
Gracias por leer la serie de blogs "Creación de la base de conocimientos de empresas de próxima generación basada en la búsqueda inteligente y modelos grandes". La serie completa se divide en 5 artículos. Presentará sistemáticamente nuevas tecnologías, como la forma en que los modelos de lenguaje grande pueden potenciar los modelos tradicionales. escenarios de la base de conocimientos y ayudar a la industria a reducir los costos del cliente y aumentar la eficiencia. El directorio de actualización es el siguiente:
El primer artículo "Introducción a escenarios prácticos típicos y componentes básicos"
Tercera parte "Integración de Langchain y su aplicación en el comercio electrónico" (esta parte)
Cuarta parte "Fabricación/Finanzas/Educación y otras industrias Escenarios prácticos" (próximamente)
La quinta "Integración con Amazon Kendra" (próximamente)
fondo
En esta serie de blogs "Creación de la base de conocimientos de próxima generación de empresas basada en la búsqueda inteligente y modelos grandes", los dos artículos anteriores han presentado "Introducción a escenarios prácticos típicos y componentes básicos" y "Guía para la implementación rápida a mano". El artículo presenta principalmente LangChain y la integración del modelo de lenguaje grande de código abierto, combinado con los servicios básicos de la nube de la tecnología de la nube de Amazon, crea una solución inteligente de respuesta a preguntas de búsqueda basada en la base de conocimientos de la empresa.
Introducción a LangChain
LangChain es un marco de código abierto que utiliza la capacidad de los modelos de lenguaje grandes para desarrollar varias aplicaciones posteriores. Su concepto central es implementar una interfaz común para varias aplicaciones de modelos de lenguaje grandes y simplificar la dificultad de desarrollo de las aplicaciones de modelos de lenguaje grandes. El esquema del módulo principal diagrama es el siguiente:
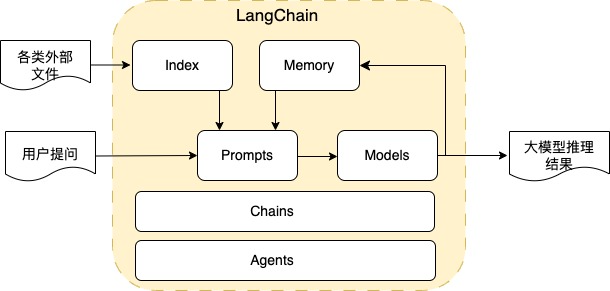
Índice: proporciona varias interfaces para la importación de documentos, división de texto y almacenamiento y recuperación de texto vectorizado. Además de Word, Excel, PDF y txt comunes, los tipos de documentos importados también incluyen API e interfaces de base de datos. El almacenamiento vectorizado incluye varios vectores A. como base de datos que también incluye el motor de búsqueda OpenSearch de Amazon. A través del módulo Index, es muy fácil procesar varios tipos de datos externos para proporcionar grandes modelos de razonamiento.
Solicitudes: convierta la entrada del usuario y otros datos externos en palabras de solicitud adecuadas para modelos de lenguaje grandes, incluida la administración de palabras de solicitud, la optimización de palabras de solicitud y la serialización de palabras de solicitud. Al ajustar las palabras del mensaje, el modelo de lenguaje grande se puede usar para realizar varias tareas, como texto de generación de texto (incluido chat, pregunta y respuesta, resumen, informe, etc.), SQL de generación de texto, código de generación de texto, etc. Además, el modelo se puede usar para realizar un aprendizaje de pocas tomas, actualmente la práctica óptima de palabras indicadoras para cada tarea está en pleno apogeo. A través de las palabras indicadoras, los límites de capacidad de los modelos de lenguaje grandes se exploran continuamente. LangChain proporciona una forma fácil de -utilice la herramienta de gestión de palabras rápidas.
Modelos: proporciona administración e integración de varios modelos de lenguajes grandes. Además de las interfaces API de modelos de lenguajes grandes de código cerrado, también proporciona interfaces de integración para modelos de lenguajes grandes de código abierto en múltiples almacenes de modelos de código abierto, así como modelos de lenguajes grandes implementados en La interfaz del modelo de idioma, como la interfaz del modelo de idioma grande implementada en Amazon SageMaker Endpoint.
Memoria: se utiliza para guardar el estado del contexto al interactuar con el modelo y es un componente clave para realizar múltiples rondas de diálogo.
Cadenas: los componentes principales de LangChain, que pueden combinar los componentes anteriores para completar tareas específicas. Por ejemplo, una cadena puede incluir plantillas de solicitud, modelos de lenguaje grandes y componentes de procesamiento de salida para completar las funciones de chat del usuario. Para varias tareas, LangChain proporciona diferentes cadenas. Por ejemplo, la tarea de respuesta de preguntas proporciona la cadena de respuesta de preguntas, la tarea de resumen de texto proporciona la cadena de resumen, la tarea SQL de generación de texto proporciona la cadena SQL y la tarea de cálculo matemático proporciona el LLM Math. Cadena La cadena se puede personalizar, y el componente Cadena proporciona diferentes modos de razonamiento del modelo, incluidos cosas, map_reduce, refine, map-rerank, etc. .
Agentes: las funciones avanzadas de LangChain pueden decidir a qué herramientas llamar en función de la entrada del usuario y pueden combinar una serie de cadenas para completar tareas complejas, como preguntar: ¿Cuánto oro puedo comprar con el saldo de mi cuenta? Los agentes consultan el saldo de la cuenta a través de la cadena SQL, encuentran el precio del oro en tiempo real llamando al LLM de la interfaz de consulta de la página web y completan la tarea final llamando al LLM Math para calcular la cantidad de oro que se puede comprar. las operaciones lógicas se pueden configurar en Agentes.
Además de LangChain, otro marco de desarrollo de aplicaciones de modelo de lenguaje grande de código abierto de uso común es LIamaIndex. LIamaIndex tiene una rica interfaz de importación de datos, especialmente el soporte para datos estructurados es más amigable Además, el índice de LIamaIndex encapsula la lógica de preguntas y respuestas de múltiples modos, que es fácil de usar pero carece de flexibilidad. LIamaIndex admite la integración con LangChain y los dos marcos pueden llamarse entre sí.
Basado en búsqueda inteligente
Guía de solución de aumento de modelo de lenguaje grande
Combinando las diversas interfaces funcionales de LangChain y los servicios básicos de Amazon Cloud Technology, hemos construido la guía de soluciones de Amazon Cloud Technology para la mejora del modelo de lenguaje grande basada en la búsqueda inteligente. El diagrama de la arquitectura es el siguiente:
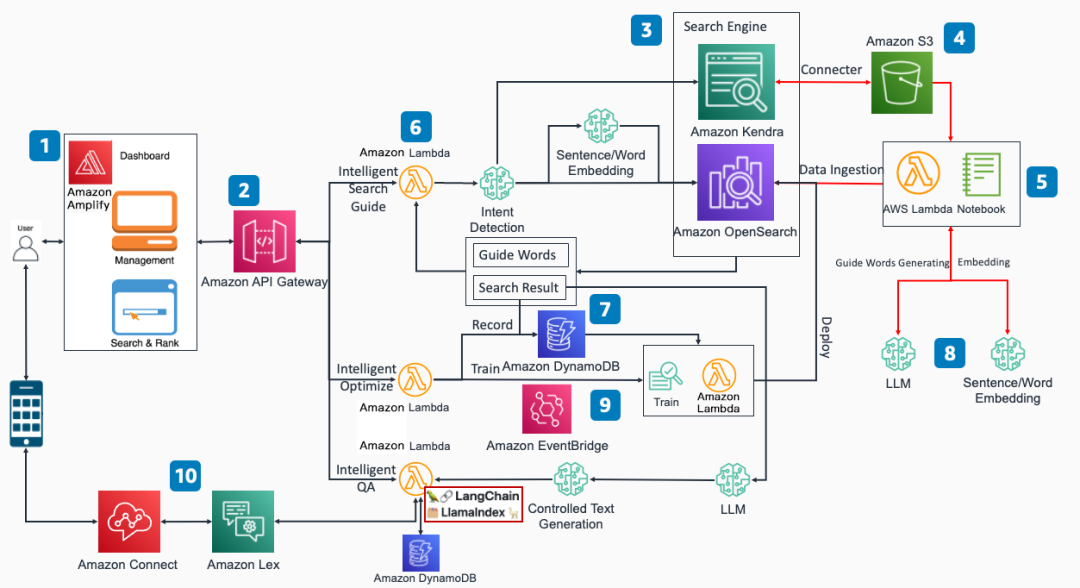
En comparación con el diagrama de arquitectura del primer artículo de esta serie de blogs "Escenarios prácticos típicos e introducción a los componentes principales", las principales diferencias de este artículo son las siguientes:
En la función de control de calidad inteligente, el código Lambda que implementa la lógica funcional integra los marcos LangChain y LIamaIndex, utilizando el marco de código abierto para mejorar la flexibilidad y la escalabilidad de la solución, y la capacidad de LangChain se puede usar para agregar rápidamente nuevas funciones en el futuro.
Se agregó el componente DynamoDB, que se utiliza para guardar los registros de diálogo de múltiples rondas del usuario y realizar la función de diálogo de múltiples rondas.
El diagrama de flujo de trabajo del esquema es el siguiente:
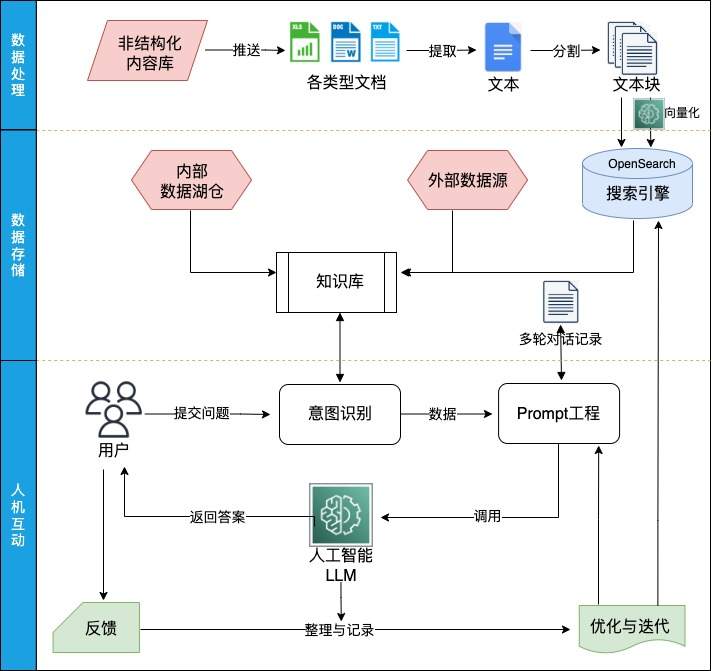
El flujo de trabajo del esquema y la integración con LangChain son los siguientes:
1. El módulo de procesamiento y almacenamiento de datos integra la interfaz de índice de LangChain, admite una variedad de importaciones de datos externos, resume varios tipos de datos y forma una base de conocimiento empresarial:
Para datos no estructurados, admite principalmente documentos comunes como Word, Excel, PDF y txt. A través de la extracción de texto y la división de texto de datos no estructurados, se obtienen múltiples bloques de texto y se obtienen llamando al modelo vectorial implementado en SageMaker Endpoint. Los vectores correspondientes y, finalmente, almacenar el bloque de texto y los vectores en el motor de búsqueda de OpenSearch.
Para datos estructurados, el índice SQL integrado con LlamaIndex se utiliza para leer la base de datos y obtener los datos correspondientes. En la actualidad, la base de datos de consulta del lenguaje SQL se genera principalmente a través de reglas, y el lenguaje SQL generado a través del modelo de lenguaje grande de código abierto todavía está en puesta en marcha
Si necesita consultar la red para obtener información en tiempo real, puede leer la información de la URL a través de la interfaz de índice o consultar la información de la red en tiempo real a través de la interfaz del motor de búsqueda.
2. El módulo de reconocimiento de intenciones integra la interfaz RouterChain de LangChain y selecciona automáticamente la fuente de datos adecuada para responder a la pregunta del usuario al hacer un juicio semántico sobre la pregunta de entrada del usuario.
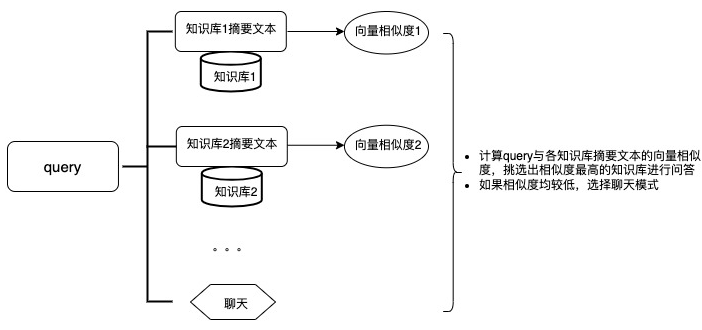
3. El módulo de ingeniería de Prompt integra la interfaz de Prompt de LangChain para administrar y optimizar Prompts con diferentes tareas, escenarios e idiomas. Al mismo tiempo, integra la interfaz de memoria de LangChain, almacena las preguntas y respuestas del usuario en DynamoDB, forma la información del historial de la pregunta y respuesta del usuario y sirve como base de razonamiento para el gran modelo de lenguaje del diálogo de múltiples rondas. tarea.
4. El módulo del modelo de lenguaje grande integra la interfaz de modelo de LangChain, llama al modelo de lenguaje grande de código abierto implementado en SageMaker Endpoint y razona en varios tipos de tareas.
5. El módulo de iteración de retroalimentación y optimización, al registrar las respuestas a las preguntas, analiza los problemas en la solución y los optimiza en la base de conocimiento y el proyecto Prompt a tiempo.
En comparación con otras soluciones de implementación de privatización de base de conocimiento basadas en LangChain, esta solución utiliza servicios nativos en la nube de Amazon Cloud Technology, incluidos SageMaker, OpenSearch y Lambda, etc. Estos servicios nativos en la nube pueden usar el mecanismo de escalado automático de acuerdo con el tráfico en línea real. condiciones, Expanda o contrate rápidamente los recursos para garantizar el buen funcionamiento de los negocios en línea con el mejor rendimiento de costos.
Puede depurar fácilmente la función inteligente de preguntas y respuestas a través de la página de depuración de la solución:
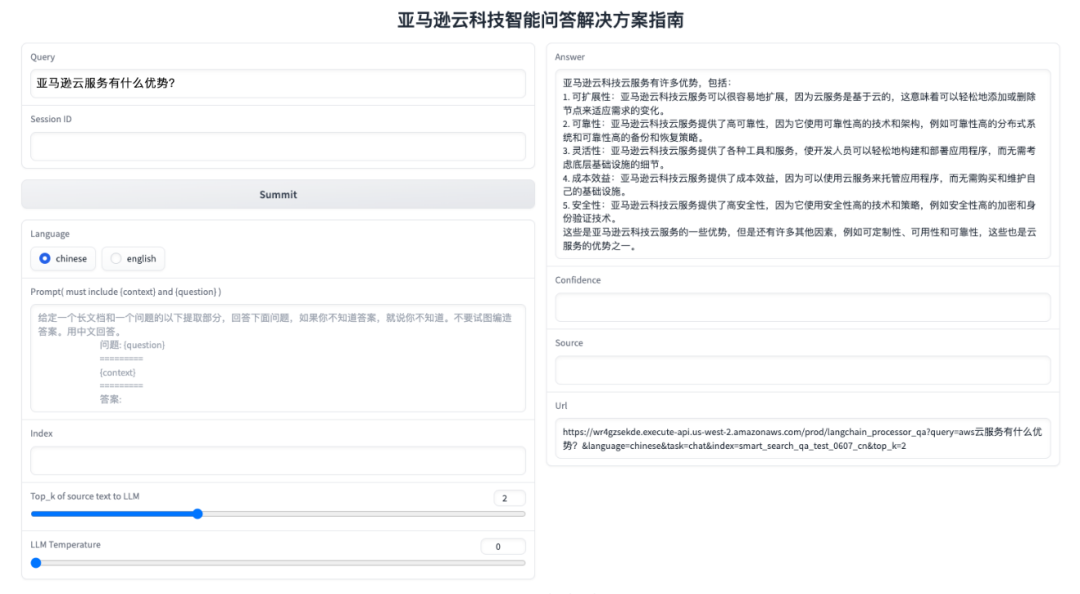
ingresar:
consulta: texto de la pregunta del usuario
ID de sesión: la ID de sesión solicitada por el usuario, la información del diálogo se guardará en DynamoDB con la ID de sesión como clave
Idioma: selección de idioma, actualmente es compatible con chino e inglés, el método de división de texto, el modelo de vector de texto y el modelo de idioma grande de código abierto son diferentes para diferentes idiomas
Solicitud: depuración de palabras de solicitud, según la palabra de solicitud predeterminada, puede probar el impacto de diferentes textos de palabras de solicitud en los resultados
Índice: índice de datos almacenados de OpenSearch
Top_k: la cantidad de textos relevantes incluidos en el razonamiento del modelo grande. Si los documentos están más estandarizados, los documentos y la consulta son fáciles de combinar, y Top_k se puede reducir para aumentar la certeza de la respuesta.
Temperatura LLM: el parámetro de temperatura del modelo de lenguaje grande. El parámetro de temperatura controla el grado de aleatoriedad del modelo de lenguaje grande. Cuanto menor sea la temperatura, mayor será la certeza de la respuesta.
producción:
Respuesta: La salida de inferencia del modelo de lenguaje grande a la pregunta
Confianza: Confianza de la respuesta
Fuente: el texto relacionado con Query y colocado en el razonamiento del modelo grande
Aplicación de la guía de solución de mejora del modelo de lenguaje grande basado en búsqueda inteligente en escenarios de comercio electrónico
Atención al cliente inteligente
Con el desarrollo de la industria del comercio electrónico, los consumidores tienen requisitos cada vez más altos para la calidad del servicio de compras en línea, y el servicio al cliente se ha convertido en una parte indispensable de los servicios de comercio electrónico. Para ahorrar costos, los comerciantes tienden a utilizar el servicio de atención al cliente inteligente para responder automáticamente preguntas simples y responder manualmente las preguntas que no pueden ser resueltas por el servicio de atención al cliente inteligente. Sin embargo, los sistemas inteligentes de servicio al cliente de las principales plataformas de comercio electrónico a menudo brindan respuestas preestablecidas a través de palabras clave y no pueden comprender completamente las preguntas planteadas por los clientes. Existe una brecha entre las respuestas y las necesidades de los clientes, y la experiencia del usuario no es amigable. . La comprensión semántica y las capacidades de razonamiento inductivo del modelo de lenguaje grande son muy adecuadas para escenarios de servicio al cliente inteligente. La aplicación actual de la solución en escenarios de atención inteligente al cliente incluye:
1. Preguntas y respuestas inteligentes basadas en la base de conocimiento empresarial. Utilice los datos de la base de conocimientos de la empresa, combinados con la capacidad de razonamiento de los grandes modelos lingüísticos, para lograr preguntas y respuestas precisas.
En el siguiente ejemplo, después de importar el documento de muestra de devolución e intercambio de comercio electrónico, el cliente pregunta la respuesta a la pregunta de devolución:
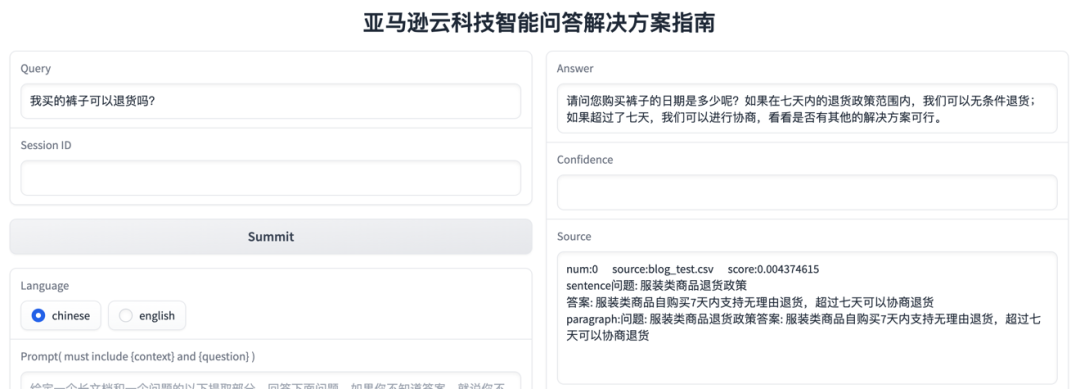
Como se puede ver en el ejemplo anterior, el modelo de lenguaje grande entiende que los pantalones comprados por el cliente pertenecen a la categoría de ropa, y existe una política de devolución sin motivo de 7 días correspondiente, pero se requiere una mayor adquisición de la fecha de compra. para confirmar si se puede realizar la devolución, y finalmente se genera una nueva adquisición de compras del cliente fechas y respuestas explicadas sobre la política de devolución de 7 días sin preguntas.
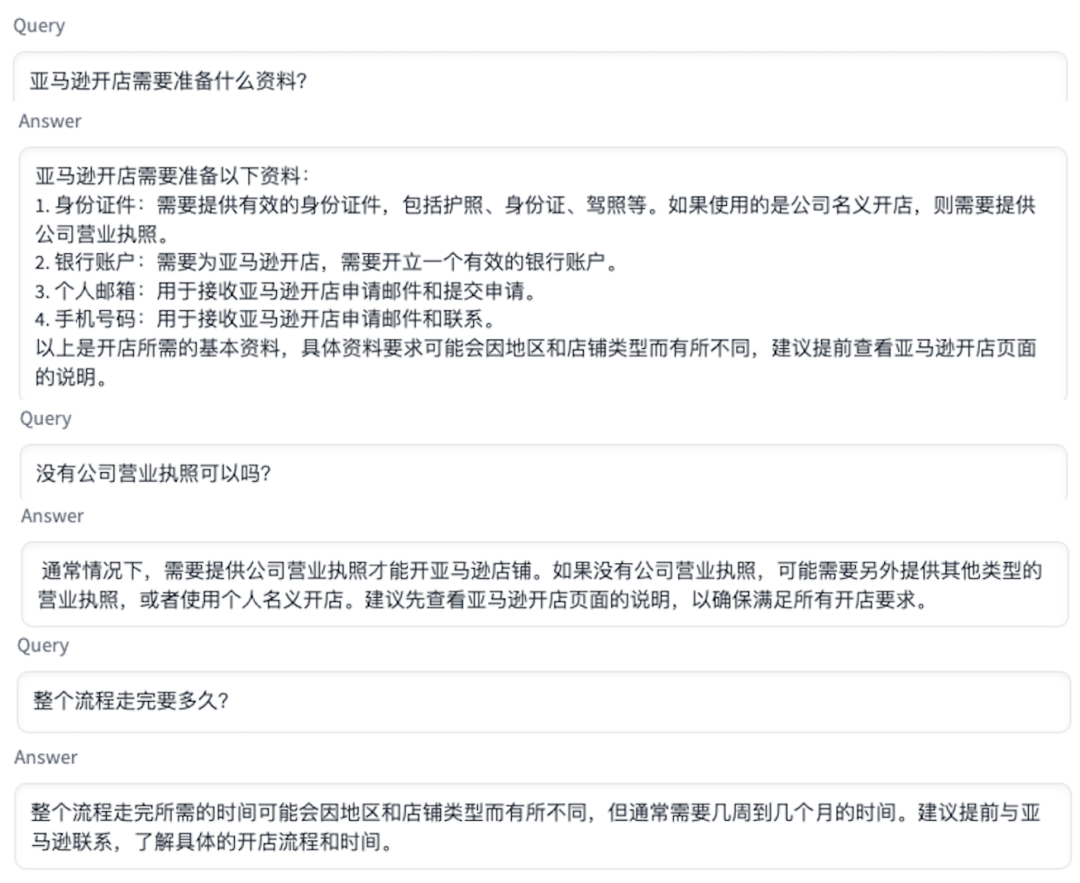
2. Múltiples rondas de chat. La solución guardará la información sobre la interacción entre el usuario y el modelo de lenguaje grande, e incorporará palabras de aviso como información de contexto en la próxima conversación, de modo que el modelo de lenguaje grande pueda conocer la información de contexto para responder preguntas posteriores.
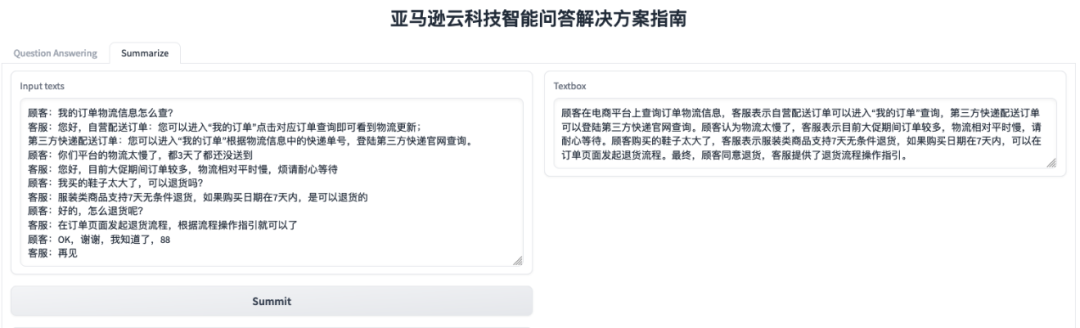
3. Extracción de resumen de texto y generación de informes de texto. Al ingresar los registros de llamadas telefónicas en el servicio al cliente, genere rápidamente un resumen de llamadas y extraiga con precisión los puntos de demanda mencionados por el usuario en los registros de llamadas, para que el análisis posterior de los registros de llamadas y el marketing de seguimiento del cliente. El siguiente es un caso de un cliente que consulta un problema de compra de un producto:
Recomendación inteligente
En la actualidad, la industria del comercio electrónico está entrando gradualmente en la era del comercio electrónico de contenido, y la entrega de transmisión en vivo representa una proporción cada vez mayor de las transacciones de comercio electrónico. Una de las características de la entrega de entrega en vivo es que la interacción entre el ancla y la audiencia es muy frecuente y la audiencia suele hacer preguntas sobre la escena de transmisión en vivo. El sistema inteligente de preguntas y respuestas se puede utilizar como una guía de compras para ayudar al presentador a responder preguntas. Por ejemplo, en una sala de transmisión en vivo donde el presentador promociona zapatillas de deporte, la audiencia puede preguntar: "¿Qué serie de zapatillas de deporte son adecuadas para jugar al fútbol en días lluviosos?", "¿Qué color se ve mejor para las personas gordas?", "¿Qué par de zapatillas están disponibles para parejas?", El sistema inteligente de preguntas y respuestas puede combinar información de descripción del producto, información de evaluación del producto, y la información de registro de compra del usuario para generar directamente recomendaciones de productos o sugerencias de uso de productos para las preguntas de los usuarios, mejorando la interacción entre los anclajes y la eficiencia de las audiencias.
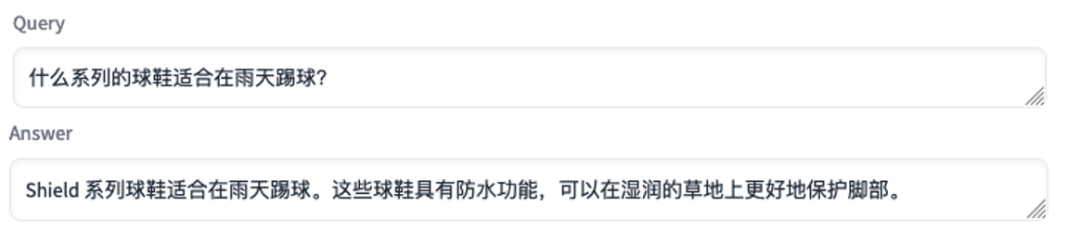
Los datos de muestra del producto utilizados por el sistema inteligente de respuesta a preguntas para generar respuestas:

En el ejemplo anterior, después de proporcionar información sobre los escenarios de uso apropiado de diferentes series de zapatillas, el sistema inteligente de respuesta a preguntas puede recomendar productos adecuados a los usuarios de acuerdo con las preguntas planteadas por los clientes.
Problemas y soluciones más frecuentes
En la actualidad, la función inteligente de preguntas y respuestas basada en la base de conocimiento empresarial es la función más demandada e implementada. Cuando la solución se implementa en diferentes escenarios, a menudo debe ajustarse de acuerdo con los requisitos específicos del escenario. Problemas comunes y soluciones encontrados durante la implementación incluyen:
1. ¿Cómo encontrar exactamente el texto relevante para la pregunta en la base de conocimientos?
Utilizamos principalmente documentos de reglas empresariales y datos anteriores de preguntas y respuestas del servicio de atención al cliente como base de conocimiento. Los documentos se almacenan en formato docs, y se usan oraciones y párrafos para dividir los datos. Sin embargo, el problema principal es: múltiples oraciones o los párrafos forman un párrafo lógico, y el tamaño del párrafo lógico No uno, si se divide por oración o párrafo, es posible separar el párrafo lógico, por ejemplo, la pregunta y la respuesta se pueden dividir en dos bloques de texto para almacenamiento, o parte del párrafo lógico anterior se puede agregar al siguiente párrafo lógico. Algunos de ellos se almacenan, por lo que las respuestas correspondientes no se pueden encontrar correctamente de acuerdo con las preguntas durante la recuperación. El diagrama esquemático de la división de errores es el siguiente:
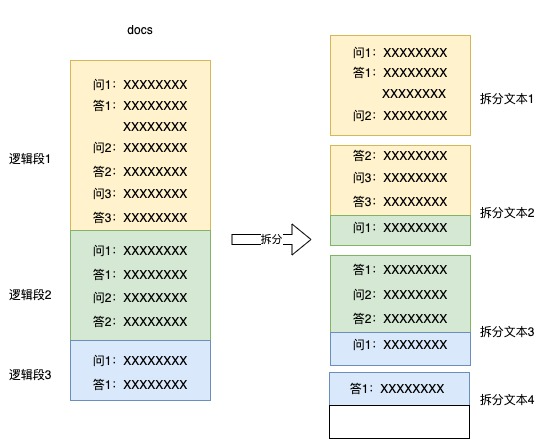
solución:
Convierta el procesamiento de documentos docs al almacenamiento en formato csv, coloque el contenido de cada segmento lógico en una línea y separe manualmente los segmentos lógicos.
El bloque de texto dividido se divide en múltiples textos vectorizados por oraciones o párrafos para la vectorización, todo el texto del bloque lógico se usa como texto de recuperación, y el texto de vector, el vector y el texto de recuperación se almacenan como una pieza de información de texto.
Al buscar, el vector de texto se usa para hacer coincidir el vector de pregunta, y todo el texto del bloque lógico se usa como texto de recuperación que se enviará al modelo grande para el razonamiento.
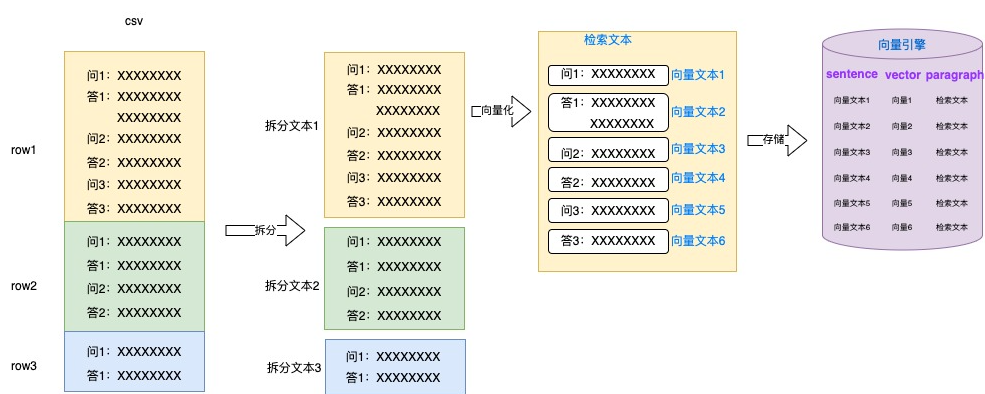
A través de medidas como la separación manual de bloques lógicos, vectores de texto de grano fino y recuperación de texto de grano grueso, la precisión de la recuperación de texto relevante ha mejorado considerablemente.
2. ¿Cómo evaluar si la salida de respuesta del modelo de lenguaje grande es inventada?
Para evaluar si la respuesta es confiable mediante el cálculo de la confianza de la respuesta, las dimensiones calculadas incluyen los siguientes tres aspectos:
Calcule la similitud entre la pregunta y la respuesta. Por lo general, la similitud entre la respuesta y la pregunta generada por el modelo de lenguaje grande es relativamente alta. Ocasionalmente, la similitud es relativamente baja. En este caso, es probable que la respuesta sea irrelevante para la pregunta, y ocasionalmente la similitud es muy En el caso de alto, el texto de respuesta es básicamente una repetición del texto de pregunta, y la respuesta en este caso no se puede usar.
Calcula la similitud del texto de respuesta con el texto relacionado utilizado para la inferencia por el modelo grande. Si la similitud entre el texto de respuesta y el texto relevante utilizado por la inferencia del modelo grande es baja, es probable que el modelo fabrique el texto de respuesta.
Calcule la tasa de coincidencia de la lista de texto relevante recordada por el texto de respuesta en la base de datos y la lista de texto relevante recordada por el texto de pregunta en la base de datos. Si la tasa de coincidencia de las 2 listas es baja, la confianza de la respuesta también lo será.
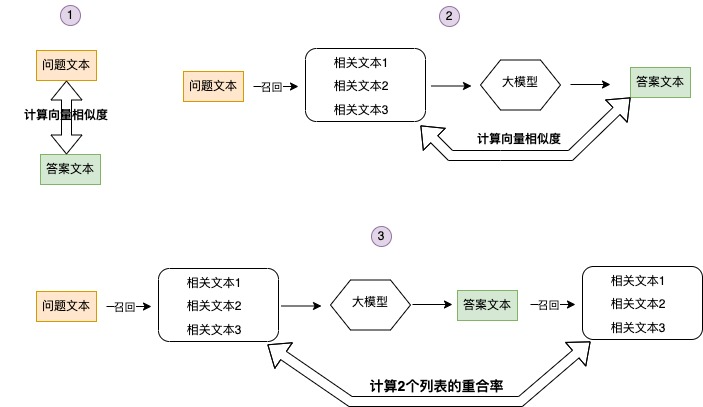
Ajuste razonablemente los umbrales de las tres puntuaciones según diferentes escenarios para juzgar si la respuesta es convincente.
Resumir
En la actualidad, además de la implementación de la industria del comercio electrónico presentada anteriormente, la guía de solución de mejora del modelo de lenguaje grande basada en la búsqueda inteligente integrada de LangChain tiene casos de aterrizaje en las industrias de fabricación, finanzas, educación y medicina. la solución se ha integrado con los servicios de Amazon Kendra, preste atención a nuestro próximo blog de seguimiento para obtener más detalles.
El autor de este artículo

él bo
Arquitecto de soluciones de la industria de la tecnología en la nube de Amazon, trabajó en Ali durante seis años, responsable del desarrollo de algoritmos de recomendación, algoritmos de búsqueda y algoritmos de coincidencia multimodal, y tiene una amplia experiencia en la aplicación de modelos de aprendizaje automático en varios escenarios en el comercio electrónico. industria.

Ji Jun Xiang
Arquitecto sénior de soluciones de Amazon Cloud Technology, responsable del diseño e implementación de extremo a extremo de escenarios innovadores en el equipo de creación rápida de prototipos.

tian bing
El científico de aplicaciones de tecnología en la nube de Amazon se ha dedicado durante mucho tiempo a la investigación y el desarrollo del procesamiento del lenguaje natural, la visión por computadora y otros campos. Admite proyectos de laboratorio de datos y tiene una rica experiencia en algoritmos e implementación en modelos de lenguaje grandes, detección de objetos, etc.

zhenghao
Especialista en IA/ML de Amazon GCR SA. Centrarse principalmente en el entrenamiento y el razonamiento del modelo de lenguaje, los algoritmos de búsqueda e inferencia y la optimización relacionada y la construcción de programas basados en la pila de tecnología Amzon AI/ML. En Ali, Ping An tiene muchos años de experiencia en investigación y desarrollo de algoritmos.


Escuché, haga clic en los 4 botones a continuación
¡No encontrarás errores!
