1. Entrenamiento básico de Pytorch
La sección anterior trataba sobre
video básico e IA, y la interacción con el proceso (2) pytorch entrenó mínimamente su propio conjunto de datos y lo reconoció.Después
de la sección anterior, comenzamos a usar el aprendizaje de transferencia para entrenar nuestro propio conjunto de datos y guardar la red, cargar la red y reconocerlo.
2. pytorch carga resnet18
La base de la red RetNet es la red residual, y su arquitectura original es ResNet.Como su nombre indica, la profundidad de la red es de 18 capas. Incluye agrupación, activación, lineal, excluyendo la normalización por lotes, agrupación, ¿por qué cargar resnet18? Debido a que puede usar el modelo establecido y ajustar la salida, en pytorch, puede usar el modelo de clasificación de imágenes entrenado previamente en ImageNet proporcionado por torchvision para entrenar el modelo de aprendizaje profundo en el conjunto de datos de imágenes recopilado por usted mismo. Esto puede ahorrar mucho tiempo, utilizando el modelo de ajuste fino, la capa de salida del modelo resnet18 final se restablece y se logra el aprendizaje de transferencia.
2.1 Estandarización del procesamiento de estandarización de datos
Definición: Procesamiento de estandarización de datos: transforms.Normalize()
Estandarización de datos, en términos generales, la media (media) es 0, la desviación estándar (std) es 1
En pocas palabras, los datos se calculan por canal y los datos de cada canal Primero calcule su varianza y valor medio, luego reste el valor medio de cada dato en cada canal y luego divídalo por la varianza para obtener el resultado normalizado. Después de la normalización, los datos pueden responder mejor a la función de activación, mejorar la expresividad de los datos y reducir la ocurrencia de explosión de gradiente y desaparición de gradiente.
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torch.backends.cudnn as cudnn
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
#通过设置让内置的cuDNN的auto-tuner自动寻找最适合当前配置的高效算法,来达到优化运行效率的问题
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
cudnn.benchmark = True
plt.ion() # interactive mode 交互模式
#定义三个全局变量
dataloaders=None
dataset_sizes =None
class_names = None
Defina la función de normalización, el valor dentro es el valor de normalización de la red resnet, no está escrito casualmente.
#标准化函数
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
]),
}
2.2 Función de entrenamiento
A continuación, escriba la función de entrenamiento, los parámetros se han explicado
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
""" 训练模型,并返回在最佳模型
参数:
- model(nn.Module): 要训练的模型
- criterion: 损失函数
- optimizer(optim.Optimizer): 优化器
- scheduler: 学习率调度器
- num_epochs(int): 最大 epoch 数
返回:
- model(nn.Module): 最佳模型
- best_acc(float): checkpoint最好准确率
"""
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print(f'Epoch {
epoch}/{
num_epochs - 1}')
print('-' * 10)
# 训练集和验证集交替进行前向传播
for phase in ['train', 'val']:
if phase == 'train':
model.train() # 设置为训练模式,可以更新网络参数
else:
model.eval() # 设置为预估模式,不可更新网络参数
running_loss = 0.0
running_corrects = 0
# 遍历数据集
for inputs, labels in dataloaders[phase]:
global device
inputs = inputs.to(device)
labels = labels.to(device)
# 清空梯度,避免累加了上一次的梯度
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
# 正向传播
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 反向传播且仅在训练阶段进行优化
if phase == 'train':
loss.backward() # 反向传播
optimizer.step()
# 统计loss、准确率
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f'{
phase} Loss: {
epoch_loss:.4f} Acc: {
epoch_acc:.4f}')
# 发现了更优的模型,记录起来
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print(f'Training complete in {
time_elapsed // 60:.0f}m {
time_elapsed % 60:.0f}s')
print(f'Best val Acc: {
best_acc:4f}')
# 加载训练的最好的模型
model.load_state_dict(best_model_wts)
return model
3. Carga y colocación de conjuntos de datos
Coloque dos directorios en el directorio de datos, uno es tren, el otro es val, que son obviamente el conjunto de entrenamiento y el conjunto de verificación. Hay

tres categorías, hormigas, abejas y vehículos de ingeniería. Los vehículos de ingeniería utilizan el contenido del artículo anterior. .

La imagen del vehículo de construcción es la siguiente, solo guárdelo y el conjunto de verificación es el mismo. 
La lista de códigos es la siguiente:
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torch.backends.cudnn as cudnn
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
#通过设置让内置的cuDNN的auto-tuner自动寻找最适合当前配置的高效算法,来达到优化运行效率的问题
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
cudnn.benchmark = True
plt.ion() # interactive mode 交互模式
dataloaders=None
dataset_sizes =None
class_names = None
def imshow(inp, title=None):
# 可视化一组 Tensor 的图片
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # 暂停一会儿,为了将图片显示出来
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
""" 训练模型,并返回在验证集上的最佳模型和准确率
Args:
- model(nn.Module): 要训练的模型
- criterion: 损失函数
- optimizer(optim.Optimizer): 优化器
- scheduler: 学习率调度器
- num_epochs(int): 最大 epoch 数
Return:
- model(nn.Module): 最佳模型
- best_acc(float): 最佳准确率
"""
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print(f'Epoch {
epoch}/{
num_epochs - 1}')
print('-' * 10)
# 训练集和验证集交替进行前向传播
for phase in ['train', 'val']:
if phase == 'train':
model.train() # 设置为训练模式,可以更新网络参数
else:
model.eval() # 设置为预估模式,不可更新网络参数
running_loss = 0.0
running_corrects = 0
# 遍历数据集
for inputs, labels in dataloaders[phase]:
global device
inputs = inputs.to(device)
labels = labels.to(device)
# 清空梯度,避免累加了上一次的梯度
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
# 正向传播
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 反向传播且仅在训练阶段进行优化
if phase == 'train':
loss.backward() # 反向传播
optimizer.step()
# 统计loss、准确率
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f'{
phase} Loss: {
epoch_loss:.4f} Acc: {
epoch_acc:.4f}')
# 发现了更优的模型,记录起来
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print(f'Training complete in {
time_elapsed // 60:.0f}m {
time_elapsed % 60:.0f}s')
print(f'Best val Acc: {
best_acc:4f}')
# 加载训练的最好的模型
model.load_state_dict(best_model_wts)
return model
def visualize_model(model, num_images=6):
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders['val']):
global device
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images//2, 2, images_so_far)
ax.axis('off')
ax.set_title(f'predicted: {
class_names[preds[j]]}')
imshow(inputs.cpu().data[j])
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
def main():
# 在训练集上:扩充、归一化
# 在验证集上:归一化
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
]),
}
data_dir = './data'
image_datasets = {
x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
global dataloaders
dataloaders = {
x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
global dataset_sizes
dataset_sizes = {
x: len(image_datasets[x]) for x in ['train', 'val']}
global class_names
class_names = image_datasets['train'].classes
print(class_names)
# 获取一批训练数据
inputs, classes = next(iter(dataloaders['train']))
# 批量制作网格
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
model = models.resnet18(pretrained=True) # 加载预训练模型
for param in model.parameters():
param.requires_grad = False
num_ftrs = model.fc.in_features # 获取低级特征维度
model.fc = nn.Linear(num_ftrs, 3) # 替换新的输出层
model = model.to(device)
# 交叉熵作为损失函数
criterion = nn.CrossEntropyLoss()
# 所有参数都参加训练
optimizer_ft = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 每过 7 个 epoch 将学习率变为原来的 0.1
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
model_ft = train_model(model, criterion, optimizer_ft, scheduler, num_epochs=3) # 开始训练
visualize_model(model_ft)
PATH = './test.pth'
torch.save(model_ft.state_dict(), PATH)
if __name__== "__main__" :
main()
4. Cómo llamar
Guardamos el archivo pth anteriormente, pero en realidad usamos state_dict, que es diferente del guardado directo del modelo
import torch
from PIL import Image
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
from torchvision import models
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
PATH = './test.pth'
transform = transforms.Compose(
[transforms.Resize((256, 256)),transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
model = models.resnet18(pretrained=True) # 加载预训练模型
num_ftrs = model.fc.in_features # 获取低级特征维度
model.fc = nn.Linear(num_ftrs, 3) # 替换新的输出层
print(device)
model = model.to(device)
model.load_state_dict(torch.load(PATH))
model.eval()
img = Image.open("./ant.jpg") .convert('RGB')
img = transform(img)
img = img.unsqueeze(0)
img = img.to(device)
with torch.no_grad():
outputs = model(img)
_, predicted = torch.max(outputs.data, 1)
print("the test img lable is ",predicted)
La función de descompresión interna es necesaria. Preste atención a esto. Al cargar una imagen, la imagen generalmente tiene 3 dimensiones, ancho, alto y número de canales de color. Para imágenes en blanco y negro, el número de canales de color es 1 y para imágenes en color, hay 3 canales de color (rojo, verde y azul, RGB). Por lo tanto, cargando una imagen y almacenándola como un tensor, el orden de las dimensiones es [canal, alto, ancho], para una red neuronal convolucional bidimensional, el volumen de datos tridimensional no puede corresponder. En las redes convolucionales profundas, los datos se procesan por lotes. En lugar de procesar una imagen a la vez, una red neuronal convolucional procesa N imágenes en paralelo al mismo tiempo. Llamamos a este conjunto de imágenes un lote. Entonces, en lugar de la dimensión [C, H, W], es [N, C, H, W]. , si solo está procesando una imagen a la vez, aún debe colocarla en un formulario por lotes para que el modelo la acepte. Por ejemplo, si tiene una imagen con una forma de [3, 255, 255], debe convertirla a [1, 3, 255, 255]. Esto es lo que hace la función unsqueeze(0).
El cuda utilizado durante el entrenamiento se puede utilizar durante el reconocimiento, o no cuda, es decir, "cpu", también se puede utilizar. El resultado de la llamada es el siguiente:
python test.py contiene ant.jpg

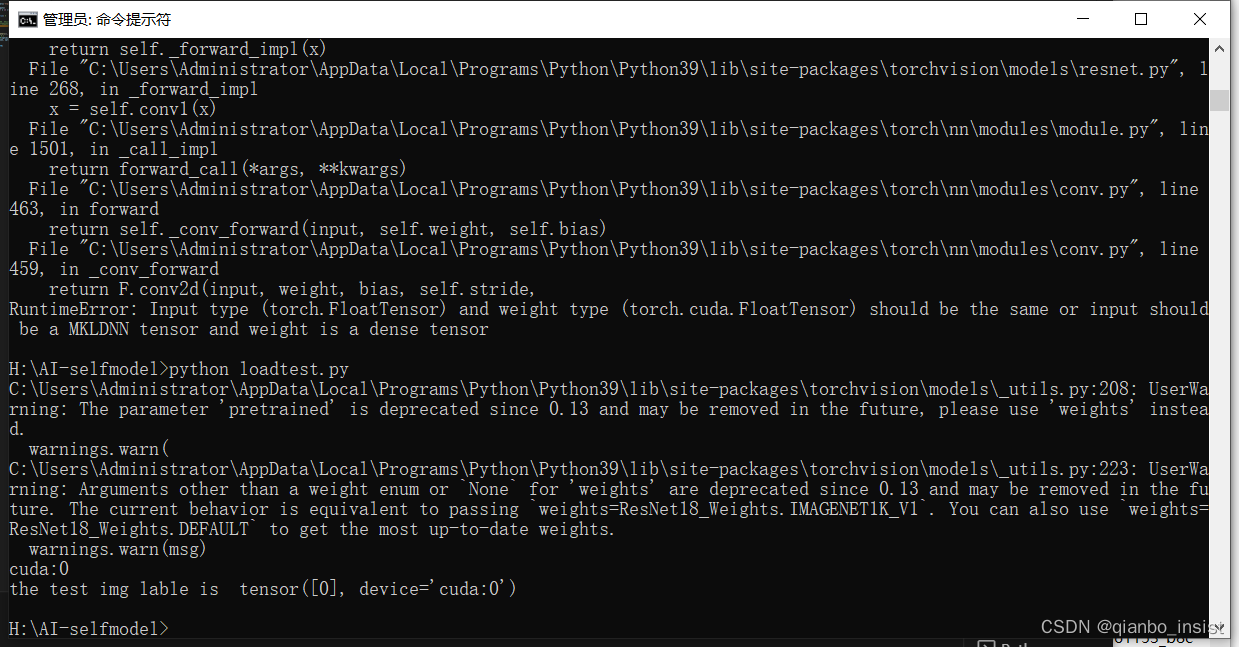
Pon un camión de ingeniería, adentro está

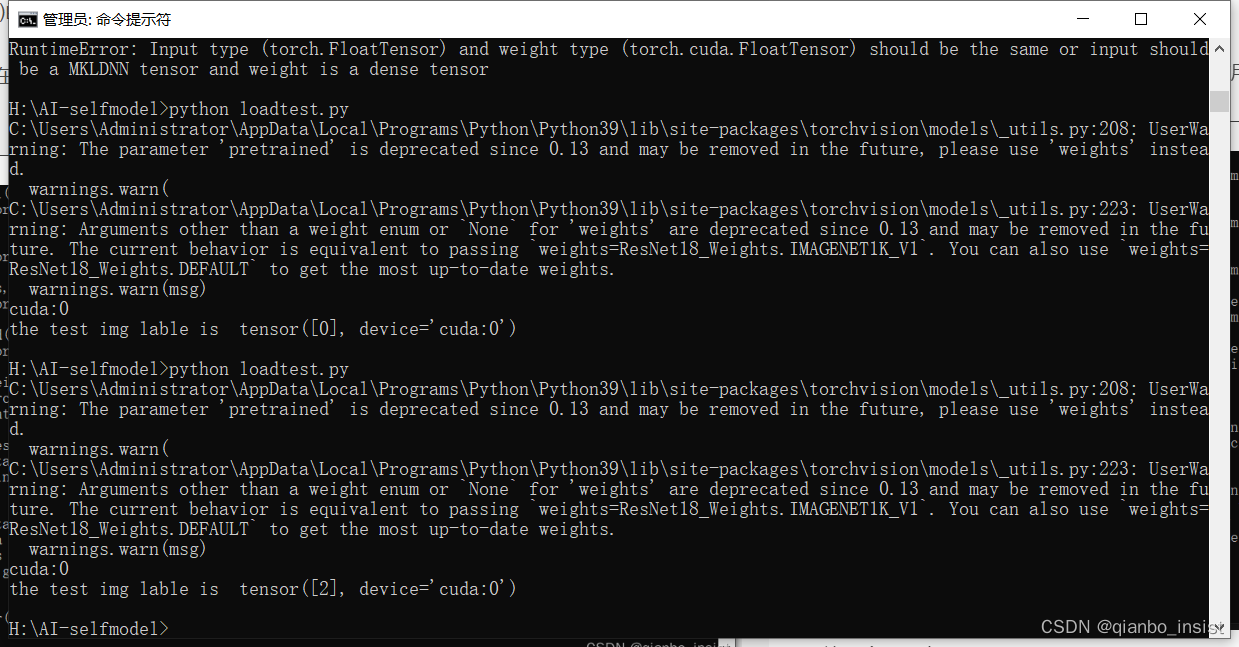
Vi que salió la tercera categoría, a saber, tensor[2], es decir, tensor[0] es hormiga, tensor[1] es abeja, tensor[2] es un vehículo de ingeniería
Hemos completado la capacitación y el reconocimiento mediante el aprendizaje de migración, pero aquí hay una limitación. Se trata del reconocimiento de un solo objeto principal, sin reconocimiento de clasificación múltiple ni detección de objetivos. En el próximo artículo, utilizaremos la clasificación múltiple y la detección de objetivos para detectar objetos.