En el último número, compartimos el artículo "El misterio del conjunto de datos de ChatGPT". Desde la perspectiva del modelo, según seis categorías (Wikipedia, libros, revistas, enlaces de Reddit, Common Crawl, otros), analizamos y ordenamos los datos desde 2018 hasta principios de 2022. Detalles de todos los dominios del conjunto de datos
Hoy, continuamos usando estas 6 categorías principales como contexto, desde la perspectiva de los conjuntos de datos públicos y clasificando los recursos de datos que se han colocado en los estantes de OpenDataLab y que se pueden usar para el entrenamiento previo de lenguaje grande. modelos, ajuste de instrucciones y otras categorías correspondientes a diferentes categorías, con la esperanza de ahorrarle tiempo de preparación de datos de piezas y brindarle iluminación.
Clasificación de grandes conjuntos de datos de modelos de lenguaje:
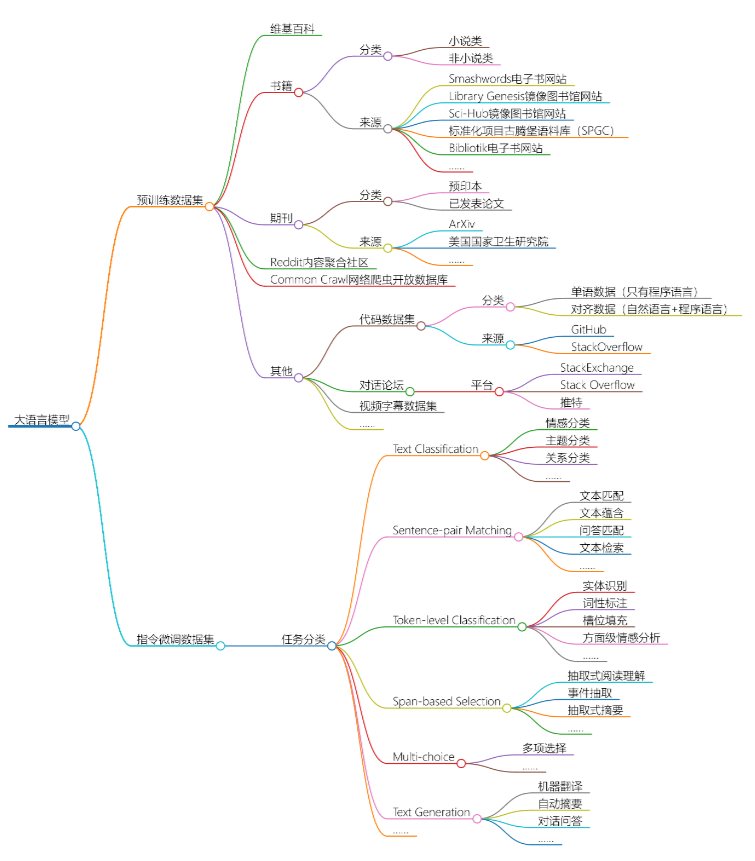
Referencia de clasificación: "ChatGPT Dataset Mystery" y recopilación de redes
1. Clase de Wikipedia
No.1
Identificación del plagio parafraseado por máquina
● Editorial : Universidad de Wuppertal, Alemania · Universidad Mendel de Brno
● Fecha de lanzamiento : 2021
● Breve :
este conjunto de datos se usa para entrenar y evaluar modelos para detectar texto interpretado por máquinas. El conjunto de entrenamiento contiene 200 767 segmentos (98 282 originales, 102 485 parafraseados) extraídos de 8024 artículos de Wikipedia (inglés) (4012 originales, 4012 parafraseados mediante la API de SpinBot). El conjunto de prueba se divide en 3 subconjuntos: uno de preprints de trabajos de investigación de arXiv, uno de disertaciones y uno de artículos de Wikipedia. Además, se utilizan diferentes métodos de paráfrasis de Marchine.
● Dirección de descarga :
https://opendatalab.org.cn/Identifying_Machine-Paraphrased_etc
No.2
Punto de referencia para la detección de paráfrasis neuronal
● Editor : Universidad de Wuppertal, Alemania
● Fecha de publicación : 2021
● Introducción :
este es un punto de referencia para la detección de paráfrasis neuronal para distinguir el contenido original del contenido generado por la máquina. Entrenamiento: 1.474.230 párrafos alineados extraídos de 4.012 artículos de Wikipedia (inglés) (98.282 párrafos originales, 1.375.948 párrafos parafraseados con 3 modelos y 5 configuraciones de hiperparámetros, 98.282 cada uno).
● Dirección de descarga :
https://opendatalab.org.cn/Benchmark_for_Neural_Paraphrase_etc
Numero 3
NatCat
● Fecha de lanzamiento : 2021
● Introducción :
un conjunto de datos de clasificación de texto general (NatCat) de tres fuentes en línea: Wikipedia, Reddit y Stack Exchange. Estos conjuntos de datos consisten en pares de categorías de documentos seleccionados manualmente derivados de eventos naturales en las comunidades.
● Dirección de descarga :
https://opendatalab.org.cn/NatCat
No. 4
Quoref
● Editor : Instituto Allen de Inteligencia Artificial · Universidad de Washington
● Tiempo de lanzamiento : 2019
● Introducción :
Quoref es un conjunto de datos de control de calidad para probar la capacidad de razonamiento de correferencia de los sistemas de comprensión de lectura. En este punto de referencia de selección de intervalos que contiene 24 000 preguntas en 4,7 000 pasajes de Wikipedia, el sistema debe resolver correferencias duras antes de poder seleccionar un intervalo adecuado dentro de un pasaje para responder a la pregunta.
● Enlace de descarga :
https://opendatalab.com/Quoref
Numero 5
QuAC (respuesta a preguntas en contexto)
● Publicado por : Instituto Allen de Inteligencia Artificial · Universidad de Washington · Universidad de Stanford · Universidad de Massachusetts Amherst
● Tiempo de lanzamiento : 2018
● Introducción :
la respuesta contextual a preguntas es un conjunto de datos a gran escala que consta de aproximadamente 14 000 conversaciones de preguntas y respuestas de colaboración abierta y un total de 98 000 pares de preguntas y respuestas. Los ejemplos de datos incluyen una conversación interactiva entre dos trabajadores colectivos: (1) un estudiante que hace una serie de preguntas de forma libre para aprender tanto como sea posible sobre el texto oculto de Wikipedia y (2) un estudiante que responde las preguntas proporcionando un breve extracto .El maestro (que abarca) proviene del texto.
● Dirección de descarga :
https://opendatalab.org.cn/QuAC
No.6
Trivia QA
● Editor : Instituto Allen de Inteligencia Artificial, Universidad de Washington
● Tiempo de lanzamiento : 2017
● Introducción :
TriviaQA es un conjunto de datos realista de respuesta a preguntas basado en texto que consta de 950 000 pares de preguntas y respuestas en 662 000 documentos de Wikipedia y la web. Este conjunto de datos es más desafiante que los conjuntos de datos de referencia de control de calidad estándar, como el conjunto de datos de respuesta a preguntas de Stanford (SQuAD), porque es posible que las respuestas a las preguntas no se obtengan directamente mediante la predicción de amplitud y el contexto es muy largo. El conjunto de datos de TriviaQA consta de subconjuntos de control de calidad verificados por humanos y generados por máquinas.
● Enlace de descarga :
https://opendatalab.com/TriviaQA
No.7
WikiQA (respuesta de preguntas de dominio abierto de Wikipedia)
● Editor : Microsoft Research
● Tiempo de lanzamiento : 2015
● Introducción :
el corpus de WikiQA es un conjunto de pares de preguntas y oraciones disponibles públicamente recopilados y anotados para el estudio de la respuesta a preguntas de dominio abierto. Para reflejar las necesidades reales de información de los usuarios generales, se utiliza el registro de consultas de Bing como origen del problema. Cada pregunta enlaza con una página de Wikipedia que puede tener una respuesta. Dado que la sección de resumen de una página de Wikipedia proporciona la información básica y, a menudo, la más importante sobre el tema, las oraciones de esta sección se utilizan como posibles respuestas. El corpus incluye 3.047 preguntas y 29.258 oraciones, de las cuales 1.473 oraciones están etiquetadas como oraciones de respuesta a las preguntas correspondientes.
● Dirección de descarga :
https://opendatalab.com/WikiQA
2. Libros
No.8
La pila
● Editorial : EleutherAI
● Tiempo de lanzamiento : 2020
● Introducción :
The Pile es un conjunto de datos de modelado de lenguaje de código abierto diverso de 825 GiB compuesto por 22 conjuntos de datos más pequeños de alta calidad ensamblados.
● Enlace de descarga :
https://opendatalab.com/The_Pile
No.9
LibroCorpus
● Editorial : Universidad de Toronto MIT
● Tiempo de lanzamiento : 2015
● Introducción :
BookCorpus es una colección masiva de libros de ficción gratuitos de autores inéditos, que contiene 11 038 libros (~74 millones de oraciones y 1 g de palabras) en 16 subgéneros diferentes (p. ej., romance, historia, aventuras, etc.).
● Enlace de descarga :
https://opendatalab.org.cn/BookCorpus
No.10
EXEQ-300k
● Editor : Universidad de Pekín · Universidad Estatal de Pensilvania · Universidad Sun Yat-Sen
● Tiempo de lanzamiento : 2020
● Introducción :
el conjunto de datos EXEQ-300k contiene 290 479 preguntas detalladas con los títulos matemáticos correspondientes de Math Stack Exchange. Este conjunto de datos se puede utilizar para generar subtítulos matemáticos concisos a partir de problemas matemáticos detallados.
● Dirección de descarga :
https://opendatalab.org.cn/EXEQ-300k
3. Publicaciones periódicas
No.11
publicado
● Publicado por : Universidad de Maryland
● Tiempo de lanzamiento : 2008
● Introducción :
el conjunto de datos de Pubmed contiene 19717 publicaciones científicas relacionadas con la diabetes de la base de datos de PubMed, clasificadas en una de tres categorías. La red de citas consta de 44338 enlaces. Cada publicación en el conjunto de datos se describe mediante un vector de palabras ponderado TF/IDF de un diccionario que consta de 500 palabras únicas.
● Enlace de descarga :
https://opendatalab.org.cn/Pubmed
No.12
Conjunto de datos de lectura en papel de PubMed
● Editorial : Universidad de Illinois en Urbana-Champaign · Didi Lab · Instituto Politécnico Rensselaer · Universidad de Carolina del Norte en Chapel Hill · Universidad de Washington
● Tiempo de lanzamiento : 2019
● Introducción :
este conjunto de datos recopila 14 857 entidades, 133 relaciones y entidades correspondientes al texto tokenizado de PubMed. Contiene 875.698 pares de entrenamiento, 109.462 pares de desarrollo y 109.462 pares de prueba.
● Enlace de descarga :
https://opendatalab.org.cn/PubMed_Paper_Reading_Dataset
No.13
ECA de PubMed (ECA de PubMed 200k)
● Publicado por : Adobe Research MIT
● Tiempo de lanzamiento : 2017
● Introducción :
PubMed 200k RCT es un nuevo conjunto de datos basado en PubMed para la clasificación secuencial de oraciones. El conjunto de datos consta de aproximadamente 200 000 resúmenes de ensayos controlados aleatorios que suman un total de 2,3 millones de oraciones. Cada oración de cada resumen está etiquetada con una de las siguientes categorías según su función en el resumen: antecedentes, objetivos, métodos, resultados o conclusión. El propósito de publicar este conjunto de datos es doble. En primer lugar, la mayoría de los conjuntos de datos para la clasificación secuencial de textos cortos (es decir, la clasificación de textos cortos que aparecen en secuencias) son pequeños: los autores esperan que la publicación de un nuevo conjunto de datos grande ayude a desarrollar un algoritmo más preciso. En segundo lugar, desde una perspectiva aplicada, los investigadores necesitan mejores herramientas para explorar la literatura de manera eficiente. La categorización automática de cada oración en un resumen ayudará a los investigadores a leer los resúmenes de manera más eficiente, especialmente en campos donde los resúmenes pueden ser largos, como la medicina.
● Dirección de descarga :
https://opendatalab.org.cn/PubMed_RCT
No.14
MedHop
● Publicado por : University College London Bloomsbury AI
● Tiempo de lanzamiento : 2018
● Introducción :
en el mismo formato que WikiHop, el conjunto de datos de MedHop se basa en resúmenes de trabajos de investigación en PubMed, y las consultas son sobre interacciones entre pares de medicamentos. La respuesta correcta debe deducirse combinando la información de la secuencia de reacciones del fármaco y la proteína.
● Dirección de descarga :
https://opendatalab.org.cn/MedHop
No.15
ArxivPapers
● Publicado por : Facebook · University College London · DeepMind
● Tiempo de lanzamiento : 2020
● Introducción :
el conjunto de datos de ArxivPapers es una colección de más de 104 000 artículos sin etiqueta relacionados con el aprendizaje automático publicados en arXiv.org entre 2007 y 2020. El conjunto de datos incluye aproximadamente 94 000 artículos (el código fuente de LaTeX está disponible) en un formato estructurado donde los artículos se dividen en título, resumen, secciones, párrafos y referencias. Además, el conjunto de datos contiene más de 277 000 tablas extraídas de documentos LaTeX. Debido a la licencia de la disertación, el conjunto de datos se publica como metadatos y se puede utilizar una canalización de código abierto para obtener y transformar la disertación.
● Dirección de descarga :
https://opendatalab.org.cn/ArxivPapers
No.16
unarXive
● Editorial : Instituto de Tecnología de Karlsruhe
● Tiempo de lanzamiento : 2020
● Perfil :
una colección de conjuntos de datos académicos que contienen el texto completo de las publicaciones, citas anotadas en el texto y enlaces a metadatos. El conjunto de datos de unarXive contiene 1 millón de documentos de texto sin formato 63 millones de contextos de citas 39 millones de cadenas de referencia 16 millones de datos web de citas conectadas de todas las fuentes de LaTeX en arXiv entre 1991 y 2020/07, por lo que es de mayor calidad que los datos generados a partir de archivos PDF. Además, dado que todos los artículos que citan están disponibles en texto completo, se pueden extraer contextos de citas de cualquier tamaño. Los usos típicos del conjunto de datos son métodos en la recomendación de citas, el análisis del contexto de la cita, la cadena de referencia, el análisis del código para generar el conjunto de datos, está disponible públicamente.
● Dirección de descarga :
https://opendatalab.org.cn/unarXive
No.17
Conjunto de datos de resumen de arXiv
● Publicado por : Universidad de Georgetown · Adobe Research
● Tiempo de lanzamiento : 2018
● Introducción :
Este es un conjunto de datos para evaluar métodos de abstracción en trabajos de investigación.
● Dirección de descarga :
https://opendatalab.org.cn/arXiv_Summarization_Dataset
No.18
SCICAP
● Publicado por : Universidad Estatal de Pensilvania
● Fecha de lanzamiento : 2021
● Introducción :
SciCap es un conjunto de datos de subtítulos de gráficos a gran escala basado en artículos de ciencia informática arXiv, publicado en 2010 y publicado en 2020. SCICAP contiene más de 416k gráficos centrados en un tipo de gráfico dominante: gráficos de gráficos, extraídos de más de 290 000 artículos.
● Dirección de descarga :
https://opendatalab.org.cn/SCICAP
No.19
MathMLben (prueba comparativa de semántica de fórmulas)
● Editor : Instituto Nacional de Estándares y Tecnología de la Universidad de Konstanz
● Tiempo de lanzamiento : 2017
● Introducción :
MathMLben es un punto de referencia de herramientas de evaluación para la conversión de formatos matemáticos (LaTeX ↔ MathML ↔ CAS). Contiene tareas/conjuntos de datos de NTCIR 11/12 arXiv y Wikipedia, la Biblioteca digital de funciones matemáticas (DLMF) del NIST y un sistema para recomendar fórmulas y nombres de identificadores mediante AnnoMathTeX (https://annomathtex.wmflabs.org).
● Dirección de descarga :
https://opendatalab.org.cn/MathMLben
4. Clase de comunidad de agregación de contenido de Reddit
No.20
AbrirTextoWeb
● Editor : Universidad de Washington · Investigación de IA de Facebook
● Tiempo de lanzamiento : 2019
● Introducción :
OpenWebText es una reingeniería de código abierto del corpus WebText. Este texto es contenido web extraído de una URL compartida en Reddit con al menos 3 votos positivos (38 GB).
● Dirección de descarga :
https://opendatalab.org.cn/OpenWebText
5. Base de datos abierta del rastreador web Common Crawl
No.21
C4 (Corpus Rastreado Limpio Colosal)
● Editor : Investigación de Google
● Tiempo de lanzamiento : 2020
● Introducción :
C4 es una versión enorme y limpia del corpus de rastreadores web de Common Crawl. Se basa en el conjunto de datos de Common Crawl: https://commoncrawl.org. Se utiliza para entrenar el modelo de transformador de texto a texto T5. El conjunto de datos se puede descargar en formato preprocesado desde allennlp.
● Enlace de descarga :
https://opendatalab.com/C4
No.22
Rastreo común
● Editorial : Instituto Nacional de Informática y Automatización de Francia · Universidad de la Sorbona
● Tiempo de lanzamiento : 2019
● Introducción :
Common Crawl Corpus contiene petabytes de datos recopilados durante 12 años de rastreo web. El corpus contiene datos de páginas web sin procesar, extracción de metadatos y extracción de texto. Los datos de Common Crawl se almacenan en conjuntos de datos públicos de Amazon Web Services y en varias nubes académicas de todo el mundo.
● Dirección de descarga :
https://opendatalab.org.cn/Common_Crawl
6. Otras categorías
conjunto de datos de código
No.23
CodeSearchNet
● Editor : Microsoft Research GitHub
● Tiempo de lanzamiento : 2020
● Introducción :
CodeSearchNet Corpus es un gran conjunto de datos de funciones que contiene documentación relevante escrita en Go, Java, JavaScript, PHP, Python y Ruby de proyectos de código abierto en GitHub. El corpus de CodeSearchNet incluye: * 6 millones de métodos en total * 2 millones de los cuales tienen documentación asociada (docstrings, JavaDoc, etc.) * Metadatos que indican dónde se encontraron originalmente los datos (como repositorio o número de línea).
● Dirección de descarga :
https://opendatalab.org.cn/CodeSearchNet
No.24
StaQC
● Publicado por : Universidad Estatal de Ohio · Universidad de Washington · Instituto de Investigación Fujitsu
● Tiempo de lanzamiento : 2018
● Introducción :
StaQC (Pares de códigos de preguntas de desbordamiento de pila) es, con mucho, el conjunto de datos más grande con aproximadamente 148 000 pares de códigos de preguntas de dominio Python y 120 000 SQL, extraídos automáticamente de Stack Overflow mediante la red neuronal jerárquica Bi-View.
● Dirección de descarga :
https://opendatalab.org.cn/StaQC
No.25
CódigoExp
● Editor : Universidad de Beihang·Microsoft Research·Universidad de Toronto
● Tiempo de lanzamiento : 2022
● Introducción :
proporcionamos un corpus de cadenas de documentación de código de Python, CodeExp, que contiene (1) una partición grande de 2,3 millones de pares de cadenas de documentación de código sin procesar, (2) una partición de 158 000 pares medianos del corpus sin procesar mediante filtros aprendidos y ( 3) anotaciones de partición con 13.000 pares estrictamente humanos. Nuestro proceso de recopilación de datos aprovecha los modelos de anotación aprendidos de humanos para filtrar automáticamente pares de cadenas de documentos y código anotados de alta calidad del conjunto de datos original de GitHub.
● Dirección de descarga :
https://opendatalab.org.cn/CodeExp
No.26
ETH Py150 Abierto
● Editor : Instituto Indio de Ciencias · Investigación de IA de Google
● Tiempo de lanzamiento : 2020
● Introducción :
un corpus deduplicado a gran escala de 7,4 millones de archivos de Python de GitHub.
● Dirección de descarga :
https://opendatalab.org.cn/ETH_Py150_Open
Conjunto de datos del foro
No.27
Desbordamiento de pila federado
● Editor : Investigación de Google
● Tiempo de lanzamiento : 2022
● Breve :
Los datos consisten en el texto de todas las preguntas y respuestas. El cuerpo se analiza en oraciones y los usuarios con menos de 100 oraciones se eliminan de los datos. El preprocesamiento mínimo se realiza de la siguiente manera: texto en minúsculas, escape de símbolos HTML, eliminación de símbolos que no sean ASCII, signos de puntuación separados como tokens separados (excepto apóstrofes y guiones), eliminación de espacios en blanco redundantes y reemplazo de URL con tokens especiales. Además, se proporcionan los siguientes metadatos: Fecha de creación Título de la pregunta Etiqueta de la pregunta Tipo de puntuación de la pregunta ("Pregunta" o "Respuesta").
● Dirección de descarga :
https://opendatalab.org.cn/Federated_Stack_Overflow
No.28
QUASAR (respuesta de preguntas mediante búsqueda y lectura)
● Publicado por : Universidad Carnegie Mellon
● Tiempo de lanzamiento : 2017
● Introducción :
Respuesta a preguntas sobre búsqueda y lectura (QUASAR) es un conjunto de datos a gran escala que consta de QUASAR-S y QUASAR-T. Cada uno de estos conjuntos de datos está diseñado para centrarse en la evaluación de sistemas diseñados para comprender consultas en lenguaje natural, grandes corpus de texto y extraer respuestas a preguntas del corpus. Específicamente, QUASAR-S consta de 37 012 preguntas para completar en blanco recopiladas del popular sitio web Stack Overflow utilizando etiquetas de entidad. El conjunto de datos QUASAR-T contiene 43 012 preguntas de dominio abierto recopiladas de varios recursos de Internet. Los documentos candidatos para cada pregunta en este conjunto de datos se recuperan de un motor de búsqueda basado en Apache Lucene creado sobre el conjunto de datos ClueWeb09.
● Dirección de descarga :
https://opendatalab.org.cn/QUASAR
No.29
Conjunto de datos de respuesta GIF
● Publicado por : Universidad Carnegie Mellon
● Tiempo de lanzamiento : 2017
● Introducción :
el conjunto de datos de respuestas GIF publicadas contiene 1 562 701 conversaciones reales de texto-GIF en Twitter. En estas conversaciones se utilizaron 115.586 GIF únicos. Los metadatos, incluido el texto extraído con OCR, las etiquetas anotadas y los nombres de los objetos, también están disponibles para algunos de los GIF en este conjunto de datos.
● Dirección de descarga :
https://opendatalab.org.cn/GIF_Reply_Dataset
Conjunto de datos de subtítulos de video
No.30
TVC (Subtítulos de programas de televisión)
● Publicado por : Universidad de Carolina del Norte en Chapel Hill
● Tiempo de lanzamiento : 2020
● Introducción :
TV Show Caption es un conjunto de datos de subtítulos multimodales a gran escala que contiene 261 490 descripciones de subtítulos y 108 965 videoclips cortos. TVC es único porque sus subtítulos también pueden describir diálogos/subtítulos, mientras que los subtítulos en otros conjuntos de datos solo describen contenido visual.
● Dirección de descarga :
https://opendatalab.org.cn/TVC
Lo anterior es este intercambio, porque el espacio es limitado, para obtener más conjuntos de datos, visite el sitio web oficial de OpenDataLab: https://opendatalab.org.cn/