Estructuras de datos y algoritmos I
Preguntas de entrevista
1.Base de datos
-
La base de datos tiene dos tablas la tabla de usuarios y la tabla user_role. Luego de ejecutar: SELECT u.*,r.
nameFROM USER u LEFT JOIN user_role r ON u.id= r.user_id, el resultado obtenido es: (A)联查: left join/right join : 特点:主表的所有数据均显示,另外一张表中有匹配的数据,则显示,若无匹配的数据,该字段显示为null inner join: 特点:查询的数据是满足所有条件的数据,若没有满足所有条件的数据,则结果集为空 user表数据: user_role表数据: id username id name user_id 1 张三 1 售后 1 2 李四 2 运维 2 3 王五 3 研发 3 4 小刘 4 实施 5 A. 1 张三 售后 2 李四 运维 3 王五 研发 4 小刘 null B. 1 张三 售后 2 李四 运维 3 王五 研发 C. 1 张三 售后 2 李四 运维 3 王五 研发 null null 实施
2.Preguntas de escritura SQL:
-
Describa el orden de ejecución de cada parte de la declaración de consulta – Entrevista
select distinct...from t1 (left/right) join t2 on t1.xx=t2.xx where t1.xx=? and t2.xx=? group by t1.xx having ...order by ... limit .. where: 筛选条件 分组之前 having: 筛选条件 前提:必然先分组 对分组后的结果再次筛选 where,group by,having三者同时出现,则顺序一定为: where....group by ... having .... limit用法: limit m,n 从索引m处开始,筛选n条件数据 -- 实现分页 limit m 从第一条数据开始,筛选前m条 1. from join 产生虚拟表v1 - 产生的是笛卡尔积 笛卡尔积:两表完全连接的结果叫做笛卡尔积,会产生m*n条数据 2. on 根据连接条件进行筛选,基于V1,产生虚拟表v2 3. left/right join 若是外连接,将主表中的所有数据进行补充到v2表中 4. where 根据查询条件,从v2中进行数据筛选,产生虚拟表v3 5. group by 对v3分组,产生虚拟表v4 经常会和聚合函数配合使用,聚合函数的结果在group by之后就会产生 使用场景: 统计每个班级的学生人数 select count(xx) ....group by bj_id 统计每个部门的人数 select count(xx) ... group by d.id 6. having 对分组后的结果再次筛选 ,产生虚拟表v5 7. select 选择最终要显示的字段,产生虚拟表v6 8. distinct 对结果集进行去重,产生虚拟表v7 9. order by 对结果根据某字段进行升序/降序排列 10. limit 选择需要的数据 where 和having区别: where是在分组之前进行数据筛选,having是对分组后的结果再次筛选 where,group by,having若同时出现,则三者的顺序一定是 where在 group by之前,having在group by之后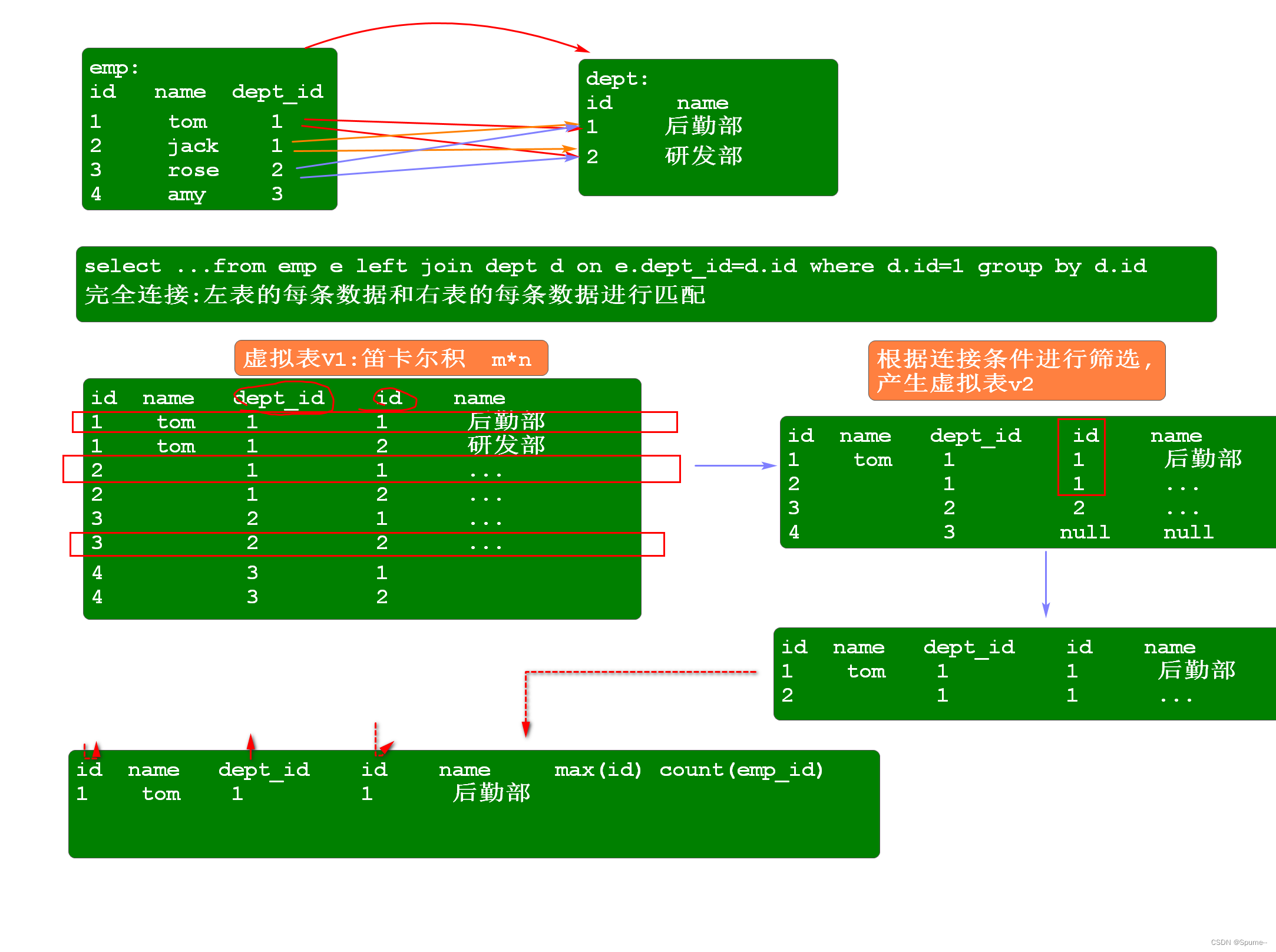
-
Nombre de la tabla: stu_score
| identificación | nombre | puntaje | bj |
|---|---|---|---|
| 1 | Zhao Yi | 89 | Clase 1 |
| 2 | Qian Er | 88 | Clase 2 |
| 3 | sol san | 84 | Clase 1 |
| 4 | Juan Pérez | 86 | Clase 2 |
| 5 | Wang Wu | 87 | Clase 1 |
| 6 | Wu Liu | 91 | Clase 2 |
Consigue la última persona de cada clase.
final.sql中最后一张表
考点:group by能查到什么
group by cola
可以查询到 分组后的cola,相关的聚合函数,与cola具有一对一关系的列,除此之外,其他字段都查询不到
正确的思路:
1. 查询出每个班级的最低分
2. 根据上述的查询结果,再次到stu_Score表中查询,查询某个班级最低分对应的学生是谁
select ss.* from stu_score ss join
(select bj,min(score) min from stu_score group by bj)tmp
on ss.score=tmp.min and ss.bj=tmp.bj
-
Usuario de la tabla, los campos incluyen: identificación (no incremental, discontinua), edad, nombre, sexo, addTime. Encuentre todos los datos con hora de creación (addTime) entre 2020-05-22 y 2020-06-17
查询某段时间区间内的数据,使用between..and... ,也可以使用> < select * from user where addTime between '2020-05-22' and '2020-06-17' 数据库中between..and两个边界值都包含 -
Según el usuario de la tabla, descubra la declaración SQL de los datos paginados consecutivos del 10 al 20 en la tabla
select * from user limit 9,11
5. Con las siguientes tablas y datos, escribe el siguiente sql
mesa de estudiantes:
| sno | despega | sabio |
|---|---|---|
| 1 | Jay Chou | 18 |
| 2 | Chow Yun Fat | 18 |
| 3 | Wu Mengda | 25 |
| 4 | Andy Lau | 25 |
| 5 | Jet Li | 29 |
| cno | nombre |
|---|---|
| 1 | Chino |
| 2 | matemáticas |
| 3 | Inglés |
| sno | cno | puntaje |
|---|---|---|
| 1 | 1 | 60 |
| 1 | 2 | 61 |
| 2 | 1 | 80 |
Las tres tablas son: estudiante, curso, puntuación.
-
Consultar el número de estudiante, el nombre, la cantidad de cursos tomados y la puntuación total de todos los estudiantes.
分析题意,得出需要使用Student表和score两表外连接查询,其中student表为主表 从student表中查询sno,sname,选课数和总成绩查询时需要根据学号分组,必须根据是student表的sno分组,不能根据score表的sno分组. select s.sno,sname,count(cno)'选课数',ifnull(sum(score),0)'总成绩' from student s left join score sc on s.sno=sc.sno group by s.sno 若结果为null,想替换为其他值,则可以使用数据库提供的函数 ifnull(exp1,exp2) count() 该函数中可以用* ,也可以用列名 count(*): 统计有多少行 count(sno) -
Consultar el número de estudiante y el nombre de los estudiantes que no han completado todos los cursos.
思路: 查询选课数<总课程数的学生 1. 查询总课程数 select count(*) from course1 2. 统计每个学生的选课数,然后筛选选课数<总课程数的 select s.sno,sname from student s left join score sc on s.sno=sc.sno group by s.sno having count(cno)<(select count(*) from course1 )
6. Se conoce la siguiente estructura de tabla.
Tabla de clases (clase)
| número de serie | nombre de la clase |
|---|---|
| identificación | nombre de la clase |
| 1 | clase uno |
| 2 | segundo turno |
| 3 | clase tres |
| 4 | Clase 4 |
| 5 | Clase 5 |
mesa de estudiantes (estudiante)
| número de serie | Identificación del Estudiante | Nombre | género | Clase |
|---|---|---|---|---|
| identificación | estu_no | nombre_estudia | este_género | identificador de clase |
| 1 | 2020001 | Zhang San | masculino | 1 |
| 2 | 2020002 | Juan Pérez | masculino | 1 |
| 3 | 2020003 | Li-Li | femenino | 2 |
| 4 | 2020004 | Zhao Ting | femenino | 3 |
| 5 | 2020005 | Wang Wu | masculino | 3 |
Puntaje
| alumno | Chino | matemáticas |
|---|---|---|
| Identificación del Estudiante | chino | matemáticas |
| 1 | 70 | 47 |
| 2 | 80 | 60 |
| 3 | 50 | 82 |
| 4 | 80 | 90 |
Restricciones del escenario empresarial:
- Hay muchos estudiantes en una clase y un estudiante solo pertenece a una clase.
- Los estudiantes pueden no tener calificaciones.
tema:
-
Consultar la información de todos los estudiantes (número de estudiante, nombre, sexo, nombre de la clase)
select stu_no,stu_name,stu_gender,class_name from student s join class c on s.class_id=c.id -
Consultar los puntajes de los cursos (número de estudiante, nombre, género, nombre de la clase, puntajes de chino, puntajes de matemáticas) de todos (incluidos los estudiantes sin calificaciones)
三表联查,其中student表和class 表内联;student表和score是外连接查询 多表联查,既有内联又有外联的语法: select...from A join B on A.xx=B.xx left join C on A.xx=C.xx 不要写成: select..from A join B left join C on A.xx=B.xx and A.xx=C.xx 若三表全都内联语法: select..from A join B join C on A.xx=B.xx and A.xx=C.xx 不要写成: select..from A join B on A.XX=B.xx join C on A.xx=c.XX -- 语法通过,结果也是正确的 select stu_no,stu_name,stu_gender,class_name,chinese,math from student s join class c on s.class_id=c.id left join score sc on s.id=sc.stu_id -
Consultar a los estudiantes cuyas puntuaciones en chino son superiores a "Zhang San" (número de estudiante, nombre, sexo, nombre de la clase, puntuación en chino)
1. 查询张三的语文分数 SELECT chinese FROM student s JOIN score sc ON s.id=sc.stu_id WHERE stu_name='张三' 2. 三表联查,查询语文>张三语文分的学生信息 -- 三表内联查询结果即可 select stu_no,stu_name,stu_gender,class_name,chinese from student s join class c join score sc on s.class_id=c.id and s.id=sc.stu_id where chinese>(SELECT chinese FROM student s JOIN score sc ON s.id=sc.stu_id WHERE stu_name='张三') -
查询各科都合格(分数>=60)的学生(学号,姓名,语文分数,数学分数)
select stu_no,stu_name,chinese,math from student s join score sc on s.id=sc.stu_id where chinese>=60 and math>=60 -
查询班级人数>=2的班级(班级编号,班级名称,人数)
1. 求出每个班级的人数,然后筛选人数>=2的班级 -- 注意:无需使用外连接 select class_id,class_name,count(stu_no) cou from student s join class c on s.class_id=c.id group by class_id having cou>=2
4. 有一张表score,三个字段名,姓名,课程,分数,数据如下,请写一条sql语句,查询出每门课程都大于等于80分的学生信息
| name | course | score |
|---|---|---|
| 张三 | 语文 | 81 |
| 张三 | 数学 | 75 |
| 李四 | 语文 | 76 |
| 王五 | 语文 | 81 |
| 王五 | 数学 | 100 |
| 王五 | 英语 | 90 |
思路:统计每个学生的最低分,筛选最低分>=80
select name from score group by name having min(score)>=80
或者
SELECT score.*
FROM score
WHERE `name`
NOT IN(
SELECT DISTINCT NAME
FROM score a
WHERE score<80)
5. 有一张表student,包括字段id和name,请写一条sql语句,将表中name字段中重复的记录删除,只保留重复数据中的id最大的那一条数据。
| id | name |
|---|---|
| 1 | 张三 |
| 2 | 张三 |
| 3 | 李四 |
| 4 | 王五 |
| 5 | 王五 |
| 6 | 王五 |
要求只留下:2 张三, 3 李四, 6 王五 这三条记录
1. 查询每个学生的最大id
2. 从表中删除数据,删除条件是id不在以上值之内
delete from student1 where id not in(select max(id) from student1 group by name)
注意点:在查询结果基础上进行update操作,在mariadb10版本是支持的,在mysql5.5 mysql8都不支持
6. 学生表如下
| 自动编号 | 学号 | 姓名 | 课程编号 | 课程名称 | 分数 |
|---|---|---|---|---|---|
| 1 | 2021001 | 张三 | 0001 | 数学 | 69 |
| 2 | 2021002 | 李四 | 0001 | 数学 | 89 |
| 3 | 2021001 | 张三 | 0001 | 数学 | 69 |
-
删除除了自动编号不同,其它都相同的学生冗余信息
考点:group by后可以加多个字段 delete from student2 where id not in(select min(id) from student2 group by stu_no,name,course_id,course_name,score)
7. 有如下一张表,按照右侧的结果格式写出生成右侧结果的SQL语句
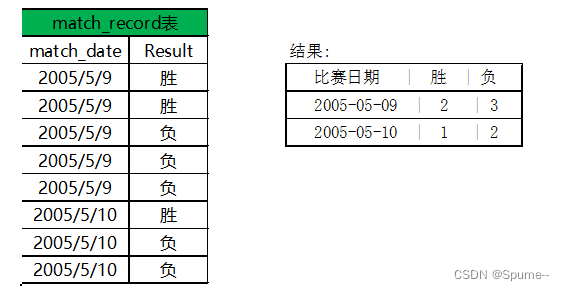
高频笔试题
考点: case when类比与java中的if..else
case when exp then ..
when exp1 then...
when exp2 then...
else....end
在成绩表 col: name course score 显示出每个学生分数处于哪个级别(>=90 优秀 >=80 良好 >=70 中等 >=60 及格 <60 不及格 )
要求:查询每个学生的成绩,并显示级别: name course score level
select name,course,score,
(case when score>=90 then '优秀'
when score>=80 then '良好'
when score>=70 then '中等'
when score>=60 then '及格'
ELSE '不及格' end)level
from score
case when经常和聚合函数配合使用 -- 经常考察
要求:统计出每个学生及格和不及格的科目数
select name,
sum(case when score>=60 then 1 else 0 end)'及格科目数',
sum(case when score<60 then 1 else 0 end)'不及格科目数' from score group by name
select name,
count(case when score>=60 then 1 end)'及格科目数',
count(case when score<60 then 1 end)'不及格科目数' from score group by name
注意点:case when 和sum()和count()使用时,用法不同(意义不同)
sum()配合使用,满足条件返回1,表示进行+1 else 0表示+0
count()配合使用,返回的值只要不是null,就进行一次计数,所以使用count()必须注意:若满足条件想进行一次计数,不满足条件不计数,应写成:
count(case when ....then 1 else null end)
或 count(case when ...then 1 end) 没有else,表示不满足条件,返回null
本题解法:
select match_date '比赛日期',
sum(case when result='胜' then 1 else 0 end)'胜',
sum(case when result='负' then 1 else 0 end)'负'
from match_record group by match_date
- 有如下3张表,完成如下需求:
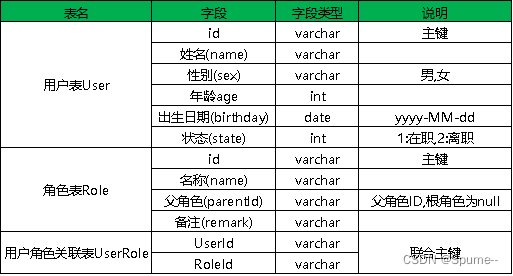
(1) 用户表中添加一条数据,请写出SQL语句
(2) 在用户表中把姓名为"李四"的在职用户的年龄修改为28
(3) 查询所有的角色名称为"技术人员",性别是女的在职人员
(4) 把角色名称为"研发人员"的用户"张三"从用户表中删除
(5) 查询年龄在18到24岁之间的男性在职人员
(6)查询年龄为18,19,20的男性和女性员工的人数,结果如下图所示:
| 年龄 | 男 | 女 |
|---|---|---|
| 18 | 5 | 3 |
| 19 | 4 | 6 |
| 20 | 1 | 0 |
(7) 查询前50名姓张的男员工
(8)查询所有根角色员工,根角色就是父角色为null的角色.
9. 以下四个表,表名称及表结构如下:
student(sno,sname,sage,ssex) 学生表
course(cno,cname,tno) 课程表
sc(sno,cno,score) 成绩表
teacher(tno,tname) 教师表
- 查询课程1的成绩比课程2的成绩高的所有学生的信息
- 查询平均成绩大于60分的同学的学号和平均成绩
- 查询学过‘李四’老师所教课程的所有同学的学号,姓名
- 查询姓“李”得老师的个数
- 查询每门课程的选修人数(课程名称,学生数量)–存在没有人选的课程
- 删除“1002”同学的“1”课程的成绩
- 查询选修人数最多的课程(课程id,课程名称,学生数量)–考虑有多门课程都是选修最多的情况
10. 数据库表名为guest,请简答
| 账号 | 消费 | 时间 | 金额 | 班次 |
|---|---|---|---|---|
| accounts | details | date | money | class |
| s0001 | 房费 | 2020-01-01 | 280 | 001 |
| s0001 | 酒水 | 2020-01-02 | 120 | 001 |
| s0001 | 房费 | 2020-01-08 | 300 | 003 |
| s0002 | 酒水 | 2020-01-29 | 50 | |
| s0003 | 房费 | 2020-01-31 | 180 | 002 |
| s0004 | 房费 | 2020-02-01 | 230 | 001 |
| s0005 | 酒水 | 2020-02-01 | 100 | |
| s0005 | 房费 | 2020-02-02 | 128 | 001 |
- 查询出房费都大于200的账号
- 查询出1月份每个账号酒水和房费的总金额
- 将不是房费的班次都更改为‘001’
- 查询出消费都大于100的账号
3. 完成以下sql查询
下面是学生成绩表(student_score)结构说明
| 字段名称 | 字段解释 | 字段类型 | 字段长度 |
|---|---|---|---|
| student_id | 学号 | 字符 | 8 |
| student_name | 姓名 | 字符 | 50 |
| student_gender | 性别 | 字符(男/女) | 4 |
| course_id | 课程号 | 字符 | 5 |
| score | 分数 | 数值 | 3 |
| ismakeup | 当前考试是否为补考 | 字符(补考:1;非补考:0) | 2 |
下面是课程表(course)说明
| 字段名称 | 字段解释 | 字段类型 | 字段长度 | 约束 |
|---|---|---|---|---|
| course_id | 课程号 | 字符 | 5 | PK |
| course_name | 课程名 | 字符 | 30 | Not null |
| course_desc | 课程介绍 | 字符 | 60 |
1、查找第一次考试后所有需要补考(小于60分)的学生姓名和这门课程的名称和成绩;
2、查询每个学生第一次考试后需要补考(小于60分)的课程平均分和科目数
3、查询所有参加了补考的学生的学生姓名,课程名称,补考成绩和非补考成绩;
6. 有如下表:
emp:
empno int(员工编号) ,ename varchar(50)(员工姓名) ,job varchar(100) (工作岗位),mgr int (上级领导编号),hiredate date(雇佣日期),sal int(薪金),comm int(佣金) deptno int (部门编号)
提示:工资=薪金+佣金
dept表:
deptno int (部门编号) , dname 部门名称 loc 地点
- Enumere la cantidad de empleados que trabajan en cada departamento y el salario promedio.
- Enumere los nombres de todos los empleados, nombres de departamentos y salarios.
- Enumere todos los detalles del departamento y la plantilla del departamento.
- Enumere los salarios mínimos para varios trabajos.
- Enumere el salario mínimo de los gerentes en cada departamento (si es gerente, el valor del trabajo es gerente)
- Enumere todos los empleados que fueron contratados antes que su supervisor inmediato.
- Enumere los nombres de los departamentos y la información de los empleados de esos departamentos, así como de aquellos departamentos que no tienen empleados.
- Enumere todos los nombres de puestos de 'secretario' y nombres de departamentos
- Listar varios trabajos con salario mínimo superior a 6.500
- Enumere los nombres de los empleados que trabajan en el departamento de I+D, suponiendo que no se conoce el número del departamento de I+D.