Solicitar biblioteca de solicitud
Cómo funcionan los rastreadores
Primero, revise el principio básico del funcionamiento del rastreador (el siguiente es un lenguaje escrito más formal):
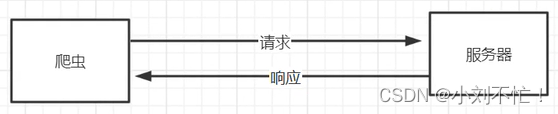
un rastreador es un programa automatizado que se utiliza para obtener información de Internet,
- Iniciar una solicitud: el rastreador primero debe iniciar una solicitud HTTP para solicitar el contenido de la página del sitio web de destino. Esta solicitud puede contener parámetros específicos, encabezados, autenticación, etc.
- Recibir la respuesta: después de que el sitio web de destino reciba la solicitud, devolverá una respuesta HTTP. La respuesta contiene el contenido de la página y otra información relevante, como el código de estado, la información del encabezado, etc.
- Análisis de la página: después de recibir la respuesta, el rastreador debe analizar la página para extraer los datos necesarios. Los métodos de análisis comúnmente utilizados incluyen expresiones regulares, XPath, selectores CSS, etc.
- Extraer datos: al analizar la página, el rastreador puede extraer los datos necesarios. Estos datos pueden ser información en varias formas, como texto, imágenes y enlaces.
- Almacenar datos: el rastreador almacena los datos extraídos en archivos o bases de datos locales para su posterior procesamiento y análisis.
- Procesar la página siguiente: después de rastrear los datos de una sola página, es posible que el rastreador deba procesar los datos de la página siguiente. Por lo general, esto implica una operación de cambio de página, y el contenido de la página siguiente se puede obtener simulando los clics del usuario o modificando los parámetros de la URL.
- Repita la operación: el rastreador puede realizar los pasos anteriores en un bucle según sea necesario para obtener más datos o información en diferentes páginas.
Pero para nosotros, lo que vemos es casi una interfaz gráfica, pero el rastreador puede devolver los parámetros correspondientes a la página. Esta parte está representada por un código, que no podemos ver en la superficie, como el código de estado, la página lleva Cookies. y más. El rastreador simula el proceso de nuestros usuarios visitando páginas web.
Solicitudes solicitud de biblioteca
Para acceder a la página web, también necesitamos la herramienta correspondiente - Solicitudes biblioteca de solicitudes.
La biblioteca de solicitudes Requests es una biblioteca de solicitudes HTTP, a través de la cual podemos iniciar una solicitud al sitio web.
Entorno de instalación
Instale la biblioteca en Pycharm. Si la instalación no tiene éxito, puede encontrar una fuente de espejo doméstica, por lo que la instalación será más fluida.
Uso de la biblioteca de Solicitudes
Abra pycharm, cree un nuevo archivo y luego ingrese las solicitudes de importación para ver si hay un error:

A continuación, comprenda la sintaxis simple de Solicitudes:
En Python, requestses una biblioteca de terceros popular para enviar solicitudes HTTP. Proporciona una interfaz simple y fácil de usar que facilita el envío de solicitudes HTTP. Aquí hay requestsalgunos usos comunes y sintaxis de la biblioteca:
- Enviar una solicitud GET:
import requests
response = requests.get(url)
¿Dónde urlestá la URL de destino a la que desea enviar la solicitud? requests.get()El método enviará una solicitud GET a la URL especificada y devolverá un Responseobjeto.
- Envíe una solicitud GET con parámetros:
import requests
payload = {
'key1': 'value1', 'key2': 'value2'}
response = requests.get(url, params=payload)
En el ejemplo anterior, payloadhay un diccionario que contiene los parámetros. requests.get()Los paramsparámetros del método le permiten agregar estos parámetros a la URL solicitada.
Debido a que el contenido de la solicitud GET se puede ver en el enlace, por ejemplo, la carga útil aquí se refiere a:

- Enviar una solicitud POST:
import requests
payload = {
'key1': 'value1', 'key2': 'value2'}
response = requests.post(url, data=payload)
En este ejemplo, payloadun diccionario que contiene los datos a enviar. requests.post()El método enviará una solicitud POST a la URL especificada y la usará payloadcomo los datos solicitados. Esto es diferente de la solicitud GET, estos parámetros no son visibles en el enlace abierto.
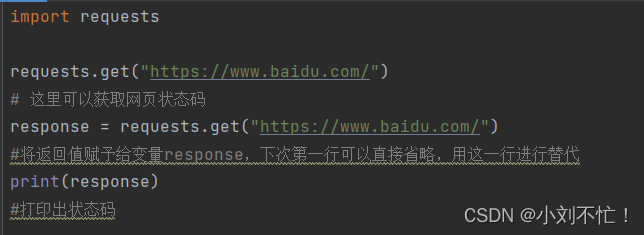
- Manejar la respuesta:
import requests
response = requests.get(url)
print(response.status_code) # 打印状态码
print(response.text) # 打印响应内容
response.status_codeEs el código de estado de la respuesta, que se utiliza para determinar si la solicitud es exitosa. response.textes el contenido de la respuesta, que se puede utilizar para obtener los datos devueltos por el servidor.
código de estado
Tome Baidu como ejemplo:

aquí está la URL para visitar.
El resultado de usar print(response.status_code) aquí es consistente con print(response).
Comprueba el resultado de la devolución:

el código de devolución es 200, lo que significa que podemos acceder con normalidad.
contenido web
A continuación, obtenga el contenido de la página web, o tome Baidu como ejemplo:
aquí, response.text se usa para la salida, y puede ver que se muestra el contenido de la página, pero algunos de ellos están distorsionados. Se puede encontrar en el código que la codificación original de la página web es utf-8, por lo que mantenemos la misma codificación original de la página web y la cambiamos a utf-8.
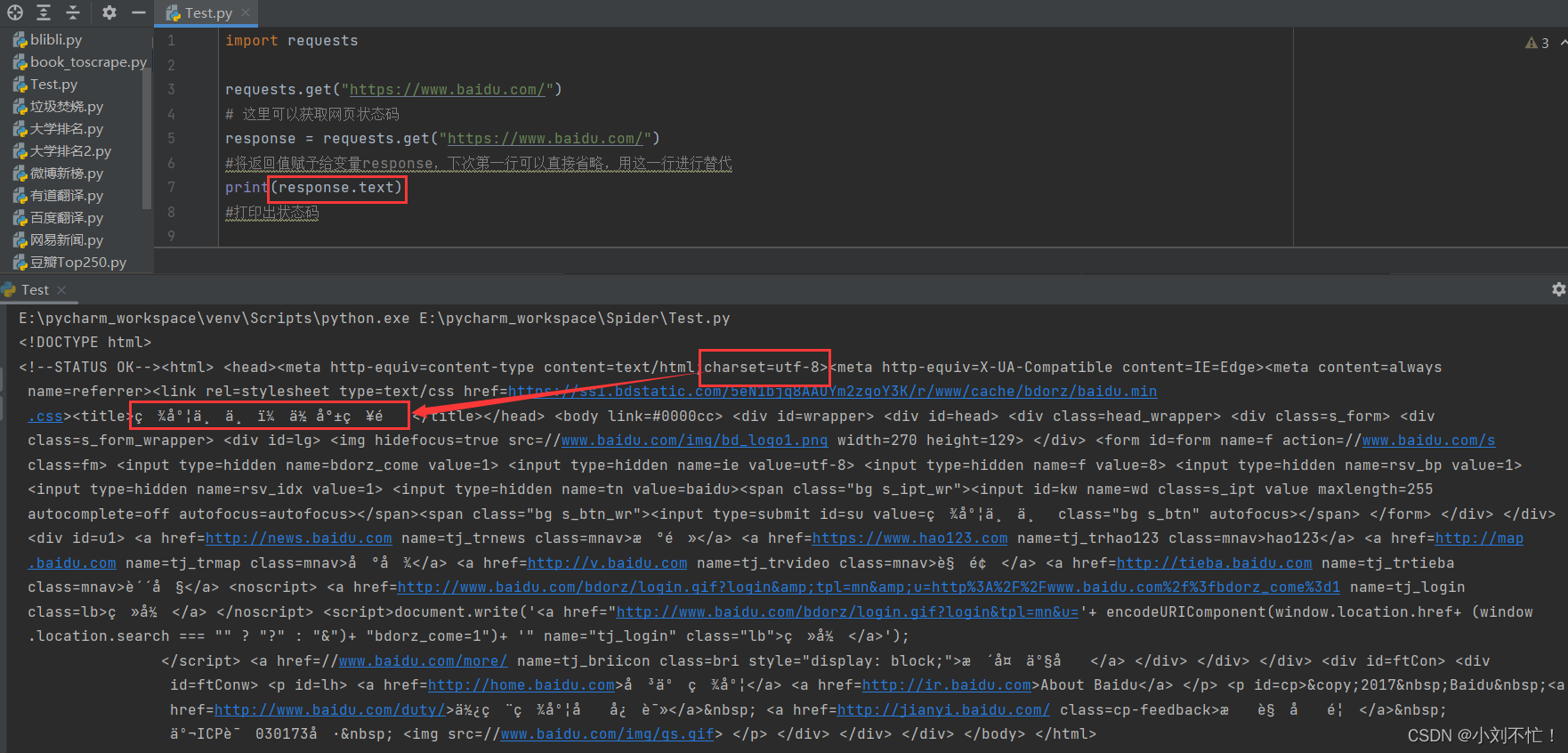
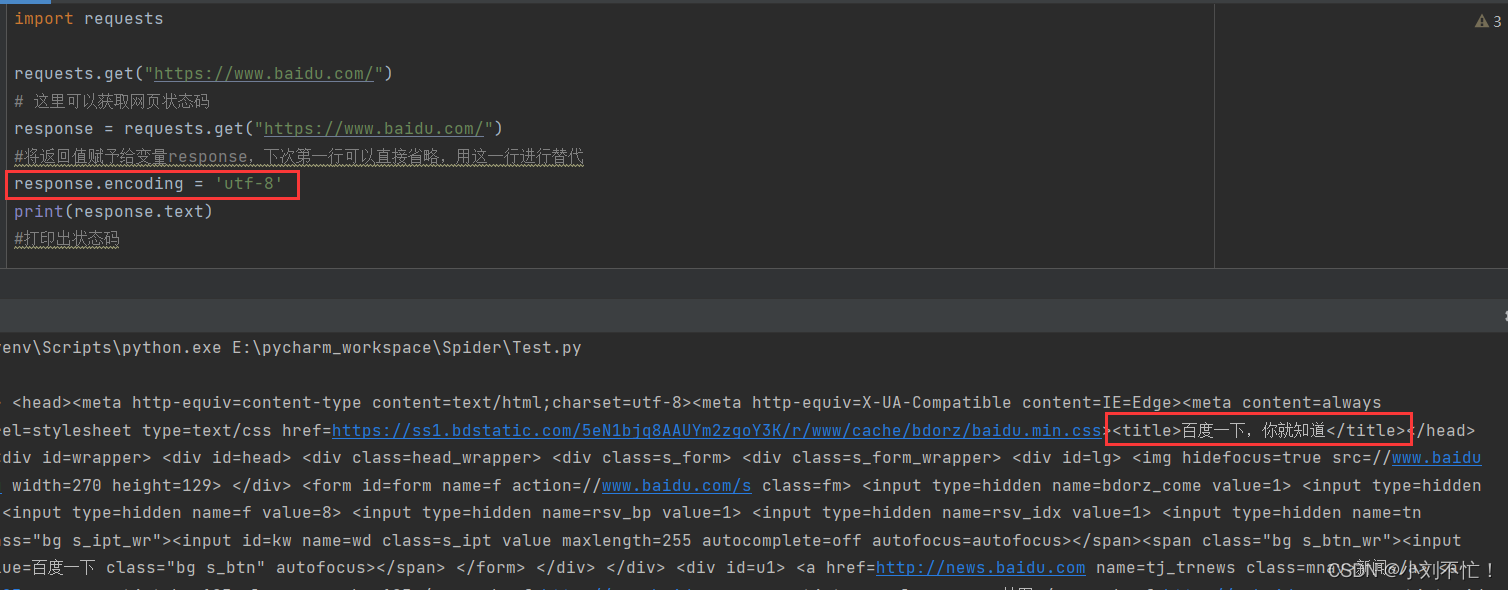
En este momento, el contenido de la página se puede mostrar normalmente.