Tabla de contenido
Demostración de la nueva versión:
Las principales tecnologías utilizadas por Quiv
El primer paso: ahora el código fuente
Paso 2: Establecer variables de entorno
Paso 5: Demostración del efecto
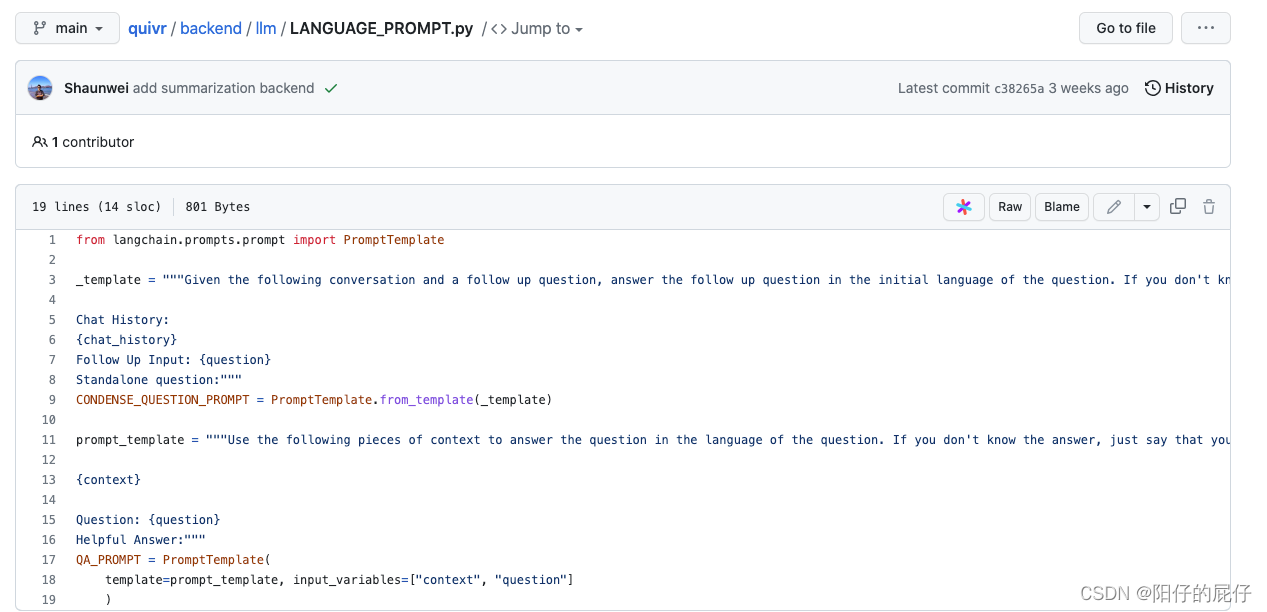
Modificar el aviso de Preguntas y respuestas para Preguntas y respuestas

Hoy tratamos de usar el marco de código abierto Quivr para construir nuestra propia base de conocimiento. El sitio web oficial anuncia a Quivr como su segundo cerebro, aprovechando el poder de la inteligencia artificial generativa para almacenar y recuperar información no estructurada. Puedes pensar en ello como Obsidian con capacidades de IA. Mirando el patrón de introducción en el sitio web oficial, también hay un árbol de sabiduría que crece de obsidiana, y la implicación es realmente asombrosa.
Introducción a Quivr
Quivr utiliza tecnología de inteligencia artificial avanzada para ayudarlo a generar y recuperar información, y puede manejar casi todos los tipos de datos, incluidos texto, imágenes, fragmentos de código, etc. Al mismo tiempo, también se enfoca en la velocidad y la eficiencia, asegurando que se pueda acceder rápidamente a los datos. La seguridad de los datos está bajo tu control. Quivr admite múltiples formatos de archivo, incluidos texto, Markdown, PDF, PowerPoint, Excel, Word, audio, video, etc.
Características de Quivr
- Aceptación universal de datos: Quivr puede manejar casi cualquier tipo de datos que le envíes. Incluyendo texto, Markdown, PDF, PowerPoint, Excel, Word, audio, video y más.
- IA generativa: Quivr utiliza inteligencia artificial avanzada para ayudarlo a generar y recuperar información.
- Rápido y eficiente: debido a que fue diseñado teniendo en cuenta la velocidad y la eficiencia, Quivr garantiza un acceso rápido a los datos.
- Seguro: En cualquier escenario y en cualquier momento, sus datos están bajo su control.
- Open Source: código abierto, gratuito.
Demostración de Quivr
Demostración con GPT3.5:
El siguiente video es una demostración de demostración basada en ChatGPT3.5, que demuestra la construcción de una base de conocimiento y múltiples rondas de diálogo de preguntas y respuestas. https://user-images.githubusercontent.com/19614572/238774100-80721777-2313-468f-b75e-09379f694653.mp4
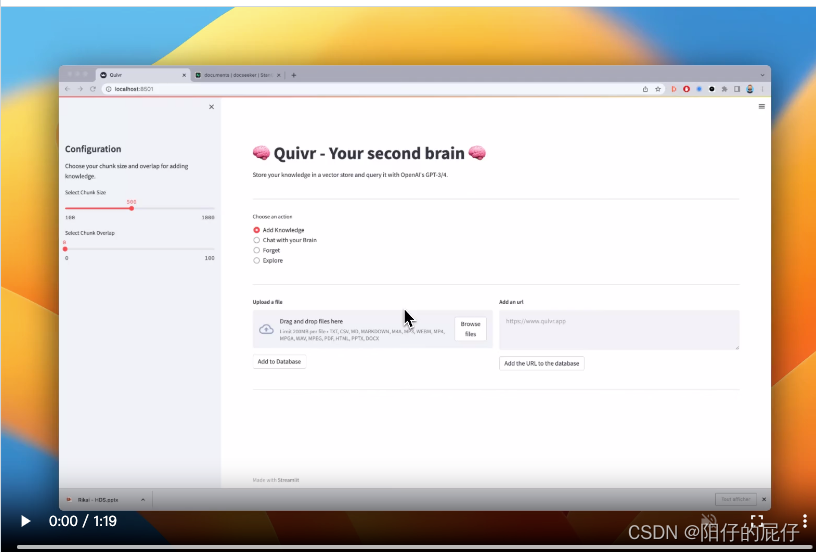
Demostración de la nueva versión:
El siguiente video es un video de demostración de la última versión lanzada a fines de mayo. La nueva versión reemplaza la interfaz de usuario de operación. A continuación, intentamos usar la nueva versión para crear nuestra propia base de conocimientos. https://user-images.githubusercontent.com/19614572/239713902-a6463b73-76c7-4bc0-978d-70562dca71f5.mp4
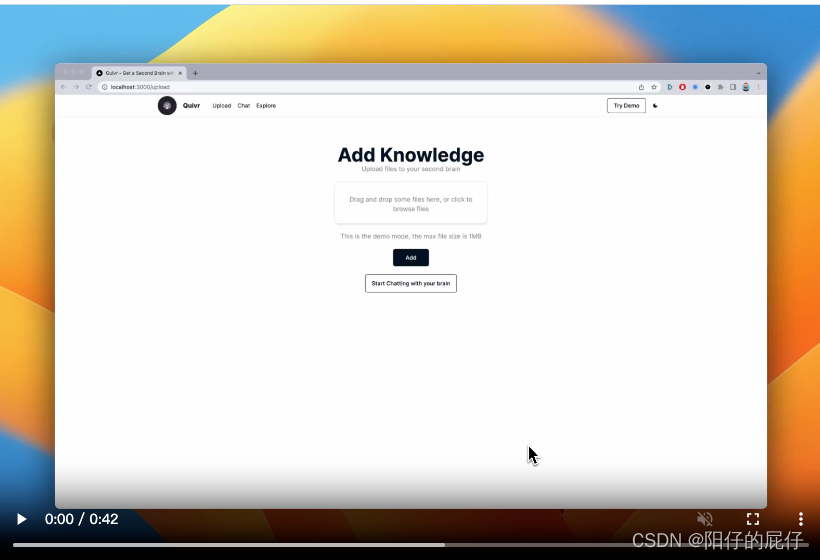
Quivr en acción
Las principales tecnologías utilizadas por Quiv
Quivr, al igual que otras soluciones de base de conocimientos, se basa esencialmente en la interacción entre indicaciones y modelos grandes. Las principales tecnologías utilizadas por Quivr son:
- Maestría en Derecho: GPT3.5 / GPT 4
- Incrustación: incrustación de OpenAI
- Base de conocimientos de vectores: Supabase
- Ventana acoplable:Redacción de ventana acoplable
La práctica de Quiv depende
Hemos mencionado anteriormente que Quivr usa la base de datos vectorial de Supabase, por lo que antes de eso debemos crear una cuenta de Supabase, obtener la clave API del proyecto de Supabase, la URL del proyecto de Supabase y generar varias tablas necesarias.
Crear un proyecto Supabase
La dirección del sitio web oficial de Supabase es: Dashboard | Supabase Si tiene una cuenta de github, puede iniciar sesión directamente con su cuenta de GitHub. Si no tiene una, puede registrarse de otras maneras. Crear un proyecto es relativamente sencillo, los hay de pago y gratuitos a la hora de crearlo, podemos practicar la prostitución directa y optar decididamente por el método gratuito. Una vez creado el proyecto, aparecerá la configuración relevante del proyecto, lo que necesitamos es la marcada en la segunda imagen, si desea volver a encontrar esta información más adelante, puede usar esta dirección: Configuración API | Supabase, o seleccione el proyecto para entrar en la configuración Consultar.


Implementar el proyecto Quiv
Una vez que el entorno previo está listo, comenzamos a implementar el proyecto Quiv.
El primer paso: ahora el código fuente
git clone https://github.com/StanGirard/quivr.git && cd quivr
# 切换到 v0.0.4分支
git checkout v0.0.4
git checkout -b v0.0.4Paso 2: Establecer variables de entorno
Debe modificar las variables de entorno en los directorios frontend y backend, cópielas aquí primero. La imagen a continuación es mi reemplazo local de acuerdo con la configuración en el proyecto creado. Cabe señalar que ANTHROPIC_API_KEY en el directorio backend es la configuración de Claude, podemos eliminarla.
cp .backend_env.example backend/.env
cp .frontend_env.example frontend/.env
![]()

El tercer paso: ejecutar sql
Una vez completada la configuración, el siguiente paso es inicializar la base de datos. Abra el panel de Supabase, haga clic para crear un cuadro de ejecución de sql como se muestra en la siguiente figura y ejecute los siguientes códigos de sql en secuencia.
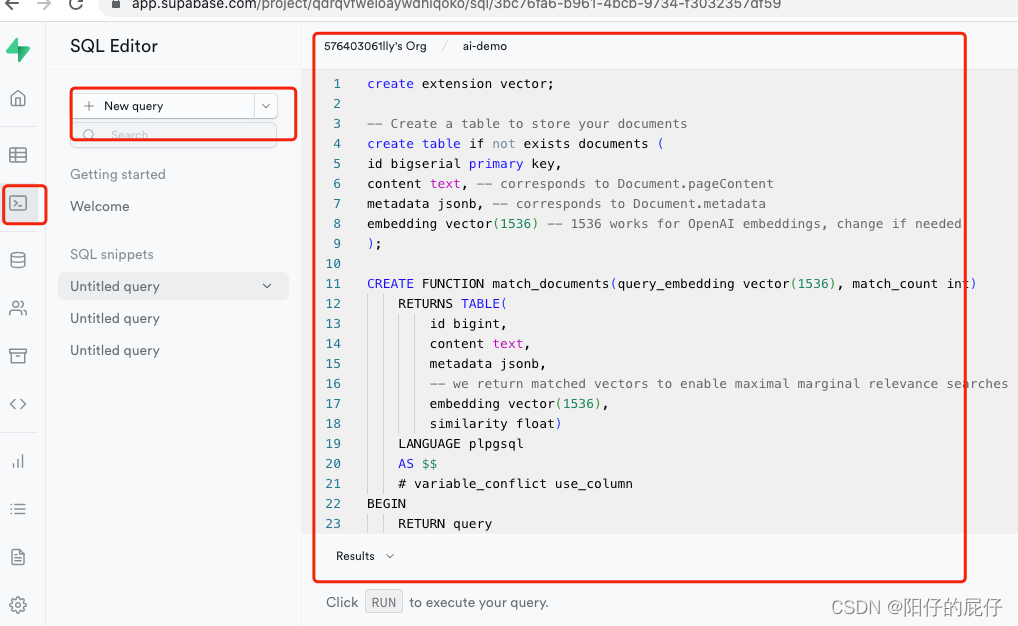

create extension vector;
-- Create a table to store your documents
create table if not exists documents (
id bigserial primary key,
content text, -- corresponds to Document.pageContent
metadata jsonb, -- corresponds to Document.metadata
embedding vector(1536) -- 1536 works for OpenAI embeddings, change if needed
);
CREATE FUNCTION match_documents(query_embedding vector(1536), match_count int)
RETURNS TABLE(
id bigint,
content text,
metadata jsonb,
-- we return matched vectors to enable maximal marginal relevance searches
embedding vector(1536),
similarity float)
LANGUAGE plpgsql
AS $$
# variable_conflict use_column
BEGIN
RETURN query
SELECT
id,
content,
metadata,
embedding,
1 -(documents.embedding <=> query_embedding) AS similarity
FROM
documents
ORDER BY
documents.embedding <=> query_embedding
LIMIT match_count;
END;
$$;create table
stats (
-- A column called "time" with data type "timestamp"
time timestamp,
-- A column called "details" with data type "text"
chat boolean,
embedding boolean,
details text,
metadata jsonb,
-- An "integer" primary key column called "id" that is generated always as identity
id integer primary key generated always as identity
);-- Create a table to store your summaries
create table if not exists summaries (
id bigserial primary key,
document_id bigint references documents(id),
content text, -- corresponds to the summarized content
metadata jsonb, -- corresponds to Document.metadata
embedding vector(1536) -- 1536 works for OpenAI embeddings, change if needed
);
CREATE OR REPLACE FUNCTION match_summaries(query_embedding vector(1536), match_count int, match_threshold float)
RETURNS TABLE(
id bigint,
document_id bigint,
content text,
metadata jsonb,
-- we return matched vectors to enable maximal marginal relevance searches
embedding vector(1536),
similarity float)
LANGUAGE plpgsql
AS $$
# variable_conflict use_column
BEGIN
RETURN query
SELECT
id,
document_id,
content,
metadata,
embedding,
1 -(summaries.embedding <=> query_embedding) AS similarity
FROM
summaries
WHERE 1 - (summaries.embedding <=> query_embedding) > match_threshold
ORDER BY
summaries.embedding <=> query_embedding
LIMIT match_count;
END;
$$;Paso 4: Inicie la aplicación
El trabajo preparatorio en los pasos anteriores está hecho y ahora puede iniciar la aplicación. Cabe señalar que si la versión de Docker es demasiado baja, aparecerá un mensaje de error y será necesario actualizar Docker. Todos pueden actualizar a la versión de acuerdo con su propio tiempo. Este paso tarda mucho en iniciarse porque es necesario empaquetar la imagen e iniciar la aplicación.
docker compose build && docker compose upPaso 5: Demostración del efecto
inicio de sesión de usuario:

Subir base de conocimientos:
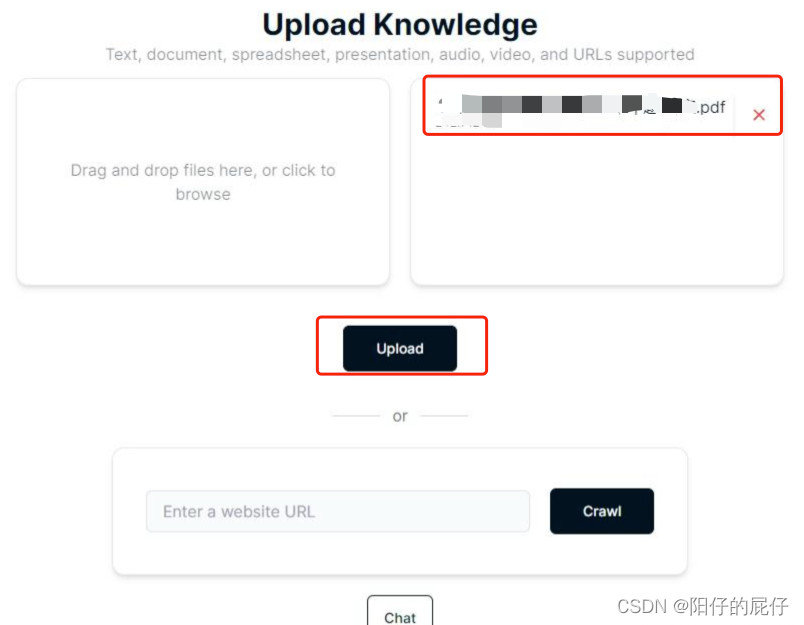
Modificar el aviso de Preguntas y respuestas para Preguntas y respuestas
A continuación, puede realizar preguntas y respuestas en la base de conocimiento. Actualmente, el código fuente aún admite preguntas y respuestas en inglés. Si queremos usar chino, podemos modificar la plantilla de preguntas y respuestas. , jajaja), la ruta del archivo es como sigue: