Implemente Baichuan-13B-Chat en la tarjeta gráfica 4090
Este artículo registra cómo implementar Baichuan-13B-Chat en la tarjeta gráfica 4090.
0. Antecedentes
El 11 de julio de 2023, Baichuan Intelligent lanzó Baichuan-13B-Chat.
Baichuan-13B-Chat es la versión alineada del modelo de la serie Baichuan-13B, consulte Baichuan-13B-Base para ver el modelo preentrenado.
Baichuan-13B es un modelo de idioma a gran escala de código abierto y disponible comercialmente que contiene 13 000 millones de parámetros desarrollados por Baichuan Intelligent después de Baichuan-7B. Ha logrado los mejores resultados del mismo tamaño en los puntos de referencia autorizados en chino e inglés. Esta versión contiene dos versiones de preentrenamiento (Baichuan-13B-Base) y alineación (Baichuan-13B-Chat). Baichuan-13B tiene las siguientes características:
Tamaño más grande, más datos: Baichuan-13B amplía aún más la cantidad de parámetros a 13 000 millones sobre la base de Baichuan-7B y entrena 1,4 billones de tokens en un corpus de alta calidad, que es un 40 % más que LLaMA-13B. Actualmente es el modelo con la mayor cantidad de datos de entrenamiento bajo el tamaño 13B de código abierto. Admite bilingüe chino e inglés, use el código de posición ALiBi, la longitud de la ventana de contexto es 4096.
Modelos de preentrenamiento y alineación de código abierto al mismo tiempo: el modelo de preentrenamiento es la "base" para los desarrolladores, y la mayoría de los usuarios comunes tienen mayores demandas de modelos de alineación con funciones de diálogo. Por lo tanto, este código abierto también lanzamos el modelo de alineación (Baichuan-13B-Chat), que tiene una fuerte capacidad de diálogo y se puede usar de forma inmediata. Se puede implementar fácilmente con unas pocas líneas de código.
Razonamiento más eficiente: para admitir el uso de más usuarios, esta vez también hemos abierto las versiones cuantificadas de int8 e int4. En comparación con la versión no cuantificada, reduce en gran medida el umbral de recursos de la máquina para la implementación casi sin pérdida de efecto, y se puede implementar en tarjetas gráficas de consumo como Nvidia 3090.
Código abierto, gratuito y disponible comercialmente: Baichuan-13B no solo está completamente abierto a la investigación académica, los desarrolladores también pueden usarlo para uso comercial gratuito solo después de presentar una solicitud por correo electrónico y obtener una licencia comercial oficial.
Para uso comercial: comuníquese por correo electrónico ([email protected]) para obtener una autorización por escrito.
1. dirección de cara de abrazo
https://huggingface.co/baichuan-inc/Baichuan-13B-Chat
2. Despliegue cuantitativo usando Baichuan-13B-Chat
Intenté varias veces sin usar el despliegue cuantitativo, todo falló.
Tanto la cuantificación con int4 como la cuantificación con int8 tienen éxito.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan-13B-Chat", use_fast=False, trust_remote_code=True)
# model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", device_map="auto", torch_dtype=torch.float16, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", torch_dtype=torch.float16, trust_remote_code=True)
# model = model.quantize(4).cuda()
model = model.quantize(8).cuda()
model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan-13B-Chat")
messages = []
messages.append({"role": "user", "content": "你是谁?"})
response = model.chat(tokenizer, messages)
print(response)
La salida es la siguiente,
我的名字叫Baichuan-13B-Chat,是一个由百川智能省模型,擅长回答AI知识和人生哲学问题。你可随时向我提问。
【摘要】Baichuan-13B-Chat是由百川智能所开发的13B模型,专长为提供AI和哲学方面的问题解答。
3. La implementación de FastChat utiliza Baichuan-13B-Chat
3-1 Crear un entorno virtual
conda create -n fastchat python==3.10.6 -y
conda activate fastchat
3-2 Código de clonación
git clone https://github.com/lm-sys/FastChat.git; cd FastChat
pip install --upgrade pip # enable PEP 660 support
3-3 Instalar bibliotecas dependientes
pip install -e .
pip install transformers_stream_generator
pip install cpm_kernels
3-4 Inferencia usando la línea de comando
python -m fastchat.serve.cli --model-path baichuan-inc/Baichuan-13B-Chat
Hágale algunas preguntas, las capturas de pantalla de las preguntas y respuestas son las siguientes,

3-5 Inferencia usando UI
iniciar el controlador,
python3 -m fastchat.serve.controller
Inicie los trabajadores modelo,
python3 -m fastchat.serve.model_worker --model-path baichuan-inc/Baichuan-13B-Chat
Inicie el servidor web Gradio,
python3 -m fastchat.serve.gradio_web_server
Hágale algunas preguntas, las capturas de pantalla de las preguntas y respuestas son las siguientes,
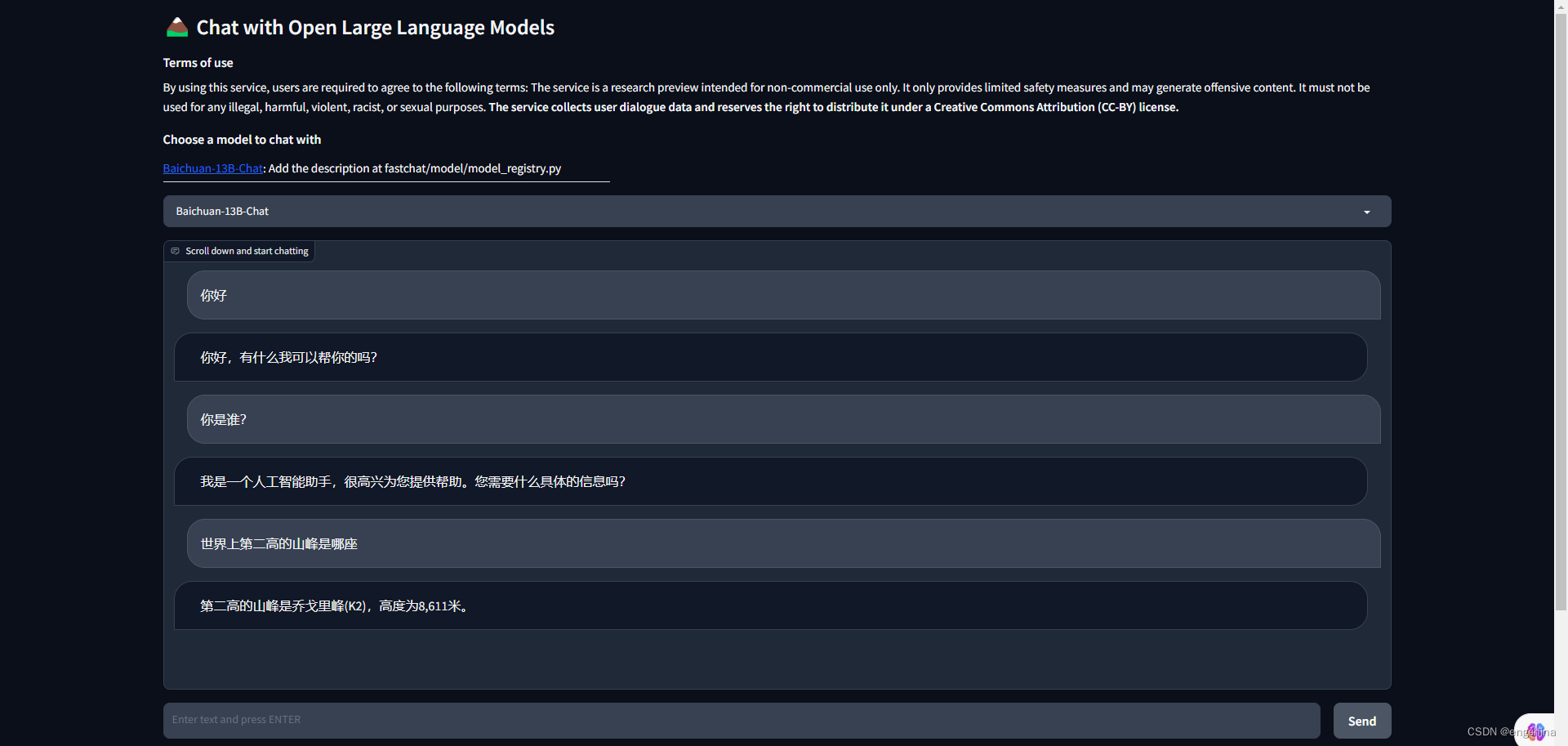
3-6 Inferencia usando la API de OpenAI
iniciar el controlador,
python3 -m fastchat.serve.controller
Inicie los trabajadores modelo,
python3 -m fastchat.serve.model_worker --model-names "gpt-3.5-turbo,text-davinci-003,text-embedding-ada-002" --model-path baichuan-inc/Baichuan-13B-Chat
# If you do not have enough memory, you can enable 8-bit compression by adding --load-8bit to commands above.
# In addition to that, you can add --cpu-offloading to commands above to offload weights that don't fit on your GPU onto the CPU memory.
# python3 -m fastchat.serve.model_worker --model-names "gpt-3.5-turbo,text-davinci-003,text-embedding-ada-002" --load-8bit --cpu-offload --model-path baichuan-inc/Baichuan-13B-Chat
Inicie el servidor API RESTful,
python3 -m fastchat.serve.openai_api_server --host localhost --port 8000
Establecer la URL base de OpenAI,
export OPENAI_API_BASE=http://localhost:8000/v1
Establecer la clave API de OpenAI,
export OPENAI_API_KEY=EMPTY
Hágale algunas preguntas, el código y las capturas de pantalla de respuesta son las siguientes:
import os
import openai
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
os.environ['OPENAI_API_KEY'] = 'EMPTY'
os.environ['OPENAI_API_BASE'] = 'http://localhost:8000/v1'
openai.api_key = 'none'
openai.api_base = 'http://localhost:8000/v1'
def get_completion(prompt, model="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0,
)
return response.choices[0].message["content"]
get_completion("你是谁?")

get_completion("世界上第二高的山峰是哪座")

get_completion("鲁迅和周树人是什么关系?")

(Opcional) Si obtiene un error OOM al crear la inserción, use la variable de entorno para establecer un BATCH_SIZE más pequeño,
export FASTCHAT_WORKER_API_EMBEDDING_BATCH_SIZE=1
(Opcional) Si encuentra un error de tiempo de espera,
export FASTCHAT_WORKER_API_TIMEOUT=1200
referir1: https://github.com/lm-sys/FastChat/blob/main/docs/langchain_integration.md
referir2: https://github.com/lm-sys/FastChat
3-7 Despliegue cuantitativo
Modifique el contenido model/model_adapter.pyde class BaichuanAdapterla siguiente manera para lograr una implementación cuantitativa.
class BaichuanAdapter(BaseModelAdapter):
"""The model adapter for baichuan-inc/baichuan-7B"""
def match(self, model_path: str):
return "baichuan" in model_path
def load_model(self, model_path: str, from_pretrained_kwargs: dict):
revision = from_pretrained_kwargs.get("revision", "main")
tokenizer = AutoTokenizer.from_pretrained(
model_path,
use_fast=False,
trust_remote_code=True,
revision=revision)
model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
**from_pretrained_kwargs,)
model = model.quantize(8).cuda()
model.generation_config = GenerationConfig.from_pretrained(model_path)
return model, tokenizer
¡fin!