Hoy en día, Redis se está volviendo cada vez más popular y se usa en casi muchos proyectos. Cuando usas Redis, ¿alguna vez has pensado en cómo Redis brinda servicios de manera estable y de alto rendimiento?
-
El escenario donde uso Redis es muy simple, ¿hay algún problema si solo uso la versión independiente de Redis?
-
¿Qué debo hacer si mi Redis falla y mis datos se pierden? ¿Cómo puedo asegurarme de que mis aplicaciones comerciales no se verán afectadas?
-
¿Por qué necesita un clúster maestro-esclavo? ¿Cuáles son sus ventajas?
-
¿Qué es un clúster fragmentado? ¿Realmente necesito un clúster fragmentado?
-
...
Si ya tiene algún conocimiento de Redis, debe haber oído hablar de los conceptos de " persistencia de datos, replicación maestro-esclavo, centinelas y clústeres de fragmentos ". ¿Cuáles son las diferencias y conexiones entre ellos?
Si tiene esas dudas, en este artículo lo llevaré del 0 al 1, y luego del 1 al N, y lo guiaré paso a paso para construir un clúster de Redis estable y de alto rendimiento.
En este proceso, puede aprender qué soluciones de optimización ha adoptado Redis para lograr estabilidad y alto rendimiento, y por qué.
Una vez que haya dominado estos principios, podrá hacerlo "con facilidad" al usar Redis.
Comience con lo más simple: Redis independiente
Primero, comenzamos con el escenario más simple.
Supongamos que tiene una aplicación empresarial y necesita introducir Redis para mejorar el rendimiento de la aplicación. En este momento, puede optar por implementar una versión independiente de Redis, como esta:

Esta arquitectura es muy simple. Su aplicación comercial puede usar Redis como caché, consultar datos de MySQL y luego escribirlos en Redis, y luego la aplicación comercial lee los datos de Redis, porque los datos de Redis se almacenan en la memoria, por lo que esta velocidad es rápido.
Si su volumen de negocios no es grande, entonces dicho modelo arquitectónico puede satisfacer básicamente sus necesidades. ¿No es sencillo?
A medida que pasa el tiempo, el volumen de su negocio se desarrolla gradualmente y cada vez se almacenan más datos en Redis. En este momento, sus aplicaciones comerciales dependen cada vez más de Redis.
De repente, un día, su Redis deja de funcionar por algún motivo. En este momento, todo el tráfico de su negocio llegará al backend MySQL, y la presión sobre MySQL aumentará considerablemente. En casos severos, incluso abrumará a MySQL.
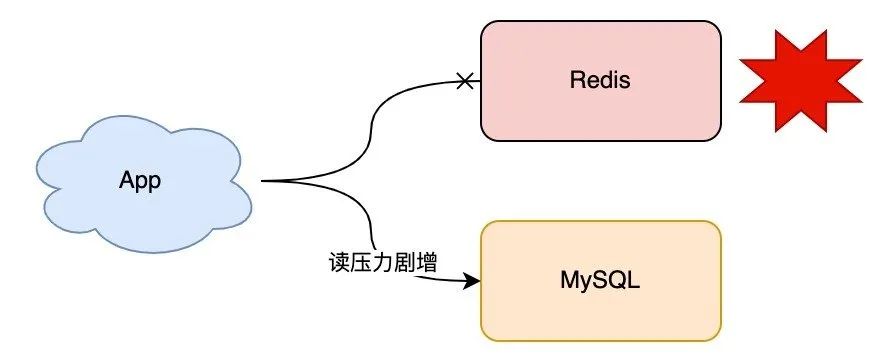
¿Qué debes hacer en este momento?
Supongo que su solución debe ser reiniciar Redis rápidamente para que pueda continuar brindando servicios.
Sin embargo, debido a que los datos en Redis estaban en la memoria antes, incluso si reinicia Redis ahora, los datos anteriores se perderán (suponiendo que la persistencia no esté habilitada). Aunque Redis puede funcionar con normalidad después de reiniciar, debido a que no hay datos en Redis, el tráfico comercial aún llegará al back-end de MySQL, y la presión sobre MySQL sigue siendo grande.
¿Hay alguna buena manera de resolver este problema?
Dado que Redis solo almacena datos en la memoria, ¿puede también escribir una copia de estos datos en el disco?
Si se utiliza este método, cuando se reinicia Redis, rápidamente " restauramos " los datos en el disco a la memoria, para que pueda continuar brindando servicios con normalidad.
Sí, esta es una buena solución. El proceso de escribir datos de memoria en el disco es "persistencia de datos".
Persistencia de datos: Esté preparado
Ahora, la persistencia de datos de Redis prevista se ve así:

Sin embargo, ¿qué se debe hacer específicamente para la persistencia de datos?
Supongo que la solución más sencilla que se te ocurre es que cada vez que Redis realiza una operación de escritura, además de escribir en la memoria, también escribe una copia en el disco, así:

Sí, esta es la solución más simple y directa.
Pero si lo piensa detenidamente, hay un problema con esta solución: cada operación de escritura del cliente necesita escribir tanto en la memoria como en el disco, ¡y el tiempo que lleva escribir el disco es definitivamente mucho más lento que escribir la memoria! Esto inevitablemente afectará el rendimiento de Redis.
¿Cómo eludir este problema?
En este momento necesitamos analizar los detalles de escritura en disco.
Todos sabemos que en realidad hay dos pasos para escribir datos de memoria en el disco:
-
PageCache (escribir) para que los programas escriban archivos
-
Vaciar PageCache al disco (fsync)
Específicamente, se ve así:

La idea más aproximada para la persistencia de datos es como se mencionó anteriormente. Después de escribir en la memoria de Redis, escriba en el disco PageCache + fsync sincrónicamente. Por supuesto, esto debe ser porque el disco ralentiza toda la velocidad de escritura.
¿Cómo optimizar? También es muy simple, podemos hacer esto: Redis escribe la memoria por el hilo principal y devuelve el resultado al cliente después de escribir la memoria, y luego Redis usa "otro hilo" para escribir en el disco, de modo que el El subproceso principal puede evitar escribir en el disco. Impacto en el rendimiento.

Este esquema de persistencia es en realidad el Redis AOF (Append Only File) que escuchamos a menudo.
La persistencia de Redis AOF proporciona tres mecanismos de cepillado:
-
appendfsync always: el subproceso principal sincroniza fsync
-
appendfsync no: por OS fsync
-
appendfsync everysec: subproceso de fondo fsync cada 1 segundo
Después de resolver la persistencia de los datos en tiempo real, nos enfrentaremos a otro problema. Los datos se escriben en AOF en tiempo real. A medida que pasa el tiempo, el archivo AOF se hará cada vez más grande, por lo que será muy lento al usar AOF para restaurar . ¿Qué tengo que hacer?
Redis brinda de manera considerada la solución de reescritura de AOF, comúnmente conocida como "adelgazamiento" de AOF, como su nombre lo indica, es para comprimir el volumen de AOF.
Debido a que AOF registra cada comando de escritura, como ejecutar set k1 v1, set k1 v2, de hecho, solo nos importa la versión final v2 de los datos. La reescritura de AOF aprovecha esta función. Cuando el volumen de AOF se vuelve cada vez más grande (sobre el umbral establecido), Redis reescribirá periódicamente un nuevo AOF. Este nuevo AOF solo registra la versión final de los datos.

Esto comprime el volumen AOF.
Además, ¿podemos cambiar el ángulo y pensar en otras formas de conservar los datos?
En este momento, debe considerar los escenarios de uso de Redis.
Recuerde, cuando usamos Redis, ¿para qué escenario lo usamos generalmente?
Sí, caché.
El uso de Redis como caché significa que, aunque la cantidad total de datos no se almacena en Redis, para los datos que no están en el caché, nuestras aplicaciones comerciales aún pueden obtener resultados consultando la base de datos de back-end, pero la velocidad de consulta de la parte posterior -Los datos finales serán más lentos. , pero no tiene efecto en los resultados comerciales.
En función de esta función, nuestra persistencia de datos de Redis también se puede realizar en forma de " instantánea de datos ".
Entonces, ¿qué es una instantánea de datos?
En pocas palabras, puedes entenderlo así:
-
Te imaginas a Redis como un vaso de agua, escribir datos en Redis es equivalente a verter agua en este vaso.
-
En este momento, toma una foto de la taza de agua con una cámara. En el momento de tomar la foto, la capacidad de agua en la taza de agua se registra en la foto, que es la instantánea de datos de la taza de agua.

Es decir, la instantánea de datos de Redis es registrar los datos en Redis en un momento determinado y luego solo necesita escribir esta instantánea de datos en el disco.
Su ventaja es que solo escribe datos en el disco " una vez " cuando se requiere persistencia, y no necesita operar el disco en otros momentos.
Según esta solución, podemos tomar instantáneas de datos " regularmente " para Redis y conservar los datos en el disco.

Esta solución es Redis RDB que solemos escuchar. RDB utiliza " instantáneas programadas " para la persistencia de datos. Sus ventajas son:
-
Los archivos de persistencia son pequeños (binario + comprimido)
-
Baja frecuencia de escritura en disco (escritura programada)
La desventaja también es obvia, porque es una persistencia cronometrada, los datos definitivamente no son tan completos como la persistencia en tiempo real de AOF, si su Redis solo se usa como un caché y no es sensible a la pérdida de datos (consulta de la base de datos back-end ), entonces este método de persistencia es muy adecuado.
Si se le pide que elija una solución de persistencia, puede elegir así:
-
Si la empresa no es sensible a la pérdida de datos, elija RDB
-
La empresa tiene requisitos relativamente altos para la integridad de los datos, elija AOF
Después de comprender RDB y AOF, pensemos un poco más: ¿hay alguna manera no solo de garantizar la integridad de los datos, sino también de reducir el tamaño de los archivos persistentes y restaurarlos más rápido?
Repasemos las características de RDB y AOF que mencionamos anteriormente:
-
RDB se almacena en modo binario + compresión de datos, y el tamaño del archivo es pequeño
-
AOF registra cada comando de escritura, los datos más completos
¿Podemos aprovechar sus respectivas fortalezas?
Por supuesto, esta es la " persistencia híbrida " de Redis.
Si desea tener una mayor integridad de datos, no solo debe usar RDB, sino también centrarse en la optimización de AOF.
Específicamente, cuando AOF está reescribiendo, Redis primero escribe una instantánea de datos en el archivo AOF en formato RDB y luego agrega cada comando de escritura generado durante este período al archivo AOF.
Debido a que el RDB está escrito en compresión binaria, el tamaño del archivo AOF se vuelve más pequeño.

Debido a que el volumen AOF se comprime aún más, cuando usa AOF para restaurar datos, ¡el tiempo de recuperación será más corto!
Redis versión 4.0 y superior solo es compatible con la persistencia híbrida.
Nota: la persistencia híbrida es una optimización de la reescritura de AOF, lo que significa que debe basarse en la reescritura de AOF + AOF.
Con tal optimización, su Redis ya no tiene que preocuparse por el tiempo de inactividad de la instancia. Cuando ocurre un tiempo de inactividad, puede usar archivos persistentes para restaurar rápidamente los datos en Redis.
¿Pero está bien?
Piénsalo con cuidado. Aunque hemos optimizado los archivos persistentes al mínimo, aún lleva tiempo restaurar los datos . Durante este período, su aplicación comercial no puede proporcionar servicios. ¿Qué debemos hacer?
Si una instancia se cae, solo se puede solucionar restaurando los datos. ¿Podemos implementar varias instancias de Redis y luego mantener los datos de estas instancias sincronizados en tiempo real, de modo que cuando una instancia se caiga, podamos elegir una de las restantes? instancias para continuar Simplemente proporcione el servicio.
Así es, esta solución es la "replicación maestro-esclavo: copias múltiples" que se discutirá a continuación.
Replicación maestro-esclavo: copias múltiples
Puede implementar varias instancias de Redis y el modelo arquitectónico se convierte en este:

Aquí llamamos maestro al nodo que lee y escribe en tiempo real, y esclavo al otro nodo que sincroniza datos en tiempo real.
Las ventajas de adoptar el esquema multicopia son:
-
Acortar el tiempo no disponible : si el maestro está caído, podemos promover manualmente el esclavo al maestro para continuar brindando servicios
-
Mejore el rendimiento de lectura : deje que el esclavo comparta una parte de la solicitud de lectura para mejorar el rendimiento general de la aplicación

Esta solución es buena, no solo ahorra tiempo de recuperación de datos, sino que también mejora el rendimiento.
Pero su problema es: cuando el maestro está inactivo, necesitamos promover "manualmente" el esclavo al maestro, y este proceso también lleva tiempo.
Si bien es mucho más rápido que restaurar datos, aún requiere intervención humana. Una vez que se requiere la intervención manual, se debe contar el tiempo de reacción humana y el tiempo de operación, por lo que sus aplicaciones comerciales aún se verán afectadas durante este período.
¿Podemos automatizar este proceso de cambio?
Centinela: conmutación por error
Si desea cambiar automáticamente, no debe confiar en las personas.
Ahora, podemos introducir un "observador" para monitorear el estado de salud del maestro en tiempo real. Este observador es el "centinela".
¿Cómo hacerlo?
-
El centinela le pregunta al maestro si es normal a intervalos.
-
El maestro responde normalmente, lo que indica que el estado es normal, y el tiempo de espera de respuesta indica anormalidad
-
El centinela encuentra una excepción e inicia un cambio maestro-esclavo

Con esta solución, no hay necesidad de que los humanos intervengan en el proceso, y todo se vuelve automático, ¿no es genial?
Pero hay otro problema aquí.Si el estado del maestro es normal, pero el centinela tiene un problema con la red entre ellos cuando le pregunta al maestro, entonces el centinela puede " calcular mal ".

¿Cómo resolver este problema?
Dado que un centinela juzgará mal, podemos desplegar varios centinelas, distribuirlos en diferentes máquinas y permitirles monitorear el estado del maestro juntos. El proceso se vuelve así:

-
Múltiples centinelas le preguntan al maestro si es normal a intervalos.
-
El maestro responde normalmente, lo que indica que el estado es normal, y el tiempo de espera de respuesta indica anormalidad
-
Una vez que un centinela juzga que el maestro es anormal (ya sea un problema de red o no), le preguntará a otros centinelas. Si varios centinelas (establecen un umbral) piensan que el maestro es anormal, entonces se determina que el maestro realmente lo ha hecho. fallido.
-
Después de negociar múltiples centinelas, se determina que el maestro está defectuoso y se inicia un cambio maestro-esclavo
Por lo tanto, utilizamos múltiples centinelas para negociar entre sí para determinar el estado del maestro, de modo que la probabilidad de juicio erróneo pueda reducirse en gran medida.
Después de que la negociación centinela determina que el maestro es anormal, surge otra pregunta: ¿ qué centinela iniciará el cambio maestro-esclavo?
La respuesta es seleccionar un "líder" centinela que cambiará entre maestro y esclavo.
Aquí viene la pregunta nuevamente, ¿cómo elegir a este líder?
¿Imagina cómo se hacen las elecciones en la vida real?
Sí, vota.
Al elegir líderes centinela, podemos formular una regla de elección de este tipo:
-
Cada centinela pide a los demás centinelas que voten por él.
-
Cada centinela solo vota por el primer centinela que solicita un voto, y solo puede votar una vez
-
El centinela que obtiene más de la mitad de los votos primero es elegido líder e inicia un cambio maestro-esclavo.
Este proceso de elección es lo que escuchamos a menudo: el " algoritmo de consenso " en el campo de los sistemas distribuidos.
¿Qué es un algoritmo de consenso?
Desplegamos centinelas en varias máquinas y necesitan trabajar juntos para completar una tarea, por lo que forman un "sistema distribuido".
En el campo de los sistemas distribuidos, el algoritmo de cómo varios nodos alcanzan un consenso sobre un problema se denomina algoritmo de consenso.
En este escenario, varios centinelas negocian juntos para elegir un líder que todos reconozcan, lo que se hace mediante un algoritmo de consenso.
Este algoritmo también estipula que la cantidad de nodos debe ser un número impar, lo que puede garantizar que incluso si falla un nodo en el sistema, más de la "mitad" de los nodos restantes están en estado normal y aún pueden proporcionar resultados correctos. decir, este algoritmo también es compatible Hay un caso de un nodo fallido.
Hay muchos algoritmos de consenso en el campo de los sistemas distribuidos, como Paxos, Raft y el escenario donde los centinelas eligen líderes.El algoritmo de consenso Raft se usa porque es lo suficientemente simple y fácil de implementar.
Bien, hagamos un resumen aquí.
Su Redis se ha optimizado desde la versión independiente más simple a través de la persistencia de datos, copia múltiple maestro-esclavo y clúster centinela. El rendimiento y la estabilidad de Redis son cada vez mayores. No se preocupe.
Implementado en un modo arquitectónico de este tipo, Redis básicamente puede funcionar de manera estable durante mucho tiempo.
...
Con el paso del tiempo, su volumen de negocios ha comenzado a marcar el comienzo de un crecimiento explosivo. En este momento, ¿su modelo de arquitectura aún puede soportar un tráfico tan grande?
Analicémoslo juntos:
-
Miedo a la pérdida de datos : persistencia (RDB/AOF)
-
Largo tiempo de recuperación : copia maestro-esclavo (la copia se puede cortar en cualquier momento)
-
Largo tiempo de conmutación manual : grupo centinela (conmutación automática)
-
Presión de lectura : copia de expansión (separación de lectura y escritura)
-
Escribir está bajo presión : ¿qué debo hacer si un mater no puede manejarlo?
Se puede ver que el problema restante ahora es que cuando aumenta la cantidad de solicitudes de escritura, es posible que una instancia maestra no pueda soportar una cantidad tan grande de tráfico de escritura.
Para resolver perfectamente este problema, debe considerar el uso de "clústeres fragmentados" en este momento.
Clústeres fragmentados: escalabilidad horizontal
¿Qué es un "clúster fragmentado"?
En pocas palabras, una instancia no puede soportar la presión de escribir, por lo que podemos implementar varias instancias y luego organizar estas instancias de acuerdo con ciertas reglas, tratarlas como un todo y brindar servicios al mundo exterior, para que podamos resolver el problema de la escritura centralizada de una instancia es el problema del cuello de botella?
Entonces, el modelo de arquitectura actual se vuelve así:

Ahora vuelve la pregunta, ¿cómo organizar tantas instancias?
Formulamos las reglas de la siguiente manera:
-
Cada nodo almacena una parte de los datos por separado, y la suma de todos los datos del nodo es la cantidad total de datos
-
Cree una regla de enrutamiento, para diferentes claves, diríjala a una instancia fija para lectura y escritura
Los datos se almacenan en varias instancias y las reglas de enrutamiento para encontrar la clave deben realizarse en el lado del cliente, específicamente de la siguiente manera:
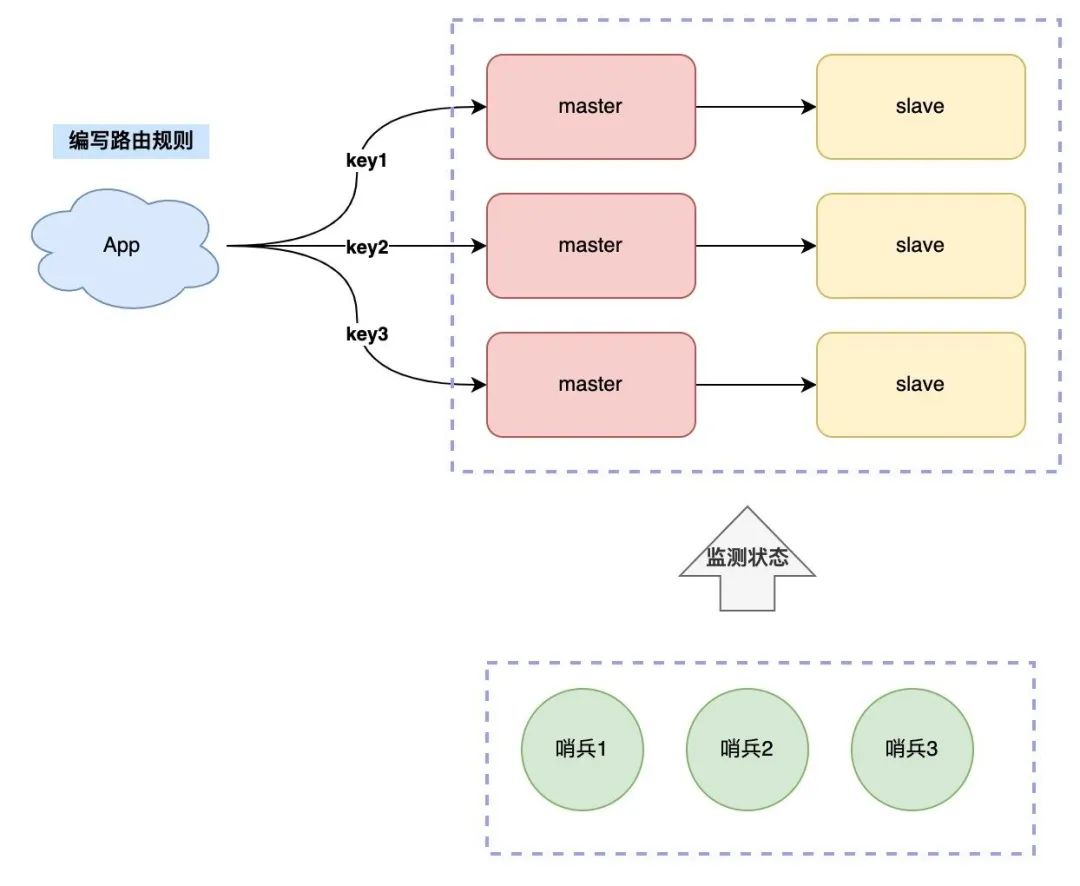
Esta solución también se denomina "fragmentación del cliente". La desventaja de esta solución es que el cliente debe mantener las reglas de enrutamiento, es decir, debe escribir las reglas de enrutamiento en su código comercial.
¿Cómo evitar el acoplamiento de las reglas de enrutamiento con el código comercial del cliente?
Para continuar con la optimización, podemos agregar una "capa de proxy intermedia" entre el cliente y el servidor. Este proxy es el proxy que escuchamos a menudo, y las reglas de enrutamiento y reenvío se colocan en esta capa de proxy para mantenimiento.
De esta manera, el cliente no necesita preocuparse por la cantidad de nodos de Redis en el servidor, sino que solo necesita interactuar con el Proxy.
El proxy reenviará su solicitud al nodo de Redis correspondiente de acuerdo con las reglas de enrutamiento. Además, cuando la instancia del clúster no es suficiente para admitir solicitudes de tráfico más grandes, también puede expandirse horizontalmente y agregar nuevas instancias de Redis para mejorar el rendimiento. Todo esto es para usted. Para el cliente, es transparente e imperceptible.
Las soluciones de clúster de sharding Redis de código abierto de la industria, como Twemproxy y Codis, adoptan esta solución.
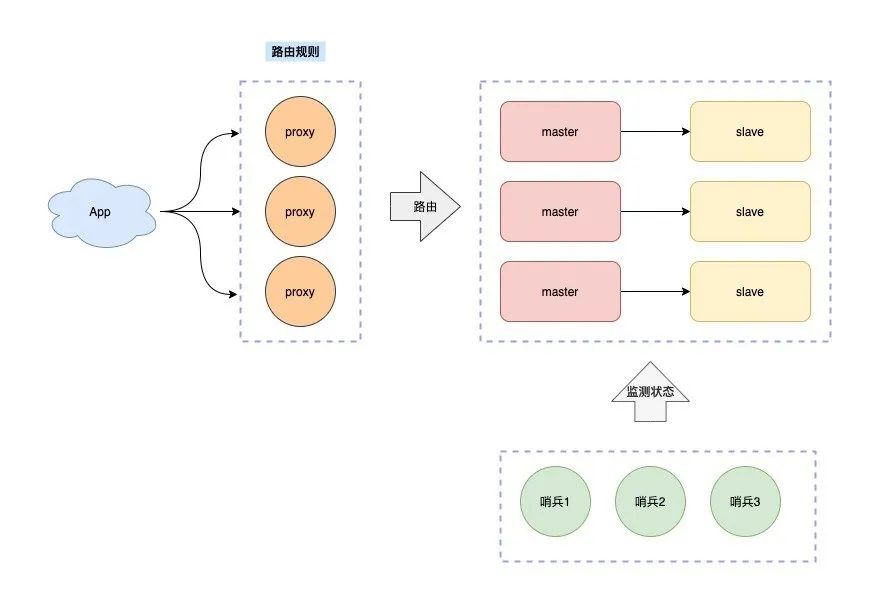
La ventaja de esta solución es que el cliente no necesita preocuparse por las reglas de reenvío de datos, sino que solo necesita lidiar con el Proxy. El cliente opera el clúster subsiguiente como un Redis independiente, que es fácil de usar.
Evolución de la arquitectura Hasta ahora, ya sea que las reglas de enrutamiento sean implementadas por el cliente o el proxy, todas son soluciones de sharding desarrolladas por la "comunidad". Su característica es que los nodos de Redis en el clúster no conocen la existencia de los demás. Solo el cliente o Proxy coordinará dónde se escriben y se leen los datos, y todos confían en el clúster centinela para que sea responsable de la conmutación por error automática.
En otras palabras, en realidad estamos combinando múltiples nodos Redis aislados para su uso.
Redis en realidad lanzó la solución de sharding "oficial" de Redis Cluster en 3.0, pero debido a la inestabilidad en la etapa inicial del lanzamiento, pocas personas la usan, por lo que han surgido varias soluciones de código abierto en la industria, como Twemproxy y Codis sharding mencionado. Es en este contexto que nació el programa de cine.
Sin embargo, con la madurez gradual de la solución Redis Cluster, cada vez más empresas de la industria han comenzado a adoptar la solución oficial (después de todo, la solución oficial garantiza un mantenimiento continuo, y Twemproxy y Codis han renunciado gradualmente al mantenimiento). su esquema es el siguiente.

Redis Cluster no necesita implementar clústeres centinela. Los nodos de Redis en el clúster detectan el estado de salud de los demás a través del protocolo Gossip y pueden iniciar el cambio automático en caso de falla.
Además, con respecto a las reglas de enrutamiento y reenvío, no es necesario que el cliente lo escriba por sí mismo. Redis Cluster proporciona un SDK de "soporte". Siempre que el cliente actualice el SDK, se puede integrar con Redis Cluster. El SDK lo ayudará a encontrar el nodo Redis correspondiente a la clave. Lee y escribe, y también puede adaptarse automáticamente a la adición y eliminación de nodos Redis, y el lado comercial no tiene percepción.
Aunque se omite la implementación de clústeres centinela, el costo de mantenimiento se ha reducido mucho, pero para que el cliente actualice el SDK, el costo puede no ser alto para las nuevas aplicaciones comerciales, pero para el negocio antiguo, el "costo de actualización" es todavía relativamente alto, que tiene mucha resistencia a cambiar la solución oficial de Redis Cluster.
Como resultado, varias empresas comenzaron a desarrollar sus propios Proxies para Redis Cluster a fin de reducir el costo de las actualizaciones de los clientes, y la arquitectura quedó así:

De esta forma, el cliente no necesita realizar ningún cambio, solo necesita cambiar la dirección de conexión al Proxy, y el Proxy es responsable de reenviar los datos y manejar los cambios de enrutamiento causados por la adición o eliminación de nodos en el clúster subsiguiente.
Hasta ahora, se ha formado la arquitectura de fragmentación de Redis principal de la industria. Cuando utiliza clústeres de fragmentación, puede enfrentar con calma una mayor presión de tráfico en el futuro.
Resumir
En resumen, cómo construimos un clúster Redis estable y de alto rendimiento de 0 a 1, y luego de 1 a N, desde el cual se puede ver claramente todo el proceso de evolución de la arquitectura Redis.
-
Miedo a la pérdida de datos -> Persistencia (RDB/AOF)
-
Largo tiempo de recuperación -> copia maestro-esclavo (la copia se puede cortar en cualquier momento)
-
Conmutación por error manual lenta -> clúster centinela (conmutación automática)
-
Hay presión en la lectura -> copia de expansión (separación de lectura y escritura)
-
Escribir cuello de botella de presión/capacidad -> Clúster fragmentado
-
Solución de comunidad de clúster fragmentado -> Twemproxy, Codis (sin comunicación entre los nodos de Redis, es necesario implementar Sentry, se puede expandir horizontalmente)
-
Solución oficial de clúster fragmentado -> Redis Cluster (protocolo de chismes entre nodos de Redis, no es necesario implementar centinelas y se puede escalar horizontalmente)
-
Es difícil actualizar el lado comercial -> Proxy + Redis Cluster (no invade el lado comercial)
Hasta ahora, nuestro clúster de Redis ha podido brindar servicios para nuestro negocio con estabilidad a largo plazo y alto rendimiento.
Espero que este artículo pueda ayudarlo a comprender mejor la evolución de la arquitectura Redis.