Indique la fuente de la reimpresión: La teoría del Big Bang del mayor Xiaofeng [xfxuezhang.cn]
Este contenido es resultado de la traducción automática, si tiene alguna objeción se recomienda leer el texto original.
Algunos puntos a tener en cuenta sobre la traducción automática, como por ejemplo:
- Época, era => época
- trabajador => trabajador
- entrenar, entrenar, entrenador => entrenar
Tabla de contenido
Cargador de datos eficiente para un entrenamiento GNN rápido basado en muestreo en gráficos grandes
Antecedentes y motivación Antecedentes y motivación
2.1 Graficar redes neuronales Graficar redes neuronales
2.2 Entrenamiento basado en muestreo con GPU Uso de GPU para entrenamiento basado en muestreo
2.3 Problemas y Oportunidades Problemas y Oportunidades
3.2 Entrenamiento y partición en paralelo de datos Entrenamiento y partición en paralelo de datos
3.3 Canalización de carga de datos y cálculo GNN Canalización de carga de datos y cálculo GNN
5.1 Configuración experimental 5.1 Configuración experimental
5.2 Rendimiento de una sola GPU Rendimiento de una sola tarjeta gráfica
5.4 Rendimiento de múltiples GPU Rendimiento de múltiples tarjetas gráficas
5.5 Implicaciones de la partición de gráficos El significado de la partición de gráficos
5.6 Efectos de la canalización
5.7 Impacto de los volúmenes de carga de datos Impacto de los volúmenes de carga de datos
5.8 Respaldo de otros métodos de muestreo Respaldo de otros métodos de muestreo
5.9 Convergencia del entrenamiento Convergencia del entrenamiento
Trabajo relacionado Trabajo relacionado
Discusión y trabajo futuro Discusión y trabajo futuro
Cargador de datos eficiente para un entrenamiento GNN rápido basado en muestreo en gráficos grandes
Abstracto
Las redes neuronales de gráficos (GNN) emergentes han extendido el éxito de las técnicas de aprendizaje profundo para conjuntos de datos como imágenes y texto a datos estructurados en gráficos más complejos. Al aprovechar los aceleradores de GPU, los marcos existentes combinan mini lotes y muestreo para un entrenamiento de modelos eficaz y eficiente en gráficos grandes. Sin embargo, esta configuración enfrenta problemas de escalabilidad, ya que la carga de características de vértices enriquecidas desde la CPU a la GPU a través de enlaces de ancho de banda limitados a menudo domina el ciclo de entrenamiento. En este artículo, proponemos PaGraph, un cargador de datos novedoso y eficiente que admite entrenamiento GNN general y eficiente basado en muestreo en un único servidor con múltiples GPU. PaGraph reduce significativamente los tiempos de carga de datos al utilizar los recursos de GPU disponibles para mantener en caché los datos de gráficos a los que se accede con frecuencia. También incorpora una estrategia de almacenamiento en caché liviana pero efectiva que considera simultáneamente la información de la estructura del gráfico y los patrones de acceso a los datos para el entrenamiento GNN basado en muestreo. Además, para escalar horizontalmente en múltiples GPU, PaGraph desarrolló un rápido algoritmo de partición con reconocimiento de computación GNN para evitar accesos entre particiones durante el entrenamiento de datos en paralelo y lograr una mejor eficiencia de la caché. Finalmente, superpone la carga de datos y el cálculo de GNN para ocultar aún más el costo de carga. La evaluación de dos modelos GNN representativos, GCN y GraphSAGE, utilizando métodos de muestreo por capas y de adyacencia, muestra que PaGraph puede eliminar el tiempo de carga de datos de los canales de entrenamiento de GNN y lograr una aceleración del rendimiento de hasta 4,8 veces con respecto a la tecnología de última generación. líneas de base. . Combinado con la optimización del preprocesamiento, PaGraph proporciona además una aceleración de extremo a extremo de hasta 16,0×.
Introducción Introducción
Recientemente, se han propuesto redes neuronales gráficas (GNN) [1] [2] [3] [4] para extender las redes neuronales profundas desde el procesamiento de datos no estructurados, como imágenes y texto, hasta datos de gráficos estructurados, y se han aplicado con éxito a varios importantes tareas, incluida la clasificación de vértices [2], [3] predicción de enlaces [5] , [4] extracción de relaciones [6] y traducción automática neuronal [7] Sin embargo, por un lado, los métodos tradicionales como PowerGraph [8] Por otro lado, los marcos de aprendizaje profundo actualmente populares (como TensorFlow [9] ) no tienen soporte suficiente para las abstracciones de planificación de vértices y las primitivas de operación de gráficos. Para cerrar la brecha entre estos dos campos, se han propuesto nuevos sistemas como DGL, Python [10] Geométrico, MindSpore [11] GraphEngine [12] y NeuGraph [13] para proporcionar gráficos convenientes y eficientes compatibles con las primitivas de operación GNN.
Muchos gráficos del mundo real son enormes. Por ejemplo, la instantánea más reciente del gráfico de amistad de Facebook consta de 700 millones de vértices y más de 100 mil millones de aristas [14] . Además de los datos estructurados en gráficos, las características de alta dimensión (normalmente entre 300 y 600) asociadas con vértices y aristas dan como resultado una mayor complejidad computacional y de almacenamiento. Dadas las limitaciones de tiempo y recursos, ejecutar un tren de gráficos gigante completo como un lote ya no es eficiente ni siquiera factible. Por lo tanto, un enfoque típico es el muestreo [2], que muestrea repetidamente subgrafos del gráfico original como entrada al mini lote, [15] reduciendo así el cálculo de un solo mini lote, [16] sin dejar de converger con la precisión esperada.
Desafortunadamente, el entrenamiento GNN basado en muestreo enfrenta graves problemas de rendimiento en la carga de datos. En particular, cuando se cargan características de vértice de alta dimensión (por ejemplo, descripciones de usuario, incrustaciones semánticas en papel), el movimiento de datos desde la memoria del host a la memoria de la GPU requiere mucho tiempo [17] . Por ejemplo, observamos que cuando utilizamos una sola GPU para entrenar el modelo GCN [3] en el conjunto de datos LiveJournal [18] , el 74% del tiempo de entrenamiento se dedica a la carga de datos. La razón principal es que los modelos GNN suelen utilizar redes neuronales profundas con una complejidad computacional relativamente baja en comparación con datos masivos. Por lo tanto, los cálculos GNN realizados en la GPU toman mucho menos tiempo que la carga de datos. Peor aún, cuando se utilizan varias GPU en una máquina para acelerar el entrenamiento, la demanda de muestras de datos que se cargan desde la CPU a la GPU crece proporcionalmente. Algunas estrategias optimizadas, como el preprocesamiento [19] , podan el modelo GNN para obtener un mejor rendimiento del entrenamiento. Sin embargo, incluso con estas estrategias optimizadas, el movimiento de datos sigue dominando el proceso de formación.
Este artículo se centra en cómo acelerar el entrenamiento GNN de gráficos grandes basado en muestreo en máquinas con múltiples GPU. Nuestra idea clave es reducir la sobrecarga del movimiento de datos entre CPU y GPU. Este trabajo se basa principalmente en las siguientes observaciones. En primer lugar, debido a la referencia a vértices y estructuras de gráficos en los cálculos de GNN, diferentes iteraciones de entrenamiento pueden utilizar mini lotes de datos superpuestos y exhibir patrones de acceso a vértices redundantes. Como se muestra en el estudio de caso a continuación (Sección 2.3), puede cargar hasta 4 veces el número de vértices durante épocas en comparación con la población de vértices del gráfico objetivo. En segundo lugar, en cada iteración, el cálculo de entrenamiento solo necesita retener el subgrafo muestreado correspondiente al mini lote actual, que solo consume una pequeña porción (por ejemplo, no más del 10%) de la memoria de la GPU. Por lo tanto, el resto de la memoria de la GPU queda libre para almacenar en caché las características de los vértices a los que se accede con más frecuencia, evitando cargas repetidas desde la memoria del host. Sin embargo, los cargadores de datos actuales aún no han explorado la disponibilidad de memoria GPU adicional para implementarlo.
La introducción del caché para acelerar el entrenamiento GNN basado en muestreo enfrenta los siguientes desafíos del sistema. En primer lugar, debido al patrón de acceso aleatorio de la naturaleza del muestreo, es difícil predecir a qué datos del gráfico se accederá en el próximo mini lote. En lugar de predecir los siguientes datos del gráfico al que se accede, aprovechamos el hecho de que los vértices con mayor grado de salida tienen una mayor probabilidad de ser muestreados en el mini lote. Después de esto, como primera contribución, adoptamos una estrategia de almacenamiento en caché estático para guardar los datos gráficos a los que se accede con frecuencia en la memoria de la GPU e introducimos un nuevo mecanismo de carga de datos habilitado para caché. Cuando el mini lote muestreado llega a la GPU, los datos de funciones requeridos se obtienen del caché de la GPU local y de la memoria del host administrada por el servidor de almacenamiento de gráficos original.
En segundo lugar, los diseños de sistemas actuales equilibran las cargas de trabajo de entrenamiento en múltiples GPU y al mismo tiempo comparten una única copia de los datos gráficos completos entre ellas. Este paralelismo de un solo gráfico hace que la solución de almacenamiento en caché anterior sea ineficiente. Para evitar esta ineficiencia, como segunda contribución, adaptamos el "paralelismo de datos" al entrenamiento GNN basado en muestreo con almacenamiento en caché en una única máquina con múltiples GPU, donde cada GPU trabaja en su partición de gráficos. Obviamente, el beneficio del paralelismo de datos es que se puede mejorar la localidad de los datos y aumentará el número total de vértices almacenados en caché. Con este fin, diseñamos un nuevo algoritmo de partición de gráficos compatible con GNN, que difiere del algoritmo de partición de gráficos general tradicional [20] en dos aspectos [21] . Primero, para equilibrar las cargas de trabajo de entrenamiento entre las GPU, debemos asegurarnos de que cada partición contenga una cantidad similar de vértices objetivo de entrenamiento relevantes para la carga de trabajo, en lugar de vértices arbitrarios. En segundo lugar, para evitar accesos entre particiones durante el muestreo, duplicamos para cada vértice del tren en su partición sus L vecinos accesibles para todos los saltos. Dado que L normalmente no es mayor que 2, [2], [3], [4] y nuestro algoritmo de partición está altamente optimizado, la redundancia generada por L es aceptable.
En tercer lugar, la mejora del rendimiento que aporta el almacenamiento en caché es proporcional al número de vértices almacenados en caché de alto grado. Dado que la memoria de la GPU suele estar limitada a entre 10 y 30 GB, es posible que el mecanismo de almacenamiento en caché no sea suficiente para admitir cálculos GNN en gráficos grandes donde la mayoría de los vértices no se pueden almacenar en caché. Por ejemplo, para entrenar GCN [3] en el gráfico enwiki [22] , solo se puede almacenar en caché hasta el 51,2% de sus vértices usando una sola GPU. Esto redujo el tiempo de carga de datos de 38,9 ms a 9,7 ms, pero aún así representó el 34,3% del tiempo de entrenamiento en una sola iteración. Para complementar el almacenamiento en caché y la partición, exploramos más a fondo oportunidades para ocultar la sobrecarga de carga de datos en el tiempo de cálculo. Esto requiere que diseñemos una nueva canalización para paralelizar el cálculo del minilote actual y la captura previa de datos del gráfico para el siguiente minilote.
Integramos los conceptos de diseño anteriores en PaGraph, un cargador de datos novedoso y eficiente para admitir el entrenamiento GNN basado en muestreo en gráficos grandes en una única máquina con múltiples GPU. PaGraph se integra aún más con Deep Graph Library (DGL) [10] y PyTorch [23] . Entrenamos dos GNN conocidos y comúnmente evaluados, GCN [3] y GraphSAGE [2], en siete gráficos del mundo real a gran escala utilizando dos algoritmos de muestreo importantes, a saber, muestreo de vecinos y muestreo capa por capa [2][ 15]. Los resultados experimentales muestran que PaGraph protege completamente la sobrecarga de carga de datos de cada ciclo de entrenamiento y, aunque converge aproximadamente con la misma precisión dentro del mismo número de épocas, logra una aceleración de hasta 4,8 veces en comparación con DGL, en el que el caché y la canalización Las estrategias contribuyeron respectivamente entre el 70% y el 75% y entre el 25% y el 34% a la aceleración general. Combinado con la optimización del preprocesamiento, PaGraph incluso logra una aceleración de hasta 16,0× DGL.
En resumen, hicimos las siguientes contribuciones:
-
El análisis del entrenamiento GNN basado en muestreo en un único servidor con múltiples GPU muestra que el rendimiento del entrenamiento se ha convertido en un cuello de botella en la carga de datos.
-
PaGraph, un novedoso cargador de datos, se utiliza para fusionar cachés de GPU estáticas, reduciendo así la cantidad de datos enviados desde la memoria del host a la GPU. Esto se mejora aún más mediante (1) la partición del gráfico para aprovechar una mejor localidad de datos para el entrenamiento GNN de múltiples GPU y (2) la carga de datos canalizada y el cálculo GNN, mitigando así la posible contención de memoria de la GPU entre la caché de la GPU y el cálculo. .
-
PaGraph se evalúa en profundidad en comparación con DGL, la biblioteca GNN de última generación, que incluye dos modelos GNN representativos y siete gráficos del mundo real.
-
Se proporciona una discusión visionaria sobre las limitaciones, el alcance de la aplicación, las oportunidades y desafíos de generalización y las direcciones futuras de PaGraph.
Antecedentes y Motivación Antecedentes y Motivación
2.1 Graficar redes neuronales Graficar redes neuronales
En este trabajo, nos centramos en los gráficos de atributos, donde además de la información estructural del gráfico, los vértices o aristas están asociados con una gran cantidad de características (generalmente más de cientos). Los modelos GNN suelen constar de varias capas. La figura 1 muestra la arquitectura del modelo GNN de dos capas, donde el azul y el verde representan la primera y la segunda capa respectivamente.
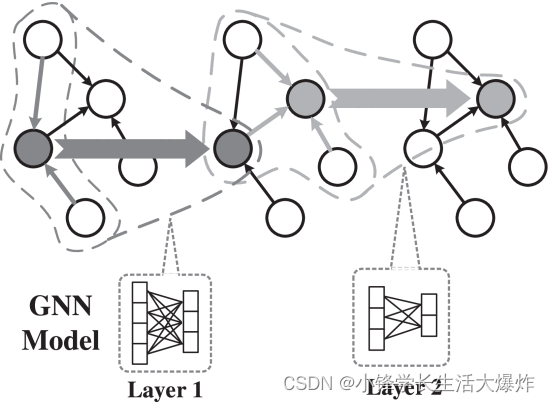
El cálculo en diferentes capas sigue el modelo tradicional de procesamiento iterativo de gráficos centrado en vértices [8] . [24] En cada capa, cada vértice sigue sus bordes entrantes para agregar características de los vecinos (flechas delgadas) y luego usa una red neuronal para convertir las características en características de salida (flechas gruesas), que servirán como características de entrada [2] Pasa a la siguiente capa. En la misma capa, todos los vértices comparten la misma red neuronal de agregación y red neuronal de transformación. Una única capa GNN solo puede implementar información transmitida desde vértices vecinos directos (1 salto). Para 2 capas GNN, podemos conectar vecinos de 2 saltos ingiriendo la salida de la capa anterior como entrada para la siguiente capa. De manera similar, en un GNN de capa L, un vértice puede recopilar información de sus vecinos en L saltos. La salida de la última capa se puede utilizar para mejorar tareas como la clasificación de vértices [2], [3] o como incrustaciones para la extracción de relaciones [6] .
2.2 Entrenamiento basado en muestreo con GPU Uso de GPU para entrenamiento basado en muestreo
Entrenar un modelo GNN para lograr la precisión deseada generalmente requiere docenas de épocas, y cada época se define como un escaneo completo de todos los vértices de entrenamiento del gráfico objetivo. Una época consta de una serie de iteraciones; durante cada iteración, se selecciona aleatoriamente un pequeño lote de vértices de entrenamiento para evaluar y actualizar el modelo. Sin embargo, a diferencia de los datos de entrenamiento, como imágenes y oraciones, donde cada muestra de datos es independiente, los datos gráficos están altamente estructurados y conectados. Por lo tanto, el entrenamiento en vértices requiere cargar no solo los datos relacionados con el vértice, sino también los datos de sus bordes de enlace y vértices de conexión, lo que hace que la carga de datos en GNN sea muy diferente del entrenamiento de aprendizaje automático tradicional.
El patrón único de acceso a datos del cálculo GNN hace que sea difícil manejar de manera eficiente el crecimiento exponencial en el número de vértices y sus características asociadas para entrenar capas GNN. Por el contrario, para resolver este problema, el muestreo como solución de optimización típica se adopta ampliamente [2] [15] [16] [19] El entrenamiento basado en muestreo selecciona un número limitado de mini lotes de saltos de capa que pueden llegar a los vecinos . y lograr casi la misma precisión de entrenamiento a un menor costo computacional [19].
Además, las unidades de procesamiento de gráficos (GPU) brindan una densidad informática y una flexibilidad de programación sin precedentes y son compatibles con casi todos los marcos de aprendizaje profundo, incluidos PyTorch, TensorFlow [23] [9] y MXNet [25] , lo que las convierte en una opción ideal para el aprendizaje profundo. entrenamiento Acelerador estándar de facto. Las GPU, que constan de una gran cantidad de procesadores potentes y memoria GPU dedicada de gran ancho de banda, son una excelente opción para realizar cálculos relacionados con tensores. Por lo tanto, las bibliotecas GNN existentes, como DGL, siguen la misma práctica de utilizar GPU para acelerar el entrenamiento. Nuestros experimentos muestran que cuando se entrena un modelo GCN [3] a través del conjunto de datos LiveJournal [18] , una sola GPU 1080Ti proporciona 3 veces el rendimiento de la configuración de solo CPU (16 núcleos). A medida que haya más GPU involucradas, la brecha de rendimiento se ampliará gradualmente.
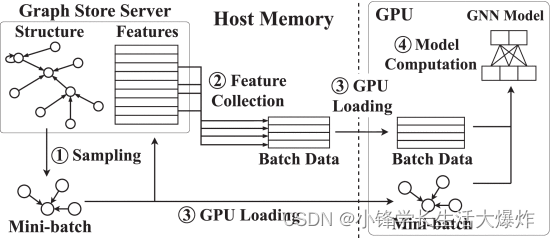
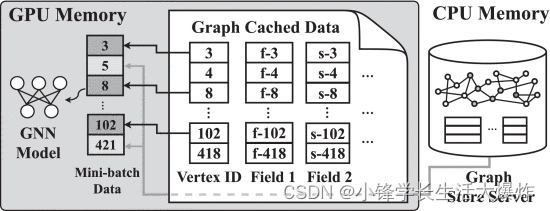
La figura 2 muestra el flujo de trabajo del entrenamiento GNN basado en muestreo basado en GPU. Hay un servidor de almacenamiento de gráficos global que administra la estructura de gráficos completa, así como los datos de funciones en la memoria de la CPU. Cada iteración de entrenamiento implica tres pasos principales, a saber, muestreo ((1)), carga de datos ((2)-(3)) y cálculo del modelo ((4)). En cada iteración, el muestreador de datos recopila aleatoriamente una cantidad de vértices de entrenamiento (tamaño de mini lote), luego atraviesa la estructura del gráfico y toma muestras de sus vértices vecinos de salto L para formar muestras de datos de entrada ((1)). Como ejemplo representativo entre los métodos de muestreo, Neighborhood Sampling (NS) [2] simplemente selecciona una pequeña cantidad de vecinos aleatorios del vértice actualmente visitado. Por ejemplo, en el muestreo de 2 vecinos, como se muestra en la Fig. 3, para entrenar el vértice v1, selecciona v2, v5 de sus vecinos de 1 salto. Luego, toma muestras de los intravecinos de 2 saltos v6,v2,v9,v8 de los vecinos directos del vértice v2,v5 de 1 salto seleccionado. El paso de carga de datos prepara los datos de características para el cálculo de la GPU. Aquí queremos enfatizar que la carga de datos es más que simplemente transferir datos de la CPU a la GPU a través de PCIe. En cambio, el proceso de carga de datos pasa por las dos etapas siguientes. El cargador de datos elige un mini lote y consulta el almacenamiento de gráficos para recopilar características de todos los vértices del lote ((2)) y carga estas muestras en la memoria de la GPU a través del enlace PCIe ((3)). Finalmente, el entrenador en la CPU inicia el kernel de la GPU y realiza cálculos GNN en la GPU en las muestras de datos cargadas ((4)). Este proceso se ejecutará de forma iterativa hasta que el modelo objetivo converja.

2.3 Problemas y OportunidadesProblemas y Oportunidades
A pesar de aprovechar los potentes recursos informáticos proporcionados por la GPU, todavía hay mucho margen para mejorar el entrenamiento de GNN utilizando la GPU. En particular, el entrenamiento GNN basado en muestreo basado en GPU tiene serios problemas de carga de datos que deben resolverse. Para comprender esto, entrenamos un GCN de 2 capas [3] en 1 a 4 GPU como ejemplo de tutorial. Creamos minilotes de vértices para cada iteración de entrenamiento utilizando el muestreo de vecinos y el muestreo por capas (LS) ampliamente utilizados [15] . LS es casi lo mismo que NS, excepto que trata una capa como un todo y limita el número total de vértices muestreados por capa en lugar de por vértice, evitando así que el número de vértices muestreados crezca exponencialmente a medida que la capa se profundiza. Como lo sugiere el trabajo existente [15], [19] el método de muestreo de vecindad aquí selecciona 2 vecindades para cada vértice, mientras que el método de muestreo capa por capa limita el número de vértices muestreados por capa a 2400. A continuación, informamos nuestras principales observaciones sobre las ineficiencias del desempeño y revelamos sus causas fundamentales, que en conjunto motivaron el diseño de nuestro trabajo. Comenzamos con el entrenamiento de una sola GPU en la popular biblioteca DGL [26] y la GPU GTX-1080Ti.
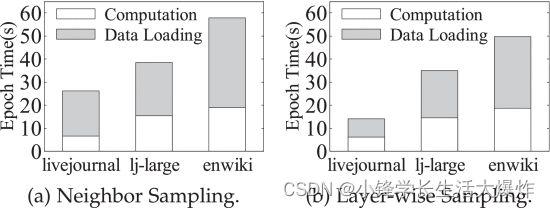
La carga de datos domina el tiempo de entrenamiento. En experimentos [22] en 3 grandes gráficos del mundo real (livejournal [18] , lj-large [27] y enwiki) , encontramos que la carga de datos de la CPU a la GPU generalmente domina el tiempo de entrenamiento GNN de un extremo a otro. En los experimentos, adoptamos un modelo GNN representativo, a saber, GCN de 2 capas [3], y utilizamos muestreo de vecindario y muestreo capa por capa [2] [15] ampliamente utilizados para crear pequeños lotes de vértices para el entrenamiento. . La figura 4 resume el tiempo de la época de entrenamiento en diferentes gráficos y muestra el desglose del tiempo en carga y cálculo de datos. Tenga en cuenta que omitimos la sobrecarga de muestreo porque el muestreo se ejecuta más rápido que la carga de datos y ya se superpone con la carga de datos. Claramente, en los tres conjuntos de datos de gráficos, la carga de datos lleva mucho más tiempo que el cálculo. Por ejemplo, GCN en livejournal dedicó el 74 % y el 56 % del tiempo de capacitación de un extremo a otro a la carga de datos cuando utilizó muestreo vecino y capa por capa, respectivamente. Esta situación empeora cuando se utilizan varias GPU para entrenar conjuntamente un modelo compartido, ya que el tiempo de cálculo se reducirá y la sobrecarga de carga de datos se volverá más dominante.
Con un profundo conocimiento de los resultados, identificamos los siguientes factores que ralentizan gravemente todo el proceso de formación. Al mismo tiempo, también nos brindan la oportunidad de mejorar aún más el rendimiento del entrenamiento GNN basado en el muestreo de GPU.
Patrones redundantes de acceso a vértices. Continuamos observando la cantidad total de datos enviados desde la CPU a la GPU para completar el ciclo de entrenamiento. Sorprendentemente, la cantidad de datos cargados puede exceder 4 veces el número total de vértices del gráfico objetivo en nuestros experimentos. Esto significa que algunos vértices se cargan varias veces. Para verificar esto, recopilamos rastros de acceso a los vértices para diferentes trabajos de capacitación y contamos el número de visitas a cada vértice. La Fig. 5 es un gráfico CDF para la frecuencia de acceso de los vértices cargados utilizados para entrenar GCN en el gráfico wiki-talk cuando se utilizan métodos de muestreo NS y LS. Observamos que más del 32,4% de los vértices se reutilizan hasta 519 veces. Este patrón de acceso a vértices redundante exacerba la carga de datos y crea decenas de gigabytes de carga de datos por época. Además, encontramos que estos vértices tienen un grado de salida más alto que otros vértices visitados o no visitados con menos frecuencia. Esto se debe a que un vértice del gráfico con alto grado puede estar conectado a múltiples vértices del tren, lo que le da la oportunidad de ser seleccionado varias veces por diferentes minilotes.

Con base en esta observación, obtenemos la revelación de que el almacenamiento en caché de información de características de vértices de alto grado en la memoria de la GPU reducirá la carga de datos de la CPU a la GPU, acelerando así el entrenamiento GNN basado en muestreo. Sin embargo, esta optimización conlleva algunos desafíos, como competir por la memoria de la GPU con el cálculo GNN, incurrir en la sobrecarga de mantener dichos cachés, etc.
Los recursos de la GPU están infrautilizados. Dado que la fase de carga de datos precede a la fase de entrenamiento de GPU, exploramos más a fondo el impacto negativo de los cuellos de botella en la carga de datos. Resumimos la utilización de recursos de dos modelos GNN (GCN y GraphSAGE) que se están entrenando en la Tabla 1. Sorprendentemente, independientemente del método de muestreo, sólo se utiliza una pequeña fracción de los recursos computacionales y de memoria de la GPU. Por ejemplo, cuando se utiliza el muestreo de vecinos, solo se utiliza alrededor del 20% de los recursos informáticos de la GPU y el consumo de memoria es incluso menor, por ejemplo menos del 10%. Esto se debe a que los pequeños lotes de datos enviados por la CPU a la GPU no son suficientes para explorar completamente el paralelismo del hardware en la GPU. Mientras tanto, la GPU permanece inactiva, esperando que lleguen muestras de datos de entrenamiento la mayor parte del tiempo.

Esta observación nos llevó a considerar la utilización de recursos de GPU adicionales para almacenar en caché la información de características de los vértices a los que se accede con frecuencia para su reutilización de la forma más económica posible. En teoría, esta solución de almacenamiento en caché puede eliminar la recopilación de funciones de la CPU y los cuellos de botella en la transferencia de datos PCIe en el entrenamiento GNN basado en muestreo al eliminar la cantidad de información de funciones que debe recopilarse y enviarse desde la CPU a la GPU.
La contención de CPU entre el muestreo y la recopilación de características es alta. Luego, desglosamos el tiempo dedicado a las diferentes etapas del proceso de carga de datos y descubrimos que la etapa de recopilación de funciones consume mucha CPU y lleva mucho más tiempo que el movimiento de datos CPU-GPU. Por ejemplo, para los tres conjuntos de datos utilizados, representa el 50,4%, 55,1% y 56,3% del tiempo total de carga de datos, respectivamente. Este sorprendente resultado conduce a: (1) usando una sola GPU, logramos una utilización máxima del ancho de banda PCIe de aproximadamente 8 GB/s (con una capacidad de 16 GB/s), mientras que la utilización promedio es menor; (2) para múltiples Con una GPU, los subprocesos de trabajo simultáneos utilizados para recopilar características competirán con el muestreador por los recursos de la CPU. Por ejemplo, los tiempos de muestreo y recopilación de características aumentan en un 88% y un 59% respectivamente en comparación con el caso de 1 GPU, mientras que el cálculo de la GPU el tiempo sigue siendo el mismo. En el caso de 4 GPU, la utilización máxima del ancho de banda PCIe se reduce a la mitad y el promedio es aún peor. Esto indica que la capacidad de la CPU no puede hacer frente a las demandas informáticas de la GPU, ya que cada iteración requiere una gran cantidad de datos. Por lo tanto, para reducir los costos de recopilación de características, debemos considerar reducir la cantidad de datos que deben recopilarse en esta etapa, así como aislar la asignación de recursos para el muestreo y la recopilación de características.
La carga de datos y los cálculos de GNN se realizan de forma secuencial. Al utilizar la biblioteca dominante DGL, aunque la carga de datos consume CPU y PCIe, y los cálculos GNN están programados en la GPU, aún se ejecutan en orden en serie. DGL no aprovecha la superposición de las dos etapas en el proceso de capacitación, principalmente porque la carga de datos domina todo el espacio de capacitación y los cálculos de GNN se ejecutan más rápido. Sin embargo, en nuestro trabajo, el uso del almacenamiento en caché afecta significativamente el proceso de capacitación, ya que reduce el costo de carga de datos y al mismo tiempo aumenta la densidad computacional a medida que se alimentan más muestras de datos. Por lo tanto, la nueva situación nos brinda la oportunidad de canalizar la carga de datos y los cálculos de GNN para ocultar el costo de uno en el costo de otro y viceversa. Este diseño de canalización también presenta el efecto positivo de mejorar la eficiencia de la caché cuando se enfrentan a gráficos grandes, ya que reduce la cantidad de datos que deben almacenarse en caché en la memoria de la GPU.
PaGráfico
Motivados por los resultados de la Sección Experimental 2.3, proponemos PaGraph, un cargador de datos novedoso y eficiente que permite un entrenamiento paralelo rápido de datos GNN basado en muestreo en gráficos grandes. Introdujimos tres tecnologías clave en PaGraph: 1) mecanismo de almacenamiento en caché con reconocimiento de computación GNN para reducir la carga de datos de la CPU a la GPU, 2) método de entrenamiento de datos paralelo compatible con caché para escalar el entrenamiento GNN en múltiples GPU y 3) un sistema de dos etapas. canal de entrenamiento que superpone la carga de datos y el cálculo GNN.
La Fig. 6 muestra la arquitectura general de PaGraph. Para N computadoras individuales con GPU, el gráfico completo se divide en N subgráficos. La información de la estructura del gráfico de estas particiones y los datos de las características de los vértices se almacenan en el servidor de almacenamiento de gráficos global en la memoria compartida de la CPU. Hay N entrenadores independientes. Cada entrenador es responsable de entrenar los cálculos en una GPU dedicada. Copia el modelo GNN de destino y solo utiliza su propia partición de datos. Cada GPU contiene un caché que contiene características de los vértices a los que se accede con frecuencia.
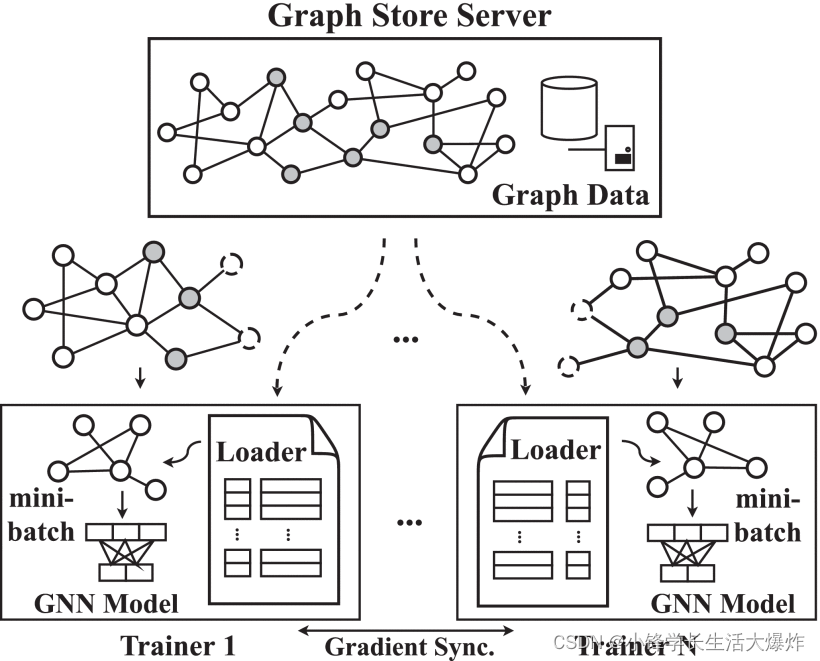
Durante cada iteración de entrenamiento, cada entrenador recibe un mini lote de información de estructura gráfica generada por el muestreador. Como se muestra en la Fig. 7, también obtiene datos cargados obteniendo características de vértice asociadas directamente desde su propia memoria caché de GPU (si está en caché) (marcada en verde) o consultando el servidor Graph Store para ver las características faltantes (marcadas en amarillo) características de vértice asociadas recogido por el El primer caso ahorra la sobrecarga de copiar datos de la CPU a la GPU, mientras que el segundo no. Posteriormente, este mini lote de datos estructurales, así como las características de vértices almacenadas en caché y cargadas (desde el host), se introducen en el modelo GNN para calcular los gradientes. Los entrenadores no interactúan entre sí excepto para sincronizar gradientes generados localmente al final de cada iteración para actualizar los parámetros del modelo.
3.1 Almacenamiento en caché GNN compatible con la computación Almacenamiento en caché GNN compatible con la computación
Estrategia de almacenamiento en caché. Para generar mejores modelos, la mayoría de los algoritmos de entrenamiento requieren una secuencia aleatoria de muestras de entrenamiento para cada época, lo que hace imposible predecir los vértices en cada mini lote en tiempo de ejecución. Los vecinos de los vértices también se seleccionan aleatoriamente y, por tanto, también son impredecibles durante el entrenamiento. Por lo tanto, es difícil predecir qué vértice es más probable que sea visitado en el próximo mini lote. Sin embargo, debido al patrón de acceso único del método de muestreo de vecindad, el grado de salida de un vértice representa la probabilidad de ser seleccionado a lo largo de las épocas. Esto significa que con un grado exterior más alto, es más probable que los vértices sean vecinos de otros vértices y, por lo tanto, es más probable que se muestreen en minilotes. Por lo tanto, basta con llenar el caché con picos de gran altitud.
Generalmente, se prefiere una estrategia de almacenamiento en caché dinámica. Sin embargo, no es adecuado cuando el caché se encuentra dentro de la GPU. Esto se debe a que la GPU no puede funcionar de forma independiente; todos los cálculos realizados en la GPU deben ensamblarse en núcleos de GPU e iniciarse desde la CPU. La mayoría de los GNN actuales son livianos [1] , por lo que el intercambio de datos gráficos entre la memoria de la CPU y la memoria de la GPU tiene una sobrecarga intolerable durante el entrenamiento (consulte la Sección 2.3). Por lo tanto, en lugar de decidir sobre la marcha qué almacenar en caché, como LRU [28] , utilizamos el almacenamiento en caché estático para evitar la sobrecarga del intercambio de datos dinámico. Podemos hacer esto ordenando previamente los vértices por grado de salida fuera de línea y seleccionando los vértices de mayor grado en tiempo de ejecución para llenar el caché de la GPU. Dejamos la exploración de estrategias eficientes de almacenamiento en caché dinámico para trabajos futuros. A pesar de su simplicidad, como se muestra en la Sección 5, esta estrategia de almacenamiento en caché estático logra efectivamente altos índices de aciertos de caché.
espacio de caché. Para evitar la contención de recursos para cálculos de entrenamiento de alta prioridad, debemos estimar la cantidad máxima de memoria de GPU disponible para la asignación de caché. Para lograr esto, aprovechamos el hecho de que el consumo de memoria es similar en todas las iteraciones de entrenamiento. Esto se debe a que el entrenamiento de mini lotes basado en muestreo utiliza casi la misma cantidad de muestras de datos como entrada y realiza casi la misma cantidad de cálculos para entrenar el modelo GNN compartido para cada iteración. Por lo tanto, es suficiente determinar el tamaño de caché correcto tomando una muestra única del uso de la memoria de la GPU. Con más detalle, después del primer entrenamiento de mini lotes, verificamos el tamaño de la memoria de GPU disponible durante el entrenamiento y asignamos la memoria de GPU disponible en consecuencia para almacenar en caché los datos del gráfico (consulte la Sección 4 para obtener más detalles).
Gestión de datos. En la memoria caché de la GPU, administramos las características de los vértices almacenadas en caché manteniendo dos espacios separados. Primero, asignamos bloques de memoria contiguos para los datos de características. Los datos de entidades almacenados en caché para los vértices están organizados en varias matrices [N,Ki] grandes, donde N representa el número de vértices almacenados en caché y Ki es la dimensión de la característica en el i-ésimo campo de nombre de característica. En segundo lugar, para permitir búsquedas rápidas, organizamos los metadatos de los vértices en una tabla hash que responde si el vértice consultado está almacenado en caché y su ubicación para su posterior recuperación. Los metadatos son mucho más pequeños que los datos de entidades almacenados en caché; por ejemplo, no más de 50 MB para una partición con 10 millones de vértices.
conversar. Una menor distorsión o una gran cantidad de gráficos pueden limitar la eficacia de la optimización de la caché. Sin embargo, muchos gráficos del mundo real, incluidos los gráficos evaluados, son gráficos de ley de potencias [8] [30] [29] y exhiben una alta asimetría. Por lo tanto, nuestra solución puede beneficiar los esfuerzos comunes de capacitación de GNN. Para aquellos con gráficos menos sesgados o grandes, una posible solución es combinar la captación previa y el almacenamiento en caché dinámico para lograr una buena eficiencia de caché. Abordaremos este tema en la Sección 3.3.
3.2 Entrenamiento y partición en paralelo de datos Entrenamiento y partición en paralelo de datos
Los diseños actuales de sistemas GNN, como el DGL, equilibran el cálculo entre múltiples GPU, pero hacen que compartan una única copia de los datos gráficos [26] . Al aplicar el método de almacenamiento en caché compatible con GNN anterior directamente a esta configuración, observamos una ineficiencia de la caché, es decir, la tasa de aciertos de la caché disminuye continuamente a medida que aumenta la cantidad de GPU. Esto se debe a que un único gráfico proporciona una ubicación de acceso a datos para entrenadores paralelos en varias GPU, por lo que todas las cachés de GPU mantendrán vértices similares.
Para abordar esta ineficiencia de la caché, introdujimos el "paralelismo de datos" en PaGraph, que se ha utilizado ampliamente para aprovechar múltiples GPU para entrenar modelos de redes neuronales de manera eficiente. En nuestro sistema, en lugar de acceder a un gráfico compartido, el Entrenador usa sus particiones de datos (subgrafos), realiza cálculos de entrenamiento para obtener gradientes locales y luego intercambia gradientes entre pares para actualizar sincrónicamente las réplicas de su modelo. Obviamente, los beneficios del paralelismo de datos son una mejor localidad de los datos y aumentarán el número total de vértices almacenados en caché. Para lograr esto, aunque existen muchos algoritmos de partición de gráficos [8] , [20] [21], todavía necesitamos diseñar un nuevo algoritmo para cumplir con los siguientes dos objetivos exclusivos del entrenamiento GNN con datos paralelos. En primer lugar, debe mantener los cálculos equilibrados entre diferentes entrenadores, ya que los cálculos desequilibrados pueden dar como resultado que diferentes entrenadores tengan diferentes números de minilotes por época. Esto romperá la sincronización del gradiente y bloqueará el entrenamiento. En segundo lugar, debe evitar en la medida de lo posible el acceso entre particiones por parte de diferentes formadores.
Calcula el saldo. Para lograr un equilibrio computacional entre diferentes entrenadores, todas las particiones deben tener una cantidad similar de vértices de entrenamiento. Supongamos que necesitamos K particiones. Escaneamos todo el conjunto de vértices del tren y asignamos iterativamente los vértices escaneados a una de las K particiones. En cada iteración, a un vértice de entrenamiento se le asigna un vector de puntuación dimensional t, donde el ésimo elemento representa la viabilidad de asignar el vértice vt a la i primera partición i∈[1,K]. La puntuación K se calcula mediante la ecuación. (1)
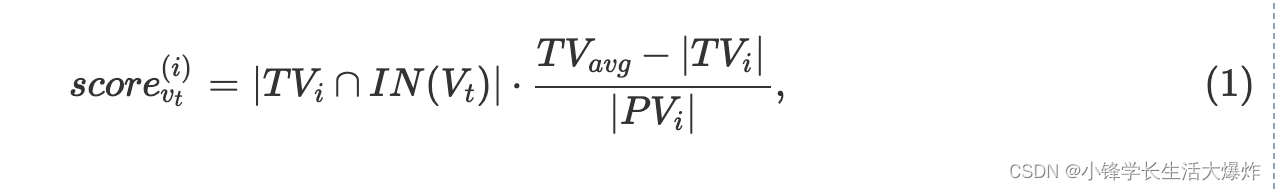
TVi representa el conjunto de vértices de entrenamiento asignados a la i-ésima partición. IN(Vt) representa el conjunto de vecinos L -hop del vértice del tren vt. PVi controla el equilibrio de la carga de trabajo y representa el número total de vértices en la i-ésima partición, incluidos los vértices replicados. Lo más probable es que vt esté asignado a la partición con el PV más pequeño. TVavg es el número esperado de vértices del tren en la última partición i. Para lograr un equilibrio computacional, configuramos TVavg |TV|K, lo que significa que todas las particiones obtendrán casi la misma cantidad de vértices de entrenamiento.
Sea autosuficiente. Para consultas que contienen bordes en diferentes particiones, se deben reenviar al servidor de almacenamiento Graph para obtener el conjunto completo de vecinos. Inspirado en [8] [31] , PaGraph introduce un mínimo de vértices y bordes adicionales en cada partición para manejar los bordes entre particiones. La figura 8 muestra cómo dividir el gráfico autosuficiente de un modelo GNN de una sola capa. Los vértices sombreados representan los vértices del tren, los vértices blancos representan los vértices de valor/prueba y los vértices discontinuos representan los vértices redundantes introducidos.
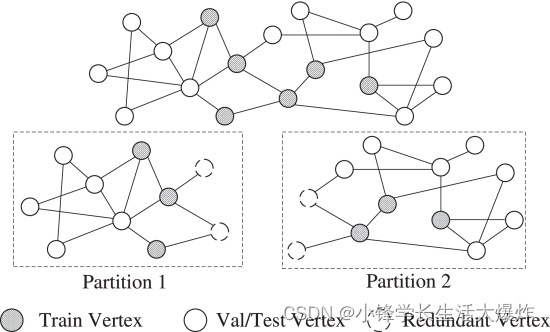
Para cada partición, PaGraph expande el subgrafo con vértices y aristas redundantes para incluir todos los vértices adyacentes del salto requerido durante el muestreo. Para un modelo GNN con una capa GNN, incluiremos saltos L de vértices vecinos para cada vértice del tren; por ejemplo, un modelo GNN de una sola capa solo necesita incluir saltos L de los vecinos inmediatos de cada vértice del tren. PaGraph solo introduce los bordes necesarios para extender los vértices y satisfacer el flujo de mensajes requerido durante el entrenamiento. Tenga en cuenta que los vértices extendidos pueden incluir vértices de entrenamiento. Estos vértices del tren extendido se tratan como espejos [8] y no se entrenarán. De esta forma, las particiones son independientes entre sí. Cada entrenador puede muestrear minilotes completamente desde su propio subgrafo sin acceder a la estructura del gráfico global.
3.3 Canalización de carga de datos y cálculo GNN Canalización de carga de datos y cálculo GNN
Como se mencionó anteriormente, la mejora del rendimiento del almacenamiento en caché es proporcional al número de vértices almacenados en caché con gran altitud. Aunque la mayoría de los gráficos del mundo real muestran una gran asimetría, dado que los tamaños de memoria de la GPU suelen estar limitados a 10-30 GB, los mecanismos de almacenamiento en caché independientes pueden no ser suficientes para admitir cálculos GNN en gráficos grandes donde la mayoría de los vértices no se pueden almacenar en caché. Por lo tanto, la carga de datos seguirá siendo el cuello de botella en estos casos. Para complementar el almacenamiento en caché y la partición, exploramos más a fondo oportunidades para ocultar la sobrecarga de carga de datos en el tiempo de cálculo. Esto requiere que diseñemos una nueva canalización para paralelizar el cálculo del minilote actual y la captura previa de datos del gráfico para el siguiente minilote.
La figura 9a muestra nuestro diseño de canal de capacitación en dos etapas, donde descomponemos la ejecución secuencial original en dos ejecuciones de transmisión paralelas, a saber, carga y cálculo. Usamos una cola de mensajes para coordinar la ejecución de los dos flujos. Tomando información del Sampler, el ejecutor de transmisión de carga es responsable de organizar la información de características requerida para el mini lote de vértices seleccionado en el almacenamiento de gráficos y la caché de la GPU (consulte la Fig. 9b). Cuando se completa la carga, publica un mensaje listo (incluida la ubicación de los datos por lotes en la memoria de la GPU) en la cola de mensajes compartida. El ejecutor de cómputo, por otro lado, se encuentra en un bucle y verifica periódicamente la llegada de nuevos mensajes del ejecutor de carga. Muestra un mensaje del encabezado de la cola compartida y programa el cálculo GNN correspondiente, que consumirá los datos ya captados previamente.
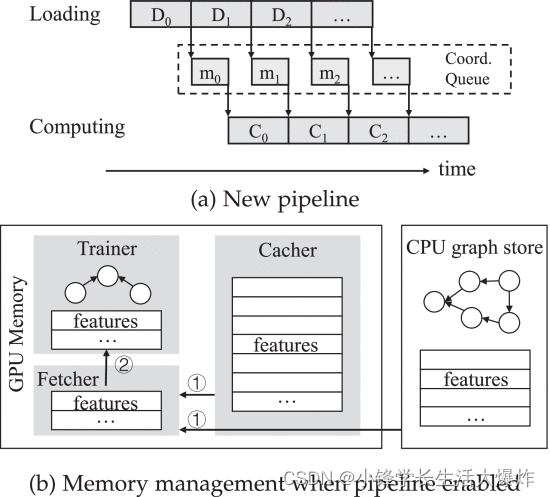
El nuevo diseño de canalización nos permite dividir aún más la memoria de la GPU en tres partes, que se utilizan para cálculos GNN, caché de datos gráficos y datos de captación previa almacenados en búfer (consulte la Fig. 9b). Sin embargo, afirmamos que el búfer de captación previa no exacerba las limitaciones de memoria de la GPU por las siguientes razones. En primer lugar, cada minilote ocupa menos de 900 MB de espacio de memoria, ocupando sólo el 8% de la memoria de la GPU en el dispositivo utilizado en nuestra evaluación. En segundo lugar, limitamos el número máximo de tareas de captación previa para evitar la contención de memoria. También utilizamos la longitud de la cola de mensajes como retroalimentación para guiar al ejecutor de carga para que ralentice o acelere de forma adaptativa la captación previa.
Implementación
Construimos PaGraph sobre Deep Graph Library (DGL (v0.4)) [10] y PyTorch (v1.3) [23] . Dado que la sincronización de gradientes no es la principal preocupación en el entrenamiento GNN, simplemente adoptamos la solución existente NCCL RingAllReduce para implementar el entrenamiento GNN con datos paralelos [32] . El servidor de almacenamiento de gráficos que implementamos usando DGL almacena datos de estructura de gráficos y datos de características en la memoria compartida de la CPU. 1 Almacenamos la estructura gráfica completa como una matriz de adyacencia en formato CSC [33] . El formato CSC agrega el conjunto de vecindad de cada vértice dentro de un espacio de memoria contiguo, permitiendo un acceso rápido para obtenerlos. La implementación completa consta de 1,47 K líneas de código en Python, de las cuales 293 líneas son para el cargador de datos, 436 líneas corresponden al algoritmo de partición y 737 líneas son cambios en el flujo de trabajo de entrenamiento de muestreo original. Estamos refactorizando el código base y planeamos ponerlo a disposición en línea para respaldar la reproducibilidad.
Inicialización y mantenimiento de caché. Ampliamos el cargador de datos para incorporar una API de Python simple para obtener los datos necesarios de la memoria de la GPU o de la CPU local, como se muestra en la Fig. 10. Primero, inicializamos el cargador de datos conectándolo al servidor Graph Store y haciéndole consciente de la configuración de entrenamiento paralelo de datos, por ejemplo, cuántas GPU se utilizan, a qué GPU sirve, etc. Durante el primer entrenamiento de mini lotes, el cargador de datos verificará la memoria total de la GPU (indicada como total_mem) y la memoria máxima de la GPU asignada por PyTorch (indicada como used_mem). También reservamos una cierta cantidad de memoria de GPU que no se utiliza para las fluctuaciones de la memoria durante el entrenamiento (indicada como preserve_mem), y descubrimos que en la práctica 1,0 GB es suficiente. Después de eso, llamamos a loader.auto_cache, que calcula el tamaño de la memoria disponible y asigna esta cantidad de memoria al caché restando used_mem y preserve_mem de total_mem. Después de asignar el caché, el cargador de datos continuará cargando las entidades almacenadas en caché (especificadas por nombres de campo) con los vértices de mayor grado hasta que el caché esté lleno. Para reducir el costo de tiempo de este proceso de inicialización, analizamos la estructura del subgrafo fuera de línea y clasificamos los vértices según su grado externo. A partir de la segunda iteración, el cargador de datos recupera datos del servidor Graph Store y de la caché de la GPU local llamando a loader.fetch_data, que está parametrizado por mini_batch. Este nuevo flujo de carga es transparente para el trabajo de formación.

Acceso computacional equilibrado y entre particiones Partición de gráficos gratuito Acceso computacional equilibrado y entre particiones Partición de gráficos gratuito
Partición de gráficos sin conexión. El algoritmo 1 proporciona nuestro método de partición específico de GNN para dividir gráficos grandes para dar cabida al entrenamiento de datos paralelos habilitado para caché. Implementamos un algoritmo de partición basado en Linear Deterministic Greedy (LDG) [20] , una solución de partición basada en flujo. Solo evaluamos los vértices de entrenamiento (línea 3), los asignamos a la partición de destino con índice ind (línea 6) según el cálculo de puntajes (líneas 4-5) y también asignamos sus vecinos L-hop (línea 7 filas). incluido en la partición. La preparación de particiones para el entrenamiento del modelo GNN es un trabajo fuera de línea antes del entrenamiento. Aunque este paso introduce costos de tiempo adicionales y consume recursos adicionales, es aceptable por las siguientes razones. Primero, la partición es un trabajo fuera de línea que se realiza una sola vez, por lo que no bloquea el proceso de capacitación. En segundo lugar, estudios recientes han encontrado [34] , [35] que muchos trabajos de aprendizaje automático se generan a partir de experimentos de ajuste de parámetros, y la mayoría de las configuraciones que comparten incluyen conjuntos de datos y particiones. Por lo tanto, este trabajo único puede resultar muy útil en estos experimentos de optimización de parámetros.
Para reducir la carga de almacenamiento en las particiones, eliminamos los vértices y aristas redundantes que no contribuyen durante el entrenamiento. Para una red neuronal de gráfico de capas dada L, verificamos si el vértice val/test L está lejos de todos los vértices de entrenamiento. Si es así, eliminamos este vértice y sus aristas asociadas del subgrafo. Además, eliminamos los bordes redundantes para evitar un flujo de mensajes ineficiente. Si no se requiere una de las direcciones del flujo de mensajes, los bordes no dirigidos se convierten en bordes dirigidos. A medida que se refina la estructura del gráfico, también se eliminan los datos del gráfico asociados con vértices y aristas redundantes.
linea de ensamblaje. Dado que DGL ya superpone el muestreo de mini lotes con los pasos restantes en la ruta de carga de datos, solo consideramos ocultar el costo de carga de datos en el cálculo. Inicialmente, introdujimos un hilo de demonio que precargaba el siguiente mini lote mientras se calculaba el mini lote actual. Desafortunadamente, esta versión es ineficiente porque la funcionalidad tradicional GIL (Global Interpreter Lock) de Python se serializa en múltiples subprocesos. Para evitar esta serialización innecesaria, iniciamos un proceso demonio para realizar tareas de captación previa de objetivos y gestionar la comunicación entre procesos a través de colas de PyTorch. Sin embargo, debido al aislamiento del proceso, esta solución multiproceso también conlleva el costo adicional de copiar los minilotes de datos precargados de la cola compartida al espacio de memoria del proceso informático. Para ocultar aún más este costo no despreciable, además generamos un hilo de demonio desde el proceso principal para copiar datos de forma asíncrona desde la cola al proceso principal en segundo plano.
Aislamiento de recursos. Las bibliotecas GNN a menudo se implementan sobre marcos de aprendizaje profundo y agregan capacidades de muestreo y almacenamiento de gráficos adicionales a estos marcos. En su implementación, tanto el muestreo como la carga de datos se colocan en un solo proceso y los trabajos simultáneos se realizan utilizando OpenMP [36] , como muestrear múltiples minilotes, recopilar datos de minilotes y copiarlos en un espacio de memoria protegido, etc. Observamos interferencia entre el muestreo y la carga de datos con un solo proceso, donde ambos competían por los recursos de la CPU. Esta interferencia también reduce la frecuencia con la que se lanza el kernel desde el host de la CPU al dispositivo GPU. Para eliminar esta contención de recursos, en nuestra implementación hacemos que el muestreo y la carga de datos utilicen procesos separados y ajustamos la configuración de OpenMP para equilibrar los recursos de la CPU entre ellos.
Mezcla parcial. Para lograr un mejor rendimiento empírico en el entrenamiento paralelo de datos [37] , es necesario mezclar las muestras de datos. El orden aleatorio se puede realizar entre particiones (global) o dentro de cada partición (local), donde el primer caso puede conducir a una convergencia más rápida pero es más costoso que el segundo caso. Sin embargo, la mezcla local se adopta ampliamente en la práctica del mundo real y estudios recientes han demostrado que aún puede funcionar bien incluso con una convergencia ligeramente más lenta [38] . Por lo tanto, PaGraph bloquea la partición asignada por cada entrenador y mezcla el orden de acceso de las muestras de datos en esa partición antes del inicio de cada época. Además, mostramos en la Sección 5.9 que la mezcla local no afecta la precisión del modelo ni la velocidad de convergencia.
conversar. Actualmente, PaGraph funciona en un único servidor multi-GPU, pero las ideas centrales de almacenamiento en caché, partición de gráficos y canalización se pueden aplicar directamente al entrenamiento GNN distribuido para utilizar más GPU para procesar gráficos más grandes que no caben en la memoria de un solo servidor. . Lo único que requiere un diseño cuidadoso en esta extensión es la sincronización eficiente de gradientes entre servidores para evitar cuellos de botella en la sincronización.
Evaluación
Realizamos una evaluación en profundidad del rendimiento de PaGraph utilizando modelos GNN representativos y conjuntos de datos del mundo real. En particular, exploramos el rendimiento de una sola GPU y la eficiencia de escalado de múltiples GPU, realizamos un análisis segmentado del rendimiento de la caché de los algoritmos de partición bajo diferentes condiciones y calidades, y comprendemos los efectos conjuntos de la caché y la canalización cuando nos enfrentamos a gráficos grandes.
5.1 Configuración experimental 5.1 Configuración experimental
ambiente. Implementamos nuestros experimentos en un servidor multi-GPU que consta de dos CPU Intel Xeon E5-2620v4, 512 GB de memoria principal DDR4 y 4 GPU NVIDIA GTX 1080Ti (11 GB de memoria) sin conexiones NVLink. La máquina está instalada con CentOS 7.6, biblioteca CUDA v10.1, DGL [10] v0.4 y PyTorch [23] v1.3.
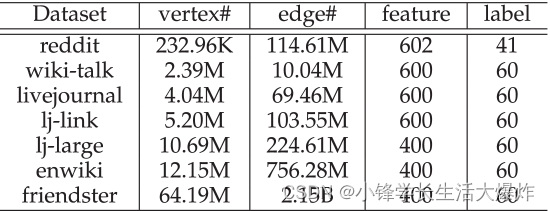
datos. Utilizamos siete conjuntos de datos de gráficos del mundo real enumerados en la Tabla 2 para la evaluación, incluida la red social reddit [2] , la red de historial de versiones de páginas wiki-talk [39] , tres variantes de livejournal y la red de comunicación ( [27] livejournal, lj- enlace, lj-large [40] [18] ) y enwiki dimension [22] red de enlaces de enciclopedia. La columna "Características" representa la dimensionalidad de las características de los vértices y la columna "Etiqueta" muestra el número de clases de vértices. Siguiendo la configuración de Reddit [2], dividimos los vértices de cada conjunto de datos en categorías de vértices de entrenamiento, valor y prueba con una proporción de 65:10:25.
Modelo. Evaluamos PaGraph utilizando dos modelos GNN representativos, Graph Convolutional Network (GCN) [3] y GraphSAGE [2], con configuraciones detalladas en la Tabla 3. GCN generaliza la operación de convolución del gráfico de la siguiente manera. Cada vértice en la capa GCN agrega las características de sus vértices adyacentes mediante la operación de suma. Luego, las características agregadas se activan a través de capas completamente conectadas y ReLU para generar la representación de salida. GCN se ha desempeñado bien en tareas como clasificación [3] y traducción automática neuronal [7] . GraphSAGE [2] es un modelo de aprendizaje inductivo para aprender diferentes funciones de agregación en diferentes números de saltos. Hay cuatro tipos de agregación en GraphSAGE: GCN (suma), media, LSTM y agrupación. Elegimos presentar resultados experimentales en el modelo GraphSAGE-Mean porque los cuatro agregadores muestran costos de ejecución similares [2].

base. Implementamos el DGL original como primera línea de base. Además, ejecutamos un DGL avanzado donde la optimización del preprocesamiento [19] está habilitada como otra línea de base, denominada "DGL+PP". La idea detrás del preprocesamiento es eliminar la primera capa del modelo GNN agregando las características correspondientes fuera de línea. Aún así, la carga de datos domina el rendimiento del entrenamiento habilitado para preprocesamiento y le impide aprovechar al máximo esta optimización. A menos que se indique lo contrario, todas las cifras de desempeño son promedios de los resultados de 10 períodos.
5.2 Rendimiento de una sola GPU Rendimiento de una sola tarjeta gráfica
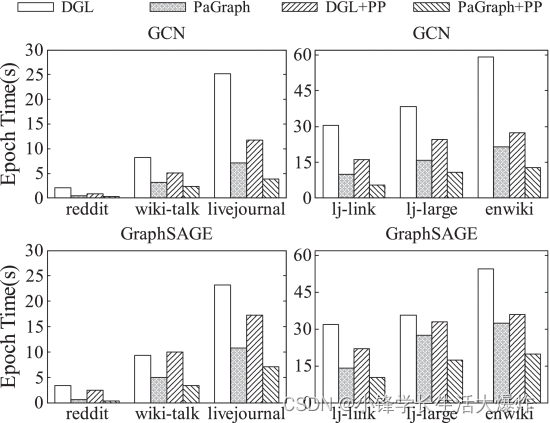
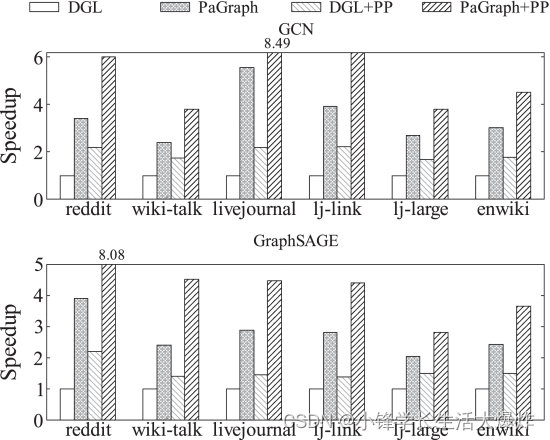
Primero evaluamos el rendimiento del entrenamiento de PaGraph en una sola GPU. La Fig. 11 muestra el rendimiento del entrenamiento de GCN y GraphSAGE en diferentes conjuntos de datos. En general, en comparación con DGL, la aceleración del rendimiento del entrenamiento de PaGraph en GCN aumenta de 2,4 × (lj-large) a 3,9 × (reddit), y en GraphSAGE de 1,3 × (lj-large) a 4,9 × (reddit). Observamos que la combinación de preprocesamiento y DGL (DGL + PP) funciona de manera diferente en los dos modelos GNN, es decir, la aceleración del rendimiento de GCN lograda mediante el preprocesamiento es mejor que la de GraphSAGE. Esto se debe a los diferentes procesos de reenvío utilizados en GCN y GraphSAGE. Durante el reenvío en GCN, cada vértice agrega características de sus características vecinas y suma estas características en una sola característica. A diferencia de GCN, para cada vértice en el mini lote correspondiente, GraphSAGE debe guardar sus propias características y las características agregadas de sus vecinos. Esto da como resultado más transferencias de datos CPU-GPU para GraphSAGE en comparación con GCN. Por el contrario, observamos además que nuestras optimizaciones en PaGraph pueden explotar mejor el potencial de las optimizaciones de preprocesamiento además del DGL simple. Por ejemplo, PaGraph+PP mejora el rendimiento de GCN y GraphSAGE entre 2,1× y 3,0× y entre 1,8× y 6,2× con respecto a DGL+PP en los primeros 6 conjuntos de datos.
Desglose del tiempo de entrenamiento. Para explorar más a fondo la reducción de la sobrecarga de carga de datos de PaGraph, descomponemos el tiempo de entrenamiento de GCN en DGL y PaGraph en tiempo de computación de GPU y tiempo de carga de datos de CPU-GPU. Usamos nvprof [41] y PyTorch Profiler [42] para recopilar dichas estadísticas del sistema. La Fig. 12 muestra los resultados de la descomposición correspondientes a los experimentos relacionados con GCN en la Fig. 11 (también observamos pedales similares para GraphSAGE). En este gráfico de barras agrupadas, de izquierda a derecha, cada grupo de barras muestra los resultados de DGL, DGL+PP, PaGraph y PaGraph+PP. De acuerdo con los resultados proporcionados en la Sección 2, DGL que utiliza el cargador de datos integrado enfrenta graves problemas de carga. Aunque el preprocesamiento ahorra cálculos y carga de datos, todavía sufre cuellos de botella en la carga de datos que ocupan hasta el 61% del tiempo de entrenamiento.
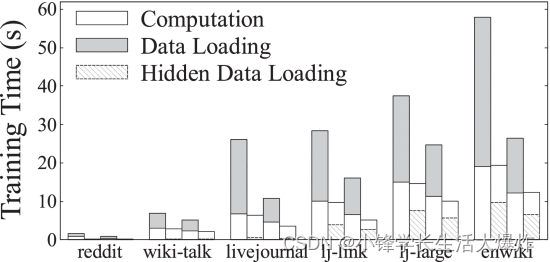
En comparación con el cargador de datos de referencia, PaGraph superpone completamente la etapa de carga de datos y la etapa de cálculo de la GPU debido a los esfuerzos conjuntos de la caché y la canalización, eliminando así el costo de carga de la canalización de entrenamiento del modelo GNN original y sus variantes habilitadas para preprocesamiento. Descubrimos que el almacenamiento en caché independiente es suficiente para entrenar el modelo de destino en los primeros tres conjuntos de datos. Esto se debe a que estos conjuntos de datos son pequeños, se pueden almacenar en caché por completo en la memoria de la GPU y el tiempo de carga de datos es insignificante. Por el contrario, aunque el tiempo de carga de datos para los últimos tres conjuntos de datos más grandes se ha reducido del 65,7 % al 78,7 % mediante el almacenamiento en caché, todavía representa el 34,9 % de todo el tiempo de entrenamiento. En este caso, la carga y el cálculo de datos de la línea de flotación pueden ocultar completamente el costo del primer caso en el segundo. Curiosamente, en algunos casos, el tiempo de cálculo se reduce ligeramente, como en "PaGraph+PP" para el conjunto de datos lj-large, porque evitamos cuidadosamente la contención de CPU entre trabajos de entrenamiento paralelos. Sin embargo, en algunos casos el tiempo de cálculo aumenta ligeramente, como el "PaGraph" del conjunto de datos enwiki. Esto se debe a que el proceso de captación previa en segundo plano requiere algunos ciclos de CPU, lo que puede afectar el inicio del núcleo de la GPU.
5.3 Efectividad de la política de almacenamiento en caché Efectividad de la política de almacenamiento en caché
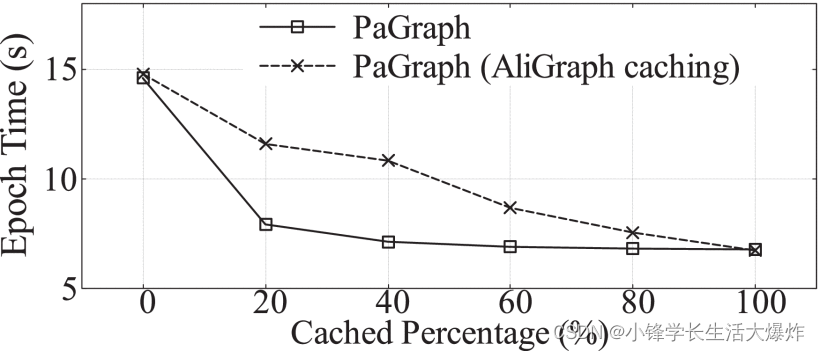
A continuación, comparamos la estrategia de almacenamiento en caché estático con la estrategia proporcionada en AliGraph [43] , que admite el entrenamiento GNN en múltiples máquinas con CPU. Si la relación entre grados de entrada y de salida de un vértice excede un umbral, el vértice se almacena en caché localmente, lo que reduce el costo de comunicación entre la tarea de capacitación y el sistema de almacenamiento remoto. También comparamos una estrategia aleatoria, que mantiene aleatoriamente los vértices en el cargador. Para ayudar a comprender cómo funcionan las diferentes estrategias de almacenamiento en caché, deducimos que la tasa de aciertos de caché óptima se obtiene si todos los accesos a vértices posteriores pueden absorberse en el caché. Denotamos esta tasa óptima de aciertos de caché como "mejor". La derivación se realiza analizando las trazas de acceso a la formación. No comparamos directamente PaGraph con AliGraph porque la versión de código abierto de AliGraph no contiene código de almacenamiento en caché, está construida sobre TensorFlow en lugar de PyTorch y está diseñada para máquinas con CPU. Para hacer una comparación justa, implementamos la estrategia de almacenamiento en caché AliGraph en PaGraph como se describe en su artículo.
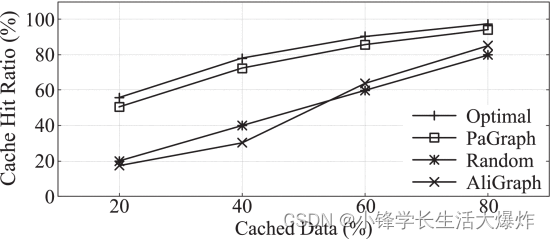
La Fig. 13 muestra la tasa de aciertos de caché bajo diferentes tasas de caché usando una sola GPU. Observamos que cuando solo se almacena en caché el 20% del gráfico, podemos lograr una tasa de aciertos de más del 50%, que es más del 200% del rendimiento de otras estrategias. Más interesante aún, muestra que nuestra estrategia de almacenamiento en caché no es compleja, pero sí muy efectiva, muy cercana al caso óptimo. También logramos índices de aciertos de caché casi óptimos similares en otros conjuntos de datos. Además, exploramos el impacto en el rendimiento de diferentes índices de aciertos de caché implementados por PaGraph y AliGraph. Como se muestra en la Fig. 14, a medida que aumenta la proporción de datos del gráfico almacenados en caché, el tiempo de entrenamiento por época de las implementaciones DGL y PaGraph disminuye continuamente y converge a 6,7 segundos cuando todos los datos requeridos están almacenados en caché. Sin embargo, cuando el tamaño de la caché es limitado, la estrategia de almacenamiento en caché de PaGraph logra una aceleración del rendimiento de hasta 1,5 veces respecto a la estrategia de AliGraph. Más interesante aún, cuando el porcentaje de caché alcanza el 40%, el rendimiento del entrenamiento se vuelve estable y no se observa ninguna mejora adicional cuando se utiliza más espacio de caché. Esto se debe a que en ese punto crítico, el tiempo de carga de datos se reduce a menos que el tiempo de cálculo de la GPU y nuestro mecanismo de canalización puede superponer completamente las dos etapas. Esto revela aún más los beneficios adicionales de combinar el almacenamiento en caché y la canalización, lo que hace que nuestra solución sea aplicable y proporcione un buen rendimiento bajo las limitaciones de memoria de la GPU.
A través de nuestra estrategia de almacenamiento en caché, PaGraph logra una reducción sustancial de la carga de datos en gráficos grandes en comparación con DGL. La Tabla 4 muestra la carga de datos reducida promedio por época en cada entrenador durante el entrenamiento de GCN. En general, logramos una reducción de carga del 91,8 %, 80,9 % y 81,0 % para los conjuntos de datos lj-link, lj-large y enwiki, respectivamente.

5.4 Rendimiento de múltiples GPU Rendimiento de múltiples tarjetas gráficas
Evaluamos la escalabilidad con diferentes números de GPU. La Fig. 15 muestra los resultados experimentales del entrenamiento de GCN y GraphSAGE en el conjunto de datos real enwiki con diferentes números de GPU. Tanto DGL como PaGraph logran un mayor rendimiento cuando se utilizan más GPU. Sin embargo, en general, PaGraph supera a DGL y muestra una mejor escalabilidad en diferentes configuraciones de hardware; por ejemplo, PaGraph supera a DGL hasta 2,4 veces (GCN para 4 GPU). Evaluamos más a fondo el rendimiento de PaGraph en múltiples GPU para mostrar su efectividad en diferentes optimizaciones de algoritmos. Con este fin, ampliamos las cifras de rendimiento cuando utilizamos 2 GPU y resumimos los resultados en la Fig. 16. PaGraph logra un rendimiento DGL de 2,1× a 5,6× en todos los conjuntos de datos. Mediante la optimización del preprocesamiento, PaGraph puede lograr una aceleración de 2,8 × a 8,5 × en DGL. Hay dos razones para la importante aceleración. En primer lugar, varias GPU proporcionan más memoria disponible para el caché, lo que genera mayores tasas de aciertos de caché y menores costos de carga de datos. Para confirmar esto, también probamos el rendimiento de GCN en enwiki con el tamaño total de caché fijado en 6 GB en cuatro GPU. Muestra que la aceleración en 4 GPU es solo 3,7x, lo que es un 23% menor que la aceleración lograda sin límite de tamaño de caché. En segundo lugar, en todos los casos de prueba, la carga de datos se ejecuta más rápido que el cálculo, por lo que nuestro mecanismo de canalización los oculta completamente del cálculo.

5.5 Implicaciones de la partición de gráficos El significado de la partición de gráficos
Para verificar los beneficios del entrenamiento de datos en paralelo respaldado por la partición de gráficos, primero adaptamos DGL para usar nuestro mecanismo de almacenamiento en caché, denominado "DGL+Cache", y luego comparamos PaGraph con DGL+Cache. La única diferencia es que solo el primero usa gráficos particionados datos, mientras que el último utiliza un gráfico completo no particionado. La figura 17a ilustra la tasa de aciertos de caché con diferentes números de GPU. Dado que los entrenadores en DGL+Cache comparten el mismo almacén de gráficos global, que mantiene la estructura gráfica completa, la parte almacenada en caché de la caché de GPU a la que accede cada entrenador es la misma. Sin embargo, en PaGraph, a medida que aumenta el número de entrenadores, cada entrenador utiliza vértices muestreados de un conjunto de vértices de entrenamiento más pequeño y muestra una mejor localidad de datos. Por lo tanto, cuando se utilizan más GPU, la tasa de aciertos de caché implementada por PaGraph sigue mejorando, mientras que DGL+Cache observa una disminución en la tasa de aciertos de caché. Esta diferencia se puede traducir directamente en la brecha de rendimiento de la Fig. 18 (usando 4 GPU). Al combinar el almacenamiento en caché con la partición, el rendimiento de PaGraph es un 25% y un 52% mayor que DGL+Cache y DGL respectivamente. El mecanismo de canalización puede aumentar aún más la velocidad de entrenamiento de GCN en un 27%.
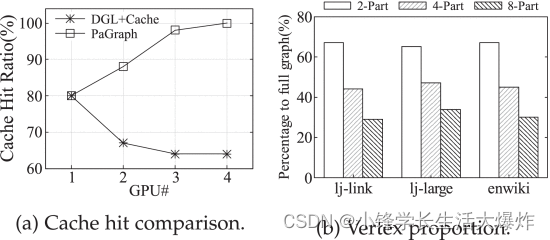
Sin embargo, las mejoras en la partición de gráficos tienen un costo, es decir, redundancia entre particiones y costos de tiempo fuera de línea. A continuación, analizamos cuantitativamente su impacto. La figura 17b muestra la proporción de vértices en una sola partición con respecto al gráfico completo a medida que cambia el número de particiones. El eje y representa la proporción de cada partición con respecto al gráfico completo. A medida que aumenta el número de particiones, disminuye el número de vértices por partición. Usando nuestro algoritmo, traemos una pequeña fracción de vértices redundantes a cada partición en una configuración de 8 particiones, que van del 2,5 % al 21,5 % del tamaño completo del gráfico. Este costo sigue siendo asequible considerando la aceleración del entrenamiento lograda mediante la partición. En segundo lugar, la Tabla 5 muestra el costo general de partición para 4 conjuntos de datos más grandes de un total de 6 conjuntos de datos, que van desde 6,0 a 32,2 minutos. Creemos que esto es aceptable porque la partición es una tarea única que se realiza fuera de línea y su costo se puede amortizar en múltiples épocas y entrenamiento repetido para el ajuste de hiperparámetros [44] .

5.6 Efectos de la canalización
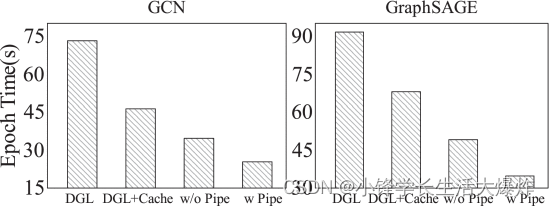
A continuación, centramos nuestra atención en comprender el impacto de la carga y el cálculo de datos canalizados. Aquí, elegimos el conjunto de datos de Friendster, que es mucho más grande que los otros seis conjuntos de datos de la Tabla 2. Este gran conjunto de datos consume 358 GB de memoria de CPU e incluso con 4 GPU, solo el 25 % de sus funciones de vértice se pueden almacenar en caché. Por lo tanto, con este conjunto de datos, podemos aislar los beneficios de rendimiento de las canalizaciones del almacenamiento en caché. Con este fin, entrenamos GCN y GraphSAGE agregando incrementalmente cada optimización introducida en la Sección 3 e informamos los números de velocidad de entrenamiento en la Fig. 18. Aquí utilizamos el método de muestreo de vecinos y habilitamos el preprocesamiento. En comparación con el DGL original, GCN y "DGL+Cache" de GraphSAGE logran una aceleración de 1,4 × y 1,3 × debido al mecanismo de almacenamiento en caché. Además del almacenamiento en caché, habilitar la partición de gráficos mejora el rendimiento de los dos modelos GNN en un 25,1% y 28,1% respectivamente. Sin embargo, en este caso, combinar el almacenamiento en caché y la partición no es suficiente para explorar completamente las oportunidades de aceleración del entrenamiento, ya que los costos de carga de datos reducidos, pero no eliminados, aún pueden tener un impacto negativo en el rendimiento general. Por lo tanto, al final, activar la canalización puede reducir aún más el tiempo de entrenamiento por época de GCN y GraphSAGE en un 27,3% y un 29,3%, respectivamente.
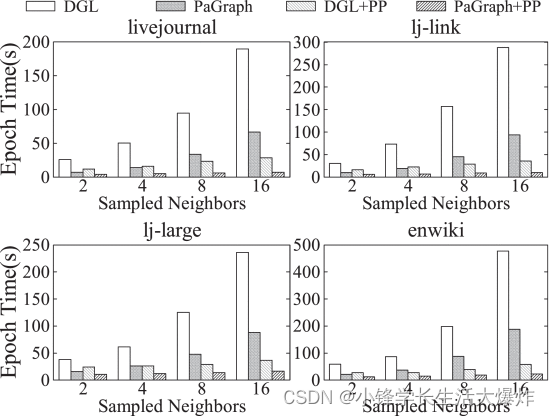
5.7 Impacto de los volúmenes de carga de datos Impacto de los volúmenes de carga de datos
Para verificar la solidez de PaGraph, evaluamos la aceleración del rendimiento en función de la cantidad de datos gráficos necesarios para cada iteración de entrenamiento. La Fig. 19 muestra el rendimiento del entrenamiento con diferentes números de vecinos de muestreo en DGL, DGL+PP, PaGraph y PaGraph+PP. A medida que aumenta la cantidad de vecinos muestreados, el cálculo de GNN consumirá más memoria de GPU, por ejemplo, de 1 GB a 5 GB al cambiar el tamaño del vecino de 2 a 16 en GCN, lo que resultará en una capacidad de caché reducida. Dado que los gráficos almacenados en caché tienen menos funciones, esto puede limitar las mejoras de rendimiento que puede aportar PaGraph. Sin embargo, como se muestra en la Fig. 19, PaGraph supera consistentemente a DGL, y sus variantes combinadas con preprocesamiento pueden lograr aceleraciones de magnitud uniforme (por ejemplo, 27,6 × para livejournal y 27,6 × para lj-link en 16 vecinos muestreados. 29,2 ×). Hay tres razones por las que el rendimiento de PaGraph mejora significativamente cuando se enfrenta a vecinos de mayor tamaño. Primero, para la línea base DGL, el número de vecinos muestreados es mayor y el desequilibrio entre la carga de datos y el cálculo es más grave. En segundo lugar, a pesar de la reducción de espacio, el almacenamiento en caché en la GPU todavía reduce significativamente la carga de datos porque la política de almacenamiento en caché prefiere retener los vértices con grados superiores. En tercer lugar, la canalización puede compensar la penalización en la mejora del rendimiento que supone tener una memoria caché más pequeña, como lo demuestra una evaluación de la eficacia de la memoria caché (consulte la Fig. 14 y la Sección 5.3).
5.8 Respaldo de otros métodos de muestreo Respaldo de otros métodos de muestreo
Para verificar la efectividad del diseño PaGraph sobre otros métodos de muestreo, elegimos el método de muestreo capa por capa como otro caso de estudio, que se diferencia del muestreo adyacente en que el tamaño de cada capa es fijo para evitar el crecimiento exponencial del campo receptivo. . La figura 20a muestra el rendimiento del entrenamiento de GCN y GraphSAGE en tres conjuntos de datos utilizando una sola GPU. Sin preprocesamiento, PaGraph logra una aceleración del entrenamiento de GCN de 2,5 × (lj-large) a 3,1 × (enwiki), y una aceleración del entrenamiento de GraphSAGE de 2,3 × (lj-large) a 2,5 × (enwiki). Después de habilitar el preprocesamiento, la velocidad de entrenamiento de PaGraph+PP aumentó de 1,9× a 2,7× y de 1,9× a 2,6× para GCN y GraphSAGE respectivamente. Estos resultados indican que PaGraph también es aplicable a otros métodos de muestreo y conduce a una aceleración del rendimiento similar. Entendemos mejor la contribución a la aceleración del entrenamiento al desglosar el costo de tiempo en la Fig. 20b en las predicciones. Observamos que PaGraph reduce el tiempo de carga de datos hasta en un 93,5% en comparación con DGL, y PaGraph+PP reduce el tiempo de carga de datos hasta en un 91,3% en comparación con DGL+PP. Al mismo tiempo, el tiempo de carga de datos se puede ocultar mediante cálculos, lo que reducirá aún más el tiempo de entrenamiento hasta en un 34,1%. Finalmente, estudiamos la escalabilidad del entrenamiento GNN utilizando PaGraph. La Fig. 20c muestra que, de manera similar a los métodos de muestreo de vecinos evaluados anteriormente, PaGraph también escala linealmente con muestreo estratificado para entrenar GCN y GraphSAGE en tres conjuntos de datos en hasta 4 GPU.

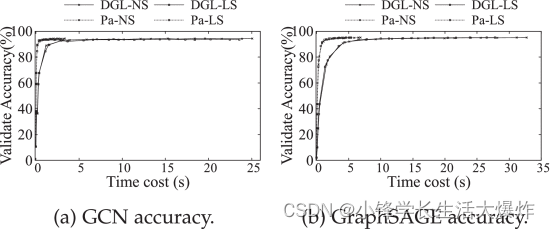
5.9 Convergencia del entrenamiento Convergencia del entrenamiento
Para confirmar la exactitud de nuestra implementación y el impacto de la mezcla, evaluamos el entrenamiento de dos bibliotecas DGL utilizando muestreo de vecinos y muestreo por estratos (NS) sobre PaGraph (con el preprocesamiento habilitado) y en el conjunto de datos de Reddit en 4 GPU. de modelos GNN ejecutados. DGL usa barajado global, mientras que PaGraph usa barajado local. Como se muestra en la Fig. 21a, independientemente del método de muestreo que se utilice, PaGraph converge con aproximadamente la misma precisión que el DGL original en el modelo GCN, pero es mejor que el DGL en velocidad de convergencia en 7,4 × (NS) y 8,5 × (LS). ). Esto se debe a que PaGraph requiere la misma cantidad de iteraciones para lograr la misma precisión, pero itera más rápido en comparación con DGL. Podemos obtener conclusiones similares basándonos en el modelo GraphSAGE de la Fig. 21b. No realizamos experimentos similares en conjuntos de datos distintos de Reddit porque las características de los vértices en estos conjuntos de datos se inicializan aleatoriamente.
Trabajo relacionado Trabajo relacionado
Marco de formación GNN. Los marcos de aprendizaje profundo como PyTorch, MXNet [23] [25] y TensorFlow [9] han sido ampliamente adoptados en el mundo académico y la industria. Sin embargo, estos marcos no proporcionan suficientes operaciones gráficas requeridas por GNN. Por lo tanto, en los últimos años, ha promovido el nacimiento de algunos marcos especializados [10] [11] [13] [43] [45] [46] [47] [48] , que toman prestados y amplían los principios tradicionales de procesamiento de gráficos. La planificación del lenguaje y los vértices se resumen en los marcos de aprendizaje profundo actuales. Por ejemplo, NeuGraph [13] desarrolla primitivas de operación de gráficos a través de Scatter-ApplyEdge-Gather-ApplyVertex (SAGA) para proporcionar un modelo de programación eficiente y conveniente.
Imagen completa versus entrenamiento de muestra. El entrenamiento de gráfico completo entrena un modelo de red neuronal de gráfico con datos de gráfico completos en cada paso hacia adelante y hacia atrás, mientras que el entrenamiento de muestra solo entrena vértices y aristas parciales en cada paso hacia adelante y hacia atrás. Para manejar gráficos grandes que no se pueden completar completamente en la GPU, PBG [46] y NeuGraph [13] dividen el gráfico completo en fragmentos y cargan iterativamente cada fragmento y sus datos de vértice en la CPU y la GPU, respectivamente. Para el entrenamiento de muestra, DGL [10] ubica el gráfico completo y sus datos en la memoria compartida de la CPU y solo carga los datos de vértices y bordes requeridos en la memoria de la GPU al comienzo de cada paso hacia adelante y hacia atrás. Para gráficos grandes, un trabajo reciente [19] ha demostrado que el entrenamiento muestreado puede lograr una convergencia varias veces más rápido que el entrenamiento con gráficos completos con un rendimiento del modelo final similar. AliGraph es una plataforma que admite el entrenamiento GNN basado en muestreo en plataformas CPU en lugar de explorar el potencial de GPU [43].
cache. El almacenamiento en caché de datos de gráficos facilita muchas tareas de procesamiento de gráficos [43], [48]. [49] Preseleccione [49] para aplicar una estrategia de almacenamiento en caché estática para acelerar los cálculos similares a BFS. AliGraph [43] almacena en caché los vértices y sus datos para escenarios de computación distribuida para evitar costos de comunicación entre el entrenador y el almacenamiento remoto. Sin embargo, como verificamos en la Sección 5.3 , su estrategia de almacenamiento en caché no es adecuada para funciones de muestreo basadas en vecinos. ROC [48] apunta al entrenamiento de gráficos completos y explora una estrategia eficaz para intercambiar resultados intermedios de modelos GNN entre CPU y GPU aprovechando la partición y el almacenamiento en caché. Nos diferenciamos de la República de China en que el procesamiento de resultados intermedios no es el enfoque principal del entrenamiento GNN basado en muestreo.
Partición de gráficos. Los gráficos de partición, [8] , [20] [21] [50] [51] se adoptan ampliamente en la informática distribuida [ 52] . PowerGraph [8] diseñó un algoritmo de partición de corte de vértices para gráficos de leyes de potencia. NeuGraph [13] utiliza Kernighan-Lin [21] para dividir el gráfico en bloques con diferentes grados de dispersión. [47] propusieron además un algoritmo de partición de gráficos específico de GNN para reducir la sobrecarga de comunicación entre múltiples máquinas. Todos los algoritmos de partición mencionados anteriormente están diseñados para tareas que no son GNN o entrenamiento GNN de gráfico completo. Nuestro algoritmo de partición está diseñado para entrenamiento de muestra y funciona con almacenamiento en caché.
Otras optimizaciones. Gorder [53] diseñó un método general de reordenamiento de gráficos para acelerar las tareas de procesamiento de gráficos. Norder [49] propuso una técnica de reordenamiento personalizada para tareas similares a BFS. Implementamos estas técnicas en PaGraph pero no encontramos ninguna mejora significativa ni en la calidad de la partición ni en el rendimiento del entrenamiento.
Discusión y trabajo futuro Discusión y trabajo futuro
Si bien creemos que PaGraph puede beneficiar a una amplia gama de modelos y sistemas GNN, todavía quedan algunos desafíos abiertos que deben abordarse antes de hacerlo más general y aplicable a una gama más amplia de entornos.
Relación de carga y cálculo de datos. Como núcleo de PaGraph, la estrategia de almacenamiento en caché funciona bien cuando la fase de carga de datos domina todo el proceso de entrenamiento. Sin embargo, sus proporciones relativas son específicas del modelo. Además de GCN y GraphSAGE, dos modelos GNN representativos y exitosos que se han adoptado ampliamente, también estudiamos otros modelos como GAT, GIN [4] [54] y diffpool [55] . La conclusión inicial aquí es que diffpool requiere más computación en comparación con GAT y GIN, que se parecen a GCN y GraphSAGE. Por lo tanto, se espera que PaGraph se beneficie de una menor difusión que los otros cuatro modelos. Sin embargo, la aparición de la optimización del cálculo GNN [56] puede enfatizar aún más el desequilibrio entre la carga de datos y el cálculo y hacer que PaGraph siga siendo un diseño eficaz para futuros modelos GNN.
Diferentes modos de muestreo y gráficos en evolución. Claramente, el patrón de recorrido del gráfico realizado por el método de muestreo juega un papel clave en la determinación de una buena eficiencia de la caché. Las mejoras de rendimiento de las implementaciones actuales de PaGraph serán limitadas si el método de muestreo correspondiente no asume que es más probable que se seleccionen vértices del gráfico con grados altos. Además, PaGraph adopta una estrategia de partición y almacenamiento en caché estático y, por lo tanto, no puede manejar métodos de muestreo que asumen características que se pueden entrenar o que cambian entre iteraciones, como variables de control [19] . Finalmente, aunque la mayor parte del trabajo existente se centra en gráficos estáticos, el entrenamiento de modelos GNN a través de gráficos dinámicos ha atraído un interés cada vez mayor [57] . [58] Dado que el grado de salida de los vértices y la asimetría del gráfico cambian rápidamente a medida que el gráfico evoluciona, existe la necesidad de diseñar una estrategia dinámica de almacenamiento en caché y partición con una eficiencia de caché sostenida y un costo moderado, así como un canal ajustable para reponer el caché. cuyo rendimiento está limitado por la localidad de los datos y las partes del gráfico almacenadas en caché.
Enfoque centrado en GPU. El problema de eficiencia de carga de datos al que se enfrenta PaGraph está muy relacionado con la arquitectura de coprocesamiento CPU-GPU actual y se utiliza ampliamente en la comunidad DNN. Recientemente, se han realizado algunos esfuerzos preliminares para explorar optimizaciones centradas en GPU para eliminar tales problemas, por ejemplo, muestreo de GPU [59] . Estos métodos proporcionan la mayor aceleración del rendimiento para gráficos pequeños, con funciones que encajan completamente en la memoria de la GPU. En este caso, no sólo se puede eliminar la tediosa etapa de carga de datos de CPU a GPU, sino que también se puede aprovechar la alta densidad de procesamiento y el ancho de banda de memoria de la GPU para un muestreo rápido. Sin embargo, esto sigue siendo un desafío para gráficos más grandes porque el acceso a datos fuera de la CPU y el ancho de banda PCIe limitado que involucra a la GPU pueden anular los beneficios del muestreo de GPU. Afortunadamente, la nueva tecnología de almacenamiento directo GPU [60] proporciona una ruta de datos directa entre el rápido almacenamiento NVMe y la memoria GPU, y demostró experimentalmente un mejor rendimiento de carga de datos al evitar la CPU. Por lo tanto, vale la pena considerar los puntos de diseño de PaGraph en el contexto de la innovación de hardware.
Conclusión
Para acelerar el rendimiento del entrenamiento de GNN en gráficos grandes, proponemos PaGraph, un esquema de entrenamiento general basado en muestreo que aprovecha una combinación de caché con reconocimiento de computación de GNN y partición de gráficos. Implementamos PaGraph en DGL y PyTorch y lo evaluamos con 2 modelos GNN representativos en 7 conjuntos de datos de gráficos utilizando dos métodos de muestreo ampliamente utilizados. Los resultados experimentales muestran que PaGraph oculta completamente el costo de transmisión de datos y logra una mejora de rendimiento de hasta 4,8 veces en comparación con DGL. Con el preprocesamiento, PaGraph puede incluso lograr una mejora de rendimiento de 16,0 veces.
EXPRESIONES DE GRATITUD
Los autores agradecen sinceramente a todos los revisores anónimos por sus valiosos comentarios. Este trabajo fue parcialmente apoyado por el Programa Nacional Clave de I+D de China (2018YFB1003204), parcialmente por la Fundación Nacional de Ciencias Naturales de China (61 802 358) y 61 772 484, y parcialmente por el Fondo de Investigación de Proyectos Dobles de Primera Clase de la Universidad. of Science and Technology of China" YD2150002006 cuenta con el apoyo parcial de Huawei y Microsoft.