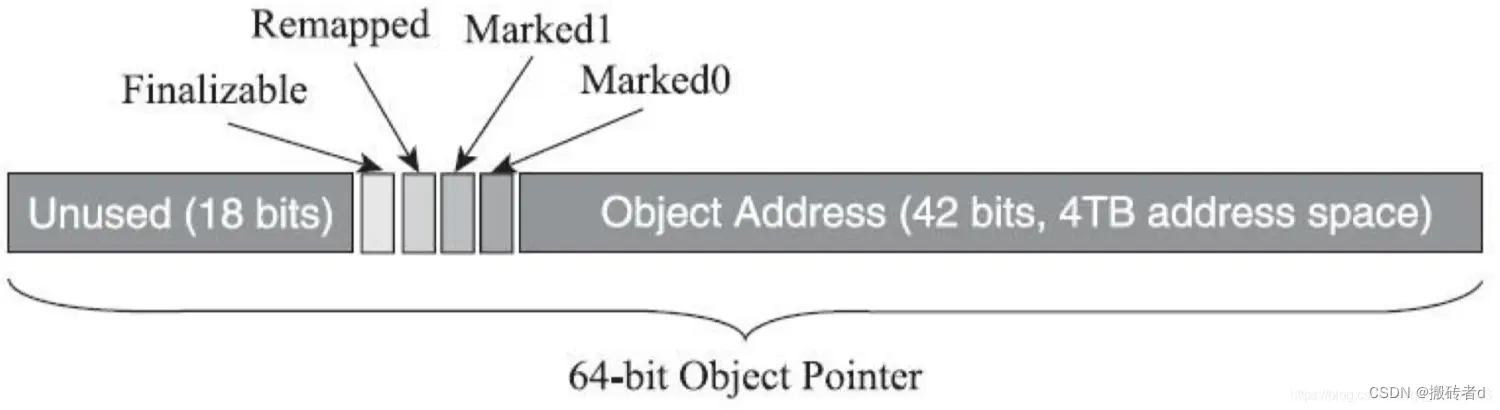
Una de las características más importantes de ZGC es que utiliza la tecnología de punteros de colores para marcar objetos. En el pasado, si la JVM necesita almacenar algunos datos adicionales en el objeto que solo utiliza el GC o la propia JVM (como la edad del GC, la identificación del subproceso sesgado, el código hash), generalmente agrega campos adicionales al encabezado del objeto. del objeto a Grabar. ZGC es potente y registra directamente la información de la etiqueta en el puntero de referencia del objeto.
¿Qué es el puntero de color? ¿Por qué el puntero de la referencia del objeto en sí puede almacenar datos?
En un sistema de 64 bits, el tamaño de memoria teóricamente accesible es 2 elevado a 64 bytes, es decir, 16 EB. Pero, de hecho, una cantidad tan grande de memoria está lejos de ser utilizada en la actualidad, por lo que, según las consideraciones de rendimiento y costo, tanto la CPU como el sistema operativo impondrán sus propias limitaciones. Por ejemplo, la arquitectura AMD64 solo admite un bus de direcciones de 54 bits (4 PB), Linux solo admite un bus de direcciones físicas de 46 bits (64 TB) y Windows solo admite un bus de direcciones físicas de 44 bits (16 TB).
En el sistema Linux, los 18 bits superiores no se pueden usar para el direccionamiento y los 46 bits restantes pueden admitir un tamaño de memoria máximo de 64 TB. De hecho, el tamaño de la memoria de 64 TB supera con creces las necesidades del servidor en la actualidad. Entonces, ZGC se centró en el ancho restante del puntero de 46 bits y extrajo sus 4 bits superiores para almacenar información de cuatro banderas. A través de estas banderas, la JVM puede ver directamente el estado de la marca de tres colores de su objeto referenciado desde el puntero, si ha ingresado al conjunto de reasignación (es decir, si se ha movido) y si solo se puede acceder a través de finalizar ( ) método. Esto da como resultado solo 42 bits del bus de direcciones físicas que la JVM puede usar, es decir, el espacio de memoria máximo que puede administrar ZGC es 2 elevado a 42 bytes, o 4 TB.
En la actualidad, ZGC aún se encuentra en etapa experimental y no hay mucha información que se pueda encontrar, la ordenaré y actualizaré más adelante.