El papel de la función de pérdida
La función de pérdida es una función que se utiliza para medir la diferencia entre el valor predicho del modelo y el valor real. Es una función de valor real no negativa y debe ser derivable en todas partes.
En la fase de entrenamiento del modelo, el valor predicho del modelo se obtiene a través de la propagación hacia adelante. En este momento, la diferencia entre el valor predicho y el valor real se obtiene utilizando la función de pérdida, y luego el gradiente de todos los parámetros de peso. a la desviación se obtiene por retropropagación, y la función de optimización se usa para actualizar. El gradiente hace que el valor predicho se acerque más al valor real, para lograr el propósito de aprendizaje.
Análisis de la entropía cruzada desde la perspectiva de la entropía
Dado que la distribución real de los datos etiquetados por humanos puede ser inconsistente con el modelo de probabilidad de la distribución predicha del modelo, se necesita un sistema unificado para evaluar cuantitativamente cada modelo, y el método específico es la entropía. La entropía es un concepto en la teoría de la información. Para entender cómo la entropía evalúa la diferencia entre dos modelos (sistemas) probabilísticos, debe comprender los siguientes conceptos.
cantidad de información
La idea básica de la cantidad de información es el grado de dificultad de un evento desde la incertidumbre hasta la certeza, cuanto menor sea la probabilidad de que ocurra un evento, mayor será la cantidad de información que porta.
Suponiendo que X es una variable aleatoria discreta cuyo conjunto de valores es ,  entonces la cantidad de información que define el evento
entonces la cantidad de información que define el evento  es:
es: 
donde es la probabilidad del valor de  la variable , y el rango de valores es [0, 1]. menor es la probabilidad del evento cuanto mayor es la cantidad de información, por lo que el factor constante es -1, de manera que cuando la probabilidad tiende a 0, la cantidad de información tiende a infinito, y cuando la probabilidad tiende a 1, la cantidad de información tiende a a 0.
la variable , y el rango de valores es [0, 1]. menor es la probabilidad del evento cuanto mayor es la cantidad de información, por lo que el factor constante es -1, de manera que cuando la probabilidad tiende a 0, la cantidad de información tiende a infinito, y cuando la probabilidad tiende a 1, la cantidad de información tiende a a 0.



entropía de la información
La entropía de la información, también llamada entropía, se utiliza para representar la expectativa de toda la información en el sistema . En un sistema, cuanto mayor es la entropía, mayor es la incertidumbre del sistema y mayor el grado de caos. La expresión de la entropía es la siguiente: 
Para profundizar más en la comprensión de la entropía, tomamos como ejemplo el equipo que gana el campeonato, a continuación se muestran dos sistemas de probabilidad, el primero tiene la misma probabilidad de que cada equipo gane el campeonato, y el segundo Las probabilidades de ganar el campeonato no son iguales. Como puede verse en la siguiente figura, el valor de la entropía es la suma de la probabilidad de ocurrencia de todos los eventos en el sistema multiplicada por la cantidad correspondiente de información.
divergencia KL
Si  hay dos distribuciones de probabilidad independientes que suman
hay dos distribuciones de probabilidad independientes que suman  la misma variable aleatoria
la misma variable aleatoria  , entonces la divergencia KL se puede usar para medir qué tan diferentes son las dos distribuciones.
, entonces la divergencia KL se puede usar para medir qué tan diferentes son las dos distribuciones.
En el aprendizaje automático, a menudo se usa  para representar la distribución real de muestras y
para representar la distribución real de muestras y  para representar la distribución prevista del modelo. Cuanto menor sea la divergencia KL, más cercana será la suma de la representación,
para representar la distribución prevista del modelo. Cuanto menor sea la divergencia KL, más cercana será la suma de la representación,  y la aproximación infinita se puede realizar a través de parámetros de entrenamiento y actualización . La fórmula de cálculo de la divergencia KL es la siguiente: La divergencia KL tiene las siguientes dos propiedades:
y la aproximación infinita se puede realizar a través de parámetros de entrenamiento y actualización . La fórmula de cálculo de la divergencia KL es la siguiente: La divergencia KL tiene las siguientes dos propiedades:



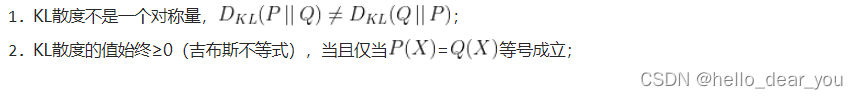
entropía cruzada
La fórmula de divergencia KL anterior se simplifica aún más: 
la primera H(p(xi ) ) es la entropía de información de la distribución real, y la última es la entropía cruzada. Entonces KL divergencia = entropía cruzada - entropía de la información, es decir, la entropía cruzada es igual a: 
en la fase de entrenamiento del modelo, los datos de entrada y las etiquetas a menudo se determinan, luego se determina la distribución de probabilidad real P(X), por lo que la la entropía de la información es una constante aquí .
Dado que el valor de la divergencia KL representa la diferencia entre la distribución de probabilidad real P(x) y la distribución de probabilidad predicha Q(x), cuanto menor sea el valor, menor será la diferencia entre las dos distribuciones, por lo que el objetivo es minimizar el KL gasto de divergencia. Sin embargo, dado que la entropía cruzada es igual a la divergencia KL más una constante, y la fórmula es más fácil que la divergencia KL, minimizar la divergencia KL es consistente con minimizar la entropía cruzada y optimizar la entropía cruzada requiere menos cálculo que optimizar la divergencia KL.
Función de pérdida de entropía cruzada
La entropía cruzada es un concepto en la teoría de la información que está estrechamente relacionado con la distribución de probabilidad de eventos. Por lo tanto, antes de usar la función de pérdida de entropía cruzada, debe usar softmax o sigmoid para convertir la salida del modelo en un valor de probabilidad. Pero cuándo usar softmax y cuándo usar sigmoid deben discutirse en las siguientes dos situaciones:
Tareas de clasificación de una sola etiqueta
La tarea de clasificación de etiqueta única se refiere al objetivo de una sola categoría en cada muestra de entrada, como la tarea de clasificación de ImageNet, Cifar, MNIST y otros conjuntos de datos.
Como se muestra en la siguiente figura, tomando como ejemplo la tarea de clasificación del conjunto de datos de reconocimiento de datos escritos a mano del MNIST, explique el proceso de cálculo específico de la pérdida:
Suponiendo que el número de muestras es "1", entonces la distribución real debería ser:
[1, 0,0,0,0,0,0,0,0,0]
, si la distribución de salida de la red es:
[7, 1, 4, 3, 4, 2, 1, 4, 5, 2]
y luego enviarlo a softmax, la distribución de probabilidad de la salida es:
[0,7567, 0,0019, 0,0377, 0,0139, 0,0377, 0,0051, 0,0019, 0,0377,
0,1024, 0,0051]
La probabilidad de salida de softmax representa la probabilidad de cada categoría incluida en la muestra, y la apariencia de cada categoría no es independiente entre sí, por lo que la suma de los valores de probabilidad de todas las categorías es 1 .
Para una sola muestra con una sola etiqueta, suponiendo que la distribución real es  , la distribución de salida de la red es
, la distribución de salida de la red es  y el número total de categorías es
y el número total de categorías es  , la fórmula de cálculo de la función de pérdida de entropía cruzada es la siguiente:
, la fórmula de cálculo de la función de pérdida de entropía cruzada es la siguiente: 
Por lo tanto, en este ejemplo, la función de pérdida de cálculo es: 

Por lo tanto, para un lote, la función de pérdida de entropía cruzada para la tarea de clasificación de etiqueta única n es:
Tarea de clasificación de etiquetas múltiples
Tareas de clasificación de etiquetas múltiples, es decir, una muestra contiene etiquetas múltiples, es decir, una variedad de categorías diferentes de objetivos. Por ejemplo, las muestras en VOC, COCO y otros conjuntos de datos contienen múltiples objetivos de diferentes categorías. A diferencia de la tarea de clasificación de una sola etiqueta que usa softmax, la tarea de clasificación de etiquetas múltiples usa la función sigmoidea para convertir la salida de la red en una probabilidad, indicando la probabilidad de que la imagen contenga este tipo de objeto. Sin embargo, para tareas de clasificación de etiquetas múltiples, cada clase es independiente entre sí, por lo que la suma de los valores de probabilidad de salida final de la red puede no ser necesariamente igual a 1. En 
tareas de clasificación de etiquetas múltiples, si cada clase es analizada por separado, la distribución verdadera  es una distribución 0-1, mientras que la distribución de predicción del modelo
es una distribución 0-1, mientras que la distribución de predicción del modelo  puede entenderse como la probabilidad de que la etiqueta sea 1. Por lo tanto, para una muestra única de etiquetas múltiples, suponiendo que la distribución real es
puede entenderse como la probabilidad de que la etiqueta sea 1. Por lo tanto, para una muestra única de etiquetas múltiples, suponiendo que la distribución real es  , la distribución de salida de la red es
, la distribución de salida de la red es  y el número total de categorías es
y el número total de categorías es  , la fórmula de cálculo de la función de pérdida de entropía cruzada es la siguiente:
, la fórmula de cálculo de la función de pérdida de entropía cruzada es la siguiente: 
Por lo tanto, para un lote , la función de pérdida de entropía cruzada de la tarea de clasificación n de etiquetas múltiples para:
Análisis de la función de pérdida de tareas de clasificación multietiqueta desde la perspectiva de la función de verosimilitud
De la introducción anterior sabemos que el valor de salida de cada neurona se convierte en una probabilidad a través de la función sigmoidea, indicando la probabilidad de que la imagen contenga este tipo de objeto, y las predicciones de cada categoría son independientes entre sí .
En una muestra única de etiquetas múltiples, si cada categoría se analiza de forma independiente, cada categoría es una tarea de clasificación binaria y la distribución real  es una distribución 0-1 (distribución de Bernoulli). Por lo tanto, podemos derivar la siguiente fórmula:
es una distribución 0-1 (distribución de Bernoulli). Por lo tanto, podemos derivar la siguiente fórmula: 
Combinando los dos casos anteriores, obtenemos: 
Al mismo tiempo, dado que las predicciones de cada categoría están distribuidas de manera independiente e idéntica, la función de verosimilitud se obtiene de la siguiente manera: 
tomar el logaritmo de la función de verosimilitud y luego agregue El signo negativo se convierte en la probabilidad logarítmica minimizada, es decir, la función de pérdida de entropía cruzada de una sola muestra es la siguiente: