Regularización - penalización de norma de parámetro
regularizaciónLa definición de: "Una modificación del algoritmo de aprendizaje, dirigida a reducir el error de generalización en lugar del error de entrenamiento."
Comprensión intuitiva: la regularización es una estrategia utilizada para reducir el sobreajuste del modelo.
Lo que sigue es uno de los métodos más comunes de regularización - L 1 L^1 sobre el peso del modeloL1 yL 2 L ^ 2L2 regularización.
Así llamadoL 1 L ^ 1L1 yL 2 L ^ 2L2 regularización, en realidad usa L 1 L^1L1 yL 2 L ^ 2L2 norma, para normalizar los parámetros del modelo (pesowww ) de un método.
Norma, podemos entenderlo como una extensión del concepto de distancia entre dos puntos en el espacio. Por ejemplo peso www , es un vector de alta dimensión, y también puede entenderse como un punto en el espacio.La distancia de este al origen, si es la distancia de Manhattan, es L 1 L^1L1 norma, si es distancia euclidiana, esL 2 L^2L2 norma.
- L 0 L ^ 0L0 norma: el número de elementos distintos de cero en el vector.
- L 1 L ^ 1L1范数:∣ ∣ W ∣ ∣ 1 = ∣ w 1 ∣ + ∣ w 2 ∣ + . . . + ∣ wi ∣ ||W||_1 = |w_1| + |w_2| + ... + |w_i|∣∣ W ∣ ∣1=∣ w1∣+∣ w2∣+...+∣ wyo∣ (distancia Manhattan)
- L 2 L ^ 2L2范数:∣ ∣ W ∣ ∣ 2 = ∣ w 1 ∣ 2 + ∣ w 2 ∣ 2 + . . . + ∣ wi ∣ 2 ||W||_2 = \sqrt{|w_1|^2 + |w_2|^2 + ... + |w_i|^2}∣∣ W ∣ ∣2=∣ w1∣2+∣ w2∣2+...+∣ wyo∣2(Distancia euclidiana)


Porque es el peso ww lo que realmente provoca el problema de sobreajustew , por simplicidad, en la siguiente discusión, solo nos enfocamos enwww _
1. Regularización de parámetros L2
L 2 L ^ 2LLa regularización de 2 parámetros a menudo se denominacaída de pesoy funciona agregando un término de regularizaciónΩ ( θ ) = 1 2 ∣ ∣ w ∣ ∣ 2 2 \Omega(\theta) = \frac{1}{2}||\pmb{w}||^2_2 a la función objetivoΩ ( θ )=21∣∣ww ∣ ∣22, acercando los pesos al origen.
Así que aquí viene la pregunta: L 2 L^2L¿Por qué la regularización de 2 parámetros se llama decaimiento de peso? ¿Cómo atenuó el peso?
Función de pérdida: J ( w , b ) J(\pmb{w}, b)J (ww ,b )
Actualización del peso:w = w − ϵ ⋅ ▽ w J ( w ) \pmb{w} = \pmb{w} -\epsilon\cdot\bigtriangledown_w{J(\pmb{w})}ww=ww−ϵ⋅▽wJ (ww )
Para la función de pérdidaJ ( W , b ) J(W, b)J ( W ,b ) , queremos encontrar un conjunto de parámetros( w ∗ , b ∗ ) (\pmb{w}^*, b^*)(ww∗ ,b∗ )来 minimizarJ ( w , b ) J(\pmb{w}, b)J (ww ,b ) _
Por simplicidad, solo consideramos el peso www , entonces la función objetivo del modelo es:
J ~ ( w ; X , y ) = α 2 w T w + J ( w ; X , y ) \widetilde{J}(\pmb{w}; \pmb{X}, \pmb{y}) = \frac{\alpha}{2}w^Tw + J(\pmb{w}; \pmb{X}, \pmb{y })j
(ww ;Xx ,yy )=2awT w+J (ww ;Xx ,yy ) donde,α ∈ [ 0 , ∞ ) \alpha \in [0, \infty)a∈[ 0 ,∞ ) se llamatasa de descomposición, es el término de penalización de la norma de compensación Ω \OmegaΩ y función objetivo estándarJJHiperparámetros para la contribución relativa de J. seráα \alphaα se establece en 0 para indicar que no hay regularización;α \alphaCuanto mayor sea α , mayor será la sanción de regularización correspondiente. Durante el proceso de solución, escalamos el término de penalizaciónΩ \OmegaHiperparámetroα \alpha de Ωα para controlarL 2 L^2L2 La fuerza de la caída del peso.
El gradiente correspondiente a la función objetivo es: ▽ w J ~ ( w ; X , y ) = α w + ▽ w J ( w ; X , y ) \bigtriangledown_w\widetilde{J}(\pmb{w}; \pmb{X}, \pmb{y}) =\alpha w + \bigtriangledown_wJ(\pmb{w}; \pmb{X} , \pmb{y})▽wj (ww ;Xx ,yy )=una w+▽wJ (ww ;Xx ,yy )
Use el descenso de gradiente de un paso para actualizar los pesos: w ← w − ϵ ( α w + ▽ w J ( w ; X , y ) ) w \leftarrow w - \epsilon(\alpha w + \bigtriangledown_wJ(\pmb{w}; \pmb{X}, \pmb{y}))w←w−ϵ ( α w+▽wJ (ww ;Xx ,yy ))
可种写法是:w ← ( 1 − ϵ α ) w − ϵ ▽ w J ( w ; X , y ) w \leftarrow (1 - \epsilon\alpha)w - \epsilon\bigtriangledown_wJ(\pmb{w}; \pmb{X}, \pmb{y})w←( 1−ϵ a ) w−ϵ▽wJ (ww ;Xx ,yy )
Podemos ver que la adición de la disminución de peso provocará la modificación de las reglas de aprendizaje, y el vector de peso se reducirá antes de que se realice cada actualización de gradiente.
De esta forma, para la atenuación del peso, podemos entenderlo intuitivamente como: la atenuación del peso consiste en agregar algunos elementos de penalización para castigar el peso y castigar un poco por cada aprendizaje, para que el peso no sea demasiado grande.
La introducción anterior es L 2 L^2L2. La influencia de la regularización en los pesos en el descenso de gradiente de un solo paso, entonces, ¿qué tipo de influencia tendrá en el proceso general de entrenamiento?
En primer lugar, debemos aclarar nuestro objetivo.Nuestro objetivo es controlar los parámetros para que el valor del parámetro no sea demasiado grande. Siguiendo esta línea de pensamiento, podemos darwww define un dominio factible, seawwW toma valores en esta zona.
Región factible: ∣ ∣ w ∣ ∣ 2 − C ≤ 0 ||\pmb{w}||_2 - C \leq 0∣∣ww ∣ ∣2−C≤0 (es decir,w \pmb{w}wLa distancia desde el punto correspondiente a w en el espacio al origen es≤ C \leq C≤C 's. )
A continuación, entendemos L 2 L^2 desde la perspectiva del método del multiplicador de LagrangeL2 El efecto de la regularización en el proceso formativo global.
Podemos escribir la función objetivo como:J ~ ( w , λ ) = J ( w ) + λ ( ∣ ∣ w ∣ ∣ 2 − C ) \widetilde{J}(\pmb{w},\lambda) = J(\pmb{w}) + \lambda(||\pmb{w}||_2 - C)j
(ww ,yo )=J (ww )+λ ( ∣∣ww ∣ ∣2−c )
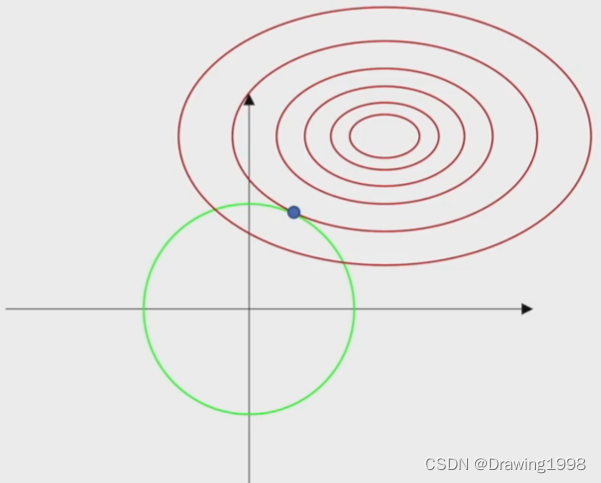
En esta figura, la línea roja es la línea de contorno de la función de pérdida, y la línea verde es lo que le damos a wwEl rango de dominio factible definido por w .
- CC en la función objetivoC determina el peso que le damos awwEl tamaño del rango de dominio factible definido por w ;
- λ \lambdaλ es el multiplicador de Lagrange, y su función es ajustar el gradiente correspondiente a la condición de restricción para que sea igual al gradiente de la función de pérdida.

De esta imagen podemos ver claramente que a través de L 2 L^2L2 norma para limitar los pesoswwEl rango de valores de w puede evitar wwEl valor de w es demasiado grande para reducir el fenómeno de sobreajuste del modelo.
Porque L 2 L ^ 2LLa región factible correspondiente a la norma 2 es un conjunto convexo, y el método de descenso de gradiente también es un método de optimización convexo, por lo que usamosL 2 L^2L2 norma parwww está restringido, el problema que queremos resolver sigue siendo un problema de optimización convexo.
Podemos pensar en la penalización de la norma del parámetro como una restricción impuesta a los pesos.
Supongamos que encontramos el valor óptimo de la tasa de decaimiento α ∗ \alpha ^*a∗ , por lo general no conocemos el coeficiente de decaimiento del peso (es decir, la tasa de decaimientoα ∗ \alpha ^*a∗ ) tamaño de región restringido, porqueα ∗ \alpha ^*aEl valor de ∗ no puede decirnos directamenteCCvalor de c En principio podemos resolverCCC , peroCCC yα ∗ \alpha ^*a∗ La relación entre depende deJJforma de j
Aunque no conocemos el tamaño exacto de la región restringida, se puede determinar aumentando o disminuyendoα \alphaα para expandir o contraer aproximadamente la región restringida. α \alphamás grandeα , obtendrá una región restringida más pequeña,α \alphaα , se obtendrá una región restringida más grande.
A veces queremos usar límites explícitos en lugar de penalizaciones. Por ejemplo, podemos modificar el algoritmo de descenso (como el algoritmo de descenso de gradiente estocástico) para que primero calculeJ ( θ ) J(\theta)El paso descendente de J ( θ ) , entoncesθ \thetaθ se proyecta para satisfacerΩ ( θ ) < C \Omega(\theta) < CΩ ( θ )<El punto más cercano de C. Si sabemos qué tipo deCCC es adecuado, y no quiero perder el tiempo buscandoCCα \ alfade Cvalor alfa , esto puede ser muy útil.
Extracto de la Sección 7.2 de "Aprendizaje profundo"
2. Regularización de parámetros L1
con L 2 L ^ 2L2 La regularización es similar, usandoL 1 L^1L1 Cuando la regularización decae el peso, también escalamos el término de penalizaciónΩ \OmegaHiperparámetroα \alpha de Ωα para controlarL 1 L^1L1 La fuerza de la caída del peso.
Término de penalizaciónΩ \OmegaΩ se puede expresar como:Ω = ∣ ∣ w ∣ ∣ 1 = ∑ ∣ wi ∣ \Omega = ||w||_1 = \sum|w_i|Oh=∣∣ w ∣ ∣1=∑∣ wyo∣
La función objetivo del modelo se puede expresar como:
J ~ ( w ; X , y ) = α ∣ ∣ w ∣ ∣ 1 + J ( w ; X , y ) \widetilde{J}(\pmb{w}; \pmb{X}, \pmb{y}) = \alpha ||\pmb{w}||_1 + J(\pmb{w}; \pmb{X}, \ pmb{ y})j
(ww ;Xx ,yy )=α∣∣ _ww ∣ ∣1+J (ww ;Xx ,yy )
Gradiente correspondiente: (en realidad subgradiente)
▽ w J ~ ( w ; X , y ) = α sign ( w ) + ▽ w J ( w ; X , y ) \bigtriangledown_w\widetilde{J}(\pmb{w}; \pmb{X}, \pmb{y}) =\alpha sign(\pmb{w}) + \bigtriangledown _wJ(\pmb{w}; \p mb{X}, \pmb{y})▽wj
(ww ;Xx ,yy )=α s i g n (ww )+▽wJ (ww ;Xx ,yy ) dondesigno ( w ) signo(\pmb{w})firmar ( _ _ _ww ) simplemente tomawwEl signo de cada elemento de w .
Use el descenso de gradiente de un paso para actualizar los pesos: w ← w − ϵ ( α sign ( w ) + ▽ w J ( w ; X , y ) w \leftarrow w - \epsilon(\alpha sign(\pmb{w}) + \bigtriangledown_wJ(\pmb{w}; \pmb{X}, \pmb{y})w←w−ϵ ( α s yo gramo norte (ww )+▽wJ (ww ;Xx ,yy )
可种写法是:w ← w − ϵ α sign ( w ) − ϵ ▽ w J ( w ; X , y ) w \leftarrow w - \epsilon\alpha sign(\pmb{w}) - \epsilon\bigtriangledown_wJ(\pmb{w}; \pmb{X}, \pmb{y})w←w−ϵ α s yo gramo norte (ww )−ϵ▽wJ (ww ;Xx ,yy )
Podemos ver que L 1 L^1L1 El efecto de la regularización yL 2 L^2L2 no es lo mismo,L 2 L^2L2 La regularización eswww escala linealmente, yL 1 L^1L1 regularización es agregar unsigno ( w ) sign(\pmb{w})firmar ( _ _ _ww ) constantes del mismo signo.
Los modelos lineales simples tienen una función de costo cuadrática, que podemos representar mediante la serie de Taylor.
Suponemos que el gradiente correspondiente a la función objetivo es la etapa de la serie de Taylor que se aproxima a la función de costo de un modelo más complejo, entonces el gradiente se puede escribir como: ▽ w J ~ ( w ) = H ( w − w ∗ ) \bigtriangledown_w\widetilde{J}(\pmb{w}) = H(w - w^* )▽wj
(ww )=alto ( ancho−w∗ )
Entre ellos,HHH es la función de pérdidaJJJ enw ∗ w ^ *wLa matriz hessianaen ∗ .
Suponemos que la arpillera es diagonal y que los datos de entrada del modelo se han procesado previamente para eliminar la correlación entre las características de entrada. Entonces podemos simplemente poner L 1 L^1L1 La aproximación cuadrática de la función objetivo regularizada se descompone en una suma sobre los parámetros:
J ~ ( w ; X , y ) = J ( w ∗ ; X , y ) + ∑ [ 1 2 H i , i ( wi + wi ∗ ) 2 + α ∣ wi ∣ ] \widetilde{J}(\pmb{w}; \pmb{X}, \p mb{y}) =J(\ pmb{w}^*; \pmb{X}, \pmb{y}) + \sum[\frac{1}{2}H_{i,i}(w_i + w^*_i)^2 + \alpha|w_i|]j
(ww ;Xx ,yy )=J (ww∗ ;Xx ,yy )+∑ [21Hyo , yo( wyo+wi∗)2+α ∣ wyo∣ ]
La solución analítica de la función (para cada dimensióniii)可以表示为:
wi = signo ( wi ∗ ) max ( ∣ wi ∗ ∣ − α H i , i , 0 ) w_i = signo(w^*_i)max(|w^*_i| - \frac{\alpha}{H_{i,i}}, 0)wyo=firmar ( w _ _ _i∗) máximo x ( ∣ wi∗∣−Hyo , yoa,0 )
Hay dos resultados posibles:
- ∣ wi ∗ ∣ − α H yo , yo ≤ 0 |w^*_i| - \frac{\alpha}{H_{i,i}} \leq 0∣ wi∗∣−Hyo , yoa≤Cuando 0 , wi w_ien la función objetivo después de la regularizaciónwyoEl valor óptimo de es wi = 0 w_i = 0wyo=0 ,L1 L^1L1 plazo de regularización willwi w_iwyoempujado a 0, de modo que el iiLas contribuciones de las funciones i se cancelarán.
- ∣ wi ∗ ∣ − α H yo , yo ≥ 0 |w^*_i| - \frac{\alpha}{H_{i,i}} \geq 0∣ wi∗∣−Hyo , yoa≥0 ,L 1 L ^ 1L1 El plazo de regularización no cambiaráwi w_iwyoempujado a 0, pero solo en wi w_iwyoMuévete en la dirección de α H i , i \frac{\alpha}{H_{i,i}}Hyo , yoadistancia.
De esta manera, después de L 1 L^1L1 Después de la regularización obtendremos una solución másescasa(escasa), por lo queL 1 L^1L1 La regularización también se usa ampliamente ende características.
A continuación, analizamos L 1 L^1L1 La influencia de la regularización en el proceso global de formación:
conL 2 L^2L2 La regularización es similar, damoswww define un dominio factible, seawwW toma valores en esta zona.
Región factible: ∣ ∣ w ∣ ∣ 1 − C ≤ 0 ||\pmb{w}||_1 - C \leq 0∣∣ww ∣ ∣1−C≤0 (es decir,w \pmb{w}wLa distancia desde el punto correspondiente a w en el espacio al origen es≤ C \leq C≤C 's. )

En esta figura, la línea roja es la línea de contorno de la función de pérdida, y la línea verde es lo que le damos awwEl rango de dominio factible definido por w .
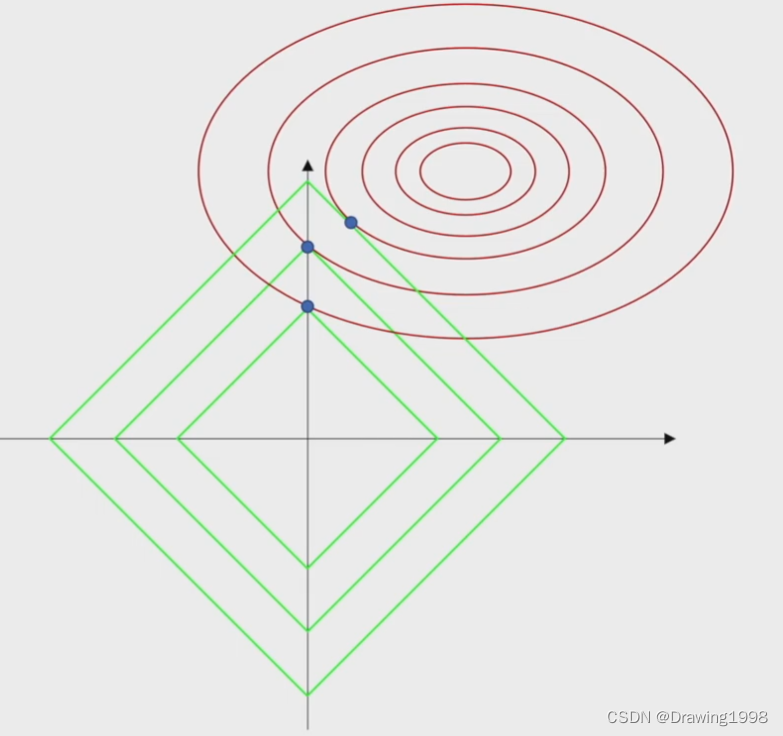
De esta figura también podemos ver que L 1 L^1L1 Regularización El punto donde el rango definido por el parámetro es tangente a la línea de contorno de la función de pérdida es más probable que esté en el eje de coordenadas, lo que hará que el peso seawwAlgunos elementos de w tienen valores, y algunos elementos son 0, lo que hará que solo funcione una parte de las funciones de entrada, no todas las funciones.
3. Penalización de norma de parámetro
Para resumir la discusión anterior: la estrategia de regularización basada en la norma de parámetro penalización se pasa a la función objetivo JJJAgregar un término de penalizaciónΩ ( θ ) \Omega(\theta)Ω ( θ ) para limitar la capacidad de aprendizaje del modelo, reduciendo así la aparición del fenómeno de sobreajuste.
Denotamos la función objetivo regularizada comoJ ~ \widetilde{J}j
:
J ~ ( w ; X , y ) = J ( w ; X , y ) + α Ω ( θ ) \widetilde{J}(\pmb{w}; \pmb{X}, \pmb{y}) = J(\pmb{w}; \pmb{X}, \pmb{y}) + \alpha\Omega(\theta)j
(ww ;Xx ,yy )=J (ww ;Xx ,yy )+α Ω ( θ ) entre ellos,α ∈ [ 0 , ∞ ) \alpha \in [0, \infty)a∈[ 0 ,∞ ) se denomina tasa de atenuación, que es el término de penalización de la norma de compensaciónΩ \OmegaΩ y función objetivo estándarJJHiperparámetros para la contribución relativa de J. seráα \alphaα se establece en 0 para indicar que no hay regularización;α \alphaCuanto mayor sea α , mayor será la sanción de regularización correspondiente. Durante el proceso de solución, escalamos el término de penalizaciónΩ \OmegaHiperparámetroα \alpha de Ωα para controlarL 2 L^2L2 La fuerza de la caída del peso.
En el caso de las redes neuronales, a veces es deseable usar una penalización separada para cada capa y asignar un α \alpha diferentecoeficiente alfa . Dado que encontrar los hiperparámetros múltiples correctos es costoso, para reducir el espacio de búsqueda usamos el mismo decaimiento de peso en todas las capas.