Azure Data Lake Storage Gen2 se basa en Azure Blob Storage y es un conjunto de funcionalidades para el análisis de macrodatos.
Las características de Azure Data Lake Storage Gen1 y Azure Blob Storage se combinan en Data Lake Storage Gen2. Por ejemplo, Data Lake Storage Gen2 proporciona escala, seguridad a nivel de archivos y semántica del sistema de archivos. También obtendrá almacenamiento en niveles de bajo costo con características de alta disponibilidad y recuperación ante desastres porque están construidos sobre Blob Storage.
Especialmente desarrollado para el análisis de datos masivos de la empresa
Azure Storage es ahora el punto de partida para crear lagos de datos empresariales en Azure, gracias a Data Lake Storage Gen2. Data Lake Storage Gen2 se creó desde cero para admitir petabytes de datos y cientos de gigabytes de rendimiento, lo que le permite administrar fácilmente grandes cantidades de datos.
Ampliar el almacenamiento de blobs para incluir un espacio de nombres jerárquico es un componente clave de Data Lake Storage Generation 2. Para un acceso eficiente a los datos, los espacios de nombres jerárquicos agrupan objetos y archivos en jerarquías de carpetas. Las barras se utilizan a menudo en los nombres de los almacenes de objetos para simular una estructura de directorio jerárquica. La llegada de Data Lake Storage Gen2 ha hecho realidad este acuerdo. Las operaciones en directorios, incluido el cambio de nombre o la eliminación de directorios, se convierten en una única operación de metadatos atómicos. No es necesario enumerar y procesar todos los objetos que comparten un prefijo de nombre de directorio.
Blob Storage es la base de Data Lake Storage Generation 2, que mejora la administración, la seguridad y el rendimiento a través de:
actuación
El rendimiento se optimiza porque no es necesario copiar ni cambiar los datos antes del análisis. Además, los espacios de nombres jerárquicos en el almacenamiento de blobs realizan actividades de administración de directorios mucho mejor que los espacios de nombres planos, lo que mejora el rendimiento del trabajo.
administrar
La administración es aún más fácil ya que puede usar directorios y subdirectorios para organizar y administrar archivos.
Seguridad
La seguridad es aplicable ya que los permisos POSIX se pueden establecer en carpetas o archivos específicos .
Además, Data Lake Storage Gen2 es relativamente asequible porque se basa en el almacenamiento económico de Azure Blob. Las capacidades adicionales reducen el costo total de propiedad por usar Azure para realizar análisis de big data.
Características importantes de Data Lake Storage Generation 2
- Data Lake Storage Gen2 le permite organizar y acceder a los datos de una manera comparable a Hadoop Distributed File System (HDFS). Todas las configuraciones de Apache Hadoop admiten el nuevo controlador ABFS, que se utiliza para acceder a los datos. Azure HDInsight, Azure Databricks y Azure Synapse Analytics son algunos ejemplos de estos entornos.
- El modelo de seguridad de Data Lake Gen 2 admite ACL y permisos POSIX, así como otras granularidades exclusivas de Data Lake Storage Gen 2. Además, los marcos como Hive and Spark y Storage Explorer permiten ajustes de configuración.
- Rentable: Data Lake Storage Gen2 proporciona espacio de almacenamiento y transacciones de bajo costo. Con funciones como el ciclo de vida de Azure Blob Storage, los costos se reducen a medida que los datos avanzan a lo largo de su ciclo de vida.
- Optimización del controlador: el controlador ABFS está diseñado para el análisis de big data. El punto final dfs.core.windows.net expone la API REST correspondiente .
escalabilidad
Ya sea que se acceda a través de las interfaces de Data Lake Storage Gen 2 o Blob Storage, Azure Storage está diseñado para escalar. Puede almacenar y servir muchos exabytes de datos. El rendimiento de este volumen de almacenamiento se mide en gigabits por segundo (Gbps) en operaciones de entrada/salida altas por segundo (IOPS). La latencia de procesamiento se supervisa a nivel de servicio, cuenta y archivo, y permanece casi constante para cada solicitud. Ya sea que se acceda a través de las interfaces de Data Lake Storage Gen 2 o Blob Storage, Azure Storage está diseñado para escalar. Puede almacenar y servir muchos exabytes de datos. El rendimiento de este volumen de almacenamiento se mide en gigabits por segundo (Gbps) en operaciones de entrada/salida altas por segundo (IOPS). La latencia de procesamiento se supervisa a nivel de servicio, cuenta y archivo, y permanece casi constante para cada solicitud.
Rentabilidad
La capacidad de almacenamiento y los costos de transacción son más bajos porque Data Lake Storage Gen 2 se basa en Azure Blob Storage. A diferencia de otros proveedores de almacenamiento en la nube, no necesita trasladarse ni cambiar sus datos para investigarlos. Para obtener más detalles sobre los precios, visite Precios de Azure Storage.
Las funciones como los espacios de nombres jerárquicos también mejoran en gran medida el rendimiento general de muchas actividades de análisis. Debido al rendimiento mejorado, ahora se requiere menos poder de cómputo para procesar la misma cantidad de datos, lo que reduce el costo total de propiedad (TCO) de todo el proyecto de análisis.
Un servicio, múltiples ideas
Dado que Data Lake Storage Gen 2 se basa en Azure Blob Storage, el mismo objeto compartido se puede describir mediante varios conceptos.
A continuación se muestran los mismos objetos descritos por varios conceptos. A menos que se indique lo contrario, los siguientes términos son inmediatamente sinónimos:
| concepto |
organización superior |
organización subordinada |
contenedor de datos |
| Blob: almacenamiento de objetos de propósito general |
envase |
Directorio virtual (solo SDK; no proporciona operaciones atómicas) |
lugar |
| Azure Data Lake Storage Gen2: almacenamiento de análisis |
envase |
Tabla de contenido |
documento |
Funciones de compatibilidad con el almacenamiento de blobs
Las cuentas tienen acceso a las funciones de almacenamiento de blobs, como el registro de diagnóstico, los niveles de acceso y las políticas de administración del ciclo de vida del almacenamiento de blobs. La mayoría de las funciones de almacenamiento de blobs son totalmente compatibles, pero algunas solo son compatibles en el modo de vista previa o no lo son en absoluto.
Consulte Compatibilidad con la característica de almacenamiento de blobs en cuentas de almacenamiento de Azure para obtener detalles sobre cómo se admite cada característica de almacenamiento de blobs en Data Lake Storage Gen 2.
Integraciones de servicios de Azure admitidas
Data Lake Storage gen2 admite varios servicios de Azure. Se pueden utilizar para realizar análisis, generar visualizaciones e ingerir datos. Para obtener una lista de los servicios de Azure admitidos, consulte Servicios de Azure que admiten Azure Data Lake Storage Gen2.
Plataformas de código abierto compatibles
Data Lake Storage Gen2 es compatible con varias plataformas de código abierto. Para obtener una lista completa, consulte Plataformas de código abierto compatibles con Azure Data Lake Storage Gen 2.
Aproveche las prácticas recomendadas de Azure Data Lake Storage Gen 2
La versión Gen 2 de Azure Data Lake Storage no es un servicio o tipo de cuenta específico. Es una colección de herramientas para tareas de análisis de alto rendimiento. Las mejores prácticas e instrucciones para aprovechar estas capacidades se proporcionan en Referencia de Data Lake Storage Gen 2. Para obtener información sobre todos los demás aspectos de la administración de cuentas, incluida la configuración de la seguridad de la red, el diseño de alta disponibilidad y la recuperación ante desastres, consulte la documentación de Blob Storage.
Revise la compatibilidad de funciones y los problemas conocidos
Aplique el siguiente método al configurar una cuenta para aprovechar el servicio de almacenamiento de blobs.
- Para saber si una cuenta es totalmente compatible con una característica, lea la página sobre compatibilidad de características de almacenamiento de blobs para cuentas de Azure Storage. En las cuentas habilitadas para Data Lake Storage Gen2, algunas funciones no se admiten en absoluto o solo se admiten parcialmente. A medida que el soporte de funciones continúa creciendo, asegúrese de consultar esta página con frecuencia para ver los cambios.
- Consulte el artículo Problemas conocidos con Azure Data Lake Storage Gen 2 para ver si hay limitaciones o instrucciones específicas para las características que desea usar.
- Explore el artículo destacado para ver las recomendaciones que se aplican específicamente a las cuentas habilitadas para Data Lake Storage Gen2.
Identificar los términos utilizados en el documento.
Al cambiar entre conjuntos de contenido, notará algunos cambios menores en el vocabulario. Por ejemplo, en el contenido destacado de la descripción del almacenamiento de blobs, se usará el término "Blob" en lugar de "archivo". Técnicamente, los datos cargados en una cuenta de almacenamiento se convierten allí en una mancha. Por lo tanto, esta frase es precisa. Sin embargo, el término "blob" puede resultar confuso si está acostumbrado al término "archivo". Los sistemas de archivos también se conocen como "contenedores". Trate estas frases como intercambiables.
Considere la prima
Si su carga de trabajo requiere una latencia constante baja o un número elevado de operaciones de entrada y salida por segundo (IOP), considere una cuenta premium de almacenamiento de blobs en bloques. En dichas cuentas se utiliza hardware de alto rendimiento para que los datos sean accesibles. Las unidades de estado sólido (SSD) están diseñadas para una latencia mínima y se utilizan para almacenar datos. Los SSD proporcionan un mayor rendimiento que los discos duros tradicionales. El rendimiento avanzado tiene costos de almacenamiento más altos pero costos de transacción más bajos. Por lo tanto, si la aplicación realiza una gran cantidad de transacciones, una cuenta de blob en bloques de rendimiento superior podría ser rentable.
Si la cuenta de almacenamiento se usará para análisis, recomendamos enfáticamente usar Azure Data Lake Storage Gen 2 con una cuenta de almacenamiento de blobs en bloques premium. El nivel Premium de Azure Data Lake Storage es una cuenta premium de almacenamiento de blobs en bloques combinada con una cuenta habilitada para Data Lake Storage.
Mejore la ingestión de datos
Al ingerir datos del sistema de origen, el hardware de origen, el hardware de red de origen o la conexión de red a la cuenta de almacenamiento pueden ser un cuello de botella.
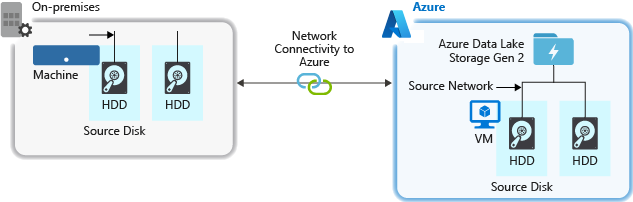
hardware fuente
Asegúrese de elegir el hardware correcto con cuidado, ya sea que use una máquina virtual (VM) en Azure o en un dispositivo local. Elija hardware de disco con ejes más rápidos y considere unidades de estado sólido (SSD). Utilice el controlador de interfaz de red (NIC) más rápido para el hardware de red. Recomendamos usar máquinas virtuales Azure D14, ya que tienen suficientes capacidades de red y hardware de disco.
Red conectada a la cuenta de almacenamiento
A veces puede haber un cuello de botella en la conexión de red entre los datos de origen y la cuenta de almacenamiento. Cuando los datos de origen son locales, es posible que sea necesario usar un vínculo privado de Azure ExpressRoute. El rendimiento es mejor cuando los datos de origen (si están en Azure) están en la misma región de Azure que la cuenta habilitada para Data Lake Storage Gen2.
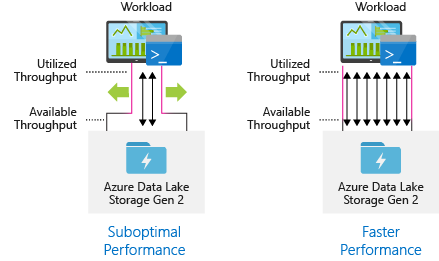
Configurar el mecanismo de ingestión de datos para el procesamiento más paralelo posible
Utilice todo el rendimiento disponible ejecutando tantas lecturas y escrituras en paralelo para un rendimiento óptimo.
conjunto de datos estructurado
Considere la estructura de organización de sus datos de antemano. El rendimiento y el costo pueden verse afectados por el formato y el tamaño del archivo y la organización del directorio.
formato de archivo
Se pueden usar diferentes formatos para ingerir datos. Los datos se pueden presentar en un formato binario comprimido como tar. go o en un formato legible por humanos, como JSON, CSV o XML. Los datos también pueden llegar en varios tamaños. Los archivos grandes (varios terabytes) pueden constituir datos, como exportar información de una tabla SQL desde un sistema local. Por ejemplo, los datos de eventos en tiempo real de las soluciones de Internet de las cosas (IoT) también pueden presentarse en forma de una gran cantidad de archivos pequeños (de unos pocos kilobytes de tamaño). Al elegir el formato de archivo y el tamaño de archivo correctos, puede maximizar la eficiencia y minimizar los costos.
Hadoop admite una variedad de formatos de archivo diseñados para almacenar y analizar datos estructurados. Los formatos Avro, Parquet y Determinante optimizado (ORC) son algunos formatos populares. Estos son formatos de archivos binarios que pueden ser leídos por máquinas. Están comprimidos para ayudarlo a controlar el tamaño del archivo. Son autodescriptivos porque cada archivo contiene un esquema incrustado. El método utilizado para almacenar datos varía según el formato. Los formatos Parquet y ORC almacenan datos en forma de columnas, mientras que Avro almacena datos en un formato basado en filas.
Si sus patrones de E/S son más intensivos en escritura, o si sus patrones de consulta tienden a obtener grandes filas de información en su totalidad, es posible que desee utilizar el formato de archivo Avro. Por ejemplo, el formato Avro es adecuado para buses de mensajes que escriben secuencias de eventos o mensajes, como Event Hubs o Kafka.
Considere los formatos de archivo Parquet y ORC cuando los patrones de E/S son más intensivos en lectura o cuando los patrones de consulta se enfocan en un subconjunto específico de columnas en un registro. Las transacciones de lectura pueden reducirse a obtener solo ciertas columnas, en lugar de leer registros completos.
Apache Parquet de código abierto es un formato de archivo diseñado para canalizaciones de análisis de lectura intensiva. Gracias al formato de almacenamiento en columnas de Parquet, puede omitir datos irrelevantes. Las consultas son mucho más eficientes porque pueden ser específicas de los datos que se enviarán desde el almacenamiento al motor de análisis. Además, Parquet proporciona técnicas eficientes de codificación y compresión de datos que pueden reducir el costo del almacenamiento de datos porque los tipos de datos similares (para columnas) se almacenan juntos. El formato de archivo Parquet nativo es compatible con servicios como Azure Synapse Analytics, Azure Databricks y Azure Data Factory.
Tamaño del archivo
Los archivos más grandes mejoran el rendimiento y reducen los costos.
Los motores de análisis, como HDInsight, suelen incluir una sobrecarga por archivo, que incluye actividades como enumerar, determinar los permisos de acceso y realizar varias operaciones de metadatos. El almacenamiento de datos en forma de varios archivos pequeños puede afectar negativamente al rendimiento. Para mejorar el rendimiento, organice los datos en archivos más grandes (256 MB a 100 GB de tamaño). Es posible que algunos motores y programas no puedan manejar eficientemente archivos de más de 100 GB.
Los costos de transacción reducidos son otro beneficio de ampliar los archivos. Se le cobrará por la actividad de lectura y escritura en incrementos de 4 MB, ya sea que el archivo contenga 4 MB o solo unos pocos KB. Para obtener detalles sobre los precios, consulte Precios de Azure Data Lake Storage.
Los datos sin procesar consisten en una gran cantidad de archivos pequeños, que a veces pueden estar sujetos a un control limitado por parte de la canalización de datos . Recomendamos que su sistema tenga un programa que fusione archivos pequeños en archivos más grandes para que los usen las aplicaciones posteriores. Si desea procesar datos en tiempo real, puede usar un motor de transmisión en tiempo real como Spark Streaming o Azure Stream Analytics con un agente de mensajes como Event Hubs o Apache Kafka para guardar los datos como archivos más grandes. Al fusionar archivos pequeños en archivos grandes, considere guardarlos en un formato optimizado para lectura (como Apache Parquet) para su posterior procesamiento.
Estructura de directorios
Estos son algunos diseños típicos que se deben tener en cuenta al trabajar con Internet de las cosas (IoT), escenarios por lotes u optimizar datos de series temporales. Cada carga de trabajo tiene varios requisitos sobre cómo se utilizan los datos.
Programación del trabajo por lotes
En las cargas de trabajo de IoT, se pueden ingerir grandes volúmenes de datos de muchos productos básicos, dispositivos, empresas y clientes. El diseño del directorio debe planificarse a tiempo para proporcionar un procesamiento de datos organizado, seguro y eficiente para los usuarios intermedios. Los siguientes diseños pueden servir como plantillas generales a considerar:
{Region}/{SubjectMatter(s)}/{yyyy}/{mm}/{dd}/{hh}/
Para ilustrar, una estructura de telemetría de aterrizaje para un motor de avión británico podría verse así:
UK/Planes/BA1293/Engine1/2017/08/11/12/
En este ejemplo, puede limitar más fácilmente áreas y temas a usuarios y grupos agregando la fecha al final de la estructura del directorio. Asegurar estos campos y temas será más desafiante si la estructura de fechas es lo primero. Por ejemplo, si desea restringir el acceso a los datos del Reino Unido o solo a aeronaves específicas, deberá solicitar autorizaciones separadas para varios directorios en cada directorio por hora. Además, este arreglo aumentará rápidamente el número de directorios con el tiempo.
La estructura de las tareas por lotes.
Agregar datos al directorio "in" es una técnica frecuente de procesamiento por lotes. Una vez que se han procesado los datos, los nuevos datos se colocan en el directorio de "salida" para que otros procesos puedan consumirlos. Esta estructura de directorios se usa ocasionalmente para tareas que solo necesitan examinar un único archivo y no necesariamente requieren una ejecución paralela masiva en grandes conjuntos de datos. Una estructura de directorios útil tiene directorios principales para cosas como áreas y temas, como la estructura de IoT que se muestra arriba (por ejemplo, organización, producto o productor). Para una mejor organización, búsqueda de filtros, seguridad y automatización en su procesamiento, considere fechas y horas al diseñar su estructura. La frecuencia con la que se cargan o descargan los datos determina el nivel de granularidad de la estructura de datos.
El procesamiento de archivos falla ocasionalmente debido a la corrupción de datos o a un formato inesperado. En estos casos, la estructura de directorios puede beneficiarse de tener una carpeta /bad para que los archivos se puedan mover allí para un análisis adicional. Las tareas por lotes también pueden monitorear informes o alertar a los usuarios sobre estos archivos problemáticos para que puedan tomar medidas manuales. Considere la siguiente disposición de plantillas:
{Region}/{SubjectMatter(s)}/In/{yyyy}/{mm}/{dd}/{hh}/{Region}/{SubjectMatter(s)}/Out/{yyyy}/{mm}/{dd}/{hh}/{Region}/{SubjectMatter(s)}/Bad/{yyyy}/{mm}/{dd}/{hh}/
Por ejemplo, una empresa de marketing recibe extractos diarios de actualizaciones de clientes de clientes norteamericanos. Antes y después del procesamiento, podría verse como el siguiente fragmento de código:
NA/Extracts/ACMEPaperCo/In/2017/08/14/updates_08142017.csvNA/Extracts/ACMEPaperCo/Out/2017/08/14/processed_updates_08142017.csv
En un escenario típico en el que los datos por lotes se procesan directamente en una base de datos como Hive o una base de datos SQL tradicional, la salida ha ido a una carpeta separada para la tabla de Hive o la base de datos externa; por lo tanto, no se requieren directorios /in o /out. Por ejemplo, cada directorio recibirá capturas de datos diarias de los consumidores. Posteriormente, servicios como Azure Data Factory, Apache Oozie o Apache Airflow inician trabajos diarios de Hive o Spark para procesar y escribir los datos en las tablas de Hive.
estructura de datos de series de tiempo
La eliminación de particiones en datos de series temporales para cargas de trabajo de Hive puede mejorar el rendimiento al hacer que algunas consultas lean solo una parte de los datos.
Las canalizaciones para la ingesta de datos de series temporales normalmente organizan sus archivos en carpetas con nombre. Aquí hay un ejemplo de datos típicamente ordenados por fecha:
/DataSet/YYYY/MM/DD/datafile_YYYY_MM_DD.tsv
Recuerde que los detalles de la fecha y la hora se pueden encontrar en los nombres de archivo y las carpetas.
Los siguientes son formatos típicos para fechas y horas:
/DataSet/YYYY/MM/DD/HH/mm/datafile_YYYY_MM_DD_HH_mm.tsv
Una vez más, las decisiones que tome sobre cómo organizar sus carpetas y archivos deben optimizarse para tamaños de archivo más grandes y cantidades manejables de archivos en cada carpeta.
establecer seguridad
Comience por revisar las recomendaciones del artículo Consideraciones de seguridad para el almacenamiento de blobs. Recibirá consejos de mejores prácticas sobre cómo proteger los datos detrás del firewall, evitar la eliminación accidental o malintencionada y usar Azure Active Directory (Azure AD) como base para la administración de identidades.
Luego, para obtener recomendaciones específicas para las cuentas con Data Lake Storage Gen 2 habilitado, consulte la sección Modelo de control de acceso en la página de Azure Data Lake Storage Gen 2. En este artículo se describe cómo aplicar permisos de seguridad a directorios y archivos en un sistema de archivos jerárquico mediante el uso de roles y listas de control de acceso (ACL) de control de acceso basado en roles (Azure RBAC) de Azure.
Introducir, implementar y evaluar.
Los datos se pueden ingerir en cuentas habilitadas para Data Lake Storage Gen2 desde una variedad de fuentes y en una variedad de métodos.
Para crear prototipos de aplicaciones, se pueden traer grandes cantidades de datos desde los clústeres de HDInsight y Hadoop, así como conjuntos de datos ad-hoc más pequeños. Puede recibir datos de transmisión generados por varias fuentes, incluidos software, hardware y sensores. Puede usar herramientas para registrar y procesar estos datos evento por evento en tiempo real y luego escribir eventos en lotes en su cuenta. También se pueden traer registros del servidor web, que incluyen detalles como el historial de solicitudes de página. Si desea la flexibilidad de integrar el componente de carga de datos en una aplicación de big data más grande, considere usar un script o programa personalizado para enviar datos de registro.
Una vez que los datos están disponibles en su cuenta, puede ejecutar análisis sobre ellos, crear visualizaciones e incluso descargar los datos a su computadora local o a otro repositorio, como una instancia de Azure SQL Database o SQL Server.
telemetría de monitoreo
Los servicios operativos requieren una cuidadosa atención al uso y la supervisión del rendimiento. Los ejemplos incluyen procesos que ocurren con frecuencia, tienen retrasos significativos o limitan el servicio.
Se puede acceder a todos los datos de telemetría de una cuenta de almacenamiento a través de los registros de Azure Storage en Azure Monitor. Esta función permite archivar registros en otra cuenta de almacenamiento y vincular la cuenta de almacenamiento con Log Analytics y Event Hubs. Visite la Referencia de datos de supervisión de Azure Storage para ver la colección completa de métricas, registros de recursos y sus estructuras correspondientes.
Dependiendo de cómo planee acceder a ellos, puede almacenar sus registros en cualquier lugar que desee. Por ejemplo, puede almacenar registros en un área de trabajo de Log Analytics si desea tener acceso casi en tiempo real a sus registros y la capacidad de unir eventos en sus registros con otras métricas en Azure Monitor. Luego, use KQL y una consulta de creación para consultar los registros, que enumeran la tabla StorageBlobLogs en el área de trabajo.
Si desea almacenar registros para consultas casi en tiempo real y retención a largo plazo, puede establecer la configuración de diagnóstico para enviar registros al área de trabajo y la cuenta de almacenamiento de Log Analytics.
Si desea recuperar registros a través de otros motores de consulta, como Splunk, puede establecer la configuración de diagnóstico para enviar registros a Event Hubs e incorporar registros de Event Hubs a su destino preferido.
en conclusión
Las características de Azure Data Lake Storage Gen1 y Azure Blob Storage se combinan en Data Lake Storage Gen2. Por ejemplo, Data Lake Storage Gen2 proporciona escala, seguridad a nivel de archivos y semántica del sistema de archivos. También obtiene almacenamiento en niveles de bajo costo con características de alta disponibilidad/recuperación ante desastres, ya que esas características se basan en Blob Storage.