Recientemente trabajé en un proyecto de reconocimiento de peleas, sintiendo la falta de materiales de desarrollo en ese momento, me gustaría hacer un resumen para su referencia. Chismes menos, veamos primero el efecto.
1. Estado de la investigación
En la actualidad, existen tres métodos principales para combatir la detección, a saber:
(1) Detección de lucha basada en Detección. La idea principal es: tomar la lucha como una categoría y detectar el comportamiento de lucha por clasificación. En la actualidad, hay pocos estudios en esta área y no hay conjuntos de datos disponibles públicamente.Si desea seguir este camino, debe traer su propio conjunto de datos y explorarlo usted mismo.
(2) Detección de peleas basada en puntos de esqueleto. La idea principal es devolver los puntos óseos del cuerpo humano a través de marcos como OpenPose y luego escribir lógica basada en los puntos óseos para hacer juicios. En la actualidad, algunas personas están haciendo detección de peleas basadas en esto. Sin embargo, si el personal se enreda durante la pelea, es más difícil usar las puntas de los huesos para hacer juicios precisos.
(3) Detección de peleas basada en la comprensión del video. La idea principal es juzgar en función del tiempo. Las peleas dependen en gran medida del tiempo, y el uso de la tecnología de detección de objetivos para identificar las peleas es propenso a la detección falsa o a la detección perdida. Además, si la superposición y oclusión de personas es grave, el reconocimiento de comportamiento basado en puntos esqueléticos tiene grandes limitaciones. La detección de peleas basada en la comprensión de videos puede resolver mejor estos problemas. Pero esto también es más difícil de lograr.
2. Plan seleccionado
Elijo la opción 1 aquí, que consiste en hacer un reconocimiento de combate basado en la detección de objetivos. Como se mencionó anteriormente, el conjunto de datos actual es muy escaso. El autor también buscó repetidamente y finalmente obtuvo un buen conjunto de datos del exterior. Teniendo en cuenta que es diferente de las tareas generales de detección de objetivos, el autor también marcó el conjunto de datos él mismo, sin involucrar a personal de terceros, con el fin de garantizar que el etiquetado sea razonable y preciso.
El flujo básico es:
Etiquetado de Labelme -> Organización de datos de etiquetado y conversión de formato -> Entrenamiento de modelo -> Despliegue
2.1 Etiquetado
El trabajo de desarrollo actual está en win11, utilizando la herramienta labelme de código abierto. También es la primera vez que el autor utiliza esta herramienta. Después de usarlo, descubrí que en realidad es bueno y las funciones son muy completas. Además, los conjuntos de datos externos que obtuve están en forma de videos, por lo que los videos deben convertirse primero en imágenes y luego etiquetarse. Para más detalles, consulte este artículo, que está bien escrito.
Video de anotación de Labelme ![]() https://www.pudn.com/news/623b0a3f49c1dc3c8980863b.html
https://www.pudn.com/news/623b0a3f49c1dc3c8980863b.html
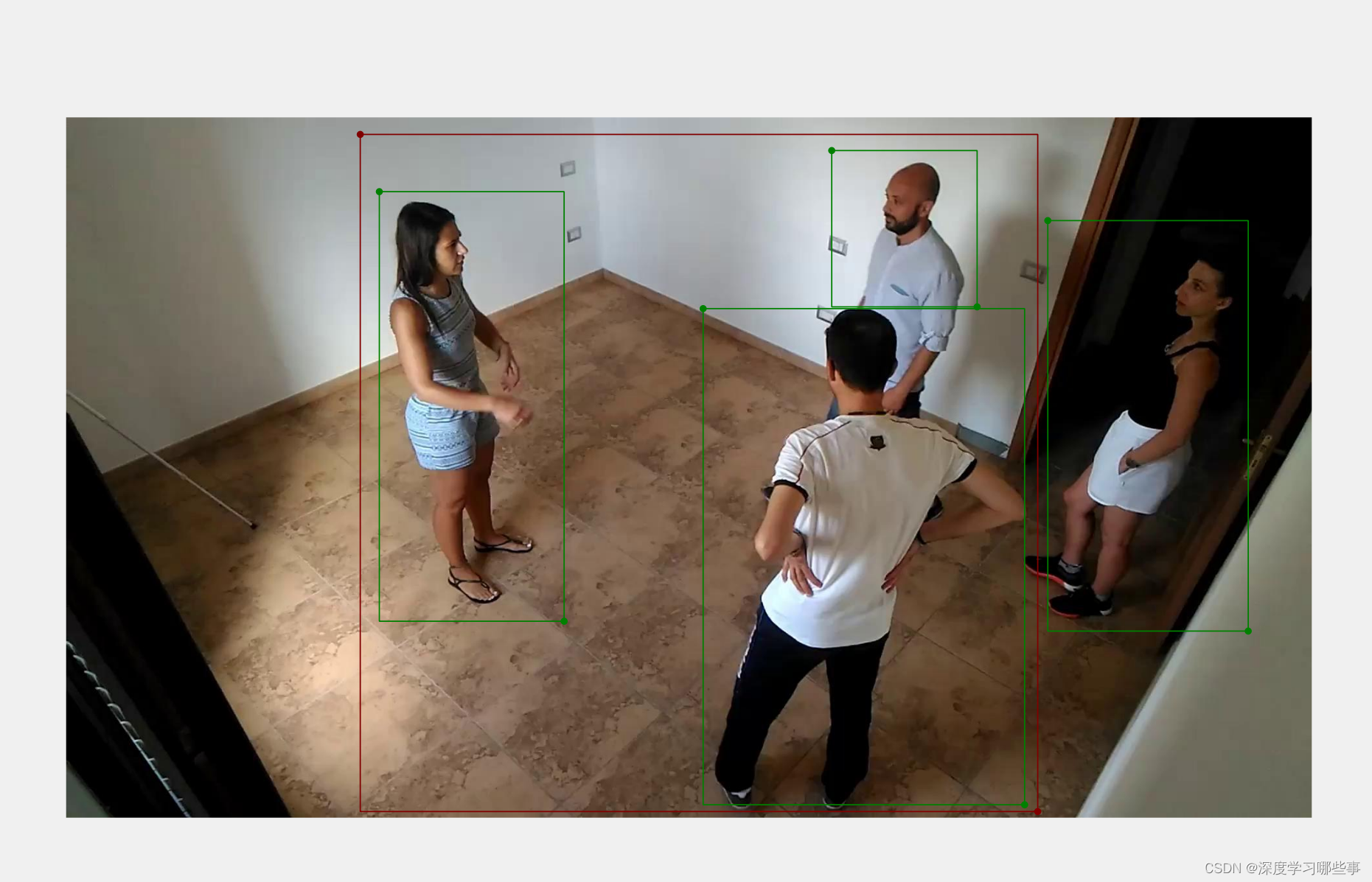
Fig.1 Uso de Labelme para el etiquetado de datos
Usando unos días de tiempo libre, el autor marcó miles de imágenes y luego eliminó algunas imágenes no válidas. La información del conjunto de datos marcado final es la siguiente:
| herramienta de marcado | Etiquetame |
| nombre del conjunto de datos | conjunto de datos de lucha |
| Cantidad de imagen/formato | Cerca de 800 hojas/jpg |
| Resolución de imagen | 1920*1080 |
| Formato de archivo de anotación | json |
| ¿Está clasificado? | No |
2.2 Recopilación de datos de etiquetado y conversión de formato
Los datos etiquetados por Labelme no se pueden usar directamente en el entrenamiento y debe convertirlos usted mismo. Debido a que se utilizará el algoritmo Yolo, aquí debemos convertir el formato Labelme al formato Yolo. Aquí está el script de conversión:
"""
2023.1.1
该代码实现了labelme导出的json文件,批量转换成yolo需要的txt文件,且包含了坐标归一化
原来labelme标注之后的是:1.jpg 1.json
经过该脚本处理后,得到的是1.jpg 1.json 1.txt
"""
import os
import numpy as np
import json
from glob import glob
import cv2
from sklearn.model_selection import train_test_split
from os import getcwd
classes = ["NOFight", "Fight", "Person"]
# 1.标签路径
labelme_path = "Data20200108/"
isUseTest = False # 是否创建test集
# 3.获取待处理文件
files = glob(labelme_path + "*.json")
files = [i.replace("\\", "/").split("/")[-1].split(".json")[0] for i in files]
print(files)
if isUseTest:
trainval_files, test_files = train_test_split(files, test_size=0.1, random_state=55)
else:
trainval_files = files
# split
train_files, val_files = train_test_split(trainval_files, test_size=0.1, random_state=55)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
wd = getcwd()
print(wd)
def ChangeToYolo5(files, txt_Name):
if not os.path.exists('tmp/'):
os.makedirs('tmp/')
list_file = open('tmp/%s.txt' % (txt_Name), 'w')
for json_file_ in files:
json_filename = labelme_path + json_file_ + ".json"
imagePath = labelme_path + json_file_ + ".jpg"
list_file.write('%s/%s\n' % (wd, imagePath))
out_file = open('%s/%s.txt' % (labelme_path, json_file_), 'w')
json_file = json.load(open(json_filename, "r", encoding="utf-8"))
height, width, channels = cv2.imread(labelme_path + json_file_ + ".jpg").shape
for multi in json_file["shapes"]:
points = np.array(multi["points"])
xmin = min(points[:, 0]) if min(points[:, 0]) > 0 else 0
xmax = max(points[:, 0]) if max(points[:, 0]) > 0 else 0
ymin = min(points[:, 1]) if min(points[:, 1]) > 0 else 0
ymax = max(points[:, 1]) if max(points[:, 1]) > 0 else 0
label = multi["label"]
if xmax <= xmin:
pass
elif ymax <= ymin:
pass
else:
cls_id = classes.index(label)
b = (float(xmin), float(xmax), float(ymin), float(ymax))
bb = convert((width, height), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
print(json_filename, xmin, ymin, xmax, ymax, cls_id)
ChangeToYolo5(train_files, "train")
ChangeToYolo5(val_files, "val")
# ChangeToYolo5(test_files, "test")
2.3 Entrenamiento modelo
Aquí uso el algoritmo yolov5 con una mejor respuesta y uso Pycharm para el desarrollo. Aquí hay una breve introducción a yolov5: yolov5 es una red de aprendizaje profundo bien diseñada, que es muy útil para tareas de detección de objetivos. Al mismo tiempo, el autor también proporcionó cuidadosamente una serie de secuencias de comandos, como conversión e implementación de modelos, que se puede decir que son muy fáciles de usar. Y el repositorio se actualiza constantemente, con muchos desarrolladores, elegir este modelo ahorra tiempo, esfuerzo y preocupaciones. Aquí el autor usa la versión yolov5-6.1 y no se han verificado otras versiones.
Figura 2 yolov5-v6.1
Descargue el repositorio localmente y ábralo con pycharm:

Fig.3 proyecto abierto pycharm
Luego use anaconda para configurar el entorno yolov5. No se ampliará aquí, amigos que no saben cómo configurar, pueden consultar aquí: annconda configura el entorno virtual
La tarjeta gráfica del autor es 3070Ti, por lo que se configura un entorno virtual compatible con cuda, como se muestra en la siguiente figura. Basado en el entorno cuda, la velocidad de entrenamiento es rápida, que puede alcanzar de 20 a 40 veces la de la cpu. Si no hay una tarjeta N independiente, debe configurar el entorno virtual de la CPU, que también se puede usar, pero la velocidad será mucho más lenta.
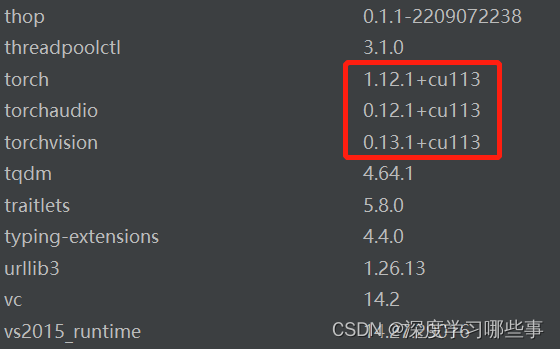
Fig.4 entorno virtual de configuración de anaconda
El autor usa torch1.12.1+cu113 aquí Veo que muchos blogs todavía te enseñan a usar torch1.7.1, lo cual es realmente engañoso. Aquí, debido a que yolov5 se usa para entrenar nuestro propio conjunto de datos, necesitamos hacer algunas configuraciones aquí, incluida la configuración del conjunto de datos, la escritura de archivos de configuración, etc., y a continuación se brindan algunas instrucciones detalladas.
2.3.1 Configuración del conjunto de datos:
El conjunto de datos para la lucha es nuestro Data20200108 aquí, en el que hay imágenes de train y val, y todas las imágenes originales se almacenan en él. Los archivos etiquetados se almacenan en etiquetas, todos los cuales se convierten en archivos txt.Al igual que las imágenes, también se dividen en train y val.
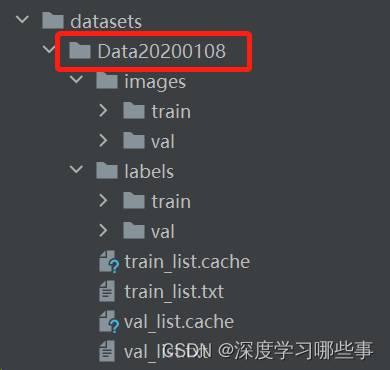
Fig.5 Configure su propio conjunto de datos
Los archivos train_list.txt y val_list.txt aquí son la ruta de la imagen del conjunto de datos de entrenamiento y la ruta del conjunto de datos de prueba. El extracto es para que lo veas:
datasets/Data20200108/images/train/cam1_100000.jpg
datasets/Data20200108/images/train/cam1_100001.jpg
datasets/Data20200108/images/train/cam1_100002.jpg
datasets/Data20200108/images/train/cam1_100003.jpg
datasets/Data20200108/images/train/cam1_100004.jpg
datasets/Data20200108/images/train/cam1_100005.jpg
datasets/Data20200108/images/train/cam1_100006.jpg
datasets/Data20200108/images/train/cam1_100007.jpg
datasets/Data20200108/images/train/cam1_100008.jpg2.3.2 Escritura del archivo de configuración:
En la carpeta de datos, creamos un nuevo script fight_person.yaml y escribimos un archivo de configuración.
 Fig.6 Escritura del archivo de configuración
Fig.6 Escritura del archivo de configuración
Bueno, todo el trabajo preparatorio se ha completado. A continuación, seleccionamos el script de entrenamiento train.py y configuramos los siguientes parámetros para entrenar.
--data fight_person.yaml --weights yolov5s.pt --img 640 --batch-size 8 --device 0 --epochs 10 --workers 0
Permítanme introducir brevemente el significado:
--data: el script de configuración correspondiente, que contiene la ruta de la imagen, la categoría y otra información
--pesos: archivo de peso, aquí elijo yolov5s.pt
--img: resolución de entrenamiento, el autor elige la predeterminada 640
--batch-size: tamaño del lote, esto está relacionado con el rendimiento de la máquina, el rendimiento es bueno, cuanto mayor sea el número
--dispositivo: dispositivo, si no hay tarjeta gráfica, escribe cpu, si es una sola tarjeta gráfica, escribe 0, varias tarjetas escriben 0, 1, 2 según la situación real...
-épocas: el número de iteraciones
2.3.3 Empezar a entrenar
Después de los resultados del entrenamiento, obtuvimos algunos registros de entrenamiento en run/train/, escojamos algunos clave para ver:

Fig.7 Gráfico de índice de entrenamiento
La información en la imagen de arriba es relativamente completa, podemos ver claramente que la pérdida está disminuyendo rápidamente y el mAp está aumentando rápidamente. Significa que convergerá pronto. Para las tareas de detección, el índice de evaluación es principalmente mAP, para obtener más información, consulte aquí:
interpretación de mAp ![]() https://blog.csdn.net/HUAI_BI_TONG/article/details/121212733
https://blog.csdn.net/HUAI_BI_TONG/article/details/121212733
Puede entenderse simplemente que cuanto mayor sea el mAP, mejor será el efecto. En la carpeta generada automáticamente por el entrenamiento, hay algunas fotos:

Fig.8 Casilla marcada manualmente

Fig.9 Caja de detección de modelo
Se puede ver que el efecto sigue siendo muy bueno, el marco marcado y el marco real pueden coincidir básicamente, lo que significa que nuestro modelo encaja bien.
3. Conclusión
Lo anterior es todo el contenido del uso de yolov5 para entrenar su propio conjunto de datos, incluido el etiquetado del conjunto de datos, la producción, la configuración del entorno de entrenamiento, el análisis del proceso de entrenamiento, etc. En el próximo artículo, haremos el desarrollo de la interfaz. Inteligencia artificial junto con un hermoso abrigo, graznido a la fuerza.