prefacio
Lo presentamos en la publicación de blog anterior Focal Loss, y el principio es relativamente simple. Si no lo entiende, puede saltar a la publicación de blog anterior para obtener más información. Introducción a la Pérdida Focal . Echemos un vistazo a la fuente de esta publicación de blog Focal Loss: Pérdida focal para la detección de objetos densosRetainNet , este documento propone una red one-stageque ha sido superada por la red two-stage.
1. Red RetainNet
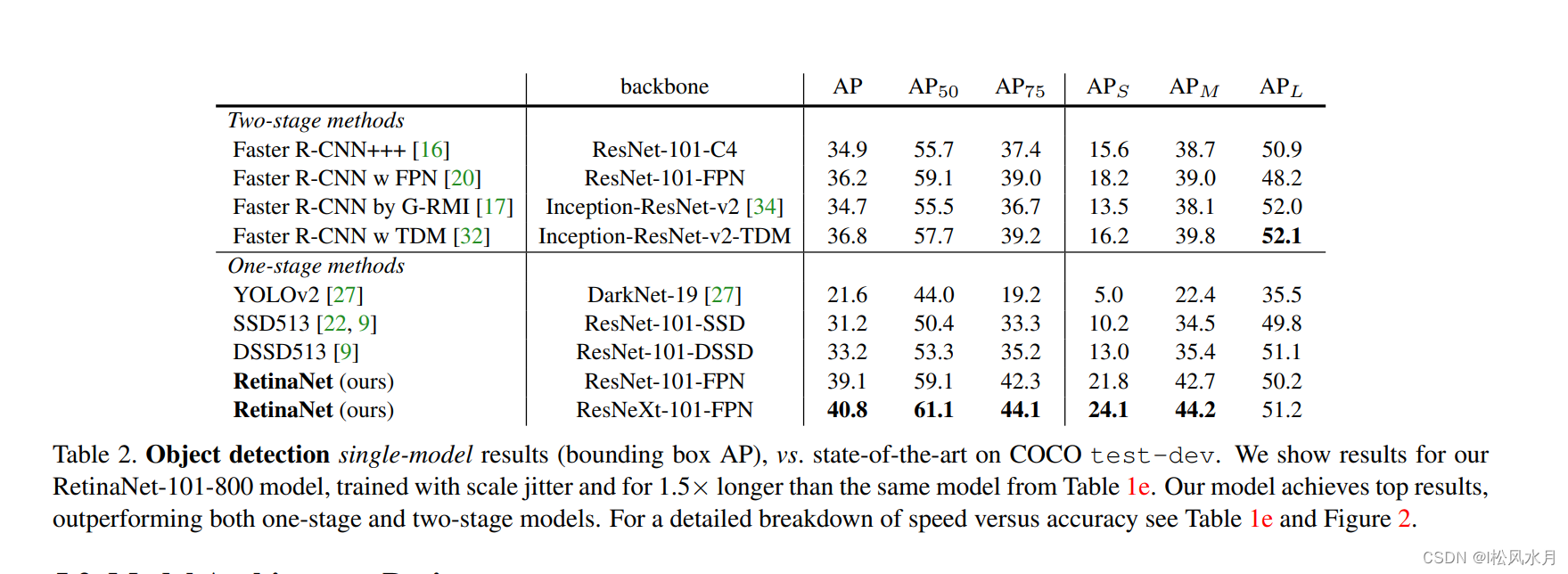
Veamos primero el rendimiento RetainNet, y se puede ver que es muy superior Faster R-CNNa la red. Echemos un vistazo a la estructura de la red
nuevamente : podemos ver que se adopta una estructura similar , con tres diferencias principales. Para aquellos que no lo saben, pueden saltar a mi publicación de blog anterior ( introducción a la red FPN ):RetainNet

RetainNetFPNFPN
FPNSe utilizanC2compilacionesP2,RetainNetno se utilizanC2compilacionesP2. La razón dada en el documento es queC2se calcularán más recursos informáticos. Debido aC2las cuatro características de bajo nivel, la resolución es relativamente grande.FPNinP6es muestreado por una capa de muestreado de escala máxima, yRetainNet es muestreado por una capa convolucional.FPNEs deP2-P6, RetainNet es deP3-P7,P7seP6basa en una función de activaciónReLU y luego se obtiene a través de una convolución.
En FPN, cada capa de características de predicción solo usa uno scaley tres ratios, y RetainNecada capa de características de predicción en t usa tres scaley tres ratios. RetainNeten scaley ratios如la siguiente tabla:
| capas | paso | ancla_tamaños | relaciones_de_aspecto_de_anclaje | El número de anclas generadas (multiplicado por 3 significa 3 proporciones) |
|---|---|---|---|---|
| P2 | 4(2 ( ^)2) | 32 | 0.5,1,2 | (1024//4) ( ^)2×3=196608 |
| P3 | 8(2 ( ^)3) | 64 | 0.5,1,2 | (1024//8) ( ^)2xx3=49152 |
| P4 | 16(2 ( ^)4) | 128 | 0.5,1,2 | (1024//16)^^2xx3=12288 |
| P5 | 32(2 ( ^)5) | 256 | 0.5,1,2 | (1024//32) ( ^)2xx3=3072 |
| P6 | 64(2 ( ^)6) | 512 | 0.5,1,2 | (1024//64) ( ^)2×3=768 |
Veamos nuevamente la parte del predictor de RetainNet:
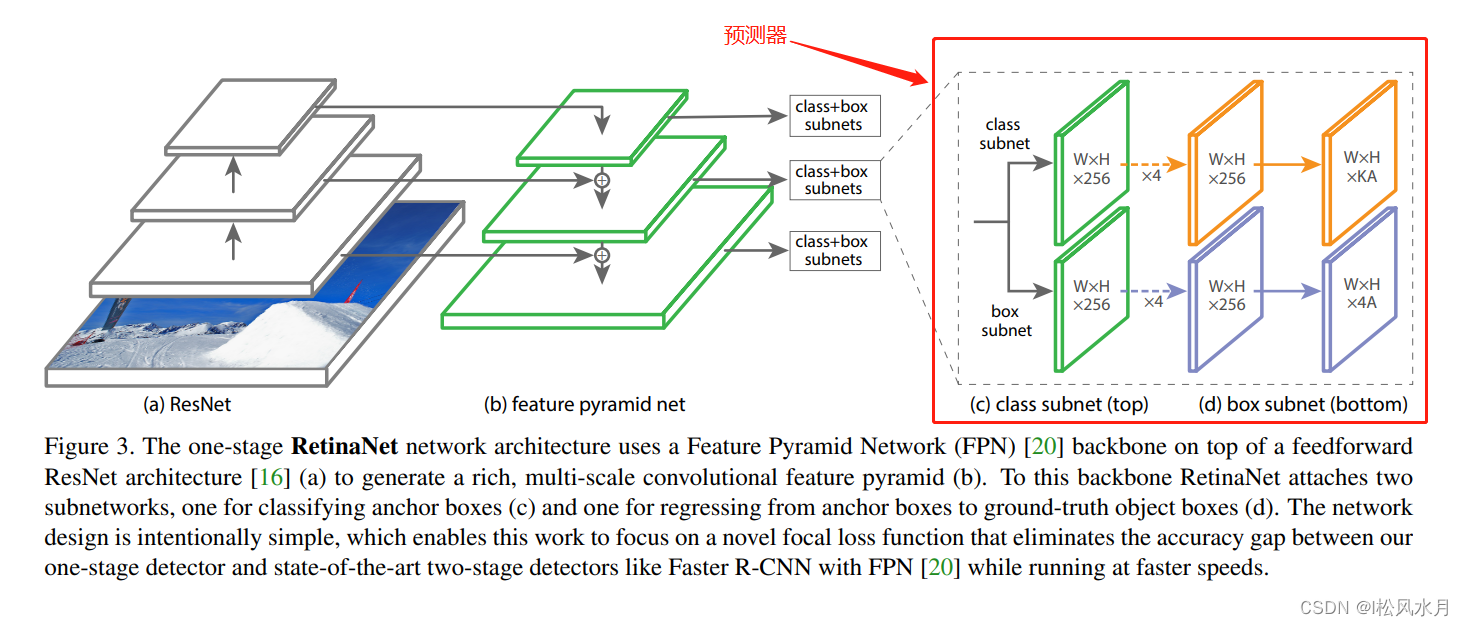
el predictor se divide en dos ramas, una predice la categoría y la otra es el parámetro de regresión del cuadro delimitador de destino. El resultado final K representa el número de categorías de objetivos de detección (excluyendo el fondo) y A representa anchorel número de cada capa de características de predicción. En FasterRCNNel medio, para la capa de predicción, cada uno anchorgenerará un conjunto de parámetros de regresión de cuadro delimitador para cada categoría, que es ligeramente diferente de la predicción aquí, y es lo mismo aquí SSD, y ahora las muestras básicamente no están disponibles para esta categoría El método de predicción conocido puede reducir los parámetros de entrenamiento de la red.
2. Cálculo de pérdidas
En primer lugar, realizaremos un partido, es decir, un cálculo, para cada uno de anchornuestros gt premarcados, ioulas reglas son las siguientes:
- Si iu >= 0,5 iu >=0,5yo o tu>=0.5 , marcado como muestra positiva
- iu < = 0,4 iu<=0,4yo o tu<=0.4 , marcado como una muestra negativa
- you ∈ [ 0.4 , 0.5 ) you \in[0.4, 0.5)yo o tu∈[ 0.4 ,0.5 ) , descartar
La pérdida total todavía usa la pérdida de clasificación y la pérdida de regresión, como sigue:
Loss = 1 NPOS ∑ i L clsi + 1 NPOS ∑ j L regj \text { Loss } =\frac{1}{N_{POS}} \sum_i L_ { cls}^i+\frac{1}{N_{POS}} \sum_j L_{reg}^j Pérdida =nortepunto de venta1i∑Lc l syo+nortepunto de venta1j∑Lre gj
- L cls L_{cls}Lc l s: Sigmoid Focal Loss, lo presentamos en la última publicación del blog, si no lo entiende, puede regresar y ver: Introducción a Focal Loss .
- L reg L_{reg}Lre _:Pérdida L1
- yoi : todas las muestras positivas y negativas
- ni una palabraj : todas las muestras positivas
- N posición N_{posición}nortepos _: el número de muestras positivas
Lo anterior es RetainNetla introducción sobre la red, si hay algún error, ¡corríjame!