I. Introducción
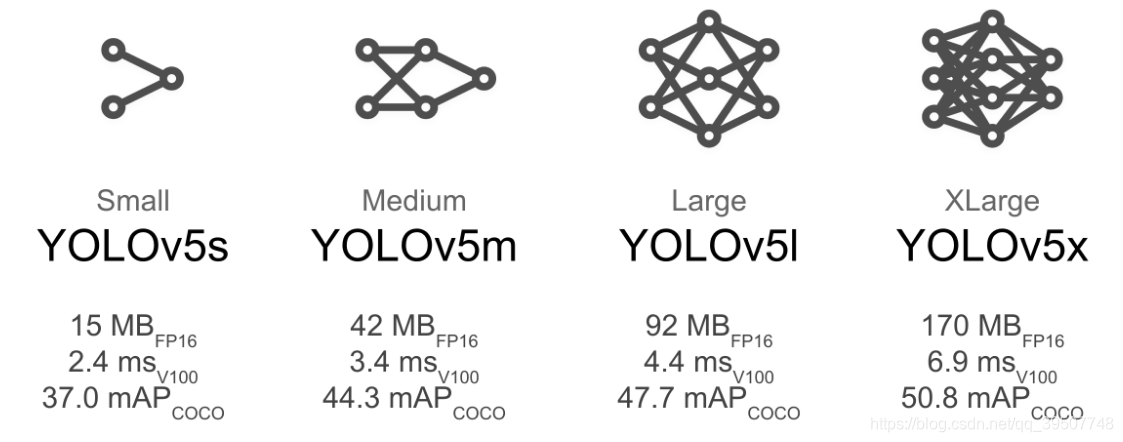
Los dos artículos anteriores han explicado el proceso de formación de la darknetversión yolov3y yolov4es hora de pasar yolov5. Personalmente, me gusta yolov5más, porque proporciona cuatro tamaños diferentes de estructura de modelo para elegir, como se muestra en la siguiente figura:
yolov5El proceso de capacitación es relativamente simple y también es conveniente windowscontinuar. Después de todo, pytorchse usa el marco. Brevemente hablar sobre cómo entrenar! ! !
2. Obtener y organizar conjuntos de datos
1. Si puede descargar el conjunto de datos etiquetado, puede utilizarlo directamente. Preste atención para comprobar si el formato de organización del conjunto de datos es el mismo que el formato VOC.
2. Si no tiene un conjunto de datos listo para usar, es posible que deba etiquetarlo usted mismo, lo explicaré más adelante si tengo la oportunidad. Es necesario utilizar algunas herramientas de etiquetado, como labelImg, ¡el método de uso específico puede referirse a los dos artículos siguientes! ! !
Use labelImg para etiquetar imágenes debajo de Windows
instrucciones de instalación de labelImg
3. El formato de organización del conjunto de datos
De acuerdo con el tutorial de capacitación oficial, necesitamos convertir el conjunto de datos a un yoloformato, por lo que necesitamos usar un script para ayudarnos a completar la conversión, pero antes de eso, debe asegurarse de que su conjunto de datos esté organizado en vocel formato. Con respecto a vocla estructura organizativa del conjunto de datos, pase a mi otro artículo: ¡ Explicación detallada de la estructura organizativa del conjunto de datos VOC ! ! !
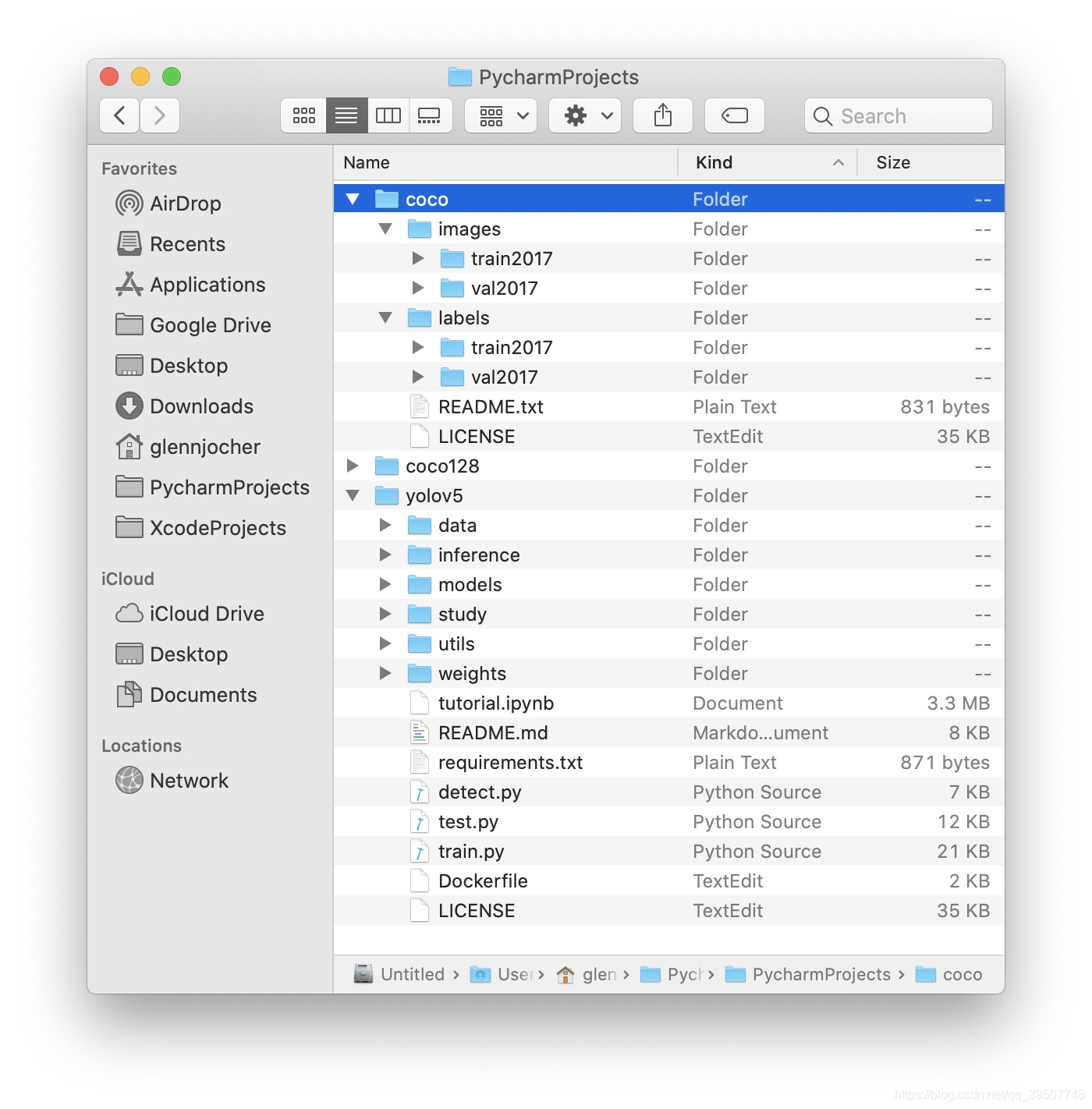
Como se muestra en la figura siguiente, esta es la estructura de organización del conjunto de datos en el tutorial de capacitación oficial, y debemos ser los mismos al final, pero la estructura es la misma y el nombre no tiene que ser exactamente el mismo. Solo necesitamos asegurarnos de que haya images、labelscarpetas y dos subcarpetas debajo de estas dos carpetas train、val. imagesLa imagen se labelsalmacena y yolola etiqueta del formato se almacena .
Nota: images、labelstrain/valLos nombres de las subcarpetas de estas dos carpetas deben ser coherentes.
4. Conversión de formato
Aquí, puede pasar a otro artículo mío: conjunto de datos de formato VOC en formato yolo (darknet) . Debe comprender el contenido de este artículo; de lo contrario, es posible que no comprenda algunas de las cosas que se mencionan a continuación, ¡emmm! ! !
Convertí el conjunto de datos de verificación de entrenamiento y el conjunto de datos de prueba por separado, por lo que es conveniente guardarlos por separado, y luego los coloqué en las carpetas designadas. Las operaciones específicas son las siguientes:
- Los generados
2007_train.txty2007_val.txtfusionados en uno2007_train.txt, debido a que las imágenes de entrenamiento y verificación están en una sola pieza, no es fácil de separar, así que simplemente utilícelas como datos de entrenamiento, luego necesitamos fusionar los dos archivos en uno, es decir,2007_val.txtcopiar y copiar directamente pegue el contenido en el2007_train.txtarchivo y luego elimine el2007_val.txtarchivo. - Luego usamos el conjunto de datos de prueba como datos de verificación, por lo que lo
2007_test.txtmodificaremos a2007_val.txt. Finalmente2007_train.txt,2007_val.txtcoloque los archivos enimagesla ruta paralela inferior, esto no es necesario, siempre que recuerde la ruta de estos dos archivos, y luegovoc.yamlconfigúrelos para la hora correcta. - Por la operación anterior, llegamos
2007_train.txt,2007_val.txtlos dos documentos, pero también tenemos que hacer algunos cambios. Debido a que el contenido de estos dos archivos es la ruta completa de las imágenes de capacitación y verificación, pero cuando organizamos el conjunto de datos más tarde, la ruta de las imágenes ha cambiado. En este momento, las imágenes están todas en laimagescarpeta, por lo que necesita para agregar estos dos La ruta antes del nombre de la imagen en cada archivo se reemplaza por la ruta que se encuentra realmente en este momento. Esto se puede hacer rápidamente reemplazando por lotes. - Coloque el
labelscontenido de la carpeta de almacenamiento de etiquetas generada por las dos conversiones enlabels/trainylabels/valdebajo respectivamente . - Mueva
JPEGImageslas imágenes en las carpetas respectivas del conjunto de datos de entrenamiento y el conjunto de datos de validación haciaimages/trainyimages/valdebajo , respectivamente .
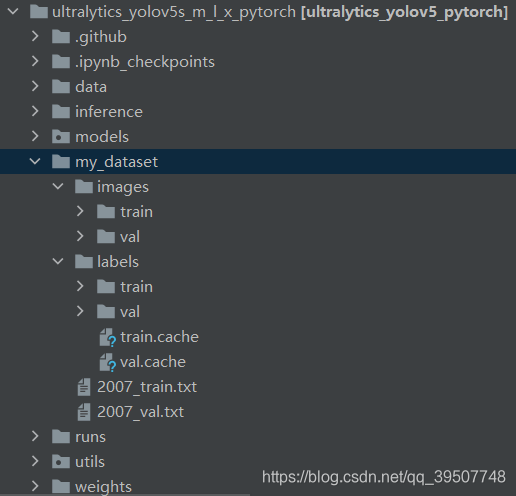
De esta forma, la organización del conjunto de datos está completa. Sin embargo, de hecho, no es necesario que sigas lo que dije anteriormente, porque el punto importante es que debes saber qué está almacenado en cada carpeta y luego convertirlo según el tuyo (incluso si usas ambos voc_label.pypara conversión, la operación puede ser diferente) Los diversos archivos generados finalmente imagesalmacenarán imágenes y labelsalmacenarán yoloetiquetas de formato, y las imágenes de verificación de entrenamiento y las etiquetas de verificación de entrenamiento se pueden almacenar en las subcarpetas trainy respectivamente val.
Por ejemplo, después de comprender el siguiente código, puede modificarlo directamente voc_label.pypara generar los archivos necesarios más rápidamente. voc_label.pyEl contenido es el siguiente:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
#转换最初的训练验证数据集的时候,使用以下sets
#转换最初的测试数据集的时候,可以将其改为sets=[('2007', 'test')]
sets=[('2007', 'train'), ('2007', 'val')]
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus",
"car", "cat", "chair", "cow", "diningtable", "dog", "horse",
"motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text),
float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'
%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'
%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
Tres, construye el proyecto
1. Descarga el código fuente
https://github.com/ultralytics/yolov5
2. Configuración del entorno
pip install -U -r requirements.txt
Cuarto, modifique los documentos relevantes.
1.data/voc.yaml Archivo
Como se muestra a continuación, debemos train、valestablecer el valor como se dijo antes 2007_train.txt, 2007_val.txtla ruta de almacenamiento del archivo. nc和namesTambién debe modificarlo de acuerdo con su situación real, que indican respectivamente el número de categorías y los nombres de las categorías.
# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC/
# Train command: python train.py --data voc.yaml
# Default dataset location is next to /yolov5:
# /parent_folder
# /VOC
# /yolov5
# download command/URL (optional)
download: bash data/scripts/get_voc.sh
# train and val data as
# 1) directory: path/images/,
# 2) file: path/images.txt, or
# 3) list: [path1/images/, path2/images/]
train: F:\0-My_projects\My_AI_Prj\0_PyTorch_projects\ultralytics_yolov5s_m_l_x_pytorch
\my_dataset\2007_train.txt # 16551 images
val: F:\0-My_projects\My_AI_Prj\0_PyTorch_projects\ultralytics_yolov5s_m_l_x_pytorch
\my_dataset\2007_val.txt # 4952 images
# number of classes
nc: 20
# class names
names: ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car',
'cat', 'chair', 'cow', 'diningtable', 'dog','horse', 'motorbike',
'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
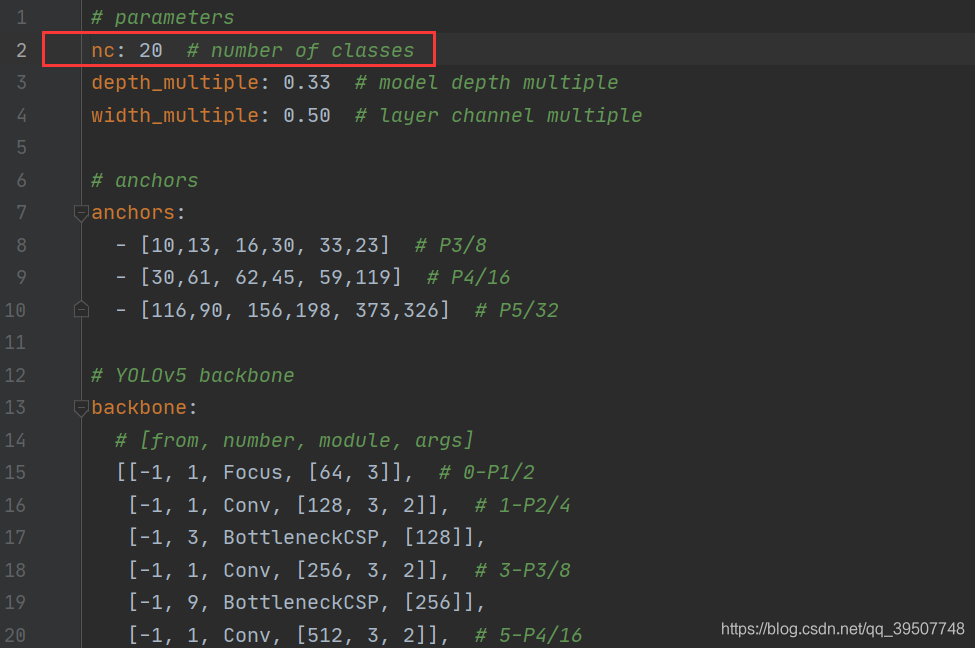
2.models/yolov5s.yaml Archivo
Aquí me estoy preparando para el entrenamiento, yolov5ssi quieres entrenar los otros tres modelos, solo tienes que seleccionar el archivo de configuración correspondiente. Por lo general, solo necesitamos modificar el ncnúmero de tipos en la primera fila para nuestro propio conjunto de datos.
3. Parámetros de entrenamiento
Para mayor comodidad, podemos train.pymodificar los parámetros directamente en el archivo y luego ejecutarlo directamente train.py, como se muestra a continuación:
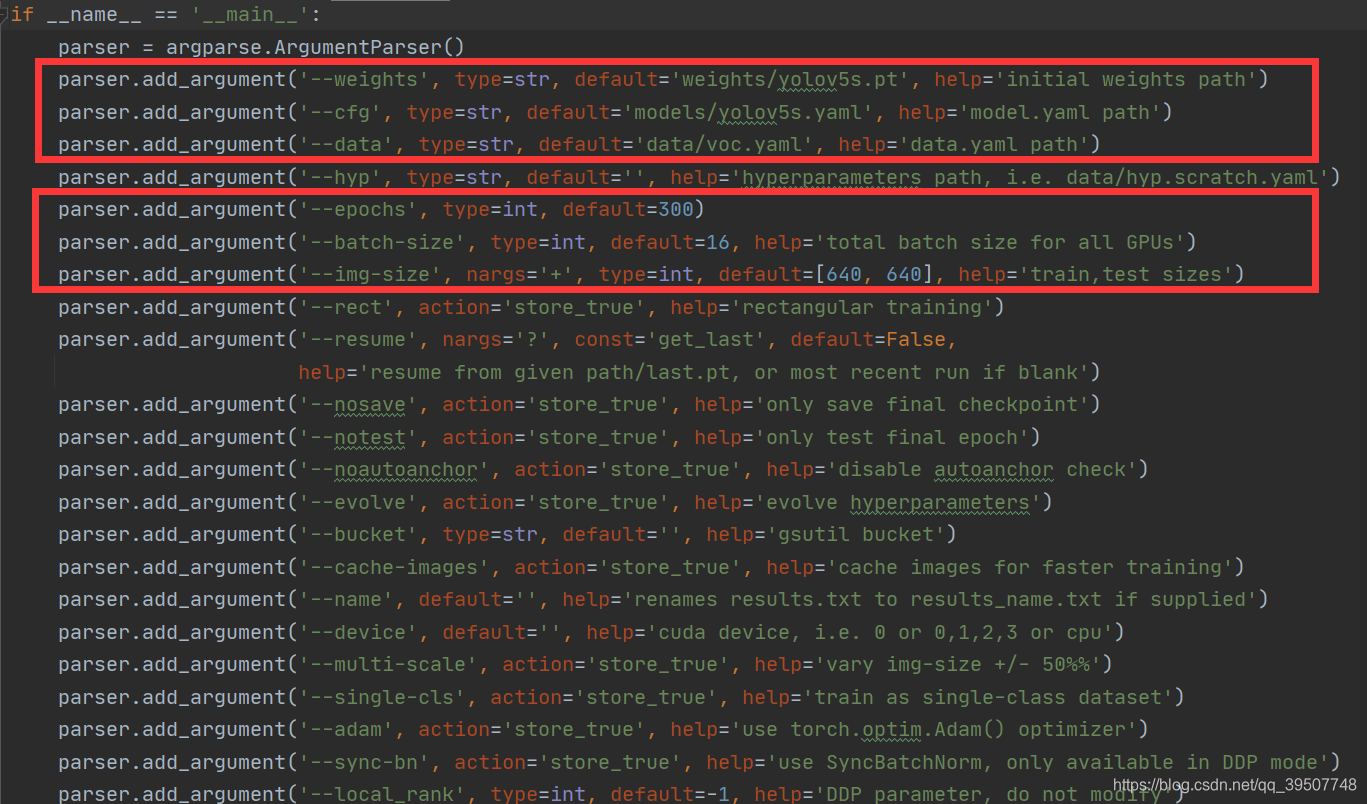
Cabe señalar que si weightsla ruta que especifica , es decir, el primer parámetro, si no existe, lo descargará por sí mismo. Si la descarga falla, puede descargar el archivo de peso inicial usted mismo y luego colocarlo en esta ruta.
Cinco, empieza a entrenar
Simplemente ejecute el train.pyarchivo directamente .