En el último artículo, aprendimos y entendimos algunos conceptos básicos y operaciones básicas del flujo óptico (Flujo Óptico), pero el método de estimación de flujo óptico tradicional es computacionalmente complejo y costoso. En los últimos años, con el desarrollo continuo y la madurez de la red neuronal convolucional CNN, ha logrado un gran éxito en varias tareas de visión por computadora (principalmente utilizadas para tareas relacionadas con el reconocimiento). Por lo tanto, la serie de artículos FlowNet se propuso combinando la estimación de flujo óptico con el aprendizaje profundo de CNN. Por primera vez, CNN se aplicó a la predicción de flujo óptico, de modo que la red pueda predecir el campo de flujo óptico a partir de un par de imágenes, alcanzando un velocidad de 5 a 10 fotogramas por segundo y la precisión ha alcanzado el estándar de la industria.
1. Red de flujo
FlowNet (o FlowNet 1.0) es la primera red de estimación de flujo óptico propuesta por la serie FlowNet, y también es la red más importante y básica. Su idea proviene del artículo "FlowNet: Aprendizaje de flujo óptico con redes convolucionales", que se publica En IEEE International Conference on Computer Vision (ICCV), 2015.
Este artículo primero propone una estructura de red neuronal de extremo a extremo para el aprendizaje de estimación de flujo óptico, que generalmente es una estructura de codificador/descodificador . La información se somete primero a compresión espacial y extracción de características en la parte de la red que se reduce, y luego se refina en la parte que se expande. La entrada de la red FlowNet es un par de imágenes (que incluye dos cuadros adyacentes) y su correspondiente realidad de campo de flujo óptico. En segundo lugar, dado que el conjunto de datos de flujo óptico actual no es suficiente para entrenar una red grande, este artículo también sintetizó un conjunto de datos de imágenes de sillas llamado Flying Chairs a través de síntesis virtual , que logró mejores resultados en el proceso de entrenamiento de la red.
1. Estructura de la red
De acuerdo con la diferencia en la estructura de red de la parte de codificación/reducción, el artículo subdivide FlowNet en dos estructuras, FlowNet-Simple (FlowNet-S) y FlowNet-Correlation (FlowNet-C), que son consistentes en la parte de decodificación/extensión. Los presentaremos respectivamente de la siguiente manera.
1.1 Codificación de la parte contratante/parte reductora
(1) FlowNet-S
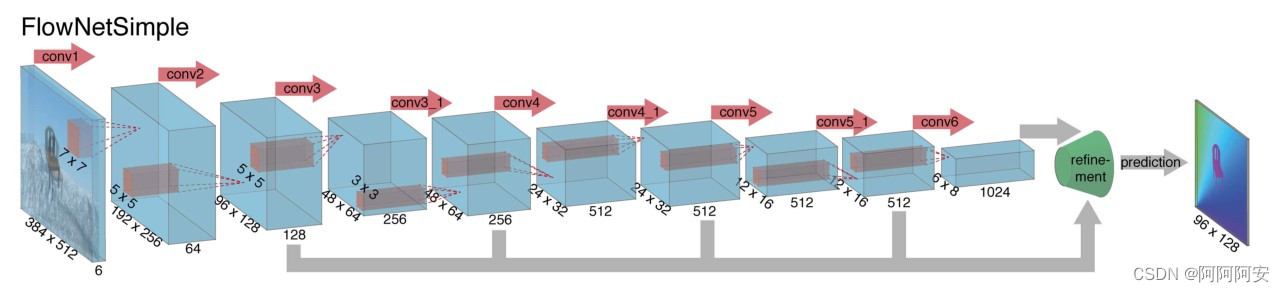
FlowNetSimple es la estructura de red más simple y rudimentaria. La red apila (une) directamente los dos marcos de imágenes de entrada en la dimensión general y luego usa una serie de capas convolucionales para reducir la muestra y extraer características, lo que permite que la red decida cómo pares de imágenes para extraer información de movimiento de ellos, y la estructura de la red se muestra en la figura anterior.
(2) FlowNet-C
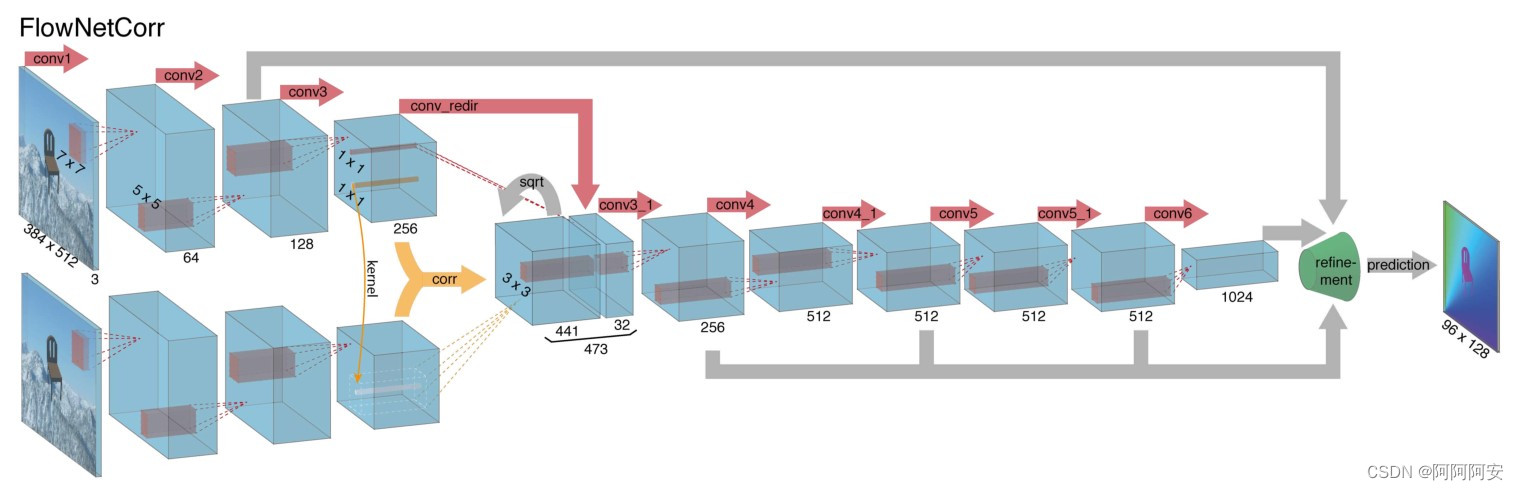
La diferencia entre FlowNetCorrelation y FlowNet-S es que FlowNet-C primero establece dos flujos de procesamiento independientes pero idénticos para dos imágenes de entrada y extrae representaciones de características significativas de las dos imágenes a través de una serie de capas convolucionales . Estas representaciones de características significativas se combinan luego en para el proceso de reducción de muestreo posterior.La estructura de la red se muestra en la figura anterior.
Sin embargo, la combinación de características de alto nivel de dos imágenes no es un simple apilamiento de dimensiones, sino que se utiliza una capa de asociación para facilitar el proceso de coincidencia de la red. Sabemos que el objetivo final de la red es predecir el flujo óptico entre dos imágenes, y el flujo óptico es esencialmente una relación de coincidencia correspondiente entre diferentes imágenes. Para "ayudar" a la red a acelerar el cálculo de esta relación de coincidencia y mejorar el rendimiento de la red, y para mejorar la precisión de la estimación, introducimos una "capa de correlación" para combinar características . La operación de "correlación" es un tipo de cálculo de correlación (lo explicaremos en detalle más adelante), que se usa para calcular la correlación entre diferentes características/bloques de imágenes , y el índice de resultados se usa para reflejar el grado de coincidencia. cálculo de coincidencia avanzado Para combinar características de alto nivel, se puede decir que proporciona una guía sólida para el posterior aprendizaje de relaciones de coincidencia de la red.
En resumen, FlowNet-C primero extrae características de dos imágenes y luego compara estos vectores de características de manera similar a los métodos de coincidencia estándar, imitando artificialmente el proceso de coincidencia estándar.
1.2 Descodificación de la parte de expansión / parte de expansión
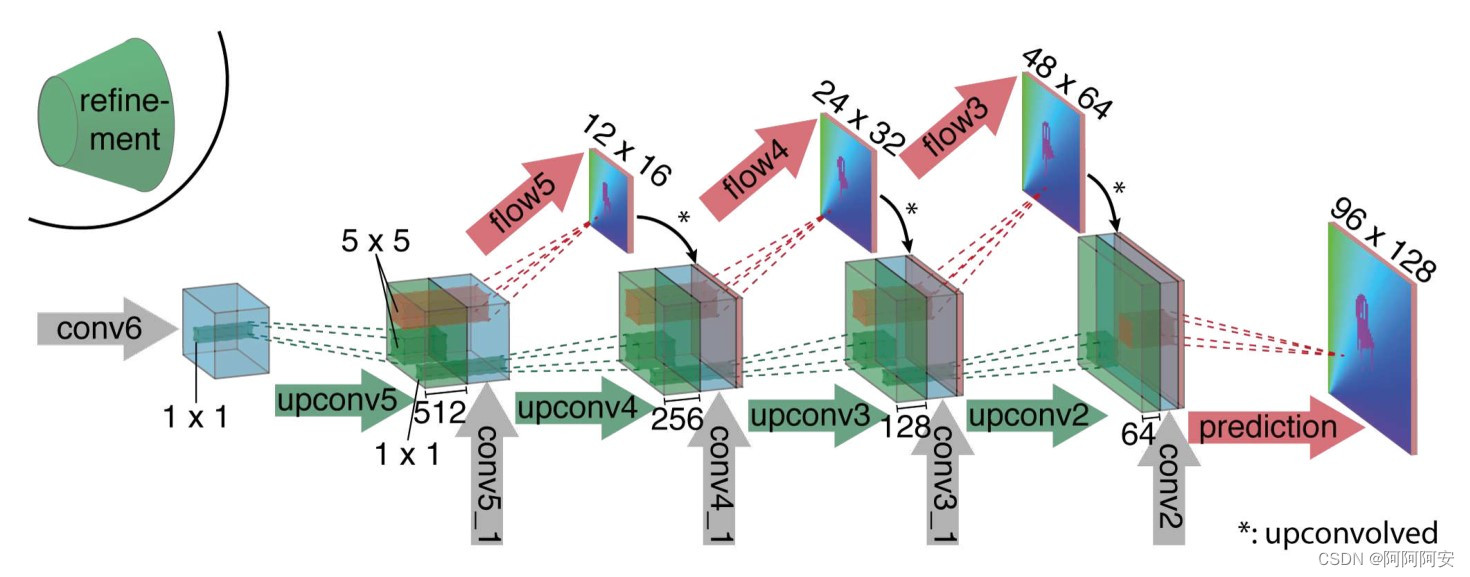
En la etapa de decodificación/expansión (como se muestra en la figura anterior), esta etapa incluye principalmente múltiples operaciones de muestreo para restaurar el tamaño de la imagen y la información. Para fusionar mejor la información semántica de diferentes capas, además de la salida de la capa anterior , la entrada de cada capa también tiene el "flujo óptico" predicho por la salida de la capa anterior y las características de la capa correspondiente de la codificador _ De esta manera, conservamos tanto la información de alto nivel transmitida desde los mapas de características más gruesos como la información local fina proporcionada por los mapas de características de la capa inferior.
Cada sobremuestreo duplica la resolución y repite el proceso 4 veces, lo que da como resultado un flujo de salida previsto. Tenga en cuenta que su resolución sigue siendo 4 veces menor que el tamaño original de la imagen de entrada , y puede restaurarse mediante interpolación bilineal más tarde . Debido a que el artículo descubrió que, en comparación con el muestreo ascendente de interpolación bilineal con un costo computacional más bajo de la resolución de imagen completa, el aprendizaje continuo de la red a partir de esta resolución no mejorará mucho los resultados, por lo que se puede obtener una interpolación bilineal directa e ingresar el mapa de predicción de flujo óptico en el misma resolución.
2. Explicación detallada de la capa de correlación
La operación de correlación es un cálculo de coincidencia de correlación , y el resultado de su cálculo indica el grado de coincidencia de dos parches de imagen . En comparación con FlowNetS, FlowNetC no solo apila las imágenes de entrada, sino que necesita proporcionar artificialmente a la red información de guía sobre cómo hacer coincidir los detalles de la imagen y fusionar y activar las características extraídas de alto nivel en las dos imágenes, por lo que presenta la correlación. capa.
El proceso de cálculo específico de la operación de correlación es esencialmente una operación de convolución en una CNN de un solo paso , pero en comparación con CNN que usa un kernel de convolución específico para la convolución, aquí se usa un dato (parche de imagen 1) para hacer otra operación de convolución de datos (parche de imagen 2) , por lo que esta operación no incluye parámetros de entrenamiento . Para el bloque de imagen rectangular (parche) en image1(w,h,c) que se extiende hacia arriba y hacia abajo con una longitud k (la longitud y el ancho del bloque rectangular es 2k+1) centrado en x1, es el mismo que en image2(w,h, c ) entreUn cálculo de correlación puede expresar como:
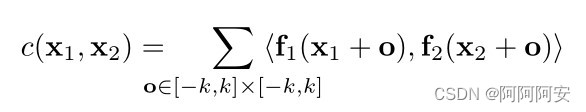
De hecho, el parche de la primera imagen se usa para convolucionar el parche de la segunda imagen (que corresponde al producto interno), y un cálculo de correlación produce un número de resultado que indica el grado de coincidencia de los dos parches. Luego, para un parche de cierto píxel x1 en la imagen 1, teóricamente debería coincidir con todos los parches de píxeles en la imagen 2 (un total de w*h parches) , luego x1 generará una longitud correspondiente de w*h El vector coincidente , luego para toda la imagen1 y la imagen2, el resultado de la correlación es de cuatro dimensiones .
Calcular la correlación una vez generará una multiplicación. En teoría, para cada parche de píxeles en la imagen 1, debemos realizar cálculos coincidentes con todos los parches en la imagen 2. La comparación de todos los parches implicará
tales cálculos de multiplicación. Pero el problema es que ese cálculo es enorme , por lo que debemos optimizar este proceso.
El artículo asume que el desplazamiento del píxel correspondiente sólo existe dentro de un rango fijo . De esta forma, al calcular realmente la información asociada, el modelo solo necesita mantener una ventana de búsqueda de tamaño fijo , y no se considerarán las cosas que estén más allá del rango de la ventana de búsqueda. Dado el rango de búsqueda máximo d, para cada posición x1, podemos limitar x2 para calcular la correlación c(x1, x2) solo en la ventana de búsqueda rectangular cuyo tamaño (largo y ancho) es D = 2d + 1 . Al mismo tiempo, el artículo utiliza zancadas s1 y s2, cuantifica x1 globalmente y cuantifica y calcula x2 en la vecindad centrada en x1 . De esta forma, para el parche de un determinado píxel x1 en la imagen 1, después de la optimización, debe coincidir con el parche del píxel en la imagen 2 dentro del rango de la ventana de búsqueda correspondiente (un total de parches D*D) , luego x1 se generará correspondientemente Un vector coincidente con una longitud de D*D , para toda la imagen1 y la imagen2, el resultado de la correlación se puede expresar como . En el documento original, establezca los parámetros k = 0, d = 20, s1 = 1, s2 = 2. En el código, se implementa mediante C++. Algunos códigos fuente clave son los siguientes:
template<typename scalar_t>
//一次 Correlation Operation 计算过程
__global__ void correlation_forward(scalar_t* __restrict__ output, const int nOutputChannels,
const int outputHeight, const int outputWidth, const scalar_t* __restrict__ rInput1,
const int nInputChannels, const int inputHeight, const int inputWidth,
const scalar_t* __restrict__ rInput2, const int pad_size, const int kernel_size,
const int max_displacement, const int stride1, const int stride2) {
int32_t pInputWidth = inputWidth + 2 * pad_size;
int32_t pInputHeight = inputHeight + 2 * pad_size;
int32_t kernel_rad = (kernel_size - 1) / 2;
int32_t displacement_rad = max_displacement / stride2;
int32_t displacement_size = 2 * displacement_rad + 1;
int32_t n = blockIdx.x;
int32_t y1 = blockIdx.y * stride1 + max_displacement;
int32_t x1 = blockIdx.z * stride1 + max_displacement;
int32_t c = threadIdx.x;
int32_t pdimyxc = pInputHeight * pInputWidth * nInputChannels;
int32_t pdimxc = pInputWidth * nInputChannels;
int32_t pdimc = nInputChannels;
int32_t tdimcyx = nOutputChannels * outputHeight * outputWidth;
int32_t tdimyx = outputHeight * outputWidth;
int32_t tdimx = outputWidth;
int32_t nelems = kernel_size * kernel_size * pdimc;
// element-wise product along channel axis
for (int tj = -displacement_rad; tj <= displacement_rad; ++tj) {
for (int ti = -displacement_rad; ti <= displacement_rad; ++ti) {
//get center x2,y2 in image2
int x2 = x1 + ti * stride2;
int y2 = y1 + tj * stride2;
float acc0 = 0.0f;
for (int j = -kernel_rad; j <= kernel_rad; ++j) {
for (int i = -kernel_rad; i <= kernel_rad; ++i) {
// THREADS_PER_BLOCK
#pragma unroll
for (int ch = c; ch < pdimc; ch += blockDim.x) {
int indx1 = n * pdimyxc + (y1 + j) * pdimxc
+ (x1 + i) * pdimc + ch;
int indx2 = n * pdimyxc + (y2 + j) * pdimxc
+ (x2 + i) * pdimc + ch;
acc0 += static_cast<float>(rInput1[indx1] * rInput2[indx2]);
}
}
}
if (blockDim.x == warpSize) {
__syncwarp();
acc0 = warpReduceSum(acc0);
} else {
__syncthreads();
acc0 = blockReduceSum(acc0);
}
if (threadIdx.x == 0) {
int tc = (tj + displacement_rad) * displacement_size
+ (ti + displacement_rad);
const int tindx = n * tdimcyx + tc * tdimyx + blockIdx.y * tdimx
+ blockIdx.z;
output[tindx] = static_cast<scalar_t>(acc0 / nelems);
}
}
}
}La implementación original de C++ es más complicada de usar, por lo que también hay muchos paquetes de Python de terceros para los cálculos de correlación, que podemos usar directamente al importarlos, como sptial_correlation_sampler/spatial_correlation_sample, etc.
(1) muestra_correlación_espacial/muestra_correlación_espacial
entrada (B x C x H x W) -> salida (B x PatchH x PatchW x oH x oW)
- El tamaño del parche
patch_sizerepresenta la longitud y el ancho de todo el parche rectangular, no solo el radio.stride1Ahora esstride,stride2es ahoradilation_patch, que se comporta como una convolución dilatada- El equivalente
max_displacementesdilation_patch * (patch_size - 1) / 2.- Para obtener los parámetros correctos para flownetc, debe configurar
kernel_size=1 patch_size=21, stride=1, padding=0, dilation_patch=2
def correlate(input1, input2):
out_corr = spatial_correlation_sample(input1,
input2,
kernel_size=1,
patch_size=21,
stride=1,
padding=0,
dilation_patch=2)
# collate dimensions 1 and 2 in order to be treated as a
# regular 4D tensor
b, ph, pw, h, w = out_corr.size()
out_corr = out_corr.view(b, ph * pw, h, w)/input1.size(1)
return F.leaky_relu_(out_corr, 0.1)3. Más detalles de implementación
FlowNet-S y FlowNet-C tienen aproximadamente la misma estructura de red: tienen 9 capas convolucionales en la parte de contracción, 6 de las cuales tienen un paso de 2, y cada convolución tiene una función de activación no lineal ReLU. El tamaño del kernel de convolución es 7×7 en la primera capa de convolución, 5×5 en las siguientes dos capas y 3×3 desde la cuarta capa en adelante. El número de canales del mapa de características se duplica aproximadamente después de cada capa con un paso de 2.
La red utiliza el error de punto final (EPE) como pérdida de entrenamiento, que es una métrica de error estándar para la estimación del flujo óptico. Su significado es la distancia euclidiana entre el vector de flujo óptico predicho y la verdad del suelo correspondiente, y se promedia sobre todos los píxeles.
El artículo elige a Adam como el método de optimización del gradiente descendente, donde los parámetros de Adam se fijan como: β1 = 0.9 y β2 = 0.999. Además, el número de mini-lotes de imágenes de entrada a la red se establece en 8 pares de imágenes. Para la tasa de aprendizaje, la estructura de red de FlowNet-C comienza a entrenarse con una tasa de aprendizaje baja de λ = 1e−6, aumenta lentamente después de 10k iteraciones para alcanzar λ = 1e−4, y luego cada 100k veces después de las primeras 300k Iterar para dividirlo por 2.
El artículo también descubrió que ampliar la imagen de entrada durante la prueba puede mejorar el rendimiento, por lo que para FlowNetS, el artículo no se amplía, pero para FlowNetC, el artículo opta por ampliar 1,25 veces. Dado que los conjuntos de datos utilizados varían mucho en términos de tipos de objetos e información de movimiento contenida, etc., una solución estándar es ajustar continuamente la red y los parámetros en el conjunto de datos de destino.
4. Implementación de código clave (tome FlowNet-C como ejemplo)
(1) Definición de estructura de red
# 下采样卷积层结构定义
def conv(batchNorm, in_planes, out_planes, kernel_size=3, stride=1):
if batchNorm:
return nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=(kernel_size-1)//2, bias=False),
nn.BatchNorm2d(out_planes),
nn.LeakyReLU(0.1,inplace=True)
)
else:
return nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=(kernel_size-1)//2, bias=True),
nn.LeakyReLU(0.1,inplace=True)
)
# 上采样反卷积层结构定义
def deconv(in_planes, out_planes):
return nn.Sequential(
nn.ConvTranspose2d(in_planes, out_planes, kernel_size=4, stride=2, padding=1, bias=False),
nn.LeakyReLU(0.1,inplace=True)
)
# 光流估计的输出层
def predict_flow(in_planes):
return nn.Conv2d(in_planes,2,kernel_size=3,stride=1,padding=1,bias=False)
# corrlation 相关性计算: 引用第三方 spatial_correlation_sample 包
def correlate(input1, input2):
out_corr = spatial_correlation_sample(input1,
input2,
kernel_size=1,
patch_size=21,
stride=1,
padding=0,
dilation_patch=2)
# collate dimensions 1 and 2 in order to be treated as a
# regular 4D tensor
b, ph, pw, h, w = out_corr.size()
out_corr = out_corr.view(b, ph * pw, h, w)/input1.size(1)
return F.leaky_relu_(out_corr, 0.1)
class FlowNetC(nn.Module):
expansion = 1
def __init__(self,batchNorm=True):
super(FlowNetC,self).__init__()
self.batchNorm = batchNorm
# image 的特征提取流(两输入图象处理流一致)
self.conv1 = conv(self.batchNorm, 3, 64, kernel_size=7, stride=2)
self.conv2 = conv(self.batchNorm, 64, 128, kernel_size=5, stride=2)
self.conv3 = conv(self.batchNorm, 128, 256, kernel_size=5, stride=2)
self.conv_redir = conv(self.batchNorm, 256, 32, kernel_size=1, stride=1)
# 收缩部分的后处理下采样流
self.conv3_1 = conv(self.batchNorm, 473, 256)
self.conv4 = conv(self.batchNorm, 256, 512, stride=2)
self.conv4_1 = conv(self.batchNorm, 512, 512)
self.conv5 = conv(self.batchNorm, 512, 512, stride=2)
self.conv5_1 = conv(self.batchNorm, 512, 512)
self.conv6 = conv(self.batchNorm, 512, 1024, stride=2)
self.conv6_1 = conv(self.batchNorm,1024, 1024)
# 扩张部分的上采样流
self.deconv5 = deconv(1024,512)
self.deconv4 = deconv(1026,256)
self.deconv3 = deconv(770,128)
self.deconv2 = deconv(386,64)
# 扩张部分的光流估计层
self.predict_flow6 = predict_flow(1024)
self.predict_flow5 = predict_flow(1026)
self.predict_flow4 = predict_flow(770)
self.predict_flow3 = predict_flow(386)
self.predict_flow2 = predict_flow(194)
# 光流上采样操作
self.upsampled_flow6_to_5 = nn.ConvTranspose2d(2, 2, 4, 2, 1, bias=False)
self.upsampled_flow5_to_4 = nn.ConvTranspose2d(2, 2, 4, 2, 1, bias=False)
self.upsampled_flow4_to_3 = nn.ConvTranspose2d(2, 2, 4, 2, 1, bias=False)
self.upsampled_flow3_to_2 = nn.ConvTranspose2d(2, 2, 4, 2, 1, bias=False)
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
kaiming_normal_(m.weight, 0.1)
if m.bias is not None:
constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
constant_(m.weight, 1)
constant_(m.bias, 0)
def forward(self, x):
x1 = x[:,:3]
x2 = x[:,3:]
# 1.提取 image1 的高层特征 (batch,h,w,3) -> (batch,h/8,w/8,256)
out_conv1a = self.conv1(x1)
out_conv2a = self.conv2(out_conv1a)
out_conv3a = self.conv3(out_conv2a)
# 2.提取 image2 的高层特征 (batch,h,w,3) -> (batch,h/8,w/8,256)
out_conv1b = self.conv1(x2)
out_conv2b = self.conv2(out_conv1b)
out_conv3b = self.conv3(out_conv2b)
# 3.进一步提取 image1 与 corr 匹配后的特征融合 (batch,h/8,w/8,256) -> (batch,h/8,w/8,32)
out_conv_redir = self.conv_redir(out_conv3a)
# 4. corr 相关性匹配计算 (batch,h/8,w/8,D*D)
out_correlation = correlate(out_conv3a,out_conv3b)
# 5. 在 channel 方向将进一步提取的特征与corr融合作为后续输入 (batch,h/8,w/8,c)
in_conv3_1 = torch.cat([out_conv_redir, out_correlation], dim=1)
# 6. 下采样操作 (batch,h/8,w/8,c) -> (batch,h/64,w/64,1024)
out_conv3 = self.conv3_1(in_conv3_1)
out_conv4 = self.conv4_1(self.conv4(out_conv3))
out_conv5 = self.conv5_1(self.conv5(out_conv4))
out_conv6 = self.conv6_1(self.conv6(out_conv5))
# 7.refinement 上采样/扩张部分
# (1)upconv1: 输出本层预测光流flow6+本层的上采样输出
# - flow6 (batch,h/64,w/64,2)
# - out_deconv5 (batch,h/32,w/32,,512)
flow6 = self.predict_flow6(out_conv6)
flow6_up = self.upsampled_flow6_to_5(flow6)
out_deconv5 = self.deconv5(out_conv6)
concat5 = torch.cat((out_conv5, out_deconv5, flow6_up), 1) # 拼接下层输入 = 本层输出deconv + 收缩部分上下文输出 + 本层输出预测光流
# (2)upconv2: 输出本层预测光流flow5+本层的上采样输出
# - flow5 (batch,h/32,w/32,2)
# - out_deconv4 (batch,h/16,w/16,256)
flow5 = self.predict_flow5(concat5)
flow5_up = self.upsampled_flow5_to_4(flow5)
out_deconv4 = self.deconv4(concat5)
concat4 = torch.cat((out_conv4, out_deconv4, flow5_up), 1)
# (3)upconv3: 输出本层预测光流flow4+本层的上采样输出
# - flow4 (batch,h/16,w/16,2)
# - out_deconv3 (batch,h/8,w/8,256)
flow4 = self.predict_flow4(concat4)
flow4_up = self.upsampled_flow4_to_3(flow4)
out_deconv3 = self.deconv3(concat4)
concat3 = torch.cat((out_conv3, out_deconv3, flow4_up), 1)
# (4)upconv4: 输出本层预测光流flow3+本层的上采样输出
# - flow3 (batch,h/8,w/8,2)
# - out_deconv2 (batch,h/4,w/4,256)
flow3 = self.predict_flow3(concat3)
flow3_up = self.upsampled_flow3_to_2(flow3)
out_deconv2 = self.deconv2(concat3)
concat2 = torch.cat((out_conv2a, out_deconv2, flow3_up), 1)
# 输出最终预测光流 flow2 (batch,h/4,w/4,2)
flow2 = self.predict_flow2(concat2)
if self.training:
return flow2,flow3,flow4,flow5,flow6
else:
return flow2
def weight_parameters(self):
return [param for name, param in self.named_parameters() if 'weight' in name]
def bias_parameters(self):
return [param for name, param in self.named_parameters() if 'bias' in name](2) Capacitación en red
# EPE Loss
def EPE(input_flow, target_flow):
return torch.norm(target_flow-input_flow,p=2,dim=1).mean()
def realEPE(output, target):
b, _, h, w = target.size()
upsampled_output = F.interpolate(output, (h,w), mode='bilinear', align_corners=False)
return EPE(upsampled_output, target)
# 多尺度训练损失(flow2~flow6的EPE损失求和权重不同)
def multiscaleEPE(network_output, target_flow, weights=None):
def one_scale(output, target):
b, _, h, w = output.size()
# 为防止 target 和 output 尺寸不一,使用插值方式来统一图像尺寸
target_scaled = F.interpolate(target, (h, w), mode='area')
return EPE(output, target_scaled)
loss = 0
for output, weight in zip(network_output, weights):
loss += weight * one_scale(output, target_flow)
return loss
# 网络训练主体框架
def run(train_loader,val_loader,model):
best_EPE = -1
# 定义 Adam 优化器
param_groups = [{'params': model.bias_parameters(), 'weight_decay': args.bias_decay},
{'params': model.weight_parameters(), 'weight_decay': args.weight_decay}]
optimizer = torch.optim.Adam(params=param_groups,lr=0.0001,betas=(0.9, 0.999))
# optimizer = torch.optim.Adam(model.parameters(), lr=1e-4, betas=(0.9, 0.999), amsgrad=False)
# 定义学习率调整策略 lr_scheduler.MultiStepLR
# milestones : epochs at which learning rate is divided by 2
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[100,150,200], gamma=0.5)
for epoch in range(args.start_epoch, args.epochs):
# 调整学习率 lr
scheduler.step()
# train for one epoch
train_loss, train_EPE = train(train_loader, model, optimizer, epoch)
print(train_loss,train_EPE)
# evaluate on validation set
with torch.no_grad():
EPE = validate(val_loader, model, epoch)
if best_EPE < 0:
best_EPE = EPE
best_EPE = min(EPE, best_EPE)
# 单轮训练
def train(train_loader, model, optimizer, epoch):
global n_iter, args
# training weight for each scale, from highest resolution (flow2) to lowest (flow6)
multiscale_weights = [0.005, 0.01, 0.02, 0.08, 0.32]
# value by which flow will be divided. Original value is 20 but 1 with batchNorm gives good results
div_flow = 20.0
losses = 0.0
flow2_EPEs = 0.0
epoch_size = len(train_loader) if args.epoch_size == 0 else min(len(train_loader), args.epoch_size)
# switch to train mode
model.train()
for i, (input, target) in enumerate(train_loader):
target = target.to(device)
input = torch.cat(input,1).to(device)
# compute output
output = model(input)
# compute loss
loss = multiscaleEPE(output, target, weights=multiscale_weights) # 多尺度训练损失
flow2_EPE = div_flow * realEPE(output[0], target) # 最终输出光流flow2的单独损失
# record loss and EPE
losses += loss.item()
flow2_EPEs += flow2_EPE.item()
# compute gradient and do optimization step
optimizer.zero_grad()
loss.backward()
optimizer.step()
n_iter += 1
if i >= epoch_size:
break
return losses, flow2_EPEs2. FlowNet 2.0 y su seguimiento
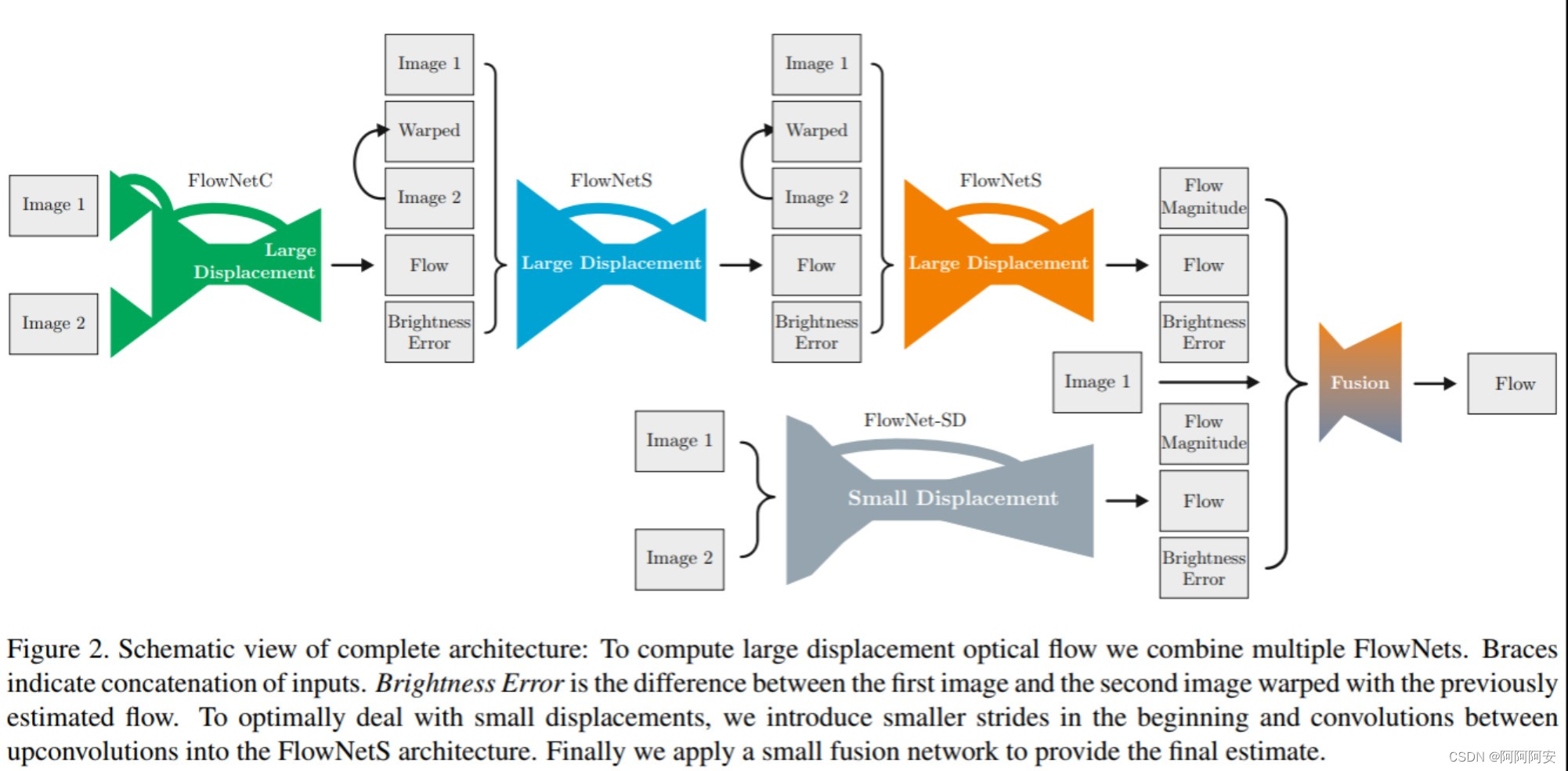
En comparación con FlowNet, FlowNet 2.0 se caracteriza por apilar múltiples subredes FlowNetC/FlowNetS para construir una estructura de red más grande, refinando gradualmente el flujo de salida y obteniendo mejores resultados.La estructura de red es la siguiente. Más tarde, con el mayor desarrollo del aprendizaje profundo de flujo óptico, surgieron una gran cantidad de nuevas redes y nuevas ideas de optimización, como PWC-Net, etc., que explicaremos y analizaremos con más detalle en artículos posteriores.