Módulo de adquisición de datos de canal
1. 1 enlace de procesamiento de datos
1.2 Preparación del entorno
1.2.1 Script de visualización del proceso de clúster _ _ _
(1) Cree el script xcall.sh en el directorio /home/bigdata_admin/bin
[bigdata_admin@hadoop102 bin]$ vim xcall.sh
(2) Escriba el siguiente contenido en el guión
#! /bin/bash
for i in hadoop102 hadoop103 hadoop104
do
echo --------- $i ----------
ssh $i "$*"
done(3) Modificar el permiso de ejecución del script
[bigdata_admin@hadoop102 bin ]$ chmod 777 xcall.sh
(4) Guión de inicio
[bigdata_admin@hadoop102 bin ]$ xcall.sh jps
1.2.2 Instalación de Hadoop _ _
1) Pasos de instalación
levemente
2) Experiencia en proyectos
(1) multidirectorio de almacenamiento HDFS basado en la experiencia del proyecto
No es necesario configurar el proyecto de la máquina virtual, solo tenemos un disco.
1. Estado del disco del servidor del entorno de producción
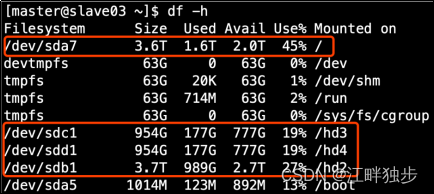
2. Configure varios directorios en el archivo hdfs-site.xml y preste atención a los derechos de acceso del disco recién montado.
La ruta donde el nodo DataNode de HDFS guarda los datos está determinada por el parámetro dfs.datanode.data.dir y su valor predeterminado es file://${hadoop.tmp.dir}/dfs/data .Si el servidor tiene varios discos, debe configurar los Los parámetros se modifican. Si el disco del servidor se muestra en la figura anterior, este parámetro debe modificarse al siguiente valor.
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///dfs/data1,file:///hd2/dfs/data2,file:///hd3/dfs/data3,file:///hd4/dfs/data4</value>
</property>Nota: Los discos montados en cada servidor son diferentes, por lo que la configuración de directorios múltiples de cada nodo puede ser inconsistente. Se puede configurar individualmente .
(2) Balance de datos de clúster de la experiencia del proyecto
1 Saldo de datos entre nodos
Habilite el comando de balance de datos.
start-balancer.sh -umbral 10
Para el parámetro 10, significa que la utilización del espacio en disco de cada nodo en el clúster no difiere en más del 10 %, lo que se puede ajustar según la situación real.
Detenga el comando de balance de datos.
stop-balancer.sh
2 Balance de datos entre discos
Generar un plan equilibrado (solo tenemos un disco, no se generará ningún plan).
balanceador de disco hdfs -plan hadoop103
Ejecutar un plan equilibrado.
balanceador de disco hdfs -ejecutar hadoop103.plan.json
Ver el estado de ejecución de la tarea de saldo actual.
balanceador de disco hdfs -consulta hadoop103
Cancelar la tarea de saldo.
balanceador de disco hdfs -cancel hadoop103.plan.json
(3) Ajuste de parámetros de Hadoop basado en la experiencia del proyecto
1. Ajuste de parámetros HDFS hdfs-site.xml
The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes.
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。
对于大集群或者有大量客户端的集群来说,通常需要增大参数dfs.namenode.handler.count的默认值10。
<property>
<name>dfs.namenode.handler.count</name>
<value>10</value>
</property>dfs.namenode.handler.count=20*log(e)(ClusterSize), por ejemplo, cuando el tamaño del clúster es 8, este parámetro se establece en 41. Este valor se puede calcular mediante un código Python simple, el código es el siguiente.
[bigdata_admin@hadoop102 ~] $ pitón
Python 2.7.5 (predeterminado, 11 de abril de 2018, 07:36:10)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] en linux2
Escriba "ayuda", "derechos de autor", "créditos" o "licencia" para obtener más información.
>>> importar matemáticas
>>> print int(20*math.log(8))
41
>>> salir()
2. Ajuste del parámetro YARN yarn-site.xml
Descripción del escenario : Un total de 7 máquinas, cientos de millones de datos por día, fuente de datos->Flume->Kafka->HDFS->Hive
Problemas a los que se enfrenta : HiveSQL se usa principalmente para estadísticas de datos, no hay sesgo de datos, se han fusionado archivos pequeños, la JVM está habilitada para su reutilización, la E/S no está bloqueada y se usa menos del 50 % de la memoria. Pero todavía funciona muy lentamente, y cuando el volumen de datos alcanza su punto máximo, todo el clúster se cae. En base a esta situación, ¿hay algún plan de optimización?
Solución :
Utilización de memoria insuficiente. Esto generalmente se debe a dos configuraciones de Yarn, el tamaño máximo de memoria que puede solicitar una sola tarea y el tamaño de memoria disponible de un solo nodo de Hadoop. El ajuste de estos dos parámetros puede mejorar la utilización de la memoria del sistema.
(a) hilo.nodemanager.resource.memory-mb
Indica la cantidad total de memoria física que YARN puede usar en este nodo. El valor predeterminado es 8192 (MB). Tenga en cuenta que si el recurso de memoria de su nodo no es suficiente para 8 GB, debe reducir este valor y YARN no detectará de manera inteligente el memoria física de la cantidad total del nodo.
(b) hilo.programador.asignación máxima-mb
La cantidad máxima de memoria física que puede solicitar una sola tarea, el valor predeterminado es 8192 (MB).
1.2.3 Instalación de Zookeeper _
1 ) Pasos de instalación
levemente
2 ) Script de inicio y parada del clúster ZK
(1) Cree un script en el directorio /home/bigdata_admin/bin de hadoop102
[bigdata_admin@hadoop102 bin]$ vim zk.sh
Escriba lo siguiente en el guión.
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
};;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
};;
"status"){
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"
done
};;
esac(2) Aumentar el permiso de ejecución del script
[bigdata_admin@hadoop102 bin]$ chmod 777 zk.sh
(3) Script de inicio del clúster de Zookeeper
[módulo bigdata_admin@hadoop102]$ zk.sh inicio
(4) Script de parada del grupo Zookeeper
[módulo bigdata_admin@hadoop102]$ zk.sh parada
1.2.4 Instalación de Kafka _ _ _
1 ) Pasos de instalación
levemente
1.2.5 Instalación de canal _ _
De acuerdo con la planificación del canal de recolección, se debe implementar un Flume en los tres nodos de hadoop102, hadoop103 y hadoop104 respectivamente. Puede consultar los siguientes pasos para instalarlo primero en Hadoop 102 y luego distribuirlo.
1) Pasos de instalación
levemente
2) Distribuya Flume a hadoop 103 , hadoop 104
[bigdata_admin@hadoop102 ~]$ xsync /opt/module/flume/
3) Experiencia en proyectos
(1) Ajuste de la memoria del montón
La memoria del montón de Flume generalmente se establece en 4G o superior, y la configuración es la siguiente:
Modifique el archivo /opt/module/flume/conf/flume-env.sh y configure los siguientes parámetros (el entorno de la máquina virtual aún no está configurado)
exportar JAVA_ OPTS ="-Xms 4096 m -Xmx 4096 m -Dcom.sun.management.jmxremote"
Nota:
-Xms indica el tamaño mínimo de JVM Heap (memoria de montón), asignación inicial;
-Xmx indica el tamaño máximo permitido de JVM Heap (memoria de montón), asignado bajo demanda.
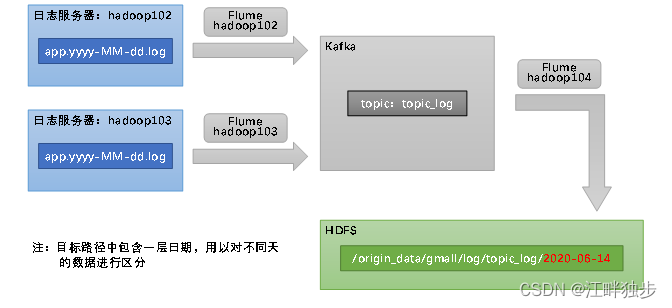
1.3 Canal de recogida de troncos
1.3.1 Descripción general de la configuración del canal de recolección de registros
De acuerdo con el plan, los archivos de registro del comportamiento del usuario que se recopilarán se distribuyen en dos servidores de registro, hadoop102 y hadoop103, por lo que la recopilación de registros Flume debe configurarse en dos nodos, hadoop102 y hadoop103. Recopilación de registros Flume necesita recopilar el contenido de los archivos de registro, verificar el formato de registro (JSON) y luego enviar los registros verificados a Kafka.
Aquí puede elegir TaildirSource y KafkaChannel, y configurar interceptores de verificación de registros.
Las razones para elegir TailDirSource y KafkaChannel son las siguientes:
1)TailDirFuente
Ventajas de TailDirSource sobre ExecSource y SpoolingDirectorySource.
TailDirSource: resumen de punto de interrupción, multidirectorio . Antes de Flume 1.6, era necesario personalizar la fuente para registrar la ubicación del archivo cada vez que se leía , a fin de realizar la reanudación del punto de interrupción.
ExecSource puede recopilar datos en tiempo real, pero los datos se perderán si Flume no se está ejecutando o si falla el comando Shell.
SpoolingDirectorySource supervisa directorios y admite cargas reanudables.
2) Canal Café
El uso de Kafka Channel ahorra Sink y mejora la eficiencia.
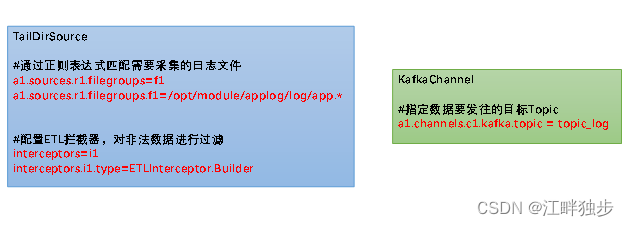
La configuración clave de Flume de recopilación de registros es la siguiente:
1.3.2 Recopilación de registros Práctica de configuración de canales
1) Cree un archivo de configuración de Flume
(1) Cree file_to_kafka.conf en el directorio de trabajo de Flume en el nodo hadoop102.
[bigdata_admin@hadoop102 flume]$ mkdir trabajo
[bigdata_admin@hadoop102 flume]$ trabajo vim/file_to_kafka.conf
El contenido del archivo de configuración es el siguiente:
#为各组件命名
a1.sources = r1
a1.channels = c1
#描述source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.bigdata_admin.flume.interceptor.ETLInterceptor$Builder
#描述channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
#绑定source和channel以及sink和channel的关系
a1.sources.r1.channels = c1(2) Distribuir archivos de configuración a hadoop103
[bigdata_admin@hadoop102 flume]$ trabajo xsync
2 ) Escriba un interceptor Flume
(1) Cree un canal-interceptor del proyecto Maven
(2) Crear paquete: com.bigdata_admin.flume.interceptor
(3) Agregue la siguiente configuración al archivo pom.xml
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>(4) Cree la clase JSONUtils en el paquete com.bigdata_admin.flume.interceptor
package com.bigdata_admin.flume.interceptor;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONException;
public class JSONUtils {
public static boolean isJSONValidate(String log){
try {
JSON.parse(log);
return true;
}catch (JSONException e){
return false;
}
}
}(5) Cree una clase ETLInterceptor en el paquete com.bigdata_admin.flume.interceptor
package com.bigdata_admin.flume.interceptor;
import com.alibaba.fastjson.JSON;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
public class ETLInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
byte[] body = event.getBody();
String log = new String(body, StandardCharsets.UTF_8);
if (JSONUtils.isJSONValidate(log)) {
return event;
} else {
return null;
}
}
@Override
public List<Event> intercept(List<Event> list) {
Iterator<Event> iterator = list.iterator();
while (iterator.hasNext()){
Event next = iterator.next();
if(intercept(next)==null){
iterator.remove();
}
}
return list;
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new ETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
@Override
public void close() {
}
}(6) Embalaje
flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar
(7) Debe colocar el paquete empaquetado en la carpeta /opt/module/flume/lib de hadoop102 y hadoop103.
1.3.3 Recolección de troncos Prueba de canal
1) Inicie los clústeres de Zookeeper y Kafka
2) Inicie la recopilación de registros Flume de hadoop 102
[bigdata_admin@hadoop102 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf -Dflume.root.logger=info,console
3) Inicie un consumidor de consola Kafka
[bigdata_admin@hadoop102 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic topic_log
4 ) Generar datos simulados
[bigdata_admin@hadoop102 ~]$ lg.sh
5 ) Observar si los consumidores de Kafka pueden consumir datos
1.3.4 Secuencia de comandos de inicio y detención de Flume para la recopilación de registros
1 ) Distribuya los interceptores y los archivos de configuración de Flume de recopilación de registros
Si pasa la prueba anterior, debe enviar una copia del archivo de configuración de Flume y el paquete jar del interceptor del nodo hadoop102 a otro servidor de registro.
[bigdata_admin@hadoop102 flume]$ scp -r trabajo hadoop103:/opt/module/flume/
[bigdata_admin@hadoop102 flume]$ scp lib/flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar hadoop103:/opt/module/flume/lib/
2) Para mayor comodidad, aquí hay una secuencia de comandos para iniciar y detener el proceso Flume de recopilación de registros
(1) Cree el script f1.sh en el directorio /home/bigdata_admin/bin del nodo hadoop102
[bigdata_admin@hadoop102 bin]$ vim f1.sh
Complete el siguiente contenido en el script.
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103
do
echo " --------启动 $i 采集flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf/ -f /opt/module/flume/job/file_to_kafka.conf >/dev/null 2>&1 &"
done
};;
"stop"){
for i in hadoop102 hadoop103
do
echo " --------停止 $i 采集flume-------"
ssh $i "ps -ef | grep file_to_kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "
done
};;
esac(2) Aumentar el permiso de ejecución del script
[bigdata_admin@hadoop102 bin]$ chmod 777 f1.sh
(3) inicio f1
[bigdata_admin@hadoop102 module]$ f1.sh inicio
(4) parada f2
[bigdata_admin@hadoop102 module]$ f1.sh parada
1.4 registro de consumo Flume
1.4.1 Resumen de la configuración del canal de consumo de troncos
De acuerdo con el plan, Flume necesita enviar los datos topic_log en Kafka a HDFS. Y distinga los registros de comportamiento del usuario generados todos los días y envíe los datos de diferentes días a las rutas de diferentes días en HDFS.
Aquí seleccione KafkaSource, FileChannel, HDFSSink.
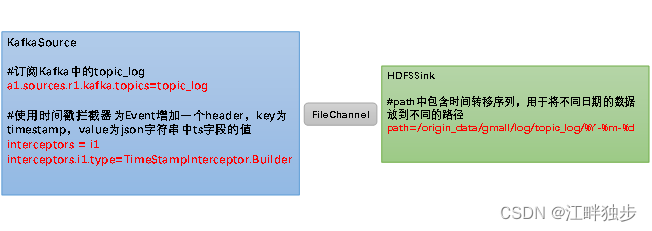
La configuración clave es la siguiente:
1.4.2 Práctica de configuración de canal de consumo de troncos
1) Cree un archivo de configuración de Flume
Cree kafka_to_hdfs_log.conf en el directorio de trabajo de Flume en el nodo hadoop104.
[bigdata_admin@hadoop104 flume]$ trabajo vim/kafka_to_hdfs_log.conf
El contenido del archivo de configuración es el siguiente:
## 组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
## source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.bigdata_admin.flume.interceptor.TimeStampInterceptor$Builder
## channel1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log-
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1Nota: optimización de la configuración
(1) optimización de FileChannel
Al configurar dataDirs para apuntar a varias rutas , cada ruta corresponde a un disco duro diferente, lo que aumenta el rendimiento de Flume.
La descripción oficial es la siguiente:
Lista de directorios separados por comas para almacenar archivos de registro. El uso de varios directorios en discos independientes puede mejorar el rendimiento del canal de archivos
checkpointDir y backupCheckpointDir también deben configurarse en los directorios correspondientes a diferentes discos duros tanto como sea posible para garantizar que después de que se rompa el punto de control, puede usar rápidamente backupCheckpointDir para restaurar datos.
(2) Optimización del sumidero HDFS
①¿Cuál es el impacto de almacenar una gran cantidad de archivos pequeños en HDFS?
Nivel de metadatos: cada archivo pequeño tiene una parte de los metadatos, incluida la ruta del archivo, el nombre del archivo, el propietario, el grupo, el permiso, el tiempo de creación, etc., todos los cuales se almacenan en la memoria de Namenode. Por lo tanto, demasiados archivos pequeños ocuparán una gran cantidad de memoria en el servidor de Namenode, lo que afectará el rendimiento y la vida útil de Namenode.
Nivel de computación: De manera predeterminada, MR habilitará un cálculo de tarea de mapa para cada archivo pequeño, lo que afecta en gran medida el rendimiento de la computación. También afecta los tiempos de búsqueda del disco.
②Procesamiento de archivos pequeños HDFS
La configuración predeterminada oficial de estos tres parámetros generará archivos pequeños después de escribir en HDFS, hdfs.rollInterval, hdfs.rollSize, hdfs.rollCount.
Según los efectos completos de los parámetros anteriores hdfs.rollInterval=3600, hdfs.rollSize=134217728, hdfs.rollCount=0, el efecto es el siguiente:
- Cuando el archivo alcance los 128M, comenzará a generar un nuevo archivo
- Cuando el archivo se crea durante más de 3600 segundos, se generará un nuevo archivo de forma continua
2 ) Escriba un interceptor Flume
(1) Cree una clase TimeStampInterceptor en el paquete com.bigdata_admin.flume.interceptor
package com.bigdata_admin.flume.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class TimeStampInterceptor implements Interceptor {
private ArrayList<Event> events = new ArrayList<>();
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);
JSONObject jsonObject = JSONObject.parseObject(log);
String ts = jsonObject.getString("ts");
headers.put("timestamp", ts);
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
events.clear();
for (Event event : list) {
events.add(intercept(event));
}
return events;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TimeStampInterceptor();
}
@Override
public void configure(Context context) {
}
}
}(2) Reempaquetado
flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar
(3) Primero debe colocar el paquete en la carpeta /opt/module/flume/lib de hadoop104.
1.4.3 Prueba de canal de consumo de troncos
1) Inicie los clústeres de Zookeeper y Kafka
2) Iniciar la recopilación de registros Flume
[bigdata_admin@hadoop102 ~]$ f1.sh inicio
3) Inicie el registro de consumo Flume de hadoop 104
[bigdata_admin@hadoop104 flume]$ bin/flume-ng agent -n a1 -c conf/ -f job/kafka_to_hdfs_log.conf -Dflume.root.logger=info,console
4 ) Generar datos simulados
[bigdata_admin@hadoop102 ~]$ lg.sh
5 ) Observar si los datos aparecen en HDFS
1 .4 .4 Script de inicio y parada del canal para el consumo de troncos
Si pasa las pruebas anteriores, por conveniencia, cree un script de inicio y parada para Flume aquí.
1 ) Cree el script f2.sh en el directorio /home/bigdata_admin/bin del nodo hadoop102
[bigdata_admin@hadoop102 bin]$ vim f2.sh
Complete el siguiente contenido en el script:
#!/bin/bash
case $1 in
"start")
echo " --------启动 hadoop104 日志数据flume-------"
ssh hadoop104 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/kafka_to_hdfs_log.conf >/dev/null 2>&1 &"
;;
"stop")
echo " --------停止 hadoop104 日志数据flume-------"
ssh hadoop104 "ps -ef | grep kafka_to_hdfs_log | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
;;
esac2 ) Aumentar el permiso de ejecución del script
[bigdata_admin@hadoop102 bin]$ chmod 777 f2.sh
3 ) inicio f2
[bigdata_admin@hadoop102 module]$ f2.sh inicio
4 ) parada f2
[módulo bigdata_admin@hadoop102]$ f2.sh parada
1.5 Script de inicio/ detención del canal de adquisición
1 ) Cree el script cluster.sh en el directorio /home/bigdata_admin/bin
[bigdata_admin@hadoop102 bin]$ vim clúster.sh
Complete el siguiente contenido en el script:
#!/bin/bash
case $1 in
"start"){
echo ================== 启动 集群 ==================
#启动 Zookeeper集群
zk.sh start
#启动 Hadoop集群
cdh.sh start
#启动 Kafka采集集群
kf.sh start
#启动 Flume采集集群
f1.sh start
#启动 Flume消费集群
f2.sh start
};;
"stop"){
echo ================== 停止 集群 ==================
#停止 Flume消费集群
f2.sh stop
#停止 Flume采集集群
f1.sh stop
#停止 Kafka采集集群
kf.sh stop
#停止 Hadoop集群
cdh.sh stop
#循环直至 Kafka 集群进程全部停止
#xcall.sh 是我们写的脚本,作用是在集群的每个节点都执行一次后面的命令。此处 xcall.sh jps 的作用是查看所有节点的 java 进程
#grep Kafka 的作用是过滤所有 Kafka 进程
#wc -l 是统计行数,每个进程会在 jps 中单独占据一行,因此行数等于进程数
#$()的作用是将括号内命令的执行结果作为值取出来
#因此如下命令的作用是统计集群未停止的 Kafka 进程数然后将进程数赋值给 kafka_count 变量
kafka_count=$(xcall.sh jps | grep Kafka | wc -l)
#判断 kafka_count 变量的值是否大于零,如果是则说明仍有未停止的 Kafka 进程,此时不能停止 Zookeeper,因为 Kafka 的工作要依赖于 Zookeeper 的节点,如果在 Kafka 进程停止之前停止了 Zookeeper,可能会导致本次 Kafka 进程无法正常停止。所以当 Kafka 进程数大于零时进入循环,休眠一秒,然后重新统计 Kafka 进程数,直至 Kafka 进程数为零跳出循环,才能进行下一步(停止 Zookeeper 集群)
while [ $kafka_count -gt 0 ]
do
sleep 1
kafka_count=$( xcall.sh jps | grep Kafka | wc -l)
echo "当前未停止的 Kafka 进程数为 $kafka_count"
done
#停止 Zookeeper集群
zk.sh stop
};;
esac2 ) Aumentar el permiso de ejecución del script
[bigdata_admin@hadoop102 bin]$ chmod u+x clúster.sh
3 ) secuencia de comandos de inicio de clúster de clúster
[módulo bigdata_admin@hadoop102]$ cluster.sh inicio
4 ) secuencia de comandos de parada de clúster
[módulo bigdata_admin@hadoop102]$ cluster.sh parada