Directorio de artículos
prefacio
La primera búsqueda en profundidad ( DFS ) es un algoritmo para atravesar o buscar una estructura de datos de árbol o gráfico. El algoritmo comienza desde el nodo raíz (en el caso de un gráfico, elige algún nodo arbitrario como nodo raíz) y explora lo más lejos posible a lo largo de cada rama antes de retroceder. Se requiere memoria adicional, generalmente una pila, para realizar un seguimiento de los nodos descubiertos hasta el momento a lo largo de una rama determinada, lo que facilita el seguimiento.
Las características del algoritmo de búsqueda primero en profundidad:
- Comenzando desde un nodo inicial, continúe visitando los nodos adyacentes a lo largo de una ruta hasta que no haya nodos adyacentes sin visitar, y luego regrese al nodo anterior y continúe visitando otros nodos adyacentes.
- Utilice la pila o la recursividad para lograrlo.
- Se puede generar una tabla ordenada topológicamente correspondiente del gráfico de destino.
Ventajas del algoritmo de búsqueda primero en profundidad:
- Simple y fácil de implementar.
- Ocupa menos espacio.
- Se puede encontrar una ruta desde un nodo inicial hasta cualquier nodo accesible.
Desventajas del algoritmo de búsqueda primero en profundidad:
- No es necesariamente posible encontrar el camino más corto o la solución óptima.
- Puede caer en un bucle infinito o recursión infinita.
Escenarios de aplicación del algoritmo de búsqueda primero en profundidad:
- Clasificación topológica (calendario del curso, progreso del proyecto, dependencias)
- Juegos de simulación (por ejemplo, ajedrez, laberintos, etc.)
- Detección de conectividad (como juzgar si hay un ciclo en el gráfico, etc.)
- Problema del viajante de comercio (como encontrar el camino más corto, etc.)
- Coincidencia de corchetes (como verificar si los corchetes en la expresión coinciden, etc.)
- Recorrido de estructuras de datos como árboles binarios, árboles de segmento de línea, árboles rojo-negro y gráficos
En este artículo, presentaremos los principios básicos y la implementación del algoritmo de búsqueda primero en profundidad, y demostraremos su aplicación a través de algunos ejemplos.
1. Realización
1.1 Implementación recursiva
Comenzando desde un nodo inicial, visite los nodos adyacentes a lo largo de una ruta hasta que no haya nodos adyacentes sin visitar, luego retroceda al nodo anterior y continúe visitando otros nodos adyacentes hasta que todos los nodos hayan sido visitados.
El código de ejemplo es el siguiente:
public void dfs(int start) {
visited[start] = true; //将起始节点标记为已访问
for (int i = 0; i < n; i++) {
//遍历邻接矩阵中start所在行
if (matrix[start][i] == 1 && !visited[i]) {
//如果存在边且未被访问过
dfs(i); //递归调用dfs方法,以该节点为新起点进行遍历
}
}
}
1.2 Implementación de pila
Comience con un nodo de inicio, empújelo a la pila y repita los siguientes pasos: extraiga el elemento superior de la pila y márquelo como visitado; empuje todos los vecinos no visitados de ese elemento a la pila. hasta que la pila esté vacía
El código de ejemplo es el siguiente:
public void dfs(int start) {
Stack<Integer> stack = new Stack<>(); //创建栈对象
stack.push(start); //起始节点入栈
Set<Integer> visited = new HashSet<>(); //创建集合对象
visited.add(start); //起始节点加入集合
while (!stack.isEmpty()) {
//只要栈不为空就继续循环
int cur = stack.peek(); //获取栈顶元素但不出栈
boolean flag = false; //设置标志位,表示是否有未访问过的邻接节点
for (int i = 0; i < n; i++) {
//遍历邻接矩阵中cur所在行
if (matrix[cur][i] == 1 && !visited.contains(i)) {
//如果存在边且未被访问过
stack.push(i); //将该节点入栈
visited.add(i); //将该节点加入集合
System.out.print(i + " "); //打印该节点
flag = true; //修改标志位为true,表示有未访问过的邻接节点
break; //跳出循环,以该节点为新起点进行遍历
}
}
if (!flag) {
//如果没有未访问过的邻接节点,则说明已经到达最深处,需要回溯上一层继续遍历其他分支路径。
stack.pop(); //将栈顶元素出栈
}
}
}
La siguiente es una animación de la búsqueda de dfs
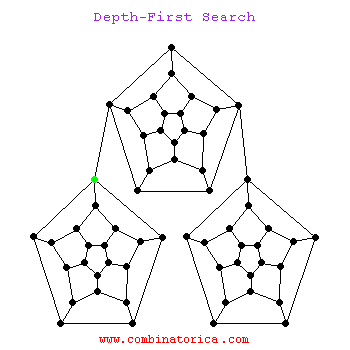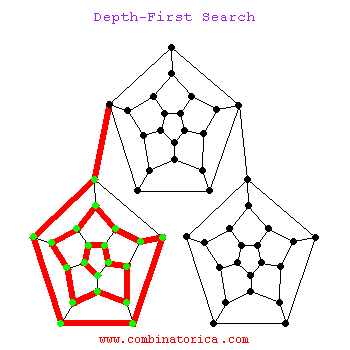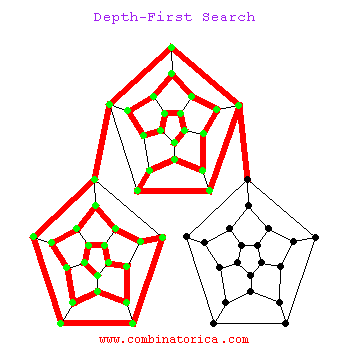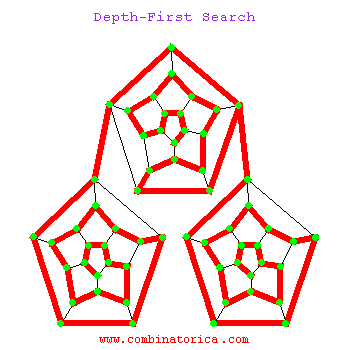
1.3 La diferencia entre los dos
- La implementación recursiva consiste en utilizar la pila del sistema para guardar el estado del nodo actual. Cuando se encuentra un callejón sin salida, volverá automáticamente al nodo anterior para continuar con la búsqueda. La implementación de la pila utiliza una pila personalizada para guardar el estado del nodo actual. Cuando se encuentra un callejón sin salida, el elemento superior de la pila se vuelve a colocar manualmente en el nodo anterior para continuar con la búsqueda.
- La implementación recursiva es relativamente concisa y fácil de entender, pero la eficiencia no es alta y puede causar un desbordamiento de pila para gráficos a gran escala. La implementación de la pila es más complicada, pero es más eficiente y puede evitar el problema del desbordamiento de la pila.
- Tanto la implementación recursiva como la implementación de pila necesitan una matriz de banderas para registrar qué nodos se han visitado para evitar visitas repetidas o bucles.
2. Combate real LeetCode
2.1 Prepedido de recorrido del árbol binario
94. Pedido anticipado de recorrido de árboles binarios
Dado el nodo raíz de su árbol binario , devuelva un recorrido de preorden
rootde sus valores de nodo .
List<Integer> ans = new ArrayList(); //定义一个整数列表,用来存储前序遍历的结果
public List<Integer> preorderTraversal(TreeNode root) {
if (root != null) {
//如果当前节点不为空,才进行以下操作
ans.add(root.val); //把当前节点的值加入列表
preorderTraversal(root.left); //递归地对左子树进行前序遍历
preorderTraversal(root.right); //递归地对右子树进行前序遍历
}
return ans; //返回前序遍历的结果
}
2.2 Número de islas
Dada una cuadrícula bidimensional que consta de
'1'(tierra) y (agua), cuente el número de islas en la cuadrícula.'0'Las islas siempre están rodeadas de agua, y cada isla solo se puede formar conectando tierra adyacente horizontal y/o verticalmente.
Además, puede suponer que la malla está rodeada de agua por los cuatro costados.
// 定义一个二维数组pos,表示四个方向
int[][] pos = {
{
0, 1 }, {
1, 0 }, {
0, -1 }, {
-1, 0 } };
// 定义一个变量ans,表示岛屿的数量
int ans = 0;
// 定义一个方法numIslands,接受一个二维字符数组grid作为参数,返回岛屿的数量
public int numIslands(char[][] grid) {
// 获取grid的行数和列数
int m = grid.length, n = grid[0].length;
// 定义一个二维布尔数组visited,表示每个位置是否被访问过
boolean[][] visited = new boolean[m][n];
// 遍历grid中的每个位置
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
// 如果当前位置是'1'且没有被访问过,则从该位置开始深度优先搜索,并将ans加一
if (grid[i][j] == '1' && !visited[i][j]) {
dfs(grid, visited, i, j);
ans++;
}
}
}
// 返回ans作为结果
return ans;
}
// 定义一个方法dfs,接受一个二维字符数组grid、一个二维布尔数组visited、两个整数i和j作为参数,无返回值
public void dfs(char[][] grid, boolean[][] visited, int i, int j) {
// 如果i或j越界或者当前位置是'0'或者已经被访问过,则直接返回
if (i < 0 || i >= grid.length || j < 0 || j >= grid[0].length || grid[i][j] == '0'
|| visited[i][j]) {
return;
}
// 将当前位置标记为已访问
visited[i][j] = true;
// 遍历四个方向,并递归调用dfs方法
for (int[] p : pos) {
dfs(grid, visited, i + p[0], j + p[1]);
}
}
2.3 Contando el número de islas cerradas
1254. Cuenta el número de islas cerradas
La matriz bidimensional consta
gridde0(tierra) y1(agua).0Una isla es un grupo compuesto por las 4 direcciones más grandes conectadas , y una isla cerrada es una完全isla rodeada por 1 (izquierda, arriba, derecha, abajo).Por favor devuelva el número de islas cerradas .
// 定义一个二维数组pos来存储上下左右四个方向的偏移量
int[][] pos = {
{
0, 1 }, {
1, 0 }, {
0, -1 }, {
-1, 0 } };
// 定义一个变量ans来记录封闭岛屿的个数
int ans = 0;
public int closedIsland(int[][] grid) {
// 判断矩阵是否为空,如果为空,直接返回0
if (grid == null || grid.length == 0 || grid[0].length == 0) {
return 0;
}
// 获取矩阵的行数和列数
int m = grid.length, n = grid[0].length;
// 遍历矩阵中的每一个元素
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
// 如果当前元素是岛屿(0),则调用dfs函数来检查它是否被水域(1)完全包围
if (grid[i][j] == 0 && dfs(grid, i, j)) {
// 如果dfs函数返回true,说明当前岛屿是封闭的,ans加一
ans++;
}
}
}
// 返回ans作为最终答案
return ans;
}
public boolean dfs(int [][] grid, int i, int j) {
// 如果当前坐标超出了矩阵的边界,说明当前岛屿不是封闭的,返回false
if (i < 0 || i >= grid.length || j < 0 || j >= grid[0].length) {
return false;
}
// 如果当前元素是水域(1),说明没有遇到边界,返回true
if (grid[i][j] == 1) {
return true;
}
// 将当前元素标记为水域(1),避免重复访问
grid[i][j] = 1;
// 使用一个for循环来遍历上下左右四个方向,并将结果进行逻辑与运算
boolean res = true;
for (int [] p: pos) {
res &= dfs(grid, i + p[0], j + p[1]);
}
// 返回res作为dfs函数的结果
return res;
}
2.4 Restaurar el árbol binario desde el recorrido de preorden
1028. Restaurar árbol binario desde Preorder Traversal
Hacemos
rootuna búsqueda en profundidad comenzando desde el nodo raíz del árbol binario.En cada nodo del recorrido, generamos
Dguiones (dondeDestá la profundidad del nodo), seguidos del valor del nodo. ( Si un nodo tiene una profundidad deD, entonces sus hijos inmediatos tienen una profundidad deD + 1. El nodo raíz tiene una profundidad de0).Si el nodo tiene solo un hijo, se garantiza que ese hijo sea el hijo izquierdo.
Dada la salida transversal
S, restaure el árbol y devuelva su nodo raízroot.
int index = 0; // 定义全局变量index
public TreeNode recoverFromPreorder(String traversal) {
int[] deep = Arrays.stream(traversal.split("[0-9]{1,10}")).mapToInt(String::length).toArray(); // 将输入字符串按照数字分割成数组deep
int[] number = Arrays.stream(traversal.split("-{1,100}")).mapToInt(Integer::parseInt).toArray(); // 将输入字符串按照连字符分割成数组number
if (deep.length == 0) deep = new int[]{
0}; // 如果deep为空,则赋值为[0]
return dfs(deep, number); // 调用dfs函数并返回结果
}
public TreeNode dfs(int [] deep, int [] number) {
TreeNode treeNode = new TreeNode(number[index]); // 创建新的TreeNode对象并赋值
int curHeight = deep[index]; // 获取当前节点的深度
if (index + 1 < deep.length && curHeight == deep[index + 1] - 1) {
// 判断是否有左子节点
index++; // 将index加1
treeNode.left = dfs(deep, number); // 递归调用dfs并赋值给左子节点
}
if (index + 1 < deep.length && curHeight == deep[index + 1] - 1) {
// 判断是否有右子节点
index++; // 将index加1
treeNode.right = dfs(deep, number); // 递归调用dfs并赋值给右子节点
}
return treeNode; // 返回当前节点
}