1. Explicación detallada de kafka
Dirección de descarga del paquete de instalación: https://download.csdn.net/download/weixin_45894220/87020758
1.1 ¿Qué es Kafka?
1. Kafka es un sistema de mensajería de código abierto escrito en Scala. Es un proyecto de sistema de mensajería de código abierto desarrollado por Apache Software Foundation.El objetivo del proyecto es proporcionar una plataforma unificada, de alto rendimiento y baja latencia para procesar datos en tiempo real.
2. Kafka es una cola de mensajes distribuidos: las funciones de productores y consumidores. Proporciona características similares a JMS, pero es completamente diferente en diseño e implementación, y no es una implementación de la especificación JMS.
3. Cuando Kafka guarda mensajes, se clasifica según el tema. El remitente se llama Productor y el receptor se llama Consumidor. Además, el clúster de Kafka consta de varias instancias de Kafka, y cada instancia (servidor) se convierte en un intermediario. Ya sea un clúster kafka, o un productor y un consumidor, todos confían en el clúster zookeeper para guardar metainformación para garantizar la disponibilidad del sistema.
1.2 ¿La relación entre kakfa y el cuidador del zoológico?
1. Para la gestión de todos los corredores, los corredores enviarán
solicitudes de latido al cuidador del zoológico para informar su estado. Se refleja en que habrá un punto especial en zookeeper para los registros de la lista de servidores intermediarios. La ruta del nodo es /brokers/ids
2. Zookeeper guarda configuraciones relacionadas con el tema, como la lista de temas, el número de particiones para cada localización de réplicas, etc.
3. Hay uno o más intermediarios en el grupo kafka, uno de los cuales es elegido como controlador líder por el cuidador del zoológico. El controlador es responsable de administrar el estado de todas las particiones y las copias de todo el clúster, por ejemplo, si el líder de una partición falla, el controlador elegirá un nuevo líder.
1.3 Colas de mensajes comunes
Sabemos que los sistemas de mensajes comunes incluyen Kafka, RabbitMQ, ActiveMQ, etc., pero los modos de mensajes utilizados en estos sistemas de mensajes son los siguientes:
Peer-to-Peer (Cola)
se conoce como modo de cola PTP, que también puede entenderse como punto a punto. Por ejemplo, si envío un solo correo electrónico, envío un correo electrónico a Xiaoxu. Después de enviarlo, el correo electrónico se guardará en la nube del servidor. Cuando Xiaoxu abre el cliente de correo electrónico y se conecta con éxito al servidor en la nube, puede recibir automáticamente el correo electrónico o recibir manualmente el correo electrónico localmente. , cuando Xiao Xu consume el correo en la nube del servidor, ya no se almacenará en la nube (esto depende de la configuración del servidor de correo).
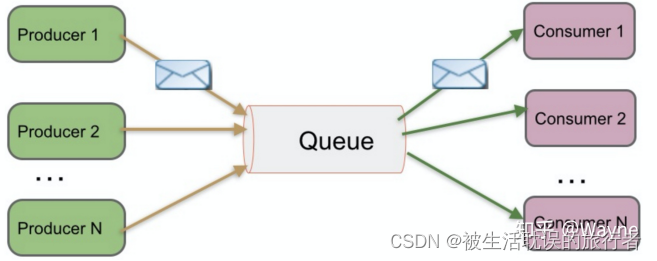
Glosario:
Productor=productor
Cola=cola
Consumidor=consumidor
El modo punto a punto funciona:
1. El productor de mensajes Producer1 produce el mensaje en la Cola y luego el Consumidor1 lo saca de la Cola y consume el mensaje.
2. Una vez consumido el mensaje, la cola ya no almacenará el mensaje y será imposible que todos los demás consumidores consuman los mensajes que han consumido otros consumidores.
3. La cola admite múltiples productores, pero para un mensaje, solo un consumidor puede consumirlo y otros consumidores no pueden consumirlo nuevamente.
4. Pero cuando el Consumidor no exista, el mensaje se mantendrá en la Cola hasta que un Consumidor lo consuma.
Publicar/suscribir (tema)
se conoce como modo de publicación/suscripción. Por ejemplo, tengo 300 000 seguidores en Weibo y actualicé un Weibo hoy, entonces estos 300 000 seguidores pueden recibir mi actualización de Weibo y todos pueden consumir mis noticias.
Nota: El Pushlisher en la siguiente ilustración es un sustantivo incorrecto y la
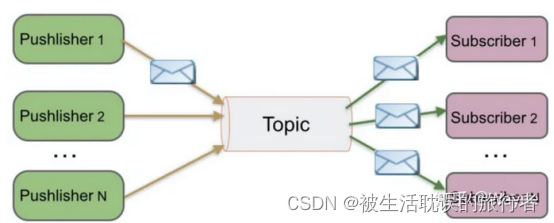
explicación correcta es el término Publisher:
Editor=Editor
Tema=Tema
Suscriptor=Suscriptor
El modo de publicación/suscripción funciona:
1. El publicador de mensajes El publicador publica el mensaje en el tema Tema y hay varios consumidores de mensajes al mismo tiempo
2. El Suscriptor consume el mensaje. A diferencia del método PTP, todos los suscriptores consumirán los mensajes publicados en un tema.
3. Cuando el editor publica un mensaje, sin importar si hay suscriptores o no, no se informará ningún mensaje de error. 4. Primero debe haber un editor de mensajes, seguido de un suscriptor de mensajes.Nota: Kafka usa el modelo de publicación/suscripción, conocido como un sistema de cola de mensajes de publicación-suscripción distribuida, persistente y de alto rendimiento.
1.4 Comparación de sistemas de mensajes comunes
1. RabbitMQ está escrito en Erlang y es compatible con múltiples protocolos AMQP, XMPP, SMTP, STOMP. Soporta equilibrio de carga y persistencia de datos. Al mismo tiempo,
es compatible con los modos Peer-to-Peer y de publicación/suscripción.
2. Redis es una base de datos NoSQL basada en pares clave-valor. También es compatible con la función MQ y se puede utilizar como un servicio de cola ligero. En lo que respecta a las operaciones de puesta en cola,
Redis funciona mejor que RabbitMQ para mensajes cortos (menos de 10 KB) y peor que RabbitMQ para mensajes largos.
3. ZeroMQ es liviano y no requiere un servidor de mensajes o middleware por separado. La aplicación en sí misma desempeña esta función, Peer-to-Peer. Es esencialmente una biblioteca que requiere que los desarrolladores combinen múltiples tecnologías y usen alta complejidad
4. Implementación ActiveMQ JMS, Peer-to-Peer, admite persistencia, transacciones XA
5. Kafka/Jafka Sistema de mensajes de publicación/suscripción distribuidos en varios idiomas de alto rendimiento , persistencia de datos, completamente distribuido, admite procesamiento en línea y fuera de línea
6, implementación de Java puro MetaQ/RocketMQ, sistema de mensajes de publicación/suscripción, admite transacciones locales y transacciones distribuidas XA
1.5 Seis características de Kafka
1. Alto rendimiento y baja latencia: puede satisfacer la producción y el consumo de millones de mensajes por segundo. Su retraso es tan bajo como unos pocos milisegundos. El tema se puede dividir en varias particiones y los grupos de consumidores realizan operaciones de consumo en las particiones.
2. Persistencia y confiabilidad: existe un mecanismo completo de almacenamiento de mensajes para garantizar datos eficientes, seguros y persistentes. Los mensajes se conservan en el disco local y se admite la copia de seguridad de datos para evitar la pérdida de datos.
3. Distribuido: basado en la expansión distribuida; los datos de Kafka se copiarán en varios servidores. Cuando falla una falla, los productores y consumidores cambian a Y usan otros Kafka .
4. Escalabilidad: el clúster de Kafka admite la expansión térmica
5. Tolerancia a fallas: permita que los nodos en el clúster fallen (si la cantidad de réplicas es n, permita que fallen n-1 nodos) 6. Alta concurrencia: admita miles de clientes
para leer en al mismo tiempo escribir
1.6 Varios conceptos de Kafka Varios conceptos de Kafka
1. Kafka se ejecuta en uno o más servidores como un clúster, y estos servidores pueden abarcar varias salas de computadoras, por lo que Kafka es un sistema de cola de mensajes de publicación y suscripción distribuido.
2. El clúster de Kafka almacena flujos de registros en categorías llamadas Temas.
3. Cada registro consta de un valor clave, "valor clave" y una marca de tiempo.
1.7 Componentes principales de Kafka
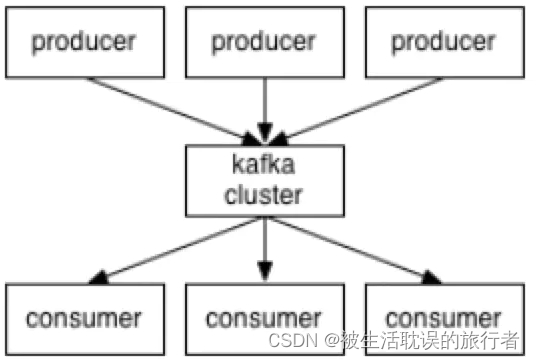
1. Productor: productor de mensajes, el mensaje generado se enviará a un tema
2. Consumidor: consumidor de mensajes, el contenido del mensaje consumido proviene de un tema
3. Tema: el mensaje se clasifica según el tema y la esencia de el tema es un directorio, es decir, para clasificar mensajes del mismo tema en el mismo directorio
4. Broker: cada instancia de kafka (o cada nodo del servidor kafka) es un broker, y un broker puede tener varios temas
Zookeeper: el clúster de zookeeper no es un componente de Kafka, pero Kafka se basa en el clúster de zookeeper para guardar la metainformación, por lo que su importancia se declara aquí.
Dirección del edificio del grupo Zookeeper: https://blog.csdn.net/weixin_45894220/article/details/127866337
El diagrama de la estructura es el siguiente
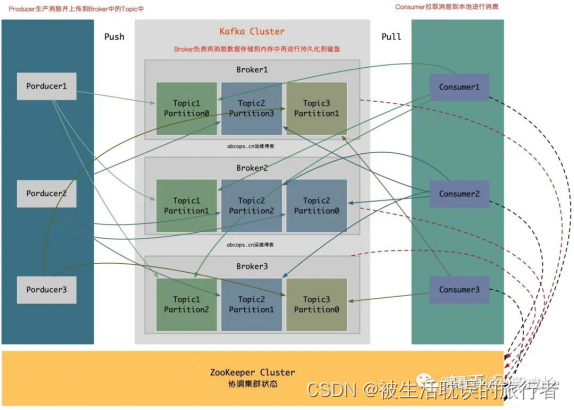
1. Productor: El productor de mensajes y datos es el principal responsable de producir mensajes Push al Tema del Broker designado.
2. Broker: los nodos de Kafka se denominan Brokers. Los Brokers son los principales responsables de crear temas, almacenar mensajes publicados por Producers y registrar el proceso de procesamiento de mensajes. Ahora, los mensajes se guardan en la memoria y luego se conservan en el disco.
3. Tema: El mensaje del mismo Tema se puede distribuir en uno o más Brokers.Un Tema contiene una o más particiones de Partición, y los datos se almacenan en varias Particiones.
4. factor de replicación: factor de replicación, este término nunca ha aparecido en la figura anterior, esta opción se especificará cuando creemos un tema en el próximo capítulo, lo que significa si se requiere una copia para crear el tema actual. establecido al crear un tema Si el valor se establece en 1, significa que solo hay una copia de todo el tema en Kafka, y se recomienda que la cantidad de factores de replicación sea coherente con la cantidad de nodos de Broker.
5. Partición: Partición, aquí se llama agrupación física de Temas, un Tema se divide en una o más Particiones en Broker, también se puede decir que cada Tema contiene una o más Particiones, (generalmente Kafka Nodo. Número total de núcleos de CPU ) la partición se puede especificar al crear un tema. Las particiones son las unidades que realmente almacenan datos.6. Consumidor: el consumidor de mensajes y datos es el principal responsable de obtener y consumir activamente los mensajes del tema suscrito.¿Por qué el consumidor no puede enviar datos del corredor como el productor? Debido a que el Broker no sabe cuánto puede consumir el Consumidor, si la cantidad de datos del mensaje push es demasiado, causará el bloqueo del mensaje, y si el Consumidor extrae activamente los datos, el Consumidor puede extraer los datos del mensaje según sus propios situación de procesamiento y, a continuación, recuperar tantos mensajes como consuma. De esta forma, los datos que el propio Consumidor ya haya obtenido no quedarán bloqueados.
7. ZooKeeper: ZooKeeper es responsable de mantener el estado de todo el clúster de Kafka, almacenar la información y el estado de cada nodo de Kafka, realizar una alta disponibilidad del clúster de Kafka y coordinar el contenido de trabajo de Kafka.
El corredor y el consumidor usan ZooKeeper, pero el productor no usa ZooKeeper.
Debido a que Kafka comienza con la versión 0.8, Producer no necesita obtener el estado del clúster de acuerdo con ZooKeeper, sino que especifica varios nodos de intermediario en la configuración para enviar mensajes y, al mismo tiempo, establece una conexión con el intermediario especificado para obtener información del estado del clúster de el Intermediario, para que el Productor pueda saber cuántos Intermediarios están activos en el clúster y cuántas Particiones tiene el Tema en cada Intermediario.
Prodocuer almacenará esta metainformación en la memoria del Productor.
Si Producer envía información a un nodo de Broker en el clúster, como fallas o tiempos de espera, Producer actualizará activamente la metainformación en la memoria para obtener el estado más reciente en el clúster de Broker actual y luego enviará la información al Broker disponible actualmente. Por supuesto, Producer también puede especificar en la configuración que actualice periódicamente la metainformación del Broker para actualizarla en la memoria.
Nota: Como
podemos ver en la figura anterior, Broker y Consumer usan ZooKeeper, pero Producer no usa ZooKeeper, porque Kafka comienza desde la versión 0.8, Producer no necesita obtener el estado del clúster según ZooKeeper, pero especifica más en la configuración. Un nodo de intermediario envía un mensaje y, al mismo tiempo, establece una conexión con el intermediario especificado para obtener la información de estado del clúster del intermediario, de modo que el productor pueda saber cuántos intermediarios en el clúster están activos y cuántos temas. están en cada Partición Broker, Prodocuer almacenará esta meta-información en la memoria del Productor. Si el productor falla como un nodo de intermediario en el clúster que envía información con el tiempo, el productor actualizará activamente la metainformación en la memoria para obtener el estado más reciente en el clúster de intermediario actual y luego enviará la información al intermediario actualmente disponible. , el Productor También puede especificar en la configuración que actualice periódicamente la metainformación del Broker para actualizarla en la memoria.
Nota: Solo Broker y ZooKeeper son servicios, mientras que Producer y Consumer son solo SDK de Kafka.
1.8 Pasos de procesamiento de datos de Kafka
1. El Productor genera un mensaje y lo envía al Broker
2. El Broker en estado Líder recibe el mensaje y lo escribe en el tema correspondiente
3. Después de que el Broker en estado Líder recibe el mensaje, se envía a el Broker en estado Follow como copia de seguridad
4. El Consumidor consume en las noticias del Broker
1.9 Explicación del sustantivo Kafka y método de trabajo
Productor: el productor de mensajes es el cliente que envía mensajes al agente kafka. Consumidor: consumidor de mensajes,
el cliente que obtiene mensajes del corredor de kafka. Tema: puede entenderse como una cola.
Grupo de consumidores (CG): este es el método utilizado por Kafka para transmitir (enviar a todos los consumidores) y unidifundir (enviar a cualquier consumidor) un mensaje de tema. Un tema puede tener varios CG. El mensaje del tema se copiará (no se copiará realmente, pero sí conceptualmente) a todos los CG, pero cada partición solo enviará el mensaje a un consumidor en el CG. Si necesita implementar la transmisión, siempre que cada consumidor tenga un CG independiente. Lograr unidifusión siempre que todos los consumidores estén en el mismo CG. Con CG, los consumidores también pueden agruparse libremente sin enviar mensajes a diferentes temas varias veces.
Broker: Un servidor kafka es un broker. Un clúster consta de varios intermediarios. Un corredor puede contener múltiples temas.
Partición: para lograr la escalabilidad, un tema muy grande se puede distribuir a varios intermediarios (es decir, servidores), un tema se puede dividir en varias particiones y cada partición es una cola ordenada. A cada mensaje en la partición se le asignará una identificación ordenada (desplazamiento). Kafka solo garantiza que los mensajes se envíen a los consumidores en el orden de una partición y no garantiza el orden de un tema como un todo (entre varias particiones).
1.10 Relación entre consumidor y tema
Kafka solo admite Tema
1. Puede haber múltiples consumidores en cada grupo, y cada consumidor pertenece a un
grupo de consumidores; por lo general, un grupo contendrá múltiples consumidores, lo que no solo puede mejorar la capacidad de consumo simultáneo de mensajes en el tema, sino también mejorar la "tolerancia a fallas". ", si un consumidor del grupo falla, las particiones que consume serán asumidas automáticamente por otros consumidores.
2. Para un mensaje específico en el Tema, solo será consumido por uno de los consumidores en cada grupo que se suscriba al Tema, y este mensaje no se enviará a múltiples consumidores en un grupo, entonces todos los consumidores en un grupo Ser consumo intercalado de todo el Tema, el consumo de mensajes de los consumidores en cada grupo es independiente entre sí, podemos pensar en un grupo como un "suscriptor".
3. En Kafka, los mensajes en una partición solo serán consumidos por un consumidor en el grupo (al mismo tiempo),
cada partición en un Tema solo será consumida por un consumidor en un "suscriptor", pero un consumidor Mensajes de múltiples Las particiones se pueden consumir al mismo tiempo.
4. El principio de diseño de Kafka determina que para un tema, no puede haber más que el número de particiones en el mismo grupo. Los consumidores pueden consumir al mismo tiempo, de lo contrario, significará que algunos consumidores no podrán recibir el mensaje. .Kafka solo puede garantizar que los mensajes en una partición estén ordenados cuando los consume un consumidor; de hecho, desde la perspectiva de Topic, cuando hay varias particiones, los mensajes aún no están ordenados globalmente.
1.11 Distribución de mensajes Kafka
1. El cliente Producer es responsable de la distribución de mensajes.
2. Cualquier intermediario en el clúster de Kafka puede proporcionar información de metadatos al productor. Estos metadatos incluyen
información como "lista de servidores supervivientes en el clúster" y "lista de particiones líder". ";
3. Cuando Después de que el productor obtenga la información de metadatos, el productor mantendrá conexiones de socket con todos los líderes de partición bajo el tema;
4. El mensaje se envía directamente del productor al intermediario a través del socket sin ninguna "capa de enrutamiento" en entre.
De hecho, a qué partición se enruta el mensaje lo determina el cliente productor, por ejemplo, se puede usar "aleatorio", "key-hash", "sondeo", etc.
Si hay varias particiones en un tema, es necesario implementar una "distribución equilibrada de mensajes" en el lado del productor.
1. En el archivo de configuración del lado del productor, el desarrollador puede especificar el método de enrutamiento de la partición.
2. El mecanismo de respuesta del envío de mensajes del productor es establecer si el envío de datos requiere retroalimentación del servidor. Hay tres valores 0, 1, -1 0: el productor no esperará a que el intermediario envíe un
acuse de recibo
1: envíe un acuse de recibo cuando el líder recibe el mensaje
-1: cuando todos los seguidores envían un acuse de recibo request.required.acks=0 después del mensaje de sincronización exitosa
1.12 Equilibrio de carga del consumidor
Cuando un consumidor se une o deja un grupo, se activará el balance de particiones. El objetivo final del balance es mejorar la capacidad de consumo concurrente del tema. Los pasos son los siguientes:
1. Si tema1 tiene las siguientes particiones: P0, P1, P2, P3
2. Agregue al grupo A, hay los siguientes consumidores: C0, C1
3. Primero ordene las particiones según el número de índice de partición: P0, P1, P2 , P3
4. Ordenar según consumidor.id: C0,C1
5. Calcular el múltiplo: M = [P0,P1,P2,P3].size / [C0,C1].size, el valor de este ejemplo es M= 2 (redondear hacia arriba)
6. Luego asigne las particiones a su vez: C0 = [P0,P1], C1=[P2,P3], es decir, Ci = [P(i * M), P((i + 1) * M-1)]
Dirección de referencia del principio Kafka:
https://zhuanlan.zhihu.com/p/163836793
https://cdn.modb.pro/db/105106
https://www.jianshu.com/p/47487f35b964
2. Tutorial súper detallado sobre la construcción de clústeres de kafka
2.1 Prepare tres máquinas virtuales:
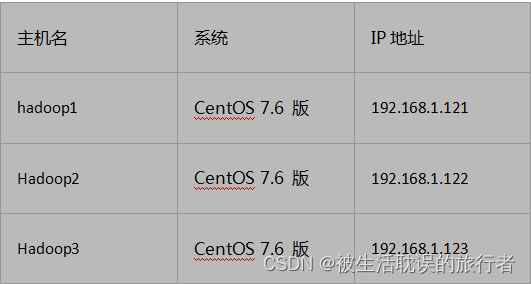
1. El servicio ssh está configurado en la máquina virtual y es posible iniciar sesión sin contraseña.
2. Kafka se ejecuta en la JVM y es necesario instalar JDK.
3. Kafka depende de zookeeper, que debe instalarse.
Para más detalles , consulte:
https://blog.csdn.net/ weixin_45894220/article/details/127866337
2.2 Descargar el paquete de instalación
[root@hadoop1 ~]# cd /opt/module
#Descargue el paquete de instalación de kafka
[root@hadoop1 module]# wget https://archive.apache.org/dist/kafka/2.6.0/kafka_2.13-2.6.0.tgz
2.3, descompresión
[root@hadoop1 module]# tar -zxvf kafka_2.13-2.6.0.tgz
[root@hadoop1 module]# mv kafka_2.13-2.6.0 kafka
2.4 Crear un directorio para almacenar mensajes kafka
[root@hadoop1 module]# cd kafka
[root@hadoop1 kafka]# mkdir kafka-logs
2.5 Modificar el archivo de configuración
Ingrese al directorio del archivo de configuración
[root@hadoop1 config]# cd config/
respaldo
[root@hadoop1 config]# cp server.properties server.properties.bak
Modificar el archivo de configuración
[root@hadoop1 config]# vim server.properties
# 修改如下参数
broker.id=0
listeners=PLAINTEXT://hadoop1:9092
log.dirs=/opt/module/kafka/kafka-logs
zookeeper.connect=hadoop1:2181,hadoop2:2181,hadoop3:2181
Descripción de parámetros:
broker.id: identificador único global en el clúster, se deben establecer diferentes valores en cada nodo
de escucha: esta dirección IP también está relacionada con esta máquina, y cada nodo se establece en su propia dirección IP log.dirs: Zookeeper
que almacena mensajes kafka
.connect: configura la dirección del clúster zookeeper
2.6 Distribuir el directorio de instalación de kafka
#Distribuir el directorio de instalación de kafka a otros nodos del clúster
[root@hadoop1 config]# scp -r /opt/module/kafka/ hadoop2:/opt/module
[root@hadoop1 config]# scp -r /opt/module/kafka/ hadoop3:/opt/module
Una vez completada la distribución, otros nodos del clúster deben modificar los parámetros broker.id y listeners en el archivo de configuración server.properties
hadoop2 修改
broker.id=2
listeners=PLAINTEXT://hadoop2:9092
hadoop3修改
broker.id=3
listeners=PLAINTEXT://hadoop3:9092
2.7, escriba el script de operación de clúster kafka
[root@hadoop1 config]# cd /opt/module/kafka/bin
#Crear secuencia de comandos de inicio de kafka
vim kafka-cluster.sh
# 添加如下内容
#!/bin/bash
case $1 in
"start"){
for i in hadoop1 hadoop2 hadoop3
do
echo -------------------------------- $i kafka 启动 ---------------------------
ssh $i "source /etc/profile;/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
}
;;
"stop"){
for i in hadoop1 hadoop2 hadoop3
do
echo -------------------------------- $i kafka 停止 ---------------------------
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh"
done
}
;;
esac
Después de guardar y salir, modifique los permisos de ejecución
chmod +x ./kafka-cluster.s
Descripción del comando de secuencia de comandos:
iniciar el comando de clúster kafka
./kafka-cluster.sh start
Detener el comando del clúster kafka
./kafka-cluster.sh stop
7.8 Inicie el clúster de kafka
Primero inicie el clúster zookeeper
y luego ejecute el comando de inicio del script del clúster kafka
[root@hadoop1 bin]# ./kafka-cluster.sh start
-------------------------------- hadoop1 kafka 启动 ---------------------------
-------------------------------- hadoop2 kafka 启动 ---------------------------
-------------------------------- hadoop3 kafka 启动 ---------------------------
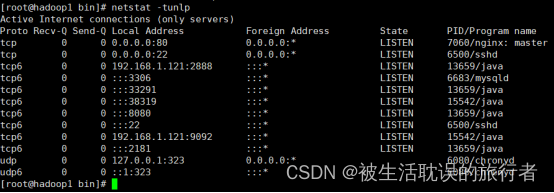
Comprobar si el proceso existe
[root@hadoop1 bin]# netstat -tunlp
7.9 Verificación de la prueba
Después de que el clúster de kafka se inicie con éxito, podemos operar el clúster de kafka
Crear un tema
[root@hadoop1 kafka]# cd /opt/module/kafka
[root@hadoop1 kafka]# ./bin/kafka-topics.sh --create --bootstrap-server hadoop1:9092 --replication-factor 3 --partitions 1 --topic test
输出:Created topic test.
ver lista de temas
[root@hadoop1 kafka]# ./bin/kafka-topics.sh --list --bootstrap-server hadoop1:9092
输出:test
Inicie el productor de la consola
[root@hadoop1 kafka]# ./bin/kafka-console-producer.sh --broker-list hadoop1:9092 --topic test
Inicie el consumidor de la consola
[root@hadoop1 kafka]# ./bin/kafka-console-consumer.sh --bootstrap-server hadoop1:9092 --topic test --from-beginning
Ingrese hola kafka en la consola del productor, consola del consumidor, puede consumir el mensaje del productor y generar hola kafka, lo que indica que el consumidor ha consumido con éxito el mensaje producido por el productor.
¡Hasta ahora, hemos completado con éxito todo el proceso de construcción de un clúster kafka!