1. Breve introducción del artículo
1. Primer autor: Xiuchao Sui, Shaohua Li
2. Año de publicación: 2021
3. Publicar revista: arxiv
4. Palabras clave: flujo óptico, Transformador, autoatención, atención cruzada, volumen de correlación
5. Motivación de exploración: debido a la localidad y los pesos rígidos de la convolución, se incorpora información contextual limitada en las características de los píxeles, y la correlación calculada es tan aleatoria que la mayoría de los valores de correlación alta son coincidencias espurias, por lo que es difícil de manejar. grandes desplazamientos con desenfoque de movimiento.
- Aunque los métodos más nuevos son muy precisos en los datos de referencia, bajo ciertas condiciones, como grandes desplazamientos con desenfoque de movimiento, los errores de flujo aún pueden ser grandes.
- El paradigma actual calcula la similitud de píxeles por pares como el producto escalar de dos vectores de características convolucionales. Debido a la localidad y los pesos rígidos de la convolución, se incorpora información contextual limitada en las características de los píxeles, y las correlaciones calculadas sufren un alto nivel de aleatoriedad, de modo que la mayoría de los valores de correlación altos son coincidencias espurias. Los ruidos en las correlaciones aumentan con los ruidos en las imágenes de entrada, como la pérdida de textura, las variaciones de iluminación y el desenfoque de movimiento. Naturalmente, las correlaciones ruidosas pueden conducir a una correspondencia de imágenes fallida y a un flujo de salida inexacto. Este problema se vuelve más prominente cuando hay grandes desplazamientos. La reducción de las correlaciones ruidosas puede conducir a mejoras sustanciales en la estimación del flujo.
6. Objetivo de trabajo: resolver los problemas anteriores a través de ViT.
Una ventaja importante de Vision Transformers (ViTs) sobre la convolución es que las características del transformador codifican mejor el contexto global al atender a los píxeles con pesos dinámicos basados en su contenido. Para la tarea de flujo óptico, la información útil puede propagarse de áreas claras a áreas borrosas, o de áreas no ocluidas a áreas ocluidas, para mejorar la estimación del flujo de estas últimas. Un estudio reciente sugiere que los ViT son filtros de paso bajo que suavizan espacialmente los mapas de características. Intuitivamente, después de la autoatención del transformador, los vectores de características similares toman sumas ponderadas entre sí, suavizando las irregularidades y los ruidos de alta frecuencia.
7. Idea central: Propuesta de "Transformador de flujo óptico de atención cruzada" (CRAFT), una nueva estructura de estimación de flujo óptico. CRAFT emplea dos componentes novedosos que simplifican el cálculo de los volúmenes de correlación. Además, para probar la solidez de diferentes modelos frente a grandes movimientos, se diseña un ataque de desplazamiento de imagen para generar grandes movimientos artificiales mediante el desplazamiento de la imagen de entrada.
- Una capa transformadora de suavizado semántico fusiona las características de una imagen, haciéndolas más globales y semánticamente más suaves.
- Una capa de atención de fotogramas cruzados reemplaza al operador de producto punto para el cálculo de correlación. Proporciona un nivel adicional de filtrado de características a través de las proyecciones Query y Key, para que las correlaciones calculadas sean más precisas.
8. Resultados experimentales: SOTA
- En los puntos de referencia de Sintel (Final) y KITTI (en primer plano), CRAFT ha logrado un nuevo rendimiento de última generación (SOTA).
- Además, para probar la robustez de diferentes modelos en grandes movimientos, diseñamos un ataque de cambio de imagen que cambia las imágenes de entrada para generar grandes movimientos artificiales. A medida que aumenta la magnitud del movimiento, CRAFT funciona con solidez, mientras que dos métodos representativos, RAFT y GMA, se deterioran severamente.
9. Descarga de papel:
https://github.com/askerlee/craft
2. Proceso de implementación
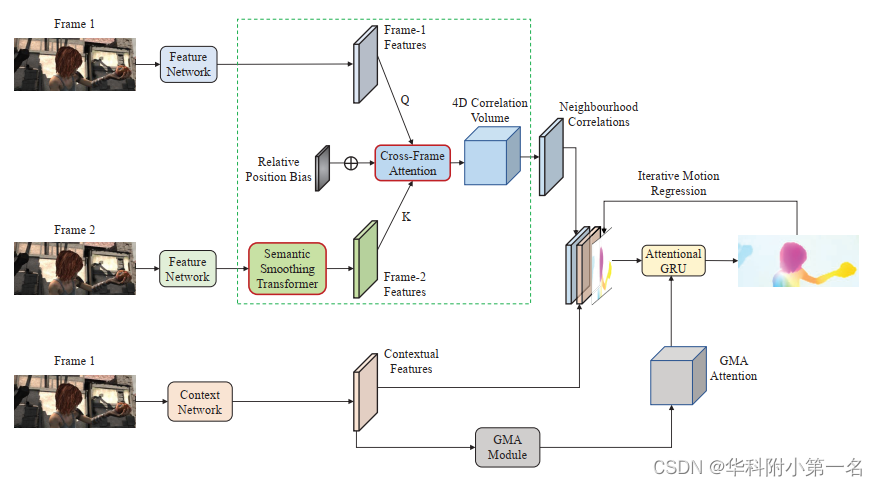
1. Descripción general de CRAFT
La red hereda la fontanería de RAFT. La contribución principal es restaurar la parte de cálculo de volumen relevante (rectángulo verde discontinuo) mediante dos nuevos componentes: un transformador suave semántico en las características del fotograma 2 y una capa de atención de fotogramas cruzados para calcular el volumen relevante, dos componentes novedosos se destacan como Cuadro con un borde rojo. Estos dos componentes ayudan a suprimir las correlaciones espurias en el volumen de correlación. El módulo GMA en la parte inferior es el módulo Global Motion Aggregation.
2. Suavizado semántico
Dadas dos imágenes consecutivas, el cuadro 1 y el cuadro 2, como entrada, el primer paso de la canalización de flujo óptico es extraer las características del cuadro utilizando una red de características convolucionales. Para mejorar las características del cuadro con un mejor contexto global, las características del cuadro 2 se transforman mediante el Transformador de suavizado semántico (SSTrans para abreviar). Para adaptarse mejor a las diferentes características, se adopta la atención extendida como SSTrans en lugar de la atención multicabezal (MHA) de uso común. Atención extendida, un sistema híbrido con mayor capacidad, muestra ventajas sobre MHA en tareas de segmentación de imágenes.
La capa de atención extendida (EA) consta de N modos (subtransformadores), que calculan N conjuntos de características que se agregan en un solo conjunto utilizando la atención de modo dinámico:

donde B(k) es la puntuación de atención del patrón y la probabilidad de atención del patrón G es el softmax de todos los B(k) a lo largo de la dimensión del patrón. La característica de salida EA(X) es una combinación lineal de todas las características del patrón. Para preservar mejor las características originales del marco, agregamos una conexión de salto ponderada aprendible con peso w1:
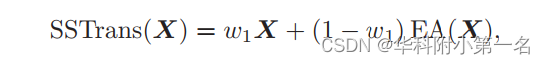
Para imponer un sesgo espacial, encontramos que las incrustaciones posicionales tradicionales no forman sesgos significativos y, en su lugar, utilizan sesgos posicionales relativos. El sesgo es una matriz B ∈ (2r+1)×(2r+1) añadida a la atención calculada, donde r es el radio que especifica la extensión local del sesgo.
Específicamente, suponga que la matriz de atención original se transforma en un tensor de cuatro dimensiones A ∈ H × W × H × W , donde H, W son la altura y el ancho de las características del marco. Para cada píxel en i,j, A(i,j) es una matriz que especifica los pesos de atención entre el píxel (i,j) y todos los píxeles en el mismo marco. Agregue un sesgo de posición relativa b a la vecindad del radio r del píxel (i,j):

En la implementación, el número de modos seleccionados es 4 y el radio r del desplazamiento de posición relativa es 7. La siguiente figura visualiza el sesgo de posición relativa de CRAFT durante el entrenamiento de Sintel. Se observaron dos patrones interesantes:
- El valor de sesgo más pequeño es alrededor de 2 en (0,0), lo que significa que al calcular una nueva característica para el píxel (i,j), este término de sesgo reducirá el peso de su propia característica en 2. Sin este término, el peso de atención del píxel (i, j) sobre sí mismo puede dominar los pesos de otros píxeles, porque el vector de características es más similar a sí mismo. Este término reduce la proporción de las características antiguas de un píxel en las características de salida combinadas, fomentando efectivamente la entrada de nueva información de otros píxeles.
- Los pesos más grandes están a 2 o 3 píxeles del píxel central, lo que significa que las características de estos píxeles circundantes se utilizan con mayor frecuencia para complementar las características del píxel central.
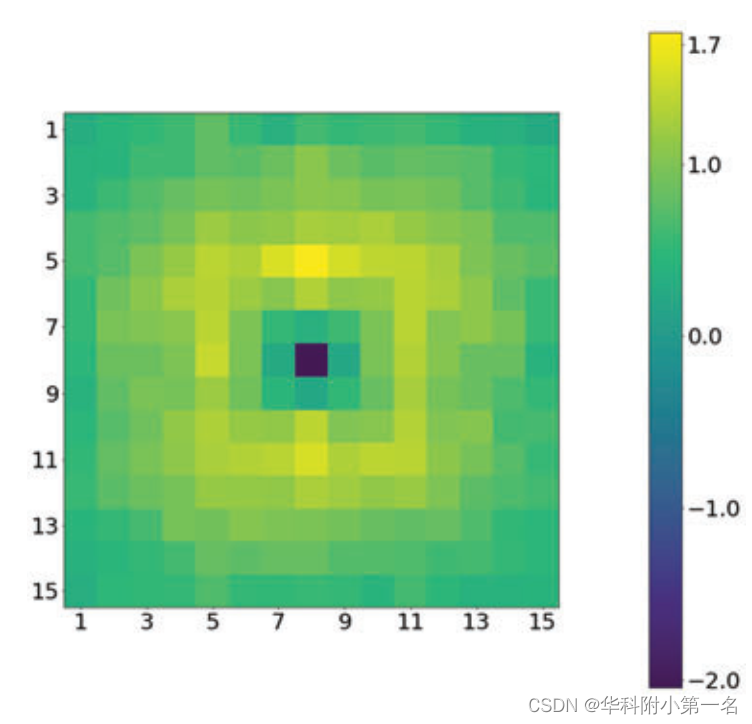
Estas dos observaciones se confirman en la siguiente figura. La siguiente figura es un mapa de calor de la autoatención del transformador SS entre el punto de consulta (rectángulo rojo) y todos los píxeles en la misma imagen. La región más densa es donde los puntos de consulta prestan la mayor atención y extraen características para enriquecerse. Establecer el sesgo de posición en 0 dará como resultado un rendimiento deficiente.

Puede ser tentador aplicar transformadores en funciones de ambos marcos. Sin embargo, en los experimentos, hacerlo resultó en un rendimiento deficiente. La hipótesis se basa en una creencia común de que la coincidencia de imágenes depende en gran medida de las características locales y estructurales de alta frecuencia (HF). Al mismo tiempo, una gran cantidad de ruido de alta frecuencia contaminará las características de la información y dificultará la coincidencia. SSTrans actúa como un filtro de paso bajo para suprimir el ruido de onda corta, pero al mismo tiempo reduce las características de HF y mejora las características de baja frecuencia (LF). Por lo tanto, el modelo aprende a compensar entre los componentes LF y HF en el cuadro 2 para coincidir con el cuadro 1. Después de aplicar SSTrans en ambos marcos, ambos marcos contienen menos componentes HF y más LF. Hacerlos coincidir puede generar muchas correlaciones espurias y dañar la precisión del flujo óptico. Esta intuición se confirma en la siguiente figura. Correlación entre los puntos de consulta en el cuadro 2 y el cuadro 1 en el conjunto de pruebas Sintel (Pase final). La imagen está recortada. La configuración estándar de CRAFT ("Single SSTrans") tiene una correlación de ruido mínima. "Double SSTrans" produjo más correlaciones de ruido.

3. Atención de fotogramas cruzados para volúmenes relacionados
En el paradigma actual, los volúmenes de correlación son la base para la coincidencia de píxeles entre fotogramas. Después de calcular las características del marco f1 y f2, el volumen de correlación se calcula como un tensor 4D ∈ H×W×H×W. Tradicionalmente, el volumen de correlación se calcula como el producto escalar por pares de f1 y f2:
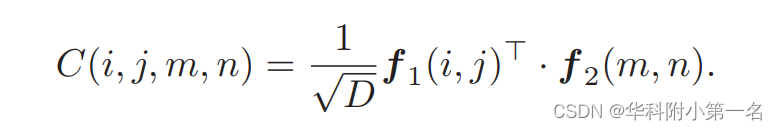
Conceptualmente, un cuerpo de correlación es esencialmente la atención cruzada en el Transformador sin transformación de características a través de consultas y proyección de claves. Las proyecciones de consulta/clave se pueden ver como filtros de características que seleccionan las características más informativas para la correlación. Además, para obtener diferentes correlaciones se pueden utilizar múltiples consultas y proyecciones clave, al igual que la Atención Extendida (EA). Se buscan correlaciones multifacéticas similares en las VCN con múltiples canales. Estos beneficios llevaron al artículo a reemplazar el producto punto con un EA simplificado:
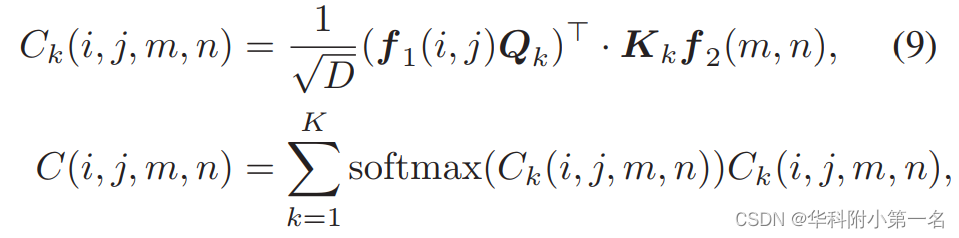
Donde Q k , K k son la consulta kth y la proyección clave respectivamente, C k (i, j, m, n) es la correlación calculada con el modo kth. El operador Softmax toma k modalidades y agrega k correlaciones. Aquí, el EA se simplifica eliminando la proyección de valor y la red de retroalimentación. Los pesos de Q k y K k se comparten porque la correlación entre los dos marcos es simétrica.
Normalización de correlación global. A veces aparecen extremos en el volumen relevante, lo que puede perturbar la coincidencia de píxeles. Para hacer coincidir un píxel, intuitivamente, el orden relativo de las correlaciones de los píxeles candidatos es más importante que el valor de correlación absoluto. En base a esto, la normalización de capas se realiza en todo el volumen de correlación para estabilizar la correlación. Empíricamente, esto da como resultado una ligera mejora en el rendimiento.
4. Función de pérdida
Igual que RAFT, empleando pérdida L1 iterativa múltiple ponderada.
5. Experimenta
5.1 Detalles de implementación
Es convincente evaluar la correlación de los pesos de atención y los objetos relacionados a través de mapas de calor. Además, Shifting Attack está diseñado para mover el desplazamiento para demostrar la superioridad de la red.
5.2 Comparación con tecnologías avanzadas
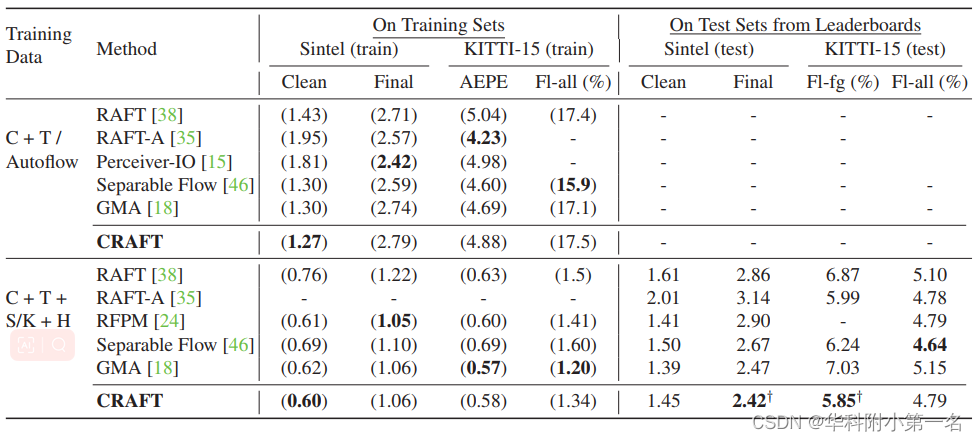
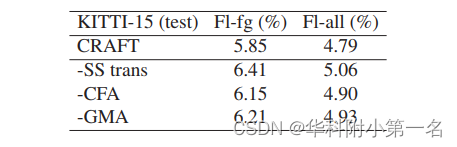
5.3 Experimento de ablación