La guía definitiva para el rendimiento de Java - Resumen 4
Caja de herramientas de ajuste de rendimiento de Java
Herramientas y análisis del sistema operativo
Cola de ejecución de la CPU
sumario rápido
- Al verificar el rendimiento de la aplicación, lo primero que debe observar es el tiempo de CPU.
- El objetivo de optimizar el código es aumentar en lugar de disminuir el uso de la CPU (durante un período de tiempo más corto).
- Antes de intentar optimizar su aplicación en profundidad, primero debe comprender por qué el uso de la CPU es bajo.
uso del disco
Supervisar el uso del disco tiene dos propósitos. El primer propósito tiene que ver con la aplicación en sí misma: si la aplicación realiza muchas E/S de disco, entonces la E/S puede convertirse fácilmente en un cuello de botella.
Saber cuándo la E/S del disco es el cuello de botella es difícil porque depende del comportamiento de la aplicación. Si la aplicación no se almacena en el búfer de manera eficaz al escribir datos en el disco, las estadísticas de E/S del disco serán muy bajas. Sin embargo, si la aplicación realiza más E/S de las que puede manejar el disco, las estadísticas de E/S del disco serán muy altas. Es necesario mejorar el rendimiento en ambos casos.
Algunos sistemas tienen una mejor supervisión básica de E/S que otros. Esto es parte de la salida de iostat en el sistema Linux:
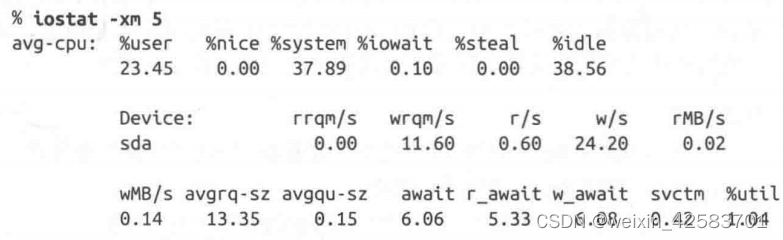
la aplicación está escribiendo datos en el disco sda. A primera vista, las estadísticas del disco no son malas. w_await, el tiempo para escribir cada E/S, es bastante bajo (6,08 ms) y el uso del disco es solo del 1,04 %. (Los valores aceptables dependen del disco físico, por debajo de 15 ms). Pero aquí hay una pista de que algo anda mal: el sistema pasa el 37,89 % de su tiempo en el kernel. Una posibilidad es que el sistema esté realizando otras E/S (en otros programas). Si todo este tiempo del sistema proviene de la aplicación que se está probando, algo ineficiente está ocurriendo.
Otra pista es que el sistema escribe a 24,2 por segundo: eso es mucho cuando escribe solo 0,14 MB por segundo. Esto muestra que la E/S ya es el cuello de botella y el siguiente paso es verificar cómo está escrita la aplicación.
Si la velocidad del disco no puede seguir el ritmo de la solicitud de E/S, aparece el otro lado del problema:

Linux tiene la ventaja de decirnos inmediatamente que la tasa de uso del disco es del 100%. También nos dice que el 47,89% de los eventos del proceso están en iowait(es decir, esperando disco).
Una segunda razón para monitorear el uso del disco, incluso si no se espera que la aplicación tenga un alto nivel de E/S, es ayudar a monitorear si el sistema está intercambiando memoria. Las computadoras tienen una cantidad fija de memoria física, pero pueden usar una memoria virtual mucho más grande para ejecutar una variedad de aplicaciones. Las aplicaciones reservan más memoria de la que realmente necesitan y, a menudo, solo usan una parte de la memoria que se les asigna. En ambos casos, el sistema operativo puede mantener la memoria no utilizada en el disco y paginarla en la memoria física cuando sea necesario.
En la mayoría de los casos, este tipo de administración de memoria puede funcionar bien, especialmente las aplicaciones interactivas y los programas GUI. Este tipo de gestión es menos eficaz para las aplicaciones de tipo servidor, que requieren más memoria. Debido al montón de Java, esta gestión es mala para cualquier programa Java.
Los sistemas que intercambian memoria (mover datos de la memoria principal al disco o viceversa) generalmente tienen un rendimiento más bajo. Hay otras herramientas del sistema que pueden informar sobre el intercambio del sistema, por ejemplo, hay dos columnas en la salida de vmstat (si se intercambia, también se intercambia) que pueden advertirnos si el sistema se está intercambiando. La actividad del disco indica que puede estar ocurriendo un intercambio de memoria.
sumario rápido
- Supervisar el uso del disco es importante para todas las aplicaciones. Incluso para las aplicaciones que no escriben directamente en el disco, el intercambio de sistemas aún puede afectar su rendimiento.
- Las aplicaciones que escriben en el disco encuentran cuellos de botella porque los datos no se escriben de manera eficiente (el rendimiento es demasiado bajo) o porque se escriben demasiados datos (el rendimiento es demasiado alto).
uso de la red
Si la aplicación requiere que la red se ejecute, como un servidor de aplicaciones Java EE, también se debe monitorear el tráfico de la red. El uso de la red es similar al tráfico del disco: una aplicación puede estar infrautilizando la red, por lo que el ancho de banda es bajo o la cantidad total de datos que se escriben en una interfaz de red es más de lo que puede manejar.
Las herramientas estándar del sistema no son buenas para monitorear el tráfico de la red, ya que generalmente solo pueden mostrar la cantidad de datagramas y bytes enviados y recibidos por una interfaz de red. Si bien esta información es útil, no puede decirnos si la red está infrautilizada o sobreutilizada. La herramienta básica para que los sistemas Unix monitoreen la red es netstat, que puede mostrar el resumen del tráfico de cada interfaz de red, incluido el uso de la interfaz de red: e1000g1

en el ejemplo es una interfaz de 1000 MB y la tasa de uso es muy baja ( 0,33%). Esta herramienta (y otras similares) se puede utilizar para calcular el uso de la interfaz. En la salida anterior, la velocidad de escritura de datos de la interfaz es de 225,7 Kbps y la velocidad de lectura es de 176,2 Kbps. Para una red de 1000 MB, la tasa de utilización puede ser del 0,33 % después de la división, y nicstat también puede calcular automáticamente el ancho de banda de la interfaz.
Herramientas como typeperf o netstat pueden reportar datos leídos y escritos, pero para calcular el uso de la red, usted mismo debe programar el ancho de banda de la interfaz. La unidad reportada por las herramientas generales es bytes/segundo (Bps), pero la unidad de ancho de banda es bits/segundo (bps). Una red de 1000 megabits maneja 125 megabytes (MB) por segundo. En este ejemplo, la lectura es 0,22 MBps, la escritura es 0,16 MBps, sume y divida por 125 para obtener un 0,33 % de uso. nicstat es más cómodo de usar.
La red no puede soportar el 100% de utilización. Para una LAN Ethernet local, la utilización sostenida de la red por encima del 40 % significa que la interfaz está saturada. Si la red es de conmutación de paquetes o utiliza un medio de transmisión diferente, el valor máximo de utilización de la red puede ser diferente, por lo que es mejor evaluar la arquitectura de la red antes de determinar el valor apropiado. Este valor no tiene nada que ver con Java, sino que simplemente utiliza parámetros de red e interfaces del sistema operativo.
sumario rápido
- Para aplicaciones basadas en red, es importante monitorear la red para asegurarse de que no sea un cuello de botella.
-
往网络写数据的应用遇到瓶颈,可能是因为写数据的效率太低(吞吐量太低),也可能是因为写入了太多的数据(吞吐量太高)。
Herramientas de supervisión de Java
Para obtener información sobre la propia JVM, debe utilizar las herramientas de supervisión de Java. El JDK viene con las herramientas que se enumeran a continuación:
- jcnd
Se utiliza para imprimir las clases básicas, los subprocesos y la información de la máquina virtual involucrada en el proceso de Java. Funciona con scripts y se puede ejecutar así:
%jcmd process_id conmand optional_arguments
jcmd helpTodos los comandos se pueden enumerar. jcmd help <command>Se puede dar la sintaxis para un comando en particular.
- jconsole
Proporciona una vista gráfica de la actividad de JVM, incluido el uso de subprocesos, el uso de clases y la actividad de GC.
- jajaja
Lee volcados de memoria y ayuda con el análisis. Es una ocurrencia tardía.
- jmap
Proporciona volcados de almacenamiento dinámico y otra información sobre el uso de la memoria JVM. Se puede adaptar para secuencias de comandos, pero el volcado de almacenamiento dinámico se debe utilizar en una herramienta de análisis post-mortem.
- jinfo
Vea las propiedades del sistema de la JVM, puede establecer dinámicamente algunas propiedades del sistema. Disponible para guiones.
- jstack
Volcar la información de la pila del proceso Java. Disponible para guiones.
- estar de pie
Proporciona información sobre el GC y la actividad de carga de clases. Disponible para guiones.
- jvisualvm
Una herramienta GUI para monitorear la JVM, que se puede usar para analizar aplicaciones en ejecución y analizar volcados de almacenamiento dinámico de JVM (después del evento, jvisualvm también puede capturar volcados de almacenamiento dinámico de programa en tiempo real).
Estas herramientas son ampliamente utilizadas en las siguientes áreas:
- Información básica de la máquina virtual
- información del hilo
- informacion de la clase
- Análisis de cromatografía de gases en tiempo real
- Procesamiento post mortem de volcados de pila
- Análisis de rendimiento de JVM
No existe una correspondencia uno a uno entre las herramientas y los campos de aplicación, y muchas herramientas se pueden utilizar en más de un campo. Entonces, en lugar de examinar cada herramienta individualmente, observamos las áreas observables importantes de Java y discutimos cómo estas herramientas brindan esta información. Al mismo tiempo, también discutiremos otras herramientas (algunas de código abierto, algunas comerciales) que brindan la misma funcionalidad básica pero tienen ciertas ventajas sobre las herramientas básicas de JDK.
Información básica de la máquina virtual
Las herramientas de JVM pueden proporcionar información básica de ejecución de un proceso de JVM: cuánto tiempo se ha estado ejecutando, qué indicadores de JVM se utilizan y las propiedades del sistema de JVM, etc.
Tiempo de ejecución
Este comando puede ver el tiempo de ejecución de JVM:
% jcmd process_id VM.uptime
Propiedades del sistema Entradas individuales
que se pueden mostrar con los siguientes comandos .System.getProperties()
% jcmd process_id VM.systen_properties
o
% jinfo -sysprops process_id
Esto incluye todas las propiedades establecidas a través de la línea de comando -D flag, todas las propiedades agregadas dinámicamente por la aplicación y las propiedades predeterminadas de JVM.
Versión de JVM
Obtenga la versión de JVM de la siguiente manera:
% jcmd process_id VM.version
La página "Resumen de VM" de la línea de comando de JVM
jconsole puede mostrar la línea de comando utilizada por el programa o mostrarla con jcmd:% jcmd process_id VM.command_line
Indicadores de ajuste de JVM
Puede obtener los indicadores de ajuste de JVM que son efectivos para su aplicación de las siguientes maneras:
% jcmd process_id VM.flags [-all]
Indicadores de ajuste
La JVM puede establecer una serie de indicadores de ajuste, los dos últimos ejemplos de jcmd anteriores son útiles para obtener este tipo de información. command_line muestra las banderas especificadas directamente en la línea de comando. flags muestra las banderas establecidas por la línea de comando, así como las banderas establecidas directamente por la JVM (porque sus valores están determinados por la optimización automática). Cuando se agrega todo a este comando, se pueden enumerar todos los indicadores dentro de la JVM.
Al diagnosticar problemas de rendimiento, es común averiguar qué banderas están en juego. Mientras se ejecuta la JVM, puede hacerlo con jcmd. Agregar en la línea de comando -XX:+Printflagsfinalpuede ser útil si desea averiguar cuáles son los valores predeterminados específicos de la plataforma para una JVM en particular.
Para averiguar qué banderas están configuradas para una plataforma en particular, ejecute el siguiente comando:
% java other_options -XX:+PrintFlagsFinal -version
...unos cientos de líneas de salida, incluyendo...
uintx InitialHeapSize : = 4169431040 {product}
intx InlineSmallCode = 2000 {pd product}
Todas las banderas deben incluirse en la línea de comando, ya que algunas banderas afectan a otras, especialmente las relacionadas con GC. Este comando imprimirá una lista completa de banderas de JVM y sus valores (el resultado es el mismo que imprime jcnd combinado con VM.flags -all). Los datos de marca para estos comandos se muestran en una de las dos formas descritas anteriormente. Los dos puntos en la línea 1 de la salida indican que el indicador está utilizando un valor no predeterminado. Esta situación puede deberse a las siguientes razones.
- Los valores de las banderas se especifican directamente en la línea de comando.
- Otras banderas cambian indirectamente el valor de esta bandera.
- La JVM optimiza automáticamente el valor predeterminado calculado.
La línea 2 (sin los dos puntos) indica que el valor es el predeterminado para esta versión de JVM. Los valores predeterminados para algunas banderas pueden variar en diferentes plataformas, como se indica en la columna más a la derecha de la salida. producto significa que la configuración predeterminada es la misma en todas las plataformas. Los valores predeterminados para los indicadores de representación del producto pd son independientes de la plataforma.
Otra herramienta para ver dicha información sobre una aplicación en ejecución se llama jinfo. Lo bueno de jinfo es que permite que un programa cambie el valor de una bandera mientras se ejecuta.
Aquí se explica cómo obtener los valores de todas las banderas en un proceso:
% jinfo -flags process_id
Cuando jinfo tiene -flags, puede proporcionar información sobre todas las banderas; de lo contrario, solo imprime las banderas especificadas en la línea de comando. Ninguno
de los datos es tan legible como -XX:+Printflagsfinal, pero jinfo tiene otras características notables.
jinfo puede verificar el valor de las banderas individuales:
% jinfo -flag PrintGCDetails process_id
-XX:+PrintGCDetails
Aunque jinfo en sí mismo no indicará si es manejable, jinfo puede activar o desactivar el indicador manejable (como se identifica en la salida final de Printflags):
% jinfo -flag -PrintGCDetails process_id # turns off PrintGCDetails
% jinfo -flag PrintGCDetails process_id
-XX:-PrintGCDetails
Tenga en cuenta que jinfo puede cambiar el valor de cualquier indicador, pero eso no significa que la JVM responderá al cambio. Por ejemplo, la mayoría de los indicadores que afectan el comportamiento del algoritmo GC se utilizan al inicio para determinar cómo se comporta el recolector de elementos no utilizados. Cambiar el valor de la bandera más tarde a través de jinfo no hace que la JVM cambie su comportamiento. Continúa con el algoritmo original. Por lo tanto, esta técnica solo funcionará para aquellas banderas marcadas como manejables en la salida final de Printflags.
sumario rápido
- jcmd se puede usar para encontrar información básica sobre la JVM que ejecuta una aplicación, incluidos los valores de todos los indicadores de ajuste.
- 2. Agregue l en la línea de comando
-XX:+Printflagsfinapara generar el valor predeterminado de la bandera. Esto es útil cuando se observan los valores predeterminados determinados por la optimización automática específica de la plataforma.
3. La información es útil al inspeccionar (y en algunos casos cambiar) banderas individuales.