1. Productos de bases de datos en la nube
1.1 Descripción general de los proveedores de bases de datos en la nube
Los proveedores de bases de datos en la nube se dividen principalmente en tres categorías.
① Proveedores de bases de datos tradicionales, como Teradata, Oracle, IBM DB2 y Microsoft SQL Server, etc.
② Proveedores de nube involucrados en el mercado de bases de datos, como Amazon, Google, Yahoo!, Alibaba, Baidu, Tencent, etc.
③ Proveedores emergentes, como Vertica, LongJump y EnterpriseDB, etc.
Los productos de bases de datos en la nube más comunes en el mercado se muestran en la Tabla 6-3.
1.2 Productos de bases de datos en la nube de Amazon
Amazon es pionero en el mercado de bases de datos en la nube. Además de su conocido servicio de almacenamiento S3 y su servicio informático EC2, Amazon también ofrece servicios de bases de datos basados en la nube SimpleDB y Dynamo.
SimpleDB es un sistema de almacenamiento de datos distribuido desarrollado por Amazon que se puede consultar, es el primer servicio de base de datos NoSQL en AWS (Amazon Web Service) e integra una gran cantidad de la infraestructura AWS de Amazon. Como sugiere el nombre, SimpleDB está diseñado para usarse como una base de datos simple, y sus elementos de almacenamiento (atributos y valores) están determinados por un campo de identificación para determinar la ubicación de la fila. Esta estructura puede satisfacer las funciones básicas de lectura, escritura y consulta de los usuarios. SimpleDB proporciona una API fácil de usar para almacenar y acceder rápidamente a datos. Sin embargo, SimpleDB no es una base de datos relacional. Las bases de datos relacionales tradicionales utilizan almacenamiento de filas, mientras que SimpleDB utiliza almacenamiento "clave/valor", y sirve principalmente a los desarrolladores web que no necesitan una base de datos relacional. Sin embargo, SimpleDB tiene algunos defectos obvios, como la limitación de una sola tabla, el rendimiento inestable y solo puede admitir una coherencia eventual.
Dynamo absorbe la esencia de SimpleDB y otras ideas de diseño de bases de datos NoSQL y está diseñado para aplicaciones más exigentes que requieren almacenamiento de datos escalable y funciones de administración de datos más avanzadas. Dynamo utiliza almacenamiento "clave/valor". Los datos que almacena son datos no estructurados y no reconoce ningún dato estructurado. Los usuarios deben completar el análisis de los valores ellos mismos. La clave en el sistema Dynamo no se almacena como una cadena, sino como md5_key (obtenida después de la conversión mediante el algoritmo md5), por lo que solo se puede acceder a ella en función de la clave y no admite consultas. DynamoDB utiliza unidades de estado sólido para tiempos de lectura y escritura constantes y de baja latencia y está diseñado para escalar a grandes capacidades manteniendo un rendimiento constante, aunque con un modelo de consulta más riguroso.
Amazon RDS (Amazon Relational Database Service) es un servicio web desarrollado por Amazon que permite a los usuarios crear y operar bases de datos relacionales en un entorno de nube (puede admitir bases de datos como MySQL y Oracle). Los usuarios deben centrarse en el contenido de nivel empresarial y de aplicaciones sin dedicar demasiado tiempo al tedioso trabajo de gestión de bases de datos.
Además, Amazon ha desarrollado una buena cooperación con otros proveedores de bases de datos. El servicio de alojamiento de aplicaciones Amazon EC2 ya puede implementar muchos tipos de productos de bases de datos, incluidas plataformas de bases de datos convencionales como SQL Server, Oracle 11g, MySQL e IBM DB2, así como otros productos de bases de datos. , como EnterpriseDB. Como entorno de alojamiento escalable, los desarrolladores pueden desarrollar y alojar sus propias aplicaciones de bases de datos en el entorno EC2.
1.3 Productos de bases de datos en la nube de Google
Google Cloud SQL es una base de datos en la nube basada en MySQL lanzada por Google. Los beneficios de usar Cloud SQL son obvios. Todas las transacciones están en la nube y son administradas por Google. Los usuarios no necesitan configurar ni solucionar errores, simplemente pueden confiar en él. para realizar su trabajo. . Debido a que los datos se replican en los múltiples centros de datos de Google, siempre están disponibles. Google también proporcionará servicios de importación o exportación para facilitar a los usuarios la entrada o salida de bases de datos de la nube. Google utiliza MySQL muy familiar, un entorno de base de datos MySQL tradicional con soporte JDBC (para aplicaciones App Engine basadas en Java) y soporte DB-API (para aplicaciones App Engine basadas en Python), por lo que la mayoría de las aplicaciones no necesitan pasar. se ejecuta con múltiples depuraciones y el formato de datos es muy familiar para la mayoría de los desarrolladores y administradores. Otro beneficio de Google Cloud SQL es su integración con Google App Engine.
1.4 Productos de bases de datos en la nube de Microsoft
En marzo de 2008, Microsoft proporcionó la función de base de datos relacional de SQL Server a través del Servicio de datos SQL (SDS), lo que convirtió a Microsoft en el primer gran proveedor de bases de datos en el mercado de bases de datos en la nube. Desde entonces, Microsoft ha ampliado la funcionalidad SDS y le ha cambiado el nombre a SQL Azure. La plataforma Azure de Microsoft proporciona una colección de servicios web que permiten a los usuarios crear, consultar y utilizar bases de datos de SQL Server en la nube a través de la red. La ubicación del servidor SQL Server en la nube es transparente para los usuarios. Este es un hito importante para la computación en la nube. SQL Azure tiene las siguientes características.
- ① Es una base de datos relacional. Admite el uso de TSQL (Transact Structured Query Language) para administrar, crear y operar bases de datos en la nube.
- ② Admite procedimientos almacenados. Sus tipos de datos y procedimientos almacenados son muy similares a los del SQL Server tradicional, por lo que las aplicaciones pueden desarrollarse localmente y luego implementarse en la plataforma en la nube.
- ③ Admite una gran cantidad de tipos de datos. Contiene casi todos los tipos de datos típicos de SQL Server 2008.
- ④ Admitir transacciones en la nube. Se admiten transacciones locales, pero no se admiten transacciones distribuidas.
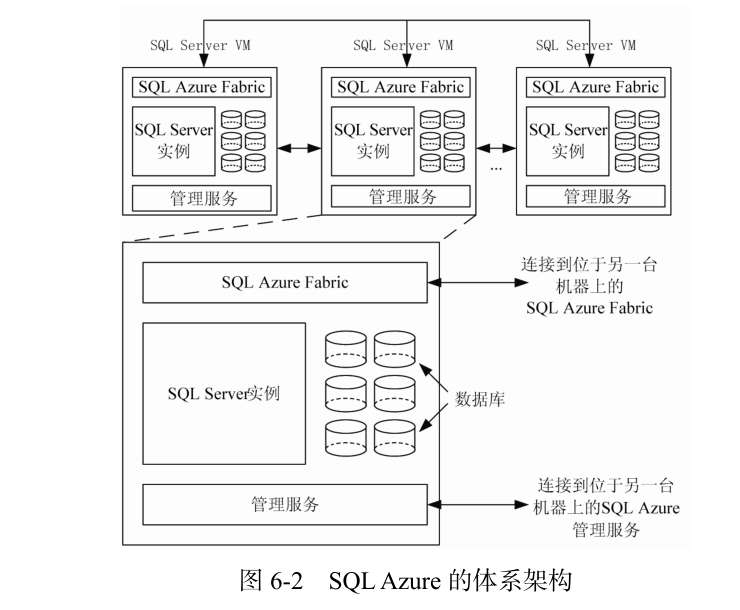
La arquitectura de SQL Azure incluye un clúster de máquinas virtuales, que puede aumentar o disminuir dinámicamente la cantidad de máquinas virtuales según los cambios en la carga de trabajo, como se muestra en la Figura 6-2. Cada máquina virtual SQL Server VM (Virtual Machine) está instalada con el sistema de administración de bases de datos SQL Server2008 para almacenar datos en un modelo relacional. Por lo general, una base de datos se distribuirá y almacenará en entre 3 y 5 máquinas virtuales de SQL Server. Cada máquina virtual con SQL Server se instala con SQL Azure Fabric y SQL Azure Management Services, este último es responsable de la replicación de datos de la base de datos para garantizar los requisitos básicos de alta disponibilidad de SQL Azure. SQL Azure Fabric y los servicios de administración en diferentes máquinas virtuales de SQL Server intercambiarán información de monitoreo entre sí para garantizar la capacidad de monitoreo del servicio general.
1.5 Otros productos de bases de datos en la nube
Yahoo! PNUTS es un sistema de base de datos masivamente paralelo y distribuido geográficamente desarrollado para aplicaciones web. Es una parte importante de la plataforma de computación en la nube de Yahoo!. Vertica Systems lanzó una base de datos en la nube en 2008. Mongo de 10Gen y la base de datos AppJet de AppJet también proporcionan las versiones correspondientes de la base de datos en la nube. EnterpriseDB, con inversión de IBM, también proporciona una base de datos en la nube que se ejecuta en Amazon EC2. LongJump es una nueva empresa que compite con Salesforce y ha lanzado un producto de base de datos en la nube basado en la base de datos de código abierto PostgreSQL. Intuit QuickBase también ofrece su propia familia de bases de datos en la nube. La nube relacional desarrollada por el MIT puede distinguir automáticamente tipos de carga y asignar tipos similares de cargas al mismo nodo de datos. También adopta una estrategia de partición de datos basada en gráficos, que también es muy buena para cargas transaccionales complejas. Además, admite escalabilidad. ejecutar consultas SQL sobre datos cifrados. Alibaba Cloud RDS es un servicio de base de datos relacional proporcionado por Alibaba Cloud que alquila a los usuarios instancias de bases de datos que se ejecutan directamente en servidores físicos. Baidu Cloud Database puede admitir servicios de bases de datos relacionales distribuidas (basados en MySQL), servicios de almacenamiento de bases de datos distribuidas no relacionales (basados en MongoDB) y servicios de bases de datos no relacionales clave/valor (basados en Redis).
2. Arquitectura del sistema de base de datos en la nube
Existen grandes diferencias en la arquitectura del sistema adoptada por diferentes productos de bases de datos en la nube. A continuación se utiliza el sistema UMP (Plataforma Unificada MySQL) desarrollado por el equipo de base de datos del sistema central del Grupo Alibaba como ejemplo.
2.1 Descripción general del sistema UMP
El sistema UMP es una solución de base de datos en la nube MySQL de bajo costo y alto rendimiento, y los módulos clave están implementados en el lenguaje Erlang. Los desarrolladores solicitan recursos de instancia MySQL desde la plataforma a través de la red, y la plataforma proporciona una entrada única para acceder a los datos. El sistema UMP divide varios recursos del servidor en grupos de recursos y asigna recursos a instancias de MySQL en función de los grupos de recursos. El sistema contiene una serie de componentes que trabajan juntos para proporcionar una serie de servicios como respaldo activo maestro-esclavo, respaldo de datos, migración, recuperación ante desastres, separación de lectura y escritura y fragmentación de bases de datos y tablas de manera transparente para los usuarios. El sistema se divide en tres tipos de usuarios, a saber, usuarios con pequeño volumen de datos y tráfico, usuarios medianos y usuarios que necesitan dividir bases de datos y tablas. Varios usuarios de pequeña escala pueden compartir la misma instancia de MySQL, los usuarios de tamaño mediano pueden usar exclusivamente una instancia de MySQL y varias instancias de MySQL de usuarios que necesitan dividir bases de datos y tablas comparten la misma máquina física.A través de estos métodos, se logra la virtualización de recursos. y el costo se reduce costo total. UMP implementa el aislamiento de recursos, la asignación bajo demanda y la restricción de recursos de CPU, memoria y IO a través de dos métodos: "usar Cgroup para limitar los recursos del proceso MySQL" y "limitar QPS (consulta por segundo) en el lado del servidor proxy"; al mismo Al mismo tiempo, también admite expandir y reducir dinámicamente la capacidad de acuerdo con el desarrollo del negocio de los usuarios sin afectar la prestación de servicios de datos. El sistema también utiliza de manera integral conexión de base de datos SSL, lista blanca de IP de acceso a datos, registro de registros de operaciones del usuario, interceptación de SQL y otras tecnologías para proteger de manera efectiva la seguridad de los datos del usuario.
En general, el diseño de la arquitectura del sistema UMP sigue los siguientes principios.
- ① Mantener una única entrada externa al sistema y mantener un único grupo de recursos dentro del sistema.
- ② Elimine los puntos únicos de falla y garantice una alta disponibilidad de los servicios.
- ③ Asegúrese de que el sistema tenga una buena escalabilidad y pueda agregar y eliminar dinámicamente nodos informáticos y de almacenamiento.
- ④ Asegúrese de que los recursos asignados a los usuarios también sean elásticos y escalables, y que los recursos estén aislados entre sí para garantizar la seguridad de las aplicaciones y los datos.
2.2 Arquitectura del sistema UMP
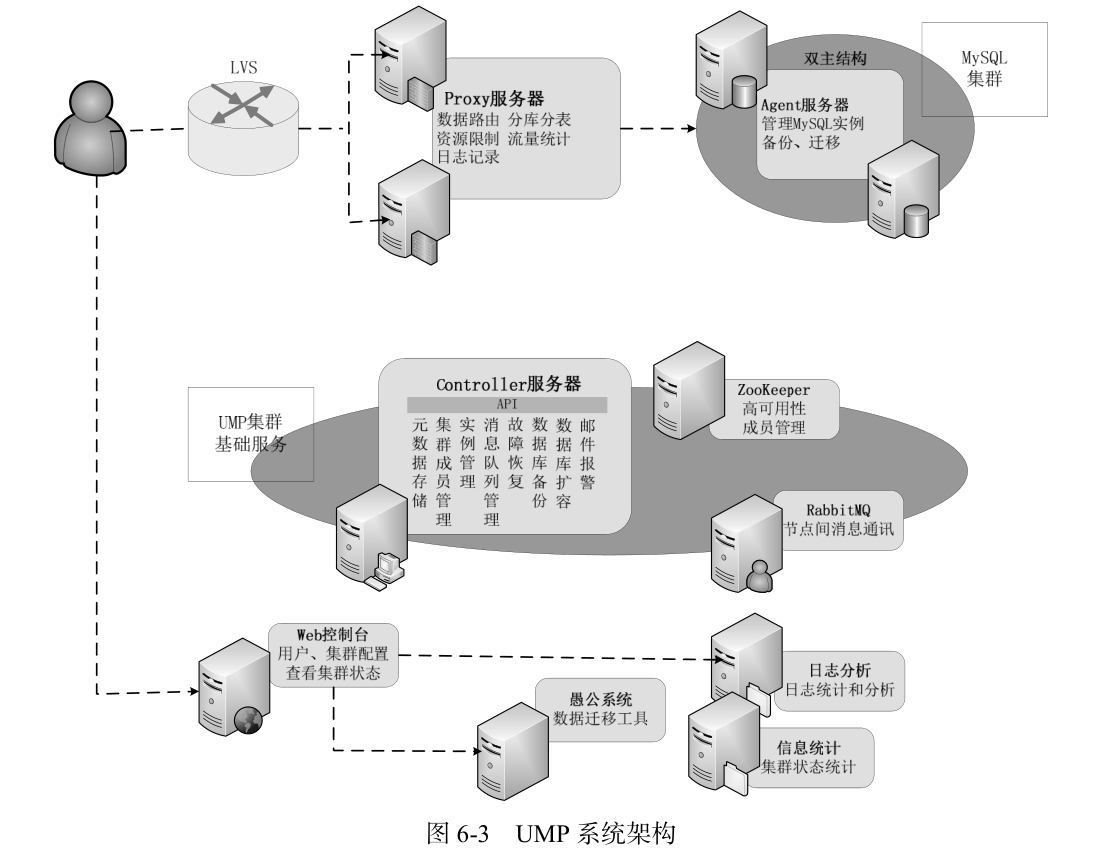
La arquitectura del sistema UMP se muestra en la Figura 6-3. Las funciones en el sistema UMP incluyen servidor controlador, servidor proxy, servidor agente, consola web, servidor de análisis de registros, servidor de estadísticas de información y sistema Yugong; los componentes dependientes de código abierto incluyen Mnesia , LVS , RabbitMQ y Zookeeper.
2.2.1.Mnesia
Mnesia es un sistema de gestión de bases de datos distribuido adecuado para telecomunicaciones y otras aplicaciones de Erlang que requieren operación continua y características suaves en tiempo real. Es parte de la plataforma del sistema de control para crear aplicaciones de telecomunicaciones: Open Telecom Platform (Open Telecom Platform OTP). Erlang es un lenguaje de programación estructurado de tipo dinámico con soporte de computación paralela incorporado, que es muy adecuado para construir sistemas de computación paralela distribuidos y suaves en tiempo real. Las aplicaciones escritas en Erlang generalmente constan de miles de procesos livianos en tiempo de ejecución y se comunican entre sí mediante el paso de mensajes. El cambio de contexto entre procesos de Erlang es mucho más eficiente que los programas C. Mnesia y el lenguaje de programación Erlang están estrechamente acoplados. La mayor ventaja es que al operar datos, no habrá problemas de desajuste de impedancia causados por diferentes formatos de datos utilizados en la base de datos y el lenguaje de programación. Mnesia admite transacciones, admite la fragmentación transparente de datos, utiliza bloqueos de dos fases para implementar transacciones distribuidas y se puede expandir linealmente a al menos 50 nodos. El esquema de la base de datos de Mnesia se puede reconfigurar dinámicamente en tiempo de ejecución y las tablas se pueden migrar o copiar a múltiples nodos para mejorar la tolerancia a fallas. Estas características de Mnesia hacen que se utilice para proporcionar servicios de bases de datos distribuidas al desarrollar bases de datos en la nube.
2.2.2.ConejoMQ
RabbitMQ es un producto de cola de mensajes de nivel industrial desarrollado en Erlang (similar en función al producto de cola de mensajes de IBM IBM WEBSPHERE MQ) y se utiliza como middleware de transmisión de mensajes para lograr una transmisión de mensajes confiable. La comunicación entre los nodos en el clúster UMP no necesita establecer una conexión especial, sino que se realiza leyendo y escribiendo mensajes en cola.
2.2.3.Cuidador del zoológico
Zookeeper es un sistema de trabajo colaborativo eficiente y confiable que proporciona servicios básicos como bloqueos distribuidos (como servicio de nombres unificado, servicio de sincronización de estado, administración de clústeres, administración de elementos de configuración de aplicaciones distribuidas, etc.) y se utiliza para crear aplicaciones distribuidas y aliviar las tareas de coordinación realizadas por aplicaciones distribuidas (para conocer el principio de funcionamiento de Zookeeper, consulte los libros o materiales en línea relevantes). En el sistema UMP, Zookeeper desempeña principalmente tres funciones.
(1) Como servidor de configuración global. El sistema UMP requiere varios servidores para ejecutarse, y algunos elementos de configuración de los sistemas de aplicaciones que ejecutan son los mismos. Si desea modificar estos mismos elementos de configuración, debe modificarlos en varios servidores al mismo tiempo. Esto no solo es problemático , pero también propenso a errores. Por lo tanto, el sistema UMP entrega completamente este tipo de información de configuración a Zookeeper para su administración, guarda la información de configuración en un nodo de directorio de Zookeeper y luego configura todos los servidores que deben modificarse para monitorear este nodo de directorio, es decir, monitorear el Estado de la información de configuración. Una vez que la información de configuración cambie, cada servidor recibirá una notificación de Zookeeper y luego obtendrá nueva información de configuración de Zookeeper.
(2) Proporcionar cerraduras distribuidas. Se implementan varios servidores de controlador en el clúster UMP. Para garantizar el funcionamiento correcto del sistema, algunas operaciones solo pueden ser ejecutadas por un servidor a la vez y no pueden ejecutarse al mismo tiempo. Por ejemplo, después de que falla una instancia de MySQL, se requiere una conmutación maestro-esclavo y otro servidor normal reemplaza el servidor actualmente fallido. Si todos los servidores del Controlador rastrean e inician el proceso de conmutación maestro-esclavo en este momento, entonces todo el sistema entrará en un estado de caos. Por lo tanto, al mismo tiempo, se debe elegir un "gerente general" de varios servidores del controlador en el clúster, y este "gerente general" es responsable de iniciar varias tareas del sistema. La función de bloqueo distribuido de Zookeeper puede ayudar a seleccionar un "maestro" y permitir que este "administrador" administre el clúster.
(3) Supervisar todas las instancias de MySQL. Cuando falla un servidor que ejecuta una instancia de MySQL en el clúster, debe detectarse a tiempo y luego se pueden usar otros servidores normales para reemplazar el servidor fallido. El sistema UMP utiliza Zookeeper para monitorear todas las instancias de MySQL. Cada instancia de MySQL creará un nodo de directorio temporal en Zookeeper cuando se inicie. Cuando una instancia de MySQL se bloquea, este nodo de directorio temporal también se eliminará. El proceso de monitoreo en segundo plano puede capturar este cambio, sabiendo así que esta instancia de MySQL ya no está disponible.
2.2.4.LVS
LVS (Linux Virtual Server) es un servidor virtual Linux, que es un sistema de clúster de servidores virtuales. El clúster LVS utiliza tecnología de equilibrio de carga IP y tecnología de distribución de solicitudes basada en contenido. El programador es el único punto de entrada del sistema de clúster LVS. El programador tiene una tasa de rendimiento muy buena y transfiere solicitudes de manera uniforme a diferentes servidores para su ejecución. El programador protege automáticamente las fallas del servidor, formando así un grupo de servidores en un clúster de alto rendimiento. Servidores virtuales de alto rendimiento y alta disponibilidad. La estructura de todo el clúster de servidores es transparente para el cliente y no es necesario modificar los programas del cliente y del servidor. El sistema UMP utiliza LVS para lograr el equilibrio de carga dentro del clúster.
2.2.5. Servidor del controlador
El servidor del controlador proporciona varios servicios de administración al clúster UMP, realizando administración de miembros del clúster, almacenamiento de metadatos, administración de instancias MySQL, recuperación de fallas, respaldo, migración, expansión y otras funciones. Un conjunto de servicios de bases de datos distribuidas de Mnesia se ejecuta en el servidor del Controlador, que almacena varios metadatos del sistema, que incluyen principalmente información de configuración y estado de los miembros del clúster, usuarios y la relación de mapeo entre los nombres de usuario y las direcciones de instancia de MySQL back-end (o llamado "enrutamiento tabla"), etc. Cuando otros componentes del servidor necesitan obtener datos del usuario, pueden enviar solicitudes al servidor del Controlador para obtener datos. Para evitar puntos únicos de falla y garantizar una alta disponibilidad del sistema, se implementan múltiples servidores de controlador en el sistema UMP y luego la función de bloqueo distribuido de Zookeeper ayuda a seleccionar un "gerente general" que sea responsable de la programación y monitoreo de diversas tareas del sistema.
2.2.6.consola web
La consola web proporciona a los usuarios una interfaz de administración del sistema.
2.2.7.Servidor proxy
El servidor Proxy proporciona a los usuarios acceso a los servicios de base de datos MySQL. Implementa completamente el protocolo MySQL. Los usuarios pueden utilizar clientes MySQL existentes para conectarse al servidor Proxy. El servidor Proxy obtiene la información de autenticación del usuario y las restricciones de cuota de recursos a través del nombre de usuario [tales como QPS, IOPS (E/S por segundo), número máximo de conexiones, etc.] y la dirección de la instancia de MySQL en segundo plano, y luego la solicitud de consulta SQL del usuario se reenviará a la instancia de MySQL correspondiente. Además de las funciones básicas de enrutamiento de datos, el servidor Proxy también implementa muchas funciones importantes, incluida la protección contra fallas de instancias de MySQL, la separación de lectura y escritura, la fragmentación de bases de datos y tablas, el aislamiento de recursos, el registro de registros de acceso de usuarios, etc.
2.2.8. Servidor de agente
El servidor Agente se implementa en la máquina que ejecuta el proceso MySQL. Se utiliza para administrar la instancia MySQL en cada máquina física, realizar conmutación maestro-esclavo, creación, eliminación, copia de seguridad, migración y otras operaciones. También es responsable de recopilar y analizando las estadísticas y ralentización del proceso MySQL Query log (Slow Query Log) y bin-log.
2.2.9. Servidor de análisis de registros
El servidor de análisis de registros almacena y analiza los registros de acceso de los usuarios entrantes desde el servidor Proxy y admite consultas en tiempo real de registros lentos e informes estadísticos durante un período de tiempo.
2.2.10.Servidor de estadísticas de información
El servidor de estadísticas de información recopila periódicamente estadísticas sobre el número de conexiones de usuario, valores QPS y estado del proceso de instancias de MySQL utilizando RRDtool. Los resultados estadísticos se pueden mostrar visualmente en la interfaz web y los resultados estadísticos también se pueden utilizar para lograr recursos flexibles. Asignación y automatización en el futuro: la base para migrar instancias de MySQL.
2.2.11. Sistema del viejo tonto
El sistema Yugong es una herramienta que combina la replicación completa con el análisis bin-log para una replicación incremental, que puede lograr una expansión, contracción y migración dinámicas sin tiempo de inactividad.
2.3 Funciones del sistema UMP
El sistema UMP está construido sobre un gran clúster. A través del trabajo colaborativo de múltiples componentes, todo el sistema logra recuperación ante desastres, separación de lectura y escritura, subbases de datos de bases de datos y tablas, administración de recursos, programación de recursos, aislamiento de recursos y funciones de seguridad de datos.
2.3.1. Recuperación de desastres
La base de datos en la nube debe proporcionar a los usuarios una conexión a la base de datos que esté siempre disponible. Cuando falla una instancia de MySQL, el sistema debe realizar automáticamente la recuperación de fallas. Todos los procesos de manejo de fallas son transparentes para los usuarios y los usuarios no estarán al tanto de todo lo que sucede en segundo plano. .
Para lograr la recuperación ante desastres, el sistema UMP creará dos instancias de MySQL para cada usuario, una es la base de datos maestra y la otra es la base de datos esclava, y las dos instancias de MySQL se configurarán entre sí como máquinas de respaldo. Si se produce alguna actualización de alguna instancia de MySQL se copiarán entre sí. Al mismo tiempo, el servidor Proxy puede garantizar que los datos solo se escriban en la base de datos principal.
Zookeeper mantiene el estado de la base de datos principal y la base de datos esclava. Zookeeper puede monitorear el estado de cada instancia de MySQL en tiempo real. Una vez que la base de datos principal está inactiva, Zookeeper puede detectarla inmediatamente y notificar al servidor del controlador. El servidor del controlador iniciará la operación de conmutación maestro-esclavo, modificará la relación de mapeo entre el nombre de usuario y la dirección de la instancia MySQL back-end en la tabla de enrutamiento y marcará la base de datos principal como no disponible. Al mismo tiempo, con la ayuda de El middleware de cola de mensajes RabbitMQ notificará a todos los servidores proxy para que modifiquen la relación de mapeo del usuario desde el nombre hasta la dirección de instancia de MySQL de backend. Después de esta serie de operaciones, se completa el cambio maestro-esclavo y el nombre de usuario se asignará a una nueva instancia de MySQL que se puede usar normalmente, y todo esto es completamente transparente para el propio usuario.
La base de datos principal que se cayó debe estar en línea nuevamente después del procesamiento de recuperación. Durante el tiempo de inactividad y recuperación de la base de datos maestra, es posible que la base de datos esclava se haya actualizado varias veces. Por lo tanto, cuando la base de datos maestra se recupere, copiará todas las actualizaciones en la base de datos esclava a sí misma. Cuando el estado de la base de datos de la base de datos maestra esté a punto de alcanzar el mismo estado que el de la base de datos esclava, el servidor del controlador ordenará a la base de datos esclava que deje de actualizar y entre en un estado que no se puede escribir, lo que prohíbe a los usuarios escribir datos. En este momento, los usuarios pueden sentir que no pueden escribir datos durante un corto período de tiempo. Cuando la base de datos maestra se actualiza al mismo estado que la base de datos esclava, el servidor del controlador iniciará una operación de cambio maestro-esclavo, marcará la base de datos maestra como disponible en la tabla de enrutamiento y luego notificará al servidor proxy para que vuelva a cambiar la operación de escritura. a la base de datos maestra, las operaciones de escritura del usuario pueden continuar ejecutándose y luego la biblioteca esclava se puede modificar a un estado de escritura.
2.3.2. Separación de lectura y escritura.
Dado que cada usuario tiene dos instancias de MySQL, es decir, la base de datos maestra y la base de datos esclava, las bases de datos maestra y esclava se pueden utilizar por completo para separar las operaciones de lectura y escritura del usuario y lograr el equilibrio de carga. El sistema UMP implementa una función de separación de lectura y escritura que es transparente para los usuarios. Cuando toda la función está activada, el servidor proxy responsable de proporcionar a los usuarios acceso a los servicios de la base de datos MySQL analizará la declaración SQL iniciada por el usuario. Si es así una operación de escritura, se enviará directamente a la biblioteca principal, si es una operación de lectura, se enviará a la biblioteca principal y a la biblioteca esclava para su ejecución de manera uniforme. Sin embargo, puede ocurrir una situación, es decir, el usuario acaba de escribir datos en la base de datos principal y antes de que los datos se hayan copiado en la base de datos esclava, el usuario lee los datos de la base de datos esclava, lo que resulta en que el usuario no esté capaz de leer los datos, o leer los datos de la base de datos esclava a una versión anterior de los datos. Para evitar que ocurra esta situación, el sistema UMP iniciará un temporizador después de cada operación de escritura del usuario. Si el usuario lee datos dentro de los 300 ms posteriores al encendido del temporizador, ya sea que esté leyendo los datos recién escritos u otros datos, Se distribuye por la fuerza a la biblioteca principal para realizar operaciones de lectura. Por supuesto, en aplicaciones reales, el sistema UMP permite modificar el valor de configuración de 300 ms, pero en términos generales, 300 ms puede garantizar que los datos se copie a la base de datos esclava después de escribirse en la base de datos maestra.
2.3.3. Subbase de datos y subtabla
UMP admite particiones fragmentadas/horizontales que son transparentes para los usuarios, pero los usuarios deben especificar el tipo como instancia múltiple y establecer el número de instancias al crear una cuenta. El sistema creará múltiples grupos de instancias de MySQL según la configuración del usuario. Además, los usuarios también deben establecer sus propias reglas para fragmentar bases de datos y tablas, por ejemplo, deben determinar el campo de partición, es decir, qué campo debe usarse para fragmentar bases de datos y tablas, y cómo se modifican los valores en el Los campos de partición se asignan a diferentes instancias de MySQL.
Cuando se utilizan subbases de datos y subtablas, el sistema procesa las consultas de los usuarios de la siguiente manera: primero, el servidor proxy analiza la declaración SQL del usuario y extrae la información necesaria para reescribir y distribuir la declaración SQL; segundo, reescribe la declaración SQL para obtener múltiples Apunte a las subdeclaraciones de la instancia de MySQL correspondiente y luego distribuya las subdeclaraciones a la instancia de MySQL correspondiente para su ejecución; finalmente, reciba los resultados de ejecución de la declaración SQL de cada instancia de MySQL y combínelos para obtener el resultado final.
2.3.4. Administracion de recursos
El sistema UMP utiliza un mecanismo de grupo de recursos para administrar recursos informáticos como CPU, memoria, disco, etc. en el servidor de base de datos. Todos los recursos informáticos se colocan en el grupo de recursos para una asignación unificada. El grupo de recursos es la unidad básica para asignar recursos. a instancias de MySQL. Todos los servidores de todo el clúster se dividirán en múltiples grupos de recursos según factores como su modelo y sala de computadoras, y cada servidor se agregará al grupo de recursos correspondiente. Para cada instancia de MySQL específica, el administrador especificará el grupo de recursos donde se ubican la base de datos principal y la base de datos esclava para la instancia de MySQL en función de factores como en qué salas de computadoras se implementa la aplicación, qué recursos informáticos se requieren y luego el sistema. El servicio de administración de instancias se basará en la carga. Según el principio de equilibrio, se selecciona un servidor con carga ligera del grupo de recursos para crear una instancia de MySQL. Sobre la base de la división del grupo de recursos, UMP también utiliza grupos C dentro de cada servidor para refinar aún más los recursos, limitando así el límite superior de recursos utilizados por cada grupo de procesos y garantizando el aislamiento mutuo entre los grupos de procesos.
2.3.5. Programación de recursos
Hay tres tipos de usuarios en el sistema UMP: usuarios con tráfico y volumen de datos relativamente pequeños, usuarios de escala media y usuarios que necesitan dividir bases de datos y tablas. Varios usuarios de pequeña escala pueden compartir la misma instancia de MySQL. Para usuarios medianos, cada usuario tiene una instancia MySQL exclusiva. Los usuarios pueden ajustar el espacio de memoria y el espacio en disco según sus propias necesidades, si el usuario necesita más recursos puede migrar a un servidor con recursos libres o una configuración superior. Para los usuarios con subbases de datos y tablas, tendrán múltiples instancias MySQL independientes, estas instancias pueden coexistir en la misma máquina física, o cada instancia puede ocupar una máquina física exclusivamente.
UMP implementa la programación de recursos mediante la migración de instancias de MySQL. Con la ayuda del sistema Yugong desarrollado por el equipo de middleware de Alibaba Group, UMP puede lograr una expansión, contracción y migración dinámicas sin tiempo de inactividad.
2.3.6.Aislamiento de recursos
Cuando varios usuarios comparten la misma instancia de MySQL o coexisten varias instancias de MySQL en la misma máquina física, para proteger la seguridad de las aplicaciones y los datos del usuario, se debe implementar el aislamiento de recursos; de lo contrario, el consumo excesivo de recursos del sistema por parte de un usuario afectará gravemente Rendimiento operativo de otros usuarios. El sistema UMP adopta dos métodos de aislamiento de recursos que se muestran en la Tabla 6-4.
2.3.7.Seguridad de datos
La seguridad de los datos es la clave para permitir a los usuarios utilizar productos de bases de datos en la nube con confianza, especialmente para los usuarios empresariales. La base de datos almacena una gran cantidad de datos comerciales, algunos de los cuales son secretos comerciales y, una vez filtrados, causarán pérdidas a la empresa. El sistema UMP ha diseñado varios mecanismos para garantizar la seguridad de los datos.
(1) Conexión de base de datos SSL. SSL (Secure Sockets Layer) es un protocolo de seguridad que proporciona seguridad e integridad de datos para las comunicaciones de red. Cifra las conexiones de red en la capa de transporte. El servidor Proxy implementa un protocolo cliente/servidor MySQL completo y puede establecer una conexión de base de datos SSL con el cliente.
(2) Lista blanca de IP de acceso a datos. Puede colocar las direcciones IP a las que se les permite acceder a la base de datos en la nube en una "lista blanca", solo las direcciones IP en la lista blanca pueden acceder y se denegará el acceso desde otras direcciones IP, lo que garantiza aún más la seguridad de la cuenta.
(3) Registrar registros de operaciones del usuario. Todos los registros de operaciones del usuario se registrarán en el servidor de análisis de registros. Al verificar los registros de operaciones del usuario, se pueden descubrir vulnerabilidades de seguridad ocultas.
(4) Intercepción de SQL. El servidor proxy puede interceptar varios tipos de declaraciones SQL según los requisitos, como la declaración de escaneo de tabla completa "select *".