I. Introduction
A null pointer was generated when it was released today. According to the stack display, a null pointer was generated when BeanCopyUtils.copyAppointFields was displayed. Here it is explained that this tool class and method are internally encapsulated by the company, and are used to specify some fields for copying.
When the author saw the stack, his first reaction was that there was a problem with this tool class. After discussing with the leader, the author felt that it was possible. The following describes the investigation process and principle.
2. The investigation process
In the beginning, I actually copied the json typed out of the log and ran it locally. I always check my own code first, and then go to the bottom layer.
1. Stack
From the stack, you can see where the specific error is reported, and you can find the source code to view

2. Tools source code
The developer uses two hashmaps for caching. The getset method of the storage class will enter the caching method if it has not been cached. Some students may know from this that the problem lies in the two hashmaps. We will talk about this later
private static Map<Class<?>, MethodAccess> methodMap = new HashMap<Class<?>, MethodAccess>();
private static Map<Class<?>, Map<String, Integer>> methodIndexMap = new HashMap<>();
if (source == null || target == null) {
log.error("BeanCopyUtils Process", "source or target is null, {}, {}", source, target);
return;
}
if (methodMap.get(source.getClass()) == null || methodMap.get(target.getClass()) == null) {
cache(source, target);
}Use synchronized to prevent concurrent settings, and then the lazy mode is judged once, and finally stored in the cache
private synchronized static void cache(Object source, Object target) {
if (methodMap.get(source.getClass()) == null) {
cacheMethodIndex(source.getClass());
}
if (methodMap.get(target.getClass()) == null) {
cacheMethodIndex(target.getClass());
}
}
protected synchronized static void cacheMethodIndex(Class<?> clazz) {
if (methodMap.get(clazz) != null) {
return;
}The problem is that when the get method corresponding to the field is fetched from the cache, the null pointer explodes
Map<String, Integer> sourceMethodIndexMap = methodIndexMap.get(source.getClass());
for (String field : sourceFieldList) {
Integer getMethodIndex = sourceMethodIndexMap.get(GET + StringUtils.capitalize(field));Here it is explained that when the field method corresponding to the storage class is mapped to sourceMethodIndexMap, the get is null, but here the concurrency is guaranteed through synchronized, and the problem cannot be seen at once by looking at the code.
The author thought about it for a while, it judged get first! = null and then get the value. This is a two-step operation. When = null, it needs to go through a cache before getting it again. During this period, if a hash conflict occurs and the node of the linked list or red-black tree moves, then it will be null when getting;
3. Verification
Once you have a direction, you need to verify it. Then you need to write a piece of verification code. The code must meet:
1. After the hash conflict, a linked list or red-black tree node movement will be formed in the entry
2. Concurrency settings and values
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<>();
map.put("key", "value");
ExecutorService executorService = Executors.newFixedThreadPool(2);
// 线程1执行put操作
executorService.execute(() -> {
for (int i = 0; i < 100000; i++) {
map.put("key" + i, "value" + i);
}
});
// 线程2执行get操作
executorService.execute(() -> {
for (int i = 0; i < 100000; i++) {
if (map.get("key" + i) != null) {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
String value = map.get("key" + i);
if (value == null) {
System.out.println("get方法返回null,key=" + ("key" + i));
}
}
}
});
executorService.shutdown();
}Look at the running results and verify the guessed direction

3. Principle and solution
Only when you know the principle can you talk about the solution, otherwise you will just follow what others say
1. Principle
The author only introduces a simple situation here, which is easy to understand. After the linked list is formed in the left picture, when the value of the corresponding node is obtained according to the key, it is not null, but when it comes to the right picture, the linked list is being reconnected. At this time, it is null
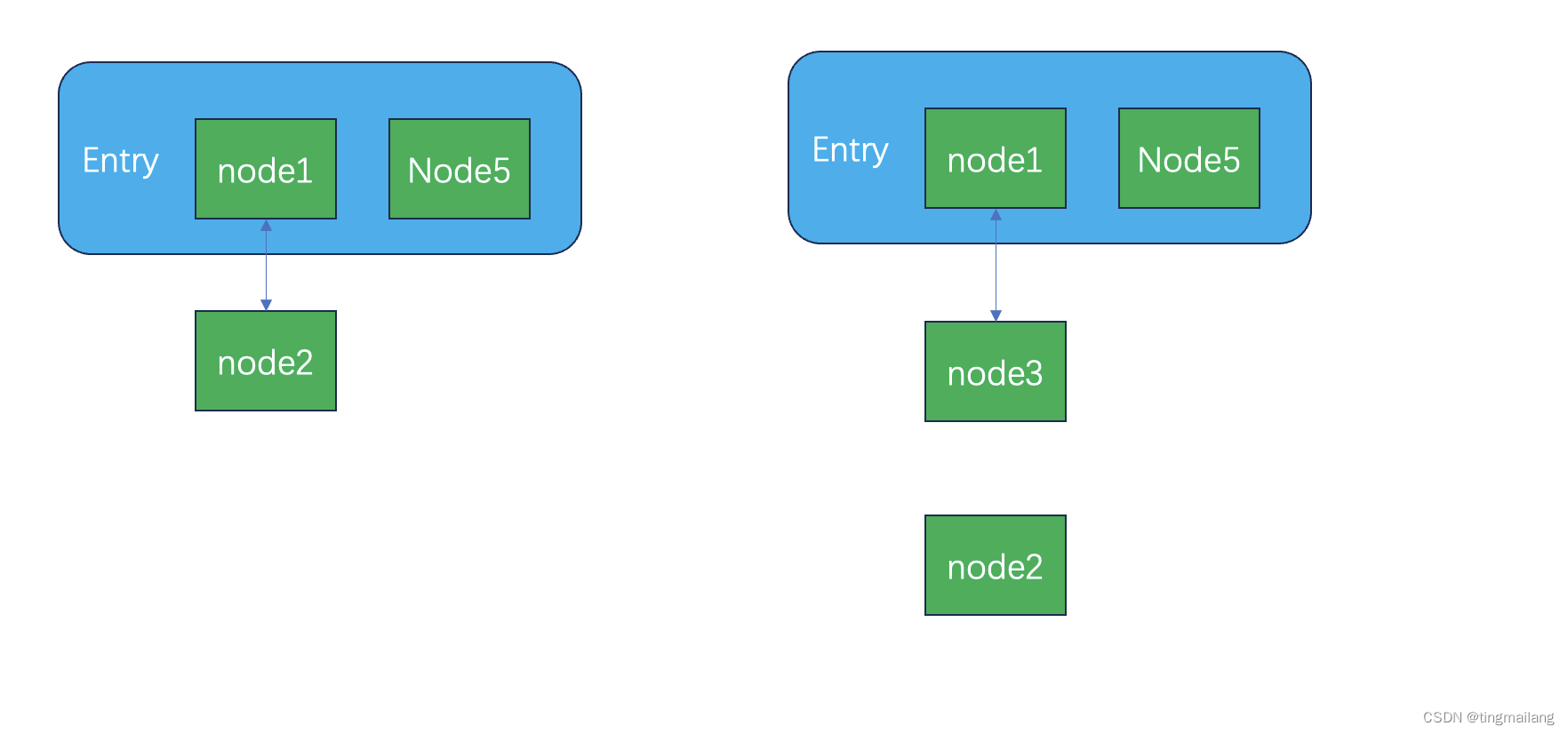
2. Solve
The solution is actually very simple, which is to replace the hashmap with ConcurrentHashMap, because Doug Lea created the Concurrent package with concurrent mutual exclusion, and when the data is changed, the segment lock will be used to block reading in the ConcurrentHashMap. ConcurrentHashMap in Java 8 uses a new implementation, namely CAS+Synchronized, to replace the segment lock implementation in the old version. This new implementation can better utilize the hardware characteristics of modern CPUs and improve concurrent performance.
Some students may say that as long as I use hashmap in concurrent places, I can replace it with ConcurrentHashMap, right?
Yes, in most cases, it can be directly replaced. In a very few cases where performance is pursued and risks are well controlled, hashmap can reduce the performance of segment locks.
In addition, the most important thing for R&D personnel is to know what is happening and why. If Doug Lea did not create a Concurrent package or ConcurrentHashMap, he must know how to troubleshoot and solve it. If ConcurrentHashMap has new problems in extreme cases, you need to know how to troubleshoot and solve them.
Just like the author often said about k8s, systemd, mq, etc., the open source community or the middleware operation and maintenance team said that upgrading can be solved. Is that solved? That's what others say, and they don't know why, so who solves the problems in the open source community, it requires every R&D personnel to question all the bottom layers and try to solve them.
There is no problem with the absence of systems, frameworks, and middleware!
public static void main(String[] args) {
ConcurrentHashMap<String, String> map = new ConcurrentHashMap<>();
map.put("key", "value");
ExecutorService executorService = Executors.newFixedThreadPool(2);
// 线程1执行put操作
executorService.execute(() -> {
for (int i = 0; i < 100000; i++) {
map.put("key" + i, "value" + i);
}
});
// 线程2执行get操作
executorService.execute(() -> {
for (int i = 0; i < 100000; i++) {
if (map.get("key" + i) != null) {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
String value = map.get("key" + i);
if (value == null) {
System.out.println("get方法返回null,key=" + ("key" + i));
}
}
}
});
executorService.shutdown();
}Four. Summary
It is actually a good thing that the apparent release problem involves the bottom layer. After solving the problem, the problem can be solved once and for all. The investigation process can also exercise the thinking and summarizing ability of the R&D personnel.
Again, here is the author's understanding, and students with different ideas are welcome to discuss.