Directorio de artículos
prefacio

Jetson Nano es una pequeña computadora lanzada por NVIDIA. Tiene un excelente rendimiento, bajo consumo de energía y tamaño pequeño. Es muy adecuada para aplicaciones de aprendizaje profundo en sistemas embebidos y dispositivos de borde. Jetson Nano está equipado con el procesador Tegra X1 de NVIDIA, que tiene 4 núcleos de CPU ARM Cortex-A57 y 128 núcleos de GPU NVIDIA Maxwell, que pueden proporcionar hasta 472 GFLOPS de potencia informática y permitir el razonamiento de aprendizaje profundo en tiempo real.
Jetson Nano es compatible con una variedad de marcos de aprendizaje profundo, como TensorFlow, PyTorch, Caffe y MXNet, y puede realizar entrenamiento y razonamiento de modelos de aprendizaje profundo al instalar los paquetes de software correspondientes. Jetson Nano también proporciona una gran cantidad de interfaces de hardware, como GPIO, I2C, SPI, UART y CSI, etc., que pueden conectar fácilmente varios sensores y actuadores para realizar un control inteligente y adquisición de datos.
1. Instalación de anaconda
En primer lugar, se instala Anaconda para resolver un problema de conflicto ambiental, ya que todos los paquetes de funciones de ROS se desarrollan en base a Python2.7, y los marcos de trabajo de aprendizaje profundo convencionales actuales se desarrollan en base a Python3, y las diferentes versiones de Python conducirán a la compatibilidad. Los problemas sexuales dan lugar a un montón de informes de errores, por lo que la mejor solución es crear un entorno virtual de Python3 en Anaconda, que ejecuta el marco principal de aprendizaje profundo, para no entrar en conflicto con ROS.
Hay muchos blogs que dicen que primero debe instalar ROS y luego instalar Anaconda.Acabo de instalar ROS Melodic primero y aún no he instalado Anaconda3.
Sitio web oficial de Anaconda: https://www.anaconda.com/products/individual
Otras versiones: https://repo.anaconda.com/archive/
descargarAnaconda3-2022.05-Linux-aarch64.sh, el directorio descargado es /home/nvidia/, abra una terminal en este directorio y ejecute el archivo .sh
bash Anaconda3-2022.05-Linux-aarch64.sh
El siguiente paso es presionar Enter hasta el final para confirmar y seleccionar sí donde se requiere sí/no. Una vez completada la instalación, edite ~/.bashrc para configurar las variables de entorno de conda y agregue lo siguiente después del archivo ~/.bashrc
sudo vim ~/.bashrc
Luego fuente la variable de entorno
source ~/.bashrc
Abra la terminal y verifique la versión de conda.Si la información de la versión de conda se muestra correctamente, significa que se ha instalado Anaconda.
conda --version
Pero esto entrará en conflicto con ROS, porque Anaconda3 también es un entorno de desarrollo basado en Python3, por lo que es necesario comentar la configuración anterior en el archivo ~/.bashrc
sudo vim ~/.bashrc

source ~/.bashrc
Vuelva a abrir el terminal, luego inicie el entorno Anaconda3 y verifique la versión de Python. Independientemente de la versión de Python y Python3 ingresada en el terminal, solo aparecerá el número de versión de Python3 en el entorno. Este entorno virtual no se verá afectado por Python2.7
source ~/anaconda3/bin/activate
Ejecute el siguiente comando para cerrar el entorno virtual de Anaconda
conda deactivate
2. Configuración del entorno Pytorch y TensorFlow

Tanto TensorFlow como PyTorch son actualmente marcos de trabajo de aprendizaje profundo muy populares, y ambos brindan una gran cantidad de herramientas y API para ayudar a los desarrolladores a construir, entrenar e implementar rápidamente modelos de aprendizaje profundo.
TensorFlow es un marco de aprendizaje profundo de código abierto desarrollado por Google, que tiene una amplia gama de aplicaciones y soporte comunitario. TensorFlow se calcula principalmente en función de gráficos de cálculo estáticos. Puede realizar cálculos distribuidos en varios dispositivos y admite la aceleración de GPU, lo que lo hace muy adecuado para tareas de aprendizaje profundo a gran escala. TensorFlow también proporciona API de alto nivel, como Keras, y la herramienta de visualización TensorBoard, etc., lo que facilita la construcción y depuración de modelos.
PyTorch es un marco de aprendizaje profundo de código abierto desarrollado por Facebook. Es un marco gráfico computacional dinámico que permite una construcción y depuración más flexibles de modelos de aprendizaje profundo. PyTorch también es compatible con la aceleración de GPU y la computación distribuida, y proporciona muchas API y herramientas avanzadas, como torchvision y torchaudio, que facilitan la construcción y el entrenamiento de modelos.
Por el contrario, TensorFlow es más adecuado para tareas de aprendizaje profundo a gran escala, como la clasificación de imágenes y el procesamiento del lenguaje natural. PyTorch es más adecuado para tareas de aprendizaje profundo orientadas a la investigación, como la exploración y experimentación de nuevos modelos.
Antes de instalar TensorFlow primero, cree un entorno virtual de Python3 y abra la terminal
conda create -n mydl python=3.6
Activar el entorno virtual recién creado
conda activate mydl
Según el tutorial oficial de Nvidia, la versión JetPack de mi Jetson Nano es 4.6.3 y la versión de Python es 3.6. Primero instale algunas herramientas y dependencias
https://forums.developer.nvidia.com/t/official-tensorflow- para jetson-agx-xavier/65523
pip3 install -U pip testresources setuptools
Instale bibliotecas de análisis de datos y aprendizaje automático de uso común, como numpy y keras
pip3 install -U numpy==1.19.4 future mock keras_preprocessing keras_applications gast==0.2.1 protobuf pybind11 cython pkgconfig packaging
Descargue el marco TensorFlow optimizado del sitio web oficial de NVIDIA
pip3 install --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v461 tensorflow
Luego cree el entorno Pytorch (versión 1.10)
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
Después de la instalación, pruebe si la instalación es exitosa y abra la interfaz de entrada python3 en la terminal
python3
Importe el paquete tensorflow.Si no hay ningún error, significa que tensorflow se instaló correctamente.
import tensorflow as tf
Importe el paquete pytorch, si no hay ningún error, significa que la instalación de pytorch se realizó correctamente
import torch
import torchvision
# 该指令显示pytorch版本
print(torch.__version__)
# 若cuda已安装,将显示true
torch.cuda.is_available()
Si cuda está instalado y configurado, mostrará verdadero
3. Configuración del motor de razonamiento TensorRT
NVIDIA TensorRT es un motor de inferencia de aprendizaje profundo que optimiza y acelera las aplicaciones de inferencia de aprendizaje profundo para entornos de producción. Optimiza y acelera la inferencia utilizando modelos de aprendizaje profundo, mejorando así el rendimiento de la inferencia y la eficiencia del modelo.
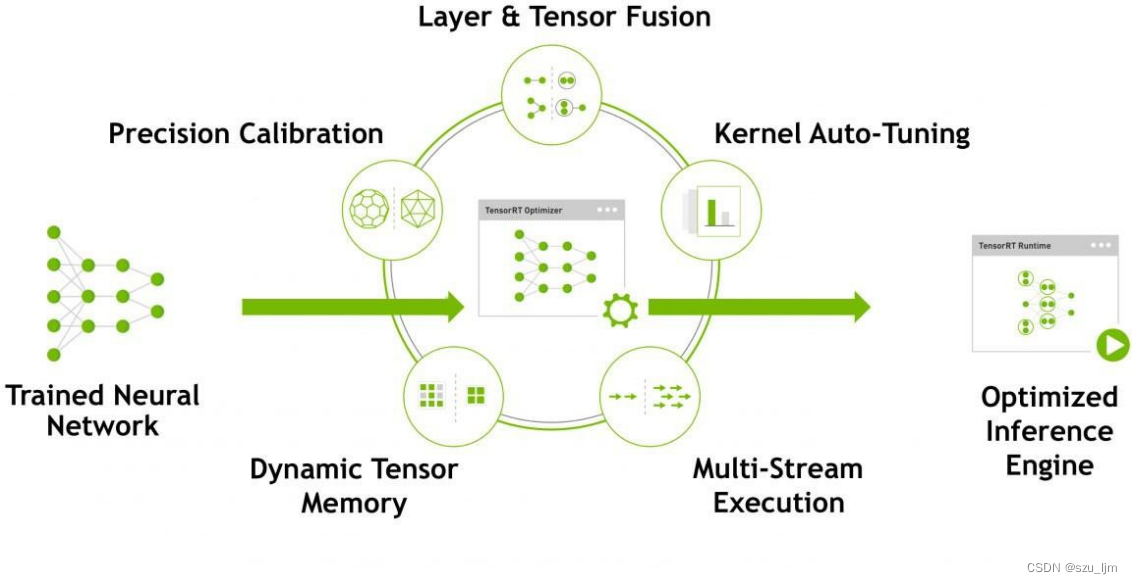
TensorRT puede analizar automáticamente modelos de aprendizaje profundo y optimizarlos para mejorar el rendimiento de la inferencia. Estas optimizaciones incluyen técnicas como poda de red, fusión de capas, optimización de memoria y mezcla de precisión. Además, TensorRT también admite la conversión de modelos de aprendizaje profundo en un formato de motor TensorRT altamente optimizado para su implementación en entornos de producción.
TensorRT también proporciona un conjunto de API para programación y ajuste de rendimiento, así como integraciones con marcos de aprendizaje profundo populares como TensorFlow, Caffe y ONNX. El modelo optimizado de TensorRT puede lograr una velocidad de razonamiento más rápida, reducir la latencia y mejorar el rendimiento; TensorRT optimiza y acelera automáticamente el proceso, lo que reduce la carga de trabajo y el tiempo de optimización manual; TensorRT tiene una alta confiabilidad y estabilidad, y ha sido ampliamente utilizado en varias computadoras aplicaciones de procesamiento de visión y lenguaje natural; TensorRT proporciona API e integraciones fáciles de usar para que los desarrolladores puedan aplicarlo fácilmente a las aplicaciones de aprendizaje profundo existentes.
La documentación oficial de Jetson Nano nos recomienda dos ejemplos, uno de los cuales utiliza Tensor RT para el reconocimiento de elementos. Para obtener más información, consulte el ejemplo de inferencia jetson de NVIDIA. El servidor que almacena estos modelos está bloqueado, por lo que los paquetes descargados previamente solo se pueden transferir de forma remota al directorio de descarga correspondiente.
Primero, si no tiene instalados git y cmake, instálelos primero
sudo apt-get install git cmake
Luego, clone la biblioteca de inferencia jetson de git
git clone https://github.com/dusty-nv/jetson-inference
Ir a la carpeta jetson-inference
cd jetson-inference
Aquí no descargué el modelo por Internet científico, directamente subí el modelo a Jetson Nano de forma remota. El funcionamiento es el siguiente:
1) Edite jetson-inference/CMakePrebuild.sh. Comente ./download-models.sh, (agregue un # comentario al frente)
2) Transferir remotamente el modelo al directorio de datos/redes
Cree una nueva carpeta de compilación para almacenar archivos compilados
mkdir build #创建build文件夹
entrar en la carpeta
cd build #进入build
ejecutar cmake
cmake ../ #运行cmake,它会自动执行上一级目录下面的 CMakePrebuild.sh
Luego realice la descompresión en este directorio:
for tar in *.tar.gz; do tar xvf $tar; done
Después de que cmake tenga éxito, debe compilar e ingresar a la carpeta de compilación
cd jetson-inference/build
empezar a compilar
make (或者make -j4) //注意:(在build目录下)
// 这里的 make 不用 sudo
// 后面 -j4 使用 4 个 CPU 核同时编译,缩短时间
Si la compilación es exitosa, se generará la siguiente estructura de carpetas

Inicie la prueba y pruebe los resultados del reconocimiento de imágenes
cd jetson-inference/build/aarch64/bin
Importar imágenes para el reconocimiento
./imagenet-console ./images/bird_0.jpg output_wyk.jpg
Resumir
Eso es todo por esta nota. El aprendizaje profundo es una de las tecnologías más populares en la actualidad y se ha utilizado ampliamente en la visión artificial, el procesamiento del lenguaje natural, el reconocimiento de voz y otros campos. En las aplicaciones de aprendizaje profundo, generalmente se requiere una gran cantidad de recursos informáticos y soporte de algoritmos, lo que requiere configurar un entorno de aprendizaje profundo apropiado.
La configuración del entorno de aprendizaje profundo incluye la instalación de varios marcos de aprendizaje profundo, controladores de GPU, bibliotecas y herramientas como CUDA y cuDNN. La configuración adecuada del entorno de aprendizaje profundo puede hacer que el desarrollo y la depuración de algoritmos de aprendizaje profundo sean más convenientes y eficientes. Al mismo tiempo, cuando se utiliza GPU para acelerar el aprendizaje profundo, un entorno de aprendizaje profundo adecuado también puede mejorar la velocidad informática y la utilización de recursos, y acelerar el razonamiento y el entrenamiento de algoritmos.