
Fuente | Espacio latente
compilación OneFlow
Traducción|Jia Chuan, Yang Ting, Wan Zilin
La longitud del contexto solía ser una de las mayores limitaciones de GPT-3. GPT-3 solo puede aceptar hasta 4000 tokens (3000 palabras, 6 páginas); de lo contrario, se informará un error. Por lo tanto, para manejar documentos extensos y avisos, es necesario introducir otras tecnologías de recuperación como LangChain. Sin embargo, MosaicML (que ha sido adquirido por Databricks por alrededor de 1300 millones de dólares) abrió el contexto MPT-7B a principios de mayo con una longitud de 84 000 tokens (63 000 palabras, 126 páginas), ampliando enormemente el rango de texto que se puede procesar. , El modelo Claude desarrollado por Anthronpic tiene una longitud de contexto extendida a 100.000 tokens.
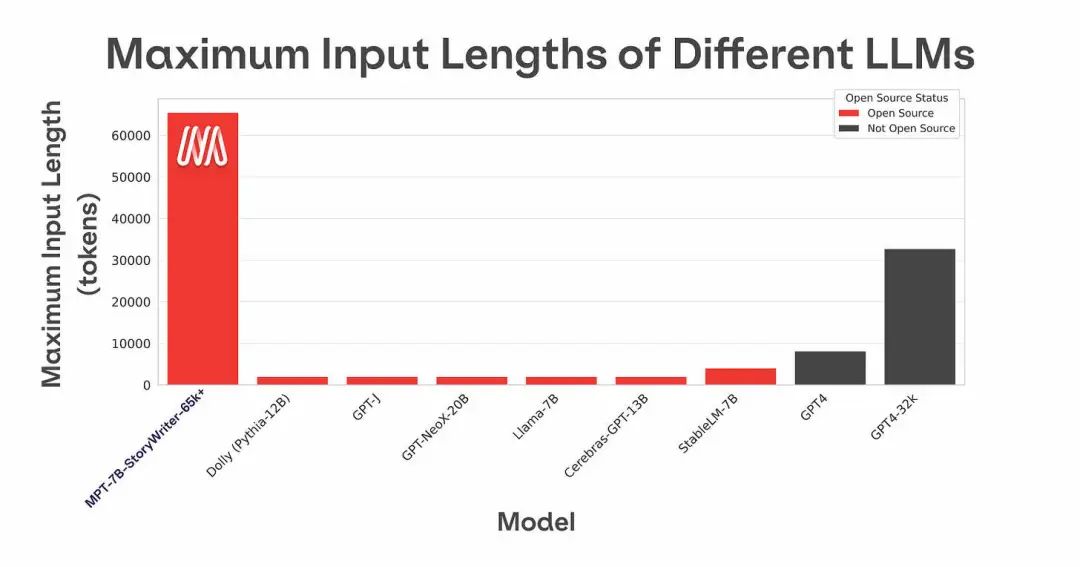
MPT-7B se entrenó desde cero utilizando 1 billón de tokens de texto y código como datos de entrenamiento. En comparación con otros modelos similares (como Pythia y OpenLLaMA usan 300 mil millones de tokens, StableLM usa 800 mil millones de tokens), los datos de entrenamiento de MPT-7B son más grandes y su calidad es comparable a la de LLaMA-7B. El modelo fue entrenado en la plataforma MosaicML, usando 440 GPU, y el proceso de entrenamiento tomó 9.5 días sin intervención humana a un costo de alrededor de $200,000. A diferencia de otros modelos abiertos, MPT-7B tiene licencia para uso comercial y está optimizado para entrenamiento e inferencia rápidos con FlashAttention y FasterTransformer.
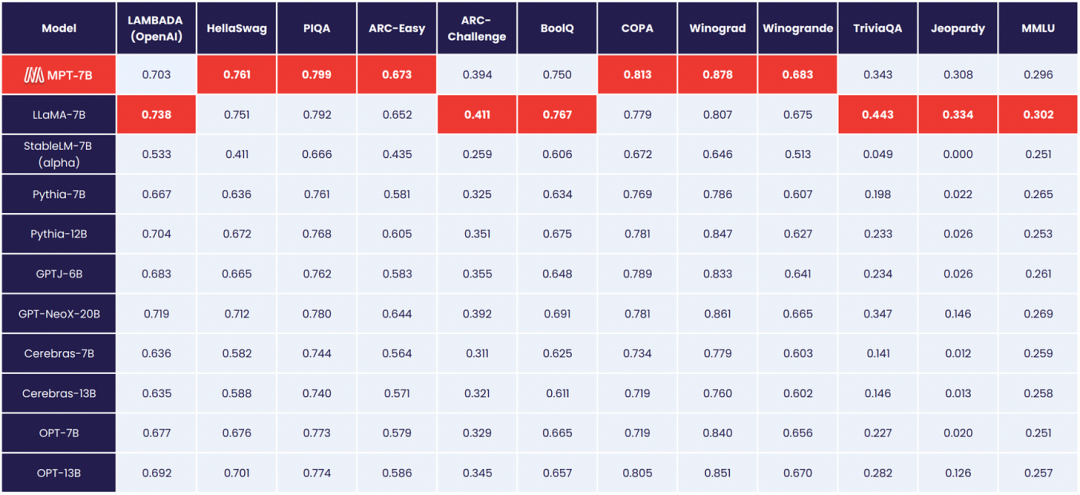
(Rendimiento MPT-7B en tareas académicas de muestra cero)
MosaicML también lanzó tres modelos MPT-7B-Instruct, MPT-7B-Chat, MPT-7B-StoryWriter-65k+ basados en el MPT-7B básico para el ajuste fino.
El modelo está ajustado en dolly_hhrlhf. El conjunto de datos dolly_hhrlhf se crea sobre el conjunto de datos "dolly-5k".
El modelo está ajustado en los conjuntos de datos ShareGPT-Vicuna, HC3, Alpaca, Útil e inofensivo y Evol-Instruct.
El conjunto de datos de ajuste fino para este modelo es un subconjunto filtrado de novelas en libros3 con una longitud de contexto de 65k. Si bien el tamaño anunciado era de 65 000 tokens, el equipo pudo obtener una respuesta de 84 000 tokens cuando se ejecutaba en una GPU A100-80 GB de un solo nodo. La tecnología clave detrás de esto es ALiBi. El Gran Gatsby originalmente solo tenía alrededor de 68k fichas, por lo que el equipo usó el modelo MPT-7B-StoryWriter-65k+ para crear un nuevo final para la novela.

Además de los puntos de control del modelo, el equipo ha abierto el código base completo para el entrenamiento previo, el ajuste y la evaluación de MPT a través de su nuevo MosaicML LLM Foundry. La tabla anterior se creó utilizando el marco de evaluación de aprendizaje contextual en LLM Foundry.
El científico jefe de MosaicML, Jonathan Frankle, y el científico investigador Abhinav Venigalla son los jefes de MPT-7B y lideran todo el proceso de capacitación de MPT-7B. En el último podcast de Latent Space, el socio principal de Swyx y Decibel Partners, Alessio, discutió con ellos la innovación del proceso de entrenamiento MPT-7B y explicó por qué la combinación de conjuntos de datos LLM es un arte importante y misterioso. Además, algunos puntos de referencia tradicionales de opción múltiple pueden no ser muy útiles para la tecnología que se está construyendo, y también explorarán las razones detrás de esto.
(OneFlow compila y publica el siguiente contenido después de la autorización. Para reimprimir, comuníquese con OneFlow para obtener autorización. Fuente: https://www.latent.space/p/mosaic-mpt-7b#details)
1
Construcción del modelo MPT-7B
Swyx: ¿Por qué desarrolló el MPT-7B?
Abhinav: El proyecto MPT-7B tomó entre 6 y 12 meses. Comenzamos a trabajar en modelos de lenguaje el verano pasado y publicamos una publicación de blog que analizaba modelos de lenguaje y descubrió que el costo de la capacitación en realidad puede ser mucho más bajo de lo que la gente piensa. Además, desde entonces, inspirados en el modelo LLaMA lanzado por Meta AI y muchos otros trabajos de código abierto, nos propusimos crear un modelo realmente bueno con 7 mil millones de parámetros, que es el origen de MPT.
Alessio: Dijiste en uno de los podcasts: Mosaic no tiene planes de construir y lanzar modelos. Pero al final lanzaste el modelo de todos modos, ¿qué te hizo cambiar de opinión?
Jonathan: Creo que hay varios factores: Todavía nos falta un modelo de primera. A diferencia de OpenAI, donde nuestro negocio gira en torno a los clientes que crean sus propios modelos, principalmente les proporcionamos las herramientas y, para que esas herramientas sean efectivas, primero debemos crear nuestros propios modelos.
Tiene que quedar claro que si nuestros clientes pueden hacer grandes cosas, nosotros también podemos hacer grandes cosas. Muchas personas en Twitter cuestionaron la veracidad de los números que mostró Mosaic, como Ross Whiteman que dijo: "Veamos los resultados reales", a lo que yo diría: "Ross, ¿qué piensas de estos? ¿Cómo funcionó? ?" Desarrollamos el modelo en 9,5 días a un costo de $200,000, así que tú también puedes hacerlo.
Swyx: En referencia a los datos que publicó el año pasado, inicialmente se estimó que el costo de capacitación de GPT-3 era inferior a $450 000, que luego se redujo a $100 000; el costo de Stable Diffusion también se redujo de $160 000 a menos de $50 000.
Jonathan: Sigo siendo muy cauteloso con la cifra de $100,000. Todavía no está allí, pero vamos en esa dirección, y ese es un gran desafío para Abhi.
Swyx: Hay tres variantes del modelo MPT-7B, una de las cuales logra SOTA en términos de longitud de contexto, ¿cuál es el proceso de entrenamiento para estos modelos?
Abhinav: Nuestro modelo básico es una recreación de LLaMA-7B, con 7 mil millones de parámetros y datos de entrenamiento de 1 billón de tokens, lo que proporciona un punto de partida de entrenamiento eficiente para el modelo de ajuste fino sin una intervención excesiva. El ajuste fino del modelo también es muy interesante, como MPT-7B-StoryWriter-65k+ se puede usar para escribir historias, la longitud de la ventana de contexto es de 65,000 y también puede continuar escribiendo en función del contenido conocido.
Por supuesto, esta es solo una de las direcciones en las que pensamos. Puede usar el modelo base MPT-7B para crear modelos personalizados que se adapten a diferentes necesidades, como modelos de código de contexto largo o modelos de lenguaje específico. Entonces, en base al modelo básico, se construyeron tres variantes, MPT-7B-Instruct, MPT-7B-Chat y MPT-7B-StoryWriter-65k+, que se utilizan para seguir instrucciones breves, chatear y escribir historias, respectivamente.
Alessio: ¿Cómo decide cuántos tokens y parámetros usar al entrenar el modelo? Los parámetros del modelo 7 mil millones y 3 mil millones parecen ser dos números mágicos que están de moda en este momento.
Abhinav: Para los modelos de entrenamiento, la ley de escala puede decirle cómo hacer el uso más eficiente de los recursos informáticos de entrenamiento. Por ejemplo, si el presupuesto es de 200 000 dólares estadounidenses, de acuerdo con la ley de la escala, se puede impartir el programa de capacitación más eficaz.
Entre ellas, la que más solemos seguir es la ley de Chinchilla. Para el modelo MPT-7B y sus variantes relacionadas, estas leyes no se siguen estrictamente, porque queremos asegurarnos de que el modelo sea adecuado para uso personal y tenga un buen rendimiento de inferencia, por lo que está sobreentrenado, superando el Punto Chinchilla (referido a datos nivel medido en fichas). Algunas personas en Internet llaman en broma a estos modelos Llongboi porque su tiempo de entrenamiento es bastante largo.Tomando el modelo 7B como ejemplo, el Chinchilla Point puede ser de 140 mil millones de tokens, pero en realidad entrenamos 1 billón de tokens, por lo que el tiempo de entrenamiento es de casi 7 veces más largas de lo normal.
Swyx: ¿Llongboi se refiere a un método de entrenamiento?
Jonathan: Llongboi es solo una broma interna, se refiere a un método de entrenamiento que usa más fichas de las que dicta la ley de Chinchilla. Se puede ver que Llongboi tiene dos "L" al principio, que se utiliza para rendir homenaje a LLaMA. Nuestro CEO una vez hizo público el nombre en Twitter, refiriéndose al modelo como "Llongboi". A veces tengo muchas ganas de tomar su contraseña de Twitter para que no se filtre antes de tiempo, pero ahora todo el mundo conoce el nombre.
2
Sobre arquitectura, ALiBi, contexto
Alessio: Flash Attention y Faster Transformer son los dos elementos centrales de la construcción de su modelo. ¿Cuáles son sus ventajas?
Abhinav: Flash Attention es una implementación más rápida de Full Attention, desarrollada por el laboratorio Hazy Research de Stanford. Integramos Flash Attention en nuestra biblioteca en septiembre pasado y ha jugado un papel importante en la velocidad de entrenamiento e inferencia. En comparación con otros modelos de Hugging Face, este modelo es muy especial. Puede cambiar entre Torch Attention general y Flash Attention especialmente diseñado para GPU, lo que hace que la velocidad de entrenamiento del modelo aumente aproximadamente 2 veces y la velocidad de inferencia aumente en un 50%. -100%.
Swyx: ¿Qué lo motivó a elegir la codificación posicional ALiBi?
Abhinav: Combinamos la codificación posicional ALiBi, Flash Attention y la estabilidad del entrenamiento de una manera interesante. ALiBi puede eliminar la necesidad de incrustaciones posicionales en el modelo. Anteriormente, si un token tenía la posición 1, entonces necesitaba agregar una incrustación de posición específica y no podía exceder la posición máxima (generalmente 2000). Pero con ALiBi, este problema se soluciona. Solo necesitamos agregar un sesgo (sesgo) al mapa de atención, que es como una pendiente, y si se requiere un rango más largo de posiciones para la inferencia, extenderá esta pendiente a un mayor número de posiciones. Este enfoque funciona porque la pendiente es continua y se puede interpretar.
Curiosamente, a través de Flash Attention, el modelo ahorra mucha memoria y mejora el rendimiento, por lo que comenzamos a realizar pruebas de rendimiento en modelos con contextos muy largos (hasta 65k) el año pasado y, al mismo tiempo, es muy difícil de realizar. entrenamiento estable. Más tarde, intentamos integrar ALiBi en el modelo y la estabilidad del modelo mejoró significativamente. Ahora podemos entrenar modelos de escritura de historias de manera estable en contextos muy largos y garantizar un uso eficiente de ellos.
Jonathan: La longitud del contexto es técnicamente ilimitada. Siempre que se proporcione suficiente memoria, el diálogo puede continuar indefinidamente. Creemos que el número más largo que puede manejar el modelo es 84K, que es la longitud de contexto más larga que los humanos pueden manejar cómodamente en la práctica. Pero también hemos probado longitudes de contexto superiores a 84K en la práctica, y podemos manejar longitudes más largas.
Swyx: Por ejemplo, podemos ingresar la novela "El gran Gatsby" en el modelo y luego dejar que el modelo continúe escribiendo la novela en función del texto ingresado y, finalmente, el modelo genera un contenido bastante interesante.
Jonathan: Hay muchas versiones realmente buenas del final de la historia dentro de Mosaic. Una versión describe el funeral de Gatsby, Nick comienza a hablar con el fantasma de Gatsby, el padre de Gatsby también aparece y luego él y Tom se presentan en la estación de policía. Esta versión pone mucho énfasis en la trama, describiendo lo que sucede a continuación. Además, muchas versiones tienen finales muy al estilo de Fitzgerald y están bellamente escritas. Entonces, es emocionante ver que el modelo parece estar procesando la entrada y produciendo una salida significativa. Podemos hacer mucho con esta longitud de contexto.
Alessio: La memoria comienza a convertirse en una de las restricciones del modelo, entonces, ¿cómo se debe elegir el tamaño del parámetro y la longitud del contexto?
Jonathan: Recientemente, la investigación sobre contextos largos ha atraído mucha atención y han surgido una serie de artículos relacionados. Sin embargo, estos documentos no son del todo precisos y, en cierta medida, especialmente con respecto a los mecanismos de atención, comparan los mecanismos de atención no cuadrática (como la atención jerárquica aproximada) con la atención cuadrática explícita y correcta. . Soy optimista sobre los métodos de aproximación, así que no puedo esperar para profundizar en estos documentos.
Escribir y leer documentos me enseñó una lección importante acerca de no confiar en ningún dato hasta que lo hayas hecho tú mismo. En Mosaic, muchas veces nos decepcionaron las implementaciones porque los artículos que parecían prometedores al principio solo se dieron cuenta después de la implementación de que habían manipulado los datos. Como tal, siempre soy escéptico con respecto a los datos y no confío en ningún resultado hasta que se vuelvan a implementar y validar. En general, la práctica valió la pena y, muchas veces, las teorías no funcionaron tan bien en la práctica como se esperaba.
3
Características de MPT-7B
Swyx: ¿Cuáles son las características específicas del MPT-7B?
Abhinav: Lo dividiría en dos partes, la primera es la estabilidad del entrenamiento. Esta pregunta se puede dividir en tres partes. Primero, el modelo necesita evitar picos de pérdida durante el entrenamiento , que es nuestra primera línea de defensa. En mi opinión, los picos de pérdida no son un gran problema con un tamaño de entrenamiento de 7 mil millones de parámetros. Sin embargo, evitar picos de pérdida se vuelve difícil a medida que aumenta el tiempo de entrenamiento. Dedicamos mucho tiempo a descubrir cómo ajustar los métodos de inicialización, los optimizadores, las arquitecturas, etc. para evitar picos de pérdidas. Incluso durante nuestro entrenamiento, si observamos con atención, aún podemos encontrar algunos picos pequeños intermitentes, pero estos picos volverán a la normalidad en unos pocos cientos de pasos, lo cual es un fenómeno muy mágico, que puede ayudarnos naturalmente a recuperar la pérdida de picos.
El determinismo y las estrategias de recuperación inteligente son nuestra segunda línea de defensa . En caso de error catastrófico, podremos retomar rápidamente el entrenamiento, aplicando alguna intervención en los pocos lotes previos al fallo. Para posibles problemas, hemos realizado varios preparativos. Sin embargo, en el entrenamiento de MPT-7B, no usamos estas medidas de respaldo en absoluto, lo que debe decirse que es un tipo de suerte.
La infraestructura de formación adecuada es la tercera línea de defensa . Si intentamos entrenar el modelo en cientos de GPU, a menudo hay fallas de hardware. Por ejemplo, al entrenar un modelo en un clúster grande con 512 GPU, el entrenamiento fallará casi cada dos días. El motivo de la falla puede ser una falla en la red.
Por lo general, las personas configuran equipos de guardia las 24 horas del día, los 7 días de la semana para hacer frente a estas fallas. Cuando hay una falla, el equipo intenta verificar el clúster, eliminar los nodos rotos, reiniciar, etc., lo cual es una tarea muy tediosa. Solíamos pasar meses revisando manualmente los errores, pero ahora construimos una plataforma para automatizar cada nodo en el proceso de entrenamiento del modelo.
Cuando hay un problema con la ejecución de un modelo, nuestro sistema de monitoreo automatizado detiene el trabajo, prueba y verifica si hay nodos dañados y se reinicia. Debido a las capacidades de recuperación rápidas y deterministas de nuestro software, el modelo sigue funcionando correctamente. Como resultado, a veces podemos ver en los registros del modelo que después de que un modelo falla a las 2 am, vuelve a funcionar en minutos sin la intervención manual de un miembro del equipo.
Jonathan: Realmente no es fácil hacer esto, si hubiera una falla de hardware en el modelo hace unos meses, los miembros del equipo tendrían que levantarse a las dos de la mañana para verificar la causa de la falla del nodo y reiniciar el trabajo. Anteriormente, incluso a una escala de entrenamiento de 7 mil millones de parámetros, a menudo nos encontrábamos con picos de pérdidas catastróficos, y estos problemas afectaban seriamente el entrenamiento del modelo.
Ahora hemos abordado estos problemas a través de mejoras incrementales. Como dijo Abhinav, ahora podemos sentarnos en una oficina mientras entrenamos múltiples modelos sin preocuparnos de que el modelo falle e interrumpa el entrenamiento.
4
Selección y replicación de datos y desafíos de evaluación de LLM
Swyx: La selección de datos es su enfoque, ¿puede ampliarlo?
Jonathan: Abhi casi me mata cuando traté de usar todas las GPU para el procesamiento de datos en lugar de entrenar el modelo. Sabemos que entrenar un modelo requiere muchos datos, pero también hay muchas incertidumbres.
Una es qué tipos de fuentes de datos diferentes son importantes y la otra es la importancia de la duplicación. Entre ellos, la pregunta sobre la duplicación se puede dividir en compensaciones de calidad y cantidad. Supongamos que tengo los mejores 10 mil millones de datos léxicos del mundo, ¿es mejor volver a entrenarlos cien veces, o es mejor usar 1 billón de datos léxicos actualizados y de baja calidad? Por supuesto, puede haber un punto de compromiso, pero cómo determinar los datos de alta calidad también es un problema, y todavía no hay una respuesta clara. Si tuviera que volver a la academia ahora, definitivamente escribiría un artículo sobre eso, porque todavía no sé nada al respecto.
Swyx: No he visto ningún trabajo de investigación sobre esto hasta ahora.
Jonathan: La pregunta central de la investigación de tesis es "qué combinación de conjuntos de datos se debe usar".
En el proceso de creación del modelo, volví a la Facultad de Derecho de Georgetown, donde daba clases, y me senté con un grupo de estudiantes de derecho para discutirlo. Les doy un conjunto de datos de alta calidad, cómo mezclar los datos y la cantidad de tokens que tienen, y les permito crear el mejor conjunto de datos para su modelo.
No saben nada sobre los LLM aparte de que los datos de entrada afectan el comportamiento. Les digo que creen un híbrido que cubra todas las diferentes compensaciones. Al principio, se puede requerir una gran cantidad de corpus en inglés, que se puede obtener a través de Internet; si desea que sea un modelo multilingüe, entonces se reducirá mucho el corpus en inglés; además, ya sea para incluir el código en él.
Algunas personas piensan que el código puede hacer que el modelo funcione mejor en el razonamiento lógico, pero nunca he visto ninguna evidencia que respalde esta idea. Aunque de hecho hemos desarrollado un modelo de código excelente, si el modelo de código puede conducir a una mejor capacidad de razonamiento en cadena de pensamiento requiere más investigación.
Se dice que se entrena una versión de GPT-3 de la novela "El código Da Vinci", por lo que algunas personas piensan que esto puede ser útil, pero no hay evidencia;) ayudará al entrenamiento del modelo, pero también hay una falta de evidencia.
Por lo tanto, experimentamos con muchas combinaciones de datos diferentes y descubrimos que algunas combinaciones de datos funcionaban mejor o peor que otras. Por ejemplo, "The Pile" es una combinación de datos muy estable, pero según las métricas de evaluación, existen otras combinaciones de datos mejores. A continuación también tocaré el tema de la evaluación, que es muy importante.
El modelo T5 se entrenó originalmente en el conjunto de datos C4, que funcionó excepcionalmente bien. Otros, incluida Stella Beaterman de EleutherAI, mencionaron esto cuando tuiteé al respecto. En el documento original sobre el modelo T5, el método de preprocesamiento para el conjunto de datos C4 parece extraño y los autores eliminaron todo lo que contenía la palabra "JavaScript" del conjunto de datos porque no querían advertencias relacionadas con JavaScript. Además, eliminaron el contenido que contenía llaves porque no querían obtener contenido con javascript.
Miraron una lista de malas palabras y eliminaron el contenido que contenía malas palabras. Sin embargo, la lista de malas palabras en realidad incluye algunas palabras que en realidad no son malas, como "gay". Pero debido a este proceso de limpieza, el conjunto de datos resultante parece no tener rival. Desde este punto, no sabemos nada acerca de los datos.
De hecho, también usamos un conjunto de datos llamado MC4, MC4 y C4 tenían el mismo preprocesamiento, pero agregamos más llamadas web (llamadas web), pero en comparación con C4, la parte en inglés de MC4 es peor, por razones desconocidas.
Para ello, establezco dos criterios:
En primer lugar, la parte en inglés debería ser al menos tan buena como MC4. En comparación con otros conjuntos de datos disponibles, la parte en inglés de MC4 es mejor. En segundo lugar, haga todo lo posible por la diversidad de datos y asegúrese de que el conjunto de datos incluya cosas como código, artículos científicos y Wikipedia, porque las personas usarán el modelo para una variedad de tareas diferentes.
Pero creo que, lo más importante, el modelo es tan bueno como la métrica de evaluación. Abhi puede estar en desacuerdo sobre este punto. No sabemos cómo evaluar con precisión los modelos generativos cuando se les pide que realicen tareas específicas. En algunos casos, tenemos que admitir que nuestras propias evaluaciones ni siquiera miden lo que realmente nos importa, por lo que solo podemos tomar decisiones razonables.
Swyx: ¿Cree que los métodos de evaluación como MMLU (Massive Multitask Language Understanding) y BIG-bench no son lo suficientemente convincentes?
Jonathan : Estos métodos definitivamente hacen dos tipos de tareas. Una es una tarea de opción múltiple, que contiene una respuesta correcta, que permite que el modelo genere opciones como A, B, C o D, y luego elige la respuesta que es más probable que genere el modelo calculando la perplejidad de cada respuesta posible. Pero en lugar de pedirle al modelo que haga preguntas de opción múltiple, hacemos un segundo tipo de tarea generativa abierta, como el resumen. Comparar usando métricas como BLEU y ROUGE no es lo suficientemente preciso, hay muchos resúmenes en papel excelentes y métodos abiertos de generación. Por el contrario, el manual es un estándar de evaluación más confiable, pero la evaluación manual requiere mucho tiempo y es laboriosa, y no se puede comparar con el modelo en tiempo real, lo que puede ser posible en el futuro.
Abhinav: Tenemos un gran equipo de evaluación que nos está ayudando a construir nuevas métricas.
Jonathan: Pero es difícil evaluar los LLM, y no creo que ninguna de estas métricas capte realmente lo que podemos esperar de un modelo en la práctica.
5
Reducción de costes y aumento de la eficiencia de la formación de modelos.
Swyx: Ahora la gente necesita pasar de tres a diez días para entrenar al modelo, ¿cuánto tiempo quieres acortar el tiempo?
Abhinav: Este año es probablemente uno de los años más emocionantes en términos de mejoras en la eficiencia del entrenamiento de modelos sin procesar. Este año, tanto el hardware como el software se han actualizado en consecuencia. El primero es el hardware H100 de nueva generación de Nvidia, que por sí solo puede mejorar el rendimiento al menos dos veces. En segundo lugar, hay un nuevo formato de número de punto flotante FP8, que puede lograr la misma mejora de rendimiento cuando se usa solo.
Hace unos años, comenzamos a usar la precisión de 32 bits y luego Nvidia introdujo la precisión de 16 bits. Después de varios años de desarrollo, hemos dominado gradualmente las habilidades de entrenamiento de 16 bits debido a la mejora continua de los requisitos.
Con el FP8 de este año, podemos duplicar el rendimiento, lo que significa que podemos triplicar el costo. Al mismo tiempo, comenzamos a perfilar la capacitación LLM utilizando FP8 en el H100 y el progreso ha sido rápido. Entonces, solo mejorando el hardware, podemos reducir mucho el costo.
Además, hay muchos estudios sobre aplicaciones de arquitectura. Estamos explorando formas de introducir cierta escasez, pero no una escasez completamente aleatoria. ¿Existe un mecanismo de compuerta o una forma arquitectónica de estilo MoE para lograr esto?
Nuestro objetivo original era reducir el costo de capacitación del modelo GPT-J de $500 000 a $100 000, y si podemos lograrlo para fin de año, sería un gran logro.
Jonathan : Esta idea no es un castillo en el aire. Si bien aún no se ha alcanzado esa etapa, es probable que este objetivo se alcance para 2023.
Las estadísticas sobre costos de entrenamiento e inferencia son escasas. David Patterson de Google publicó una publicación de blog sobre el uso de energía de Google para el aprendizaje automático. Después de un análisis detallado, en los últimos tres años, Google gastó tres quintas partes de sus recursos en inferencia y dos quintas partes en capacitación. Lo anterior son datos de Google, proporcionan modelos para miles de millones de usuarios.
Google es probablemente el lugar con la mayor carga de inferencias del mundo. Y eso es solo la asignación de recursos para la capacitación, con la inferencia representando las tres quintas partes y la capacitación representando las dos quintas partes. El hardware puede ser más costoso y la estructura de red del hardware puede ser más compleja, por lo que la capacitación y el razonamiento pueden dividirse por la mitad. El anterior es el ratio de asignación de Google, pero para otras empresas, la formación puede suponer un mayor peso.
6
La importancia de la apertura para la investigación en IA
Alessio: El costo de capacitación anterior era muy alto, lo que nos impedía realizar suficientes experimentos, por lo que hubo muchos problemas para seleccionar conjuntos de datos, etc.
Jonathan: En la escuela de posgrado, solía estar celoso de mis amigos porque tenían GPU y yo no tenía una en mi computadora portátil, por lo que no podía entrenar a ningún modelo. Fantaseaba con ganar la lotería para poder tener una GPU K80.
En el fondo, sigo siendo ese ávido estudiante de ciencias. Creo firmemente que si queremos hacer investigación científica y realmente entender estos sistemas, cómo hacer que funcionen bien, comprender los elementos de su comportamiento, seguridad y confiabilidad, tenemos que reducir el costo de la capacitación para que realmente podamos hacer investigación científica. investigación. Tome los experimentos biológicos, por ejemplo, donde necesitamos hacer múltiples cultivos celulares y experimentos para asegurarnos de que un medicamento funcione, se necesita mucha investigación científica antes de que realmente entendamos algo.
Abhinav: MosaicML tiene muchos clientes que intentan entrenar modelos, por lo que la empresa tiene un incentivo para dedicar muchos recursos y tiempo a la investigación científica. Solo entendiendo verdaderamente cómo se deben entrenar los modelos podemos ayudar a más personas. Entonces, para nosotros, este proceso de agregación es muy importante.
Recuerdo que antes había un artículo de Google que investigaba el tamaño del lote o algo así. Este documento probablemente costó millones de dólares y tiene enormes beneficios para la comunidad en su conjunto. Ahora, todos podemos aprender de él y ahorrar dinero sin arruinarnos. Por lo tanto, para Mosaic, a través de la investigación experimental, hemos obtenido conocimientos profundos sobre los datos, la arquitectura previa al entrenamiento, etc., razón por la cual los clientes nos eligen.
Jonathan: La apertura es muy importante para la comunidad de IA. En cierto sentido, no tenemos ninguna razón para estar cerrados. Obtenemos ingresos ayudando a los clientes a entrenar modelos. No hay pérdida para nosotros al compartir los resultados con la comunidad. Después de todo, tenemos que obtener ingresos a través de modelos personalizados y una excelente infraestructura. Y la combinación de estos aspectos es la razón por la que llamamos a nuestra empresa MosaicML.
Siempre hemos mantenido una actitud abierta y no ocultaremos los resultados que hemos logrado. Pero ahora, me doy cuenta de que nos hemos convertido en uno de los laboratorios de código abierto más grandes de la industria, lo cual es un hecho triste, porque MosaicML no es tan grande en términos de la industria en general, solo tenemos alrededor de 15 investigadores, muchos otros. Los laboratorios se han cerrado y ya no publican mucho contenido públicamente. Sin embargo, MosaicML continuará comunicándose y compartiendo con la comunidad, y hará todo lo posible para convertirse en un pionero de la investigación abierta. Si bien nuestra escala y volumen de investigación no pueden igualar los de un gran laboratorio, continuaremos compartiendo lo que aprendemos en un esfuerzo por crear recursos para la comunidad.
Cuando hablo del ecosistema de IA con los responsables políticos, siempre surge una preocupación común: que la falta de apertura obstaculizará el ritmo de la innovación. Llevo años insistiendo en este tema, pero finalmente es una realidad. Abogo por el código abierto, pero no creo que todos compartan su trabajo. Una vez dimos por sentado el código abierto, pero ya no es así.
Creo que va a ralentizar nuestro desarrollo. En muchos casos, existe una cultura monolítica en cada laboratorio, y la comunicación es un motor importante para el progreso científico. Por lo tanto, el código abierto no solo es indispensable en la comunidad académica y de código abierto, sino que también es fundamental para el avance de la tecnología. Necesitamos una comunidad de investigación de código abierto vibrante.
7
Futuras tendencias
Swyx: Mencionaste que muchas cosas no durarán mucho y se reemplazan fácilmente, pero Transformer existirá por mucho tiempo.
Jonathan: Transformer siempre existirá. Las redes neuronales convolucionales (CNN) todavía se utilizan hoy en día y los transformadores visuales no han ocupado su lugar. Mire la red neuronal recurrente (RNN), que ha existido durante décadas, pero todavía está activa en muchos campos. Como resultado, es difícil implementar mejoras importantes en la infraestructura.
Abhinav: Creo que tu apuesta depende mucho de lo que se defina como atención. Si una operación como la multiplicación de matrices QK se reemplaza por un método similar, ¿qué efecto tendrá esto en el resultado?
Jonathan: En el análisis final, esto es solo una red feedforward completamente conectada, Transformer con un mecanismo de atención simple. Entonces, las cosas pueden cambiar, pero continuamos usando Transformer como lo imaginó Ashish Vaswani (autor de Transformer) hace seis años, y tal vez sigamos haciéndolo en el futuro.
Abhinav: Creo que se volverá similar a MLP (Multilayer Perceptron), que es la única opción que tenemos en este momento, porque ahora la arquitectura se ha simplificado mucho, dejando solo algunas capas lineales, conexiones residuales, atención, operación de multiplicación de puntos. .
Jonathan: Su suposición es que la arquitectura se volverá más simple, pero la realidad puede ser la contraria, la arquitectura puede volverse más compleja.
Swyx: ¿Cuál es su opinión sobre el reciente debate sobre los "fenómenos emergentes"?
Abhinav: He visto documentos similares, y estos son probablemente solo subproductos de técnicas de evaluación como el escalado de registros, métricas de evaluación y lo que estamos haciendo con precisión de malla, que es estrictamente decisiones binarias, que clasifican los resultados como verdaderos o falsos. , no tenga en cuenta las diferencias secuenciales más finas.
Pero, al igual que el punto de Jonathan sobre la evaluación, también tenemos un problema con la diversidad de métricas de evaluación: cuando lanzamos estos modelos, incluso el modelo de chat, el modelo de comando, la gente a menudo lo usa para una variedad de tareas diferentes. Difícilmente podemos medir y evaluar cada dimensión con precisión de antemano, e incluso a una escala de 7 mil millones, estos modelos todavía funcionan mal en algunas tareas MMLU muy difíciles. A veces obtienen una puntuación apenas superior al azar, especialmente cuando se trata de tareas muy difíciles.
Por lo tanto, algunos de estos problemas pueden ser más útiles para nosotros si buscamos modelos de mayor calidad. Sin embargo, desarrollamos el MPT-7B un poco a ciegas porque no entendimos completamente cómo se comportaría el modelo en última instancia. Solo se puede desarrollar con un pequeño conjunto de tareas comunes de inferencia de percepción, y el rendimiento se evalúa comparando estas métricas con otros modelos de código abierto.
Alessio: Creo que la inferencia y el entrenamiento rápidos son uno de los objetivos, por lo que existe un compromiso entre resolver las tareas más difíciles y ser rápido en otras tareas.
Abhinav: Sí. Incluso a una escala de datos de 7 mil millones, las personas intentarán ejecutarlo en la CPU de su hogar o intentarán portarlo a su teléfono móvil, principalmente porque las aplicaciones a pequeña escala impulsarán a las personas a adoptar esta tecnología, y esta es una tendencia importante en el momento.
Alessio: ¿Hay cosas en la IA que se están moviendo mucho más rápido de lo esperado?
Jonathan: Recuerdo cuando se lanzó GPT-2, no estaba muy emocionado, pero en ese momento ya tenía 1.500 millones de parámetros. A medida que los modelos aumentan de tamaño, su rendimiento no puede seguir mejorando. Luego salió GPT-3, y pensé que era un poco mejor para generar texto, pero me equivoqué una y otra vez. Ampliar el modelo puede generar modelos muy útiles al predecir el próximo token.
Para ser justos, estamos bastante equivocados al respecto, por lo que tampoco podemos culparnos a nosotros mismos. De lo contrario, Google, Facebook y Microsoft Research habrían lanzado megamodelos de lenguaje asesino mucho antes de que tuviera la oportunidad de actuar. Hice una apuesta muy extraña que resultó ser correcta: los modelos de difusión, aunque algo tontos, producían imágenes asombrosamente hermosas.
Abhinav: Con respecto a los chatbots a escala, creo que pasará mucho tiempo antes de que cientos de millones de personas tengan conversaciones masivas con modelos de IA. Con tantas nuevas empresas y empresas que ahora usan no solo ChatGPT, sino también otros proyectos como la creación de personajes, es sorprendente cuántas personas están creando conexiones emocionales con estos modelos de IA. No creo que hubiera predicho eso en septiembre u octubre del año pasado. El punto de inflexión que se ha producido en los últimos seis meses ha sido realmente inesperado.
Swyx: ¿Para qué crees que se usarán, como apoyo emocional?
Abhinav: Algunos de ellos son para apoyo emocional, o simplemente como amigos. La soledad y los problemas de salud mental son un tema candente. Si vas a los subreddits de esas comunidades, la gente está hablando y pensando en sus amigos de IA y estos personajes, es como algo salido de la ciencia ficción, y nunca esperé que eso sucediera.
Swyx: ¿Cuáles son los problemas sin resolver más interesantes en IA?
Abhinav: Estoy interesado en saber hasta dónde podemos llegar en términos de precisión y cosas como BF16/FP16.
Me pregunto si estos problemas se vuelven más tratables a medida que aumenta el tamaño del modelo. Documentos relacionados muestran que la cuantificación y la poda pueden volverse más fáciles a medida que aumenta la escala. Entonces, como consecuencia natural de la ampliación en los próximos años, podríamos avanzar hacia el uso de pesos de cuatro o dos bits o incluso binarios.
Jonathan: Me gustaría ver de otra manera cuán pequeño es el modelo que podemos lograr y cuán eficientemente podemos desarrollar un modelo con un rendimiento equivalente. Esta fue la pregunta en la que trabajé a lo largo de mi doctorado y, en cierto sentido, también en Mosaic. OpenAI nos ha mostrado una ruta hacia esta increíble capacidad, a saber, escalar. Pero espero que esta no sea la única manera. Espero que haya muchas otras formas de lograr esto también, a través de mejores métodos de modelado, mejores algoritmos, etc.
Si bien no soy un fanático de los tropos de la neurociencia, en cierto sentido, nuestra existencia y nuestros cerebros prueban que hay al menos otra forma de lograr esta increíble habilidad sin trillones de parámetros o incluso astronómicos: inversión de capital. Entonces, tengo mucha curiosidad sobre qué tan pequeño es el modelo que podemos lograr. ¿Existe otro camino hacia estas capacidades que no tenga que seguir el camino actual? Espero encontrar la respuesta en Mosaic, si existe.
Swyx: Sí, una de las cosas que más me interesan es el hecho de que el cerebro humano consume solo 30 vatios de potencia, y el modelo está lejos de eso en órdenes de magnitud.
Abhinav: No creo que puedas hacer eso con una sola GPU u otras herramientas.
Alessio: Hay mucha información en este momento, como ¿cómo debería pensar la gente sobre la inteligencia artificial? ¿En qué deberían enfocarse?
Jonatán: Mantén la calma. Algunas personas se toman la exageración demasiado en serio; otras son muy pesimistas, reaccionan fuertemente a ella o la niegan hasta cierto punto. Quédese tranquilo y sepa que hemos creado una herramienta muy útil.
Pero aún no hemos creado inteligencia general y, personalmente, no estamos ni cerca de ese objetivo. Por lo tanto, es importante ser pacífico y seguir la ciencia, y eso es por lo que se esfuerza Mosaic AI. Intentamos centrarnos en las cosas que son útiles para los humanos, con la esperanza de crear un mundo mejor. Haremos nuestro mejor esfuerzo, pero lo más importante, seguiremos la ciencia, nos guiaremos por los datos y lograremos este objetivo a través de resultados reales, no retóricos.
Abhinav: Creo que no hay nada como investigar en una comunidad abierta. En la comunidad, no solo un gran número de personas prestan atención a tu modelo, sino que incluso dan su opinión sobre los problemas del modelo y cómo mejorarlo. Este tipo de investigación abierta será el camino a seguir, tanto para mantener nuestros modelos seguros como para profundizar en el impacto y las consecuencias en el mundo real de estos modelos de IA.
todos los demás están mirando
La trayectoria evolutiva de los modelos grandes del lenguaje
El secreto de las ventanas de contexto de 100K para modelos de lenguaje grandes
Arquitecto jefe de GPT: el futuro de los grandes modelos de lenguaje
El autor de Transformer: el método de construcción de agentes instructivos
OneEmbedding: Entrenar un modelo de recomendación a nivel de TB con una sola tarjeta no es un sueño
Pruebe OneFlow: github.com/Oneflow-Inc/oneflow/
