Confusion Matrix es un formato tabular utilizado para evaluar el rendimiento de los modelos de clasificación. Muestra varias combinaciones entre las predicciones del modelo y las etiquetas reales en un problema de clasificación.
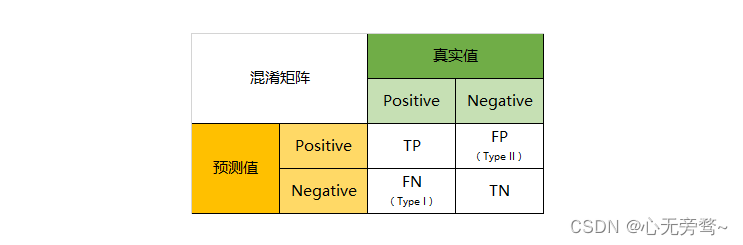
Las matrices de confusión se usan comúnmente para problemas de clasificación binaria, pero también se pueden extender a problemas de clasificación de clases múltiples. Para problemas de clasificación binaria, consta de cuatro indicadores importantes:
Verdadero Positivo (TP): El número de casos positivos predichos por el modelo y realmente positivos.
True Negative (TN): el número de ejemplos negativos predichos por el modelo y realmente negativos.
Falso positivo (FP): el número de ejemplos positivos predichos por el modelo, pero en realidad ejemplos negativos. También conocido como "falso positivo".
Falso Negativo (FN): El número de ejemplos negativos predichos por el modelo pero realmente positivos. También conocido como "falso negativo".
La forma general de una matriz de confusión es la siguiente:
La matriz de confusión se puede utilizar para calcular múltiples indicadores para medir el rendimiento del clasificador, como exactitud (Exactitud), precisión (Precisión), recuperación (Recuperación, también conocida como sensibilidad o tasa de casos reales) y valor F1. Estas métricas se pueden calcular a partir de los elementos individuales en la matriz de confusión:
Precisión (Precisión): La proporción de muestras correctas predichas por el clasificador al número total de muestras, la fórmula de cálculo es (TP + TN) / (TP + TN + FP + FN).
Precisión (Precisión): La proporción de predicciones positivas que son correctas, la fórmula de cálculo es TP / (TP + FP).
Recall (Recall): La proporción de ejemplos positivos que se predicen correctamente como ejemplos positivos, la fórmula de cálculo es TP/(TP+FN).
Valor F1: un indicador que tiene en cuenta la tasa de precisión y la tasa de recuperación, y la fórmula de cálculo es 2 (Precisión de recuperación) / (Precisión + recuperación).
Las matrices de confusión brindan la capacidad de evaluar el rendimiento del modelo de clasificación de manera más detallada y completa, lo que nos ayuda a comprender los falsos positivos y los falsos negativos en las predicciones. Al analizar la matriz de confusión, podemos obtener información valiosa sobre el rendimiento del clasificador en cada clase y optimizar los resultados de la clasificación.
No hay muchas tonterías, el código anterior:
def draw_confusion_matrix(label_true, label_pred, label_name, normlize, title="Confusion Matrix", pdf_save_path=None, dpi=100):
"""
@param label_true: 真实标签,比如[0,1,2,7,4,5,...]
@param label_pred: 预测标签,比如[0,5,4,2,1,4,...]
@param label_name: 标签名字,比如['cat','dog','flower',...]
@param normlize: 是否设元素为百分比形式
@param title: 图标题
@param pdf_save_path: 是否保存,是则为保存路径pdf_save_path=xxx.png | xxx.pdf | ...等其他plt.savefig支持的保存格式
@param dpi: 保存到文件的分辨率,论文一般要求至少300dpi
@return:
example:
draw_confusion_matrix(label_true=y_gt,
label_pred=y_pred,
label_name=["Angry", "Disgust", "Fear", "Happy", "Sad", "Surprise", "Neutral"],
normlize=True,
title="Confusion Matrix on Fer2013",
pdf_save_path="Confusion_Matrix_on_Fer2013.png",
dpi=300)
"""
cm1=confusion_matrix(label_true, label_pred)
cm = confusion_matrix(label_true, label_pred)
if normlize:
row_sums = np.sum(cm, axis=1)
cm = cm / row_sums[:, np.newaxis]
cm=cm.T
cm1=cm1.T
plt.imshow(cm, cmap='Blues')
plt.title(title)
plt.xlabel("Predict label")
plt.ylabel("Truth label")
plt.yticks(range(label_name.__len__()), label_name)
plt.xticks(range(label_name.__len__()), label_name, rotation=45)
plt.tight_layout()
plt.colorbar()
for i in range(label_name.__len__()):
for j in range(label_name.__len__()):
color = (1, 1, 1) if i == j else (0, 0, 0) # 对角线字体白色,其他黑色
value = float(format('%.1f' % (cm[i, j]*100)))
value1=str(value)+'%\n'+str(cm1[i, j])
plt.text(i, j, value1, verticalalignment='center', horizontalalignment='center', color=color)
# plt.show()
if not pdf_save_path is None:
plt.savefig(pdf_save_path, bbox_inches='tight',dpi=dpi)
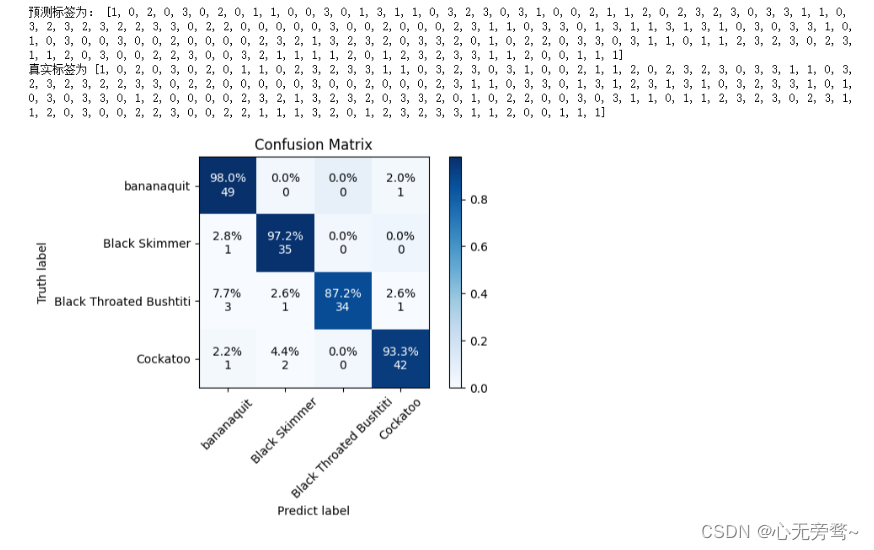
labels_name = ['bananaquit', 'Black Skimmer', 'Black Throated Bushtiti', 'Cockatoo']
y_gt=[]
y_pred=[]
model_weight_path = "./best_CBAM_model.pth"
models = Xception(num_classes = 4)
models.load_state_dict(torch.load(model_weight_path))
models.eval()
for index, (imgs, labels) in enumerate(test_dl):
labels_pd = models(imgs)
predict_np = np.argmax(labels_pd.cpu().detach().numpy(), axis=-1).tolist()
labels_np = labels.numpy().tolist()
y_pred.extend(predict_np)
y_gt.extend(labels_np)
print("预测标签为:", y_pred)
print("真实标签为", y_gt)
draw_confusion_matrix(label_true=y_gt,
label_pred=y_pred,
label_name=labels_name,
normlize=True,
title="Confusion Matrix",
pdf_save_path="Confusion_Matrix.jpg",
dpi=300)
El resultado es el siguiente: