
Gracias por leer la serie de blogs "Creación de la base de conocimientos de empresas de próxima generación basada en la búsqueda inteligente y modelos grandes". La serie completa se divide en 5 artículos. Presentará sistemáticamente nuevas tecnologías, como la forma en que los modelos de lenguaje grande pueden potenciar los modelos tradicionales. escenarios de la base de conocimientos y ayudar a la industria a reducir los costos del cliente y aumentar la eficiencia. El directorio de actualización es el siguiente:
El primer artículo "Introducción a escenarios prácticos típicos y componentes básicos"
La segunda "guía práctica de implementación rápida" (este artículo)
Tercera parte "Integración de Langchain y su aplicación en el comercio electrónico"
Cuarta parte "Fabricación/Finanzas/Educación y otras industrias Escenarios prácticos" (próximamente)
La quinta "Integración con Amazon Kendra" (próximamente)
fondo
En el primer artículo de esta serie "Introducción a escenarios prácticos típicos y componentes básicos", le presentamos los principios básicos y los antecedentes de esta solución. Creo que ya está ansioso por probar y quiere construir una solución de mejora de modelo de lenguaje grande de búsqueda inteligente en su propio entorno por primera vez. Por lo tanto, hemos escrito este artículo para que los lectores implementen rápidamente la solución. El proceso de implementación de esta solución no es complicado y solo requiere que tenga un conocimiento básico de los servicios relacionados con la tecnología en la nube de Amazon.
Esquema Arquitectura Diagrama y Principio Funcional
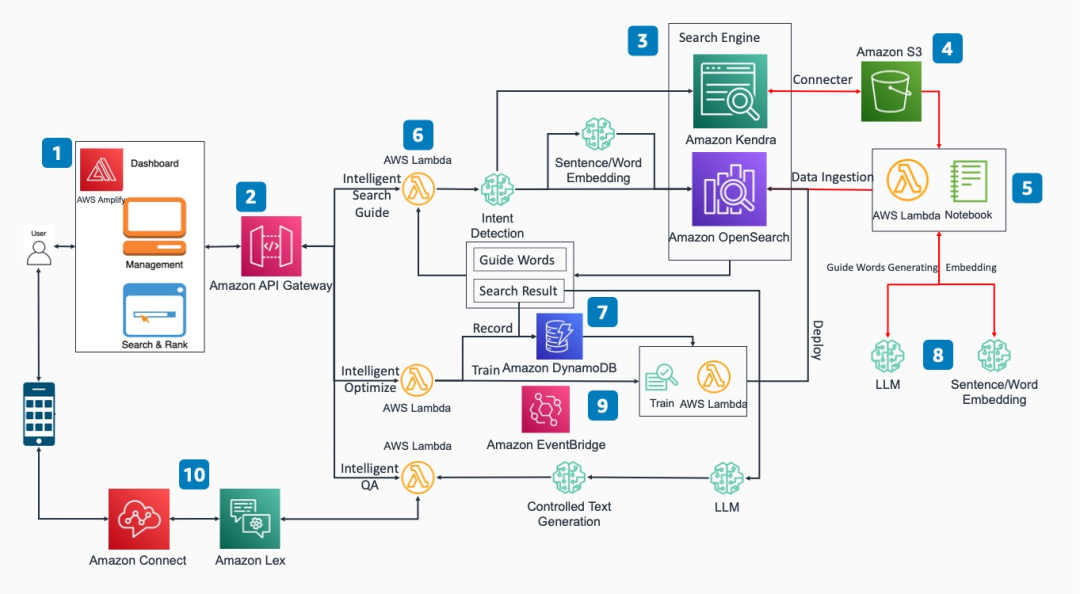
El programa se divide en los siguientes módulos funcionales básicos:
Interfaz de acceso frontal: esta solución proporciona una interfaz de acceso frontal basada en React. Los usuarios pueden realizar funciones como la búsqueda inteligente de documentos en forma de API REST a través de la página web.
REST API: interactúe con motores de búsqueda de back-end, bases de datos y puntos finales de inferencia de modelos a través de implementaciones que integran las funciones correspondientes de Amazon API Gateway y Amazon Lambda.
Motor de búsqueda empresarial: basado en Amazon OpenSearch o Amazon Kendra. Basado en el mecanismo de aprendizaje de retroalimentación bidireccional, puede iterar de forma automática y continua para mejorar la precisión de coincidencia de salida. Al mismo tiempo, se adopta un mecanismo de búsqueda guiada para mejorar la precisión de la descripción de la entrada de búsqueda.
Almacenamiento de origen de datos: se pueden seleccionar varios métodos de almacenamiento, como base de datos, almacenamiento de objetos, etc.. Aquí, Amazon Kendra obtiene objetos en Amazon S3 a través de un conector.
Inyección de datos vectorizados: use el módulo Notebook de Amazon SageMaker o el programa Amazon Lambda para inyectar los datos vectorizados de los datos originales en Amazon OpenSearch.
Módulos funcionales como búsqueda inteligente/orientación/respuesta de preguntas: use las funciones de Amazon Lambda para lograr la interacción con los motores de búsqueda de back-end, las bases de datos y los puntos finales de inferencia de modelos.
Base de datos de registros: los registros de comentarios de los usuarios se almacenan en la base de datos de Amazon DynamoDB.
Modelo de aprendizaje automático: las empresas pueden crear grandes modelos de lenguaje y modelos de vectores de palabras según sus propias necesidades y alojar los modelos seleccionados en los nodos de punto final de Amazon SageMaker.
Optimización de retroalimentación: los usuarios retroalimentan los resultados de búsqueda óptimos en la página de inicio, activan nuevas tareas de capacitación manualmente o a través del desencadenador de eventos Amazon EventBridge y vuelven a implementar en el motor de búsqueda.
Aplicación de complemento: utilizando las capacidades básicas de esta solución, se puede integrar con Amazon Lex para realizar la función de robot de conversación inteligente y también se puede integrar con Amazon Connect para realizar la función de servicio al cliente de voz inteligente.
Introducción a los pasos de implementación
Tomamos como ejemplo la versión v1 de smart-search para explicar todo el proceso de despliegue de la solución.
1. Preparación del entorno
En primer lugar, debe instalar herramientas comunes como python 3, pip y npm en su entorno de desarrollo y asegurarse de que su entorno tenga más de 16 GB de espacio de almacenamiento. De acuerdo con sus hábitos de uso, puede implementar en su propio portátil de desarrollo (entorno Mac OS o Linux) o elegir EC2 o Cloud9 para la implementación.
2. Implementación automática de CDK
2.1 Actualmente, comuníquese con el canal oficial de Amazon Cloud Technology para obtener el código
Línea directa: +86 (10) 1010 0866 o inicie un chat en vivo
Enlace:
https://webchat-aws.clink.cn/chat.html?accessId=1e956ec1-f000-4f41-87f7-ff1d3e6d8b87&language=zh_CN&refid=acts-hero2
Después de obtener el código, cópielo en el directorio especificado. Abra una ventana de terminal, ingrese el paquete smart_search y cambie a la carpeta llamada deployment:
cd smart_search/deploymentDespués de ingresar al directorio de implementación, las operaciones de implementación de CDK correspondientes se realizan en este directorio. Luego instale el paquete Amazon CDK:
npm install -g aws-cdk2.2 Instale todas las dependencias y variables de entorno requeridas por el script de implementación automatizada de CDK
Ejecute el siguiente comando en el directorio de implementación para instalar bibliotecas dependientes:
pip install -r requirements.txtA continuación, importe la información de su cuenta de Amazon de 12 dígitos, el ID de clave de acceso, la clave de acceso secreta y el ID de región para implementarlos en la variable de entorno:
export AWS_ACCOUNT_ID=XXXXXXXXXXXX
export AWS_REGION=xx-xxxx-x
export AWS_ACCESS_KEY_ID=XXXXXX
export AWS_SECRET_ACCESS_KEY=XXXXXXXDesliza a la izquierda para ver más
Luego ejecute "cdk bootstrap" para instalar la cuenta y el kit de herramientas de CDK en la región de destino, por ejemplo:
cdk bootstrap aws://$AWS_ACCOUNT_ID/$AWS_REGIONDesliza a la izquierda para ver más
2.3 La configuración personalizada se puede realizar en cdk.json
El archivo de configuración predeterminado de esta solución se encuentra en el archivo cdk.json en el directorio de implementación. Si desea configurar qué módulos funcionales deben implementarse, puede modificar la parte de "contexto" de cdk.json según sea necesario. Por ejemplo, si necesita modificar qué funciones se implementan, puede modificar el valor de "selección".
Los parámetros predeterminados son los siguientes:
"selecton":["knn","knn_faq","feedback","post_selection","xgb_train","knn_doc"]Desliza a la izquierda para ver más
Si solo necesita usar la "función de búsqueda de documentación habilitada para knn", puede conservar "knn_doc". Además, también puede optar por modificar otros parámetros correspondientes de cdk.json para personalizar el método de implementación, qué complementos implementar y configuraciones como el nombre y la ruta.
2.4 Departamento de automatización de comandos de CDK
Ejecutar el siguiente comando verificará el entorno y generará la plantilla json de Amaon CloudFormation:
cdk synthSi no se informa ningún error, ejecute el siguiente comando para implementar todas las pilas.
cdk deploy --allLa implementación de CDK proporcionará pilas de Amazon CloudFormation relacionadas y recursos relacionados, como Amazon Lambda, Amazon API Gateway, instancias de Amazon OpenSearch e instancias de notebook de Amazon SageMaker, etc. El tiempo de implementación estimado para la instalación es de aproximadamente 30 minutos.
3. Use la instancia de Notebook de Amazon SageMaker para implementar el modelo e importar datos
3.1 Modelo de implementación
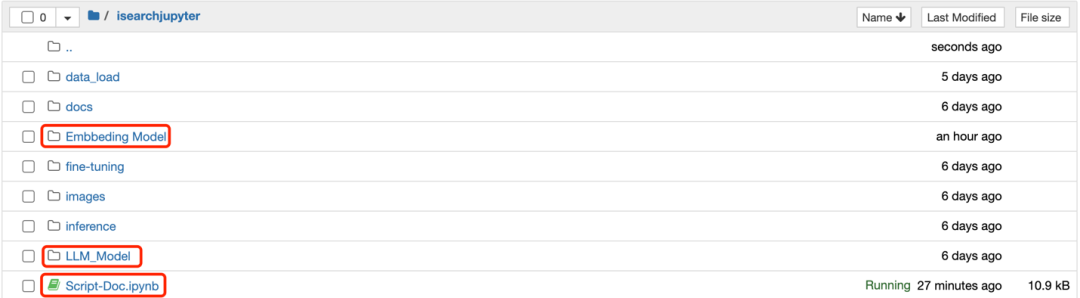
3.1.1 Ingrese a la consola de Amazon SageMaker, ingrese Instancias de NoteBook, seleccione la instancia de SmartSearchNoteBook, haga clic en "Abrir Jupyter", ingrese el directorio de código principal de SmartSearch, haga clic en el directorio "isearchjupyter" para ingresar, puede ver el directorio que incluye el modelo de incrustación, LLM_Model, etc. Los dos directorios contienen secuencias de comandos de implementación del modelo, y la secuencia de comandos Script-Doc.ipynb se utilizará para las cargas de documentos posteriores. Los directorios se muestran en la siguiente figura:
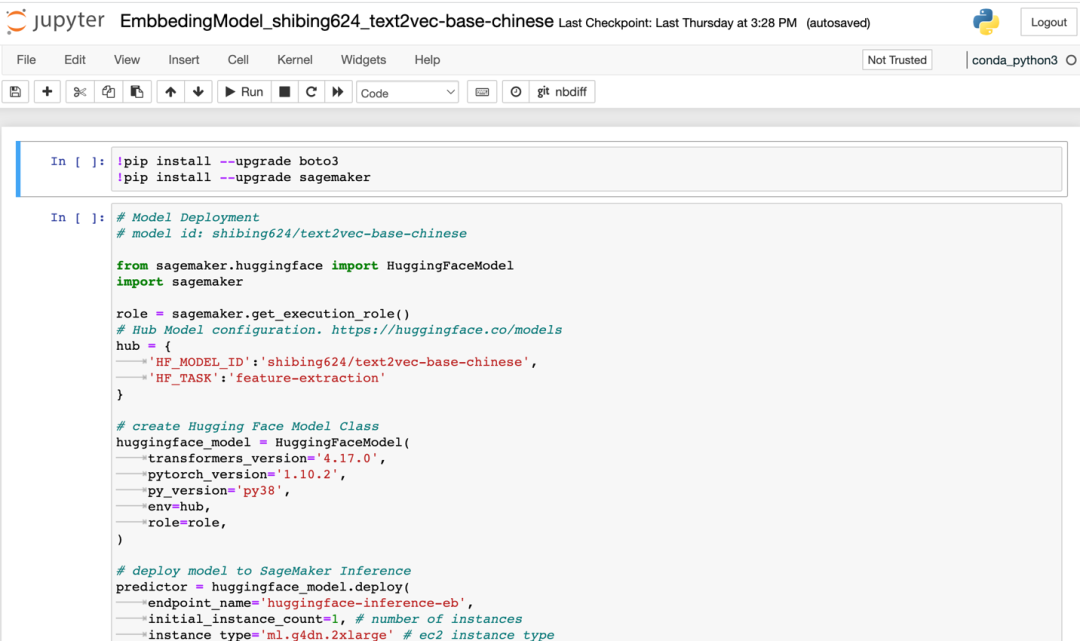
3.1.2 Primero instale el modelo de incrustación, ingrese al directorio "/isearchjupyter/Embbeding Model" y podrá ver varios scripts correspondientes. Entre ellos, "EmbbedingModel_shibing624_text2vec-base-chinese.ipynb" es la palabra modelo vectorial en chino, y los otros dos están en inglés. Abra el script correspondiente y ejecute las celdas una por una para comenzar a implementar el modelo de incrustación. Espere a que se implemente el script. Después de una implementación exitosa, verá un punto de conexión denominado "huggingface-inference-eb" en el punto de conexión de Amazon SageMaker y el estado es "InService".
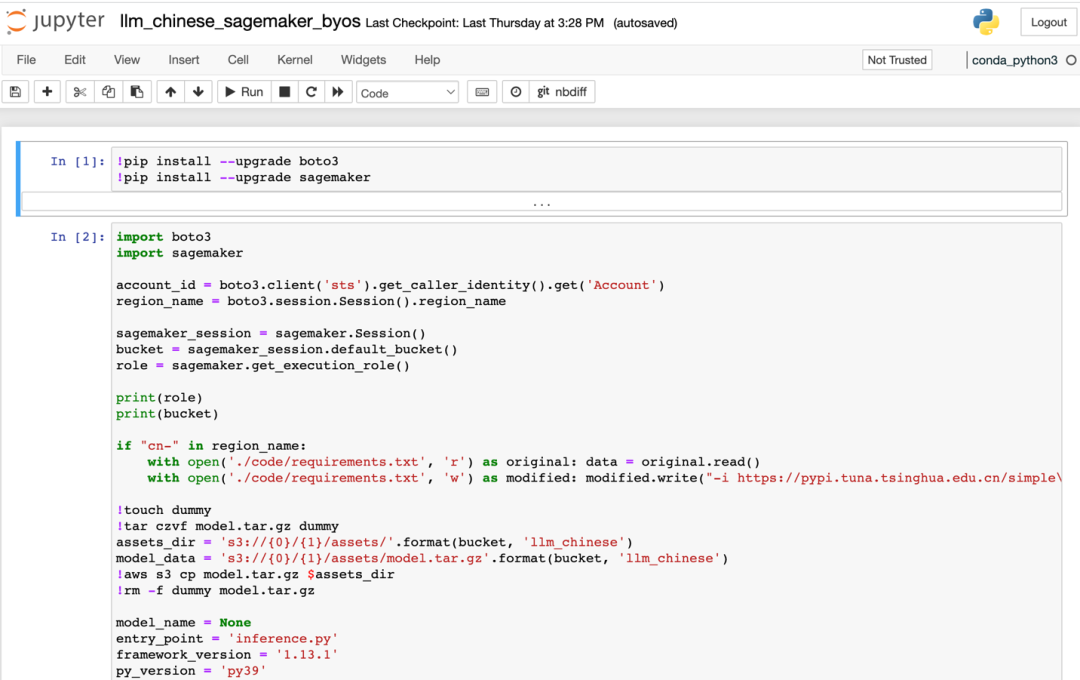
3.1.3 A continuación, implemente el modelo de idioma grande El directorio LLM_Model actualmente contiene bibliotecas de modelos de idioma grande en chino e inglés. Aquí, primero presentaré el método de implementación del modelo de idioma grande chino, busque isearchjupyter/LLM_Model/llm_chinese/code/inference.py, este archivo define el método de implementación unificado del modelo de idioma grande. El modelo de lenguaje grande se puede implementar con un nombre único. Declaramos el nombre único como el valor del parámetro "LLM_NAME" y lo pasamos a la secuencia de comandos de implementación como parámetro. Puede determinar el valor de "LLM_NAME" a partir de la documentación del modelo de lenguaje grande. Usamos la documentación de URL https://huggingface.co/THUDM/chatglm-6b como referencia para ilustrar cómo determinar el valor "LLM_NAME". Después de abrir la URL, consulte el documento para encontrar el nombre único de la implementación del modelo y luego péguelo en la ubicación asignada a "LLM_NAME". Puede consultar este método para hacer inferencias y especificar el modelo de lenguaje grande que necesita utilizar en su proyecto. Después de modificar el archivo inference.py, ingrese al directorio "isearchjupyter/LLM_Model/llm_chinese/" y ejecute el script en este directorio. Espere a que se implemente el script. Después de la implementación correcta, verá un punto de conexión denominado "pytorch-inference-llm-v1" en el punto de conexión de Amazon SageMaker.
Si elige implementar el modelo de idioma grande en inglés, el método de implementación es similar, debe completar los parámetros del modelo de idioma grande en inglés en el parámetro "LLM_NAME" del archivo LLM_Model/llm_english/code/inference.py. Tome https://huggingface.co/TheBloke/vicuna-7B-1.1-HF como ejemplo para ilustrar la implementación del modelo en inglés, busque el nombre del proyecto de modelo de idioma grande, luego copie el nombre y péguelo en la ubicación asignada a "LLM_NAME" , puede usar este método para hacer inferencias y especificar cualquier modelo de lenguaje grande que satisfaga sus necesidades comerciales. Ingrese al directorio "isearchjupyter/LLM_Model/llm_english/" y ejecute las celdas de implementación de los scripts del modelo de idioma grande en inglés en este directorio a su vez. Como se muestra abajo:
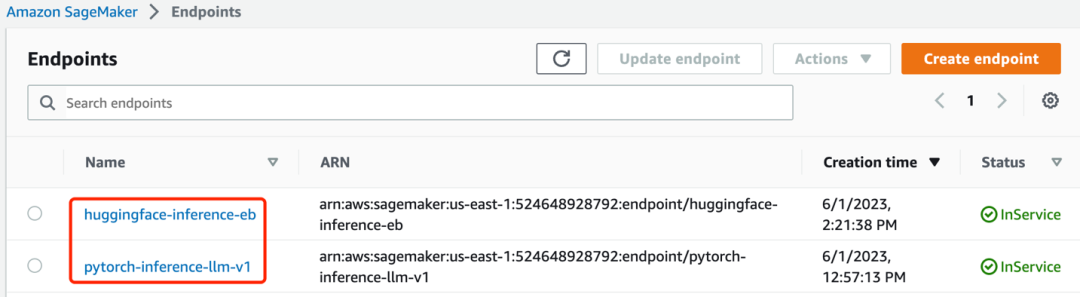
3.1.4 Una vez completada la instalación, verá que los dos puntos finales ya están en el estado "En servicio", como se muestra en la siguiente figura:
3.2 Carga de datos de la base de conocimiento
3.2.1 Preparación de datos. Ingrese al directorio jupyter "/isearchjupyter", en el directorio "docs", cargue los documentos requeridos en formato word, excel o pdf, y el archivo de muestra "sample.docx" para la prueba se proporciona en esta carpeta "(El archivo de muestra se compila a partir de http://www.360doc.com/content/19/1017/08/7696210_867360083.shtml).
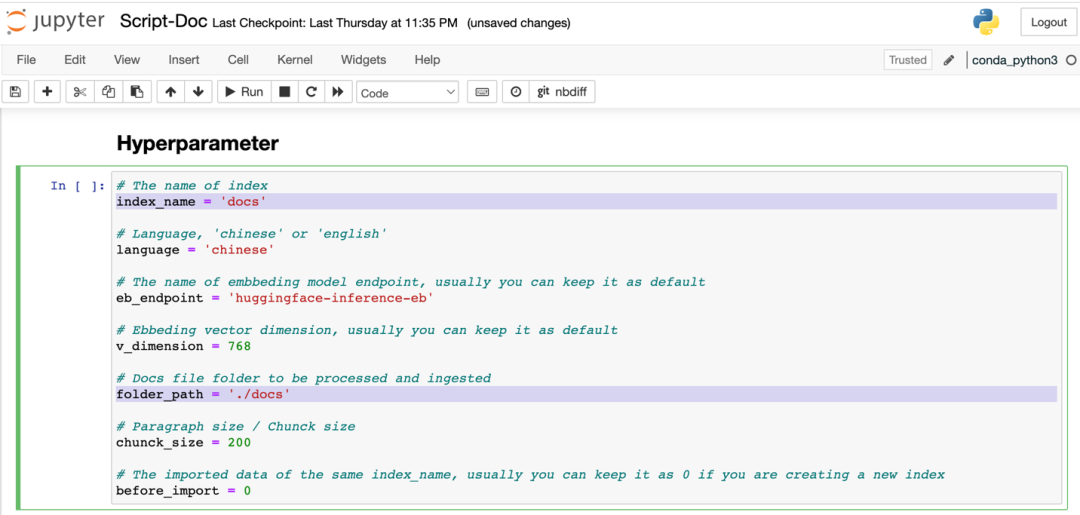
3.2.2 Ingrese Script-Doc.ipynb, modifique los siguientes parámetros en la celda "Hyperparameter", folder_path es el directorio de documentos especificado, index_name es el nombre de índice de Amazon OpenSearch, como se muestra en la siguiente figura:
Luego ejecute el script desde cero para completar la importación de datos.
4. Configurar interfaz de usuario web
4.1 Ingrese al directorio smart_search/ search-web-knn, que contiene el código de interfaz de usuario basado en React. Luego edite el archivo /src/pages/common/constants.js, como se muestra a continuación:
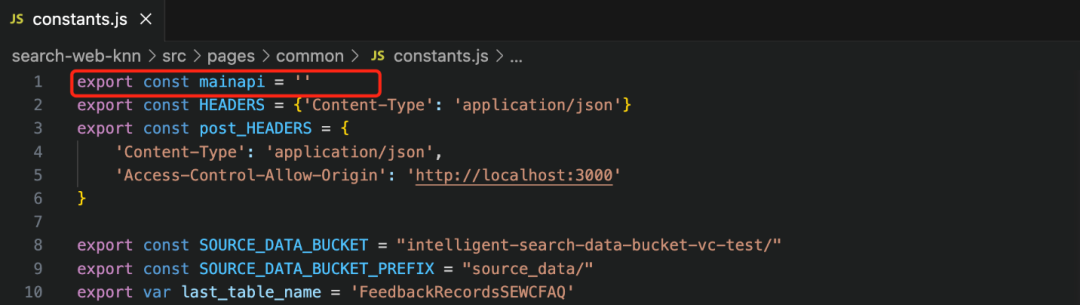
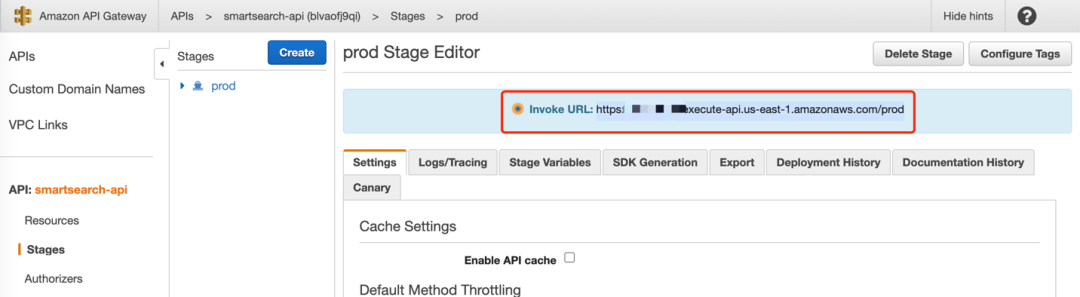
La variable constante de Mainapi especifica la entrada de API para la llamada de front-end. Este valor se puede obtener de API Gateway desde la página web, ingrese a la barra lateral Etapas de "smartsearch-api" y asigne la URL involucrada de la etapa prod a la variable constante mainapi de constants.js, por ejemplo: https:/ /xxxxxxxxxx.execute-api.us-east-1.amazonaws.com/prod.
4.2 Compruebe la configuración de parámetros de la página principal. smart_search/search-web-knn/src/pages/MainSearchDoc.jsx es la página de visualización de la función.En el parámetro last_index de este archivo, se establece el valor de índice predeterminado que se completa automáticamente en la página, y el nombre del índice implementado por el se completa la instancia de Notebook anterior, como "docs".
4.3 Ejecute la interfaz frontal. Ingrese al directorio search-web-knn y ejecute los siguientes dos comandos:
npm installLuego ejecute el siguiente comando para iniciar la interfaz frontal:
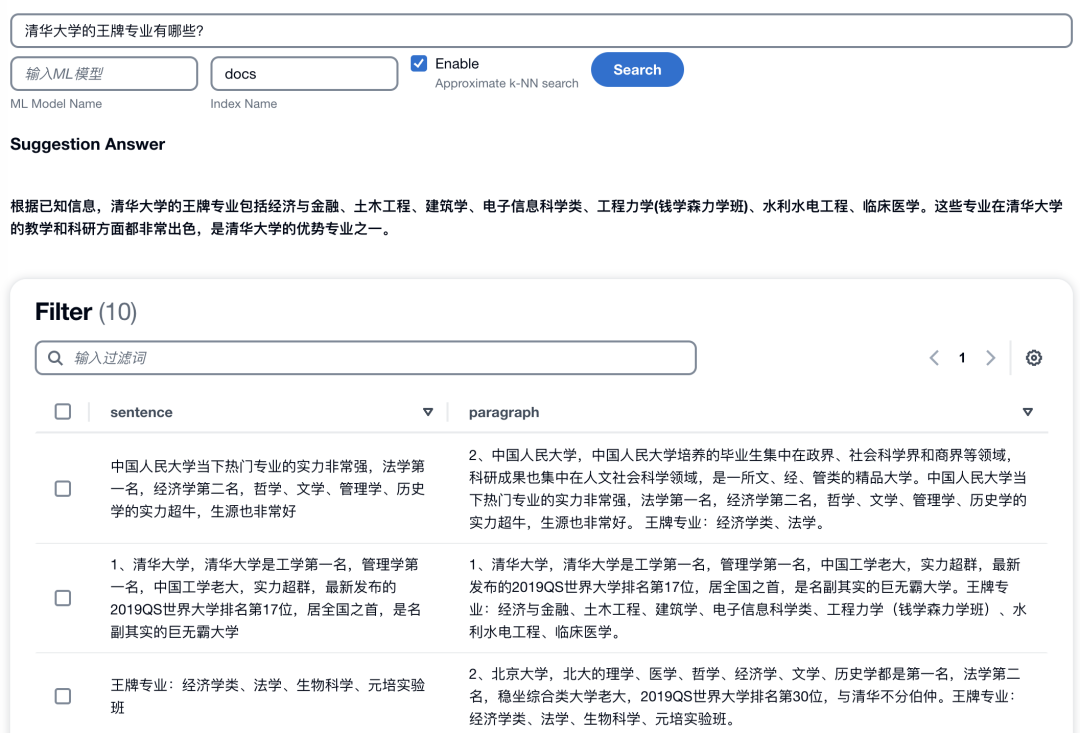
npm startSi todo va bien, obtendrá una interfaz web. La dirección de acceso y el número de puerto predeterminados de la implementación del cuaderno de desarrollo local es localhost: 3000. Si se trata de una implementación de EC2, debe habilitar la política de grupo de seguridad para el acceso al puerto correspondiente y acceder a través de la dirección de red pública de EC2 más el número de puerto. El método para usar la página de inicio es: ingrese la pregunta en la barra de búsqueda, configure el nombre del índice y la opción k-NN, y haga clic en el botón "Buscar" para obtener una respuesta resumida basada en el modelo de lenguaje grande de la empresa. base de conocimientos. Como se muestra abajo:
5. Instala la extensión
5.1 Integración con Amazon Lex para realizar un chatbot inteligente
Esta solución ha integrado la función de robot conversacional de Amazon Lex, y Amazon Lex está actualmente disponible en regiones del extranjero. En el archivo cdk.json, agregue "bot" a la clave de extensión.
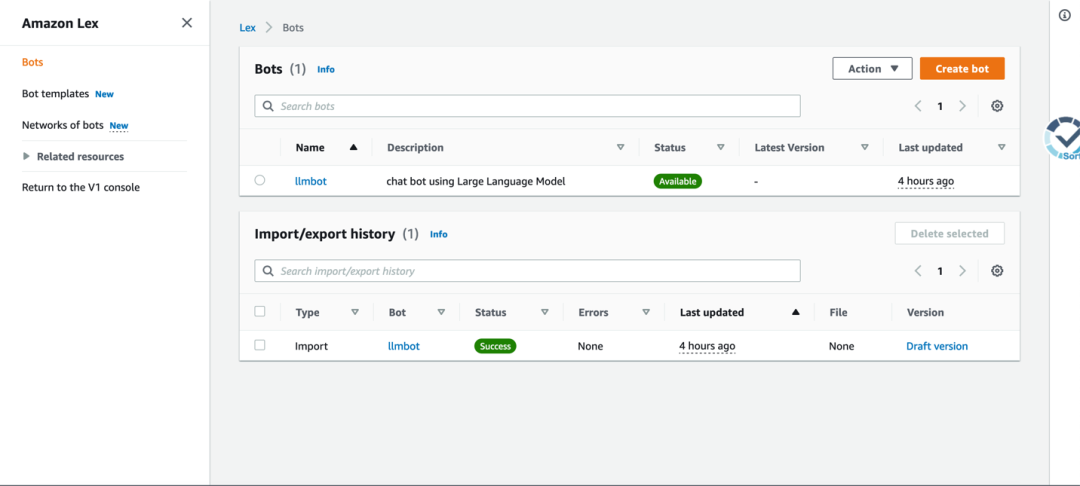
"extension": ["bot"]Después de que la implementación de cdk sea exitosa, ingrese a la interfaz de administración y podrá ver un robot de diálogo llamado "llmbot", como se muestra a continuación:
El robot puede integrar fácilmente la página de inicio. Por ejemplo, puede iniciar la plantilla de implementación en el área correspondiente en https://github.com/aws-samples/aws-lex-web-ui y pasar la información de llmbot ( LexV2BotId, ID de alias, etc.) para completar la plantilla de CloudFormation. La interfaz de trabajo del robot Lex se muestra en la siguiente figura.
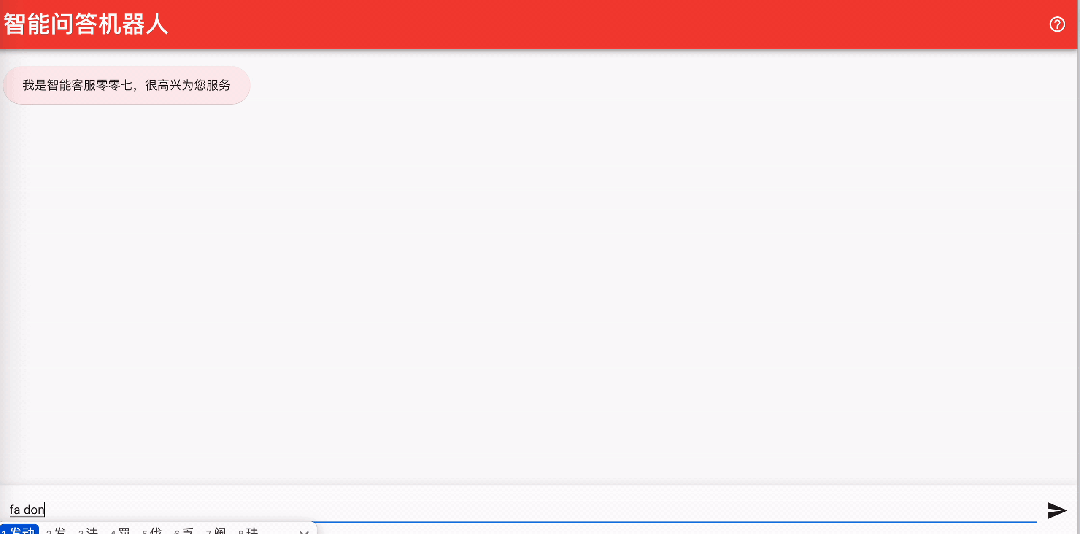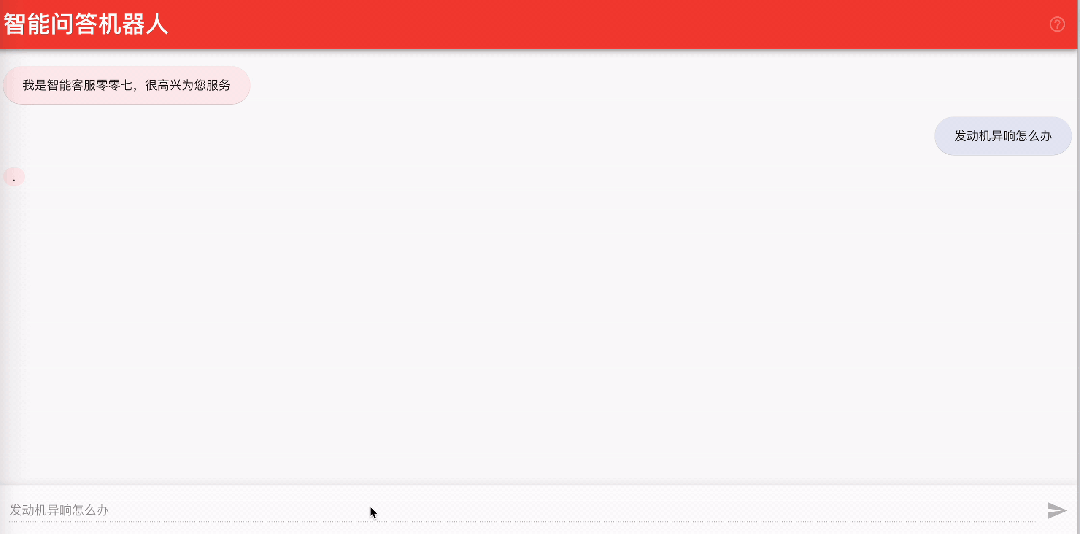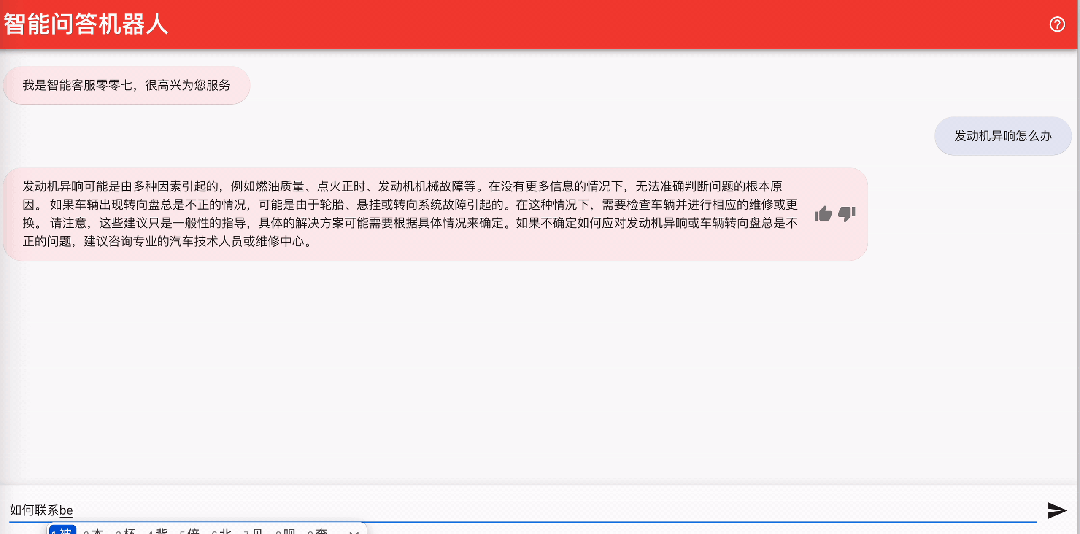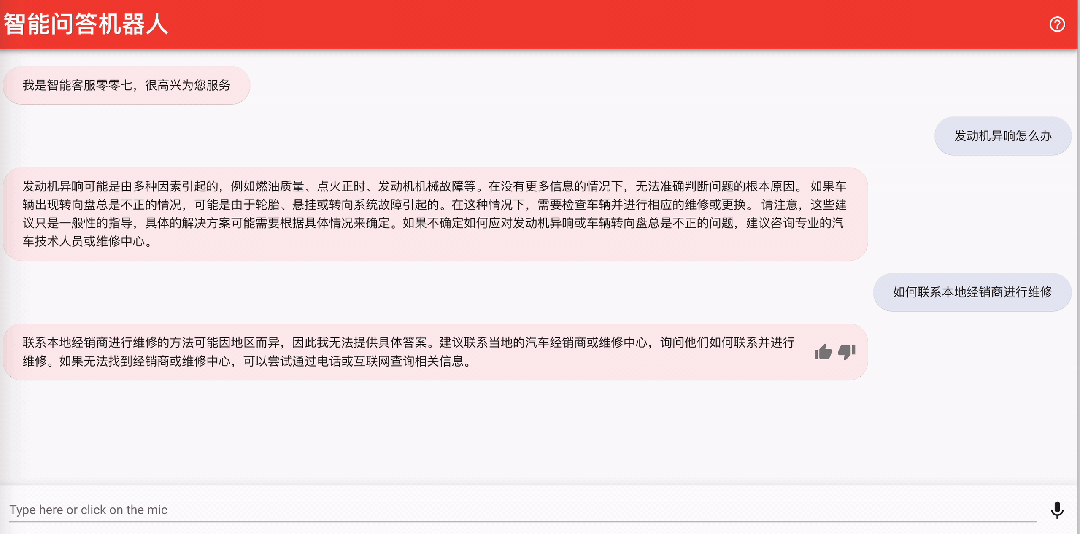
5.2 Integración con Amazon Connect para realizar un servicio de atención al cliente de voz inteligente
Amazon Connect es el servicio de centro de llamadas en la nube de Amazon Cloud Technology, que actualmente está disponible en regiones en el extranjero. Esta solución puede integrar la capacidad del modelo de lenguaje grande en el centro de llamadas en la nube de Amazon Connect a través del robot Amazon Lex, y puede obtener un robot de servicio al cliente inteligente que admita llamadas de voz a través de los siguientes pasos.
5.2.1 Integre el robot llmbot generado en el paso anterior en la instancia de Amazon Connect existente.
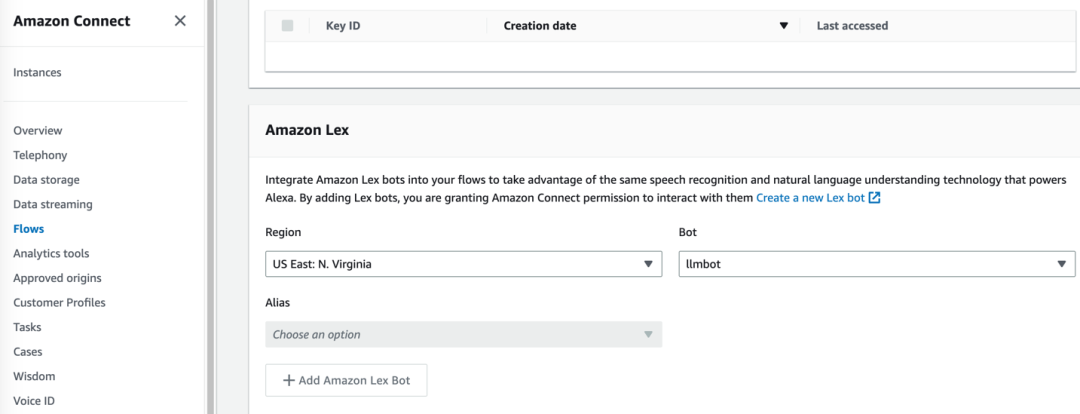
5.2.2 Luego ingrese a la instancia de Amazon Connect, importe los archivos en smart-search/extension/connect a Contact Flow, guarde y publique.
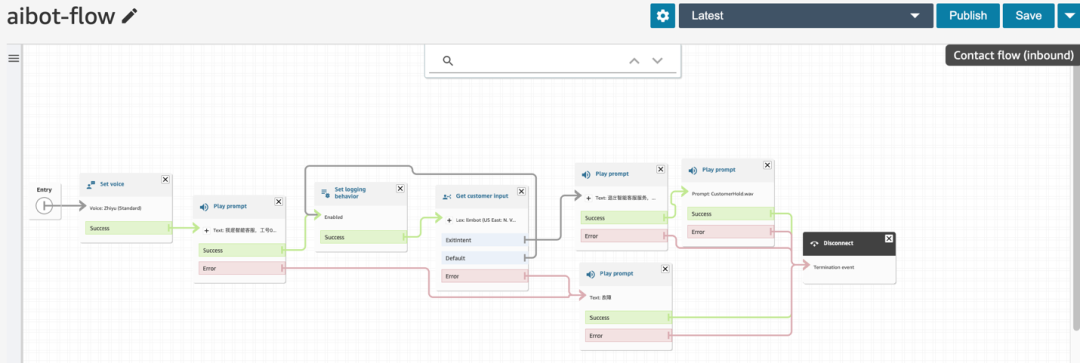
5.2.3 Finalmente, asocie el número de llamada entrante con el Flujo de contacto configurado en el paso anterior en Amazon Connect. Luego, todas las llamadas de voz a este número se conectarán al proceso de servicio de llamadas del servicio de atención al cliente inteligente.
En circunstancias normales, el servicio de atención al cliente inteligente reconocerá la entrada de voz de la persona que llama, y luego el robot de servicio de atención al cliente inteligente integrado en Amazon Connect responderá de manera lógica cerca de los humanos según la información de la base de conocimiento empresarial y la capacidad de los grandes. modelo de lenguaje El siguiente audio muestra el caso de servicio al cliente inteligente de esta solución utilizada en la escena de posventa de automóviles, haga clic para reproducir:
6. Limpieza de recursos
Cuando desee limpiar los recursos, utilice el siguiente comando para eliminar todas las pilas:
cdk destroy --allNota: Los recursos del modelo de inferencia creados a través de la instancia de Notebook de Amazon SageMaker deben eliminarse manualmente. Ingrese "punto final" en la barra lateral "inferencia" de Amazon SageMaker y haga clic en "eliminar" para eliminar todos los puntos finales.
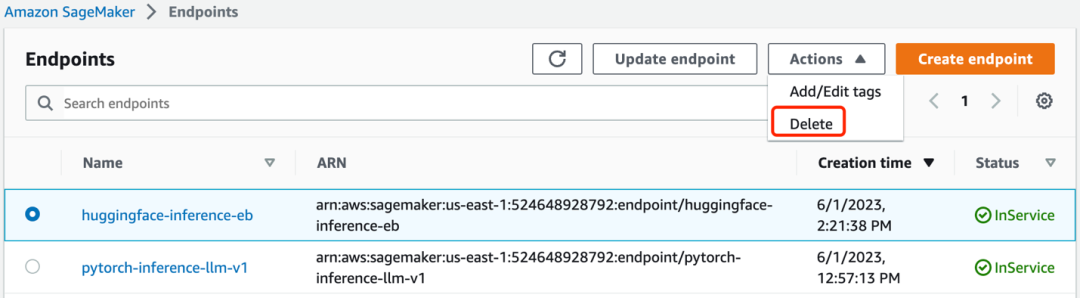
Cuando ya hay datos en el depósito de Amazon S3 creados por la pila u otros recursos creados o modificados manualmente, también deben eliminarse manualmente.
Resumir
A través de esta implementación, ha dominado con éxito el método de implementación de la solución y obtuvo una comprensión más profunda de la solución. También continuaremos iterando y optimizando la solución para admitir más tipos de datos, bibliotecas de modelos y funciones extendidas, y luego extenderemos las capacidades de la solución a más escenarios comerciales. Esta solución puede resolver escenarios profesionales o generales en muchas industrias y campos, y también se espera que aplique esta solución a los escenarios comerciales reales de su empresa. Al usar esta solución, puede utilizar los últimos avances en inteligencia artificial y tecnología de nube de Amazon. productos para inyectar nueva vitalidad en el desarrollo de la industria.
El autor de este artículo

Peng Xu
Arquitecto de soluciones de la industria automotriz de tecnología en la nube de Amazon, tiene más de diez años de experiencia en la investigación y el desarrollo de dispositivos electrónicos y de conducción autónoma para empresas internacionales de vehículos, se ha desempeñado como la persona a cargo de la verificación y prueba de big data de conducción autónoma de alto nivel, incluida la recopilación de big data, la verificación de simulación de big data, el análisis de big data y el aprendizaje automático y el diseño e implementación de otras soluciones. Actualmente se centra en la conducción autónoma, las redes de automóviles, los automóviles definidos por software y otros negocios.

Shi Feng
Senior Solution Architect de Amazon Cloud Technology, responsable del diseño e implementación de soluciones en la industria de la educación y la industria del transporte. Ha trabajado en Alibaba Cloud durante seis años, responsable de los equipos técnicos de proyectos de gran envergadura como transporte, gobierno, Juegos Olímpicos, medios deportivos, etc. Ha trabajado en IBM y Oracle durante 10 años, y ha trabajado en varios Industrias para computación en la nube, big data, inteligencia artificial, Internet de las cosas. Tiene una rica experiencia práctica en campos como Metaverse.

Liang Yiming
Arquitecto de soluciones de tecnología en la nube de Amazon, dedicado al diseño, aplicación y promoción de la arquitectura de soluciones de computación en la nube. Con 15 años de experiencia laboral en la industria de TI, es bueno en el desarrollo y la protección de recuperación de datos ante desastres. Ha trabajado como ingeniero de desarrollo de software, gerente de proyectos y arquitecto de sistemas. Antes de unirse a Amazon Cloud Technology, trabajó para EMC, Microsoft y otras empresas.

yang zhihao
Arquitecto de soluciones de tecnología en la nube de Amazon, responsable de la consultoría y el diseño de la arquitectura de las soluciones de computación en la nube basadas en la tecnología de la nube de Amazon, que actualmente se enfoca en la industria de la energía nueva. Comprometidos con la promoción de la aplicación de la tecnología HPC e IoT en las industrias de energía eólica, fotovoltaica y otras nuevas energías.


Escuché, haga clic en los 4 botones a continuación
¡No encontrarás errores!
